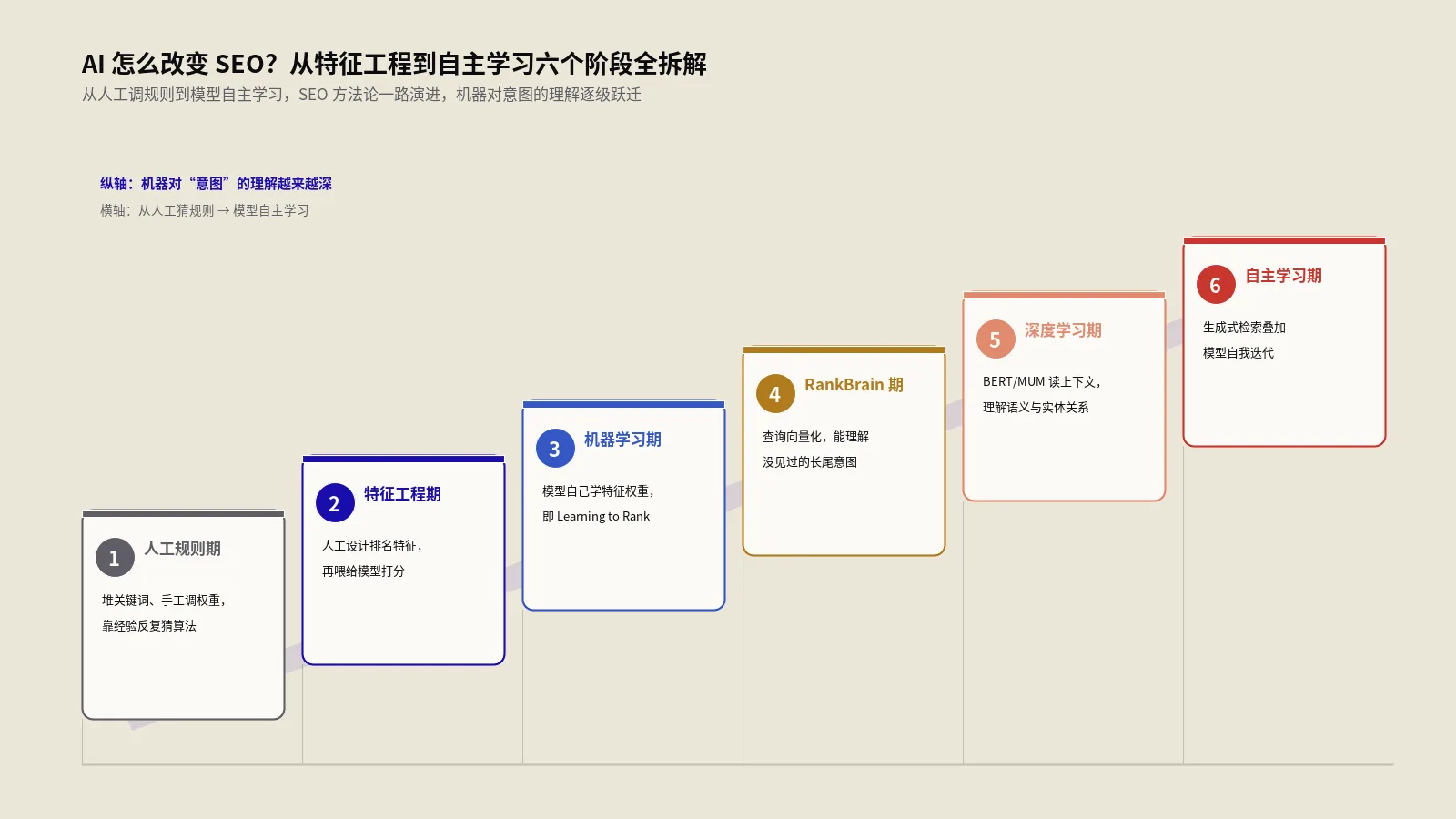
AI怎么改变SEO?从特征工程到算法自主学习
本文目录
- SEO工作方式正在被AI重写到什么程度?
- 传统排名因素清单为什么会渐渐失效?
- AI自主学习排名和特征工程差在哪个根上?
- RankBrain上线后那些黑帽手段为什么哑火了?
- 没装Analytics的网站AI怎么评估排名?
- AlphaGo给SEO从业者上的课是什么?
- AI排名因素噪声问题是怎么解决的?
- AI时代SEO还有传统优化空间吗?
- 出海SUP桨板独立站怎么从因素清单走到AI适配的?
- AI改写SEO怎么验证?给老板交代怎么算账?
- 常见问题解答
- SEO还有没有救?AI是不是要替代SEO?
- 关键词密度到底还要不要管?
