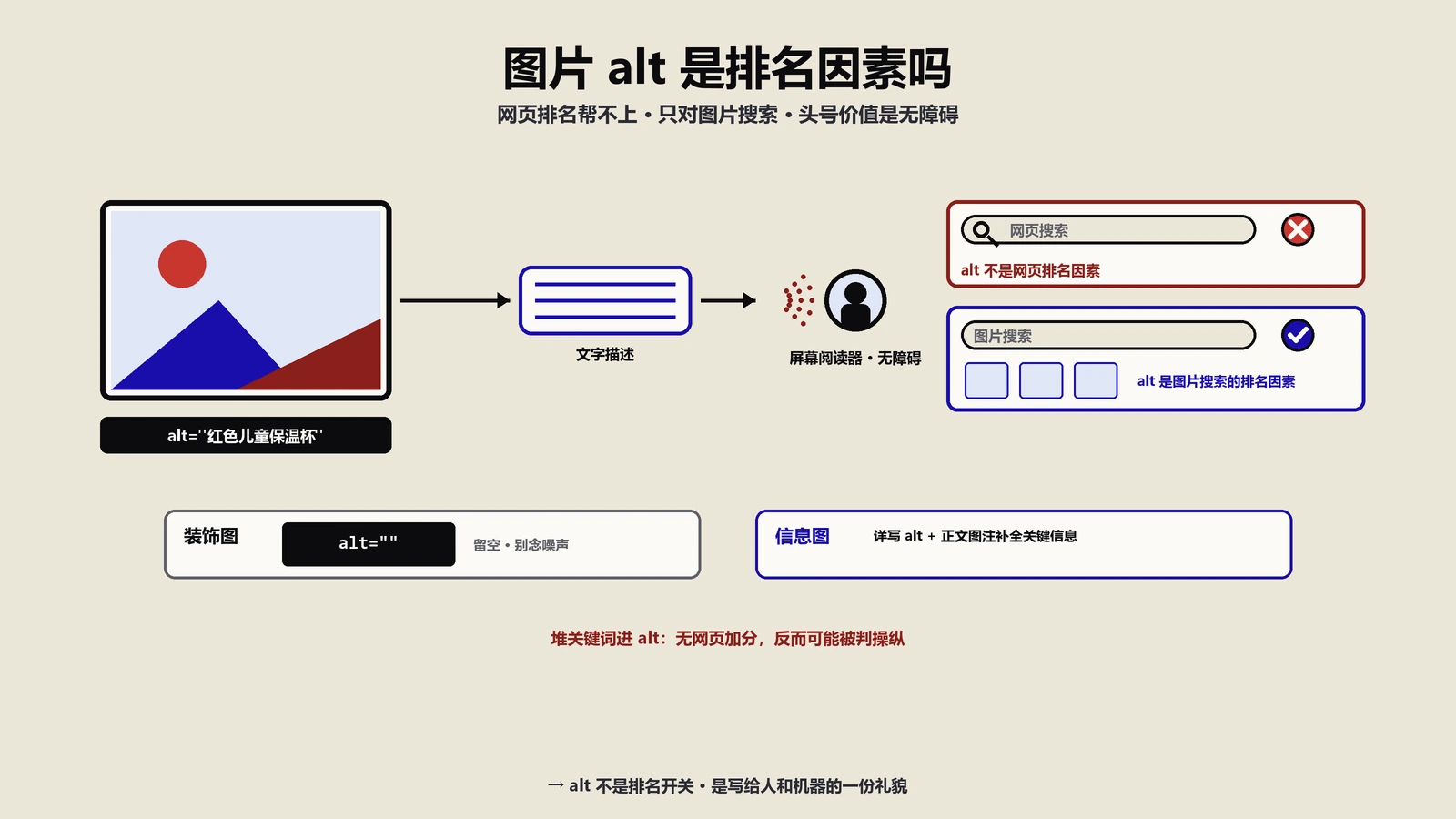
文章目录怎么挂锚点,才能被搜索和AI抓成段落直达

本文目录
- 文章目录到底要不要挂、挂在哪里、怎么挂?
