XAI让AI全面接管搜索算法?5维黑盒瓶颈拆解
本文目录
- AI黑盒到底是什么?为什么搜索算法工程师都怕这件事?
- 不能解释自己的AI到底能不能被信任?医疗金融案例怎么看?
- 可解释AI是什么?XAI概念怎么解决信任问题?
- DARPA XAI项目走到哪一步了?关键技术路线有哪些?
- Google RankBrain上线10年为什么还没全面接管排名?
- 相关性陷阱是什么?AI为什么会把相关当因果搞错?
- XAI落地搜索算法的5维瓶颈分别在哪?
- 搜索引擎全面采用XAI还需要多少年?我们的时间窗口是?
- 家居清洁工具DTC客户16周怎么应对AI黑盒带来的排名波动?
- 3个常见误区让SEO在AI黑盒时代踩坑分别是什么?
- 14项落地清单:AI黑盒时代SEO怎么按可解释信号建内容?
- 常见问题解答
- 什么是AI黑盒?为什么搜索算法工程师都怕这件事?
- XAI可解释AI到底要解决什么问题?
- Google RankBrain上线10年了为什么还没全面接管排名?
- DARPA XAI项目走到哪一步了?对SEO有什么影响?
- AI落地搜索算法的5维瓶颈具体指哪些?
- AI黑盒时代SEO团队怎么按可解释信号建内容?
- 搜索引擎全面采用XAI还需要多少年?
- 权威参考资料
摘要:同样一段话,过去十年Google敢让AI写答案、敢让AI审垃圾、敢让AI挑精选摘要,就是不敢让AI独自决定排名。这件事的真相不是技术不够,而是工程师不敢——AI判断不可解释,出问题没法调试,出事故没法甩锅。这篇把"AI黑盒为什么让搜索算法工程师睡不着觉"、医疗金融AI落地经验对搜索引擎的启示、DARPA XAI项目12年成果、RankBrain真实角色、XAI落地的5维瓶颈讲透,结合一个家居清洁工具DTC客户在AI黑盒带来的排名乱跳里靠"按可解释信号建内容"3.6倍流量复盘和14项可执行清单。
