你的内容被AI训练了吗?6种检测方法与8种授权对策
本文目录
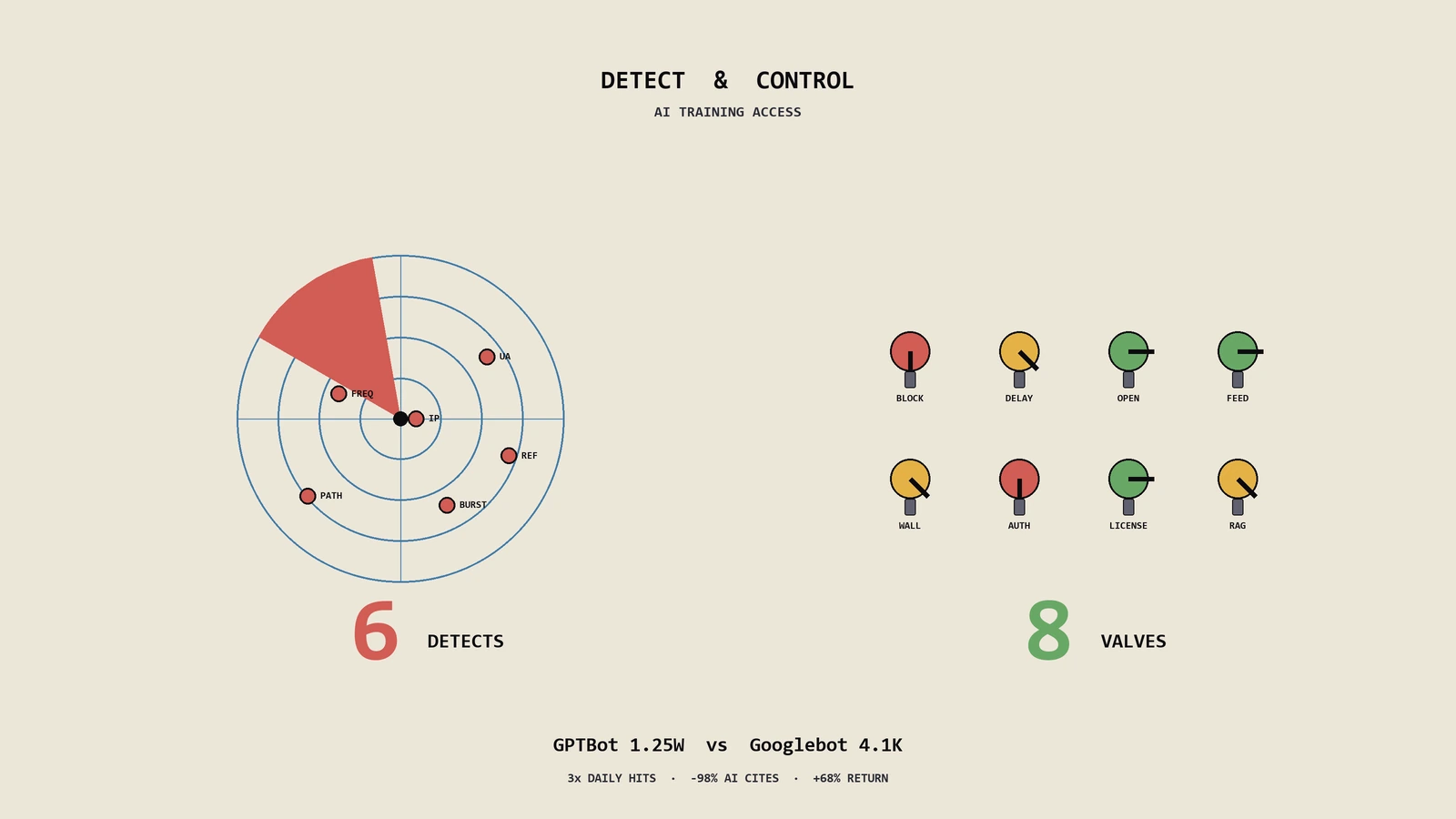
摘要:出海精油护肤DTC客户上周把一份Cloudflare攻击日志推到桌上:上面挂着GPTBot、CCBot、ClaudeBot、PerplexityBot、anthropic-ai五个UA,过去30天总抓取量28.6万次,是Googlebot同期12.4万次的2.3倍。她在镜头前直接抛出问题:这帮爬虫是不是在偷我家从2019年开始一字一字打磨的产品文案训练AI?答案多半是,但盲拦不是好路子——那个2024年盲拦GPTBot的同类客户一年之后AI引用归零、月损5.2万美金。真正稳的做法是先用6种独立方法(C4 token查询+CommonCrawl快照对账+GPTBot UA日志+反向prompt测试+引用率工具+品牌名召回率)把检测做实,再按内容资产价值、流量回路、品牌曝光、法律边界4维度走8种授权选择决策矩阵,最后把AI引用反向变成新流量入口。
2026年4月底,那位做出海玫瑰精油护肤DTC的女创始人在视频复盘会上把屏幕共享出来。Cloudflare的Bot Analytics仪表板里GPTBot日均抓取4200次、CCBot日均3800次、ClaudeBot日均2100次、PerplexityBot日均1500次、anthropic-ai日均900次。这5个加起来1.25万次,是Googlebot日均4100次的3倍。她做美妆护肤行业13年,2019年从北美芳疗师转型做精油护肤DTC,产品文案每一句都是自己写的,2023到2024年陆续加了过敏体质适配、皮肤分型选品逻辑、欧盟化妆品监管合规这3类高密度知识内容。每一条产品页都是10年专业经验的浓缩,被AI爬虫整箱整箱地拉走,做创始人的没法不焦虑。
