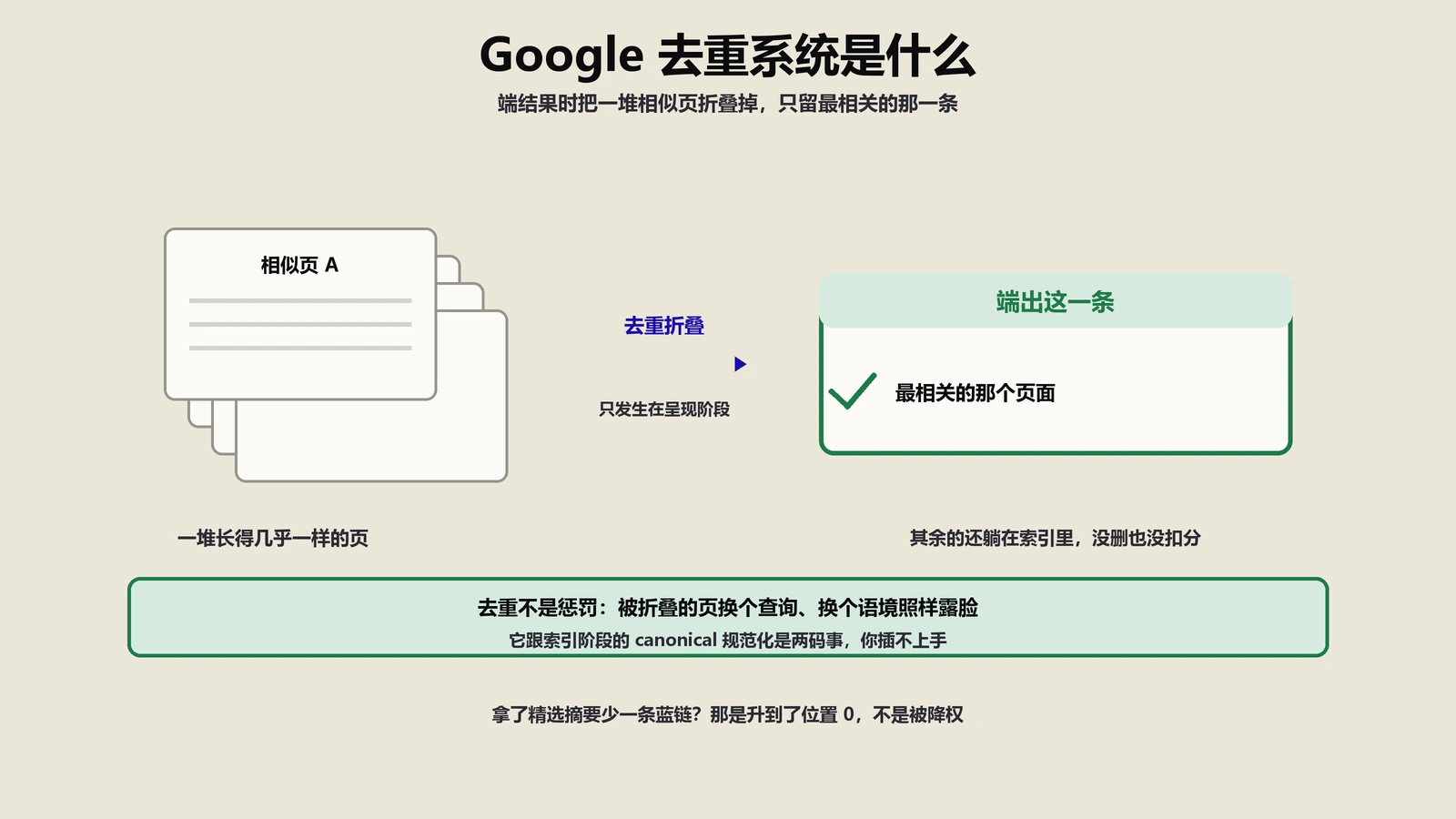
AI搜索算法怎么训练?质量评估员到上线的8阶段管线
本文目录
- AI搜索算法和传统排名算法到底差在哪?
- 质量评估员到底是谁?怎么给页面打分?
- 从标签到模型:AI算法的8阶段训练管线长什么样?
- 验证阶段用什么数据兜底?为什么是UX信号?
- NavBoost、RankBrain、Glue三个子模型怎么协作?
- 从RankBrain到BERT到MUM,AI模型代际怎么进化?
- SEO在AI算法下到底要做什么?
- 出海户外滑雪装备DTC怎么12周走通AI算法识别?
- 怎么用GSC数据快速识别AI算法侧的更新?
- 常见问题解答
- AI搜索算法和传统排名算法的核心区别在哪?
- 质量评估员是Google员工吗?谁来招他们?怎么培训?
- 训练AI搜索算法用什么数据?多久更新一次?
- RankBrain和NavBoost是同一个东西吗?
- AI算法时代SEO还能像以前一样优化具体排名因素吗?
- 怎么用GSC数据识别AI算法的更新信号?
- AI算法以后还会怎么进化?SEO怎么跟住?