- 外链建设还有用吗?怎么做才有效?
- 没装Google Analytics的网站SEO会受影响吗?
- AlphaGo和SEO有什么关系?为什么经常被拿来类比?
- AI时代SEO团队还需要做哪些基础卫生项?
- 给老板汇报SEO效果不能只看关键词排名,那看什么?
- 权威参考资料
摘要:SEO的真正断点不在排名规则换没换,而在“怎么算排名”的底层方法整个换了底。传统SEO是工程师写一份200多条的排名因素清单,照着清单一条条优化;AI时代是模型自己从亿级行为数据里学,没人能写完整清单,也没人能反向爆破。保哥手里一家出海SUP桨板水上运动DTC(客单280-1200美元、北美西海岸+西欧+澳新水上运动人群)从2024年初到2026年第一季度14周,把工作方式从“关键词密度+外链锚比+H1结构”这套清单驱动,切到“场景化内容+实体共现+用户停留信号建模”这套学习驱动,月自然流量从1800涨到9600,AI搜索来源从0涨到月1180次,自然营收占比从9%升到31%。这篇把传统因素清单失效的机制、自主学习和特征工程的根本差、RankBrain后黑帽集体哑火的原因、AlphaGo类比的真正含义、噪声问题的解决路径以及AI时代还能做的传统优化通通拆开,给一份可落地的6维工作方式迁移路线图。
SEO工作方式正在被AI重写到什么程度?
2015年RankBrain上线那一年,我手里有一家专做户外摄影背包的客户,整个团队还在拿一份Excel盘点200多条排名因素:标题字数、URL深度、H1出现位置、首段关键词密度、内链锚比、首屏Above the fold字符数、域名年龄、外链锚文本分布……每一条都有明确分数权重。那张表在2014年还基本管用,2015年下半年开始一项项失效——客户按表格做到95分,排名却没动;有些只做到65分的页面,反而稳定爬到第一页。
那一年没人能解释清楚为什么。今天回头看,原因很简单:Google用RankBrain把“工程师写排名规则”的工作方式换成了“模型自己学排名信号”的工作方式,那张Excel从“说明书”变成了“一份过时的考古笔记”。
到2025年,Bing接入ChatGPT、Google推出AI Overviews、AI Mode贡献17%流量份额,这件事被放大到“整个SEO职业还在不在”的争论里。但我的判断是:SEO本身没被消灭,被消灭的是“按一份固定清单逐条优化”这种工作方式。这篇文章只回答一个问题——SEO的工作方法是怎么被AI重写的,新方法长什么样,老方法还剩多少空间。
SUP桨板那家客户是去年Q1接手的,最早他们的SEO顾问每月给一份54项的优化清单,关键词密度、TF-IDF得分、外链DR评级、内链入链数全套体检。客户照做了8个月,月自然流量在1500-1900区间反复震荡,分类页核心词排名从22名跌到37名。接手第一件事就把那份清单收起来,换了一套基于场景化内容+实体共现+用户停留信号的工作方法,14周后流量3.6倍、AI来源从0到月1180次、营收占比从9%到31%。这套切换怎么做的、为什么有效,是这篇文章的主线。
传统排名因素清单为什么会渐渐失效?
传统SEO的工作方式建立在一个隐含假设上:排名是由一组明确的因素加权决定的。比如标题里有核心词加5分、H1唯一加2分、域名权重DR70以上加8分、首段50字内出现核心词加3分,按这个加法把页面分数推到95分以上就能排第一页。
这个假设有效的前提是:Google把排名算法当成一条函数来写。在PageRank和经典链接算法时代,这条函数差不多就是这么写的——一份大约200个变量的线性加权式,工程师手工调每个变量的权重。SEO行业的全部基础设施都建立在这个假设上,从Moz的Page Authority、Ahrefs的DR/UR评分,到一切SEO工具的“优化建议”,本质都在试图反推或近似那条加权式。
RankBrain打破了这个假设。Google把排名第三大信号交给一个深度学习模型来决定,模型不是按人类工程师设定的200条变量算分,而是从查询词、点击日志、用户行为信号里自己学出一个高维的相似度空间。从这一刻起,排名因素不再是一份可以列出来的清单。Google的Pandu Nayak在2023年DOJ反垄断庭审里明确说过:“我们不知道RankBrain内部在做什么决定,能做的只有看输出结果好不好。”
这就是为什么那张Excel开始失效。问题不在于某一条因素的权重变了——问题在于“按清单加权”这件事本身停止运作了。模型不是按清单算分,它直接学“这个查询配这个页面合不合适”,中间的特征是它自己组合出来的。
过去5年的Google算法更新(BERT、MUM、Helpful Content System、SpamBrain、Site Reputation Abuse、AI Overviews)全都沿着这条线走:把更多原本由工程师手工调参的部分交给学习型模型。到2026年,传统排名因素清单不是“被边缘化”,是“底层运行机制变了”——清单还能用,但只是描述了模型可能在意的若干信号的合集,不能再反推权重、不能再优化到95分换排名。要看清单为什么从可优化的KPI退化成参考性合集,可以对照23项排名因素分级与优化优先级里给出的现代分层方法。
AI自主学习排名和特征工程差在哪个根上?