- 长文阈值与挂位规范
- 桌面端常驻与移动端折叠的不同呈现
- 锚 ID 该怎么命名才不冲突不重复?
- 命名规范五条铁律
- 跨组件 ID 冲突的排查方法
- scroll-spy 高亮当前章节的工程实现是什么?
- IntersectionObserver 的现代实现
- scroll-spy 与 sticky TOC 的联动
- scroll-spy 的常见性能陷阱
- 片段索引 sitelinks fragment 怎么主动埋?
- 触发 sitelinks fragment 的三个前置条件
- 文本片段 STTF 的双轨埋点
- Passage Ranking 与页面内导航是什么关系?
- 段落语义可独立性的工程要求
- H 层级承载主题的物理切片
- AI 答案引用你的正文,怎么让它带回标题和品牌?
- 归属信号的三件套
- Schema 与 entity 关联的额外保障
- 移动端的页面内导航有哪些反模式必避?
- Page Layout 算法的像素阈值
- 折叠交互与可访问性
- 页面内导航做完怎么衡量是否生效?
- 四层指标衡量看板
- 常见问题解答
- 文章目录到底要不要挂在长文顶部?
- 锚 ID 怎么命名才不会重复或冲突?
- scroll-spy 高亮当前章节对 SEO 有用吗?
- 片段索引 sitelinks fragment 和 Passage Ranking 是同一回事吗?
- AI 答案引用你的正文一段,怎么让它带回标题和品牌?
- 移动端 sticky 目录会不会被 Google 当成插页打分?
- TOC 工程化后 SERP 上 sitelinks 二级跳转什么时候出现?
- 权威参考资料
摘要:页面内导航不是装饰,是 Passage 抽取、sitelinks fragment、AI 引用三个抽取路径的物理入口。文章目录的位置和样式、锚 ID 的命名规范、scroll-spy 的工程实现、sticky 移动导航的设备分发、文本片段 STTF 的双轨埋点,每一项都直接影响搜索和 AI 能不能把你的文章切片、能不能把品牌信号带回去。这篇把页内导航当一套系统工程拆开讲,给出可照搬的命名规范、对照表和反模式清单。区别于Google Read more 深链与 STTF 那篇的被动配合视角,本篇讲的是主动工程化。
保哥前阵子帮一个跨境户外装备 DTC 客户排查问题:他们的长测评文章字数堆到 8000 字以上、H 层级也挂得有规则,但 Google 上从来没出现过 sitelinks 二级跳转,AI Overviews 引用他们正文一段的时候带回来的标题经常是空的或错位的。看了一遍发现根源不在内容,在页内导航工程做得太草率——文章目录是装饰组件、锚 ID 用数字编号、移动端 TOC 是死的不会折叠、整篇正文没有一个 cite 或 schema 帮 AI 识别归属。改完一整套页内导航之后,三个月里被 sitelinks 二级跳转抓住的页面从 8 篇涨到 21 篇,AI 引用回链率从 14% 涨到 38%。
页面内导航不是 UX 设计师的私域,它直接长在搜索可见度和 AI 引用的物理通道上。这篇把整套工程化的东西摊开讲,从信息架构到命名规范、从 scroll-spy 实现到 sitelinks fragment 触发、从 Passage 切片到 AI 归属信号,每一节都给可以照抄的方案。
文章目录到底要不要挂、挂在哪里、怎么挂?
