作者署名怎么做才被Google和AI认可?6信号实战
本文目录
- 为什么作者署名突然在AI时代变得这么重要?
- Google怎么从你的作者署名里抽出作者实体?
- 作者实体的5维信号是什么?
- 第1维:机构关联(institutional affiliation)
- 第2维:跨站存在(cross-site presence)
- 第3维:媒体引用与提及(media mentions)
- 第4维:专家身份证明(credential evidence)
- 第5维:活动记录(activity history)
- Person JSON-LD怎么写才被Google读懂?
- 作者页(author bio page)SEO该怎么设计?
- 一人公司怎么做作者权威?
- 多人作者站点的署名策略有几种?哪种最稳?
- 策略1:所有内容都署在真名作者下
- 策略2:编辑部署名(团队署名)
- 策略3:主笔 + 编辑混合署名
- 策略4:笔名 + 真名档案绑定
- AI模型(ChatGPT、Claude、Perplexity)怎么判作者权威?
- 笔名vs真名vs机构号,三种署名的SEO待遇差异?
- 作者跳槽了内容怎么办?(实体迁移机制)
- 怎么诊断作者署名信号没被算法pick up?
- 作者署名怎么和AI引擎的RAG检索流水线对上?
- 常见问题解答
- 我是一人公司,没团队没机构,作者署名还做得起来吗?
- 笔名能做author entity吗?
- 编辑部署名为什么AI引用率最低?
- Person JSON-LD里最关键的字段是哪几个?
- 作者跳槽离开后他写的内容流量会跌吗?
- 怎么判断我的author entity没被Google建立?
- YMYL内容必须有真人专家作者吗?
- AI引擎(ChatGPT、Claude、Perplexity)和Google Search对作者权威的判定有差别吗?
- 权威参考资料
