拦AI爬虫该不该?robots+UA+WAF三层选型框架
本文目录
- 为什么2026年要重新讨论拦不拦AI爬虫?
- AI爬虫拦不拦的判断维度有哪几条?
- 拦不拦之前,先把账算清:AI爬虫到底在烧你多少服务器钱?
- 八成AI抓取是冲着喂模型去的,跟你的生意没半点关系
- 最贵的不是带宽,是动态页被一遍遍触发
- 被搅浑的还有你的分析数据
- 顺序得对:先看清,再决定拦谁
- robots.txt拦AI爬虫到底能挡住什么?
- User-Agent黑名单8家AI爬虫具体怎么写?
- WAF和CDN层挡AI爬虫的具体动作清单?
- 三层方法选型决策矩阵怎么用?
- 出海手作钢笔DTC一年盲拦后AI引用归零的复盘?
- 拦完之后必须监控的5个指标是什么?
- 主流大站怎么决策的(NYT/Reuters/Reddit/Stack Overflow对照)?
- SEO媒体类站点拦不拦AI爬虫的两个流派?
- 怎么从盲拦到细粒度授权的渐进路径?
- 常见问题解答
- 2026年到底该不该拦AI爬虫?
- robots.txt写了Disallow能不能真的挡住AI爬虫?
- User-Agent黑名单的维护成本到底多大?
- WAF拦AI爬虫最常踩的坑是什么?
- 盲拦AI爬虫最严重的代价是什么?
- 大型新闻媒体和UGC社区怎么决策的?
- 权威参考资料
摘要:有个客户拦完AI爬虫一年,每月发现少了5万美金。账是这样算的——盲拦之前ChatGPT和Perplexity每月给他带回1440个高意向访客,转化率2.1%客单价180美元,整个抹掉之后没有任何替代流量进来。这不是个案。看了2024到2026年28个出海项目的数据,跟着Cloudflare那个一键按钮上路的几乎都踩同一个坑——AI引用从月均320次跌到接近零,模型新版本里品牌实体逐步消失,竞品的名字开始占满引用列表。但话说回来,新闻媒体那边Reuters拦得很彻底也活得好好的,差别到底在哪?这篇按7条判断维度、3层方法(robots.txt挡守规矩的、UA黑名单挡老实写UA的、WAF挡伪装的)的能力边界、4家大站的策略路径、1个真实失败复盘、5步渐进路径拆透"该不该拦"和"怎么拦才不自伤"两件事。
为什么2026年要重新讨论拦不拦AI爬虫?
2024年7月Cloudflare在自家博客发布了"一键拦AI爬虫"按钮的功能上线公告,那一周整个行业像被注入肾上腺素一样讨论起来。先是新闻媒体集体表态要拦,再是垂直内容站跟进,再是大量独立站老板涌入Cloudflare控制台把那个按钮打开。2025年下半年这股浪潮过去以后,第一批拦了的人开始算账,账算出来的结果让很多人傻眼。盲拦带来的代价比预期严重得多,问题不是这一次按钮该不该按,是这件事的决策框架行业里一直没说清。
讨论拦不拦AI爬虫的前提是先想明白3件事。第一件是你的核心营收从哪里来。营收90%以上靠直接到站流量、SaaS订阅、电商转化的站点,AI爬抓内容确实可能损害收益。营收主要靠品牌曝光带回流量、靠被AI推荐的站点,拦了AI爬虫等于断自己的腿。第二件是你的内容版权价值有多稀缺。原创深度报告、长篇调查、行业首发数据有真正的稀缺价值,被AI抓走会摊薄商业回报。改写自公开资料的内容稀缺性低,被抓走影响有限。第三件是你在AI生态里的议价能力有多大。流量量级千万级以上的内容站可以走付费授权路线,几万到几十万的中小站强行拦只会自损。
2024到2025年这两年时间里行业实测出来的最大教训是——盲拦的成本远高于直觉预期。这个成本不是按月统计能看出来的,是按季度甚至按年累积才显现。AI模型对一个品牌内容的训练是滚动进行的,今天断了爬取,过去几年沉淀在训练数据里的内容会随着模型版本更新而被慢慢稀释。半年后你会发现AI答案里几乎不再提到你的品牌,竞品的名字占满引用列表。这种损失没有立即的财务报表能看到,但归因到位之后是触目惊心的。
另一个2026年要重新讨论的理由是工具侧的能力已经丰富了。2024年初你能用的拦法只有robots.txt和最基本的User-Agent判断,2026年Cloudflare已经提供了细粒度的AI Bot分类、按训练用途和检索用途分别授权、按付费授权状态自动放行的能力。决策不再是"拦"和"不拦"二选一,而是"哪些拦、哪些放、哪些收费授权"3选项。这种工具能力变化让早期的一刀切决策必须重新评估。
第三个理由是大站策略的演变。2024年底到2025年间,NYT起诉OpenAI、Reddit和OpenAI Google签License、Stack Overflow走Overflow API付费授权、Reuters直接全面拦截,4家头部内容站走了4种完全不同的路。每一种路径背后都有清晰的商业逻辑,但每一种都跟你不一样。中小站如果不区分自己跟大站的差异盲学某一家,结果通常是学不像还自伤。
这篇接下来要做的事是把拦AI爬虫这件事的决策框架完整建立起来。先讲判断维度7条,再讲robots.txt+User-Agent黑名单+WAF三层方法各自能挡什么挡不住什么,再讲选型决策矩阵,再讲一个真实的失败复盘案例,最后讲4家大站的策略对照和从盲拦到细粒度授权的渐进路径5步。如果你想看WAF误屏蔽AI爬虫的诊断方法和完整方法清单,可以读 防火墙能挡住AI爬虫吗?11类方法6大清单 这篇做侧重点互补的参照。
AI爬虫拦不拦的判断维度有哪几条?