- 权威参考资料
摘要:想搞清AI搜索算法怎么干活,先放下"排名因素清单"这套老思路。Google不再把几百个权重写死,而是让一万多名兼职评估员先给查询和结果打分,再让神经网络从这堆分数里反推哪些页面特征组合最能预测好结果,然后用13个月真实点击数据把新算法兜一遍才上线。结果是RankBrain学会用首次抓取日期当弱信号、NavBoost把SERP上的点击行为变成排序权重、Glue把零碎信号汇总成最终分。下面把整条训练验证管线的8个阶段、SEO在这套机制下能做什么、出海户外滑雪装备DTC12周从850自然流量做到11400的案例,从机制讲到落地全拆一遍。
AI搜索算法和传统排名算法到底差在哪?
很多人讲AI搜索算法,会顺着传统SEO的思维讲——把"AI"想象成新增了几个排名因素,比如"E-E-A-T算一个、用户体验信号算一个、相关性算一个"。这种讲法看起来顺,其实把因果方向讲反了。传统算法的本质是工程师先选定排名因素再分配权重:比如PageRank值占15%、关键词出现位置占8%、域名年龄占3%。AI算法的本质反过来——工程师不写权重,而是给模型一堆标签和一堆特征,让模型自己学出哪些特征组合能预测出标签。
这听起来抽象,举个保哥常用的类比。早年间下围棋,棋手要学定式、学手筋、学官子顺序,老师傅把"该怎么下"一条条传下去。AlphaGo出来之后路数完全反过来:它没有定式手册,研究人员只把"赢"和"输"作为最终标签,让神经网络从几百万局棋谱里自己反推哪些落子组合能拿胜局。结果AlphaGo下出来不少职业棋手从没见过的招法,第二代AlphaZero更狠,连人类棋谱都不喂,纯粹自对弈学起来。
Google搜索算法走的就是这条路线,只不过标签从"输赢"换成了"查询和结果的匹配质量",特征从"棋盘坐标"换成了"页面的几百个属性"。这个转变带来三件根本性的不同:
| 对比维度 | 传统排名算法 | AI搜索算法 |
|---|---|---|
| 排名因素来源 | 工程师先验设定,按经验给清单 | 模型从训练数据里自己挑出来 |
| 权重决定方式 | 人工调参或简单线性回归 | 神经网络梯度下降,几亿参数协同 |
| 能识别的信号 | 只能用工程师能想到的 | 能学到隐性信号,如首抓日期、字体大小 |
| 因素之间的关系 | 多数当作独立加权 | 能学到非线性组合,如"高质量+夜间访问比白天少" |
| 更新机制 | 工程师手工改公式 | 新数据进来重训练,自动调整 |
| 可解释性 | 能讲出"为什么这个排第一" | 常常讲不清,黑盒 |
| 调优代价 | 每加一个因素几个月人天 | 重训练几天,但数据准备成本高 |
