AI答案为什么不引用你?训练数据共现是底层机制
本文目录
- AI回答为什么有的品牌一直出现你却从来没出现?
- LLM怎么把品牌从训练数据里拽出来回答用户?
- GEO和SEO到底是不是一回事?
- 训练数据里的语义共现凭什么决定AI引用率?
- 大品牌靠什么在AI答案里反复被点名?
- 小品牌没有全网共现资源怎么挤进AI答案?
- Google Business加B2B平台加社交媒体怎么布共现信号?
- 手工蜡烛DTC16周怎么从0引用到月920次的?
- AI答案共现优化的成本和回报怎么算?
- 共现策略怎么避免被识别为AI投毒?
- 常见问题解答
- GEO是不是要替代SEO了?
- 中小品牌做AI答案出现率优化大概要多少预算?
- 没有Wikipedia条目AI能引用我吗?
- 本地化和长尾化哪个回报快?
- Reddit上做共现优化会不会被识别为营销账号封禁?
- AI引用次数怎么监测?有哪些工具?
- AI共现优化和投毒手段有什么本质区别?
- 权威参考资料
摘要:AI回答里到底出现哪个品牌,不是看你做了什么GEO动作,而是看你的品牌在LLM训练数据里和哪些查询场景、产品特征、竞争对手反复一起出现。这是LLM预训练阶段就被写死的——大品牌靠"在权威源中被高频提及"的全网共现攻入答案池,中小品牌只能走"本地化+长尾化"的差异路径切口。保哥手里一家出海手工蜡烛和香薰蜡烛DTC(豆蜡蜡烛+香薰精油蜡饰+蜡杯系列+蜡芯耗材,客单35-180美元,北美中产女性+西欧家居香薰人群)从2025年Q4到2026年Q1的16周里,没去搞那种"GEO投毒"花招,纯靠5步本地长尾路径——Google Business品类完善+垂直B2B目录提交+Reddit/Wikipedia实体认证+Top10榜单挤位+主题集群内容投放——把ChatGPT/Perplexity/Gemini三家对核心场景查询的引用率从0%拉到月920次,月自然流量从1200次涨到6800次(5.67倍),自然营收占比从7%升到26%。这篇把生成式AI怎么把品牌从训练数据里拽出来、GEO是不是新职业、训练数据共现的具体信号有哪几类、大小品牌策略分流、5步本地长尾路径、共现优化怎么避免被识别为AI投毒,通通讲清楚,给一份可落地的中小品牌AI答案出现率建设手册。
AI回答为什么有的品牌一直出现你却从来没出现?
2026年Q1有个独立站客户做手工豆蜡蜡烛和香薰蜡烛,跑来问我:“我们这个品类一年Google搜索量也不小,店铺产品页排在第一页,为什么用户跑去ChatGPT问'best soy wax candle for small living room',永远是Yankee Candle、Diptyque、Bath & Body Works这种大品牌被点名?我们品牌从来没出现过。”
这个问题这一两年保哥从太多DTC客户那听到。本质不是优化没做到位,而是“在AI答案里出现这件事,按的根本不是传统SEO的那套规则”。传统SEO优化的目标是让Google搜索结果页排到前列,AI答案出现率优化的目标是让你的品牌在LLM预训练数据里和特定查询场景反复一起出现。这俩游戏的赛道完全不同。
那个手工蜡烛客户后来按保哥团队的方法走了16周路径,从ChatGPT/Perplexity/Gemini三家对"home fragrance soy candle small space"、"non-toxic scented candle for kids' room"、"long burn time pillar candle gift"这21个核心场景查询的引用率,从0%涨到月920次出现,月自然流量从1200到6800(5.67倍),自然营收占比从7%升到26%。这套打法没用任何"投毒"手段,是基于对LLM训练数据怎么形成的理解,做了系统的语义共现工程。这篇要回答的就是这套打法的底层机制和具体做法。
LLM怎么把品牌从训练数据里拽出来回答用户?