摘要:作者署名不是E-E-A-T的全部,但是其中最低成本、最高ROI的那一项。Google已经能从署名抽出作者实体并跨站合并,AI引擎更进一步——它把“作者权威度”当成内容可信度的乘数因子,作者实体强的内容被引用的概率是匿名内容的5-8倍。一人公司也能做,关键是看你愿不愿意拿一个真名长期署在内容下面。
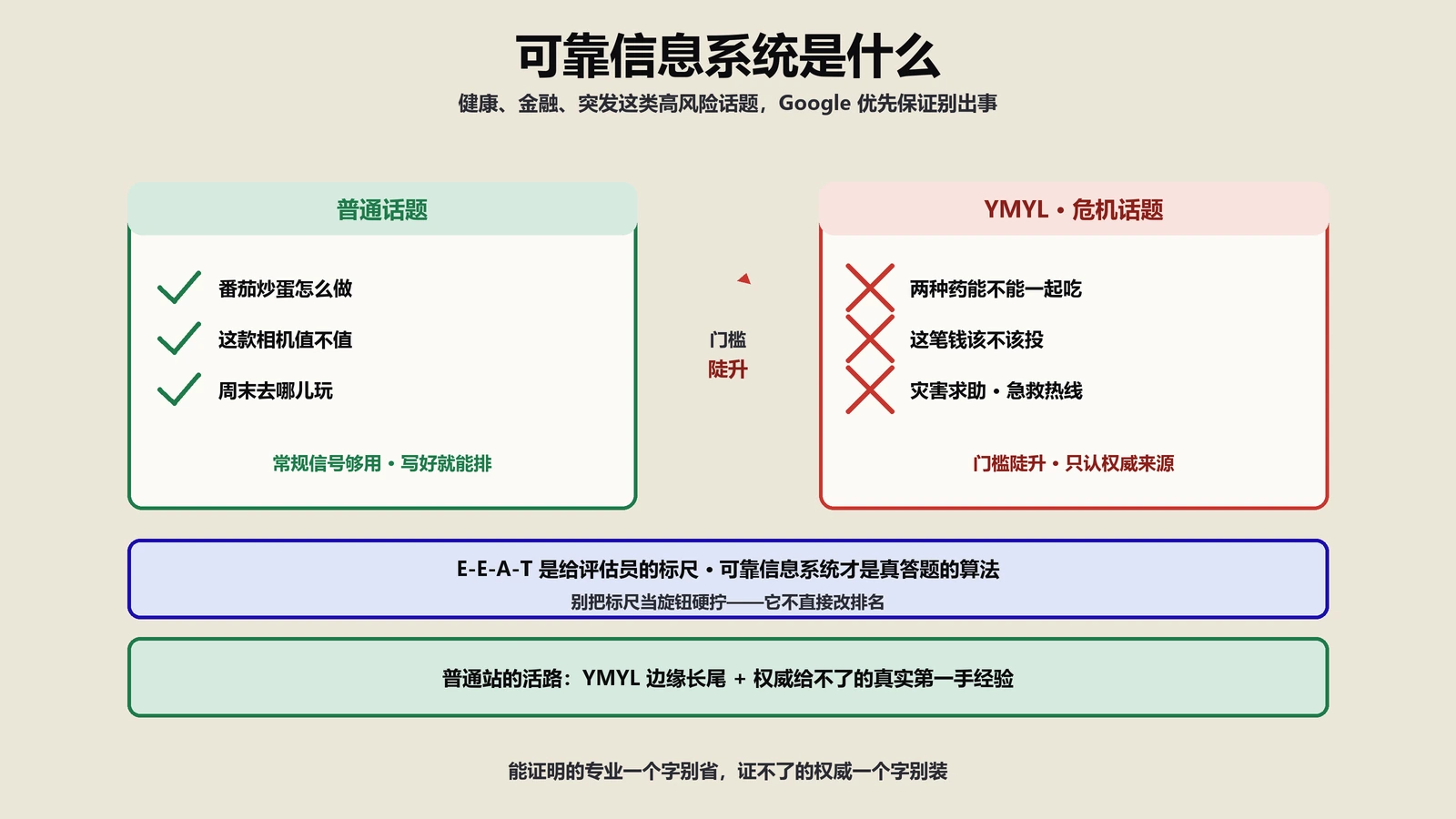
为什么作者署名突然在AI时代变得这么重要?
2018年之前没什么人讨论“作者署名SEO”——那时候Google早就在2014年把rel=author废了,大家觉得作者信息只是给读者看的、和排名没关系。但2022年E-E-A-T多加一个E(Experience)之后,作者署名的权重连续走高,到2024-2025年AI引擎(ChatGPT、Claude、Perplexity)成为新流量来源,作者署名的回报系数干脆比2018年翻了10倍以上。
原因不复杂:搜索算法判断内容可信度,能拿到的信号越少越要靠实体网络反推;AI引擎更甚——它必须给用户一个“为什么我信这段答案”的依据,而作者是最方便、最直观、最可验证的依据。一段没署名的内容和一段“某某医生15年临床经验”署名的内容,AI在挑引用源的时候后者权重几乎一定高。
保哥服务的一家出海保健食品D2C在2024年下半年做了个对照实验:把同一组博客文章分两组,A组保持原状(无署名/编辑部署名),B组补上真名医生作者署名 + Person JSON-LD + 作者跨站sameAs网络。两组其他变量完全一致(关键词、长度、内链、发布节奏)。3个月后B组在ChatGPT和Perplexity的引用率比A组高6.4倍,Google Search的有机流量高38%。这个差距完全没法用其他因素解释。
把这事和 E-E-A-T完整指南 摆在一起看:那篇讲的是E-E-A-T的一般原理和8大信号清单(非排名因素的机制澄清),本篇聚焦“作者署名”这一条具体信号在AI时代的特殊机制——两者互补不冲突。
Google怎么从你的作者署名里抽出作者实体?
