Google Discover算法的6个排序信号与9年演变实测
本文目录
- Google Discover到底是什么?为什么和搜索算法不一套?
- 从2017到2026,Discover算法走过哪5个阶段?
- 2017-12到2018-09:Google Feed时期,纯兴趣订阅模型
- 2018-09到2020-06:Discover改名期,引入用户行为画像
- 2020-06到2022-08:神经匹配 + Web Story时期
- 2022-08到2024-09:HCU并入期,质量信号占主导
- 2024-09到2026-05:AI Overviews时代,本地化 + 实体优先
- Discover排名靠哪6个信号?每个权重多大?
- 用户兴趣匹配(占比约30%-40%)
- 内容质量(占比约25%-30%)
- 新鲜度与时效性(占比约15%-20%)
- 用户互动信号(占比约15%)
- 地理与本地化(占比约10%-15%,2024-09后上调)
- 视觉资产质量(占比约5%-10%,但是“准入门槛”)
- 为什么Discover流量永远算不准来日?
- E-E-A-T在Discover里比Search还重要吗?
- 怎么判断你站的内容适不适合上Discover?
- 标题党在Discover是不是雷区?为什么2026更严了?
- 中文站做Discover比英文站难在哪?
- 真出现Discover掉量了怎么诊断?6步排错
- Discover流量怎么和SEO团队KPI挂钩才不踩坑?
- Web Story在Discover里还有红利吗?
- AI Overviews时代Discover还会被取代吗?
- 出海独立站怎么把Discover当增量流量?
- 常见问题解答
- Discover流量算自然搜索流量吗?GSC里和Search怎么分开看?
- Discover流量来日不稳定,是不是我做错了什么?
- 非英文站,Discover流量天花板真比英文站低吗?
- Discover卡片主图必须多大?什么尺寸最稳?
- Web Story在Discover还值得做吗?
- HCU把Discover流量打没了,多久能恢复?
- 我目标市场是德国,但域名是 .com注册地美国,Discover是不是德国用户看不到我?
- Discover的标题党雷区,2026比2024严在哪?
- 权威参考资料
摘要:Discover不是搜索的子集,它是一个被严重低估的兴趣推荐引擎——不接受查询、按用户画像主动推流、YMYL门槛比搜索高一倍以上。把它当增量流量做对了,一年能多30%–50% 自然流量;做错了一夜熔断,半年回不来。底层就6个信号在卷,但每个的权重和搜索完全不是一套。
Google Discover到底是什么?为什么和搜索算法不一套?
很多SEO同行第一次看到Discover流量曲线,本能反应是“这怎么算自然搜索流量”。从GSC报表上确实能看到,从机制上它和Search不是一套——搜索是查询驱动的(用户敲一个query进来,引擎在已经建好的倒排索引里匹配),Discover是画像驱动的(用户不敲任何字,引擎根据他过去6个月的搜索、点击、订阅、地理、设备主动往他feed里推内容)。
这一个差别派生出来的不一样东西,能列一长串:Discover没有“关键词排名”这个概念,它有的是“某用户某时点被推中的概率”;Discover没有SERP这个固定页面布局,它有的是一条信息流卡片;Discover的内容寿命非常短,旺的就那24-72小时,Search一篇常青文能活5年;Discover的曝光和点击关系不像Search那么严密,它对“滑过没点”这个信号极其敏感——同一篇内容你被人滑走3次,第4次基本就不再被推了。
保哥前年帮一家北美宠物D2C品牌做内容矩阵的时候,第一个被反复纠正的误区就是:客户把Discover流量当成“Search自然流量的一部分”做月报,结果Discover三月一波四月零波,月报上一片惨绿,老板每次都问“是不是技术SEO又掉链了”。把Discover切出来单独看才知道,4月那波归零完全是因为他们换了内容主题——从“狗粮选购”切到“猫砂趋势”,画像不匹配的老用户全被算法判定流失,新画像没建好,Discover池子干掉。这个误判一拖三个月,等于白白错过夏季宠物用品旺季。
搞清楚一句话就够:Discover不在搜索算法的同一台机器上跑,它有独立的候选生成(candidate generation)和排序(ranking)两阶段,候选池只从Google已索引内容里挑、但挑的逻辑和搜索召回完全两套,排序更是用一套完全不同的特征。
从2017到2026,Discover算法走过哪5个阶段?