这是最容易被一句话答错的问题——大多数 SEO 工具默认开 TOC、大多数主题模板默认装 TOC,但真把它配对的站不到三成。挂错位置等于没挂,挂错样式还会反过来扣阅读体验。
长文阈值与挂位规范
什么样的文章配挂 TOC,按字数和 H2 数量两个维度决策:
| 文章字数 | H2 数量 | 是否挂 TOC | 位置与样式 |
|---|---|---|---|
| ≥3000 字 | ≥5 个 | 必挂 | TLDR 之后、第一 H2 之前;桌面常驻、移动折叠 |
| 2000 到 3000 字 | ≥3 个 | 选择性 | 同上;测评类、操作类挂,故事类可不挂 |
| 1500 到 2000 字 | 3 到 4 个 | 建议不挂 | 顶部用 TLDR 概要替代 |
| <1500 字 | ≤2 个 | 不挂 | 挂了反而显得文章注水 |
挂位有三个常见错位:一是挂在 H1 标题正上方(破坏视觉层级),二是挂在第一段正文之中(让正文被打断),三是挂在文章底部(用户已经读完了,TOC 失去意义)。正确的位置只有一个——开篇 TLDR 概要段之后、第一个 H2 标题之前,作为一个独立模块嵌入。
样式上的硬约束有两条:背景色与正文区分但不喧宾夺主(淡灰、淡蓝、淡黄都行);字号比正文小一档但行高足够(line-height 1.6 以上)保证可点击。禁止用全宽度的卡片包裹——TOC 应该占内容栏宽度的 100% 或 80%,不要变成横跨整个视窗的“内容拦腰带”。
桌面端常驻与移动端折叠的不同呈现
同一份 TOC 在桌面和移动端要做完全不同的呈现:
- 桌面端:默认全展开、嵌入正文流;如果浏览器宽度 ≥1200px 还可以做侧栏常驻 sticky TOC(左右栏布局);正文滚动时高亮当前章节(scroll-spy)。
- 平板端:与桌面相同呈现,但 sticky 侧栏不开(屏幕宽度不够,挤压正文)。
- 移动端:默认折叠成一行或一个汉堡按钮;用户点击展开成全屏遮罩层;遮罩内滚动浏览所有锚点,点击跳转后自动收起。
移动端的折叠是硬要求,不是可选项。理由有两个:一是 Page Layout 算法对首屏被遮挡比例超过 30% 像素的页面会扣分,常驻 sticky TOC 在窄屏下很容易触发;二是用户在小屏上不需要 TOC 默认占据视野,需要时点开就行。一个跨境家居 DTC 客户最初坚持移动端也用 sticky TOC,三个月 Core Web Vitals 的 CLS(累积布局偏移)始终红色,把 TOC 改成折叠后立刻转绿。
锚 ID 该怎么命名才不冲突不重复?
锚 ID 是页内导航的物理标识,但绝大多数站的命名都很随意——序号编号、拼音首字母、纯数字 ID、甚至自动生成的 UUID。这些“看起来能用”的命名在 sitelinks fragment 触发、AI 解析、跨组件协作上都会出问题。
命名规范五条铁律
沉淀下来的锚 ID 命名规则有五条:
| 规则 | 对的做法 | 错的做法 |
|---|---|---|
| 1. 用核心关键词的英文 kebab-case | id="rank-tracking-frequency" | id="section-3" 或 id="title3" |
| 2. 全小写、纯英文字母数字与短横线 | id="ai-citation-method" | id="AI_引用方法" 或带空格 |
| 3. 同一篇内全局唯一 | 章节名加锚号区分同名块 | 多个 H3 用同一 ID |
| 4. 加站级命名空间前缀防撞库 | id="zwb-toc-rank" | id="toc"(与第三方组件冲突) |
| 5. 长度控制在 30 个字符内 | 简短语义化 | 整句翻译成英文做 ID |
第三和第四条最容易踩坑。第三条的典型反例是模板里 H2/H3 自动按文案 hash 生成 ID,碰到两个 H3 文案接近(哪怕只是大小写不同)就会生成相同 ID,浏览器只能跳到第一个,后面的全失效。第四条的典型反例是评论组件、社交分享按钮、广告位都用 id="share" 这种通用名,与文章的内容锚撞车。
跨组件 ID 冲突的排查方法
页面上线后要做一次锚 ID 冲突扫描。用浏览器 DevTools Console 跑一行 JS 就能查:
document.querySelectorAll('[id]').length === new Set(Array.from(document.querySelectorAll('[id]')).map(e=>e.id)).size