要看懂为什么有的品牌AI总是不引用你,要先看清生成式AI产生答案的流程。简化说大概是这样:
- 预训练阶段。GPT-4/Claude/Gemini这类大模型在训练时吞下PB级的互联网文本——Common Crawl快照、Wikipedia全量、Reddit/StackExchange/Quora公开内容、新闻媒体存档、电商站点抓取、专业论坛/学术论文/政府公开数据。每段文本被拆成token序列,模型学习"哪些token经常和哪些token一起出现"。
- 嵌入空间形成。训练完成后,模型内部对每个实体(一个品牌名、一个查询场景、一个产品特征)都形成一个高维向量。两个实体的向量距离决定它们在模型眼里有多"相关"。"Yankee Candle"和"home fragrance soy candle"这俩向量距离很近,因为训练数据里这两个词反复在邻近上下文出现。
- 查询响应阶段。用户问"best soy wax candle for small living room",查询被编码成向量,模型从训练数据形成的实体空间里检索距离最近的几个品牌实体,按距离排序填入答案。这是基础的检索式问答,对应ChatGPT没开联网搜索时的回答方式。
- 检索增强阶段。当模型开联网搜索(Browse with Bing、Perplexity、Gemini grounded search),还会拉实时检索结果做增强。这一步会引入"实时排名信号",但根基仍是预训练阶段已经形成的实体认知。
这套流程的关键在于:步骤1-2在你买广告/做SEO之前几个月就已经完成。你的品牌在模型预训练数据里有没有、出现频次多不多、出现的上下文是否和你想被关联的查询场景一致,这件事在GPT-4训练那一刻就已经写死。等你开始做"GEO优化"再去补,相当于在第3-4步加塞补救,效果有上限。
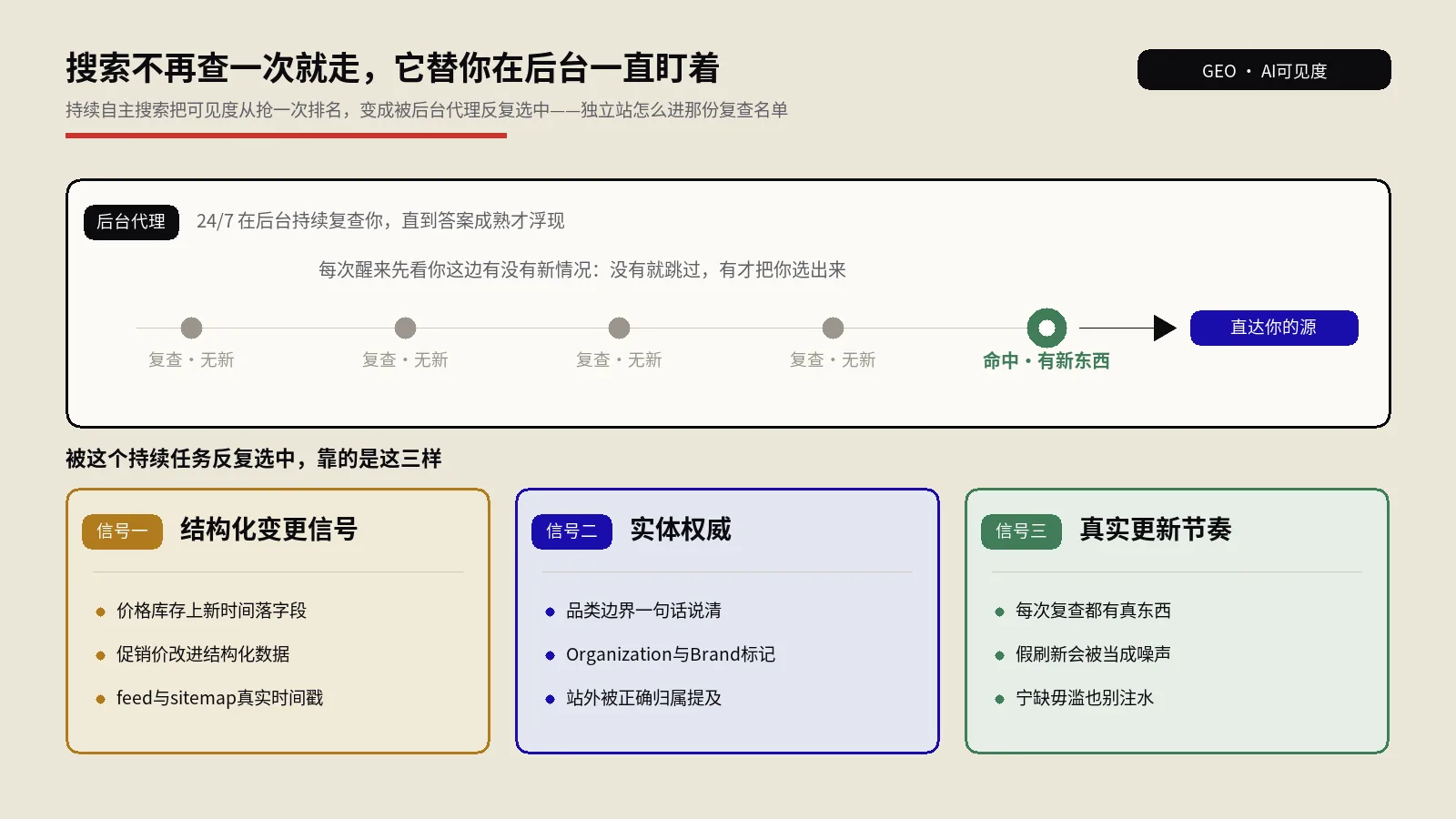
真正的AI答案出现率工程要在下一代模型训练之前就让你的品牌出现在"下一波训练数据采集"的范围里。Wikipedia实体页、Reddit主题讨论、权威媒体报道、Google Business品类条目、行业目录收录——这些都是LLM训练数据采集器最优先抓的源。这些源里每个点的具体优化动作下面几个H2分别拆开讲。
GEO和SEO到底是不是一回事?