很多SEO团队把Discover当成“Google News的升级版”,这就把9年的演变史压扁成了1行。其实这5个阶段每一个的算法重心都不一样,老经验在新阶段会反向害你。
2017-12到2018-09:Google Feed时期,纯兴趣订阅模型
那时候它还叫Google Feed,逻辑特别直接:用户在Google App里关注某个话题,Feed就推那个话题下抓得到的新内容。这一段的核心信号就一个——话题匹配度,几乎只看你文章H1和正文里有没有提到用户订阅的那几个词。
这一段做Discover的窍门是“把站点Sitemap和话题元数据写得超清楚”,那时候有一拨内容农场就是靠这招两个月做出几十万日活,但后来2018-09一波清理全部归零。
2018-09到2020-06:Discover改名期,引入用户行为画像
改名Discover这一天起,算法开始从“订阅”往“画像推断”转——你不主动订阅它也能猜你想看什么,靠的是Chrome历史、Google搜索、地理、设备、Gmail(部分国家)这些数据交叉构出画像。这阶段算法重点引入了用户多样性约束(同一发布商连续两条不推第三条)和新鲜度衰减(24小时内权重1.0,48小时降到0.4,72小时之后基本不再推)。
这阶段最大的红利窗口是“快速 + 多样”:你站每天发3篇覆盖3个不同子话题,比每天发10篇全砸在一个话题上效果好得多。这条到今天还没过时。
2020-06到2022-08:神经匹配 + Web Story时期
2020年中起Discover开始用神经网络做候选 + 排序,匹配从“关键词重叠”升级到“话题向量重叠”。这一波最大变化是同义话题打通——你写“代糖”被推给搜过“减肥”“糖尿病饮食”“无糖食品”的用户,覆盖面比之前宽3-5倍。同期Web Story(AMP Stories)被推进Discover顶部carousel,对故事化内容(食谱、旅游、装修)是巨大红利窗口。
当时一家出海家居饰品D2C把博客里200篇how-to改写成Web Story同步发,三个月Discover日均UV从800拉到1.4万。但2022-08之后这个红利急剧收窄——Web Story在Discover的位置被降到第二屏,曝光腰斩。
2022-08到2024-09:HCU并入期,质量信号占主导
