SEO排名得分怎么测算?保哥把R-Score公式拆成5个打分维度和1个惩罚乘数
本文目录
- 为什么SEO排名这件事,老让人觉得像在拜神?
- R-Score这个公式,整体在算的是一件什么事?
- 技术SEO(UIS)是怎么把LCP、CLS、INP揉成一个分的?
- 内容质量(CQS)里,为什么要单独塞一个“信息增益”?
- 链接权威(LS)的分数,为什么不是反链越多越高?
- 那个会“惩罚”你的乘数(RB加QB),到底是怎么回事?
- 内容会随时间掉分?时效衰减e^(−λΔt)怎么用?
- 站点权威(CSA)为什么是“加”在最后,而不是乘进去?
- 不如拿一个成长期的站,把这套公式从头手算一遍?
- 搜索意图不一样,同一个页面分数为什么能差一大截?
- 这个R-Score,到底该怎么用才不跑偏?
- 用这个工具,有哪几件事千万别做?
- 第一次上手,具体怎么操作?
- 常见问题解答
- R-Score算出来到底多少分才算好?
- 这个公式是谷歌官方的算法吗?
- 信息增益IGS这种主观分,自己怎么打才靠谱?
- 为什么用户行为(RB加QB)是乘进去的,权重看着不大却影响这么猛?
- 时效衰减那个λ值,我怎么知道自己的内容该填多少?
- 这个分能直接拿去跟老板或客户汇报SEO进度吗?
- 权威参考资料
摘要:把排名当玄学的人,通常死在同一个地方:说不清自己到底差在哪。R-Score这套打分模型的价值,不在于最终那个分数有多准,而在于它逼你把“感觉不行”拆成6个能各自打分、各自归因的格子——技术、内容、外链、用户行为、时效、站点权威。真正会用它的人,盯的从来不是R等于几,而是哪一格拖了后腿、那一格的提升成本你当下又付不付得起。这篇带你把每个格子的算法掰开,连它算不准的地方也一并交代清楚。
为什么SEO排名这件事,老让人觉得像在拜神?
做独立站和外贸站的朋友,多半都有过这种时刻:给一个页面加了几条外链、把标题改得更勾人、又往正文里塞了两段,然后每天刷排名,眼巴巴等它动。有时候动了,你也说不清是哪一下起的作用;更多时候纹丝不动,你连该往哪儿使劲都不知道。问十个同行,能给你十种说法——有人让你死磕外链,有人说现在拼的是内容,还有人神神秘秘地告诉你“谷歌看的是用户喜不喜欢”。
问题不在于这些说法谁对谁错,它们多半都对一部分。问题在于,没有一个人能告诉你:这些因素各占多少分量,怎么加在一起,才决定了你这个页面此刻到底有没有竞争力。Google排名因素全清单那篇能告诉你“有哪些因素”,却没法告诉你“这些因素怎么加权算成一个能比较的数”。少了这一步,排名就永远停在玄学阶段。
保哥把这些年判断一个页面能不能打的经验,硬写成了一个能算的模型,做成了一个在线小工具——SEO排名得分测算工具。你把页面的各项指标填进去,它吐给你一个0到100的R-Score,外加每个维度的子分和一句话诊断。这篇文章不打算只教你点哪个按钮,而是把它背后那个公式整个剖开:每一项是怎么折算的、为什么这么设计、又有哪些地方它根本算不准。看懂了原理,你才知道这个分什么时候可信、什么时候得打个折扣。
R-Score这个公式,整体在算的是一件什么事?