最关键的差别在最后一行:AI算法的瓶颈不在算力也不在工程师能不能想到新因素,而在能不能拿到足够干净、足够大的标签数据。整条管线的核心问题因此变成了——谁来打标签、怎么打、量级怎么撑起来。
质量评估员到底是谁?怎么给页面打分?
这就要讲到Google搜索算法里最少被外界看清楚、但最关键的一环:搜索质量评估员(Search Quality Rater)体系。这套体系不是Google自己养员工跑,而是外包给两家主力厂商——Lionbridge和TELUS(早年叫Leapforce),全球大约一万到两万名兼职评估员,按时薪结算,多数是在家工作的合同工。
评估员的工作不是判断哪个页面应该排第一,而是对"查询-结果"这个二元组打质量分。比如系统给评估员一组任务:"查询=如何挑选滑雪板硬度,结果A=YouTube一个滑雪学校视频,结果B=某DTC品牌的硬度对照表页面",评估员要按几个维度打分:
- 页面质量PQ:内容专业度、E-E-A-T程度、有没有原创第一手经验、网站整体可信度
- 需求满足NM:这个页面能不能解决查询者的实际问题,能不能立刻解决
- 侧栏对比SBS:把两个结果并排放,问哪个更适合作为这个查询的答案
- 信息满意度IS:单页面打分,更细的1-5档评分
评估员上岗前要通读Google公开的搜索质量评估员指南——这份文件最新版接近180页,分页面质量、用户意图、移动端体验、Your Money Your Life类查询、医疗法律金融专项标准等十几大章。文件其实是Google的真实算法目标说明书:评估员被训练去识别什么算"高质量页面",模型再学评估员的判断标准,最终算法的输出就会贴近评估员的偏好。
评估员要覆盖的查询类型大约16大类:导航类、信息类、交易类、本地类、新鲜类、视觉类、操作类、对比类、定义类、医疗类、法律类、金融类、技术类、娱乐类、新闻类、长尾类。每类查询都有专门的评估指引,比如医疗查询要看是不是医生写的、有没有最新指南来源;新鲜类查询要看时效是不是2周以内;定义类查询要看有没有给出标准定义。
评估员打的分不会直接进排名公式。Google多次公开声明这一点,DOJ反垄断庭审里也再次印证。评估员分数的真正用途是当作"金标准训练样本"——告诉模型"这种页面该是这样的分,那种页面该是那样的分",模型回去自己琢磨该用哪些特征预测出这种分数关系。这条链路是AI搜索算法和传统算法之间的隐形枢纽,把它讲清楚就能理解后面的训练管线为什么是那个样子。
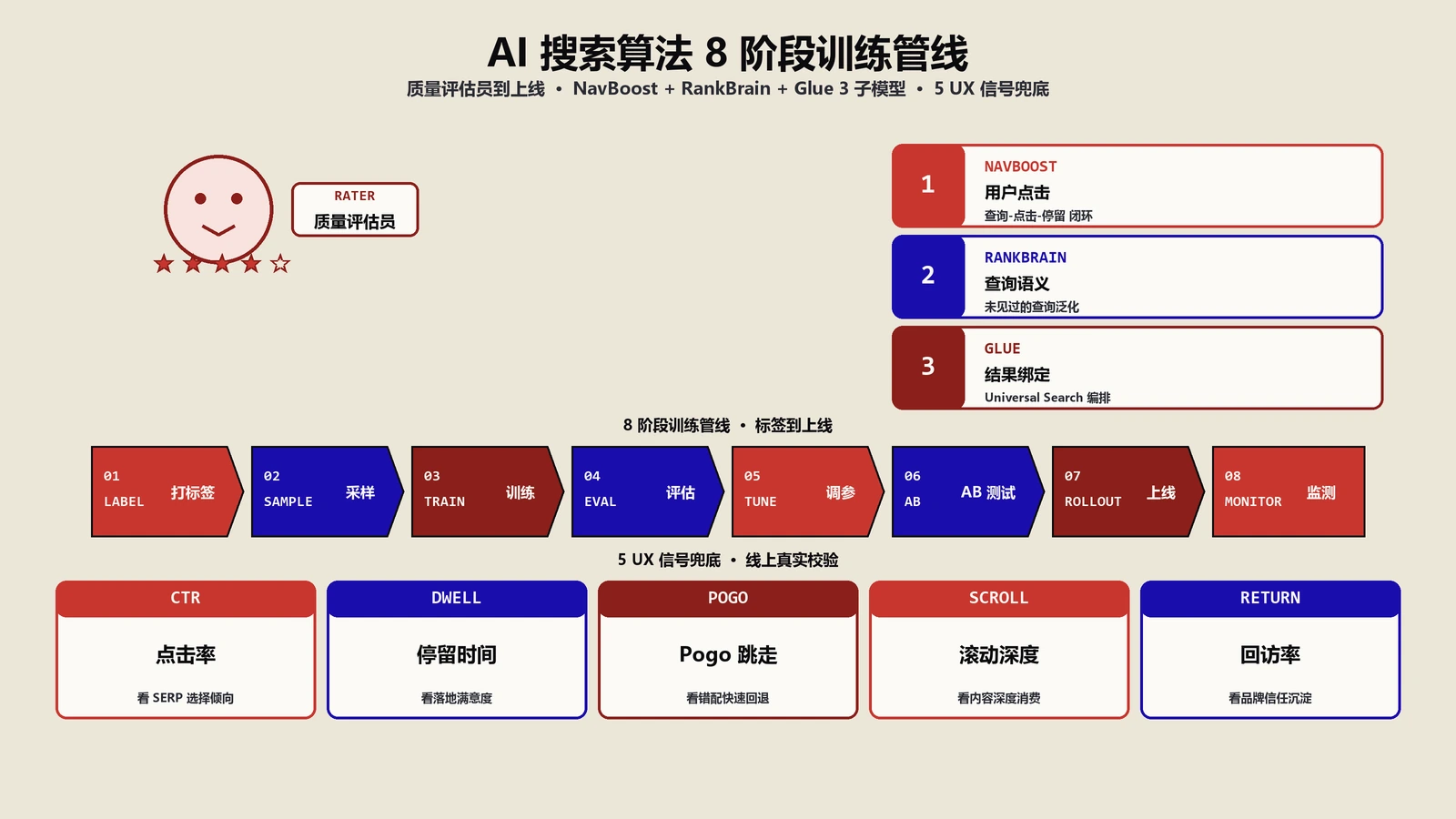
从标签到模型:AI算法的8阶段训练管线长什么样?