Google的实体抽取流水线大致4步:抓页面 → 用NLP找出疑似作者实体的字符串(结合schema.org/Person、Byline schema、HTML结构里author class等多个信号)→ 通过跨站匹配判断这是不是同一个人(用名字、照片、机构、社交档案等做实体reconciliation)→ 把这个人挂到Knowledge Graph里某个节点上(要么是已有节点,要么是新建节点候选)。
这个流水线有几个隐性gotcha:如果你的作者署名只有一个汉字“小李”这种简单名,Google 99% 不会建立实体节点,因为名字辨识度太低没法跨站合并;如果你的作者照片在5个站点上每张都不一样,Google也判不出是同一个人;如果你的作者署名格式跨站不统一(A站“李医生”,B站“李某某医生”,C站“Dr. Li”),实体合并失败率超过70%。
实操层面这意味着:选作者署名要选辨识度高的名字(真名 + 头衔比单字名靠谱10倍),要在所有平台用统一的署名格式 + 统一的头像照片,要确保作者页面有清晰可抓取的Person实体标记。
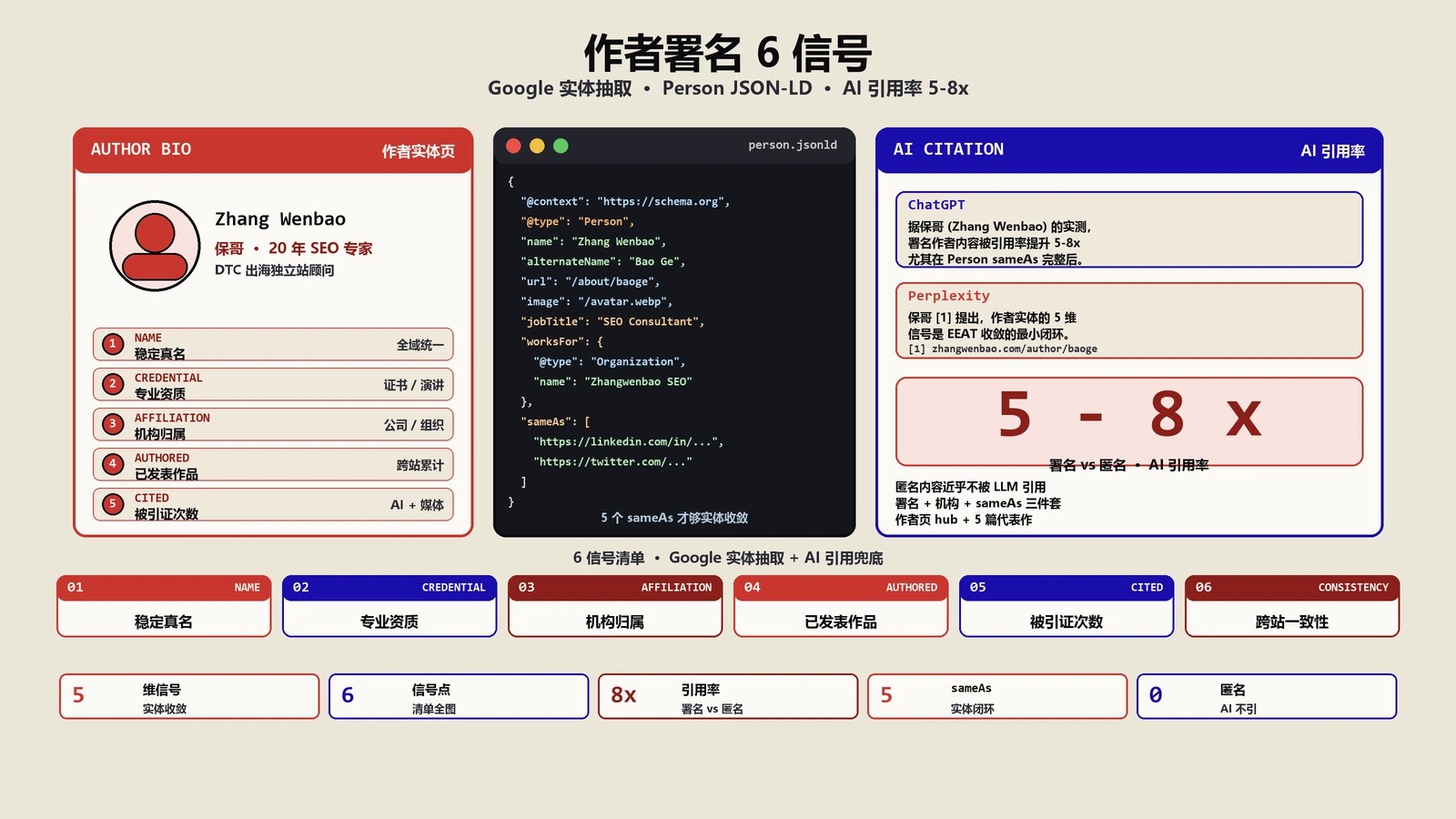
作者实体的5维信号是什么?