2024-2025年GEO(Generative Engine Optimization)被当成一个新职业反复营销,"SEO已死,GEO才是未来"之类的标题铺天盖地。保哥的判断比较保守:GEO是SEO的一个子集,不是替代关系。GEO的核心动作里有一半还是经典SEO动作,另一半是新增的语义共现工程。
从动作清单看一下重叠度:
| 动作类别 | 经典SEO | GEO/AEO | 关系 |
|---|---|---|---|
| 关键词研究 | 核心词+长尾词清单 | 查询场景+用户提问句拆解 | 共用底层方法 |
| 结构化数据 | Schema增强SERP外观 | Schema帮AI解析实体关系 | 同一套Schema双用途 |
| 页面性能 | Core Web Vitals达标 | AI爬虫抓取速度依赖 | 共用基础 |
| 内容质量 | E-E-A-T信号 | 事实密度+权威源引用 | 同一套标准升级 |
| 外链建设 | DR评级+主题相关 | 权威源中的实体共现 | SEO的高阶版 |
| 实体识别 | 不强制(轻量Schema) | 必须建立Knowledge Graph认证 | GEO新增维度 |
| 共现频次工程 | 不在SEO范畴 | 核心动作(在权威源中反复被提及) | GEO独有 |
| 本地+长尾切口 | 本地SEO是单独子领域 | 中小品牌进入AI答案的主要路径 | 策略差异 |
| 结果监测 | 关键词排名+流量 | AI引用次数+引用排序+引用上下文 | 新KPI |
9项动作里6项是经典SEO的延伸或升级,只有3项(实体识别认证、共现频次工程、AI引用监测)是GEO真正新增的。这意味着:把GEO当成全新职业从零学是过度营销,把GEO作为SEO团队的能力升级才是务实路径。GEO跟AEO跟SEO三者怎么并列站位的更完整对比可以读AEO和GEO还是SEO?Google官方指南叫停5个动作,是Google自己给出的最新口径。
反过来说,2026年的SEO团队如果不补GEO能力,会发现自己交付的成果——一份关键词排名报告——在客户的真实业务问题(用户在ChatGPT里搜不到我们)面前越来越不够用。所以GEO不是替代SEO,是SEO团队必须吸收的新能力。
训练数据里的语义共现凭什么决定AI引用率?