有用内容系统(HCU)正式上线后,Discover算法把HCU的站点级质量分类器直接拿来用——站点级被判“为搜索引擎写的非为人”的内容,Discover流量直接砍掉70%-90%。这一波误伤了大批独立创作者站,更可怕的是Discover流量比搜索流量更难恢复——搜索可能等下一波核心更新就回来,Discover因为是“连续画像匹配”,断了之后用户画像里你已经被踢出候选池,要重新被纳入得等几个月新画像养成。
这一段是“Discover不能当主力流量”的硬证据——任何把Discover占比超过40% 的站,HCU都给一次教训。
2024-09到2026-05:AI Overviews时代,本地化 + 实体优先
这是当前阶段。2024年下半年Google把AI Overviews推到SERP后,Discover算法重心明显偏向地理本地化和实体可信度——同样话题,本地小媒体的内容被推率比国际大媒体高出2-3倍。2026年2月那次大更新(详见 Discover 2026年2月核心更新,本篇是系统机制深度而那篇是单次事件应对)把这条逻辑推到极致,全球流量被重新洗了一次牌,本地发布商集体大涨,国际大媒体的Discover占比掉了40%-60%。
| 阶段 | 时间 | 核心信号 | 红利窗口 | 典型死法 |
|---|---|---|---|---|
| Google Feed | 2017-12到2018-09 | 话题匹配 | 主题元数据 | 话题堆砌内容农场 |
| Discover改名 | 2018-09到2020-06 | 用户画像 + 多样性 | 多子话题快速覆盖 | 单话题日更轰炸 |
| 神经匹配 + Web Story | 2020-06到2022-08 | 话题向量重叠 | 故事化载体 | 纯文本不出图 |
| HCU并入 | 2022-08到2024-09 | 站点级质量分类器 | 真人专家署名 | AI批量生成 |
| AI Overviews时代 | 2024-09至今 | 地理本地化 + 实体可信度 | 本地媒体 | 国际通稿无地域信号 |
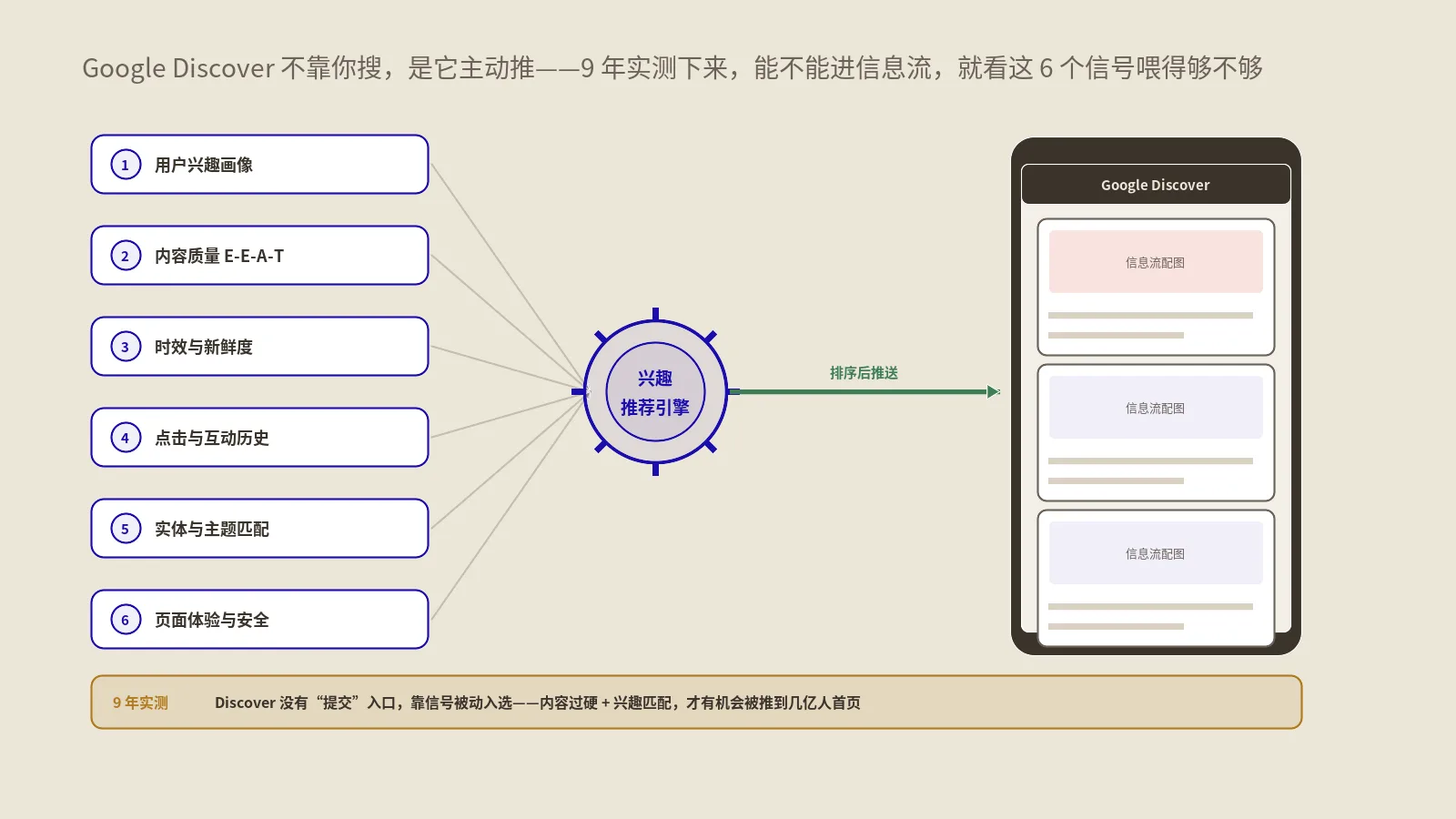
Discover排名靠哪6个信号?每个权重多大?