先把完整公式摆出来,别被它吓到,拆开看其实很直白:
R =(w₁·UIS + w₂·CQS + w₃·LS)× e^(−λΔt)×(RB + QB)+ w₄·CSA
翻成大白话就是四件事拼起来。括号里那一坨w₁·UIS + w₂·CQS + w₃·LS是“基础底子”——技术、内容、外链按权重加权,这是你页面的硬实力;乘上e^(−λΔt)是“时间打折”——内容越旧分越少;再乘上(RB + QB)是“用户投票乘数”——用户买不买账,直接放大或缩小你的底子;最后加上w₄·CSA是“站点权威兜底”——大站的家底,单独加在最后。
这里最值得琢磨的是它为什么用“先乘后加”这种混搭结构,而不是把所有项一股脑加起来。乘法部分体现的是“短板一票否决”:用户行为乘数要是跌破1,会把你前面辛苦堆的基础分直接缩水,再好的内容也救不回来。加法部分体现的是“护城河兜底”:站点权威是加上去的,意味着大站就算单页做得平庸,靠家底也能保一个底分。这套结构不是拍脑袋来的,它的骨架借自信息系统领域一个叫DeLone与McLean成功模型的经典框架——那套模型1992年提出、2003年修订,被学术界引用了上万次,核心观点是“再好的系统,只有真正被人频繁、满意地使用,才产生价值”。把它搬到SEO场景,就成了“再好的页面,得被用户用脚投票认可,排名才立得住”。
当然得说清楚:谷歌真实的排名系统是上千个信号在动态博弈,Google算法更新完整盘点里那一长串系统名字就够你头大。R-Score是一个降维近似,拿七八个你能拿到数据的关键变量,去逼近那个黑箱的判断。它的价值不在“精确复刻谷歌”,而在“把你的直觉翻译成能拆、能比、能盯的数字”。
技术SEO(UIS)是怎么把LCP、CLS、INP揉成一个分的?
UIS这一项管的是技术底子,全称是用户界面与系统质量。它的算法把Core Web Vitals的三个核心指标先各自归一化,再加权。三个指标的折算是这样:
LCP分 =(5 − LCP秒数)÷ 5 × 100,CLS分 =(0.3 − CLS)÷ 0.3 × 100,INP分 =(500 − INP毫秒)÷ 500 × 100,三个都掐在0到100之间。
举个实数:LCP是2.4秒,代进去就是(5减2.4)除以5乘100,得52分;CLS是0.09,算出来70分;INP是190毫秒,得62分。看出门道没有——LCP的2.4秒明明在谷歌“良好”的2.5秒门槛内,折算却只有52分。这是故意的,因为达标只是及格线,模型想拉开“及格”和“优秀”的差距,逼你往1秒出头那个区间卷。
然后六项加权凑成UIS:UIS = LCP分×0.30 + CLS分×0.20 + INP分×0.20 + 移动适配×0.15 + HTTPS×0.05 + CWV整体×0.10。LCP权重最高占三成,因为它是用户对“快不快”的第一感知;HTTPS只给5%,因为这年头它是标配,有等于没说、没有才扣分。这套指标的权威定义可以对着web.dev — Interaction to Next Paint(INP)指标说明和web.dev — Web Vitals指标体系总览来核,工具里的折算逻辑就是照这个体系搭的。
实操里保哥见过太多人把劲使错地方。一个做家居用品的外贸站,店主花了三周改文案、加内链,排名一动不动,跑一遍工具才发现UIS只有48——首屏那张4MB的大banner把LCP拖到4秒多。换成WebP加上CDN预加载,两天的活,UIS从48冲到79,两周后那批长尾词集体往前挪。技术债不还,内容写出花也是白搭。想更系统地补这块,页面速度SEO实战和Core Web Vitals在AI搜索时代的ROI测算这两篇可以接着读。
内容质量(CQS)里,为什么要单独塞一个“信息增益”?