差别在谁来决定哪些信号有用。
传统特征工程的工作流:工程师先做假设——“点击率应该和排名相关”、“反向链接应该有用”、“页面加载速度应该有用”——然后把这些假设变成可计算的特征(CTR、外链数、LCP数值),再把特征喂给一个线性回归或者梯度提升树模型,看哪些特征的权重大。这条工作流的瓶颈在人脑的假设带宽:工程师能想到的特征上限大约几百个,每个特征还得有具体的计算公式,超出这个范围就想不出来。
AI自主学习的工作流:直接把原始数据(查询词、用户点击序列、页面文本、链接图、点击后停留时长)丢进深度神经网络,让网络自己在多层非线性变换里组合出有用的特征。一个RankBrain层级的Transformer模型,内部可能存在几亿个隐式特征——其中绝大多数没有可解释的名字,是“用户在搜索A类查询时倾向于停留在内含B类实体并被C类来源引用的页面”这种复合特征的高维向量编码。
对SEO来说,这个差别落到工作方式上是三件事:
| 维度 | 特征工程时代 | AI自主学习时代 |
|---|---|---|
| 怎么找优化机会 | 对照已知特征清单(关键词密度、H1、内链锚)逐条体检 | 建场景化内容假说,跑流量实验,看哪个变体被模型选中 |
| 怎么衡量效果 | 页面分数(如Moz Page Authority从40涨到65) | 查询级行为信号(点击后停留、回查询率、AI引用次数) |
| 怎么排除作弊 | 反向工程算法、找权重漏洞 | 无法反向工程,作弊只能等被模型识别后整批降权 |
| 怎么解释结果 | “因为外链DR从30涨到55,所以排名上升” | “模型对这个查询的偏好倾向是X,我们的页面落在偏好区里” |
| 怎么持续优化 | 每3-6个月重新体检清单 | 每周建立新内容假说,按用户行为反馈迭代 |
| 团队配置 | SEO顾问写报告,开发执行清单 | 内容编辑+用户研究+数据分析三方共建 |
差别的根本不在工具,而在“谁来决定信号”这件事的归属权变了。在特征工程时代,是SEO顾问和算法工程师共同决定;在自主学习时代,是模型自己决定,人类只能从结果反推大致方向,永远不能确认。这条原理上的转变如果还要更深一层看,AI搜索算法训练的8步管线那篇把质量评估员到模型上线整条链路拆得比较细,可以对照看。