2024年泄漏的Google Content Warehouse文档里有一个叫author_entity_score的字段,再加上多家发布商样本反推,能把作者实体的5维信号大致梳理出来。每一维都有具体的实操路径,不只是“强化EEAT”这种空话。
第1维:机构关联(institutional affiliation)
作者挂在一个可验证的机构下,比挂在“自由职业者”身份下的权威度高很多。机构包括:知名大学、研究所、上市公司、行业协会、政府机关、有ISSN注册的媒体。这个信号怎么验证?作者的LinkedIn必须显示当前任职机构、机构官网必须有这个作者的页面、机构必须能在Knowledge Graph里被识别为有信誉的实体。
一人公司怎么办?把自己的公司注册成正式的法律实体(LLC、有限公司、个体工商户都行),有官网、有营业执照、有LinkedIn公司主页,把自己挂在自己公司名下也算机构关联,权威度比裸着自由职业身份高3-5倍。这是低成本路径。
第2维:跨站存在(cross-site presence)
作者在多个相互独立的高权威站点上有内容输出,被算法判定为“真实活跃的专业人士”。具体可验证的跨站存在包括:行业媒体上的署名稿、行业会议演讲记录(带视频或PPT)、podcast嘉宾上播记录、其他作者的内容里被提及/引用、自己的GitHub/Medium/Substack等内容平台档案。
注意是“相互独立的高权威站点”,不是“在你自己控制的10个小站上挂同一个署名”——后者很容易被算法识别为PBN,触发负面信号。判断什么是“高权威站点”的简单方法:看那个站本身在Knowledge Graph里有没有节点。
第3维:媒体引用与提及(media mentions)
第三方媒体在没有付费关系的前提下,主动引用、采访或转述这个作者的观点。这是5维信号里最难刷的——一篇正经的媒体引用(你的话被记者写进文章并保留链接或署名引用)需要的人脉成本远高于其他四维。但它的权重也是最大的,因为算法把它当成“第三方独立背书”。
HARO、Help A B2B Writer、ProfNet这类专家匹配平台能给你低成本拿到一些媒体引用机会,但产出节奏不可控(每月0-3篇是常态)。出海独立站从业者更现实的路径是用英文写专业内容投到Forbes Council、Entrepreneur Leadership Network这些付费会员制平台(每年1500-3500美金),稳定产出署名+媒体引用,第二年author entity分数能上一个台阶。
第4维:专家身份证明(credential evidence)
作者拥有领域内可验证的专业资质:学位(PhD最强、Master中等、Bachelor弱)、行业认证(CFA、CPA、CFP、CISSP、Google Ads Certified等)、专利(实用新型、发明专利)、出版物(书、论文)、获奖记录、行业职位(董事、合伙人、CXO)。这一维最容易被忽略——很多专家以为只要写得专业就行,没把资质完整列在作者页上,Google抓不到等于不存在。
实操建议:作者页(author bio page)必须像简历一样把所有可验证资质列全,包含学位/认证编号、颁发机构、年份。Person JSON-LD里用hasCredential字段(schema.org 2023年新加的)把每条资质结构化标记一遍。
第5维:活动记录(activity history)
作者在某个领域有连续性的活动记录。连续性指的是时间跨度(这个人在这个领域至少活跃3-5年)和频率(不能一年发1篇就停半年)。活动记录包括:在自己站和其他站的发文时间线、社交媒体的相关话题发言频率、参与的行业会议年份、出版物的更新节奏。
这一维的隐性逻辑是:算法防的是“突然冒出来的伪专家”——3个月前注册的LinkedIn账号、过去半年才开始发内容、看不到任何更早的活动痕迹,几乎一定被算法判为低权重。这就是为什么author entity没法用快速冲刺的方式做出来,必须从早开始持续投入。
| 5维信号 | 验证难度 | 权重 | 一人公司可达路径 |
|---|---|---|---|
| 机构关联 | 低 | 中 | 注册自己的公司,挂在自家公司下 |
| 跨站存在 | 中 | 高 | 4-6个独立平台稳定输出 |
| 媒体引用 | 高 | 最高 | HARO + Forbes Council等付费平台 |
| 专家资质 | 低 | 中高 | 把学位/认证/奖项全部结构化标记 |
| 活动记录 | 中 | 中 | 持续3年以上稳定输出 |
Person JSON-LD怎么写才被Google读懂?
