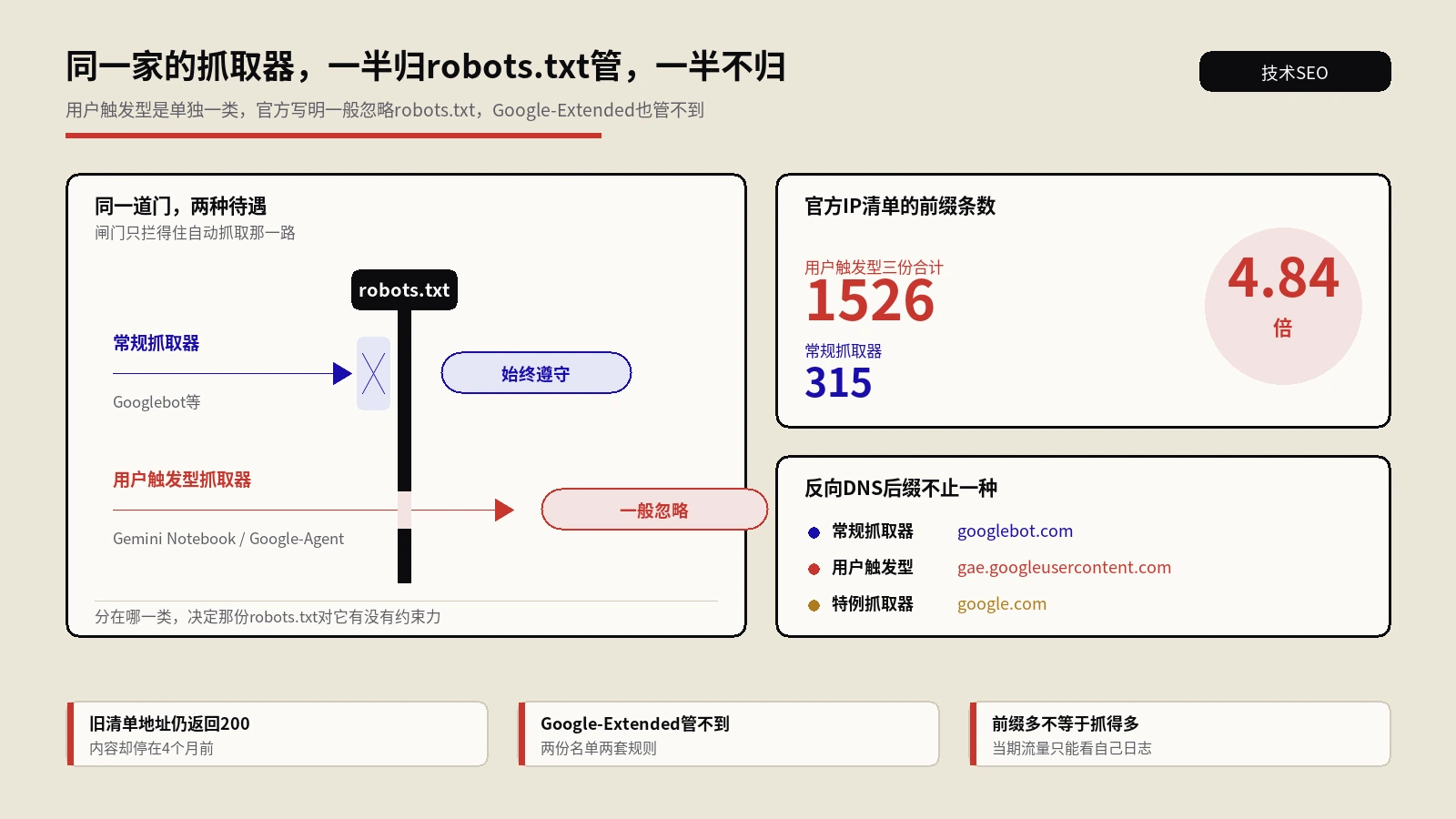
防火墙到底拦不拦得住AI爬虫?答案没那么简单
本文目录
- 为什么WAF和Bot Management会误伤搜索与AI爬虫?
- "挡bot"和"挡恶意bot"的天然矛盾
- 默认模式越来越激进
- SaaS化Bot Management的“共享指纹库”问题
- Googlebot等合规爬虫不会主动报错
- 哪些信号说明你的站正在被WAF误拦?
- GSC抓取统计里的“服务器错误”比例突增
- 新页面收录速度突然变慢
- AI引擎里完全看不到你的品牌
- 第三方SEO工具的反链抓取数据停滞
- 合作伙伴说“你家网站打不开”但你测又正常
- 渲染服务(Prerender / Rendertron / Cloudflare Workers AI)对自家站点返回异常
- 现代WAF是怎么识别bot的?
- 第一层:UA字符串与已知IP列表
- 第二层:TLS与TCP指纹(JA3/JA4)
- 第三层:JS执行能力测试
- 第四层:行为序列分析
- 怎么从日志和GSC里确诊误拦?