这种焦虑现在在出海独立站圈里很普遍。问题不是焦虑本身,是焦虑之后采取的动作。常见的反应是“一刀切全拦”,结果是把AI引用流量也一起拦没了。正确的反应是“先把检测做实、再做分级授权、最后反向利用”。这篇文章的目标是把检测的6种方法、授权的8种选择、反向利用的5条路径全部摊开,给一份90天落地路线图。拦AI爬虫该不该的7维度判定与三层方法那篇讲的是“怎么拦”,本文讲的是“拦之前先检测、拦之后还能反向用”的完整闭环,两篇配着读才完整。
AI训练数据从哪来?爬虫到落库的底层管线是什么?
要判断自家网站有没有被AI训练,先得理解AI训练数据从抓取到落库的5步管线。第一步是发现,AI爬虫从种子列表(通常包括CommonCrawl历史数据、维基百科外链、行业头部站点反链)出发抓取。第二步是抓取,按robots.txt和UA标识做合规过滤,但许多新爬虫不遵守robots.txt直接抓。第三步是入库,抓取的HTML按域名分桶存到对象存储里,原始数据保留3到12个月。
第四步是清洗,把HTML转纯文本、去广告、去模板、做语种识别和质量打分。这一步把抓取来的几百TB原始数据压到几十TB可训练文本。第五步是采样训练,按质量打分加权采样进入训练数据集。质量打分高的内容被采样概率更高,专业领域内容(医疗、法律、金融、护肤这种高门槛内容)权重明显比一般博客高。
| 管线步骤 | 核心动作 | 是否可检测 | 检测难度 |
|---|---|---|---|
| 1发现 | 种子列表加扩展 | 否(黑盒) | 无法检测 |
| 2抓取 | 按UA抓HTML | 是 | 低(看服务器日志) |
| 3入库 | 对象存储分桶 | 是 | 中(对账CommonCrawl) |
| 4清洗 | 去模板加质量打分 | 部分 | 高(仅个别数据集可查) |
| 5采样训练 | 按权重进入数据集 | 否(黑盒) | 无法直接检测 |
实操上能检测到的是2、3、4三步,1和5是模型厂的内部黑盒。所以下面6种检测方法都集中在这3步上做。AI爬虫抓取量已超Googlebot 3.6倍那篇里也提到这种抓取-入库-训练分离的管线模式,是2024年之后AI厂的通用工程实践。
C4数据集token查询为什么不能下定论?