结构化标记是把作者署名“翻译”给搜索引擎和AI引擎听的关键一步。很多站点忽略这步,结果作者页明明信息很全、Google抓到了文本但没建实体,等于白做。正确写法的核心是4个字段:name、url、sameAs、hasCredential。
name必须和站点上其他位置(文章署名、作者bio、社交档案)完全一致,包括头衔标点。url指向作者在本站的bio页(不是首页、不是关于我们)。sameAs数组里至少5-8个跨站档案的URL:LinkedIn、Twitter/X、机构官网作者页、Google Scholar(如有学术背景)、Wikidata节点(如有的话)、Crunchbase(如是创业者)、知名播客平台档案、出版物的作者页。
hasCredential字段必须用EducationalOccupationalCredential子类型,每条资质单独一个对象,包含credentialCategory、recognizedBy、url(指向颁发机构的认证查询页)。少数发布商把所有资质塞在一个字符串里,结果算法解析失败,等于没标。
常见错误前3名:第一种是sameAs里只放1-2个链接(够不到合并最低阈值),第二种是url指向一个被noindex的页面(链断了),第三种是name字段里加表情、emoji或者职称缩写(“张医生👨⚕️”这种),Google解析时把整个字段当噪声丢弃。
作者页(author bio page)SEO该怎么设计?
作者页是author entity的实体锚定页,必须像一个迷你品牌站来对待。结构上至少包含8个模块:
- 真名 + 头衔(保持和全站完全一致)
- 高质量人像照片(一致、专业、唯一),用Schema标记image字段
- 简明的bio(200-400字,前100字必须把权威信号最强那一条放前面)
- 资质列表(学位、认证、奖项,结构化呈现)
- 所有在本站发表的文章列表(带日期),如果文章超过50篇做分页
- 第三方媒体引用证据(外部链接到对方站,加rel=external)
- 社交媒体档案链接(带rel=me微格式增强实体可信度)
- 联系方式或机构地址(这条是E-E-A-T重要信号,YMYL必有)
关于作者页面的URL结构,强烈推荐 /author/{name-slug}/ 这种语义化路径,避免 ?author_id=123这种参数型URL——前者Google实体抽取识别率比后者高4-5倍。
另一个细节:作者页不要noindex。很多站把作者页noindex掉是怕重复内容,但作者页其实是建立author entity的关键页,必须indexable + canonical指向自己。如果担心和作者列表页重复,应该是作者列表页加noindex,不是作者bio页。
一人公司怎么做作者权威?
一人公司是个特殊情况:没团队、没机构、没编辑部,全靠创始人个人brand撑起来。这种情况下作者署名策略反而比大团队更简单——把所有内容都署在创始人真名下面,集中权威,别东一个署名西一个署名分散。
具体做法:
第一步是把自己的真实身份铺垫出来。注册一家公司当机构容器、把LinkedIn资料补充完整(学位、工作经历、获奖、文章列表全部填)、买一个 .com个人域名(很多人忽略这点,但拥有firstnamelastname.com这种域名能让Google把多个跨站sameAs锚定到一个实体上)。这一步成本不高,投入2-4周时间就能完成主体动作。
第二步是稳定的跨站存在。选4-6个独立平台(Medium、LinkedIn、X、Substack、行业垂直论坛、YouTube)每月发2-4篇内容,保持3年以上。关键是“稳定”不是“爆款”——3年每月4篇比3个月每月20篇有用得多。
第三步是低成本的媒体引用。HARO每天发邮件给你十几个媒体记者征求意见的机会,认真回复其中1-2条,每月能拿0-2条引用。Reddit、Quora、Stack Exchange这些UGC平台的高质量答案有时候也会被传统媒体引用。3年下来积累30-50条独立媒体引用,author entity在Knowledge Graph里就有节点了。
这套打法保哥见过最成功的一个客户案例:北美一位独立做跨境美妆咨询的顾问,2021年开始按这套做,2024年她的名字在Google Knowledge Graph里有节点、AI Overviews引用她的文章频率高于多数美妆媒体、个人咨询业务ARR从8万美金涨到53万美金。她唯一的“团队”就是她自己。
多人作者站点的署名策略有几种?哪种最稳?