- 从GSC抓取统计反推
- 从服务器/CDN日志精确确诊
- 对AI爬虫的特殊确诊路径
- 各家主流WAF的放行配置怎么做?
- Cloudflare:分级放行的关键节点
- Akamai:Bot Manager的Category Action
- Imperva:Advanced Bot Protection的Site Specific Policy
- AWS WAF + CloudFront:靠Bot Control Managed Rule
- 自建nginx / OpenResty:基于反向DNS的白名单lua
- 跨层一致性——CDN、WAF、源站三层都不能漏
- AI爬虫的特殊情况——该放还是该挡?
- 不同AI爬虫的目的与价值差异
- 战略决策——放、挡、还是分类放
- 放行配置必须双层——WAF和robots.txt都不能漏
- 一个真实的“半年掉60% 收录”案例
- 出海工业品B2B的诡异掉量
- 诊断过程:日志一翻就明白
- 修复与恢复曲线
- 常见问题解答
- WAF误拦多久能恢复?
- 怎么验证一个声称是Googlebot的请求是真的?
- 所有AI爬虫都应该放行吗?
- Cloudflare升级套餐时怎么避免误拦?
- robots.txt和WAF哪个生效优先?
- 反链工具数据停滞是不是一定WAF拦了?
- 修复WAF后流量多久能涨回来?
- 权威参考资料
摘要:站点收录在掉,但你做了的所有SEO看着都没问题——这种情况下首先该查的不是内容、不是技术SEO,是WAF。过去几年Cloudflare、Akamai、Imperva这类Bot Management默认越来越激进,加上AI爬虫的爆发让指纹识别更敏感,搜索与AI爬虫被静默拦的案例反而越来越多。这篇按怎么识别误拦信号、WAF现代识别机理、日志与GSC双向确诊、各家主流配置怎么放行、AI爬虫该放还是挡六件事讲透,附一个出海工业品站半年从6000收录掉到2400的真实复盘。
这两年保哥接的SEO救火案例里,越来越多走到最后发现锅在WAF——不在内容、不在结构、不在外链。一个常见的剧本是:客户更换了CDN或开启了Cloudflare Bot Management默认级别,三四周之后GSC抓取异常飙升、收录数缓慢掉、流量看着没大变化但新页几乎进不去——大家忙着查内容质量、查robots、查hreflang,没人想到防火墙这一层把搜索引擎机器人当攻击拦了。等发现时多数已经掉了20%-60% 的收录,恢复又是6-12周的事。
这篇专门把这件事讲透。和站内已有的几篇是分工的:AI爬虫逆向工程那篇讲的是从抓取行为反推爬虫的真实偏好(outbound观察),本篇讲的是inbound——你的防火墙在拦谁;robots协议机制那篇讲的是协议层的访问规则(合规爬虫会主动遵守),本篇讲WAF层(即使爬虫想抓也可能被防火墙挡住);日志分析那篇讲的是常规爬虫真伪辨识与抓取预算,本篇讲日志里如何挑出被拦的爬虫信号;和GSC完全指南那篇的关系是:GSC抓取统计是确诊WAF误拦最直接的入口之一。四篇合起来才是完整的爬虫可见性工程。
为什么WAF和Bot Management会误伤搜索与AI爬虫?
WAF与Bot Management设计初衷是挡爬虫——挡的是恶意爬虫(爬数据、刷流量、薅羊毛、扫漏洞)。问题是它没有上帝视角,识别bot与识别恶意bot是两件不同的事,技术上很难区分清楚。一刀切到激进档位,连合规搜索引擎都会被吞。