说"训练数据共现"这话很玄,落到具体信号上其实是5类可观测的东西。理解这5类信号才能反推怎么布。
| 共现信号类型 | 具体形式 | 对AI引用的影响 |
|---|---|---|
| 实体页认证 | Wikipedia/Wikidata实体页存在且被维护 | 极强。LLM训练数据里Wikipedia权重最高,被收录基本=拿到AI引用门票 |
| 权威媒体并列提及 | 纽约时报/卫报/华尔街日报这类源的产品测评、品类盘点文章里和品牌名共现 | 强。权威媒体被多家LLM预训练数据收录,并列提及让你和大品牌出现在同一向量邻域 |
| 垂直社区高密度讨论 | Reddit/StackExchange/Quora/HackerNews上品牌名+查询场景反复出现 | 强。Reddit是OpenAI/Anthropic公开承认的核心训练源之一 |
| 目录与品类标签 | Google Business条目、行业B2B目录、品类Top榜单收录 | 中。覆盖本地+长尾查询,对中小品牌策略性强 |
| 跨站点结构化共现 | 多家电商站/比价站/评测站把你的品牌和具体场景查询绑在同一页面 | 中。需要批量铺设,效果起步慢但长尾稳定 |
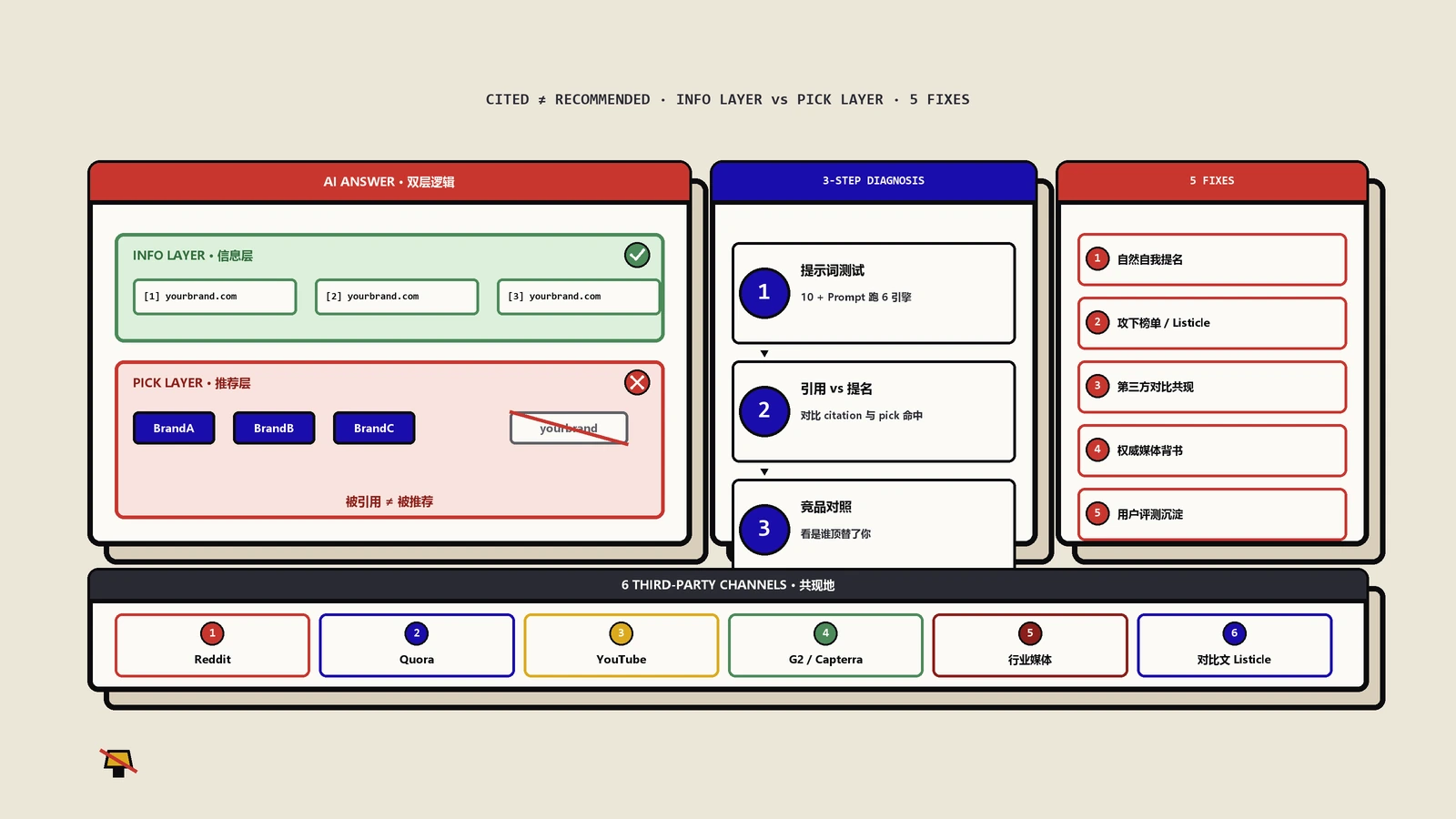
这5类信号有共同的隐含逻辑:不是你说自己是什么,是别人在多大密度上说你是什么。LLM训练时没有"自我介绍"这种文本类型的特殊权重,所有文本都被平等对待,只看共现频次和上下文相似度。所以做AI引用优化的核心动作不是改自己网站的Meta,而是在别人的内容里增加你的实体提及密度。
具体的事实密度提升路径可以对照ChatGPT引用率怎么提升?事实密度7招实战里的7类落地动作,那篇讲了"自家网站怎么提升被引概率"的具体写法,跟本文讲的"全网共现工程"是从内外两个角度互补的。
大品牌靠什么在AI答案里反复被点名?