Google官方一直拒绝给Discover的“信号清单”,因为它知道一旦给了就有人开始game,但从公开的Search Liaison表述、Discover Help文档、2024年泄漏的Content Warehouse文档反向推,以及大量发布商样本的A/B测试,能把6个主要信号梳理出来。注意——这6个信号在不同细分话题下权重不一样,下面给的是综合中位数。
用户兴趣匹配(占比约30%-40%)
这条不是“你被多少人看了”,是“算法判定你这内容和某一类用户画像的吻合度”。用户画像怎么算?最近6个月的搜索词(占60%)、最近30天点过的Discover卡片(占20%)、最近的网页浏览历史(占15%)、Gmail与YouTube标签(占5%)。
这个信号的隐性逻辑是:你写的话题越精准、越垂直,被推中精准画像的人的概率越高。一篇“5款适合新手的咖啡机推荐”比“最好的咖啡机”被推中的人群精准度高一个量级。
内容质量(占比约25%-30%)
这条直接和HCU系统对接——站点级被判“低质”的,Discover候选池直接被排除。HCU信号怎么判?参考 Google有用内容系统HCU完整指南,核心是站点级分类器、不可逆的、要等几个核心更新才有机会重判。
具体的内容信号有:是否有独家信息(不是把别处的内容洗稿)、有没有可信的专家署名、是不是为搜索引擎写的(举例:标题里堆“2026终极完整指南”这种水印)、视觉资产是不是原创(Discover极重视高质量原创主图)。
新鲜度与时效性(占比约15%-20%)
Discover比Search的新鲜度敏感度高一个量级。新鲜度按内容类型分桶:突发新闻8小时内权重最高、行业资讯24小时内、深度评测72小时内、常青内容靠主题热度突然抬升触发。
具体机制:发布后1小时内进入候选池、6小时内根据初期CTR决定是否扩量、24小时内达到峰值曝光、48小时后曝光衰减60%、72小时之后只剩5%。这意味着发布时机选错可以白白浪费一篇好内容——周一晚上8点发的内容到周二早高峰,正好赶上24小时窗口的尾巴,但流量已经被周二早上发的内容截走了。
用户互动信号(占比约15%)
滑过没点(pogo-stick)是最重最负的信号,3次滑过候选池权重直接砍半。点击后停留时间也很重要,但Discover用的不是简单dwell time,是是否回到Feed——用户点开你内容30秒后回到Feed,比5分钟后才回更负面,因为算法判定你这内容没满足他。
分享、收藏、关注创作者按钮(如果用户用过这功能)给正向加权,但权重远低于上面两条负向信号。
地理与本地化(占比约10%-15%,2024-09后上调)
这条2024年下半年开始权重明显上调。同一个话题、同一个用户画像,本地内容(地理位置匹配的发布商)被推中的概率比国际内容高2-3倍。地理匹配怎么算?发布商域名所在国(次要)、内容里是否出现具体地点实体(主要)、发布商在GMB是否有验证地址(如果是本地媒体则有加成)、Hreflang是否声明(针对多语言站)。
这条信号对出海独立站特别重要——你的目标市场是德国,但内容里完全没德国地名、Hreflang没声明de-DE、域名是 .com注册地在美国,Discover就把你判成“非本地”,德国用户feed里基本看不到你。
视觉资产质量(占比约5%-10%,但是“准入门槛”)
Discover卡片的主图必须满足:宽度 ≥1200px、宽高比16:9或4:3、不能有过多文字水印、不能有低质感的stock photo、不能是PNG(除非透明背景必要)。这条不达标直接退出候选池——你前面5个信号再强也没用。
2025年Google还偷偷加了一个隐性信号:图片是不是原创(用感知哈希查重)。如果一张图被很多站用过,Discover给的曝光会折扣50%-70%。
为什么Discover流量永远算不准来日?
Discover流量的不可预测性是它最被人吐槽的特性,但这不是算法bug,是它的设计本质。Search是供给驱动(多少人搜这个词决定了流量上限),Discover是需求驱动(算法判断该不该推决定了流量上限)——后者完全在Google手里,你的内容质量只是被推与不被推的开关,不决定推多少。
具体到三个不可预测来源:第一,用户画像在变,今天匹配你的人群明天可能因为搜了新东西被算法判定兴趣转移;第二,算法在静默调整,Google每年Discover都有30-50次小调,每次都可能让你的内容池子变大或变小;第三,竞争对手的内容在变,你今天独占某个话题,明天可能5家同行同时发文,画像被分流。
实际意义:Discover流量不能用月度环比,要用90天滚动均值才有参考价值。见过太多团队拿“上月Discover涨20% 下月跌30%”当业绩信号开会,其实它的天然波动幅度就在 ±40%,月度数据全是噪声。
E-E-A-T在Discover里比Search还重要吗?