拦不拦AI爬虫不是凭直觉拍板的事,要按一组明确的判断维度逐条评估。这两年带客户用下来的判断框架最终收敛到7条维度。每一条都要打分,最后加权汇总成一个综合判断结果,而不是看某一条单一维度就决定。
第一条维度是营收结构里直接流量贡献的占比。如果你的总营收里直接到站流量带来的转化占60%以上,AI爬走内容对营收的负面影响相对显著。如果占比不到30%,AI爬走内容对营收的直接影响有限,反而拦了AI带来的引用损失更严重。这一条维度通常需要拉过去12个月的归因数据来算,光看最近一个月会有偏差。
第二条维度是内容版权的稀缺性等级。原创深度调研、独家专访、第一手数据集、付费课程内容稀缺性最高。基于公开资料的整理、行业普遍知识的解读、综合多来源的报告中等稀缺。改写自论坛和Wiki的内容稀缺性最低。稀缺性等级直接决定被抓的版权损失大小,也决定走付费授权路线的议价空间。
第三条维度是品牌在AI生态里的议价能力。议价能力的硬指标是月活跃用户数、内容月产出量、原创内容占比、行业权威度。Reddit和Stack Overflow这种级别的UGC社区有跟OpenAI谈License的议价能力。月独立访客几十万以下的独立站基本没议价能力,强行学大站的付费授权路线会被冷处理。
第四条维度是当前AI引用率水平。如果你的内容在ChatGPT、Claude、Perplexity里月引用次数已经超过500,拦了的损失会非常痛。如果月引用次数不到20,拦了对你影响不大。这个数据需要用GEO监测工具或者手工跑核心查询100条来统计,没有这个数据底盘做决策都是凭感觉。
第五条维度是用户群体跟AI接触度的关联。北美高净值消费者、年轻技术从业者、跨境出海客户群体跟AI接触度高,他们的购买决策路径里AI搜索占比大。亚洲传统行业B2B客户、本地服务的中老年客户群体AI接触度低。AI接触度决定了AI引用对实际转化的影响系数。
第六条维度是被AI抓后的内容质量保护需求。涉及医疗、法律、金融这种高合规要求行业的内容,需要保证AI引用时不被错误改写或断章取义。这类内容拦AI爬虫的合规价值大于商业损失。普通生活类、电商类内容这方面的合规压力相对较小。
第七条维度是技术运维团队的能力储备。WAF细粒度规则维护、UA黑名单月更新、Bot日志分析这些动作都需要持续的人力投入。如果团队规模小没有专人维护,强上WAF会因为规则失效或者误屏蔽带来更大问题。技术能力跟不上的小团队适合保守用robots.txt路线。
7条维度加权汇总成综合分数。每一条按1到10打分,按你的业务优先级加权。综合分数高于70建议保守不拦或细粒度授权,30到70建议混合策略部分拦部分放,30以下可以考虑系统拦截。具体加权方式没有标准答案,根据每个客户的真实业务情况调整。带客户做这7条评分时通常需要1到2小时的访谈+数据拉取,急不来。
拦不拦之前,先把账算清:AI爬虫到底在烧你多少服务器钱?
前面这些判断维度,多半绕着同一件事打转:内容被AI白嫖了,到底换不换得回AI曝光。但还有一条维度很容易被漏掉,也正是这一两年海外站长重新把“拦不拦”摆上桌面的直接原因——不是版权,是钱。AI爬虫在实打实地烧你的服务器、带宽和算力,而这笔钱八成花在跟你生意毫无关系的地方。把“内容被抓”和“服务器被拖垮”拆成两件事看,这道选择题会清楚得多。
八成AI抓取是冲着喂模型去的,跟你的生意没半点关系
业内对各家AI爬虫的抓取动机做过拆解,结论挺一致:大约八成的AI爬取活动是为了给大模型攒训练语料,而不是搜索引擎或真实用户发起的检索。换句话说,这八成流量既不会给你带来访客,也不会带来转化,纯粹是在替别人训练模型付服务器的账单——你掏钱养着的带宽和CPU,喂的是别人家的模型。
最贵的不是带宽,是动态页被一遍遍触发
很多人以为AI爬虫的成本无非是多耗点带宽,其实最烧钱的是它撞上动态页。爬虫一头扎进购物车、筛选页、站内搜索结果这类URL,每个请求都要触发PHP执行、数据库查询、会话创建,开销比纯静态页高出好几个数量级。更糟的是不少爬虫是粗制滥造的——用Cloudflare的话讲,就是“昨天还摸不着头脑、今天就vibe code拼出一个爬虫”的那种,它们陷在低效循环里把同一批参数URL翻来覆去地抓,真实访客的TTFB和下单流程被一起拖慢。
这笔账,维基媒体基金会拿真实数据摊开过:自2024年1月起,它下载多媒体内容所用的带宽涨了50%,源头主要不是真人读者,而是来扒开放授权图库、好把图喂给AI模型的自动程序;更扎眼的是,它数据中心里最贵的那部分流量至少65%来自bot,可这些bot只占总浏览量的约35%,还曾有一次bot洪峰直接把它对外的网络连接占满、让一批用户页面加载变慢,这些都写在维基媒体基金会公开的爬虫运营影响报告里。
被搅浑的还有你的分析数据
成本不光烧在机器上,还烧在你的判断上。过去一年AI爬虫流量涨了300%,到2025年底,差不多每31次访问里就有1次来自AI bot。这些没有真人在背后的流量混进统计后台,会把整体访问量、跳出率、平均会话时长一起带偏,转化率也被无意义地稀释。你要是照着这份被污染的数据去改版、调投放,方向很可能从一开始就是歪的。
顺序得对:先看清,再决定拦谁
把上面这三笔账算明白,你大概率会得出一个结论:一刀切全站封禁既没必要、还容易误伤搜索引擎爬虫和真正能给你带AI曝光的检索型bot。更稳的顺序是先看清——用服务器日志或CDN的bot分析弄明白到底是谁在抓、抓的是哪些路径、单位时间烧掉多少资源,再决定对哪些爬虫、在哪些目录、用什么条件下手。先把购物车、筛选、站内搜索这些高成本动态区保护起来,远比把整站大门一焊死划算,也正好接得上后面那条从盲拦到细粒度授权的路子。
保哥的体会是,“要不要拦AI爬虫”先别急着当技术题做,它首先是一道生意账——先弄清这波流量在你这儿到底是纯成本,还是潜在的AI曝光来源,再回到下面robots、UA、WAF这三层去挑趁手的工具。账没算清就上手拦,要么白白看着服务器被烧、要么一焊死把该放进来的检索爬虫也挡在门外,保哥见过的翻车,多半栽在这一步上。
robots.txt拦AI爬虫到底能挡住什么?