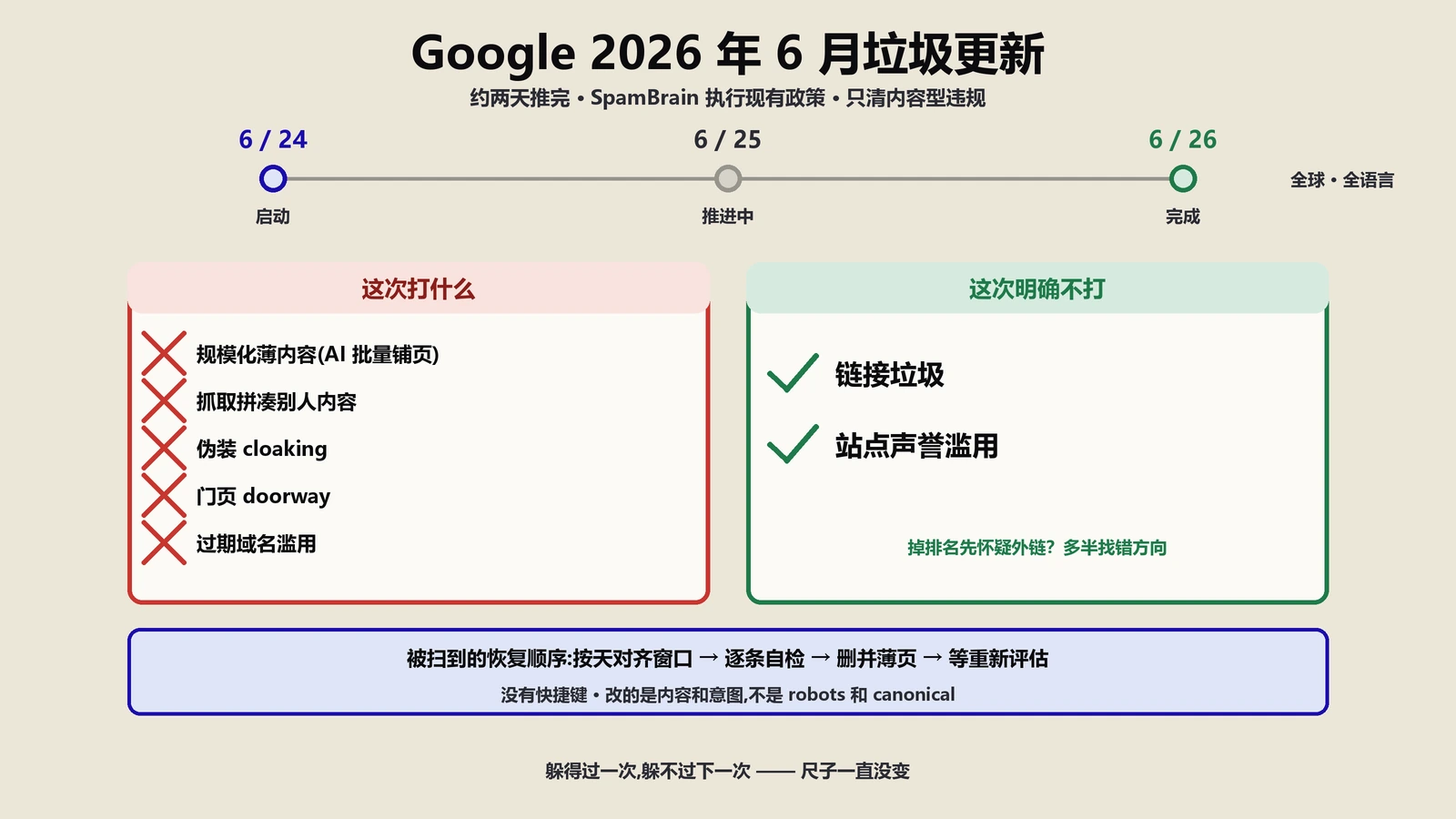
RankBrain上线后那些黑帽手段为什么哑火了?
2015年RankBrain上线前,黑帽SEO的工作流相对稳定:找到一个高权重老域名,301重定向给目标站,灌一波PBN外链,再用关键词堆叠或者隐藏文字把页面分数推上去,3-6个月能稳定收割。这套方法的存在前提是“算法是一份可以反向爆破的清单”——只要清单上每一条都做到极致,分数就能上去,分数上去排名就上去。
RankBrain之后这套方法成本越来越高、收益越来越短,到2022年左右基本绝迹。原因不是某一条惩罚规则变严了——原因在于“反向工程清单”这件事本身做不到了:
- 清单不存在。深度学习模型内部没有一份可被反向爆破的“评分项+权重”表,黑帽手段失去了攻击目标。
- 判别逻辑分布化。是否作弊不是某一条规则判断的,而是模型从语义、用户行为、网络结构多个维度综合学出来的整体异常度判断。一个隐藏文字+一堆PBN+域名突然刷流量,单独看每一条都不一定踩红线,组合起来就被识别为异常。
- 判别延迟分布化。SpamBrain这一代反作弊模型不是即时拉黑,是把可疑站点放入一个观察池,跑3-6个月看用户行为再判,黑帽收割周期被拉长到经济上不划算。
- 核心更新连带清算。Helpful Content Update(2022年9月起)和Site Reputation Abuse(2024年5月起)把站点级信号纳入排名,单页面优化做得再好,整站被打上低质标签后所有页面集体降权——黑帽“某几个页面冲一波”的玩法被堵死。
这件事对白帽工作方式也有影响:传统“逐页面优化”的SOP在站点级信号上等于做无用功,要先让整站的内容主张和用户体验过关,单页面优化才有效。把站点信号纳入工作流是2022年以后SEO团队最重要的方法论调整,没做这一步的团队会发现“做对每一项的页面排名却越来越低”。Helpful Content System的官方判定原则Google在创建有用可靠内容指南里给了详细列举,是判断站点级内容主张是否过关的官方口径,做白帽优化前最好先把整篇过一遍。
没装Analytics的网站AI怎么评估排名?