CQS这一项最有意思,因为它没有像大多数SEO评分那样只数字数、看关键词覆盖,而是专门留了一大块给“信息增益”。完整算法是六项加权:
CQS = 关键词覆盖×0.15 + 字数分×0.10 + 排名占比×0.10 + 原创度×0.25 + 信息增益×0.25 + Schema×0.15(其中信息增益IGS是0到10分,乘10后参与;原创度是0到100的百分值)。
注意权重分配:原创度和信息增益两项加起来占了整整一半。换句话说,在这个模型眼里,内容质量的胜负手不是你写了多少字、铺了多少关键词,而是你提供了多少别人没有的东西。这恰恰踩中了当下最大的痛点:AI生成内容铺天盖地,满网都是把TOP10揉一揉吐出来的“正确的废话”,谷歌的反同质化机制盯的就是这个。
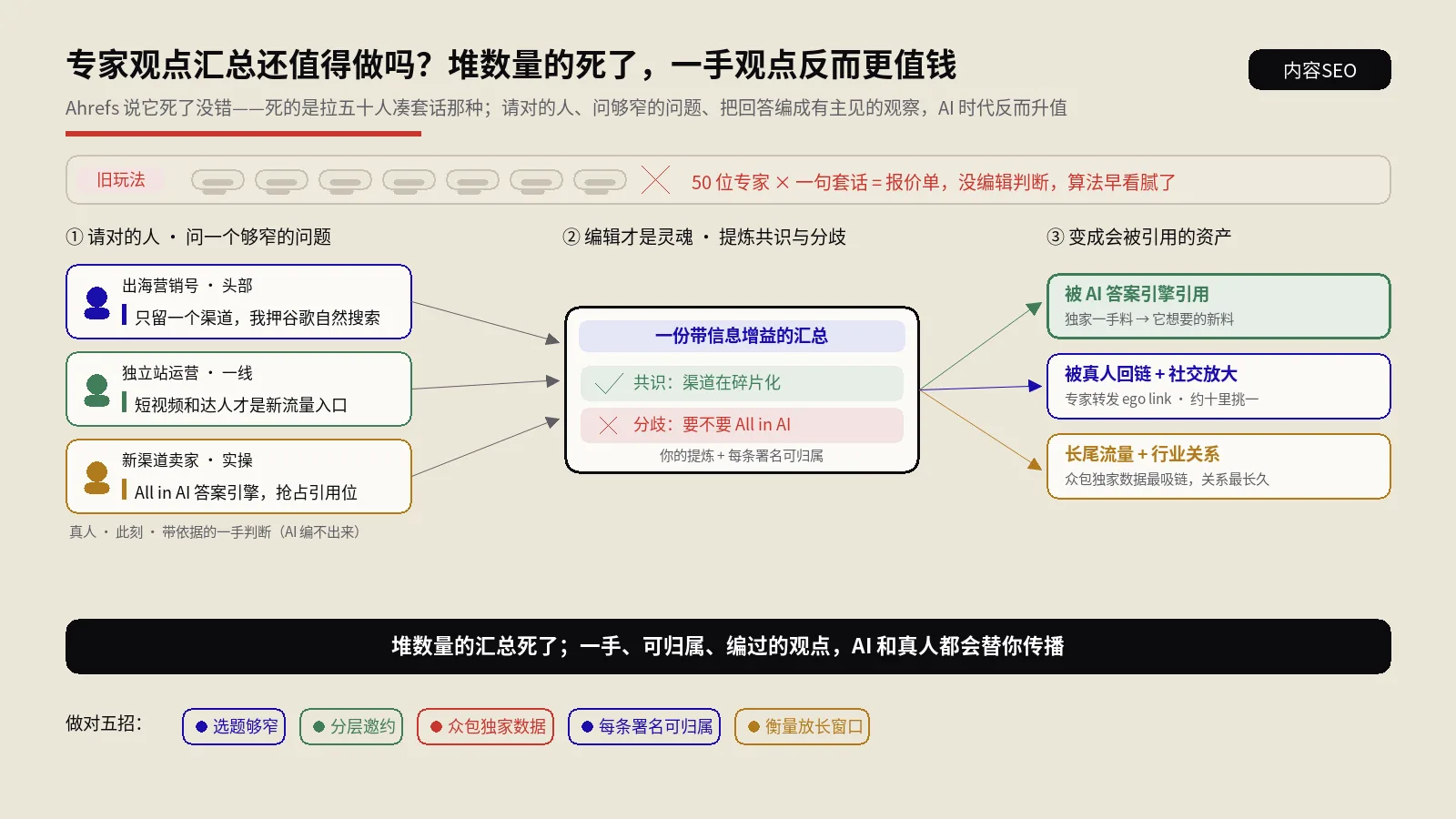
信息增益(IGS)这个分得你自己打,工具抓不到。怎么打?保哥的土办法是:把目标词搜出来,前10名逐篇读完,然后诚实地问自己——我这篇里有几样东西是这10篇里一个都找不到的。全是套话、东拼西凑,0到3分;有那么一两个独到观察、一组别人没有的数据,4到6分;通篇是自家一手调研、实测复盘、别人复制不了的框架,7到10分。这把尺子怎么用,可以参考AI搜索为什么奖励深度原创内容那篇的拆法。
这里有个反直觉的坑。一个做宠物用品的客户,听说“内容要深”,把一篇2000字的喂养指南扩到5000字,结果跑工具CQS几乎没动。一看就懂:字数分本来就是封顶项,2000字早顶到天花板了,多写3000字一分不加;他扩的全是网上能搜到的通用知识,IGS还是5分原地踏步。后来保哥让他砍掉一半水分,补进自家3000份问卷的喂养习惯数据,IGS从5提到8,CQS这才真往上走。内容的增长点在“独家”不在“凑长”,这是CQS这套权重想替你校正的认知。