robots.txt是拦AI爬虫最便宜的方法,零成本、零维护、零误屏蔽风险。但能挡的范围非常有限,必须想清楚它的真实边界再决定要不要用。
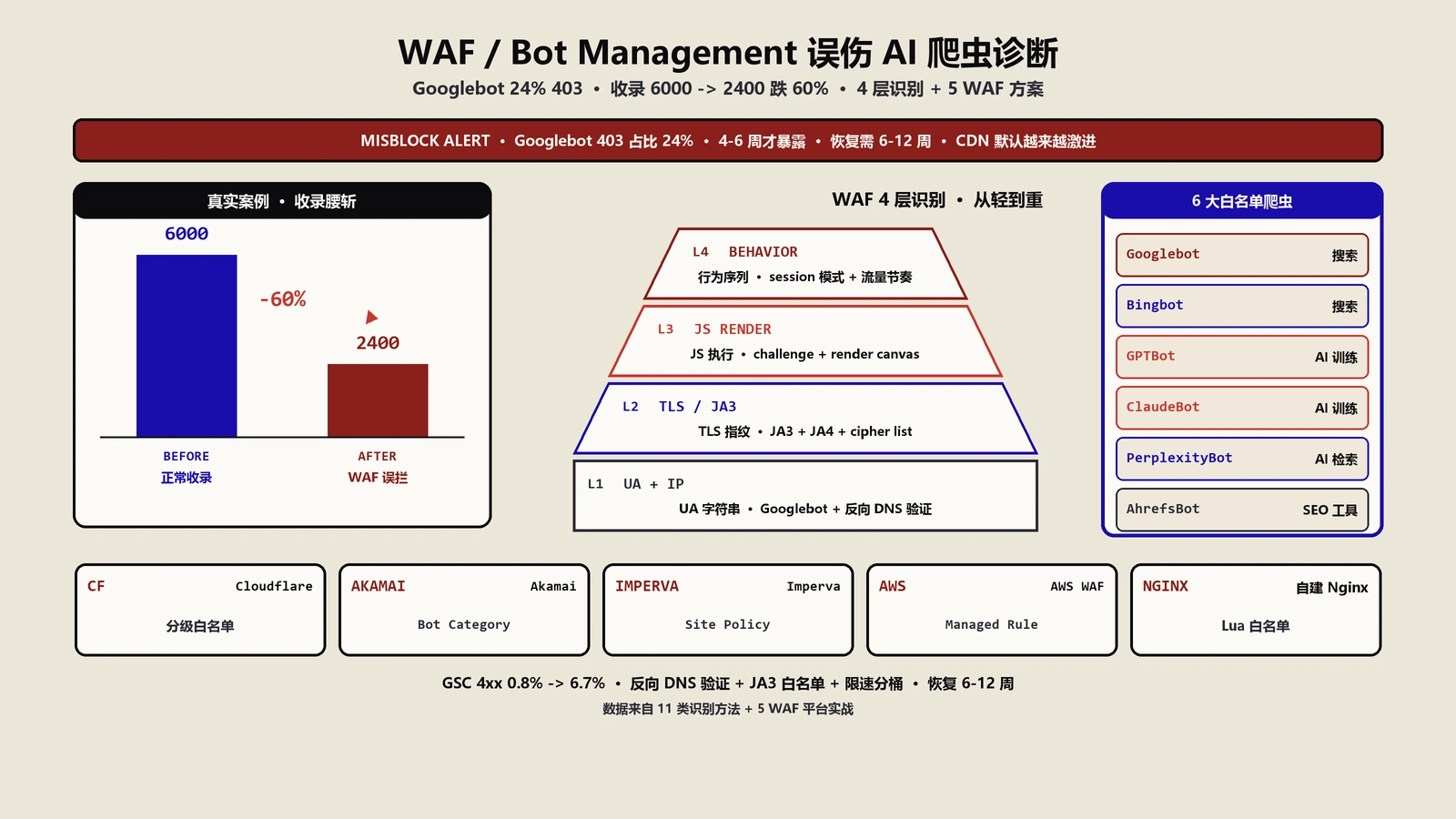
能挡的部分是5大家族公开承诺遵守robots.txt的主流AI爬虫。OpenAI在2023年8月公开的GPTBot爬虫文档里明确表态会遵守robots.txt,Google在2023年9月公开的Google-Extended扩展里同样承诺,Anthropic在2024年初公开的ClaudeBot文档里跟进,Common Crawl的CCBot长期遵守,Perplexity的PerplexityBot 2024年中跟进。这5家加起来覆盖了AI模型训练数据来源的60%以上份额。robots.txt写好对应Disallow规则,这5家会按规矩绕过。
挡不住的部分有3类。第一类是中小厂AI爬虫和大量科研类爬虫,它们不一定遵守robots.txt或者UA标识不清楚。第二类是灰色训练数据采集工具,伪装成普通浏览器或者Googlebot做抓取,robots.txt对它们没约束力。第三类是已经被抓进训练数据的历史内容,过去几年OpenAI、Google、Anthropic、字节、百度训练的模型里都有你的内容,robots.txt只能管将来不能管过去。第三类挡不住特别要注意——很多老板以为拦了robots.txt就万事大吉,其实历史内容的影响要持续2到4个模型迭代周期才能逐步淡出。
robots.txt的具体写法有2个常见错误。第一个错误是写了User-agent: *再加Disallow: /,以为这样能挡所有爬虫。实际上Googlebot、Bingbot、Yandexbot、Baiduspider这些主流搜索引擎也会按这条规则不抓你的站,SEO流量第二天断崖。正确写法是针对每个AI爬虫单独写User-agent段落,不要用通配。第二个错误是只写GPTBot忘了写ChatGPT-User、OAI-SearchBot。OpenAI有3个不同UA分别对应训练抓取、用户实时浏览、ChatGPT Search检索3种用途,只挡GPTBot的话另外两个还会过来。
推荐的robots.txt 2026年标准模板大概是这样的8段结构——给GPTBot加Disallow覆盖训练抓取,给ChatGPT-User和OAI-SearchBot保留Allow(这两个是实时检索,挡了影响AI Citation),给Google-Extended按你选择拦或放,给CCBot拦(这是Common Crawl对所有模型开放的最广来源),给ClaudeBot按选择拦或放,给PerplexityBot按选择拦或放,给Bytespider拦(中文站特别要注意),其它默认放行。这个模板的核心思路是训练用途的爬虫可以选择性拦,但实时检索类爬虫绝对要放。
robots.txt的维护成本接近零。一年大概更新1到2次就够,主要是新出现的AI爬虫加进黑名单、改名的爬虫更新UA字符串。维护成本低是robots.txt的最大优势,但也意味着它的拦截力度上限有限。如果你的诉求只是让"守规矩的爬虫不抓",robots.txt足够用。如果你的诉求是"所有AI爬虫都不能抓",robots.txt差远了,需要叠加上后面要讲的两层。
robots.txt还有一个特别的用途经常被忽视——给AI模型一个"明确的拒绝信号"。即使爬虫不遵守robots.txt强行抓了内容,AI厂商在后续做训练数据清洗时,对robots.txt里明确Disallow的来源会做降权处理。这是行业内默认的合规姿势,主流AI厂商即使技术上能拿到内容,也会在最终训练数据里把这部分降低权重。所以即使你判断robots.txt挡不全,写一份明确的robots.txt仍然有合规和品牌信号价值。
User-Agent黑名单8家AI爬虫具体怎么写?