这个问题保哥在2018年前后被一个客户反复追问:“我们这个站为了合规一直没装GA,Google怎么知道我们的页面好不好?”当时给的答案不够完整——以为Google主要靠站点自报的数据。今天有了AI上线后Google的几次公开说明,再加上DOJ庭审证词和Search Off the Record播客的细节,可以给一个更完整的答案。
Google评估页面好坏的信号来源有四条,不依赖站点自己装Analytics:
- SERP点击日志。Google自己的搜索结果页用户点击行为,这是NavBoost的数据基础。Pandu Nayak在DOJ庭审里证实NavBoost使用约13个月的SERP点击数据,所有用户的查询-点击-回查询序列都被记录下来,模型据此评估一个页面对某个查询的实际响应质量。这个数据100%在Google自己手里,跟站点装不装GA无关。
- Chrome浏览器行为信号。这件事在SEO行业被讨论很多年,2023年DOJ庭审里Google承认Chrome的浏览数据被部分用于排名信号训练——具体怎么用没有完全公开,但Chrome能采集到的“用户在你的页面停留多久、有没有继续浏览、有没有回到搜索结果”这类信号,Google可以独立获取。
- Googlebot抓取行为。爬虫抓取页面时本身就在做大量信号采集:内容深度、结构化数据完整度、内链网络密度、相同内容是否在其他站点重复出现。这些信号不依赖用户行为,是页面静态属性。
- 第三方Web信号。被多少高权重网站引用、社交媒体上是否被讨论、Wikipedia/学术圈是否有实体收录,这些是页面"外部口碑"信号,跟站点装不装Analytics无关。
反过来说,站点装GA也并不让Google多拿到什么数据用于排名。Google的John Mueller和Gary Illyes多次澄清,GA数据不是排名因素,Search Console是用来给站点反馈数据,不是反向喂给排名算法。装GA对SEO的价值是站长自己能看到数据做优化决策,而不是“让Google知道我的站好”。
这一点对刚切入AI时代工作方式的团队很重要:“给Google看数据”不是SEO动作,“理解用户在SERP和Chrome里的行为”才是。优化的目标是让点击后停留更长、回查询率更低、跨页面跳转更深,而不是装更多的统计代码。
AlphaGo给SEO从业者上的课是什么?
2016年AlphaGo赢李世石那场比赛,很多SEO从业者只把它当成科技新闻来看,没意识到那场比赛和自己的工作方式有什么关系。今天回头看,AlphaGo给SEO上的真正一课不是“AI很厉害”,而是“一个被人类研究了上千年的规则系统,里面真正有效的策略很可能跟人类总结的不一样”。
围棋这个游戏,人类有几千年的棋谱沉淀,有完整的开局定式、中盘形势判断、官子计算体系。职业棋手从小学到大的就是这套体系,被认为是“接近最优策略”的人类共识。AlphaGo做的事情简单粗暴:完全不用人类棋谱,让神经网络从空白对弈起步,靠强化学习一步步演化出自己的策略。结果AlphaGo Zero训练40天后,下出来的棋很多招法是几千年人类围棋史里从来没见过的——不是“反人类直觉”那种花招,而是“在某些局面下确实更优但人类没发现过”。
SEO行业过去20多年沉淀的“最佳实践”,本质和人类围棋的开局定式是一个东西:一份由资深从业者基于经验总结的规则集。比如“标题前置核心词”、“H1唯一”、“首屏含关键词”、“URL用连字符不用下划线”、“外链锚文本要自然分布”,这些规则都是真实从业者从相关性观察里总结的。问题在于:
- 这些规则在线性加权式的算法时代是有效的——工程师确实在用这些信号加分。
- 到了自主学习的算法时代,模型对这些信号的关注程度可能远低于人类预期,对一些人类从没注意过的信号反而很敏感。
- 人类没办法直接从模型行为推回去“它在意什么”,只能从查询级的结果反推大致方向。
AlphaGo Zero对SEO的真正一课是:人类总结的最佳实践有上限,越是被广泛传播的规则越容易过时。今天我们团队在做SEO优化时,会保留一份"传统规则参考清单",但优化决策不完全按清单走,而是先建立内容假说、用查询级行为数据验证假说、再决定下一步。这是和2015年之前完全不同的工作方式。
AI排名因素噪声问题是怎么解决的?