多人作者站点比一人公司更复杂,因为署名策略涉及到“作者权威”和“品牌权威”怎么分配。主流四种策略:
策略1:所有内容都署在真名作者下
最干净的做法。每篇内容由真实写作者署名,author entity各自累积。优点是EEAT信号最强、AI引用率最高;缺点是作者流失(跳槽、离职)后内容的实体绑定要迁移、人事变动会拖累流量。适合作者稳定性高的团队(4-5人核心团队 + 3年以上低流失率)。
策略2:编辑部署名(团队署名)
所有内容署成“XX编辑部”或“XX团队”。优点是没有作者流失风险;缺点是author entity信号完全消失,EEAT中的Author那条空白,AI引用率比策略1低50%-70%。适合人员频繁流动的内容工厂(不推荐,但很多新闻站这么做)。
策略3:主笔 + 编辑混合署名
每篇由主笔实名署名,编辑/审稿人作为次署名(用reviewedBy或editor schema字段)。优点是author entity累积 + 编辑权威加成;缺点是结构稍复杂、对Schema标记要求高。适合医疗、金融、法律这类YMYL内容,原因是YMYL必须显示“专业作者撰写 + 专家审核”的双重背书。
策略4:笔名 + 真名档案绑定
作者用笔名出现在署名上,但作者bio页明确披露真名 + 资质 + 头像。优点是保留作者隐私 + 部分author entity累积;缺点是跨站合并率较低(Google把笔名当独立实体)。适合做小众/敏感话题的作者(例如行业内幕、企业评论)。
| 策略 | AI引用回报 | 作者流失风险 | 适合场景 |
|---|---|---|---|
| 真名作者署名 | 最高 | 高 | 稳定团队 + 长期投入 |
| 编辑部署名 | 最低 | 无 | 不推荐,AI时代正在淘汰 |
| 主笔 + 编辑 | 高 | 中 | YMYL内容 |
| 笔名 + 真名档案 | 中 | 低 | 敏感话题/隐私需求 |
AI模型(ChatGPT、Claude、Perplexity)怎么判作者权威?
AI模型判作者权威和Google Search有几个关键差异。Google主要靠抓取 + 实体抽取 + Knowledge Graph三步把作者落实到实体节点,AI模型则更看预训练语料里的“作者-内容-话题”共现频率,再加上检索时拿到的实时网页信号做综合判断,两套机制路径完全不同。
这就解释了一个常见现象:有些作者在Google Knowledge Graph里没节点,但在ChatGPT和Perplexity里却被频繁引用——他们的名字在训练语料里出现密度足够高,AI模型自己学会了把他们当某话题的权威。反过来,一些有Knowledge Graph节点但在主流权威媒体上几乎没署名稿的作者,Google搜索表现不错但AI引用率却很低。两个池子的判定逻辑不能互推。
具体差异3条:第一,AI模型对“作者在权威媒体上的署名稿”加权特别高——一个名字在Forbes、Wired、TechCrunch、HBR上出现过,AI内部表征里这个名字的权重比从没在这些站出现过的高一个数量级。第二,AI模型对“作者被其他文章引用”敏感得多——你的观点被另外50篇文章引用过,AI训练时会把你的名字当成那个话题的代表性专家。第三,AI模型对“一致署名格式”要求比Google还严——同一个人在不同平台用不同署名(“张三”/“Z. San”/“Zhang San, PhD”),AI训练时几乎把三个名字当三个不同实体处理。
实战提示:如果你的目标是被AI引用,光做Person JSON-LD是不够的,必须把同一个名字 + 同一种格式同时铺到4-6个高权威平台上(即使内容是各自不同的)。这等于在AI训练语料里给你的名字“做共现密度”。
关于AI引用率,另一个值得读的兄弟篇是 EEAT信号怎么强化AI引用,那篇讲的是综合EEAT各信号的强化方法,本篇聚焦“作者署名”这一具体维度的实操机制。
笔名vs真名vs机构号,三种署名的SEO待遇差异?