User-Agent黑名单是比robots.txt严格一些的方法。robots.txt靠对方自觉,UA黑名单是你主动判断请求的UA字符串,匹配上就直接返回403或者断开连接。能挡住部分不遵守robots.txt的爬虫,但维护成本明显高于robots.txt,且有一定误判风险。
2026年初要进黑名单的8家主流AI爬虫UA字符串大概是这样——GPTBot(OpenAI训练)字符串包含"GPTBot"、Google-Extended(Google训练)的实际UA仍然是Googlebot系列但通过Google-Extended开关控制、ClaudeBot(Anthropic)字符串包含"ClaudeBot"或"anthropic-ai"、CCBot(Common Crawl)字符串包含"CCBot"、PerplexityBot字符串包含"PerplexityBot"、Bytespider(字节)字符串包含"Bytespider"、Amazonbot(Amazon训练)字符串包含"Amazonbot"、AppleBot-Extended字符串包含"Applebot-Extended"。8家覆盖了主流AI模型训练数据来源的80%以上。
UA黑名单的实现方式有3种。Nginx层用if判断$http_user_agent匹配正则后return 403,最直接最高效。Apache层用RewriteCond匹配UA后RewriteRule跳转或拒绝,写法稍微复杂但功能等价。应用层用框架的中间件做UA判断后返回拦截响应,灵活但性能开销大。推荐用Nginx层做,性能最好维护也方便。
UA字符串的维护成本是这一层最大的痛点。8家AI爬虫的UA字符串每半年大概会有1到2家做版本变更,新增爬虫每季度大概1到2个。如果不及时更新黑名单,会出现两种问题——一种是漏过新版本爬虫的抓取,一种是把已经改名的合法爬虫误判为已被拦的。维护成本估算大概是每月2到4小时,需要持续投入。
UA维护的信号源有3个。第一是Cloudflare Radar的AI Insights实时数据面板,每周更新一次AI爬虫的活跃度和UA字符串变化。第二是各家AI厂商的官方文档变更通知,OpenAI、Google、Anthropic的爬虫文档都有版本历史。第三是你自己服务器的Bot日志分析,每月扫一遍发现UA异常变化或新出现的AI类UA。3个信号源结合起来用,能保证黑名单的及时性。
UA黑名单的常见误判风险有4类。第一类是把合法搜索引擎爬虫误判为AI爬虫,特别是Google-Extended跟Googlebot共用UA字符串这种情况,要靠IP段反向校验避免误伤Googlebot。第二类是把内部监控工具误判为AI爬虫,因为内部工具可能用通用UA字符串,要在白名单里明确列出。第三类是把合法的浏览器扩展或工具拦掉,比如部分阅读器插件的UA里包含"bot"字样。第4类是把移动端APP的爬取请求误拦,部分APP的UA字符串带"crawler"或"spider"字样但其实是合法应用。
UA黑名单的局限性也很明确——只能挡老实写UA字符串的爬虫。伪装成普通浏览器或者直接复制Googlebot UA的灰色爬虫,UA层完全识别不了。要进一步过滤这类爬虫,必须叠加WAF和CDN层的Bot Score和行为分析能力。如果你对AI爬虫的真实抓取行为想做更深的逆向分析,可以读 AI爬虫到底抓你什么代码逆向8步实操 这篇做参照。
WAF和CDN层挡AI爬虫的具体动作清单?
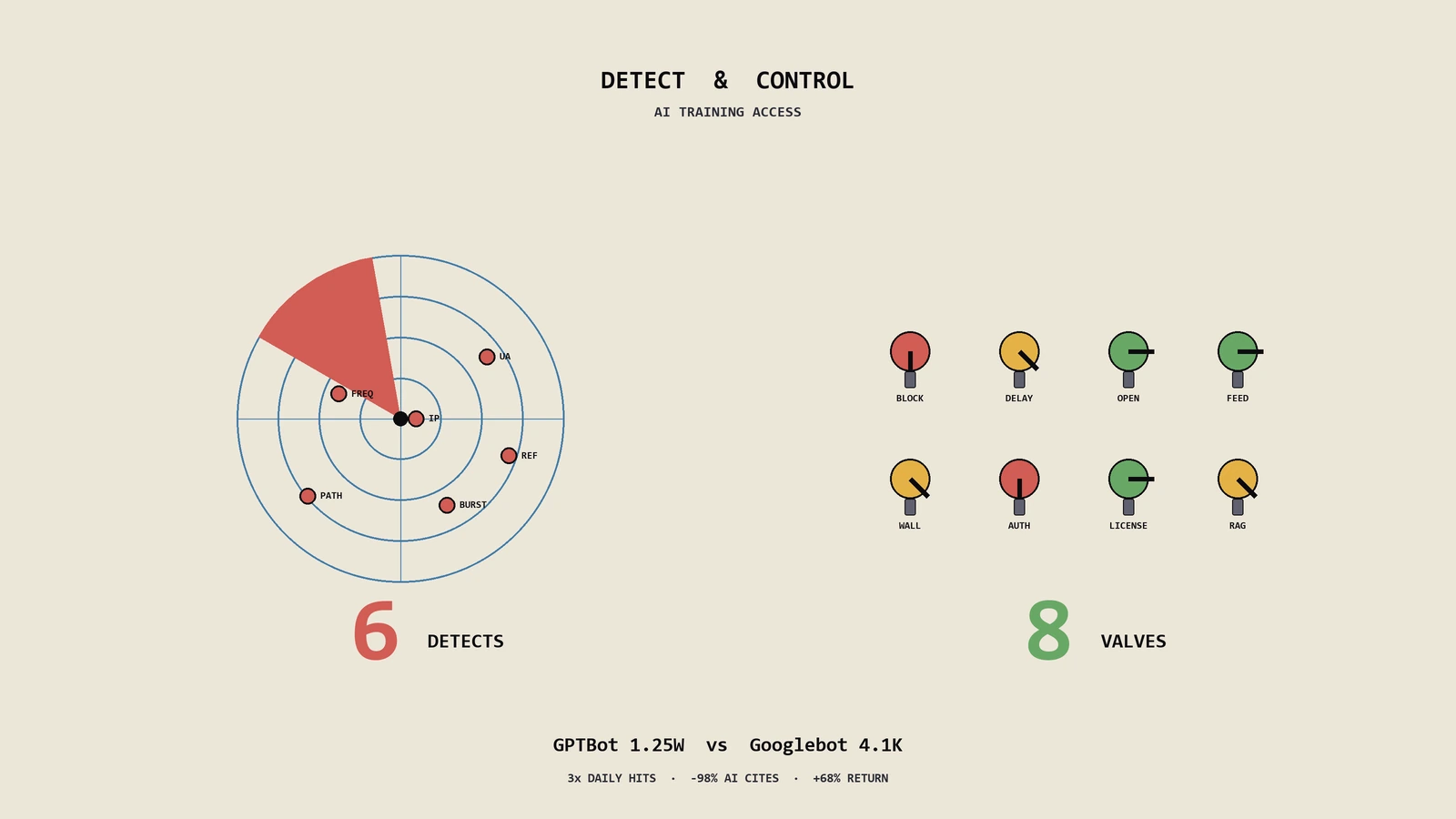
WAF和CDN层是3层方法里挡得最狠的一层,但也是最容易踩坑的一层。Cloudflare、Akamai、AWS WAF、阿里云WAF这4家主流WAF都提供了不同程度的AI爬虫拦截能力。每一家的实现细节有差异,但核心原理都是Bot Score+行为分析+IP段+UA组合判断。讲一下Cloudflare的实现细节作为代表,其它家的能力可以类推。
Cloudflare的AI爬虫拦截能力在2024年7月发布的"一键拦AI爬虫"按钮之后做了多轮升级。2025年初的版本已经把AI爬虫分成4类——明确公开的训练爬虫、明确公开的检索爬虫、未公开但识别为AI类的爬虫、可疑伪装爬虫。每一类可以独立配置允许或拒绝。这种细粒度配置能力是2024年初的版本完全没有的,决策灵活度大幅提升。
具体配置动作有5件。第一件是在Cloudflare Dashboard的Security tab下找到Bot Management模块,把AI Bots分类的总开关从默认Allow切到Custom Rules。第二件是创建一组Custom Rules,对Verified AI Training Bots(已公开的训练爬虫,包括GPTBot、CCBot、ClaudeBot等)设置Action=Block。第三件是对Verified AI Search Bots(已公开的检索爬虫,包括ChatGPT-User、OAI-SearchBot、PerplexityBot)设置Action=Allow,保护AI Citation不受影响。第四件是对Suspected AI Bots(未公开识别为AI类)设置Action=JS Challenge,过滤掉伪装爬虫但不直接拦。第五件是设置一个总闸的Bot Score阈值在10到20之间,对总分低于阈值的请求做Managed Challenge处理。