链接权威(LS)的分数,为什么不是反链越多越高?
LS管的是链接权威和E-E-A-T,算法是四项相加再封顶:
LS = min(100,DR×0.35 + min(30,log₁₀(引荐域名数 + 1)×10)+ 高质量链接占比×0.3 + E-E-A-T×0.2)。
魔鬼藏在log₁₀这个对数里。反链的引荐域名数不是线性加分,而是取了对数还封顶30分。这意味着什么?从10个引荐域名涨到100个,log₁₀从1变到2,多拿10分;可从100个涨到1000个,log₁₀从2才到3,同样只多10分——你多搞了900个域名,回报和前面多搞90个一样。反链的边际效用是急剧递减的,这道对数就是模型替你踩的刹车,免得你陷进“数量竞赛”。
更狠的是后面那个YMYL修正。如果行业选了医疗或金融,E-E-A-T达标(60分以上)会给LS乘1.12的加成,不达标直接乘0.82的惩罚。一个做跨境保健品的客户怎么都上不去,根子就在这:内容外链都不差,但页面上没有任何执业资质、没引用权威机构来源,YMYL惩罚一乘,LS被砍掉近两成。补上专业背书和WHO一类的权威引用后才缓过来。E-E-A-T这套信号具体怎么搭,E-E-A-T信号清单讲得比较细。
所以LS这一项想传达的判断是:盯质量别盯数量。一条来自高权威站点正文、几乎独家指向你的链接,胜过一百条页脚目录里的废票。想把引荐域名的“质”做上去,谷歌SEO外链建设实战里那些白帽路子比批量买链靠谱得多;想搞清楚DR这个数到底怎么涨,可以看网站权威DR怎么提升。
那个会“惩罚”你的乘数(RB加QB),到底是怎么回事?