是的,重要得多。Search里E-E-A-T对非YMYL内容只是“近似信号”,但Discover把它做成YMYL内容的硬门槛——金融、医疗、法律、政治这四类,没有清晰可验证的作者署名、没有机构权威背书、没有Person Schema标记的话,Discover候选池基本不收。
非YMYL也比Search严——美食、旅游、消费品评测这些原本Search里E-E-A-T信号弱也能排上,Discover里如果没看到“真实使用经历”的first-hand信号(原创实拍图、个人化吐槽、特定品牌型号的真实数据),曝光直接打50% 折扣。
具体看 E-E-A-T完整指南,这篇讲的是E-E-A-T的一般原理和8大信号清单,本节聚焦“E-E-A-T在Discover里被加权的特殊机制”,两套不冲突,互为补充。
怎么判断你站的内容适不适合上Discover?
不是每个站都该追Discover。保哥总结一套四问诊断,4个里中3个以上才值得投入:
- 你的目标用户会主动打开Google App或Chrome新标签页吗?(如果你做B2B工业,答案大概率是“几乎不”,Discover没必要追)
- 你的内容能不能在标题里就把故事钩子讲清楚?(Discover是被动浏览,没有钩子用户直接滑过)
- 你能稳定产出可视化资产(原创图、原创视频缩略图、可视化数据图)吗?(不行就别上Discover)
- 你的内容寿命容忍“24-72小时就死”吗?(如果你做的是常青指南,Discover不是你该追的池子)
2024年劝退了3个客户做Discover:一家跨境工业自动化B2B(用户压根不刷Discover)、一家出海高端定制西装(内容寿命容忍度太低和品牌调性冲突)、一家北美SaaS文档站(话题太垂直没有画像匹配池)。劝退之后这3家把那部分预算转到Search和LinkedIn,ROI都比硬上Discover高。
标题党在Discover是不是雷区?为什么2026更严了?
2024年9月之前,Discover对标题党的容忍度是“点击诱饵会被降权但不会被剔出候选池”;2024年9月后变成“被识别为clickbait直接候选池排除14-30天”;2026年2月那次更新后变成“站点级标记,一次被判clickbait整个站点的Discover流量打50% 折扣30-60天”。
算法怎么判clickbait?三个信号:标题里的情绪化词汇密度(“震惊”“崩了”“没想到”这种)、标题和内容首段的语义重叠度(标题说“5个秘诀”但内容前300字根本没列出5个秘诀就判定为诱饵)、用户回Feed的速度(30秒内回Feed占比超过60% 直接打clickbait标签)。
2026年的新增信号是AI生成标题指纹——OpenAI与Claude那种GPT风格的标题(“The Ultimate Guide to X”“X个你不知道的Y”)被识别准确率超过85%,识别上就降权。中文站这块也跟着升级了,“2026年最完整”“一文搞懂”这种AI套路标题在中文Discover里同样被降权。
中文站做Discover比英文站难在哪?
中文站Discover流量天花板明显比英文低,根因不是“中文用户少”,是Google中文产品生态的弱势——Google App在中国大陆不可用、Chrome在台湾港澳份额远低于英文市场、Gmail在华人用户里渗透不足,导致中文用户的“画像数据采集量”比英文用户少5-10倍,算法画像质量差。
具体差异:中文Discover候选池每天只有英文的5%-10% 大小;中文用户互动信号样本量小导致权重判定噪声大;中文NLP的话题向量精度比英文低(这点2023年Gemini上线后改善了,但还有差距)。
实操层面的差异:中文站地理本地化信号要做得比英文站更狠,因为中文用户主要分布在台港澳和北美华人区,三个市场的兴趣画像差异极大;中文站原创视觉的重要性比英文更高,因为中文Discover卡片在feed里要和小红书、抖音、知乎截图的高视觉密度竞争。
真出现Discover掉量了怎么诊断?6步排错
Discover掉量比Search掉量难诊断10倍,因为它没有“关键词排名”这个抓手。六步法:
- 分诊:是单篇掉还是站点级掉。GSC Discover报表按发布日期看,如果近30天发的内容全数据归零是站点级被踢,如果只是老内容衰减是正常生命周期。
- 查HCU影响窗口。最近6个月有没有HCU或核心更新?站点流量从那个时点开始断崖,几乎必是被打。
- 查图片资产是否合规。某些CDN重配置会自动给Discover主图加watermark或压缩到800px,触发尺寸不达标。
- 查内容是否被判AI生成。最近上线的内容是不是用了AI大量批量生成?如果是,站点级被打scaled content abuse标签的概率极高。
- 查robots.txt和sitemap没把Discover关键路径挡了。Discover走的是Googlebot Smartphone,确认这个UA没被WAF误拦。
- 查发布商验证状态。Search Console Discover报表底下的Eligibility,如果掉了说明站点级触发了某个政策,要从GSC通知里反查。
| 掉量形态 | 典型根因 | 诊断切入 | 恢复时间 |
|---|---|---|---|
| 断崖式(一夜掉80%+) | HCU或核心更新打击 | 看GSC通知 + Google算法监测站 | 3-9个月(等下次核心更新) |
| 渐进式(2-4周衰减) | 内容主题切换 + 画像断层 | 对比近期发文主题vs历史 | 6-12周(养新画像) |
| 局部式(某子话题掉) | 新闻周期结束 + 竞争对手内容涌入 | 看Trends + SERP监测 | 1-4周(等下个周期) |
| 零曝光(Discover报表无数据) | 站点失去发布商资格 | 看GSC Discover Eligibility | 不定,需逐项排除政策违规 |
Discover流量怎么和SEO团队KPI挂钩才不踩坑?