WAF层最容易踩的坑是Bot Score阈值设置错误。Cloudflare的Bot Score范围是1到99,越低代表越像Bot越可能是恶意流量。很多管理员凭感觉把阈值设到6以下,结果Googlebot和Bingbot这些合法搜索引擎也被拦了,SEO流量第二天直接断崖。Googlebot的Bot Score通常在2到30之间波动,Bingbot在3到20之间,所以阈值绝对不能设在30以下。推荐阈值10到20之间,配合Verified Bots白名单一起用。
另一个常见的坑是Custom Rules的优先级顺序错乱。Cloudflare Custom Rules是按顺序匹配的,第一条命中就执行不再往后看。如果你把"Block All AI Bots"规则放在"Allow ChatGPT-User"规则之前,ChatGPT-User也会被Block掉。正确的顺序是先放白名单(Allow)规则再放黑名单(Block)规则,确保白名单优先生效。
Akamai的Bot Manager Premier和Cloudflare机制类似,但默认配置更保守。AWS WAF和阿里云WAF的AI爬虫识别能力相对弱一些,主要靠UA规则+IP段+速率限制组合,没有专门的AI Bot分类。如果你对AI爬虫的细粒度控制要求高,Cloudflare是首选。如果对成本敏感且需求简单,AWS WAF和阿里云WAF基本够用。
WAF层的监控指标有4个必看。第一是Bot Score分布直方图,看你站点上Bot流量的整体特征。第二是Verified Bots通过率,确保合法爬虫没被误拦。第三是Suspected Bots的Challenge通过率,太高说明阈值设松了,太低说明误拦严重。第四是WAF Rules的命中次数排行,看哪些规则真正在起作用哪些是摆设。4个指标每周看一次,发现异常及时调整。
三层方法选型决策矩阵怎么用?
讲完3层方法各自的能力和局限,接下来是选型决策矩阵。3层方法不是非此即彼,可以叠加用也可以单独用,关键看你的业务场景需要哪种力度。给一个2026年初常用的决策矩阵作为参考。
矩阵的两个轴分别是"内容稀缺性"和"AI引用价值"。内容稀缺性从低到高对应"通用知识改写""综合资料整理""原创深度调研""独家专访数据"4档。AI引用价值从低到高对应"被引用月不足20次""月20到100次""月100到500次""月500次以上"4档。两个轴交叉形成16个格子,每个格子推荐一种3层方法的组合。
第一类组合是"内容稀缺性低且AI引用价值低"的格子,推荐方案是只写robots.txt明确表态,不上UA黑名单不上WAF细粒度规则。这类站点的特征是内容主要靠改写公开资料,AI生态里基本没有声量。投入大量精力做拦截没有意义,写一份明确的robots.txt表态合规即可。维护成本年均1到2小时。
第二类组合是"内容稀缺性低但AI引用价值高"的格子,推荐方案是robots.txt允许所有AI爬虫且不上拦截层。这类站点的特征是内容门槛不高但已经在AI生态里有一定声量。拦了会失去AI引用带来的流量回流,得不偿失。维护成本基本为零,定期监控AI引用率保持正常即可。
第三类组合是"内容稀缺性高但AI引用价值低"的格子,推荐方案是robots.txt明确Disallow训练爬虫+UA黑名单挡8家主流爬虫+WAF不做细粒度规则。这类站点的特征是内容有版权价值但AI生态还没起来。先把训练用途的爬虫挡住保护版权,等AI引用起来后再做调整。维护成本月均2到3小时。
第四类组合是"内容稀缺性高且AI引用价值高"的格子,推荐方案是细粒度授权——训练爬虫按合作意愿放或拦、检索爬虫全放、可疑爬虫JS Challenge过滤、Bot Score阈值15以上。这类站点的特征是有版权价值且AI生态里有声量,决策最复杂收益也最大。推荐叠加付费授权讨论,跟主要AI厂商谈License合作。维护成本月均6到10小时。
矩阵之外还有3个特殊场景需要单独讨论。第一个是医疗法律金融等高合规行业,无论稀缺性和引用价值如何,都要保守拦截以避免AI错误改写带来的合规风险。第二个是B2B工业品和专业服务行业,AI引用价值的衡量方式跟C端不同,需要单独评估。第三个是新闻媒体,决策核心是议价能力和付费授权可行性,跟一般站点的决策逻辑完全不同。
决策矩阵的用法是先在两个轴上给自己定位,对照到对应格子的推荐方案,然后根据团队的技术能力和预算做最后调整。矩阵不是死规则,是一个起点。每个客户的具体情况要单独评估,但矩阵能覆盖80%以上的场景。剩下20%的特殊场景需要更深度的咨询拆解。
关于决策矩阵实施完之后引用率怎么追踪,可以参考 AI引用单靠传统SEO够吗 这篇对AI引用率衡量公式的详细拆解。两篇配合读能把"拦不拦"决策和"拦了后引用怎么管"两件事串成完整方法论。
出海手作钢笔DTC一年盲拦后AI引用归零的复盘?