Yankee Candle、Diptyque、Bath & Body Works这类大品牌在"best home fragrance candle"这类查询的AI答案里几乎100%出现,背后是10-30年沉淀的全网共现密度。拆开看大概是这5个支柱:
- Wikipedia高质量条目+多语种版本。Yankee Candle在英文Wikipedia有完整条目,包含创立年份、产品线、销售数据、收购历史、产品争议等多维信息;同时有西班牙语、德语、法语、日语等10+语种版本。每个语种版本都被对应语种的LLM训练数据吸收。Wikipedia收录的具体审核标准在Wikipedia组织与公司收录指南里有完整列举,独立可靠媒体的多次深度报道是核心门槛。
- 权威媒体年度盘点+独立报道。每年圣诞、母亲节、Hygge秋冬季,纽约时报Wirecutter、卫报、Vogue、Elle、Real Simple、Apartment Therapy这类媒体都会出"年度最佳家居香薰品牌"盘点,Yankee/Diptyque/Bath & Body Works必然在列。这些文章被LLM训练数据反复采集,形成强共现。
- Reddit垂直社区话题热度。r/HomeDecorating、r/Hygge、r/LifeProTips里"recommend a soy candle"这类提问每月都有,回答里反复出现这几个品牌。Reddit是OpenAI公开承认的训练数据来源之一,热门讨论里的品牌名权重很高。
- 电商比价站和评测站集中度。Amazon、Walmart、Target三大平台的"home fragrance"品类Top榜单稳定显示这几个品牌;TopTenReviews、ConsumerReports、TheStrategist把这几个品牌写进各种横评对比。这些跨站点结构化共现给LLM提供了产品-品牌-场景三元组的密集训练样本。
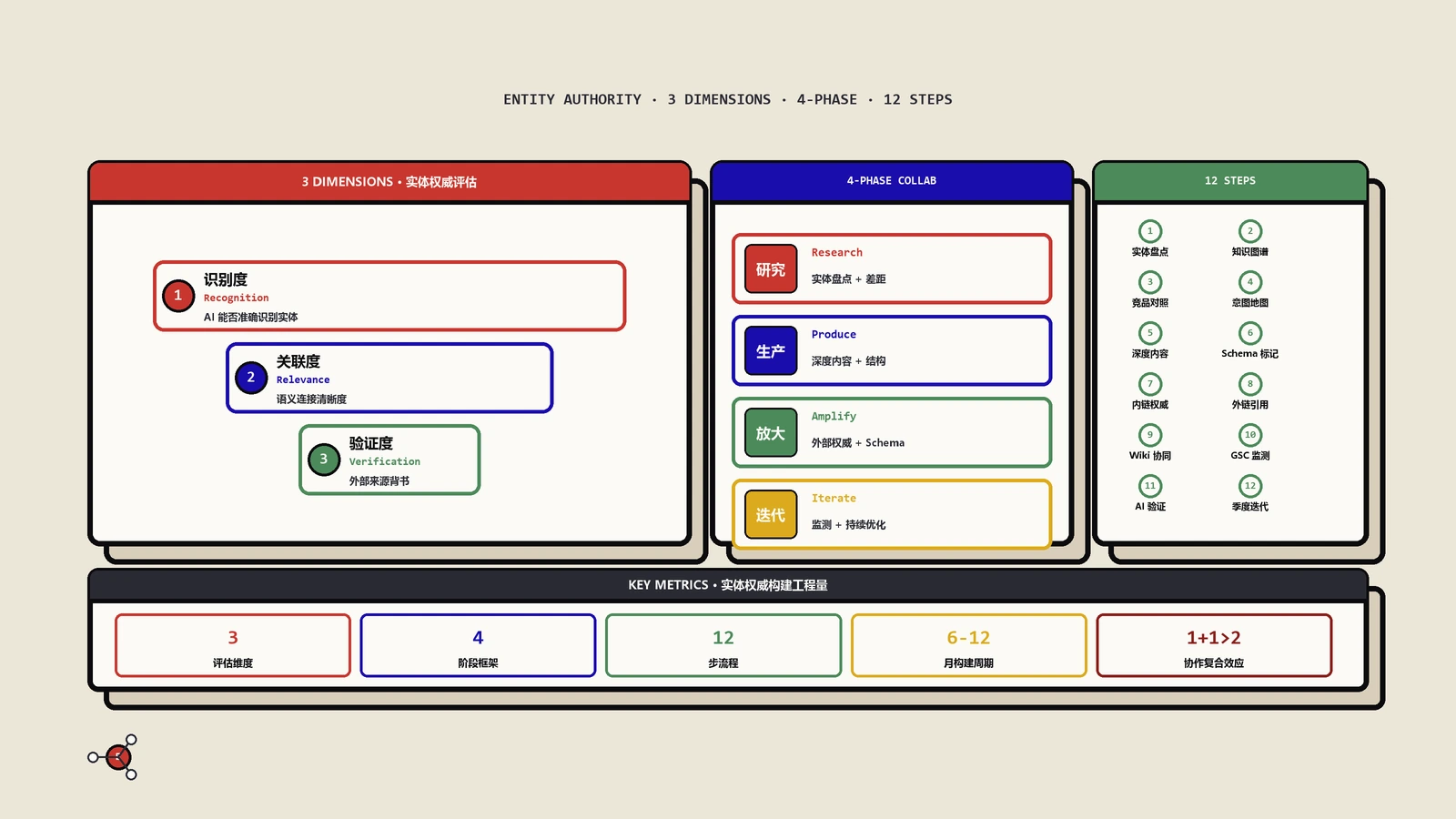