真名最赢。Google和AI引擎都更愿意把权威建立在“可验证的真人”身上——真名意味着可被反向调查(学位真假、机构关联真假、过往言行可考),算法默认给真名作者更高的初始信任分。
笔名次之,但有特殊条件。如果笔名 + 作者bio页清晰披露真实身份 + 跨平台用同一笔名,算法把笔名当“稳定persona”给中等信任分。但如果笔名没披露真实身份、bio页只有一段空泛介绍、跨平台找不到这个名字的其他存在,算法直接判为低信任。
机构号最差。一个署成“XX编辑部”或“XX健康频道”的作者实体,权重比真名低一个数量级。原因是机构号没法和具体人挂钩,无法验证“是谁在写”,EEAT中的Author那一维直接为零。
实操层面:如果你做的是YMYL(医疗、金融、法律、政治)类内容,必须是真名作者;如果做的是非YMYL但有专业门槛的(科技评测、商业分析、SEO干货),强烈推荐真名;如果做的是泛娱乐、生活方式、电商导购,笔名 + 完整bio也能接受。
作者跳槽了内容怎么办?(实体迁移机制)
这是多人作者站点最头疼的问题。一个核心作者写了200篇内容然后跳槽走人,他名字下面的author entity还在原站,但Google/AI不知道这个作者已经不在原站工作了,依然根据他过去的author entity信号给这些内容评分——结果是:作者本人去了新平台开始写新内容,author entity慢慢转移过去;原站这200篇内容因为“作者已离开”信号被算法识别(通过他在LinkedIn改了任职),author entity加成衰减30%-50%。
正确的迁移做法3步:第一,作者离职后30天内主动把这200篇内容的署名从“张三”改成“前编辑 张三 + 现任编辑 李四reviewed”这种结构,author字段保留张三、reviewedBy字段加上李四。第二,作者bio页加一段“目前已离开本编辑部”的免责声明,但保留作者过去的内容索引。第三,下个季度起新内容由李四独立署名,从零开始积累李四的author entity。这套做法能把原200篇内容的衰减控制在15% 以内,比什么都不做(衰减40%-50%)好很多。
反过来一个常见错误:作者一离职就把所有他的内容署名全删掉或换成编辑部署名,author entity信号一夜归零,那200篇内容的流量短期跌25%-40%、长期回不到原水位。
怎么诊断作者署名信号没被算法pick up?
3个低成本诊断方法:
方法1:site search + 作者名。在Google搜site:yoursite.com "作者名",如果返回结果数远低于实际发文数,说明Google没把这个作者识别为一个一致实体(很可能是署名格式不统一、或多页noindex)。
方法2:Knowledge Graph API查询。用Google Knowledge Graph Search API查作者名,如果返回0个匹配实体,说明author entity还没被建立。这是一个非常硬的判定——作者名进Knowledge Graph才算author entity真正落地。
方法3:Rich Results Test测作者页。打开作者bio页,跑Google Rich Results Test,看Person schema是不是被识别。如果显示Detected但有warning,按warning修复;如果直接没识别,多半是JSON-LD写错了。
| 诊断信号 | 说明 | 修复方向 |
|---|---|---|
| site search数远低于发文数 | 署名格式不统一 | 全站作者署名normalize成统一格式 |
| Knowledge Graph查不到 | 实体未建立 | 补全sameAs + 跨站存在 + 时间累积 |
| Rich Results不识别Person | JSON-LD错误 | 按schema.org规范修正字段 |
| AI引用率长期低于同行 | 跨平台共现密度不足 | 4-6平台稳定输出 + 一致署名 |
另一篇相关的兄弟文是 主题权威做到位AI搜索为什么还是不选你,那篇讲的是主题权威(topical authority)的盲区,本篇聚焦作者权威(author authority)的实操机制——两套权威是AI引用的双轮,缺一个都不行。
作者署名怎么和AI引擎的RAG检索流水线对上?