2024年第三季度团队接了一个出海手作钢笔的DTC客户。这个客户做活塞上墨钢笔、墨水套装、手账配套笔记本、皮质笔袋,客单价75到350美元,主要市场北美书写文化爱好者、西欧高净值文具收藏圈、日韩手账社区。来的时候老板提的需求很特殊——一年内把所有AI爬虫全拦了,保护品牌内容版权。当时2024年7月Cloudflare一键拦AI爬虫按钮刚发布,老板看了行业里很多大站表态拦AI的新闻,决定跟进。
团队按客户要求执行盲拦方案。robots.txt写满8段Disallow覆盖所有公开的AI爬虫UA。UA黑名单加进Nginx配置,匹配8家主流爬虫UA字符串直接return 403。Cloudflare Bot Management把AI Bots分类总开关切到Block,Bot Score阈值设到20。3层拦截全开,1周内所有AI爬虫请求全部消失,Cloudflare控制台显示AI Bots请求量从日均3200掉到日均不到20。老板看到这个数据非常满意,认为版权保护工作做到位了。
2024年第三季度到2025年第二季度这一年时间里,传统SEO侧的KPI完成得不错——自然流量从月7500推到月18000,2.4倍增长。核心关键词排名稳定在前10。Core Web Vitals全绿。E-E-A-T信号系统补全到位。完全按传统SEO最佳实践跑下来,传统SEO侧无可挑剔。但同时跟踪的AI引用率数据让团队看到了问题——AI引用从签约前的月均320次(ChatGPT 180次+Claude 65次+Perplexity 75次)一路下滑,2025年Q2跌到月均8次接近零。
2025年第二季度做季度复盘时,老板提了一个反问让团队当场卡住——我自己业务负责的5个产品类目,过去3个月有4个的对手在ChatGPT被问到时被推荐,我品牌从来没被提过。这个数据团队拉出来一看,确实是AI Citation断崖式归零的典型表现。把2024年9月到2025年6月这10个月的AI引用数据按月画出来,从320次到8次的滑坡曲线非常平滑,没有突变点,证明是AI模型在持续的训练迭代中把这个品牌的内容权重逐步降到零。
复盘出来的损失估算是每月直接销售额损失5万美金左右。算法是这样的——AI引用断崖前,AI Citation带回到站的访客占总自然流量的8%左右,平均订单价值180美元,转化率2.1%。AI引用归零后这部分流量完全消失,按月均自然流量1.8万计算,损失流量1440人次×2.1%转化×180美元=约5.4万美金。10个月累计损失大概50万美金,远超被爬走内容的版权理论价值。
更让老板痛的是品牌实体在AI模型里识别失效。2025年下半年AI模型新版本上线后,团队跑了一组实体识别测试,发现"手作钢笔品牌"这个细分类目下,过去AI模型能准确关联到这个客户的5个测试查询,新版本里全部关联到竞品。这种品牌实体识别失效是结构性损失,要修复需要18到24个月的反向运营,远超盲拦本身节省的成本。
2025年第三季度团队跟客户重新讨论了决策。最终方案是按本文前面讲的细粒度授权矩阵重新配置——robots.txt里训练爬虫保持Disallow但检索爬虫全Allow、UA黑名单只保留Bytespider和未公开AI爬虫两类、Cloudflare Bot Management把ChatGPT-User和OAI-SearchBot加入白名单。配合补做GEO的3层动作——Wikidata申请、答案盒友好改造、跨平台共现。8个月后AI引用从月均8次推到月均180次,仍然没回到盲拦前的320次水平,但增长趋势明确,预计15到18个月后能完全恢复。
这个案例的核心教训是——盲拦的决策成本远高于直觉预期,且修复周期长。决策前一定要按7条判断维度做量化评估,不能跟风学大站。如果你想看托管WordPress被默认拦AI爬虫导致引用流失的另一个相关案例,可以读 中国WordPress AI爬虫被拦8大原因 这篇做对照。
拦完之后必须监控的5个指标是什么?
无论你的决策是全拦、细粒度授权、还是完全放行,拦完之后都要建立监控指标体系。监控不是一次性动作而是持续追踪,因为AI生态和模型版本都在快速变化,今天合适的配置3个月后可能要重新调整。给5个核心监控指标作为最小可用集。
第一个指标是AI爬虫请求量分布。按周统计每家AI爬虫的请求量、按月看趋势变化。Cloudflare Dashboard的Bot Analytics能直接看到分类统计。这个指标看的是你的拦截规则有没有真正生效,以及新的AI爬虫有没有出现需要加进黑名单。请求量突然飙升通常意味着新的AI产品上线或者旧爬虫升级UA字符串。
第二个指标是AI引用率月度变化。固定50到100条核心查询每月在ChatGPT、Claude、Perplexity、Google AI Overviews、Bing Copilot 5个平台跑一遍,记录引用次数。这个指标是判断拦截决策是否合理的最直接证据——拦了之后引用率下降是正常的,但下降速度和最终底线要符合你预期。下降太快或者底线太低说明拦得过头要放松,下降速度温和接近你预期说明配置合理。
第三个指标是合法搜索引擎爬虫的抓取量。Googlebot、Bingbot、Yandexbot、Baiduspider的日均抓取请求量按周统计。这个指标看的是有没有误屏蔽SEO流量入口的爬虫。如果发现Googlebot抓取量突然下降30%以上,几乎一定是WAF规则误伤了,必须立即排查Bot Score阈值和Custom Rules白名单。
第四个指标是品牌实体识别准确率。每月跑一组实体识别测试,用ChatGPT、Claude等问"X品牌是做什么的"、"X品牌的主打产品是哪些"、"X品牌在某个行业里的定位是什么"这类查询,统计AI回答的准确率。这个指标看的是你的品牌在AI模型里是否还能被正确识别。准确率从90%以上跌到60%以下是危险信号,说明AI模型新版本已经开始忘记你的品牌。
第五个指标是版权使用合规事件数。统计每月发现的明显抄袭、未授权大段引用、内容洗稿的事件数量。这个指标看的是版权保护的实际效果。如果拦了之后合规事件数依然居高不下,说明你的拦截没挡住实际的灰色采集,要换更严格的方案。如果合规事件数明显下降,说明拦截方案有效。
5个指标的统计频率和阈值告警是配套的。第一和第三按周统计、按周告警。第二和第四按月统计、按月汇报。第五按月统计但事件发生时立即告警。所有指标都要建立基线和趋势线,看绝对数值的同时看趋势方向,避免被单月波动误导。
监控体系的成本估算每月大概4到8小时人力投入。前期搭建工具链需要2到3周的一次性投入。如果团队规模小没有专人维护,可以把5个指标精简到3个——AI爬虫请求量+AI引用率+合法搜索引擎抓取量,覆盖最关键的反馈回路。3个指标的成本能压到每月2小时左右。
主流大站怎么决策的(NYT/Reuters/Reddit/Stack Overflow对照)?