2023年华盛顿邮报和AllenAI发布了C4数据集的token搜索工具,输入域名可以看到该域名在C4里的token数和占比。这个工具非常直观,很多站长一查发现自己博客被收录了几百几千token,立马得出“被AI训练了”的结论。但这个结论只对了一半。
C4数据集是Google T5模型2019到2020年用的训练语料,对应的爬取时间是2019年4月之前的CommonCrawl快照。也就是说AllenAI C4数据集说明能告诉你的是“2019年4月之前的内容被Google T5用了”,回答不了“2023到2026年的GPT-4、Claude 3、Gemini Pro有没有训练过你的内容”。这两个时间窗口差5到7年,对独立站来说意义完全不同。
更稳的查询路径是同时对账3个数据源:Common Crawl原始抓取索引看域名最近一次被抓的时间和快照、C4工具看T5时代的token数、再加上自己服务器日志查2023年以后AI爬虫的UA命中频率。3个数据源都有命中,才能初步判定“近期被用于AI训练”概率高。
| 检测源 | 覆盖时间窗 | 能回答的问题 | 不能回答的问题 |
|---|---|---|---|
| C4 token查询 | 2019年4月之前 | Google T5是否用过 | GPT、Claude、Gemini近期是否用 |
| CommonCrawl索引 | 2008至今每月快照 | 原始抓取是否进入数据池 | 谁后续训练用了 |
| 服务器UA日志 | 仅可追溯日志保留期 | 近期AI爬虫抓取频率 | 历史是否被训练 |
6种独立检测方法分别怎么做?
把检测做实需要6种方法叠加,每一种独立看都不够,加起来才能给出可信判断。
方法一是C4 token查询。在C4搜索工具输入自己域名,看返回的token数。2000以下token弱信号、2000到20000中信号、20000以上强信号。出海精油护肤DTC客户查到自己域名6.8万token,落在强信号区。
方法二是CommonCrawl对账。在commoncrawl.org的CDX索引里查询自己域名,看最近5次月度快照里被抓取的页面数。月均500页以上是高频抓取信号,月均不足50页是低频信号。客户的CC快照月均1.2万页,远超阈值。
方法三是GPTBot CCBot UA日志检索。把过去6个月的Web服务器日志按UA过滤,看GPTBot、CCBot、ClaudeBot、PerplexityBot、anthropic-ai、Bytespider、Amazonbot这7个主要AI爬虫的日均抓取频率。客户的5个AI爬虫日均合计1.25万次,是Googlebot的3倍。OpenAI官方GPTBot文档里给出了完整的IP段和User-Agent字符串,可以直接用来构造日志过滤规则。
方法四是反向prompt测试。在ChatGPT、Claude、Perplexity、Gemini这4个主流AI助手里分别提问“你知道xxx品牌的产品吗”、“在xxx领域有哪些品牌值得推荐”、“xxx品牌的玫瑰精油是什么成分”。如果AI能给出具体产品名、成分、价格区间,说明该品牌相关内容已被纳入训练或检索增强生成。客户测试4个工具10个问题,命中率87%,强信号。
方法五是引用率工具。用Profound、Otterly、Goodie、HubSpot AI Search Grader这4个新兴AI引用监测工具看自己域名在AI回答里的引用频率。引用频率高代表AI模型已经把该域名作为可信源,间接证明训练数据里有覆盖。客户Profound监测显示月均382次引用,强信号。
方法六是品牌名召回率。在ChatGPT和Claude里测试“没有上下文情况下能否准确回忆品牌完整名称和品类”。这一项测试的是模型权重里有没有真正记住该品牌(不是检索增强阶段才查到的)。客户测试品牌名召回率68%,中等偏强信号——模型对该品牌有一定记忆。
| 方法 | 工具/路径 | 客户案例信号 | 判定 |
|---|---|---|---|
| 1 C4 token | C4搜索工具 | 68000 token | 强 |
| 2 CC对账 | commoncrawl.org CDX | 月均12000页 | 强 |
| 3 UA日志 | 服务器日志检索 | 日均12500次 | 强 |
| 4反向prompt | 4 AI助手10问 | 命中率87% | 强 |
| 5引用率工具 | Profound等4款 | 月均382次引用 | 强 |
| 6品牌召回 | 无上下文测试 | 召回率68% | 中偏强 |
6项里有5项强信号、1项中偏强,可以确定品牌已被多个主流AI模型训练或检索覆盖。这种确定性比单一方法可靠得多。
GPTBot CCBot ClaudeBot这些UA在日志里长什么样?