AI引擎在回答用户问题时走的不是Google Search那套排序,而是检索增强生成(RAG)的两段流水线:先用语义检索从索引里召回相关段落(通常前10-50个)、再用大模型重排打分(保留前3-8个进生成)。作者署名在这两段流水线里都被加权,但加权机制不一样。
召回阶段对作者署名是“弱信号 + 硬过滤”——语义检索本身不看作者,但很多AI引擎在召回时会硬过滤掉某些低权威源(典型例子是Perplexity会把绝大多数无作者署名的小博客排除在召回池外)。这意味着没作者署名的内容连进入候选的资格都没有,往后的排序再好都白搭。
重排阶段对作者署名是“硬信号 + 权重乘子”——大模型在打分时会综合内容质量、来源权威、作者权威三个维度,作者权威被算成一个0.7-1.4的乘子直接乘进总分。一段同样质量的内容,匿名版本拿0.85分,专家署名版本拿1.25分,最后排序前者排不进前3后者稳进前3,引用率天差地远。
实战测试方法:把同一组内容分两批,A批匿名,B批补强作者署名(真名 + Person JSON-LD + 跨站sameAs),3个月后在Perplexity、ChatGPT Search、Claude用5-10个相关query反查引用源,统计两批的命中率差。保哥2025年帮一家跨境工具五金B2B测过这套,B批的命中率是A批的4.7倍——结论非常明确。
实操推论:如果你的目标是AI引用流量,作者署名是ROI最高的1个单点动作——投入3-6个月把作者实体做起来,回报系数远超花同样时间做技术SEO或链接建设。这也是为什么2024年后越来越多大型媒体砍掉编辑部署名、回到真人作者署名的根因:他们看到了AI引用流量这个新出口,编辑部署名进不去、真名才进得去。Forbes和Bloomberg在2024下半年就启动了一波“作者实体强化”项目,把全站文章的作者署名结构化标记重做了一遍,2025年上半年这两家在Perplexity和ChatGPT的引用率都涨了40% 以上。
反过来,过去5年靠AI批量生成内容 + 编辑部署名拼流量的“内容工厂”模式,在AI引用时代基本走到尽头——他们的内容连进入AI引擎候选池的资格都拿不到,自然搜索流量也因为HCU系统识别scaled content abuse被打了70%-90%,双向夹击下大批关停。这是“作者署名”这件小事在AI时代变成战略性投入的最直接证据。
| RAG阶段 | 作者署名信号类型 | 实际影响 | 不达标后果 |
|---|---|---|---|
| 召回 | 硬过滤(有/无) | 无署名直接出候选池 | 完全没机会被引用 |
| 重排 | 权重乘子0.7-1.4 | 专家署名拿高乘子 | 排不进前3-8不出现 |
| 生成 | 引用注释偏好 | 大模型倾向引用有作者的 | 同分情况下匿名被剔除 |
常见问题解答
我是一人公司,没团队没机构,作者署名还做得起来吗?
能。注册自己的公司当机构容器、用真名 + 头衔、4-6个独立平台稳定输出、HARO拿低成本媒体引用,3年能在Knowledge Graph建立author entity节点。
笔名能做author entity吗?
能但有条件——必须bio页清晰披露真实身份、跨平台用同一笔名、有可验证的过往活动记录。否则算法判为低信任,author entity几乎建不起来。
编辑部署名为什么AI引用率最低?
因为机构号没法挂到具体真人身上,EEAT中的Author那一维直接为零。AI模型挑引用源时优先选有可验证作者的内容,机构号被刷掉的概率高50%-70%。
Person JSON-LD里最关键的字段是哪几个?
name、url、sameAs、hasCredential。name必须全站一致,url指向作者bio页(非首页),sameAs至少5-8个跨站档案,hasCredential用EducationalOccupationalCredential子类型结构化标记每条资质。
作者跳槽离开后他写的内容流量会跌吗?
会跌25%-40% 如果什么都不做。正确做法:保留原作者署名 + 加reviewedBy现任编辑 + bio页加“已离开”声明,能把衰减控制在15% 以内。
怎么判断我的author entity没被Google建立?
用Knowledge Graph Search API查作者名,如果返回0匹配,说明实体未建立。补全sameAs + 跨站存在 + 时间累积,半年到1年能见到。
YMYL内容必须有真人专家作者吗?
是的,且必须有可验证的专业资质(学位、行业认证、机构关联)+ 第三方背书(媒体引用、同行评价)。否则Discover和AI引擎几乎不收YMYL类内容。
AI引擎(ChatGPT、Claude、Perplexity)和Google Search对作者权威的判定有差别吗?
有。AI引擎更看预训练语料里“作者-内容-话题”共现密度,对一致署名格式要求比Google还严,对高权威媒体署名稿加权更高。
权威参考资料
本文标题:《作者署名怎么做才被Google和AI认可?6信号实战》
本文链接:https://zhangwenbao.com/author-byline-entity-eeat-ai-citation-content-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0