这一行返回 true 表示页面所有 ID 唯一,返回 false 表示有重复。重复的 ID 用 Array.from(document.querySelectorAll('[id]')).map(e=>e.id).filter((id,i,arr)=>arr.indexOf(id)!==i) 列出来定位。每次发新模板、改主题、加新插件后这一步都要做一次。
另一类排查是对比锚跳转的真实表现。把所有内部锚链接挨个点一遍,验证:跳转后页面位置是否对(注意 sticky header 的偏移量补偿)、URL 末尾的 # 是否正确出现、浏览器返回按钮是否能正常回到上一个锚点。任何一项失败都说明锚 ID 或滚动逻辑有 bug。
命名空间前缀的选择上有个细节——不要用太长的前缀。id="zwb-toc-rank-tracking-frequency" 这种 30 多个字符的 ID 在 sitelinks fragment 触发时反而会被截断。理想长度是 20 到 28 个字符。前缀本身 3 到 5 个字符就够,剩下的留给语义化的核心词。
历史锚 ID 怎么迁移也是个常见问题——老文章的 ID 已经被外站引用、收藏、社交分享过,直接改 ID 会导致这些外链失效。处理方式是在改新 ID 的同时保留旧 ID 作为锚(一个 H2 下挂两个 ID,新旧并存),过渡半年到一年再删除旧 ID。这一招让外站老链接不掉,新工程化的 ID 又能逐步替代。
scroll-spy 高亮当前章节的工程实现是什么?
scroll-spy 是配合 TOC 的“当前章节高亮”功能——用户在正文里滚动,TOC 里对应的章节标题自动高亮。这个交互不是必需,但对长文站的阅读体验提升明显,间接拉滚动深度和停留时间,对 SEO 行为信号有正面贡献。
IntersectionObserver 的现代实现
过去做 scroll-spy 是监听 window.onscroll 然后用 getBoundingClientRect 算每个章节的位置,性能差、移动端会卡。现代浏览器的 IntersectionObserver API 给出了高性能方案:
原理是给每个 H2/H3 节点注册一个 observer,当节点进入或离开视口的指定阈值(通常是顶部 100px 这条线)时触发回调,把 TOC 里对应链接加上 active 类。整套逻辑不到 30 行 JS,浏览器原生支持回调节流,没有性能负担。
实现细节有三个要点:一是 rootMargin 要根据 sticky header 的高度反向偏移(比如 header 60px 高,rootMargin 设 -60px 0px 0px 0px);二是 threshold 取 0 即可(节点刚进入观察区就触发);三是回调里要做防抖处理,避免连续多个章节同时进入视口时 TOC 闪烁。
scroll-spy 与 sticky TOC 的联动
当桌面端侧栏 sticky TOC 配合 scroll-spy 高亮时,需要做一个额外的联动——TOC 列表自身要能在内容很长时滚动到可见高亮项。一个跨境美妆 DTC 客户的 30 个章节长文,最初没做 TOC 内部滚动联动,结果用户读到第 25 章时侧栏 TOC 高亮的项已经滚到屏幕外,体验非常差。后来加了一段联动逻辑——每次 scroll-spy 触发高亮时检查高亮项是否在 TOC 视野内,不在则把 TOC 平滑滚动到该项位置——体验立刻顺了。
这套联动在 vanilla JS 里实现大约 50 行,移动端因为 TOC 是折叠展开的不需要这个逻辑,仅桌面端 sticky 模式启用即可。
scroll-spy 的常见性能陷阱
scroll-spy 看起来轻巧,落地时如果不留意性能细节,长文页面会出现明显的卡顿。最常见的三个陷阱:
- 把 IntersectionObserver 写在 React/Vue 等框架的 useEffect 里却忘了 cleanup。组件销毁时 observer 没解绑,路由切换之后内存里堆着十几个旧 observer,每次滚动都触发全部回调。
- 给每个 H2/H3 单独注册 observer 而不是用一个 observer 观察所有节点。前者是 N 个 observer 各跑各的,后者是一个 observer 拿到 N 个 entries,性能差几十倍。
- scroll-spy 回调里做 DOM 重排,比如直接改高亮项的 className 触发 reflow。正确做法是用 CSS 自定义属性或 data 属性,让 CSS 接管样式切换,避免 reflow。
这三条做对了,scroll-spy 在 50 个章节的超长文上跑都不卡。一个在线教育平台的课程章节页有时一篇能有 80 个 H3,最初的 scroll-spy 实现导致滚动严重掉帧,按上面三条改完后 60fps 稳定。
片段索引 sitelinks fragment 怎么主动埋?