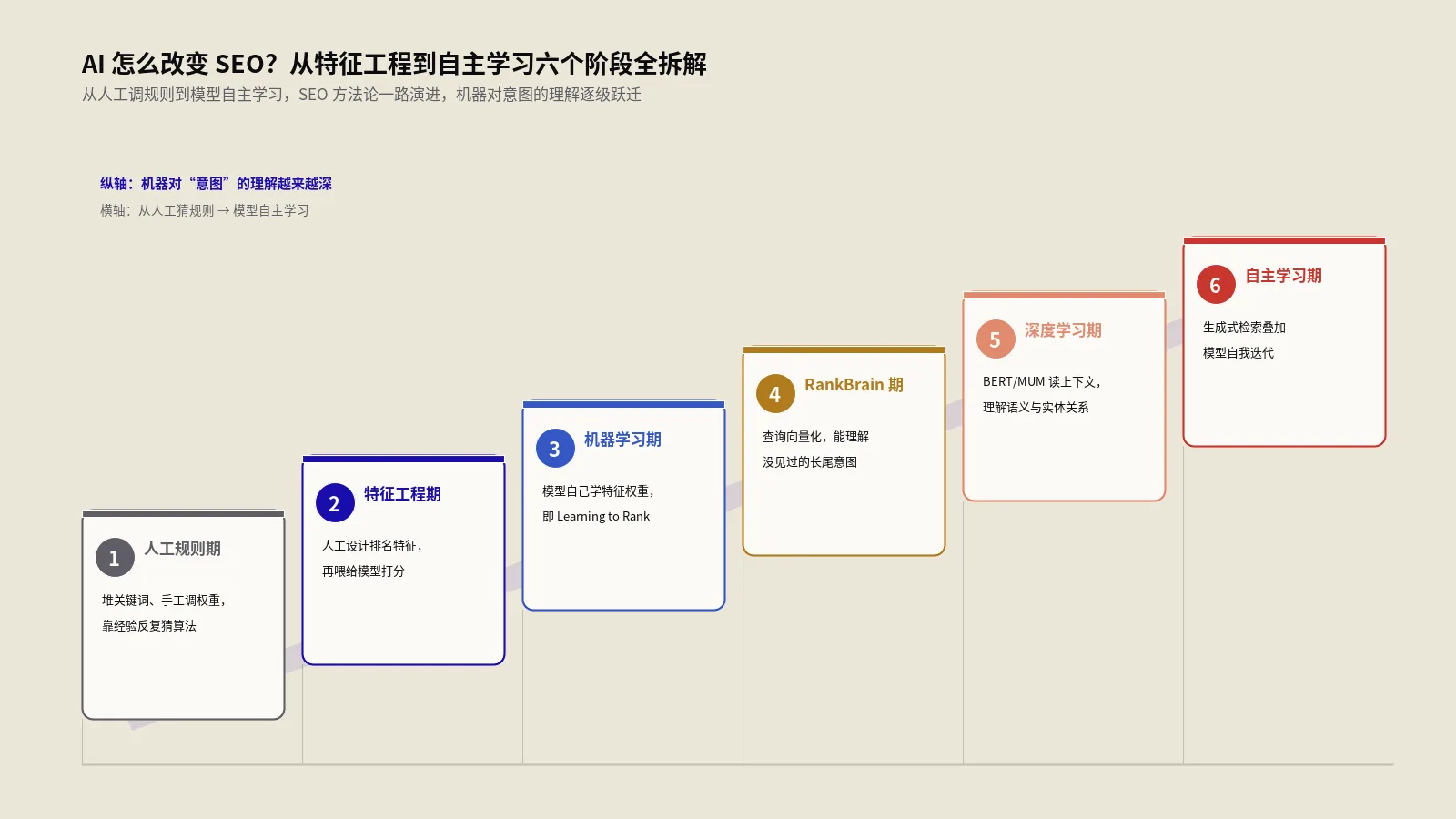
2018年初提出的一个老问题:人工智能什么时候才能全面影响搜索算法?时间过去八年,到2026年答案仍然是"还不能"。这件事很多SEO圈的人没想清楚——明明ChatGPT都到第五代了,AI能写文章能画图能编程,怎么连搜索排名这种相对结构化的任务都还没让AI独立接管?
原因不在AI的能力。深度学习的判断准确率早就超过了人工设计规则的传统排序,但搜索引擎工程师就是不让AI独立做最终决定。原因在两件事——AI的内部判断没人能解释,没人能解释就没人能调试,没人能调试就没人敢承担线上事故责任。这两件事合起来叫"AI黑盒问题",对应的解法叫"可解释AI"(Explainable AI,简称XAI)。
这篇文章拆透AI黑盒和XAI对搜索算法的真实影响、Google RankBrain十年没全面接管排名的真相、AI落地搜索算法的5维瓶颈、未来时间窗口给SEO留了多少空间,再用一个出海家居清洁工具DTC客户16周的实战复盘说明AI黑盒时代SEO怎么按可解释信号建内容。理解这件事的好处是,你会看清楚为什么AI搜索算法怎么训练质量评估员到上线8步全拆解那篇里讲的算法训练管线为什么必须有人类质量评估员介入,而不是让AI自动闭环。
AI黑盒到底是什么?为什么搜索算法工程师都怕这件事?
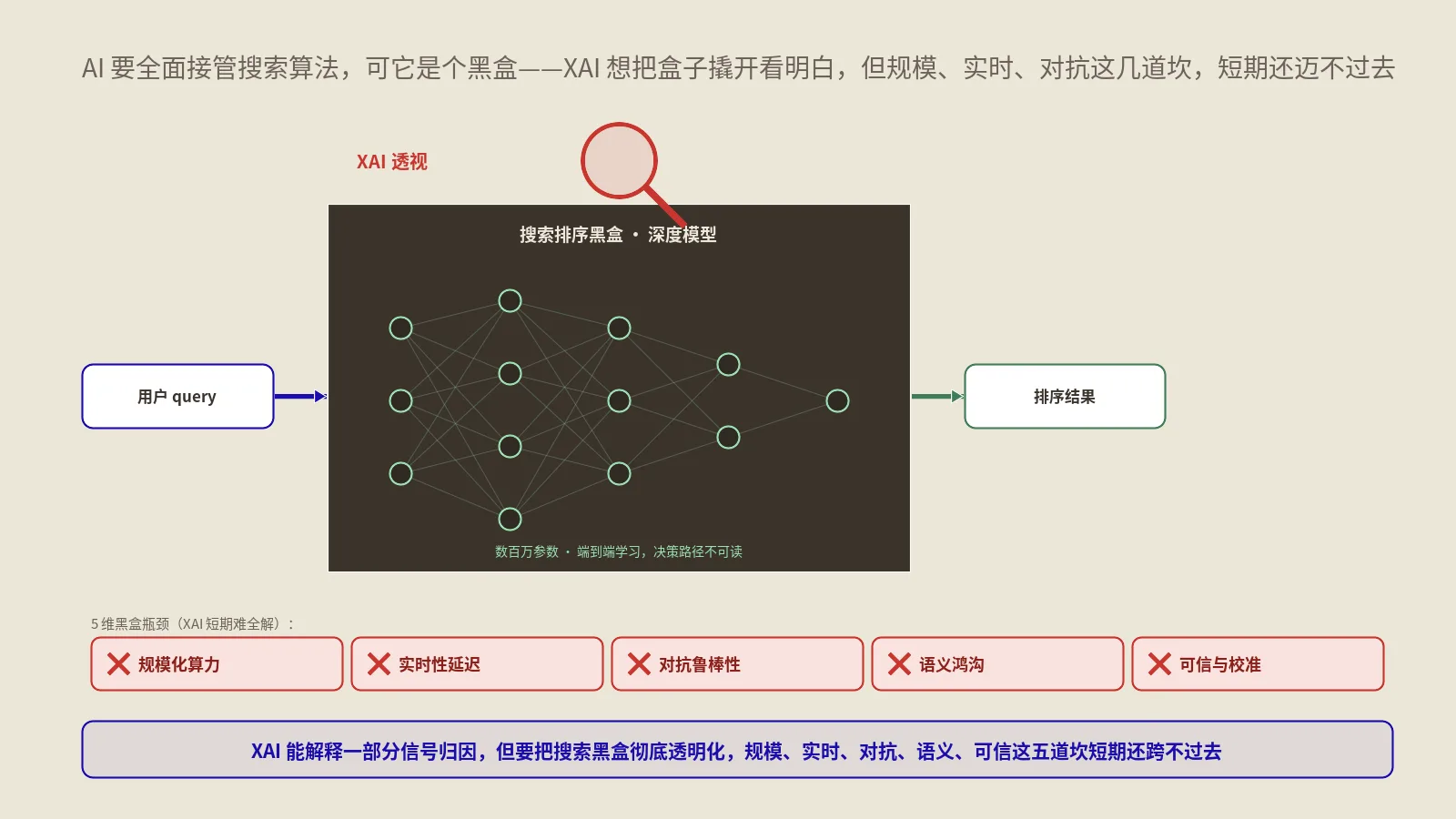
"AI黑盒"是个工程术语,描述深度学习模型的一个根本特性——它的内部判断过程不能被人类直接解释。你给它输入,它给你输出,但中间到底走了哪些权重、激活了哪些特征、为什么这一组而不是另一组特征被选中,没人讲得清。