"挡bot"和"挡恶意bot"的天然矛盾
所有Bot Management产品本质上做的是“判断这次请求像不像人发出的”。判断维度大约就那几样:UA字符串、IP段、请求频率、TLS/TCP指纹、JavaScript执行能力、鼠标轨迹与浏览器API调用。Googlebot在这几个维度里恰好都不太像人——它的请求模式是机械的、它不执行多数页面JS、它没有鼠标轨迹、它的IP段虽然公开但相对集中。所以当WAF调到激进模式,Googlebot的请求会被判为“有bot嫌疑”,跟着真正的恶意爬虫一起被处理。
默认模式越来越激进
过去几年这件事在悄悄变。2018年的Cloudflare Bot Fight Mode推出时是“可选附加”;到2022年Super Bot Fight Mode进入很多Pro套餐默认开启;到2024-2025年面对AI爬虫爆发的现实,多数Bot Management产品默认级别又调高一档。这意味着同一台站点几年前WAF不会误拦,今天可能在你不知情下已经在拦——尤其是续费时套餐升级、CDN更换、安全团队上线新规则之后,是误拦最高发的时间窗口。
SaaS化Bot Management的“共享指纹库”问题
现代Bot Management几乎都是SaaS模式——Cloudflare、Akamai、Imperva用的是一套全网共享的bot指纹模型,对所有客户站点采用同样的判别逻辑。这种模式有规模优势(一家新型恶意爬虫被某家客户标记后,全网客户都自动获益),但也有副作用:判别模型为了在大盘上保持高准确率,对个别站点的“合理bot流量分布”是没有上下文的。一家典型新闻站日常60% 流量来自合规爬虫是正常的,一家B2B静态官网正常爬虫比例也就10%——但WAF大模型用同一套阈值。结果是某些行业站点天然处在“爬虫比例偏高”位置,更容易被误判。这部分要靠人工干预——把自己站点的合规爬虫显式加白名单,让WAF不用统一阈值判断。
Googlebot等合规爬虫不会主动报错
这件事最阴险的地方是:被拦后没有人会告诉你。Googlebot收到403 / 429 / 503之后会按指数退避降低抓取频率,不会发邮件告状;过几周完全停掉对该路径的访问。GSC抓取统计要2-4周才看出来明显异常;收录变化要再4-8周才在site: 数字上反映出来;自然流量影响要更久。所以等业务侧发现“流量怎么少了”的时候,离根因发生通常已经过去三四个月。
| WAF处置 | 合规爬虫反应 | 影响显现周期 | 恢复周期 |
|---|---|---|---|
| 403直接拒绝 | 指数退避,三五周后该IP段对该路径停抓 | 4-6周(GSC抓取统计可见) | 修复后6-12周 |
| 429限速 | 降频抓取,正常但缓慢 | 6-8周(收录新增放缓) | 修复后4-8周 |
| 503临时不可用 | 重试几次后退避 | 3-5周 | 修复后4-6周 |
| JS Challenge / CAPTCHA | 无法解决,等同403 | 4-6周 | 修复后6-12周 |
| Slow response(>5s) | 仍抓取但抓取预算分摊变差 | 持续渐进,难发现 | 修复后2-4周 |
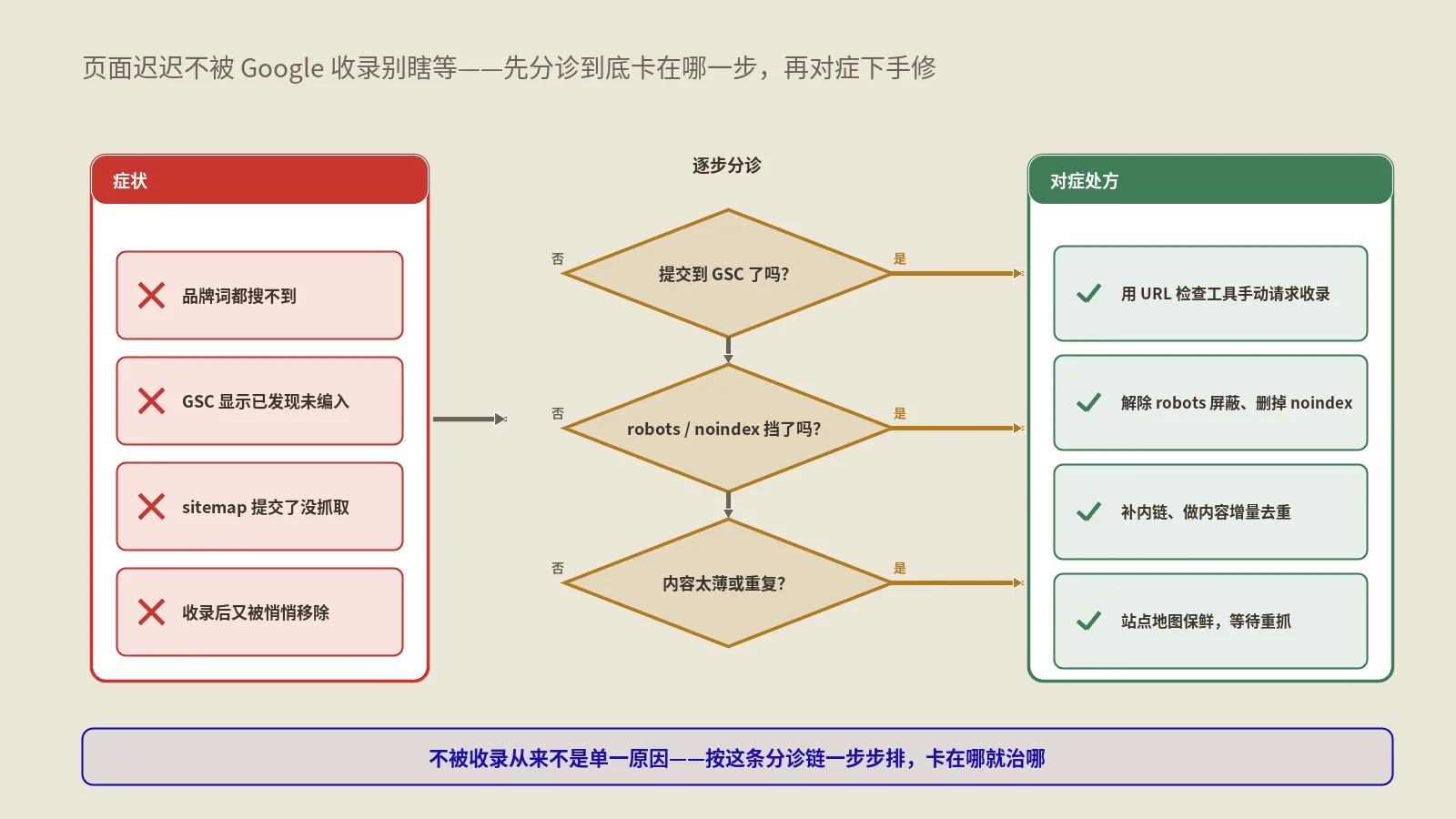
哪些信号说明你的站正在被WAF误拦?