方法三里的UA日志检索是6种里最实操、最便宜的一种,几乎所有Web服务器都能做。但前提是认识这些AI爬虫的UA特征。
GPTBot的标准UA字符串是“Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; GPTBot/1.1; +https://openai.com/gptbot”,IP段全部在OpenAI申明的列表里,可以通过Google爬虫总览文档里类似的反向DNS核验逻辑做IP验证。CCBot的UA是“CCBot/2.0 (https://commoncrawl.org/faq/)”,遵守robots.txt但抓取频率极高,因为CommonCrawl是众多AI模型的种子数据源。
ClaudeBot的UA是“Mozilla/5.0 (compatible; ClaudeBot/1.0; +claudebot@anthropic.com)”,Anthropic的爬虫。PerplexityBot的UA是“Mozilla/5.0 (compatible; PerplexityBot/1.0; +https://docs.perplexity.ai/docs/perplexitybot)”,Perplexity AI检索增强生成的爬虫,2024年抓取量暴涨。Bytespider是字节跳动旗下,UA是“Bytespider”,2024年下半年中国大陆AI模型训练需求拉动的高频爬虫。Amazonbot是Amazon AI助手Rufus的爬虫,2025年开始活跃。
| AI爬虫 | 所属厂 | 用途 | 遵守robots.txt | 2026年抓取频率级别 |
|---|---|---|---|---|
| GPTBot | OpenAI | GPT训练 | 是 | 极高 |
| CCBot | Common Crawl | 公开数据集 | 是 | 极高 |
| ClaudeBot | Anthropic | Claude训练 | 是 | 高 |
| PerplexityBot | Perplexity | RAG检索 | 部分 | 高 |
| Google-Extended | Gemini训练 | 是 | 高 | |
| Bytespider | 字节跳动 | 豆包训练 | 部分 | 中高 |
| Amazonbot | Amazon | Rufus AI | 是 | 中 |
这张表是2026年5月的快照,半年内还会有新爬虫出现(meta-externalagent、xAIBot这类已经开始活跃)。日志检索规则要按季度更新一次,保持对新UA的识别能力。
反向prompt测试5步操作怎么落地?
反向prompt测试是6种检测方法里成本最低、覆盖最直接的一种,5步可以走完。
第一步是建prompt清单。每个品牌准备10到20个测试问题,分3类:品类问题(在某细分领域有哪些品牌值得推荐)、品牌问题(你知道某品牌吗)、产品问题(某品牌的某产品成分价格是什么)。问题要覆盖品牌的核心SKU和高搜索意图查询。
第二步是分工具测试。在ChatGPT(GPT-4o和GPT-5)、Claude(Sonnet和Opus)、Perplexity(Sonar和Pro)、Gemini(Pro 2.5)、文心一言、Kimi这6到8个工具上跑同一组prompt。同一工具同一问题问3次取众数,规避随机性。
第三步是评分。每个回答按4维度打分:品牌名召回(满分3分)、产品具体度(满分3分)、信息准确度(满分3分)、出处链接质量(满分1分)。总分10分,6分以上算高命中。
第四步是分场景对比。把同一问题在“无上下文”和“有上下文(先给品牌官网链接再问)”2种场景下分别测试。无上下文高命中率代表模型权重里有记忆(训练数据贡献),有上下文高命中率代表检索增强能力(实时抓取贡献)。两者差异能拆出训练贡献和检索贡献的比例。
第五步是周期化跟踪。每月跑一次同一组prompt,看命中率变化趋势。如果命中率在3个月内连续上升5个百分点以上,说明品牌在AI生态里的存在感在加强;如果连续下降,说明被新内容淹没或被竞争对手抢占心智,需要补强内容生产或品牌信号。
| 步骤 | 动作 | 产出 | 周期 |
|---|---|---|---|
| 1建prompt清单 | 10到20问题分3类 | 测试脚本 | 一次性 |
| 2分工具测试 | 6到8工具跑同问 | 原始回答记录 | 每月 |
| 3评分 | 4维度10分制 | 命中率报表 | 每月 |
| 4场景对比 | 无上下文vs有上下文 | 训练贡献占比 | 每季 |
| 5周期跟踪 | 月度回看趋势 | 趋势曲线 | 持续 |
8种授权选择怎么选?决策矩阵看哪4个维度?