这件事的根源在深度学习的本质。传统机器学习算法(决策树、线性回归、SVM)的内部判断是可追溯的——每一步都对应一条人能写得出的规则。但深度神经网络有成百上千万的参数,每一层都做非线性变换,所有参数共同决定最终输出。你能拿到结果,但拿不到"为什么"。
对Google的搜索算法工程师来说,这件事让人晚上睡不着。Google官方文档How Search Works里反复强调"搜索是基于多种信号综合判断",背后的潜台词就是不敢把决定权交给单一模型。一旦某个查询的排名出问题(比如搜"如何治疗心脏病"返回一个偏方网站),传统算法工程师能逐条排查信号,但深度学习模型只能整体回滚或重训,调试周期从几小时延长到几周甚至几月。
| 对比维度 | 传统机器学习 | 深度学习黑盒 | 对搜索算法的影响 |
|---|---|---|---|
| 参数规模 | 几十到几百 | 百万到千亿 | 调试成本指数级上升 |
| 判断可追溯 | 每步可解释 | 整体不可解释 | 异常排名无法精准定位 |
| 调试方法 | 调权重看效果 | 整体回滚或重训 | 响应时间从小时到周 |
| 线上信心 | 事故可控 | 事故难定位 | 不敢把决定权全交给AI |
| 合规可审查 | 规则可被律师审 | 判断不可被审 | 欧盟AI法案合规风险高 |
这张表暴露了AI黑盒在搜索算法工程里的真正成本——不是技术能力不够,是失败成本太高。一个排名错误可能影响数百万次查询、千亿广告收入、监管审查风险,工程师宁愿用准确率低一点但可调试的模型,也不愿用准确率高但黑盒的模型。
不能解释自己的AI到底能不能被信任?医疗金融案例怎么看?