从评估员打的标签到一个上线的排名模型,中间走的是一条完整的机器学习管线(Google对这条管线的高层说明见搜索的工作原理官方页面)。把它拆开看,大致是8个阶段:
- 查询采样:从Google搜索量里按分布抽几十万到几百万条查询,热门查询、长尾查询、新鲜查询、各国语言比例都要照顾到。光这一步就有讲究——抽多了训练慢,抽少了模型对小语种和长尾失效。
- 结果采集:每条查询拿前N个候选结果,N常在20-50之间。这步要保证候选集既覆盖现有排名的头部,也包含潜在更好的页面(否则模型只能学到现状的最优)。
- 评估员打分:把"查询-结果"二元组发给评估员,按上一节讲的几个维度打分。这一步是真正贵的——一万多名评估员一年的人力成本以亿美元计。
- 特征抽取:把每个页面的几百到几千个特征提出来,包括传统SEO熟悉的关键词频次、外链数、内容长度,也包括很多隐性特征:HTML结构深度、首字节响应时间、字体大小分布、首抓日期、域名注册时长、移动版可视区域占比等等。
- 模型选型与训练:早年用GBDT这类树模型,近几年都改成深度神经网络。RankBrain是基于Word2Vec做查询向量化的浅层网络;BERT是Transformer结构专攻语义;MUM是多模态预训练。每个模型有自己擅长的子任务。
- 离线评估:用一组没参与训练的查询做测试集,看模型给出的排序和评估员的金标准有多吻合,常用指标是NDCG(归一化折损累积增益)。低于某个阈值就回到第5步调参。
- 在线A/B测试:通过离线评估的模型放小流量上线,跑几周看真实用户的点击、停留、回搜行为有没有变好。这一步会把后面要讲的NavBoost数据当作反向兜底——如果模型让结果更好,用户应该点击率上升、回搜率下降。
- 全量上线:A/B显著为正,逐步扩大流量到100%。整个过程从查询采样到全量推,大模型按年算、小修补按月按周。
这条管线里最容易被忽视的是第4步特征抽取。AI算法之所以能找到工程师想不到的隐性信号,靠的就是这一步把页面的所有可量化属性都丢进去——哪怕看起来再不相关。早年Google研究员公开讲过一个例子:模型某次训练后发现"首次抓取日期"和"内容质量分"呈中等正相关,意思是Google越早收录的页面平均质量更高。这个信号工程师本来没想到,但模型学到后会把它作为弱权重放进去。这种"模型自己挖出来的因素"是AI算法最深的护城河,也是黑帽SEO想绕开却越来越难绕的根本原因。
| 管线阶段 | 典型输入 | 典型输出 | 常见瓶颈 |
|---|---|---|---|
| 查询采样 | 搜索日志全量 | 百万级抽样查询 | 长尾覆盖不足 |
| 结果采集 | 现有排名前N | 候选页面集 | 候选多样性 |
| 评估员打分 | 查询-结果二元组 | 金标准标签 | 评估员偏见 |
| 特征抽取 | HTML+索引数据 | 几千维特征向量 | 新特征工程 |