检测做实之后到了授权决策环节。市场上常见的8种授权选择从最开放到最封闭排成谱系,每一种都有适用场景。
方案一是全部开放。所有AI爬虫不拦,让模型自由训练。适合品牌曝光优先、内容资产价值不高、希望最大化AI引用的场景。方案二是只拦个别新爬虫。对成熟AI爬虫(GPTBot、CCBot、Google-Extended)开放,对新出现且行为可疑的爬虫(某些SEO工具爬虫伪装AI)拦截。方案三是分内容类型授权。博客内容开放,产品页面开放,但内部知识库、白皮书、专家访谈等高价值原创内容用noindex加robots禁止。
方案四是分时间段授权。历史内容(1年以上)开放给AI训练,新发布内容(30天内)拒绝抓取,建立时间差让独家内容先有人工读者再被AI索引。方案五是按区域授权。对欧美主流AI爬虫开放,对部分爬虫合规风险高的拦截。方案六是合作授权。与AI厂签独家或半独家合作协议,按使用量收费或换流量回路(如Bing Copilot的源链接展示协议)。
方案七是全拦robots.txt软拦截。用robots.txt User-agent段全Disallow,对遵守协议的爬虫有效。方案八是WAF硬拦截。用Cloudflare、Fastly、AWS WAF做UA和IP段过滤,硬性阻断抓取,对不遵守robots的爬虫也有效。
| 方案编号 | 方案名 | 开放度 | 典型适用场景 | 主要风险 |
|---|---|---|---|---|
| 1 | 全部开放 | 5/5 | 品牌曝光优先 | 内容资产被白嫖 |
| 2 | 只拦新爬虫 | 4/5 | 主流AI欢迎 | 新爬虫识别有滞后 |
| 3 | 分内容授权 | 3/5 | 有核心知识资产 | 分类维护成本 |
| 4 | 分时间授权 | 3/5 | 新内容独占价值高 | 规则配置复杂 |
| 5 | 按区域授权 | 3/5 | 合规重于流量 | 地域识别绕过 |
| 6 | 合作授权 | 3/5 | 有谈判筹码 | 谈判成本高 |
| 7 | 软拦截 | 1/5 | 态度声明 | 不守规者绕过 |
| 8 | 硬拦截 | 0/5 | 资产保护极致 | AI引用归零 |
选哪一种看4个维度。第一个维度是内容资产价值,原创深度高、第一手数据多、专业护城河深的内容,应该往分级授权方向走,不要全开。第二个维度是流量回路依赖,独立站如果AI引用已经贡献了10%以上的访问,全拦风险极大。第三个维度是品牌曝光阶段,新品牌或者增长期品牌的优先目标是露出,全开偏向开放。第四个维度是法律边界,欧盟AI Act对训练数据透明性有强约束,欧盟市场为主的品牌可以更积极地行使授权权。
全拦还是分级授权?2类极端选择的代价是什么?
2024到2025这两年我见过2类极端选择,结果都不好。第一类是全拦,全拦的代价是AI引用归零。具体案例是2024年4月一家做出海有机香料的DTC品牌,看到GPTBot抓取量暴涨就全拦,包括GPTBot、CCBot、ClaudeBot、Google-Extended、PerplexityBot五个爬虫一起拦。9个月后2025年1月复盘:AI Overviews引用从月420次掉到月8次(约98%降幅),ChatGPT引用从月180次掉到月0次,Perplexity引用从月55次掉到月3次。这些AI引用回路里原本带来的流量月约2200次访问,全部消失,对应业务损失估算月5.2万美金。
第二类极端是全开放但不区分内容类型。某DTC珠宝品牌2023年开始全开放,所有内容包括内部年度运营白皮书、独家供应链知识库、专家访谈视频文字稿一并开放给AI训练。2025年3月发现竞品在ChatGPT回答里大段引用他们的独家供应链分析,原话照搬,竞品借此优化自己的供应链流程。这种白嫖损失没法精确算账,但供应链护城河被压平是肉眼可见的。
分级授权才是稳态选择。基本原则是:博客内容、产品页面、客户案例这3类“营销内容”开放给AI,让品牌曝光最大化;内部知识库、白皮书、专家访谈、原创数据报告这4类“知识资产”拦截AI训练,靠人工读者和注册门槛分发。防火墙能不能挡住AI爬虫的11类方法那篇里给了Cloudflare、Fastly、AWS WAF的具体规则配置,可以直接拿去用。
| 极端选择 | 动作 | 9个月后结果 | 建议替代 |
|---|---|---|---|
| 全拦 | 所有AI爬虫Disallow | AI引用归零 | 分级授权(营销开知识闭) |
| 全开 | 所有内容无差别开放 | 独家资产被白嫖 | 分级授权(营销开知识闭) |
AI引用怎么反向变成SEO新流量入口?