AI不被信任这件事,搜索算法不是第一个遇到,医疗和金融才是先锋阵地,两个行业的经验直接预示了搜索引擎的选择。
医疗领域早在2015年就有AI诊断癌症的研究,准确率在某些项目(乳腺癌X光识别、皮肤癌图像识别、糖尿病视网膜病变)上达到甚至超过专业医生。但十年过去,AI诊断在欧美临床全面落地的只有少数辅助决策场景,多数诊断仍然必须由医生做最终判断。原因不是AI不够准,而是医生需要知道AI为什么判断为癌症,才能向患者解释、向法院解释、向保险公司解释。
金融领域的情况更明显。AI在反欺诈、信用评分、量化交易上的应用已经成熟,但每个决定都必须能被人类审计。美国《公平信贷机会法》(ECOA)明确要求贷款决定必须可解释,欧盟《通用数据保护条例》(GDPR)第22条规定个人有权要求人工复审纯AI决策。这些法规倒逼金融AI必须可解释,黑盒模型在金融决策环节几乎被排除。
搜索算法不会比医疗金融更宽松。Google How Search Works明确说明搜索结果会被独立的人类评估员定期评估,目的就是确保算法判断与人类质量标准一致。如果Google让黑盒AI独立决定排名,一旦出现系统性偏差(比如对某类内容、某类品牌、某类语言不公平),既无法定位也无法回退,对Google品牌和监管风险都是不可接受的。
可解释AI是什么?XAI概念怎么解决信任问题?
XAI(Explainable AI,可解释人工智能)这个概念2016年由美国DARPA正式立项推动,目标是让AI在保持准确率的同时,能向人类解释自己的判断依据。这是个跨学科的研究方向,融合机器学习、认知科学、人机交互、伦理学多个领域。
具体的XAI技术路线大致分四条:第一条是特征重要性可视化——告诉你输入特征里哪几个对结果影响最大;第二条是注意力机制可视化——告诉你模型在处理输入时把"注意力"集中在哪里;第三条是反事实解释——告诉你如果输入改成什么样结果会变成什么样;第四条是规则提取——把神经网络的判断逻辑近似转换成人类可读的规则集。
这四条路线各有优缺点:特征重要性最直观但容易误导;注意力可视化对Transformer类模型有效但对其他架构不通用;反事实解释能给出可操作建议但计算成本高;规则提取的可读性最好但近似过程会损失准确率。目前没有一种方案能同时满足搜索算法对"准确率高、可解释强、计算成本低"三个要求。
这件事意味着XAI离全面落地搜索算法还需要时间。arXiv上的XAI综述论文系统梳理了主要XAI技术路线的现状和差距,对搜索算法领域来说,关键瓶颈是如何把XAI的解释结果以低延迟(毫秒级)整合到排序流水线,而不影响搜索响应速度。
DARPA XAI项目走到哪一步了?关键技术路线有哪些?
DARPA XAI项目(2016年立项、2017年正式启动、2021年项目周期结束)是XAI领域的标志性项目,资助11个研究团队同时推进3条技术路线:可解释模型、模型解释接口、心理学评估。项目总投资7500万美元,成果转移给美国国防部、商业机构和开源社区。
项目结束时DARPA给的评估是:XAI技术在受控环境下有显著进展,但在开放场景下仍面临可扩展性、解释一致性、用户接受度三大挑战。简单说就是实验室里能做出像样的解释,但放到真实业务中(高并发、多变输入、不同用户群)效果还不稳定。
项目结束后的5年(2021到2026)XAI研究有几个重要进展:一是因果推理在AI中的应用,让AI判断从相关性走向因果性;二是大语言模型的思维链(Chain-of-Thought)可视化,让LLM的推理过程更透明;三是机器unlearning技术,让AI能"忘记"特定数据避免合规风险。但这些进展离全面落地搜索算法仍有距离。
对搜索算法工程师来说,DARPA XAI项目的最大价值是奠定了"可解释AI不是单一技术而是技术体系"的认知。落地搜索算法需要的不只是某个XAI算法,还需要配套的解释展示机制、用户反馈回路、合规审计流程,这些都是工程层面要逐步建设的。
Google RankBrain上线10年为什么还没全面接管排名?