WAF误拦不会发警报,它是一组渐进信号。要主动监测,否则就在“静默掉量”状态。下面几个是过去几年实战里反复看到的早期信号——任何一个异常单独可能没事,组合起来出现就要立刻去WAF那一层翻设置。
GSC抓取统计里的“服务器错误”比例突增
GSC > 设置 > 抓取统计信息里,按响应码看曲线。任何站点都有少量4xx/5xx是正常的(删除的页、临时维护),但如果某周503或429占比从0.x% 突然跳到3%-5% 甚至更高,几乎一定是WAF在拦。Googlebot自己的真实错误率长期稳定在1% 以下,跨过3% 都属于异常窗口。这一信号是最早期的——比收录变化早4-6周可见。
新页面收录速度突然变慢
正常情况下一篇新内容上线后1-7天会出现在site: 索引里,热门新闻类页面甚至几小时即可。如果某段时间起新页面普遍要2-4周才能进索引,且抓取统计里看到这些URL实际被请求次数减少——这是WAF已经在拦的中期信号。这时候老页面排名还看着稳定,但是新内容投资进入“延迟收益”状态。
AI引擎里完全看不到你的品牌
这条是2024-2025年新出现的信号。如果你在ChatGPT / Perplexity / Google AI Mode里用品牌词查询,发现自己几乎从不被引用、或者出现的内容是几年前的旧版本——很可能AI爬虫被你的WAF拦了。AI爬虫普遍比Googlebot更新但同时更脆弱——它们用的IP段更动态、UA还在演化、对JS Challenge几乎完全束手。一个2024年新建的页面,如果三个月后在主流AI引擎里完全检索不到,要先怀疑爬虫被拦。
第三方SEO工具的反链抓取数据停滞
这个信号容易被误读。Ahrefs、Semrush、Moz这类工具自己的爬虫(AhrefsBot、SemrushBot等)也会被Bot Management拦掉。如果你看到反链工具里你家站点的“最后一次抓取时间”停在几个月前、或者发现你能看到的对手站点比你能看到的自家页面还多——那是你家WAF把这些SEO工具一起拦了。这件事的连锁影响是:你自己看不见自己的反链画像、看不见对手内容更新——业务侧表现为“数据驱动SEO完全失灵”。
合作伙伴说“你家网站打不开”但你测又正常
当Bot Management调到激进档位,部分公司的网络出口(VPN、企业代理、IDC数据中心IP段)也会被当作bot拦下。一个常见症状是:合作伙伴、记者、分析师反馈“你家网站打不开”,但你自己从家庭网络打开毫无问题。这是WAF已经过度激进的另一个信号——不止误拦机器人,连合规人类访问者都开始被吞。
渲染服务(Prerender / Rendertron / Cloudflare Workers AI)对自家站点返回异常
这条信号在用了第三方渲染服务的SPA/SSR混合站点上很常见。如果你的站点用了Prerender、Rendertron或类似SSR服务给爬虫返回预渲染页面——这些服务自身是“无头浏览器”性质,本身就会被一些WAF当作bot。结果是Googlebot通过Prerender拿到的页面其实是WAF给的challenge页,连内容都没看到。这一信号要从渲染服务的日志里去验证,对方应该有“成功率”指标——长期低于95% 几乎一定有WAF干预。
现代WAF是怎么识别bot的?