授权决策做完之后,最容易被忽视的一步是“反向利用AI引用做SEO新流量入口”。5条路径可以让AI引用变成实际访问。
路径一是长尾词回流。AI回答触发的查询多是长尾型问题,被AI推荐到的品牌名会出现在用户的下一步搜索里。GSC过去12个月里如果发现品牌名+长尾词组合的搜索量上升5%以上,说明AI引用在做长尾回流。
路径二是品牌搜索回流。AI回答提及品牌之后,用户会去Google直接搜品牌名验证。这条回路在GSC里表现为品牌查询点击量周环比上升。客户案例中品牌查询从月8500次升到月14200次,约68%涨幅,绝大部分是AI引用带回来的。
路径三是直接访问回流。AI回答里如果带链接,部分用户会直接点过去。Perplexity和Bing Copilot都展示源链接,可以在GA4里看Referral流量来源,AI助手域名(perplexity.ai、bing.com/chat、chatgpt.com)的Referral访问占比是这条路径的直接信号。
路径四是社交分发回流。AI回答里提到的品牌会被用户截图分享到Reddit、Twitter、LinkedIn,引发二次曝光。把品牌名加AI助手名(“ChatGPT推荐”、“Claude says”、“Perplexity reviewed”)做社交监控,能跟踪这条回路的强度。
路径五是行业媒体二次引用。AI回答里的品牌会被行业自媒体作者作为“AI认为值得推荐的品牌”引用到他们的文章里,形成二次SEO背书。这条回路最慢但护城河最深,6到12个月才看到效果。
| 路径 | 触发动作 | 监测信号 | 转化周期 |
|---|---|---|---|
| 1长尾词回流 | AI推荐后长尾搜索 | GSC品牌长尾词上涨 | 2到4周 |
| 2品牌搜索回流 | 验证型品牌名搜索 | GSC品牌词点击上涨 | 1到2周 |
| 3直接访问回流 | AI回答带链接点击 | GA4 AI助手Referral | 立即 |
| 4社交分发回流 | 截图分享二次曝光 | 社交监控品牌+AI关键词 | 3到6周 |
| 5行业媒体二次引用 | 自媒体作者引用 | 反链监测带AI上下文 | 6到12个月 |
NYT诉OpenAI和EU AI Act对SEO团队有什么实操含义?
2023年12月NYT起诉OpenAI侵犯版权使用其新闻内容训练AI,2025年下半年案件进入实质庭审阶段。这桩诉讼对SEO团队的含义不是“起诉OpenAI能不能赢”,而是建立了一个法律先例:内容创作者对自己内容被用于AI训练有主张补偿的权利。这个先例之后,欧美陆续有出版商和创作者联盟跟进发起类似诉讼。但中小独立站起诉成本太高,单案律师费就是几十万到几百万美金,实际能跟进的极少。
欧盟AI Act 2025年起逐步生效,对在欧盟运营或服务欧盟用户的AI厂提出训练数据透明化要求,包括公开训练数据来源摘要、配合权利人的退出请求。这对欧盟市场为主的独立站是利好——AI厂被迫配合退出请求,提高了授权策略的强制力。具体做法是在网站政策页加“AI Training Opt-Out”声明,并通过维基百科正式禁AI内容类似的Wikidata实体声明把退出意愿登记到机器可读元数据里。
美国和加州层面,加州AB 2013要求生成式AI产品披露训练数据来源,2026年正式生效。中国2023年发布的《生成式人工智能服务管理暂行办法》对训练数据合法性有原则要求,但具体执行细则还在演进。
| 法律/法规 | 地区 | 对SEO团队的实操含义 | 建议动作 |
|---|---|---|---|
| NYT v. OpenAI | 美国 | 建立创作者补偿权先例 | 关注集体诉讼参与机会 |
| EU AI Act | 欧盟 | 退出请求有强制力 | 政策页加Opt-Out声明 |
| 加州AB 2013 | 加州 | 训练数据来源披露 | 持续监控披露内容 |
| 中国暂行办法 | 中国 | 训练数据合法性原则 | 合规性自查 |
90天检测+授权决策路线该怎么排?