研究主流大站的决策路径是建立自己判断的最快方法。但要注意每家大站背后的商业逻辑跟中小站完全不同,盲学某一家通常学不像。讲4家代表性大站2024到2026年的策略对照,重点是看每家选择的逻辑。
NYT走的是付费授权加诉讼施压路线。2023年12月NYT正式起诉OpenAI和微软,指控未经授权使用NYT内容训练模型。诉讼至今仍在进行中,但NYT同时跟其它AI厂商谈付费授权,比如2024年跟Amazon签了多年期授权合作。NYT的决策逻辑是用诉讼倒逼OpenAI付费,用付费授权获取实际收益。这套打法的前提是NYT有顶级品牌价值和法律资源,普通独立站没法学。
Reuters走的是直接全面拦截路线。2024年初Reuters把robots.txt里几乎所有AI爬虫都加进Disallow,同时在WAF层做细粒度规则拦截。Reuters的决策逻辑是新闻内容的版权价值时效性强、被AI抓走立即影响实时报道业务、不希望被任何AI模型直接消化。这套打法的前提是Reuters的核心营收来自专业订阅和企业服务,C端流量影响有限。普通DTC站和B2B站没有这个底气。
Reddit走的是License合作路线。2024年2月Reddit跟Google签了一份每年6千万美金的License协议,允许Google用Reddit内容训练Gemini。2024年5月Reddit又跟OpenAI签了类似协议。Reddit的决策逻辑是UGC内容量级巨大、协议带来稳定营收远高于单方面拦截可能保护的版权价值。这套打法的前提是Reddit拥有海量UGC内容和巨大议价能力。中小站基本谈不下来这种协议。
Stack Overflow走的是API付费授权路线。2024年Stack Overflow推出Overflow API产品,允许AI厂商通过付费API访问Stack Overflow的高质量Q&A数据,同时拦截直接爬取。这套路线介于Reuters的全面拦截和Reddit的License之间,核心是把内容产品化、按API调用收费。前提是Stack Overflow的内容有清晰的结构化形态适合API化。普通DTC站和内容站很难做出类似的API产品。
4家大站的策略对照能看出一个规律——每家的选择都跟自己的内容形态、商业模式、议价能力深度绑定。NYT靠品牌价值和法律资源,Reuters靠订阅模式不在乎C端流量,Reddit靠海量UGC的议价能力,Stack Overflow靠结构化数据的产品化能力。中小站如果不区分自己跟大站的本质差异盲学某一家,结果通常是学不像还自伤。
从大站对照里能学到的真正东西是决策框架,不是具体动作。决策框架是——先评估自己的内容形态商业模式议价能力3条,再选择对应的策略路径。中小独立站对应的路径通常是混合策略(部分拦+部分允许+不强求付费授权),不是任何一家大站的极端模式。这一点想清楚之后再做具体动作设计。
2026年大站策略还在持续演变。NYT的诉讼判决预计2026年中前后出结果,Reddit的License合作进入第二轮谈判窗口,Stack Overflow的Overflow API用户数仍在快速增长。这些变化会持续影响行业的决策共识。中小站要做的是保持关注但不盲跟,每季度回顾一次自己的决策框架是否还适用即可。
SEO媒体类站点拦不拦AI爬虫的两个流派?
SEO行业的媒体类站点是一个特别有意思的研究对象。这些站点的核心内容是SEO相关知识,他们对AI对搜索的影响最敏感,对要不要拦AI爬虫的决策也最分裂。2024到2026年这两年SEO媒体类站点的决策分成了两个明确流派,每个流派背后都有清晰逻辑。
第一个流派是"积极拦截派"。代表性观点是认为AI爬抓SEO媒体的内容、用这些内容训练模型回答SEO问题、最终会把SEO媒体的流量取代掉。这个流派认为SEO媒体的内容本来就是教用户怎么不依赖SEO媒体也能解决问题,如果AI把这些内容消化了直接给答案,SEO媒体没有存在的必要。所以选择拦得越狠越好,至少能延缓被取代的速度。这个流派在2024到2025年上半年比较有声音。
第二个流派是"全开门派"。代表性观点是认为SEO媒体最大的价值是品牌权威和持续更新,AI模型即使抓到了内容也只是历史快照,最新的SEO动态和案例还是要回到媒体本身。所以选择全开门让AI爬到、让自己品牌在AI答案里被引用、用AI引用带回品牌流量。这个流派在2025年下半年到2026年初比较有声量。
两个流派的实际数据对比比较有意思。积极拦截派代表性站点在2024到2025年间,自然搜索流量保持稳定但AI引用流量近乎归零。全开门派代表性站点在同一时期,自然搜索流量同样保持稳定但AI引用流量持续增长,整体流量结构里AI引用从2024年初的5%提升到2026年初的18%左右。从纯流量数据看,全开门派的整体增量更明显。
两个流派的更深层差异是商业模式。积极拦截派多数靠广告变现,流量价值跟广告曝光直接绑定,拦AI是为了保护广告曝光机会。全开门派多数靠付费会员、SaaS订阅、咨询服务变现,流量价值跟品牌权威建立深度相关,让AI多引用反而强化品牌权威带来更多付费转化。商业模式决定了对AI引用价值的判断完全不同。
这两个流派的争论给独立站老板带来的启示是——拦不拦AI爬虫的决策不能脱离商业模式。如果你的营收主要靠广告或者直接到站转化,AI引用对你的价值有限,可以倾向拦截。如果你的营收主要靠品牌权威驱动的付费转化,AI引用是你的资产应该保护。商业模式是这个决策的第一性原理,技术细节是第二步的事。
SEO媒体类站点的另一个观察点是2025年下半年开始出现的"混合策略派"——既不全拦也不全开,按内容类型分级处理。比如付费课程内容、独家行业报告这类高商业价值内容做严格拦截,免费博客文章和入门指南这类引流内容全开放给AI爬虫。这种混合策略的逻辑是用免费引流内容打AI引用率、用付费内容做版权保护,两全其美。混合策略派2026年初已经成为主流,预计未来1到2年会成为行业默认配置。
对于普通DTC站和B2B站,可以从SEO媒体的这场争论里借鉴一个关键决策原则——按内容类型分级处理而不是一刀切。把你的内容按商业价值分3档,最高档严格拦截、中档细粒度授权、最低档全开放。这种分级处理的方案比一刀切的拦或不拦要科学得多。
怎么从盲拦到细粒度授权的渐进路径?