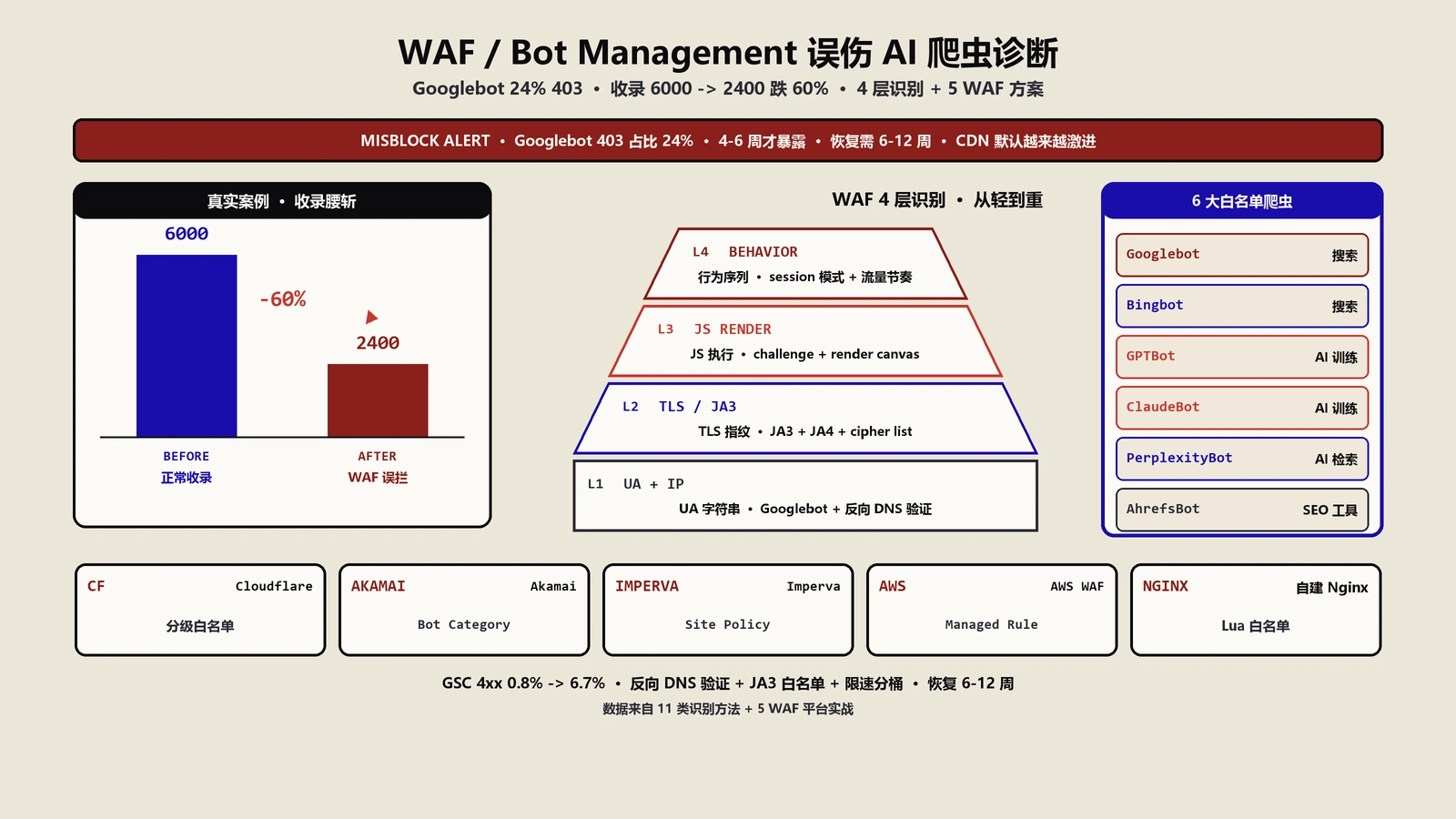
要解决误拦,先得理解WAF是怎么识别bot的。Bot Management的检测机制大致分四层——理解这四层,你就能反过来诊断自己的爬虫为什么被拦。
第一层:UA字符串与已知IP列表
最基础也最容易出错的一层。UA字符串可以伪造,所以单纯靠UA判断会漏放真爬虫(伪UA)也错拦真用户(旧浏览器)。改进做法是UA + IP双重比对——Googlebot的IP段公开(developers.google.com/search/apis/ipranges/googlebot.json),WAF可以验证UA声称的Googlebot是否来自这个段。问题是各家WAF厂商的IP列表更新频率不同,且AI爬虫普遍没有公开IP段——这就是为什么Googlebot容易被正确放、AI爬虫常常被错挡。
第二层:TLS与TCP指纹(JA3/JA4)
这是过去三年识别力提升最大的一层。JA3、JA4是基于TLS握手参数的指纹算法——任何HTTPS请求建立连接时,客户端会发送一组cipher suite、extension list、版本号等参数,这些参数在不同浏览器、不同库、不同爬虫框架上有可识别的特征。Chrome用某种组合,curl用另一种,Python requests又是一种——WAF收集了大量真实人类浏览器的JA3/JA4指纹库,遇到不在库里的就当bot处理。Googlebot用的是基于Chromium的渲染器,指纹相对接近真实浏览器;但很多AI爬虫还在用通用HTTP客户端库,指纹一看就不像人。
第三层:JS执行能力测试
JS Challenge是Bot Management最常用也最具杀伤力的一招——服务端返回一段需要客户端执行JS才能拿到真正内容的代码,能执行就放过、不能执行就当bot。问题是Googlebot有限度执行JS但不是所有;多数AI爬虫根本不执行JS(成本太高)。所以JS Challenge几乎一定误拦AI爬虫,对Googlebot也常拦。如果你的WAF启用了对全站的JS Challenge,几乎可以肯定AI爬虫被全挡。
第四层:行为序列分析
最高阶的一层。Bot Management会观察一段时间内请求的序列模式——人类访问通常是“访问首页→浏览一段时间→点击链接→停留→关闭”这种带停顿的非线性序列;爬虫访问通常是“访问列表页→访问详情页A→访问详情页B→访问详情页C→……”机械序列。这一层的识别准确度高但延迟也高——通常要几分钟到几小时才有结论,更适合追加封禁而非即时挡。
| 检测层 | 对Googlebot误拦率 | 对AI爬虫误拦率 | 关闭建议 |
|---|---|---|---|
| UA + IP比对 | 低(IP段公开) | 中(部分AI爬虫IP未公开) | 保留,配合白名单 |
| TLS/JA3指纹 | 中 | 高 | 对验证过的UA跳过 |
| JS Challenge | 中 | 极高 | 不要对SEO关键路径开启 |
| 行为序列分析 | 低 | 中 | 调阈值,不要急封 |
怎么从日志和GSC里确诊误拦?