sitelinks fragment 是搜索结果上你的标题下方多出来的“二级跳转链接”,比如搜某个长文标题,搜索结果下面紧跟着 4 到 6 个章节级的小链接,点了直接跳到对应锚点。这是 Google 自动生成的,没有显式触发开关,但有几个明确的前置条件可以主动配合。
触发 sitelinks fragment 的三个前置条件
观察下来稳定触发 sitelinks fragment 的页面有三个共同点:
- H2 结构清晰且数量适中:5 到 10 个 H2,每个 H2 文案带核心查询意图、语义独立。两三个 H2 太少不会触发,十几个 H2 又会被算法判定为目录混乱不触发。
- 锚 ID 命名稳定且语义化:ID 用核心关键词的英文 kebab-case 而非 section-1 这种序号;ID 与 H2 文案的核心词对应;ID 长期不变(改 ID 就是删旧链建新链,sitelinks fragment 要重新累积)。
- 页面在前 3 名长期稳定:sitelinks fragment 只给“高确信度页面”,Google 不会给排在 5 名外的页面加二级跳转。前 3 名稳定至少 2 到 4 周,sitelinks fragment 才会被 Google 主动加上。
具备这三条之后仍然不出,多半是 H2 文案对查询意图覆盖不到位——比如用户搜的是“怎么做”但 H2 全是“是什么”,Google 不认为该页的章节能解答用户的具体子问题。这种情况要回去重写 H2 文案,覆盖更细的查询意图。
文本片段 STTF 的双轨埋点
文本片段(Scroll To Text Fragment, STTF)是另一套机制,URL 末尾用 #:~:text=原文 直接跳到包含该文本的位置,不需要你预先埋锚 ID。这套机制 Chrome 在 2020 年开始全量支持,Google 的 Read more 深链和 AI Overviews 引用都在用。
STTF 不需要主动配置,但配合做几件事能让效果更好:一是关键句单独成段,方便 STTF 选中完整一句而不是半句;二是避免长句中夹杂大量标点,STTF 文本匹配遇到引号、括号、特殊字符时容易失败;三是段首避免空格和不可见字符,部分客户端的 STTF 匹配对前导空白敏感。
这两套机制不冲突,要双轨并行——锚 ID 给传统跳转和 sitelinks fragment 用,STTF 给 Read more 和 AI 引用用。双轨并行的另一个好处是给不同客户端兼容性留余地——老浏览器不支持 STTF 时仍能用锚 ID 跳转,新浏览器两套都能用。
Passage Ranking 与页面内导航是什么关系?