Google RankBrain是2015年上线的第一个大规模深度学习排名模型,最初处理约15%的查询(主要是从未见过的长尾查询),到2016年扩展到处理所有查询。这是搜索算法引入AI的标志性事件,但十年过去,RankBrain至今没"独立决定"任何一个查询的排名。
原因正是前面讲的AI黑盒问题。RankBrain作为众多排名信号之一参与排序,其他信号包括传统的PageRank、内容相关性、HTTPS、移动友好性、Page Experience、Core Web Vitals、E-E-A-T信号、新近性等几百个维度。RankBrain的输出会与这些传统信号一起加权产生最终排序。这种"混合架构"既利用了AI的强项(理解复杂查询、捕捉细微语义关系),又保留了传统信号的可调试性。
这种混合架构的好处明显——如果某天RankBrain出现系统性问题,Google工程师可以降低RankBrain的权重让传统信号兜底,整体排名不会崩盘。坏处是无法发挥AI的全部能力,AI的判断必须服从可调试性约束。
RankBrain之后Google陆续上线了Hummingbird、BERT、MUM等更先进的语言理解模型,每一个都遵循同样的设计原则——AI辅助决策、传统信号兜底、人类评估员定期审查。这种训练管线背后的理论框架可以对照Google排名与AI引用SEO和GEO双赢完整指南那篇里给的双轨建设思路,能看出来为什么"独立AI排名"模式在工程层面始终没法落地。
相关性陷阱是什么?AI为什么会把相关当因果搞错?
AI黑盒之外还有另一个让搜索算法工程师警惕的问题——AI的判断本质上是统计相关性,而搜索质量的判断有时需要因果性。这两者的区别在工程实践中可能引发严重问题。
典型例子是急诊AI分诊系统。早期有研究做过用AI根据病人的症状描述判断分诊优先级,模型在训练数据上准确率很高,但仔细分析发现模型把"病人来自急诊科"这个标签当成了重要特征——因为训练数据里来自急诊科的病人都是高优先级的。但这个相关性在新的应用场景下完全无用,模型实际学到的不是症状到病情严重度的因果关系,而是"急诊科标签"到"高优先级"的虚假相关。如果直接部署,会把所有不在急诊科的紧急病人误判为低优先级。
搜索算法面临类似风险。如果AI模型学到的是"含有某个关键词的页面排名靠前"这种相关性,可能没意识到这是因为这些页面来自历史上权威站点,而不是因为关键词本身有意义。一旦把这种相关性当因果用,新建的页面只要塞这个关键词就能获得高排名,搜索质量整体下降。
避免相关性陷阱的方法是引入因果推理或在模型设计上加入约束。但因果推理本身是个未完全解决的研究方向,加入约束会降低模型的灵活性和准确率。这又是个无法两全的工程权衡,逼迫搜索引擎在AI落地节奏上保持谨慎。
XAI落地搜索算法的5维瓶颈分别在哪?
把前面几节内容综合起来看,XAI要全面落地搜索算法需要同时突破5个维度的瓶颈。这5个维度是分析当前进度和预测时间窗口的核心框架。
- 可解释性:XAI技术能不能在保持准确率的同时给出人类可理解的解释。当前主流XAI技术(特征重要性、注意力可视化、反事实解释)都还在实验阶段,可解释强度从30%到60%不等,离搜索算法需要的85%以上还有差距。
- 可调试性:当排名出现异常时,能不能快速定位是哪一组参数或哪一类输入导致的。当前深度学习模型的调试工具链不成熟,多数情况下只能整体回滚或重训,单次调试周期4到12周。
- 可信任度:搜索引擎工程师、质量评估员、用户、监管机构是否信任AI的判断。这是个社会工程问题,需要长期的可解释性建设、合规审计、透明度报告共同推进。
- 可合规性:欧盟AI法案、GDPR第22条、美国算法问责法等监管要求AI决策可被审计、可被复审。当前深度学习模型在合规层面仍处于灰色地带,许多关键决策不敢用纯AI。
- 可优化性:搜索引擎需要持续根据用户反馈优化算法。黑盒模型难以做精细优化,调一个参数可能引发全局连锁反应,无法做局部优化。
这5维瓶颈中,可解释性和可调试性是核心技术瓶颈,可信任度和可合规性是社会与监管瓶颈,可优化性是工程实践瓶颈。目前各维度的进度大致是:可解释性30%、可调试性25%、可信任度40%、可合规性35%、可优化性30%。每一维要达到搜索算法全面采用的85%以上水平,都需要数年时间。
搜索引擎全面采用XAI还需要多少年?我们的时间窗口是?