确诊误拦的标准做法是双向验证:从GSC看Google这边看到什么,从服务器日志看你这边给了什么。两边对上就能定位问题。
从GSC抓取统计反推
GSC > 设置 > 抓取统计信息提供分维度的数据。重点看三个:响应码分布(4xx/5xx比例是否异常)、按文件类型分布(HTML抓取比例是否大幅下降)、按响应时间分布(响应时间是否突变拉长)。如果三项里任意两项异常,几乎一定有问题在服务侧。这一步只能定性——告诉你“出问题了”但不告诉你“是WAF拦的还是真服务器问题”。
从服务器/CDN日志精确确诊
日志层确诊比GSC精确。要找的字段是:UA含Googlebot/Bingbot/GPTBot/ClaudeBot等已知爬虫标识的请求,对应的HTTP响应码分布。正常情况下合规爬虫的200率应该 ≥95%;如果发现403/429/503比例显著上升,就是WAF在干预。日志分析的具体技巧那篇专门讲过,本篇要补的是“爬虫UA真伪反向DNS验证”——拿到声称是Googlebot的IP,做反向DNS查询应该返回googlebot.com或google.com域名结尾,再正向DNS查验证回到原IP,两步对上才是真Googlebot。如果发现“被拦的"Googlebot"实际是伪UA攻击”——那不是误拦,是正确防御。
对AI爬虫的特殊确诊路径
AI爬虫确诊比Googlebot难。它们没有GSC等价物,所以只能从两边接近:服务器日志看GPTBot、ClaudeBot、PerplexityBot、CCBot、OAI-SearchBot等UA的200率;再用品牌词在AI引擎里手动测“你家被引用情况”——如果服务器日志里AI爬虫请求几乎为零,且AI引擎里检索不到你的新内容,就是被拦。这件事要做月度监控,工具上现在Cloudflare自己的Bot Analytics、Ahrefs的Brand Radar、专门做AI监控的Profound / Otterly都覆盖了这部分指标。
各家主流WAF的放行配置怎么做?
不同WAF配置入口差异大,但放行思路是统一的:建立爬虫白名单 + 跳过激进规则 + 持续监控。下面按几家主流厂商给出具体路径。
Cloudflare:分级放行的关键节点
Cloudflare是市占最高的WAF/CDN之一,配置入口有三层。第一层Bot Fight Mode(Security > Bots)——对“已验证好爬虫”默认放行,但对“可能是bot”的请求统一挑战。第二层Super Bot Fight Mode(Pro套餐起)——加多了对“静态资源bot”和“API路径bot”的精细控制。第三层Bot Management(Enterprise)——可按bot分数(0-99)自定义动作。
对SEO站点而言,关键动作是三个:在Security > WAF > Tools里把Googlebot、Bingbot加入“已验证好爬虫”允许列表(这是默认应该已经放行的,但2022年起部分Pro用户的Super Bot Fight Mode默认ON会重新挡);在Cache Rules里对robots.txt、sitemap.xml、ads.txt等SEO关键文件设置“Always Online”和“Bypass Cache”,避免CDN缓存导致更新延迟;针对AI爬虫(GPTBot、ClaudeBot等)显式建立WAF Rule “(http.user_agent contains "GPTBot") then Skip”。
Akamai:Bot Manager的Category Action
Akamai Bot Manager的核心是“Bot Category Action”——把已知bot按类别(Search Engine Bot、Site Monitoring、Marketing Tool等)分组配置动作。对SEO站点的建议是:Search Engine Bot类别动作设为Allow(默认)、Marketing Tool类别动作设为Allow或Monitor(Ahrefs/Semrush这类工具属于此类)、Unknown Bot类别动作设为Monitor(先看一段时间,不要直接Block)。AI爬虫在Akamai的分类里多数还在Unknown类别,需要手动加自定义规则。
Imperva:Advanced Bot Protection的Site Specific Policy
Imperva的ABP默认更激进,但提供Site Specific Policy能针对特定路径定制。建议:对全站设“moderate”等级而非默认的“aggressive”等级;对 /robots.txt、/sitemap.xml、/feed等SEO关键路径设“off”等级;对AI爬虫维护一份允许列表(UA与IP段)并定期更新。
AWS WAF + CloudFront:靠Bot Control Managed Rule