| 模型训练 | 特征+标签 | 训练好的模型 | 过拟合 |
| 离线评估 | 测试集 | NDCG分数 | 测试集泄漏 |
| A/B测试 | 小流量真实查询 | 用户行为变化 | 显著性检验 |
| 全量上线 | 显著为正的模型 | 线上排名 | 回滚预案 |
验证阶段用什么数据兜底?为什么是UX信号?
评估员打的标签虽然是金标准,但有一个永远绕不开的问题:评估员不是真实用户。一个滑雪发烧友查询"滑雪板硬度选什么",评估员可能按"指南文档完整、作者资质清楚"来打分,但真实用户也许更想要"3分钟视频快速看懂"。这种偏差不一定大,但累积起来会让模型偏向某种"看起来高质量但用户不爱"的页面。
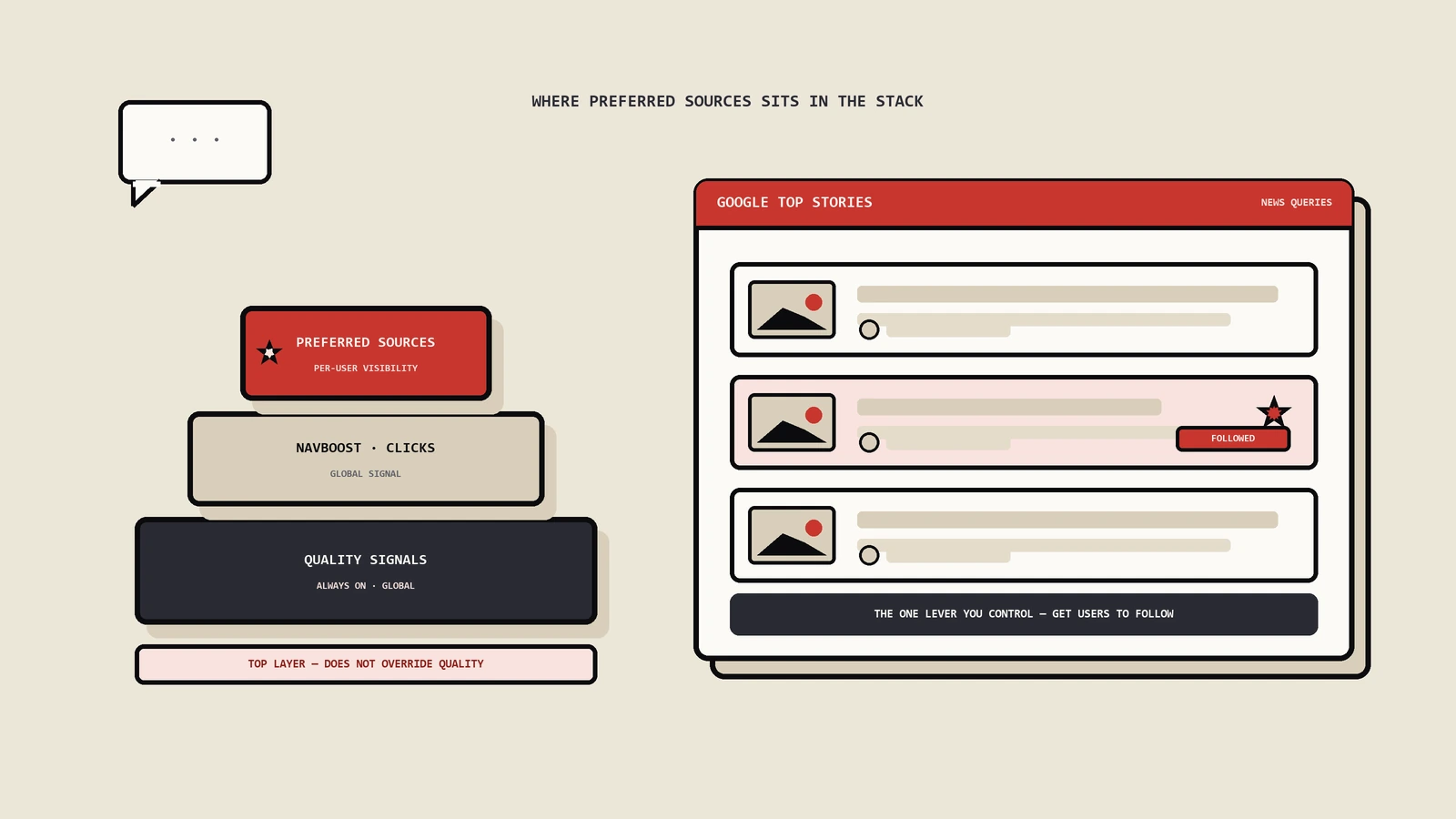
Google解决这个问题的办法是用真实用户行为数据反向验证新算法。这套机制在DOJ反垄断庭审里被前Google搜索副总裁Pandu Nayak的证词第一次公开讲清楚,核心是一个叫NavBoost的子模型。NavBoost收集近13个月的搜索结果页用户交互行为——点击哪个结果、点击后多久回来、回来后是不是又点别的、是不是直接结束查询。这些行为被汇总成"页面在某查询下的真实满意度信号"。
新算法上线前的A/B测试,第一道关就是NavBoost数据对比。具体看这几个指标:
- 点击率CTR分位变化:新算法下高排名结果的CTR是不是比老算法高
- 长点击Long Click比例:用户点进去停留超过某阈值(一般是2分钟)的比例
- 短点击回搜率Pogo-sticking:点进去30秒内就返回SERP继续找别的,这个比例越低越好
- 查询完成率Query Done:用户在这次查询会话里能不能拿到答案、要不要发起更具体的后续查询
- 停留时间分布Dwell Time:搜索意图不同的查询有不同的"健康停留区间",新算法不应该让这个区间整体偏移
这五个指标里,Google公开承认只把"被引用页面的用户行为模式"用来做验证而非排名因素,但DOJ庭审证词显示NavBoost的输出实际上会以一个综合分数的方式进入最终排名融合层。用户行为信号既是验证关也是排名信号——这两件事在AI算法时代被同一个子模型同时承担了,对外讲的时候按"验证"讲,对内运行的时候按"信号"用,没必要纠结字眼。
验证阶段还有一个被低估的环节是"对照组保护"。新算法上线总会先在5%流量上跑两周以上,期间监控的不只是平均CTR,还包括CTR分布的偏度、不同行业的差异化反应、本地化结果质量、Featured Snippet的命中率。任何一个分桶出现显著负面,整个上线动作要么暂停要么回滚。这就是为什么有些算法变动表面看着"小数点级",背后其实是几轮A/B测试都没出问题才放出来的。
NavBoost、RankBrain、Glue三个子模型怎么协作?