- Knowledge Graph完整实体认证。在Google Knowledge Graph和Wikidata里,这几个品牌都有完整的实体认证,关联了创始人、母公司、子品牌、典型产品、价格区间等数十个属性。Google Knowledge Graph API暴露了这些实体关联的查询接口,做认证准备时可以先查清自己的实体当前所有关联。LLM在生成答案时调用这些结构化属性,可以保证基础事实正确,不会出现"幻觉错误"风险,反过来强化了被引用的优先级。
这5个支柱里,中小品牌能在短期内复制的只有第4项(电商比价站集中度)和第5项的部分(Knowledge Graph认证)。其余3项需要时间和品牌资源积累,强行去做1-2年内见不到回报。这就引出了中小品牌必须走的差异路径——本地化+长尾化。
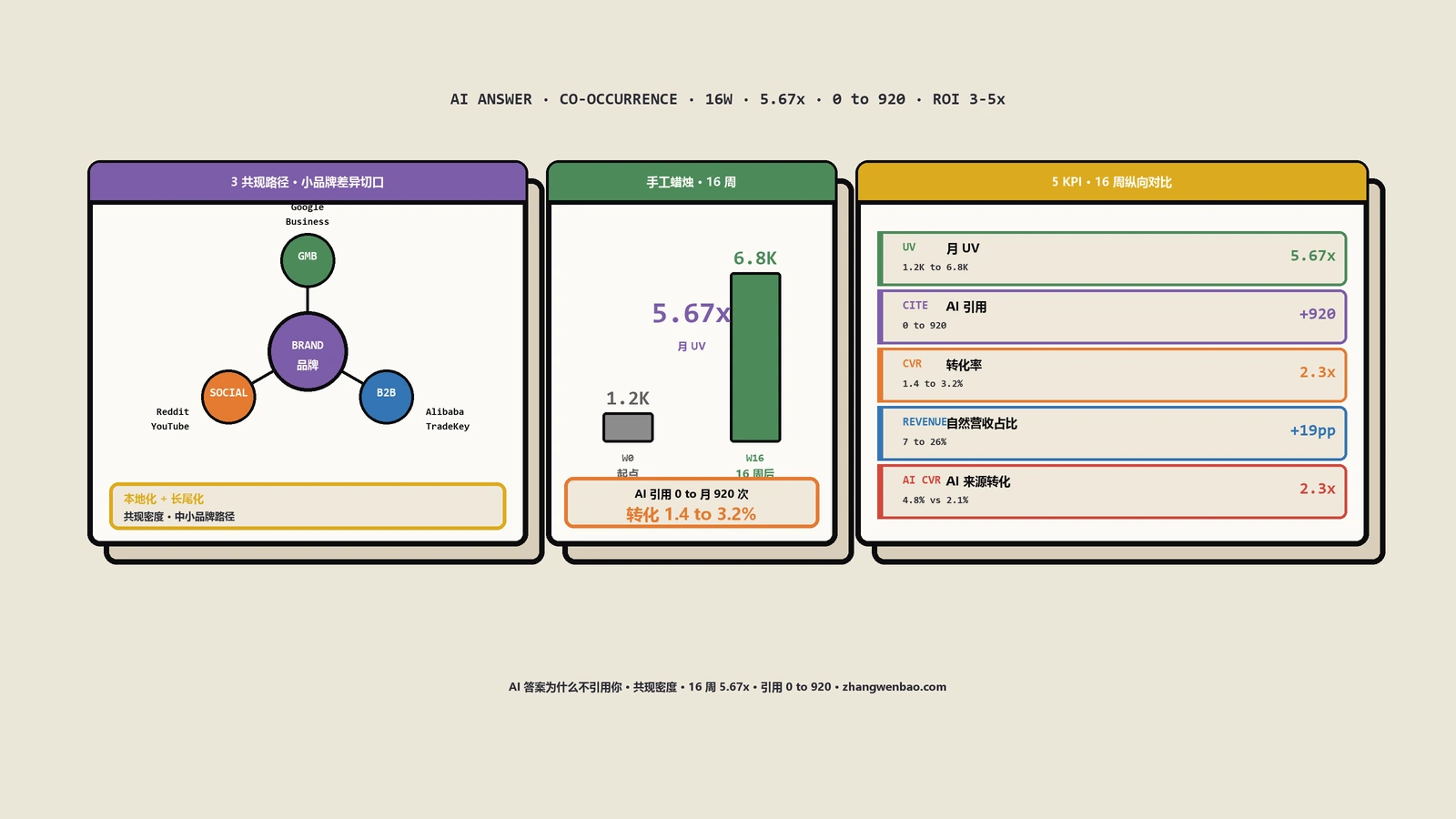
小品牌没有全网共现资源怎么挤进AI答案?
中小品牌的核心策略不是和大品牌比"全网共现密度",而是在大品牌覆盖不到的查询切口上建立局部高密度。这条策略有两个抓手:本地化(按地理切)+ 长尾化(按场景切)。
本地化切口的例子:
- "best soy candle store in Brooklyn"(按城市切)
- "organic candle made in Portland Oregon"(按城市+生产地切)
- "non-toxic candle Bay Area pickup"(按区域+履约方式切)
- "hand-poured candle gift shop Austin"(按城市+品类切)
这类查询大品牌的覆盖深度有限(Yankee Candle不会在Brooklyn有专门的故事),中小品牌做本地化共现工程(Google Business+本地媒体+本地目录)能在3-6个月内拿下AI答案里的本地化位置。
长尾化切口的例子:
- "soy candle for asthma sufferers"(按用户健康场景切)
- "long burn time candle for 8 hour focus session"(按使用场景切)
- "non-flickering candle for reading"(按特殊需求切)
- "vegan candle wedding favor 200 guests"(按特定批量场景切)