AWS WAF自身没有Cloudflare那种成熟的Bot Management体验,依赖Bot Control Managed Rule。建议启用Common Bot Control Managed Rule Group + Targeted Bot Control Managed Rule Group,并在Web ACL Rule里显式加“Verified Search Bot”类别动作为Allow。CloudFront这一层不要叠加额外IP限速规则——AWS自己的Bot Control已经处理了这块。
自建nginx / OpenResty:基于反向DNS的白名单lua
有不少B2B客户因合规或成本不上Cloudflare/Akamai,自建nginx加OpenResty来做基础bot防护。这种场景下放行Googlebot等爬虫的正确做法不是写死IP段(IP段会变),是用lua脚本:拿到声称Googlebot的请求,先做反向DNS解析→正向DNS验证两步,验证通过后直接set一个 “verified_bot=true” 变量绕过后续rate limit / WAF规则。这种自建方案要做好缓存(验证结果按IP缓存1-24小时避免每个请求都做两次DNS)。AhrefsBot/SemrushBot等也提供官方的反向DNS域名(ahrefs.com / semrush.com)可以用同样套路验证。
跨层一致性——CDN、WAF、源站三层都不能漏
容易被忽略的一层是源站防火墙。即使你把Cloudflare WAF配置好放行Googlebot,如果你源站还有fail2ban、iptables、Nginx rate limit等规则按IP拦请求,那Cloudflare转发过来的请求(已经验证过的Googlebot)到了源站还会被本地规则拦。三层规则必须保持一致——任何一层挡了,整条路径就废了。这意味着每次审计WAF配置时要从外往内扫一遍——CDN层、WAF层、源站防火墙、应用层中间件,每一层都要确认对合规爬虫放行。
AI爬虫的特殊情况——该放还是该挡?
AI爬虫这两年是新议题。它和Googlebot/Bingbot不同——后者抓你内容是为了把流量送回你的网站,前者抓你内容是为了让用户在AI答案里看到(你失去点击但获得品牌可见)。要不要放行AI爬虫成了战略级决策。
不同AI爬虫的目的与价值差异
主流AI爬虫的UA与目的差异要分清楚。GPTBot是OpenAI用于训练GPT模型的爬虫——抓的内容会进训练数据,影响未来几代模型怎么写、怎么回答;OAI-SearchBot是OpenAI用于SearchGPT实时检索的爬虫——直接影响用户在SearchGPT里搜索时是否看到你;ClaudeBot是Anthropic训练用,价值类似GPTBot;PerplexityBot是Perplexity实时检索用,每次用户提问相关内容时Perplexity会发请求抓最新;CCBot是Common Crawl用——它的数据被几乎所有LLM训练时使用,封了它等于一并被多家LLM屏蔽。每一个都决定不同的曝光场景。
战略决策——放、挡、还是分类放
有三种合理选择。第一种全放——希望最大化AI曝光、品牌建设期、不太计较内容被训练的版权问题。第二种全挡——内容是付费高价值产品、不希望被AI免费替代、流量模型不依赖搜索。第三种分类放——放“实时检索”类爬虫(OAI-SearchBot、PerplexityBot、ChatGPT-User等,目的是让用户找到你),挡“训练”类爬虫(GPTBot、ClaudeBot等,目的是把你内容融进模型),CCBot看你是否在意被通用LLM训练。第三种是目前出海中等内容资产站最常见的中庸方案。
放行配置必须双层——WAF和robots.txt都不能漏
这是最常被漏的细节。AI爬虫的合规检测同时看robots.txt(声明性允许)和WAF(实际允许)。如果你只在robots.txt里allow但WAF在挡,AI爬虫拿到的是403不是空robots.txt规则——它不会因为robots.txt允许就硬冲;如果你在WAF放行但robots.txt disallow,合规AI爬虫会主动跳过。所以决策一致性必须落到两个层面同时配置。
一个真实的“半年掉60% 收录”案例
原理讲完,下面是一个2024年保哥实际帮客户复盘的真实案例——足够典型,可以当模版用。
出海工业品B2B的诡异掉量
客户是做精密五金件出海的B2B站,2024年第一季度GSC抓取统计开始出现异常——4xx响应码占比从长期0.8% 突然跳到6.7%。当时SEO团队的第一反应是“是不是有大量旧URL在404”——但抓取报告里404比例没变,跳的是403。这一信号当时没被重视,因为site: 收录数还稳定,业务侧没感觉。
第二季度起新页面收录速度肉眼可见变慢——新发的产品规格页从原来平均3天进索引拖到14-21天。这时SEO团队怀疑过内容质量、查过技术SEO清单、甚至重新提交了Sitemap。第三季度起site: 数字开始掉——从6200慢慢往下,第四季度初到2400,自然搜索流量同步下滑约38%。客户找到我做救火。