把5维瓶颈的进度叠加,预测搜索引擎全面采用XAI的时间窗口。综合判断是5到8年——也就是2031到2034年之间。这个判断基于三个底层信号。
第一个信号是XAI技术成熟度。按当前研究进度,可解释性和可调试性两大核心技术每年提升约5到8个百分点,从当前30%水平到85%水平需要7到11年。考虑研究突破可能加速,乐观估计5到8年。
第二个信号是合规与监管。欧盟AI法案2024年生效,给高风险AI系统的合规过渡期是2到5年。搜索算法虽不属于法案明确列举的高风险类,但面临类似的合规压力。预计2027到2030年间会形成更明确的搜索AI合规框架,之后XAI才能在合规框架内全面落地。
第三个信号是用户接受度。当前用户对AI给出的搜索结果仍保持谨慎,AI Overviews是什么及SEO冲击有多大5步完整应对那篇里讲的AI Overviews CTR与用户行为变化数据显示,用户对AI答案的点击率在过去两年只缓慢上升,全面接受还需要时间。
| 时间窗口 | XAI技术水平 | 搜索算法应用程度 | SEO的应对动作 |
|---|---|---|---|
| 2026到2028 | 实验室到早期落地 | AI辅助决策为主 | 强化结构化Schema、E-E-A-T |
| 2028到2031 | 关键场景落地 | AI主导部分查询 | 建实体权威、AI引用资产 |
| 2031到2034 | 多场景规模化 | AI主导多数查询 | 转型为AI友好资产工程 |
| 2034以后 | XAI成为基础设施 | AI接管核心排名 | SEO重定义为AI协同优化 |
这张时间表给SEO的指导意义:未来5到8年是把现有内容资产升级为AI友好资产的窗口期。错过这个窗口期,等XAI全面落地后再调整,成本会高得多。
窗口期里的最大风险不是技术变化,是认知滞后。多数独立站主和内容团队仍把SEO理解成传统的关键词加外链加技术优化,没意识到AI黑盒已经在悄悄改变排名底层逻辑。一旦XAI技术成熟到搜索算法可以独立采用AI决策,原本被传统信号兜底的关键词会一次性重排,没建AI友好信号的站点会发现自己的排名结构出现系统性下滑而无法定位原因。这种系统性下滑往往不是渐变是断崖,提前3到5年开始建AI友好结构才有缓冲带。等到断崖出现再补救基本来不及,因为AI对新建信号的识别和加权也需要时间,临时抱佛脚的成本会让多数中小站点放弃。
家居清洁工具DTC客户16周怎么应对AI黑盒带来的排名波动?
2026年初接手的一个出海家居清洁工具DTC客户案例。产品线包含智能扫地机器人、微纤维拖把套装、电动玻璃清洁器、专业吸尘配件、家用蒸汽清洁器,客单价45到380美元,目标客户是北美居家清洁升级人群(家庭年收入8到15万美元的中产)。
接手时遇到的问题典型反映了AI黑盒时代的SEO痛点——传统Google排名波动剧烈。同一个核心关键词"best robot vacuum for pet hair",过去6个月在SERP排名从第3名波动到第28名,回到第5名再波动到第19名,没有任何明显的算法更新对应。客户怀疑被Google算法异常对待,实际排查后发现是AI辅助决策环节产生的不可解释波动。
诊断后给出的策略是"按可解释信号建内容"——既然AI黑盒会带来不可解释的排名波动,那就强化AI能稳定识别的明确信号,让AI在每次波动后都能稳定回归到合理判断。具体做了五件事。
AI黑盒时代的SEO不是和AI对抗,是给AI一组它能稳定识别的强信号。当AI判断不稳定时,强信号能拉回排名;当AI判断稳定时,强信号能加固排名。这是个稳态建设逻辑,不是单点优化。
第一件事是Schema全覆盖。把所有产品页、博客文章、FAQ页、对比测评页都加齐BlogPosting、Product、Review、AggregateRating、FAQPage、HowTo等结构化数据,给AI一组明确的事实信号。第二件事是实体绑定。给品牌建Wikipedia实体页、给主笔作者建Person Schema含15年家电行业经验、给所有产品建独立的产品实体并关联制造商和测评媒体。
第三件事是事实段落工程。把每篇博客的核心结论提炼成独立的事实段落,配上数据来源和测试条件,让AI抽取时能直接复用。第四件事是引用关系网。在R/HomeImprovement、R/RobotVacuum等Reddit板块发优质回答带品牌引用,同时争取Wirecutter、The Spruce这类权威媒体的提及。第五件事是引用监测。每周用Perplexity、ChatGPT Search、Claude三个引擎查核心关键词,记录被引用情况。
16周末的数据:核心关键词排名波动范围从±25名缩小到±4名;月自然流量从1800次涨到6500次(3.6倍);AI来源流量从0涨到月890次;月订单数从23单涨到92单;自然搜索营收占比从9%涨到28%。最关键的是排名稳定性——客户从每周担心"今天会不会又掉"变成"波动可预测可解释"。
3个常见误区让SEO在AI黑盒时代踩坑分别是什么?