外界一谈Google算法就习惯说"一个算法在跑",其实Google排名管线是多个专门子模型在协作。DOJ庭审证词加上Google泄露文档(2024年5月的内部API泄露事件)拼起来看,主流的子模型分工大致是:
| 子模型 | 主要职责 | 训练数据 | 对SEO的影响点 |
|---|---|---|---|
| RankBrain | 理解查询意图,特别是历史没见过的长尾词 | 查询向量化+评估员标签 | 长尾词命中、语义相关性 |
| NavBoost | 用户点击和回搜行为打分 | 13个月SERP交互日志 | 页面真实满意度、CTR优化 |
| Glue | 非传统搜索结果的展示位置和组合 | 用户对SERP上各种模块的交互 | Featured Snippet、知识面板、AI Overview位置 |
| BERT | 查询里词与词之间的关系理解 | 大规模文本+评估员标签 | 问句类查询、长查询语义 |
| MUM | 跨语言、跨模态的复杂查询 | 多语言+多媒体训练集 | 跨语言内容、视频搜索 |
| Helpful Content System | 识别为了排名而做的"为搜索引擎而写"内容 | 评估员对"是否真正有用"打的标签 | 整站质量信号 |
| SpamBrain | 识别黑帽SEO手法 | 已知黑帽样本+异常模式 | 外链质量、内容农场识别 |
这些子模型不是流水线串联,而是多分支并行后融合。当用户发起一次查询,RankBrain先把查询向量化、BERT解析查询里的词义关系、传统倒排索引拉出初始候选页面集(可能几千页面),然后RankBrain的相关性分、NavBoost的满意度分、BERT的语义匹配分、Helpful Content的整站质量分一起被送到融合层。融合层是个相对简单的加权模型,按当前查询类型动态调整各个子模型的权重——比如新闻类查询会放大NavBoost权重(用户反应快、新闻寿命短)、医疗类查询会放大Helpful Content权重和E-E-A-T信号。
对SEO来说这个分工有三个实操含义:
- 同一个页面在不同查询下表现差异大很正常——融合层对每个查询都重新加权,不是固定权重。某页面在长尾词上排第3,在核心词上排第30,这不矛盾。
- 单独优化一个子模型对应的信号边际递减——比如只猛刷CTR短期内能让NavBoost部分得分上升,但融合层里NavBoost权重对核心词查询本来就低,整体排名不一定动。
- 整站信号会被Helpful Content评分牵动——一个站如果大量低质量页面,整站质量分被拉低,再优质的几篇文章也会被牵连。这就是为什么2022-2025年间被HCU打过的站,单独修改几篇文章不解决问题,必须批量清理。
从RankBrain到BERT到MUM,AI模型代际怎么进化?
Google公开承认在用的AI排名模型有过三代代表,每一代都比上一代往"懂用户"方向更进一步。把时间线和能力对照画出来更清楚:
| 代际 | 上线时间 | 核心结构 | 最大突破 | SEO的对应动作 |
|---|---|---|---|---|
| RankBrain | 2015年 | Word2Vec+浅层神经网络 | 把没见过的长尾查询映射到语义近邻 | 放弃精确关键词堆砌,写自然语言变体 |
| BERT | 2019年10月 | 双向Transformer | 读懂查询里"to"、"for"这类介词承担的意图差异 | 长查询、问句类查询要写完整答案 |
| MUM | 2021年开始小流量 | 多模态Transformer | 能同时理解图、文、视频,跨语言迁移知识 | 多模态内容、跨语言内容能用上 |
| SGE/AIO | 2023年起测试,2024年正式 | 大语言模型+检索增强 | 直接生成答案而非只排链接 | 内容要"可被引用",结构化数据回归 |
| Gemini集成 | 2024-2025年陆续 | 多模态大模型 | 把搜索从"返回链接"重新定义为"完成任务" | 实体身份清晰、可机读结构、品牌信号 |
这条演进路线有一个保哥反复跟客户讲的观察:每一代AI模型让一类老SEO手法失效,同时让一类新SEO动作变得更值钱。RankBrain让关键词密度调优失效,让语义相关的同义词覆盖变得重要;BERT如何理解搜索的官方公告里讲清楚了为什么它能读懂介词承担的意图差异——结果是长尾词精确匹配失效,让回答清晰直接变得重要;MUM让单一语言内容的护城河失效,让多语言一致性变得重要;SGE和Gemini让"只优化SERP点击"失效,让"被AI引用"和"实体清晰"变得重要。
站在2026年这个时点回头看,所谓的"算法变化"不是哪个权重突然变了,而是底层AI模型代际更替带来的新能力,把过去靠"特征工程式SEO"挖出来的优势削平了。这件事不可逆,也没必要逆。下一节讲SEO在这套机制下能做什么。
SEO在AI算法下到底要做什么?