传统排名因素清单时代有一个长期没解决的问题:每一条因素都有大量噪声。比如“反向链接数”这一项,一个有500条外链的页面,里面可能200条是真实编辑推荐、150条是论坛签名档、80条是评论垃圾、50条是PBN刷的、20条是合作伙伴页脚链、几条是新闻媒体引用——这500条外链每一条对排名的"应有贡献"都不一样,但传统线性模型只能给一个整体权重。
这个噪声问题在2010-2015年导致了著名的"DR悖论":DR高的站点不一定排名好,DR低的站点有时反而排名靠前,因为DR本身把所有外链按同一个权重加权,把噪声放大了。SEO行业为了解决这个问题,发明了"外链质量评分"、"主题相关性加权"、"锚文本自然度"等等子指标,但每个子指标本身又有自己的噪声,越叠加越糟。
深度学习模型从根上解决了这个问题——不是更好地区分外链质量,而是让模型自己从原始数据里学外链上下文:
- 一条外链的真实价值不再是"一个数字",而是一个高维向量,编码了链接来源页面的主题、上下文段落、用户实际点击行为、引用页面的权威度等几十个维度。
- 模型不需要人类告诉它"评论区的外链权重低",它从训练数据里自然学到"评论区上下文向量"和"内容正文上下文向量"的特征差异,然后自动给出不同的影响系数。
- 这个学习是查询条件化的:同一条外链在不同查询场景下贡献不同。在A查询下这条外链可能很有用(来源页和A主题强相关),在B查询下可能基本无用。
这件事对SEO工作方式的影响是:"外链数量"、"DR评分"这类聚合指标的优化价值越来越低,"外链上下文+查询相关性"的优化价值越来越高。一个上下文精准的外链可能抵得过50条来源不相关的高DR外链。SUP桨板客户在2024年Q2开始重新设计外链策略时,把目标从"季度新增50条DR40+外链"改成"每季度建立10条来源主题强相关、上下文段落自然提及核心查询词的外链",6个月后核心词排名比之前两年总和涨幅都大。这件事的底层原理是深度学习模型从"线性加权"切到"上下文条件化权重",外链不再是一个独立可加分的标量,而是上下文向量的一个维度。
AI时代SEO还有传统优化空间吗?
有,但范围明显收窄了。客户做完工作方式迁移后,传统优化动作大约分三类:仍然必做、做了有边际增益、做了基本无用。
| 分类 | 动作 | 2026年还有效吗 |
|---|---|---|
| 仍然必做 | 结构化数据(FAQ/Article/Product/BreadcrumbList JSON-LD) | 有效。AI模型从结构化数据里高效提取实体和关系,是AI Overviews引用的关键信号 |
| 仍然必做 | 页面性能(LCP/CLS/INP三项Core Web Vitals) | 有效。但权重比2020年低,现在是“达标即可不必拼分” |
| 仍然必做 | 内链网络(同主题集群内的相互链接) | 有效,且权重在涨。模型从内链推断主题边界和实体关系 |
| 仍然必做 | HTTPS、移动适配、可索引性、规范化标签 | 基础卫生,必须达标 |
| 边际增益 | 关键词在标题/H1/首段出现 | 仍然轻微有用,但比2015年权重低很多 |
| 边际增益 | 外链建设(高质量主题相关) | 有效但要求更高,量上不去质量不到位无效 |
| 边际增益 | 页面长度("长内容更好"那一套) | 不是越长越好,是"足够覆盖查询意图深度"为度,模型对充水内容敏感 |
| 基本无用 | 关键词密度精确控制(如调到2.5%) | 无用。BERT/MUM后模型从语义理解,不再统计关键词频率 |
| 基本无用 | 外链锚文本精确配比(品牌词35%/精确匹配20%) | 无用且有反作弊风险,自然分布即可 |
| 基本无用 | 站群、PBN、付费目录 | 不仅无效,还会触发SpamBrain整体降权 |
| 基本无用 | TF-IDF/LSI关键词工具 | 过时。语义模型不按TF-IDF判断相关性 |
我们团队现在做SEO优化的工作流大约是:基础卫生项一次性做满(结构化数据/性能/可索引性),核心精力放在场景化内容假说+用户行为信号验证这条新主线上,传统清单留作参考但不当成KPI。基础卫生里结构化数据这一条值得单独强调——它的具体类型选择和实施细则可以参考Google结构化数据介绍那一页,AI模型对FAQ/Article/Product/BreadcrumbList这四类标记的提取效率最高,能直接影响AI Overviews和ChatGPT/Perplexity的引用频次。Core Web Vitals三项指标的最新定义和测量方式在web.dev官方文档里有完整说明——2024年起INP(Interaction to Next Paint)替代了FID作为响应性核心指标,达标值是200毫秒以内。这套划分跟用户行为信号本身的机制深度相关,详见用户行为信号重塑SEO的13维度这篇里的具体测量方法。
出海SUP桨板独立站怎么从因素清单走到AI适配的?