Passage Ranking 是 Google 在 2020 年公布、2021 年初在英文站全量上线的机制——把一篇长文里的某一段当成独立的搜索结果排进 SERP,而不是只把整篇文章作为一个结果排序。这套机制依赖语义化 HTML 让算法自动切片,与你显式埋的锚 ID 关系不大,但页面内导航的设计会大幅影响它的切片质量。
段落语义可独立性的工程要求
Passage Ranking 要切片成功,需要被切的段落本身能独立“说清楚一件事”。工程上有几个具体的要求:
- 每个 H2/H3 下的内容自包含——不要写“上一段提到的方法”这种依赖前文的指代,要把方法重新点出来。
- 段落里关键句要明显,可以用 strong 标记反直觉/阈值/结论性的句子,给算法切片时一个明显的“重点定位”。
- 避免一个 H2 下整段都是叙述性 prose 没有结构,混合段落、列表、表格、blockquote,给算法多个切片粒度。
这一套要求与语义化 HTML 与可提取性工程那篇讲的内容深度相关——Passage Ranking 只是众多需要可提取性的下游应用之一,AI 答案抽取、精选摘要选取、知识图谱实体抽取都用同一套底层 HTML 语义信号。
H 层级承载主题的物理切片
Passage Ranking 的切片粒度通常以 H2 或 H3 章节为单位——你给的 H 层级越合理,切片越精准。一个 B2B SaaS 帮助文档站的实践是把过去“长 H2 + 段落堆”的结构改成“H2 + 4 到 6 个 H3 + 每个 H3 下短段落”,三个月内被 Passage Ranking 命中的查询数翻了两倍。原因是新结构下每个 H3 都是一个独立可切的小段,能匹配更细的长尾查询。
这条经验后来推广到了几个长文测评站:H 层级深嵌不是 SEO 装饰,是给 Passage Ranking 准备的物理切片网格。H2 是大主题、H3 是延伸点、H4 是更细的并列项;只要内容本身有这个层级,就深嵌;没有层级时不要硬拆装饰性的伪结构。
Passage Ranking 的切片粒度从 GSC Performance 报告能反推——把过去 3 个月命中的“该页有点击但查询词不是核心主题词”的查询拉出来,绝大部分就是 Passage 切片命中的子主题。一篇 8000 字的长文如果 H3 设计得当,Passage Ranking 能在 GSC 里给它额外带来 30 到 60 个不同的子查询命中。这些子查询的点击单独不大,但合起来往往等同于核心词排名再涨 2 到 3 名的总流量。
Passage Ranking 在中文站的命中率比英文站略低,主要原因是中文 H 标题在主题表达上往往不够“独立可读”——很多 H2 写成了引导句而不是承载具体主题。如果你的中文长文 Passage Ranking 命中数很低,回头看一下 H2 文案是不是过于依赖上下文,把每个 H2 改写成“脱离全文也能独立看懂”的状态,命中数通常会有阶梯式提升。
AI 答案引用你的正文,怎么让它带回标题和品牌?
这是 2024-2025 这一年最值钱的页内导航命题——AI Overviews、ChatGPT Search、Perplexity 在引用你的正文段落时,能不能把品牌名、文章标题、作者署名一起带回来,决定了你能不能在 AI 时代积累品牌资产。
归属信号的三件套
观察主流 AI 答案引擎的归属带回机制,发现一套稳定有效的“归属信号三件套”:
| 位置 | 结构 | 归属作用 |
|---|---|---|
| 被引段前 | H3 标题写明主题 | AI 抽取时把 H3 文案作为上下文摘要带回 |
| 被引段内 | strong 标记关键句 | AI 优先选中 strong 句作为引用核心 |
| 被引段后 | cite 或 schema 引用块 | 提供归属信号,AI 答案里带回来源链接 |
三件套的核心立场保哥反复强调:不要把页面内导航当 UX 部件,要当 AI 抽取的“指引器”。每一节内容写完之后回头看一眼,AI 如果抽这段,能不能从结构上读出“这段属于这篇文章的哪个主题、这篇文章是谁写的、原文链接在哪”。读不出就把结构补上。
更细一层的工程实践:每个 H3 节里的第一句话尽量包含 H3 主题的核心词,让这段被切片之后第一句就能“自报家门”。然后在节末用一句话总结性陈述收尾,给 AI 一个明确的结束信号。这种“句首核心词 + 句尾结论”的微结构在 ChatGPT Search 和 Perplexity 的实测里都被验证过——同一段内容做了这套微结构改造后,被引用时带回上下文的比例显著提升。
还有一种结构是FAQ 块附在每个 H2 章节末尾而不是统一放在文章最后。一个跨境消费电子评测站做过 A/B 测试,把所有问题统一放在文末的版本与按章节分布的版本对比,章节末 FAQ 版本被 AI 抽取作为答案候选的概率高约 45%。原因是 AI 抽 FAQ 时上下文越短匹配越精准,文末统一 FAQ 离 H2 章节内容太远,关联度被削弱。
Schema 与 entity 关联的额外保障
在归属三件套之外,整页用 schema.org 的 Article 或 BlogPosting 标记完整 metadata(headline、author、datePublished、publisher、image、url),并在 author 里关联到一个 sameAs 的 entity 节点(个人维基、LinkedIn、公开档案)。这一套 schema 不是给搜索引擎看排名用,是给 AI 答案抽取时识别“这段话的归属在哪里”用。
实测下来,齐备 schema 的页面被 AI 引用时带回标题和作者署名的比例显著高于无 schema 的页面。这条与精选摘要丢失机制与 AI 时代价值重估那篇讲的方向一致——精选摘要的丢失和 AI 引用的归属丢失是同一组结构信号在两个机制下的两种表现。
移动端的页面内导航有哪些反模式必避?