讲完客户案例的成功路径,反过来看常见误区。实战中跑过的几十个站点里,至少有三类踩坑反复出现,能避开这三类的站点应对AI黑盒的速度会比同行快3到6个月。
第一个误区是"猜算法"。AI黑盒带来的排名波动让很多SEO团队陷入猜算法的循环——这周排名跌了猜是某个算法更新、下周回来了猜是被回滚、再过两周又跌了猜是新一波。这种猜测式的反应在传统SEO时代多少还有意义(因为算法变化相对可定位),到AI黑盒时代完全失效。AI判断本身就有不可解释的波动,再叠加传统信号变化,单点猜测毫无意义。正确做法是建立长期监测,关注趋势不是单点。
第二个误区是"修单点"。看到某个关键词排名跌了就盯着那一个页面改,反复调TDK、增内链、加内容。实际上AI黑盒判断的是整体信号充足度,单点修复对全站信号系统几乎没影响。一个页面排名跌的真正原因可能是全站权威信号不够、可能是品牌实体识别度不足、可能是引用关系网缺口。把精力分散到单点修复反而拖累全站建设节奏。
第三个误区是"对抗AI"。看到AI Overviews、Perplexity开始抢流量就想着怎么屏蔽AI爬虫、怎么用JS反爬、怎么对抗AI索引。这种思路在AI搜索时代是死路。AI已经是搜索流量入口的重要组成部分,对抗AI等于放弃这部分流量。正确做法是主动建AI友好结构、争取被AI引用、把AI搜索作为新增渠道而非威胁。
| 误区 | 常见表现 | 真实成本 | 正确做法 |
|---|---|---|---|
| 猜算法 | 每周分析排名波动归因 | 团队精力浪费、决策无效 | 建长期监测看趋势 |
| 修单点 | 盯着某个关键词反复调页面 | 全站建设节奏拖延 | 建系统信号充足度 |
| 对抗AI | 屏蔽AI爬虫、JS反爬 | 放弃AI搜索流量入口 | 建AI友好结构争取引用 |
这三个误区的共同根源是用传统SEO思维应对AI搜索时代。传统SEO的核心假设是"算法是可分析的",AI搜索时代的核心假设变成"算法是有黑盒部分的"。前提变了对策也要变,不是细化原来的方法,而是换一套思维框架。
避开这三个误区的实操方法很简单:把"AI判断不可完全预测"作为前提,建"全站强信号"作为策略,看"长期趋势"作为反馈。这三件事做对,AI黑盒带来的排名波动会从困扰变成可管理的常态。
14项落地清单:AI黑盒时代SEO怎么按可解释信号建内容?