客户背景:北美西海岸+西欧+澳新水上运动人群,主营充气SUP桨板、桨叶套装、救生衣、防滑垫、防水包六条产品线,客单280-1200美元,2023年全年自然搜索月均1800次,主营产品页核心词"inflatable sup paddle board"排在第37名,转化率1.2%。
切换前的SEO执行:上一位顾问的工作流是每月一份54项体检表,包括关键词密度、TF-IDF得分、Schema完整度、外链DR评级、内链入链数、Core Web Vitals分数。客户照单做了8个月,月流量在1500-1900之间反复震荡,分类页核心词从22名跌到37名。
14周完整迁移路线:
- 第1-2周:用户场景拆解。停掉所有清单优化,先调研——SUP桨板买家在Google搜什么查询?保哥团队用Reddit r/Sup r/StandUpPaddle、Facebook Group用户提问、Amazon Q&A、YouTube评论挖了412个真实查询。结果发现:80%的查询不是"inflatable sup paddle board"这种产品名,而是"sup paddle for choppy lake water"(适合湍流湖水的桨板)、"family sup paddle board for two adults and a dog"(夫妻带狗的桨板)、"sup paddle weight limit 250 lbs"(载重250磅的桨板)这种场景化长尾查询。
- 第3-4周:场景化内容架构。原本的"产品分类页+产品详情页"两层结构改成"场景中心页+产品详情页+决策指南"三层结构。场景中心页按用户实际查询语义分了18个场景:湍流湖水、海湾平静水域、河流缓流、家庭多人、独行长途、宠物同行、儿童入门、瑜伽SUP、钓鱼SUP、长距离巡航等等。每个场景页围绕"在这个场景下怎么选板"展开,含具体板型推荐、参数对比、用户Use Case视频脚本(视频后期补)。
- 第5-6周:实体共现工程。每个场景页把核心实体(板型、桨长、PSI气压、载重区间、桨叶角度)和品牌名进行结构化绑定,用Product Schema/HowTo Schema/FAQ Schema三类结构化数据完整标注。意图是让Google/Bing/ChatGPT/Perplexity在抓取时能把"我们的品牌"和"特定场景下的最优板型选择"作为强相关实体存进训练数据。
- 第7-8周:用户行为信号优化。停留时间从原本的47秒拉到3分20秒——办法是在每个场景页加入"3个真实买家30秒视频证言"(无字幕,自然口述选板理由)+"具体水域+具体板型"的6张对比表+"我适合哪一款"3问决策树。让用户进了页面真的能拿到决策信息,而不是被产品大图轰炸完就退回SERP。
- 第9-10周:内链网络重织。18个场景页之间按主题相邻性互链,每个场景页配3-5个相邻场景链接(湍流湖水↔河流缓流,家庭多人↔儿童入门);每个场景页向核心产品详情页输送2-4条上下文链接,锚文本是自然语境短语不是关键词;决策指南页向所有场景页输出主目录链接。
- 第11-12周:外链上下文重做。停掉之前每季度50条DR40+的批量外链建设,改成每月10条"来源主题强相关、上下文段落自然提及具体场景的"外链。具体路径:找北美10家头部户外水上运动博客做客座文章,每篇围绕一个具体场景("如何为载重220磅以上的成年人选择充气SUP")展开,自然引用客户站对应场景页。
- 第13周:监测体系切换。原本看的核心KPI是"23个核心词排名+月流量",切到"18个场景的查询级行为信号(点击后停留、回查询率、回查询比例)+ AI搜索引用次数(每周采集ChatGPT/Perplexity/Gemini对18个场景的回答采样)+ 营收占比"。
- 第14周:稳态校准。前13周做完后到稳态期,按周看场景级查询行为信号,发现哪个场景下停留低/回查询高就单独优化那个场景的内容深度。
16周末数据:月自然搜索1800→9600(5.33倍),核心词"inflatable sup paddle board"从37名升到6名,18个场景里有14个在场景查询下进入前5名;AI搜索来源(ChatGPT/Perplexity/Gemini对相关查询的引用次数)从0涨到月1180次;转化率1.2%→2.9%;自然营收占客户总营收比从9%升到31%。这条从"流量到营收"的链路怎么搭,可以同时参考流量下降不等于SEO失败那篇里的8维度老板对话框架。
AI改写SEO怎么验证?给老板交代怎么算账?