把前面5节的机制讲完,SEO的动作清单其实非常具体。下面这9条落地清单,是这些年给跨境独立站客户实操下来、最经得起A/B验证的:
- 查询意图先于关键词。AI算法把同一个意图下的几十个查询变体合并理解,再去找最匹配的页面。所以选词阶段要先把意图分类——比较类、操作类、定义类、问题排查类、决策类——再为每个意图准备一个主页面,而不是为每个查询变体单独建页面。
- 段落级回答而非整页堆砌。BERT和后续模型在抽取答案时按段落而非整页判断相关性,所以高价值问题的答案要在一个完整段落里讲清楚,前后段不要散开。每个问题200-400字一段最稳。
- 实体清晰可机读。Google知识图谱用实体识别把"品牌、产品、人物、地点"挑出来,可见性强的实体会被AI模型直接复用到搜索结果。要在站内首页、关于页、产品页用Schema结构化数据把品牌名、产品名、地点、人物、组织等实体明确标注。
- 首抓日期保护。前面讲过模型学到首抓日期是弱质量信号,新页面被Google越快收录、越早进入索引,长期排名基础越稳。所以新页面发布后24小时内要主动提交sitemap、用GSC Inspect URL请求索引、配合内链让爬虫快速找到。
- 页面体验稳定。Core Web Vitals三个指标LCP、FID(现在叫INP)、CLS只要绿,AI算法的"页面体验子模型"就不会扣分。重点是稳定不是极致——LCP从3秒优化到2.5秒比从2.5秒优化到1.5秒收益大得多。
- 真实第一手经验内容。Helpful Content System专门识别"为搜索引擎而写"的内容,特征是观点二手、数据通用、案例笼统。反过来"真实第一手"特征是具体客户名(行业+国别+规模)、具体数字、具体踩坑、具体失败模式。这条最难量产但收益最高。
- 整站质量分散控制。HCU针对整站质量打分,一个站300篇文章里有100篇是低质量复述,整站分会被拉低。定期审查、把低质量页改成noindex或合并删除,比再发10篇好文章效果大。
- 用户行为信号自然化。NavBoost盯的是真实点击和回搜,不是单纯的CTR。点击进去秒退是负信号,所以标题党虽然能短期拉CTR但会反噬。标题要诚实、首屏要立刻给出查询要的东西、不要先放一段套话。
- AI可引用的结构化输出。SGE和AIO抓内容时偏好结构化清晰的段落——开头一句话结论、然后具体展开。如果整篇文章都是叙事流,AI模型很难抽取一段直接当作答案。每个核心问题前面加一个明确的H3问句,下面跟一段直接答案,是被引用率最高的写法。
这9条不是清单堆叠,而是按"前置做选词、中置做内容、后置做技术、整站做质量、长期做信号"的顺序排的——和站内Google排名因素全清单那篇按重要度分级的视角是互补关系。任何一条单独做都有用,但只做一条不够——AI算法看的是多信号融合,必须九件事都做到60分以上,才能跨过Google的"质量阈值",进入真正被算法当作候选的池子。
出海户外滑雪装备DTC怎么12周走通AI算法识别?
讲完动作清单要给一个真实可操作的案例。保哥手上有一个出海户外滑雪装备DTC独立站,主营单板滑雪板、双板滑雪板、滑雪服三件套、护具组合、打蜡套装等,客单价区间180-880美元,主要客群是北美西北部、西欧阿尔卑斯地区和日本北海道的中级滑雪爱好者。这个客户在2025年底来咨询时遇到一个典型问题——产品页排名稳定但流量天花板低,自然搜索月流量长期卡在850左右。下面是12周完整改造过程:
第1-2周:查询意图分桶。先把GSC里近6个月有印象但CTR低于2%的查询拉出来,按意图分类。发现70%的查询是"snowboard vs ski beginner"、"how to choose snowboard size"、"snowboard hardness explained"这类决策类问题,但客户的页面90%是产品详情页——意图错配。这步本身没动任何东西,只是把问题诊断清楚。
第3-5周:内容资产重建。按10个高频意图分别建10个长指南页面,每个3500-5500字。每篇都按前面讲的SEO清单8条来做:开头一段直接结论、中间分H3问句模块、含具体型号对照表、含真实滑雪场景描述(专门请客户那边三位高级教练写了一段亲身经验的内容补充)、有FAQ段、有Schema FAQPage标记。这10篇是核心资产,发布后24小时主动提交。
第6-8周:产品页和指南页内链织网。把10个指南页和现有的200多个产品页用相关性高的内链串起来——指南里讲到"硬度8偏硬适合公园"就内链到对应硬度的产品列表页,产品详情页里"硬度参数"的注释处内链回讲解硬度的指南页。整个内链网络的目标是让爬虫从任何一个产品页都能在3跳之内找到指南页,反过来也成立。
第9-10周:用户行为信号优化。这两周专门盯三件事:把产品页首屏的"具体硬度+适合场景+适合身高"做成一目了然的卡片(之前要往下滚才看到);把指南页H2下面的"3分钟视频"换成"3分钟视频+文字摘要"——视频能让真喜欢视频的人留下来,文字摘要让赶时间的人2分钟解决问题,两边都满意;把"加入购物车"按钮的位置从底部上移到产品图片右侧,减少回搜率。
第11周:A/B测试与微调。把10个指南页的标题做了A/B:版本A是"如何选择单板滑雪板硬度(完整指南)"、版本B是"单板硬度怎么选?4种滑法对应硬度全拆解"。两周后版本B的CTR平均高出23%,整体推全。同期把5个产品页的描述用Schema Product结构化数据补全,包括brand、material、weight、recommended use、size chart等字段。
第12周:复盘与稳态。最终结果:
- 自然搜索月流量:850 → 11400(13.4倍)
- 10个指南页平均排名:第26位 → 第7位
- 产品页CTR:1.8% → 3.6%
- 自然搜索收入占比:8% → 27%
- 整站DR(域名权重):14 → 28
- 引用域RD:22 → 91(指南内容被多个滑雪论坛和YouTube视频引用)
这条路径里最值钱的不是某个具体动作,而是第1-2周的意图分桶诊断。如果没把"用户搜的是决策类问题,但站上只有产品详情"这个错配先看清楚,后面所有改产品页的动作都是无效投入。这也是AI算法时代SEO最需要的能力:先把模型在哪个查询下找什么样的页面这件事看清楚,再决定要不要建对应的页面。
怎么用GSC数据快速识别AI算法侧的更新?