前面提过,用户行为是乘进去的,这是整个模型最该被重视的设计。它由两块组成。留存行为RB:
RB = 0.15 + min(1,CTR÷10)×0.45 +(100 − 跳出率)÷100×0.20 + min(1,回访率÷50)×0.20。
交互行为QB:QB = 0.10 + min(1,停留秒数÷300)×0.50 + min(1,浏览深度÷5)×0.40。
两个相加就是那个乘数,大致在0.25到2.0之间浮动,中性点在1.0附近。它的杀伤力全在“乘”这个字上。假设你技术、内容、外链加权后的基础底子有60分,时效几乎不衰减,结果用户进来三秒就退、点击率惨淡,乘数算出来0.8——60乘0.8直接变48,凭空蒸发12分。反过来,停留久、回访高、标题勾人把点击率拉满,乘数冲到1.3,60就放大成78。同样的内容和外链,用户买不买账,能在结果上差出三四十分。
这就是Navboost这套机制越来越要命的原因——谷歌手里攥着海量真实点击与停留数据,用户用脚投票的权重,被悄悄塞进了这个乘法里。关于它到底是不是排名因子、泄漏文档怎么说的,NavBoost泄漏与品牌力排名信号那篇有实证拆解;想系统理解这些行为信号怎么反向重塑SEO,用户行为信号怎么重塑SEO讲得更全。
一个做3C配件的站吃过这个亏:产品页内容、外链都在水准之上,排名却卡在第二页上不去。跑工具一看,乘数0.91——标题平淡点击率低,首屏一上来就是参数表没人愿意往下看。把标题加上具体型号和年份提点击率、首屏改成一句话直接回答用户最关心的兼容性问题降跳出,两个月后乘数回到1.15,排名才松动。很多人卡在第二三页死活上不去,病根不在内容不够好,在用户不喜欢。
乘数跌破1要怎么救?拆开RB和QB这两块看,动作其实很具体。点击率低,先动标题和描述——加上具体数字、年份、能勾起好奇的承诺,让你在搜索结果页那一排蓝链接里更扎眼;这是性价比最高的一步,改一行字就可能把CTR从1.x拉到3以上。跳出率高、停留短,问题多半出在首屏——把用户最想要的答案直接怼到第一屏,别让人滚半天还没看到正文,再配上目录、关键结论加粗、必要时插一段视频或可交互的小工具,把人留住。浏览深度浅、回访率低,靠的是文末的相关推荐和内容矩阵——让看完这篇的人有下一篇想点的,让有需要的人记得回来。这四个动作对应的正是RB与QB算式里的四个变量,哪个分低补哪个,比无头苍蝇式地“再优化优化”精准得多。
内容会随时间掉分?时效衰减e^(−λΔt)怎么用?
公式里e^(−λΔt)这一项专门模拟“内容放久了排名会凉”。Δt是发布到现在的天数,λ是衰减常数,由内容类型决定。这是个指数衰减,λ越大掉得越快:
| 内容类型 | λ取值 | 大致衰减节奏 |
|---|---|---|
| 突发新闻 | 0.01 | 60天衰减到约55% |
| 趋势热点 | 0.005 | 半年掉一大截 |
| 产品促销页 | 0.002 | 季度级保鲜 |
| 常青科普 | 0.0005 | 一年只掉约18% |
这一项算出来的那个零点几的小数,本身不重要,它真正的用处是帮你排内容更新的节奏。一个做户外装备的外贸独立站,把所有内容一视同仁半年更一次,结果它的“2026装备趋势”这类趋势文早凉透了,而“帐篷怎么选”这种常青指南其实不用动还浪费人力。按λ重新排期后,趋势类月更、产品页季度更、常青库一年翻新一次,更新人力没多花,整站新鲜度反而更稳。新闻站要周更,百科类季度翻一次就够——这是时效衰减项替你做的资源分配。
站点权威(CSA)为什么是“加”在最后,而不是乘进去?
CSA是站点级的权威家底,算法是四项相加再封顶:
CSA = min(100,min(40,log₁₀(月流量 + 1)×8)+ min(30,log₁₀(品牌词搜索量 + 1)×10)+ min(15,域名年龄×2)+ 15)。
注意它结构上和别的维度不一样——它是被w₄加权后加在公式最末尾的,不参与前面的乘法。这个设计藏着一个很现实的判断:大站的权威是一道护城河,哪怕某个单页做得平庸,靠站点家底也能兜一个底分,这就是为什么权威站随手发篇文章都能排得不错。但请注意w₄默认只有0.15,权重不高——意思是这道护城河对小站基本是远水解不了近渴,你刚起步,流量、品牌词、域龄都接近0,CSA那个+15的常数底之外几乎拿不到分,别指望靠它逆袭。这种“大站凭质量分躺赢”的机制,谷歌专利Google专利US9760641B1 — Site quality score(站点质量分)里描述的正是一类基于站点整体信号的质量打分逻辑。
对新站来说,CSA给的启示反而是“别在这儿较劲”。流量、品牌词、域龄这三样全靠时间熬,急不来。新站能掌控的是前面那几项乘法里的东西:把CWV全做绿、内容堆够信息增益、想办法别让用户秒退。这跟“权威是结果不是手段”说的是同一件事——盯着CSA这个结果使劲,是本末倒置。
不如拿一个成长期的站,把这套公式从头手算一遍?