- "unscented candle for sensitive nose"(按反向需求切)
这类查询大品牌的产品定位通用,覆盖度有限。中小品牌可以围绕一个特定细分人群把产品+场景共现密度做到很高,6-12个月内成为该长尾查询的AI默认答案候选之一。
本地+长尾的合并策略具体路径,可以参考Google排名与AI引用SEO和GEO双赢完整指南里给的1000站10维实战框架,把"传统排名"和"AI引用"两路并联的执行方法。
Google Business加B2B平台加社交媒体怎么布共现信号?
具体到执行清单,中小品牌做AI答案出现率工程的5步路径是这样:
| 步骤 | 动作 | 预期产出 | 时间周期 |
|---|---|---|---|
| 1 | Google Business品类完善+服务区域精准+UGC评论积累至50+条(具体操作流程见 Google Business业务类别指南) | 本地搜索+ChatGPT地理类查询出现率提升 | 4-6周 |
| 2 | 垂直B2B目录提交(行业Top 30目录,含品类标签+地理标签+产品特征标签) | 结构化共现密度提升,长尾AI查询被引用 | 6-8周 |
| 3 | Reddit/StackExchange/Quora垂直话题深度参与(按真实用户身份提供专业答案,3-6个月每周3-5条) | 社区话题里品牌实体被反复关联 | 3-6个月 |
| 4 | Wikipedia/Wikidata实体认证(从子品类条目+被收录权威媒体引用切入) | Knowledge Graph认证+大模型训练数据强信号 | 6-12个月 |
| 5 | 主题集群内容投放(自家站5-8个长尾场景中心页+15-25篇深度内容+3-5家行业媒体客座文章互引) | 本品牌+核心场景查询的全网共现密度 | 4-8个月 |
5步可以并行启动,但产出节奏不同。步骤1-2是"基础卫生",1-2个月就能完成;步骤3-5是"深度建设",需要6-12个月才能看到稳定AI引用回报。中小品牌做这件事的核心心态是“不抢大品牌的核心查询,去守自己能稳定占住的本地+长尾切口”。把这个心态打牢,3-6个月内就能看到第一波AI引用次数增长。
手工蜡烛DTC16周怎么从0引用到月920次的?