Discover上挂KPI的方式如果照抄Search,几个月内必出问题。最常见的两种死法:第一种是把“Discover月环比涨幅”当KPI,团队为了短期数据开始追热点、堆clickbait标题,三五个月后HCU来一波连根拔掉;第二种是把“Discover流量占比”当KPI不设上限,团队把所有内容资源都倒向Discover适配,结果Search基本盘萎缩、Discover一波算法调整后整站流量崩盘。
合理的KPI设计三条原则:第一,永远用Search + Discover合并的90天滚动UV作为大盘指标,不要把Discover单拎出来当业绩单元;第二,给Discover流量占比设一个30%-35% 的硬上限,超过就要主动调整,不让单一渠道决定生死;第三,把“Discover用户回访率”和“Discover用户30天留存订阅率”当辅助指标,这两个比单纯UV更能反映内容质量,也更能预测算法调整后的抗跌性。
保哥服务的一家出海美容仪D2C在2024年Q2把Discover占比从52% 主动调到28%,靠的是把原本投Discover的60% 内容资源转去做Search长尾页面。当时数据短期看是丢了Discover流量,但2024年9月HCU那波席卷了大批高Discover依赖站点的时候,他们因为占比早就调下来了,整站只受了8% 的冲击,同行同体量站普遍掉40%-60%。这一年算下来等于多赚了一个Q4旺季。
| KPI设计错位 | 团队会怎么做 | 3-6个月会发生什么 |
|---|---|---|
| Discover月环比涨幅 | 追热点、堆情绪化标题 | clickbait标记 + HCU打击 |
| Discover流量占比无上限 | 所有资源倒向Discover适配 | Search基本盘萎缩、单渠道依赖 |
| Discover文章数 | 日更轰炸 + 主题失焦 | 多样性约束触发 + 画像漂移 |
| Discover CTR单维 | 标题党 + 高情绪封面图 | pogo-stick反弹率飙升被降权 |
Web Story在Discover里还有红利吗?
2023年之后红利窗口基本关了。Web Story在Discover Feed里的位置从“顶部第一屏carousel”降到“第二屏中段”,曝光衰减65% 以上。Google 2024年内部还讨论过是不是直接停掉Web Story Discover入口(参考Search Engine Journal 2024年Q3报道),最后保留但不再投入开发资源。
当前的判断:除非你已经有大量存量Web Story内容,新做不值。资源更建议投到原创主图 + 短形式垂直视频缩略图,那两个在Discover里的回报系数比Web Story高3-5倍。
AI Overviews时代Discover还会被取代吗?