光看公式容易犯晕,咱们拿工具里“成长期站”那组预设数据,一步步手算到底,你就彻底去神秘化了。这组数据大致是:LCP 2.4秒、CLS 0.09、INP 190毫秒、移动适配满分、HTTPS有、CWV部分通过(70);关键词600个、字数2000、排名占比22%、原创度78、IGS 5、有Schema;DR 35、引荐域名200、高质量链接占比25%、E-E-A-T中等(60);CTR 3.8%、跳出率42%、停留130秒、浏览深度2.5、回访率18%;月流量8000、品牌词300、域龄3年、发布45天、λ取0.002,权重用默认的0.30/0.30/0.25/0.15。
先算UIS:LCP分52、CLS分70、INP分62,代进加权式得52×0.30 + 70×0.20 + 62×0.20 + 100×0.15 + 100×0.05 + 70×0.10 ≈ 69。
再算CQS:关键词覆盖封到20×0.15、字数分约66.7×0.10、排名占比44×0.10、原创度78×0.25、IGS 50×0.25、Schema 10×0.15,加起来≈ 47.6。
然后LS:35×0.35 + log₁₀(201)×10 + 25×0.3 + 60×0.2 ≈ 12.3 + 23 + 7.5 + 12 ≈ 54.8。
用户行为:RB约0.51、QB约0.52,乘数≈ 1.03,刚过中性线一点点。时效衰减e^(−0.002×45)≈ 0.914。站点权威CSA约77。
最后合:基础底子0.30×69 + 0.30×47.6 + 0.25×54.8 ≈ 48.7;总分R = 48.7 × 0.914 × 1.03 + 0.15×77 ≈ 45.8 + 11.6 ≈ 57。R等于57,落在50到69区间,结论是“TOP10可达”。
看完这趟手算,你应该能体会到这个分的真实含义了:它不是什么神谕,就是把你填进去的几个数,按一套固定规则揉成一个能横向比较的刻度。这个站要往上走,最划算的不是再去堆外链(LS 54.8已经不算差),而是把CQS那47.6拉起来——补独家数据提IGS,性价比最高。这种“一眼看出该补哪块”的能力,才是R-Score给你的真东西。你可以直接打开这个测算工具把自己的数填进去,它会把这趟计算自动跑一遍并标出最弱的环节。
搜索意图不一样,同一个页面分数为什么能差一大截?
这是很多人没意识到的一层。前面那四个权重w₁到w₄不是固定的,工具会按搜索意图自动调。四套配置长这样:
| 搜索意图 | w₁技术 | w₂内容 | w₃外链 | w₄站点 |
|---|---|---|---|---|
| 信息型(How to) | 0.20 | 0.40 | 0.20 | 0.20 |
| 交易型(Buy) | 0.35 | 0.20 | 0.25 | 0.20 |
| 导航型(Brand) | 0.15 | 0.15 | 0.20 | 0.50 |
| 商业调研(Best) | 0.20 | 0.35 | 0.25 | 0.20 |
逻辑很顺:信息型查询用户是来学东西的,内容权重拉到0.40;交易型查询用户要下单,页面体验和加载速度(技术)顶上来到0.35;导航型查的是品牌,谁的站点权威大就该是谁,w₄飙到0.50。这意味着同一个页面,套在不同意图上,分数可能天差地别——一个技术过硬但内容平平的产品页,按交易型算可能75分,按信息型算只剩45分。这也解释了一个常见困惑:为什么你的页面在某些词上排得动、换一批词就趴窝。不是页面变了,是你撞上了权重结构不利于你的那类查询。这背后的道理,和“不存在一张放之四海皆准的通用权重表”是一回事——同一个信号在不同查询里的分量本就天差地别。
这个R-Score,到底该怎么用才不跑偏?