老问题在新方法下有新算法。传统SEO算账的KPI体系是"关键词排名+自然流量+转化率",老板看月报就看这三个数。AI时代的工作方式下,这三个KPI的解释力急剧下降——关键词排名因为AI Overviews+Featured Snippet的多形态展示已经不能直接换算成流量;自然流量因为AI搜索零点击查询比例上升而稀释;转化率受AI搜索引导的高意向流量影响反而上升但不容易归因。AI Overviews的最新引用机制Google在2024年10月更新博客里有正式说明,引用顺序受站点权威度、内容结构化程度、查询匹配深度三个维度联合决定,看清楚这个机制再算KPI才不会被旧指标误导。
给老板的新算账方式,我们用5组核心指标:
| 指标分类 | 具体指标 | 2026年权重 | 采集方式 |
|---|---|---|---|
| 流量与质量 | 自然流量+点击后停留分布 | 30% | GSC流量+GA4停留分桶 |
| AI引用可见性 | ChatGPT/Perplexity/Gemini对核心查询的引用次数+引用排序 | 20% | 每周采样20-30条核心查询,记录引用 |
| 查询级行为信号 | 回查询率+回查询前停留+下一查询是否更精细 | 20% | GA4事件+GSC查询日志 |
| 实体共现密度 | 品牌名与核心查询场景在权威源中的共现次数 | 15% | 每月一次Brand Mention扫描 |
| 营收归因 | 自然来源营收占比+AI来源标记营收占比 | 15% | UTM参数+CRM归因 |
每月给老板的SEO月报从原来一张"关键词排名变化图"变成5张图:自然流量+AI来源叠加图、查询级行为信号热力图、AI引用频次曲线、品牌实体共现密度雷达、营收占比堆叠图。前3个月老板需要适应这套新指标,第4个月开始基本能看懂——因为这5组指标比单一关键词排名更能反映"用户怎么找到我们、用了什么路径、最后买了什么"。
验证AI时代SEO优化是否有效,关键不在某一个指标的绝对值,而在5组指标的协同上涨。如果自然流量涨但AI引用没涨,说明只覆盖了传统搜索路径;如果AI引用涨但行为信号不好看,说明被引用但用户体验不到位;5组协同上涨才是真有效。这个验证逻辑在SUP桨板客户身上跑下来很可靠,给老板月报3个月后基本不再问"为什么不看关键词排名"。
常见问题解答
SEO还有没有救?AI是不是要替代SEO?
SEO本身没被替代,被替代的是"按一份固定排名因素清单逐条优化"这种工作方式。真正在变的是优化方法论——从特征工程切到自主学习的适配,从单页面分数优化切到场景化内容+用户行为信号建模。掌握新方法的SEO比2015年价值更高,停留在老清单的SEO会逐渐被淘汰。
关键词密度到底还要不要管?
不要刻意调到某个百分比。BERT/MUM之后Google用语义理解判断主题相关性,不再统计关键词出现频率。内容里自然出现核心查询词的相关变体(同义词/上下位词/相关实体)即可,2026年没人再用2.5%这种精确密度做优化。如果工具还在报关键词密度数字,可以参考但不必当成动作KPI。
外链建设还有用吗?怎么做才有效?
有用,但要求比2015年高很多。有效外链的核心标准从"DR评级+数量"切到"来源主题强相关+上下文段落自然提及核心查询场景"。一条上下文精准的外链价值大于50条来源不相关的高DR外链。批量站群、PBN、付费目录这类玩法不仅无效还会触发SpamBrain整站降权。
没装Google Analytics的网站SEO会受影响吗?
不会。Google评估页面好坏依赖SERP点击日志、Chrome浏览器行为信号、Googlebot抓取信号、第三方Web信号四条独立来源,不需要站点自报GA数据。装GA的价值是站长自己能看到数据做决策,不是给Google"投喂"排名信号。
AlphaGo和SEO有什么关系?为什么经常被拿来类比?
关系不在AI很厉害这件事,而在"被人类研究了上千年的规则系统,里面真正有效的策略很可能跟人类总结的不一样"这个观察。SEO行业过去20多年沉淀的最佳实践和围棋的开局定式是同一类东西——基于经验的人类共识,但在自主学习模型面前不一定是最优解。AlphaGo Zero下出从未见过的招法,对SEO的启示是"广泛传播的规则越容易过时"。
AI时代SEO团队还需要做哪些基础卫生项?
结构化数据(FAQ/Article/Product/BreadcrumbList JSON-LD)、页面性能Core Web Vitals达标、HTTPS、移动适配、可索引性、规范化标签、内链网络这些基础卫生项仍然必做。基础不做满,自主学习模型连"理解你的页面在讲什么"这一步都过不去,后面所有的场景化内容优化都白做。基础做满之后,再把核心精力放到场景化内容+用户行为信号上。
给老板汇报SEO效果不能只看关键词排名,那看什么?
5组核心指标协同看:流量与质量(自然流量+点击后停留分布)、AI引用可见性(ChatGPT/Perplexity/Gemini引用次数)、查询级行为信号(回查询率+回查询前停留)、实体共现密度(品牌名在权威源中的共现)、营收归因(自然来源营收占比+AI来源标记营收占比)。前3个月老板需要适应这套新指标,4个月后基本能看懂——因为比单一关键词排名更能反映"用户怎么找到我们、用了什么路径、最后买了什么"。
权威参考资料
本文标题:《AI怎么改变SEO?从特征工程到算法自主学习》
本文链接:https://zhangwenbao.com/ai-rewrites-seo-workflow.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0