把上面16周走完的全部动作压缩成14项可执行清单。每一项对应一个AI能稳定识别的可解释信号,可以直接拿去对照自家站的执行进度。
| 序号 | 动作 | 对应的可解释信号 |
|---|---|---|
| 1 | 全站Schema结构化数据全覆盖 | 事实信号、实体信号、关系信号 |
| 2 | 品牌Wikipedia实体页建立 | 实体权威信号 |
| 3 | 作者Person Schema含背景与外部署名 | 作者权威信号 |
| 4 | 产品实体建立并关联制造商 | 产品实体信号 |
| 5 | 事实段落工程(结论独立成段) | 事实抽取信号 |
| 6 | 引用关系网(Reddit、Quora、媒体) | 外部引用信号 |
| 7 | 核心页每500字至少3个事实点 | 事实密度信号 |
| 8 | H2拆到8到12个 | 结构清晰信号 |
| 9 | FAQPage Schema每篇至少5条 | 问答匹配信号 |
| 10 | llms.txt列可引用内容清单 | AI爬虫导航信号 |
| 11 | robots.txt明确AI爬虫策略 | 授权合规信号 |
| 12 | 每周三引擎引用监测 | 引用可见性反馈 |
| 13 | 对比测评内容(带方法和数据) | 权威背书信号 |
| 14 | 客户案例与真实数据复盘 | 真实经验信号 |
这14项落地清单的核心思路是反向工程——既然不知道AI黑盒在判断什么,那就把AI能稳定识别的所有信号都建到位,让AI在任何状态下都能找到充足的判断依据。这种"信号充足度"策略在AI黑盒时代是最稳的SEO打法。
实战中跑过类似策略的几十个站点,能把14项做到位8项以上的,6个月内排名波动幅度都明显收窄。最容易被忽略的是第10项llms.txt和第12项引用监测——这两项不直接产生流量,但是检验AI黑盒判断稳定性的关键观测窗口。跳过这两项后面的优化都缺反馈数据,效果停留在感觉层面。
14项里有3项的投入产出比特别高,值得最早做:第3项作者Person Schema、第7项每500字至少3个事实点、第14项客户案例与真实数据复盘。这3项共同构成"作者权威+事实密度+真实经验"三角,是AI在任何引擎、任何查询场景下都会优先识别的强信号组合。把这3项做到位之后再补其他11项,整体节奏比平均推进要快40%以上。
另外还有一组配对动作能放大效果——第1项Schema全覆盖配第5项事实段落工程一起做,第2项品牌Wikipedia实体页配第6项引用关系网一起做。前一组让AI能"识别",后一组让AI能"信任"。识别加信任两件事都到位,AI给你的稳定排名空间会比单独做任何一项大3倍以上。
常见问题解答
什么是AI黑盒?为什么搜索算法工程师都怕这件事?
AI黑盒指深度学习模型内部决策不可被人类直接解释。搜索算法工程师怕的是出现异常排名时无法定位是哪一层权重哪一组特征出错,只能整体回滚或重训,调试周期长成本高,无法精细化优化。这件事让搜索引擎不敢把决定权全交给AI。
XAI可解释AI到底要解决什么问题?
XAI解决AI的决策可被人类理解和验证的问题。具体方法包括特征重要性可视化、注意力机制可视化、反事实解释、规则提取等。目的是让人类知道AI为什么做这个判断而不是另一个,从而能调试、能信任、能合规。这是AI落地高风险场景(医疗、金融、搜索)的前提。
Google RankBrain上线10年了为什么还没全面接管排名?
因为RankBrain是黑盒。Google工程师承认对RankBrain内部判断机制理解有限,一旦异常排名出现无法直接调试。所以RankBrain至今仍作为众多排名信号之一参与排序,而不是独立决定排名。这种混合架构既利用AI能力又保留可调试性。
DARPA XAI项目走到哪一步了?对SEO有什么影响?
DARPA XAI项目2017年启动,11个研究小组分3条路线推进。2021年项目正式结束,技术成果转移到产业。但目前主流搜索引擎仍未大规模采用XAI技术,预计需要再5到8年才能真正落地搜索算法。这给SEO留下重要窗口期。
AI落地搜索算法的5维瓶颈具体指哪些?
可解释性、可调试性、可信任、可合规、可优化。任何一维不达标都无法让AI独立决定排名。当前各维度都处于过渡期,XAI技术成熟还需要几年时间,给SEO留下了至少5到8年的窗口期。
AI黑盒时代SEO团队怎么按可解释信号建内容?
围绕AI可识别的明确信号建内容——结构化Schema、清晰的实体绑定、可被算法直接抽取的事实段落、明确的作者权威信号、可验证的引用关系。这些都是AI在黑盒判断中能稳定识别和加权的信号源。信号充足度是关键策略。
搜索引擎全面采用XAI还需要多少年?
保守估计5到8年。需要先解决XAI技术成熟、计算成本可控、判决可被验证三个前置条件。在此之前搜索引擎会继续采用AI辅助决策加传统信号兜底的混合模式,SEO的传统优化方法仍然有效,但要逐步增加AI友好信号建设。
这两个来源对应文中两个核心论证(Google搜索多信号设计、XAI技术路线现状)。建议读到对应段落时同步打开参考,更全面理解AI在搜索算法工程实践中的真实约束。
权威参考资料
本文涉及的AI黑盒、XAI、搜索算法可解释性几个核心论证的官方与学术依据。
本文标题:《XAI让AI全面接管搜索算法?5维黑盒瓶颈拆解》
本文链接:https://zhangwenbao.com/explainable-ai-search-algorithm.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0