移动端是页内导航最容易出错的设备维度,因为屏幕小、手指点击精度低、视口受 sticky 元素影响大。下面这些反模式见到一个就要立刻改。
Page Layout 算法的像素阈值
Google 的 Page Layout 算法对“首屏被 sticky 元素遮挡比例”有明确阈值:
- 遮挡比例 <15%——安全区,不触发任何降权。
- 遮挡比例 15% 到 30%——警戒区,开始扣分但不严重。
- 遮挡比例 >30%——降权区,触发 Page Layout 降权,连带影响该页和站点级评分。
移动端 viewport 通常是 375×667 像素,可视面积约 25 万像素。30% 阈值意味着 sticky 元素总像素面积超过 7.5 万就开始扣分——只要一个常驻的页内 TOC 加上顶部 header,很容易就过线。移动端 sticky TOC 默认必须折叠,不折叠就违规。
折叠交互与可访问性
移动端折叠 TOC 的交互细节也要做对:
- 折叠按钮要有清晰的可点击区域(≥44×44 像素,符合 WCAG 2.1 触控目标尺寸要求)。
- 展开层要做 aria-expanded、aria-controls 等无障碍标签,让屏幕阅读器能正确读出当前状态。
- 展开后的遮罩层要支持点击空白处或下拉关闭,不能强制用户必须找按钮。
- 展开层要禁用背景滚动(body overflow hidden),关闭时恢复,避免触摸冲突。
这套移动端规范不光是 SEO 要求,也是 Web 可访问性的基本面。一个 B2B 工业自动化客户最初的折叠 TOC 没做 aria 标签,被一家欧盟客户的合规审计标红,差点丢掉订单。可访问性看似是边缘话题,实际是国际 B2B 业务的硬门槛。
页面内导航做完怎么衡量是否生效?
所有工程改动最后都要有衡量。页内导航的衡量指标分为四层,分别对应搜索、UX、AI、行为四个维度。
四层指标衡量看板
| 衡量维度 | 指标 | 数据源 | 合格阈值 |
|---|---|---|---|
| 搜索层 | sitelinks fragment 触发率 | GSC 搜索结果监控 | 长文页面 ≥20% 出现率 |
| 搜索层 | Passage Ranking 命中查询数 | GSC Performance 查询 | 同比 +30% 以上 |
| UX 层 | 滚动深度中位数 | GA4 自定义事件 | 长文 ≥75% |
| UX 层 | TOC 点击率 | GA4 自定义事件 | ≥10% 文章访问者点了至少一次 |
| AI 层 | AI 引用回链率 | 自建提示词探针 | 引用次数中 ≥30% 带回品牌或链接 |
| AI 层 | AI 摘要含品牌名比例 | 探针监测 | 引用上下文 ≥40% 提品牌 |
| 行为层 | 页面停留时间中位数 | GA4 | 长文 ≥4 分钟 |
| 行为层 | 跳出率 | GA4 | ≤40% |
保哥的做法是把这八个指标做成一个站级看板,每月对账一次。某一行掉下阈值时先排查导航工程的对应模块是不是有回归(改版、新插件、A/B 测试影响),再定位是单页问题还是站级问题。这套衡量结构跑半年以上,能稳定看出页内导航工程的真实价值。
站级看板上线后还要做一件事——建一组“对照基线页”。挑 10 到 20 个没有做页内导航工程改造的旧页面作为对照组,与改造后的新页持续对照三到六个月。这样既能排除站点级算法波动的影响,又能给团队拿到内部 PRD 评审时一个无争议的证据链。改造后的页面比对照组在 sitelinks fragment 出现率、Passage 命中数、AI 引用回链率三项上稳定高出 30% 以上,这套工程就值得继续扩展到全站。如果差距不显著,说明改造方案某一环没做对,要回去看是命名规范、sticky 折叠、归属信号哪一项失守。