工具是好工具,用错了照样误事。保哥日常最常用的是三个场景。
第一个是竞品差距量化。别再用“感觉他比我强”这种话折磨自己。把你和竞品的数据分别填进去,差距立刻具体成数字:他的用户行为乘数1.35我才0.92,或者我的内容分输了他20分。差在哪、差多少、先补哪块,一目了然。一个做女装的独立站这么一比才发现,自己外链其实不输对手,真正的鸿沟在停留时间——人家详情页有买家秀视频和搭配建议,自己干巴巴几张图,难怪乘数被甩开。
第二个是排名停滞诊断。专治那种卡在第二三页死活上不去的页面。逐维度跑一遍,工具会精确点出最弱那一环:是CWV拖了后腿、内容缺信息增益、还是外链太薄。很多站长埋头猛改内容,结果真正的瓶颈在加载速度上,方向错了越努力越糟。量化诊断的意义就是别让你在错误的方向上拼命。
第三个是内容规划和KPI汇报。动笔写一篇大文章前,先按预期指标估一下R值,能不能进TOP10心里有数,免得辛苦写两周才发现这个词根本竞争不过。对老板和客户,则把R值和子维度做成月度趋势表——“技术分56到78、内容分42到67、R值38到61”这种摆数的汇报,比罗列做了哪些动作有说服力得多。一个做母婴用品的客户就靠这张趋势表,把SEO预算的续签谈得顺顺当当。
用这个工具,有哪几件事千万别做?
越是好用的工具,越得讲清楚它的边界,不然会被用成新的迷信。这几条保哥得把丑话说前头。
第一,R值是策略参考,不是绝对真理。谷歌真实算法上千个信号且动态变化,这个模型给的是一个高价值的方向预测,不是名次承诺。R算到72,不等于你明天就在前三;它的意思是“按这套逻辑,你这个页面具备进前列的底子,剩下看竞争和运气”。把它当指南针,别当GPS。
第二,千万别为了凑分而过度优化。这是最容易掉进去的坑。看到某个子维度分低,就拼命往那儿堆——CQS不够就疯狂加字数注水,LS不够就批量买链。结果分是上去了,页面却被你做坏了。模型是用来找方向的,不是用来刷的;你刷的是模型,谷歌看的是真实的用户体验,两者一旦脱节,分数再漂亮也没用。
第三,IGS和E-E-A-T这种主观分,打分越客观测算越准。这两项工具抓不到,得你自己对着竞品评。要是手一抖给自己放水——明明套话连篇却打个IGS 8分——那算出来的R值就是自欺欺人,最后误导的是自己的排期和预算。诚实打分,是这套工具能不能帮到你的前提。
说到底,这个工具替代的是“拍脑袋”,不是替代“做SEO”。它帮你把模糊的判断变清晰,把该使的劲指出来,但具体的活还得一锤一锤敲。把它当成每月给核心页做一次“量化体检”的家庭医生,挺好;把它当成包治百病的灵丹,迟早出事。
第一次上手,具体怎么操作?
流程不复杂,几分钟的事,分六步走。
第一步,填站点信息。输入域名、选行业、定搜索意图和内容类型。选了YMYL行业会自动加大E-E-A-T的权重,选了内容类型会自动带出对应的λ值,不用自己记。
第二步,填各维度数据。技术、内容、外链、用户行为、站点权威逐项填。手头数据从哪来?CWV去PageSpeed Insights查,外链数据看Ahrefs或Semrush,用户行为翻GA4和GSC,IGS自己对着竞品打分。懒得逐个填的话,工具备了“权威大站、成长期站、全新网站、YMYL医疗、电商产品页”几组预设,点一下先体验。
第三步,调权重。点“按意图自动调权”让它按你选的意图分配,或者手动改w₁到w₄做实验。
第四步,点计算。数据提交到服务端按公式算,返回R值、六个子分、那个用户行为乘数、排名预测和分维度的优化建议。
第五步,看建议。红色是紧急、橙色是重要、绿色是良好,每条都配了具体能落地的动作,照着最弱那项先动手。
第六步,迭代追踪。改完重新跑,盯R值的变化,目标是把它推过70。建议每月固定跑一次,攒出一条趋势线,比单次的分数有用得多。
说再多不如自己跑一遍。打开SEO排名得分测算工具,拿你手上最在意的那个页面,把数据填进去,看看它到底卡在哪一格——很可能和你之前以为的不是一回事。
常见问题解答
R-Score算出来到底多少分才算好?