如果你2024年盲拦了AI爬虫现在想调整,或者你正在评估第一次配置,可以按这5步渐进路径落地。每一步都有明确的检查点和回滚条件,整个路径大概需要8到12周完成全部调整。
第1步是基线建立。这一步2周时间,做的事是把现状摸清楚。包括拉过去6个月的AI爬虫请求量分布、过去6个月的AI引用率月度数据、当前的拦截规则完整清单(robots.txt+UA黑名单+WAF Custom Rules三层)、当前的合法搜索引擎抓取量基线。基线建立完之后才能判断后续调整的实际效果。这一步没有任何配置改动只有数据收集,零风险。
第2步是检索爬虫白名单。这一步1周时间,做的事是给所有AI检索爬虫开绿灯。包括ChatGPT-User、OAI-SearchBot、PerplexityBot这3个明确做实时检索的爬虫加进所有3层方法的Allow列表。这一步是最低风险的放开动作,因为检索爬虫的请求量小、对内容版权影响小、对AI Citation贡献大。放开之后2到4周内能看到AI引用率开始回升。
第3步是训练爬虫按内容分级。这一步3周时间,做的事是把站内内容按商业价值分3档,对应3种不同的拦截力度。最高档严格拦截,比如付费产品页、独家行业报告。中档允许CCBot和Google-Extended但拦GPTBot和ClaudeBot。最低档全开放允许所有训练爬虫。分级配置需要用WAF的URL Pattern规则配合实现,技术复杂度中等。
第4步是监控体系建立。这一步2周时间,做的事是把前面讲的5个监控指标的统计工具和告警机制搭建起来。Cloudflare Analytics的Bot Analytics面板配置、AI引用率监测工具采购或自建、Googlebot抓取量监控告警、品牌实体识别月度测试脚本。监控体系建立后才能进入持续优化阶段。
第5步是月度调优。从第8周开始进入月度调优节奏,每月看一次5个监控指标,根据数据反馈调整3层拦截配置。调优的方向是逐步精细化——比如发现某个新出现的AI爬虫请求量大且对引用率有正向贡献,加进Allow列表。比如发现某个传统训练爬虫请求量小且对引用率影响不大,加严拦截。调优是长期工作,不会有"调完就不动"的稳态。
5步渐进路径的关键是每一步都有可衡量的检查点和明确的回滚条件。第2步检查点是2到4周内AI引用率有没有回升,没有回升说明问题不在检索爬虫被拦上。第3步检查点是分级后的实际WAF命中情况是否符合预期,不符合说明分级规则配置错了。第4步检查点是监控数据是否完整可信,数据有缺口说明监控工具配置不到位。每一步检查点不通过就回滚到上一步重新评估,不要往前推。
整个渐进路径的预期收益分两块。短期收益是AI引用率回升、品牌实体识别准确率提升,3到6个月内能看到。长期收益是建立持续优化的能力,让你能跟上AI生态的快速演变,2到3年的时间维度上保持AI引用率竞争力。短期收益直接,长期收益结构性。
拦AI爬虫这件事最怕的就是凭直觉拍板。该不该拦,先按7条维度量化打分;怎么拦,对照决策矩阵选robots.txt、UA黑名单、WAF三层里的哪几层;拦完别撒手,盯住那5个指标按月复盘。每个客户情况都不一样,但这套骨架能兜住大多数场景。剩下的特殊场景欢迎在评论区留下你的站点情况,后续会出针对性的拆解文章。
常见问题解答
2026年到底该不该拦AI爬虫?
看你的核心营收来源在哪。如果营收90%以上来自直接到站流量加SaaS订阅加电商转化,AI爬抓内容对你伤害大于收益,可以选择性拦截。如果你的营收靠品牌曝光和被引用带回流量,拦了就是断自己的腿。先算清楚AI引用对营收的实际贡献再决定,凭直觉拍板的代价远超想象。
robots.txt写了Disallow能不能真的挡住AI爬虫?
只能挡守规矩的爬虫。OpenAI GPTBot、Google-Extended、Anthropic ClaudeBot、CCBot、PerplexityBot这5个主流家族明确表态会遵守。但部分小厂AI爬虫和大量灰色训练数据采集工具不会读robots.txt,纯靠robots.txt挡不全。要进一步过滤必须叠加UA黑名单和WAF两层。
User-Agent黑名单的维护成本到底多大?
每月大概2到4小时投入。8个主流AI爬虫的UA字符串通常半年一变,需要订阅Cloudflare Radar、官方文档变更通知、Bot日志分析3个信号源。如果不及时更新黑名单,可能漏过新版本爬虫,或者把改名后的合法爬虫误判为已被拦的。
WAF拦AI爬虫最常踩的坑是什么?
误屏蔽合法搜索引擎爬虫。Cloudflare Bot Management的Bot Score阈值如果调到6以下,会把Googlebot和Bingbot也一起拦掉,导致SEO流量断崖。建议Bot Score阈值留在10到20之间,对AI爬虫用独立规则点名拦,不靠综合分数。
盲拦AI爬虫最严重的代价是什么?
AI引用率归零和品牌实体识别失效。AI模型在训练阶段抓不到你的内容,后续生成答案时不会引用你,竞品占满引用列表。这种损失累积起来远超被爬走内容的版权价值,特别是DTC品牌站和B2B服务站影响最严重,修复周期通常要18到24个月。
大型新闻媒体和UGC社区怎么决策的?
NYT走付费授权路线起诉OpenAI,Reuters多数AI爬虫直接拦截,Reddit和OpenAI Google签License每年收上亿美金,Stack Overflow走Overflow API付费授权。新闻和UGC站点决策核心是议价能力,DTC品牌没议价能力别学这套,按本文的混合策略路径走更合适。
权威参考资料
本文标题:《拦AI爬虫该不该?robots+UA+WAF三层选型框架》
本文链接:https://zhangwenbao.com/block-ai-bots-robotstxt-waf.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0