诊断过程:日志一翻就明白
我们做的第一件事是拉CDN日志(客户用的是Cloudflare Pro套餐)。按UA = Googlebot过滤,看响应码分布——结果是200率只有71%,403占24%、503占4%。再做反向DNS验证,被拦的403请求IP段全部确认是真Googlebot来源(不是伪UA)。然后翻Cloudflare控制台,Security > Bots显示Super Bot Fight Mode在2024年1月的某次套餐升级后被默认开启——“Definitely Automated”动作设为Block,“Likely Automated”动作设为Managed Challenge。Googlebot在TLS指纹和JS执行能力上恰好落进“Likely Automated”——它收到的是JS Challenge页面,无法解决,相当于403。同样的拦截也命中了AhrefsBot、SemrushBot和所有AI爬虫。
修复与恢复曲线
修复动作分三步。第一步立刻:在Cloudflare WAF里建一条规则,按UA + 反向DNS验证后的合规爬虫显式Skip所有Bot Management规则。第二步同步:把robots.txt与WAF配置对齐,明确GPTBot、ClaudeBot、PerplexityBot等AI爬虫的放行状态。第三步监控:每周抓GSC抓取统计 + CDN日志,确认200率回到95% 以上。
修复后第二周GSC抓取统计4xx率就回落到1% 以下,第四周新页面收录速度恢复,第八周site: 数字从2400爬回4100,第十六周回到5800(接近原6200,剩下的差距是这半年内自然产生的内容衰退)。整个事件从根因发生到完全恢复历时约11个月,其中根因诊断只用了一天——只要想到去查WAF。这一案例后来成了保哥给所有出海B2B客户的SEO健康体检里第一个必看项。
常见问题解答
WAF误拦多久能恢复?
看拦截严重程度。轻度(少部分路径偶发4xx/5xx)修复后2-4周抓取就恢复正常;中度(明显持续拦截,收录数下降10%-30%)修复后6-12周收录回升;重度(半年以上持续拦截,收录跌50%+)修复后3-6个月恢复,且要主动加快内容更新与外链推进帮Google重建抓取信任。
怎么验证一个声称是Googlebot的请求是真的?
两步反向DNS验证。第一步对IP做反向DNS查询应该返回googlebot.com或google.com域名结尾;第二步对返回的域名做正向DNS解析应该回到原IP。两步都对上才是真Googlebot。多数WAF自带这套验证,Cloudflare的“Verified Bot”分类就是这么判的。
所有AI爬虫都应该放行吗?
不一定。决策维度有三:内容是否付费高价值产品、流量模型是否依赖AI引用、版权立场如何。建议起步阶段放行实时检索类(OAI-SearchBot、PerplexityBot、ChatGPT-User)观察一两个季度,再决定是否放训练类(GPTBot、ClaudeBot、CCBot)。中等内容资产站多数选实时放、训练挡的折中。
Cloudflare升级套餐时怎么避免误拦?
升级前后做两件事:升级前导出当前的WAF规则与Bot Management配置快照;升级后立即检查Security > Bots里Super Bot Fight Mode是否被默认开启,新规则是否引入JS Challenge到SEO关键路径。这两步漏掉就是上面B2B案例的剧本。
robots.txt和WAF哪个生效优先?
WAF优先。robots.txt是声明性的(合规爬虫自愿遵守),WAF是强制性的(任何请求都过WAF)。如果两个冲突——WAF挡但robots.txt允许,结果还是被挡;WAF允许但robots.txt不允许,合规爬虫会主动跳过。所以两层配置必须保持一致。
反链工具数据停滞是不是一定WAF拦了?
不一定但很可能。先排除两个干扰:你最近是否更换过域名或大量URL改写(工具需要时间重新发现)、工具账号是否欠费或权限掉了。排除之后看CDN日志里AhrefsBot/SemrushBot等UA的响应码——如果403比例高,几乎一定是WAF拦的。
修复WAF后流量多久能涨回来?
抓取恢复在前、收录恢复在中、流量恢复在后,整体跨度3-6个月。前两周抓取统计恢复;6-12周收录数回升;3-6个月自然流量回到原水平。期间要避免叠加做大改动(不要同时上重大改版、内容大规模调整、外链运动),让Google安稳建信任。
权威参考资料
本文标题:《防火墙到底拦不拦得住AI爬虫?答案没那么简单》
本文链接:https://zhangwenbao.com/waf-bot-management-search-ai-crawler-misblock-diagnosis.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0