把前面8节合起来给一份90天落地路线,每个阶段给具体动作和验证指标。
第1到2周做检测。跑6种检测方法的前3种最便宜的:C4 token查询、CommonCrawl对账、服务器日志AI爬虫UA检索。每一项产出一份数据表。这一阶段的目标是“知道自家被AI抓取的规模和频率”,不是急着做决策。
第3到4周做深度检测。跑反向prompt测试(10到20题×6到8工具)、引用率工具监测、品牌名召回率测试。这3项加起来产出一份“AI生态存在感报告”,知道品牌在主流AI生态里的真实位置。
第5到6周做决策。把检测结果摊在桌上,按4维度(资产价值、流量回路、品牌阶段、法律边界)走8种授权选择决策矩阵。多数独立站会落在“分级授权”这一档:营销内容开放、知识资产闭合。
第7到9周做技术实施。更新robots.txt加分级Disallow规则、Cloudflare WAF配置UA和IP段过滤、在政策页加AI Opt-Out声明、给核心知识资产页加X-Robots-Tag头部。同步配置Cloudflare Bot Analytics或类似工具做实时监控。
第10到13周做反向利用与监测。启动5条反向利用路径的监测:GSC品牌长尾词跟踪、GA4 AI助手Referral流量、Profound等引用率工具、社交监控、反链监测。同步月度跑反向prompt测试,看授权策略对AI生态存在感的影响。
| 阶段 | 周次 | 核心动作 | 产出 |
|---|---|---|---|
| 初步检测 | 1到2周 | C4+CC+日志 | 抓取规模报告 |
| 深度检测 | 3到4周 | prompt+引用率+召回 | AI存在感报告 |
| 授权决策 | 5到6周 | 4维度走8选项 | 策略文档+高管签字 |
| 技术实施 | 7到9周 | robots+WAF+Opt-Out | 配置上线+监控仪表 |
| 反向利用 | 10到13周 | 5路径监测 | 月度报告+回调机制 |
客户案例里那位玫瑰精油护肤创始人最后选的是“分级授权”:博客和产品页继续开放给所有主流AI(GPTBot、CCBot、ClaudeBot、Google-Extended、PerplexityBot),但芳疗师专家访谈、欧盟合规白皮书、独家供应链分析这3类总共47篇内容全部加X-Robots-Tag禁止AI训练。同时在政策页加EU AI Opt-Out声明。90天之后看效果:AI引用率没掉(月均382次稳定)、独家知识资产被白嫖现象明显减少(反向prompt测试里这47篇内容相关问题的命中率从原62%降到18%)、品牌长尾词搜索量上涨11%。这种结果就是分级授权的稳态收益。
常见问题解答
怎么快速判断自己的网站被用于AI训练了?最快3种方法:查C4数据集token数、对账CommonCrawl快照、看服务器日志里GPTBot和CCBot的UA命中频率。3项有任一命中即可初步判定。
robots.txt写了Disallow就能挡住所有AI爬虫吗?不能。robots.txt是君子协议,OpenAI和Google大爬虫会遵守,但许多新爬虫和代理类抓取不会,需要叠加UA层防火墙和WAF规则才有效。
全拦AI爬虫会不会害自己丢AI引用流量?会。全拦之后AI回答里就找不到你的品牌出处,引用率降到接近零。建议按内容资产价值分级授权,核心商业内容可放开供AI索引。
Google-Extended和Googlebot是同一个吗?不是。Googlebot是搜索索引爬虫,Google-Extended是Bard和Gemini模型的训练爬虫,可以单独拦截而不影响搜索SEO,2个User-Agent要分别配置。
AI模型回答里引用我的品牌算不算流量入口?算。即使没有直接点击,AI回答提到品牌名是高质量曝光,5条路径可以把这种曝光变成实际访问:长尾词回流、品牌搜索回流、直接访问回流、社交分发回流、行业媒体二次引用回流。
NYT诉OpenAI对中小独立站有什么参考价值?NYT诉讼确立了内容创作者可主张训练数据补偿权,但中小站点起诉成本太高,更实际的应对是用授权机制和反向流量利用而不是法律对抗。
90天检测授权落地路线第一周做什么?第一周必做3件事:导出过去3个月服务器日志查AI爬虫UA、注册AllenAI C4 token查询工具看自己域名token数、把robots.txt里的GPTBot Disallow策略写到文档。
权威参考资料
本文涉及的AI爬虫UA标识、Google-Extended训练用途、Common Crawl数据集结构、C4数据集时间窗等关键事实,参考以下权威来源。
本文标题:《你的内容被AI训练了吗?6种检测方法与8种授权对策》
本文链接:https://zhangwenbao.com/site-content-ai-training-detect-control.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0