不会被取代,但会被重新定位。AI Overviews解决的是“用户主动搜某个问题的时候,要不要让AI把答案直接喂给他”,Discover解决的是“用户根本没搜任何东西的时候,要不要主动推内容引起他兴趣”——这两个问题完全不冲突。
实际趋势看,AI Overviews起来之后Discover的战略地位反而被加权了——因为SERP上有了AI Overviews截流,Search的“点击通过SERP进站”这个传统路径越来越窄,发布商必须找新流量来源,Discover就成了对冲AI Overviews截流的最重要工具。Google内部2025年Q1也把Discover的产品优先级从Tier 2升到Tier 1,资源投入明显增加,2025全年加了7项新功能(个性化主题订阅升级、本地新闻置顶、视频卡片重设计、创作者关注按钮改版、Discover评论区、跨设备同步、AI推荐解释卡片)。
但有一条要警惕:Google在2025年下半年开始实验“Discover卡片里嵌入AI摘要”这个功能,如果全量上线,Discover的点击率会下滑20%-35%,因为AI摘要会把内容关键信息直接抽出来塞在卡片底部,用户读完摘要就不再点击进站了。这个零点击趋势在Search已经发生过一轮,Discover大概率2026下半年到2027上半年会来同样一波。提前布局的方向是:把内容做成“摘要看了还得进站才能拿到完整价值”的结构——原创数据表、可下载资源、互动计算器、视频深度版——靠这些把点击留住。
出海独立站怎么把Discover当增量流量?
给三个不同体量站的执行节奏:
初级阶段(月Search UV <2万):先把基础门槛做完——发布商验证、Person Schema、原创主图规范、Hreflang完整——别急着抢Discover流量,把Search基本盘做到月5万再说。这阶段强求Discover大概率亏。
中级阶段(月Search UV 2-20万):选2-3个垂直子话题集中产出,每天1-2篇但每篇必须有独家信息(不是paraphrase)+ 原创高质量主图。这阶段Discover占比应该控制在15%-25%,超过30% 就是过度依赖、HCU来时砍得疼。
成熟阶段(月Search UV >20万):开始做本地化垂直内容——比如出海德国市场就专门做德国本地角度的内容、雇本地写手、用本地化数据(德国本地销量、德国本地法规、德国本地节日)。这阶段Discover是增量主力,能贡献30%-45% 流量,但要每季度复盘画像漂移。保哥服务的一家出海保健食品D2C用这个节奏在2025年下半年把德国市场Discover流量从0拉到月8万,但前两个季度几乎零回报,靠的是第三季度本地化资产积累到临界点突然起量。
另一个值得加的兄弟篇是 媒体站新鲜度与常青化机制,Discover的24-72小时窗口和媒体站新鲜度算法是同源逻辑,搭起来理解更清晰。
常见问题解答
Discover流量算自然搜索流量吗?GSC里和Search怎么分开看?
Discover流量在GSC里独立成一个报表入口,和Search Performance分开。商业层面建议做月报时把两个分开看,不要混算环比。
Discover流量来日不稳定,是不是我做错了什么?
多半不是。Discover天然波动幅度在 ±40%,月度数据全是噪声,要看90天滚动均值才有判断价值,不要拿单月波动当业绩信号。
非英文站,Discover流量天花板真比英文站低吗?
是的,根因在于Google中文产品生态弱(Google App大陆不可用、Gmail渗透低),导致中文用户画像数据采集量是英文的5%-10%,画像质量差。
Discover卡片主图必须多大?什么尺寸最稳?
宽度 ≥1200px、宽高比16:9或4:3、无过多文字水印、原创度高。低于这个尺寸直接退出候选池。原创度也会被感知哈希查,复用图扣分50%-70%。
Web Story在Discover还值得做吗?
2023年之后红利窗口基本关了,位置从顶部carousel掉到第二屏中段,曝光衰减65%+。除非有存量内容,新做不值,资源建议投原创主图和短视频缩略图。
HCU把Discover流量打没了,多久能恢复?
3-9个月,要等下一次核心更新触发站点级重判,没有快速恢复路径。期间继续按HCU修复指南清理低质内容、补真人专家署名、积累用户行为正向信号。
我目标市场是德国,但域名是 .com注册地美国,Discover是不是德国用户看不到我?
是的。地理本地化信号2024年下半年上调,必须Hreflang声明de-DE、内容里有具体德国地名实体、GMB验证地址才能进德国Discover池。
Discover的标题党雷区,2026比2024严在哪?
2026年2月更新后从“单篇被降权”升级为“站点级标记”,一次被判clickbait整站Discover流量打50% 折扣30-60天。AI生成标题指纹识别率超过85% 也算clickbait加权。
权威参考资料
本文标题:《Google Discover算法的6个排序信号与9年演变实测》
本文链接:https://zhangwenbao.com/google-discover-algorithm-mechanism-evolution-signal-deep-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0