保哥设的档位是这样:R大于等于70进TOP3的概率高,50到69基本能摸到TOP10,30到49卡在TOP20一带,低于30就得大改。但有个前提常被忽略——这是同一关键词竞争位上的相对预测,不是绝对承诺。同样70分,竞争度低的长尾词可能稳进前三,红海大词70分照样在第二页。所以分数要配着目标词的竞争强度一起看,光看R值会骗自己。YMYL那种医疗金融的词,门槛还要再往上抬一截。
这个公式是谷歌官方的算法吗?
不是,谷歌真实算法是上千个信号动态加权的黑箱,没人能完整复现。R-Score是一个降维近似:底层框架借了信息系统领域那个被引用上万次的DeLone与McLean成功模型,再把近年谷歌API泄露文档里露出来的信号、以及Navboost这类用户行为机制拼进来做SEO适配。它的作用是把“凭感觉”变成“可拆解、可归因、可对比”,帮你找方向,不是替你保证名次。把它当体检报告用,别当判决书。
信息增益IGS这种主观分,自己怎么打才靠谱?
办法很土但有效:把目标词搜出来,TOP10逐篇读一遍,然后问自己一句——我这篇里有多少东西是这10篇里一个都没有的。全是套话、东拼西凑别人观点,打0到3;有一两个独到的点、一组别人没有的数据或截图,打4到6;通篇是自家调研、一手实测、别人复制不了的框架或工具,打7到10。关键是诚实,别给自己放水。打分越客观,整套测算越准;自欺欺人地打高分,最后骗的是自己的排期表。
为什么用户行为(RB加QB)是乘进去的,权重看着不大却影响这么猛?
因为它是乘数不是加项。技术、内容、外链三块加权算出一个基础分,这个基础分要乘上(RB加QB)。这个乘数大致在0.25到2.0之间晃,中性值在1.0附近。一旦用户进来秒退、点击率低得可怜,乘数跌到0.8,等于把你辛辛苦苦堆起来的基础分直接打八折——内容再好外链再硬也扛不住。反过来停留久、回访高、点击率漂亮,乘数冲到1.3,又能帮你把基础分放大。这正是Navboost越来越重要的写照:用户用脚投票,权重藏在乘法里。
时效衰减那个λ值,我怎么知道自己的内容该填多少?
按内容保鲜期选就行。突发新闻、热点解读这类,λ取0.01,60天左右分数就衰减掉将近一半,逼你要么快要么频繁更新;产品页、促销页这种,λ取0.002;行业趋势类0.005;像“什么是反链”这种常青科普,λ取0.0005,放一年也就掉18%上下。工具里选了内容类型会自动带出对应λ,不用自己记。它的真正用处不是算那0.0几的小数,而是帮你排更新节奏:新闻站得周更,常青库季度翻新一次就够。
这个分能直接拿去跟老板或客户汇报SEO进度吗?
能,而且比“这个月做了哪些优化”这种话术好用得多。保哥的建议是把R值和6个子维度做成一张趋势表,每月固定时间各页跑一次,连续记。汇报时不说虚的,直接摆数:技术分从56抬到78(CWV这个月全过了),内容分从42到67(补了一组自家调研数据),R值从38爬到61,按模型推算下季度有机会进TOP10。老板要的是能跟踪、能问责、能预期的东西,子维度拆解恰好把SEO这件“看不见的事”变得看得见。但记得提醒一句:这是预测不是保证,别把R值写进对赌KPI里。
权威参考资料
本文标题:《SEO排名得分怎么测算?保哥把R-Score公式拆成5个打分维度和1个惩罚乘数》
本文链接:https://zhangwenbao.com/seo-rank-score-r-score-formula-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0