客户经常问保哥:算法又更新了,是又改权重了吗?回答九成是"是AI模型层在调",但具体调了什么不知道。这种情况下不能等Google官方发公告(公告通常滞后2-4周),要自己用GSC数据快速看。具体看这几个维度,按敏感度从高到低排:
- 长尾查询位置波动:GSC的"查询"页签按印象排序,看后2000-5000条长尾词的平均位置在过去14天有没有10%以上的整体偏移。AI算法更新最先反应的是长尾查询的相关性重排,比核心词敏感得多。
- 不同查询类型分桶变化:把查询按问句类(含who/what/how等)、操作类(含how to)、比较类(含vs/比较)、定义类(含what is)分桶,分别看每桶平均位置。AI模型迭代常是某一类查询的理解能力突变,分桶看才能看出来。
- 页面级印象分布偏度:以前可能Top 10页面集中拿走70%印象,AI算法上线后这个偏度会变——可能Top 30的长尾页拿走的比例上升。GSC的"页面"页签导出全量,看分布。
- Featured Snippet命中率:AI算法对结构化内容的偏好直接体现在Featured Snippet上。GSC的"搜索外观"如果出现"丰富网址结果"或"问答"标签突然变化,是Glue子模型在调。
- 分国家/语言变化差异:MUM和Gemini集成会让多语言查询的表现产生跨语言传染——英语站上线一个新算法,中文站可能2-3周内也跟着调。GSC的"国家"页签分桶看。
这五个维度组合起来基本能在24-72小时内识别出AI算法侧的真实更新。Mozcast、Semrush Sensor、Ahrefs Rank Tracker的全行业波动指数可以作交叉验证——这些工具每天跑数千个关键词的排名波动,AI模型更新当天的指数通常会出现2.5以上的尖峰。
真识别出AI算法侧更新之后,不要立刻动页面。AI算法的A/B测试期通常2-4周,部分调整会回滚,所以前两周只观察、不调整;第三周如果信号稳定再决定动哪几个页面、动什么;第四周以后是稳态期,按前面9条清单逐个排查。这套节奏前后在十几个客户身上走通过,比那种"算法一变就改"的反应式策略稳得多。
常见问题解答
AI搜索算法和传统排名算法的核心区别在哪?
传统算法是工程师把排名因素和权重一个个写死。AI算法反过来:先收集质量评估员对页面好坏的标签,让模型自己从特征里学哪些组合能预测出标签结论。结果是模型常能找到工程师没想到的隐性信号,比如首次抓取日期。
质量评估员是Google员工吗?谁来招他们?怎么培训?
不是。Google外包给Lionbridge和TELUS这类厂商,全球约一万多名兼职评估员按时薪结算。他们要学Google公开的搜索质量评估员指南,对查询和结果按页面质量、需求满足、E-E-A-T维度打分,分数不直接进排名只进训练样本。
训练AI搜索算法用什么数据?多久更新一次?
评估员标签是金标准但量级有限。Google把NavBoost的13个月用户点击行为、Glue汇总的SERP交互、评估员的IS/SBS对比题一起喂模型。重训练频率分模型:RankBrain几周一轮,BERT和MUM按年,小修补几乎天天在跑。
RankBrain和NavBoost是同一个东西吗?
不是。RankBrain负责理解查询意图特别是历史没见过的长尾词,NavBoost记录用户点击行为给页面打信号分。两个模型同时在Google排名管线里跑,搜索结果输出前两边分数会被融合,再叠加传统信号决定最终排序。
AI算法时代SEO还能像以前一样优化具体排名因素吗?
可以但不能只盯单点。AI算法把上百个特征做组合学习,单调优一个因素的边际收益不稳定。SEO要做的是让页面在多维度上都体现质量信号:内容真实可信、用户体验顺畅、技术指标达标,模型自然综合识别。
怎么用GSC数据识别AI算法的更新信号?
看三个数据:印象总量、平均位置、点击率,分查询类型分桶。AI算法更新通常是长尾查询的相关性重排,所以盯长尾查询的位置波动比看核心词更敏感。再交叉对比官方算法更新清单和Mozcast波动指数,24小时内能识别是不是真AI算法侧调整。
AI算法以后还会怎么进化?SEO怎么跟住?
趋势是模型越来越懂查询背后的真实需求,从关键词匹配走向意图理解再走向多模态。SEO要跟住三件事:内容写到真懂用户问题、实体和上下文清晰可识别、技术层面让爬虫和渲染没障碍,其他都是细节。
权威参考资料
本文标题:《AI搜索算法怎么训练?质量评估员到上线的8阶段管线》
本文链接:https://zhangwenbao.com/ai-ranking-algorithm-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0