页内导航工程的衡量周期比一般 SEO 改动要长——sitelinks fragment 出现要 2 到 4 周、Passage 命中变化要 1 到 2 个月、AI 引用回链率稳定要 2 到 3 个月。短期看不到变化不要轻易回滚,确认工程实现都做对之后给数据时间累积。这一点跟传统 SEO 的“改完一周看排名”完全不同,要提前给团队和老板做好预期管理。
关于这套页内导航工程在更广的内容差异化语境下的作用,与信息增益与内容差异化机制那篇讲的是同一个方向——结构是承载信息增益的物理介质,没有清晰的结构再独到的内容也很难被识别。两篇配合看,能形成“先用信息增益做内容、再用导航工程做承载”的完整链路。完整工程做下来一般要 2 到 3 个迭代周期才稳定,期间团队要保持节奏不放弃,结果通常对得起这份耐心。
常见问题解答
文章目录到底要不要挂在长文顶部?
看长度和阅读路径。≥3000 字、≥5 个 H2 的长文必挂;2000 到 3000 字、≥3 个 H2 选择性挂;2000 字以下不需要。挂的位置是 TLDR 段之后、第一个 H2 之前,桌面端常驻、移动端默认折叠点击展开。挂错位置等于没挂。
锚 ID 怎么命名才不会重复或冲突?
用核心关键词的英文 kebab-case,加章节序号前缀防重。同一篇里所有锚 ID 全小写、纯英文字母数字和短横线,禁中文和空格。跨站使用要在 ID 前加一个站级命名空间前缀,避免与第三方组件库(评论、社交分享)的内置 ID 撞车。
scroll-spy 高亮当前章节对 SEO 有用吗?
对自然结果排名几乎没直接影响,但对停留时间、滚动深度、点击深度三个行为信号有显著拉升,这些信号又会影响 RankBrain 等用户体验排名因子。间接收益明显,配合 sticky TOC 一起做效果最好。
片段索引 sitelinks fragment 和 Passage Ranking 是同一回事吗?
不是。sitelinks fragment 是 SERP 上你的搜索结果下方多出来的二级跳转链接,把用户直接送到锚点;Passage Ranking 是 Google 把长文里的某一段独立排进 SERP 当作单一相关结果。前者依赖你显式埋好的锚 ID,后者依赖语义化 HTML 让算法自动切片,两个机制独立运作但都受益于页内导航工程。
AI 答案引用你的正文一段,怎么让它带回标题和品牌?
在被引用段的上下文里塞结构化的归属信号:段前用 H3 写明清晰主题、段内用 strong 标记关键句、段后跟 cite 或带 schema 的引用块、整段在 main 内嵌 article。这套结构 AI 抽取时更可能把完整上下文带回,而不是孤立摘出一句没出处。
移动端 sticky 目录会不会被 Google 当成插页打分?
按目前 Page Layout 算法,sticky 元素如果遮挡首屏内容超过 30% 像素面积会触发降权。安全做法是默认收起成一个汉堡或浮动按钮,点击才展开,展开层做半透明遮罩不挡正文。这一类设计已经在多家长文站验证过,没有被算法判定为干扰。
TOC 工程化后 SERP 上 sitelinks 二级跳转什么时候出现?
Google 自动生成,没有显式开关,但有几个前置条件:长文要有清晰的 H2 结构、锚 ID 命名稳定且语义化、页面要在前 3 名长期稳定。具备这几个条件后通常 2 到 4 周自然出现;如果一直不出,多半是 H2 文案对查询意图覆盖不到位,跟 TOC 工程无关。
权威参考资料
本文标题:《文章目录怎么挂锚点,才能被搜索和AI抓成段落直达》
本文链接:https://zhangwenbao.com/in-page-navigation-engineering-toc-anchor-fragment-passage.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0