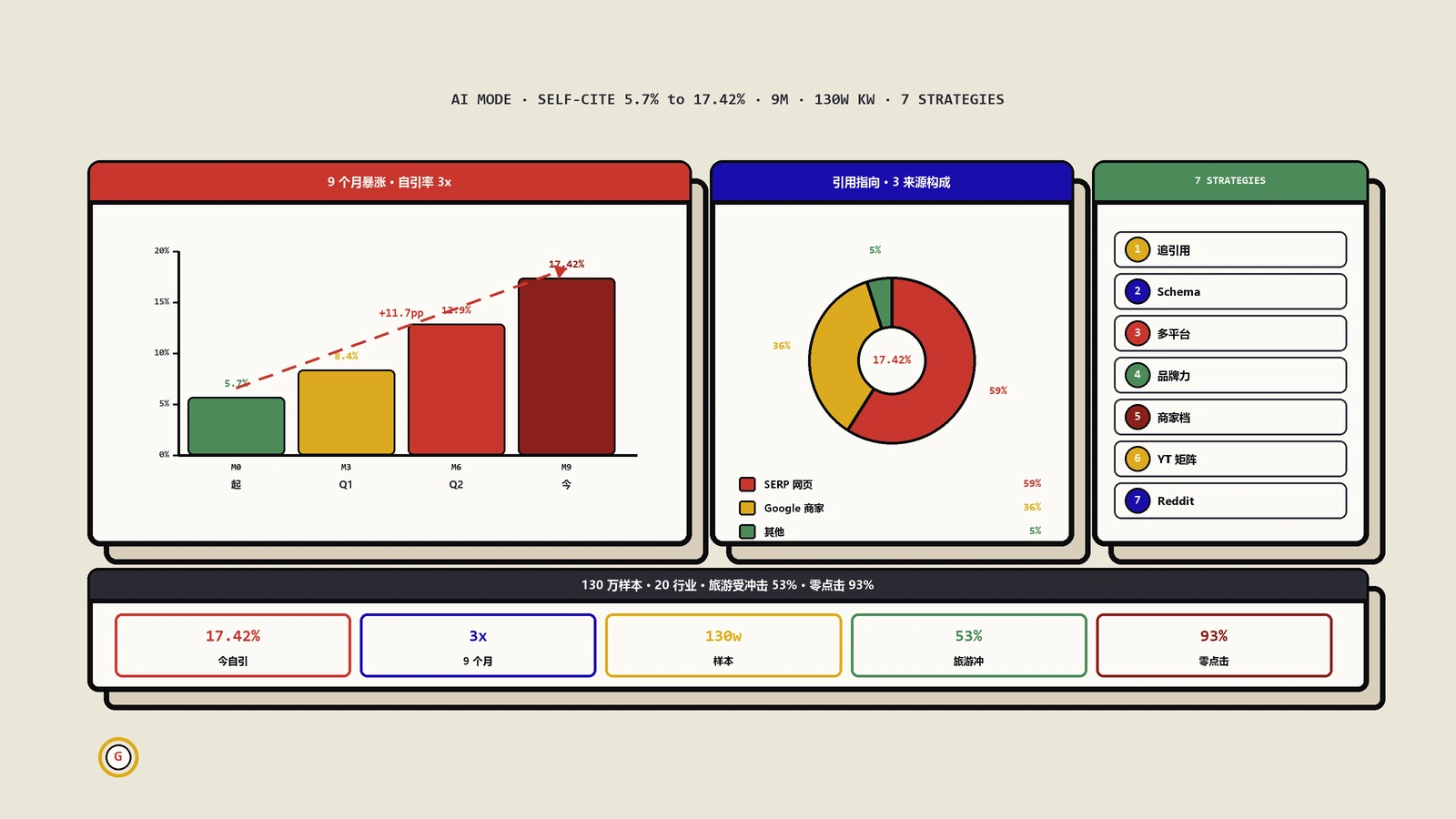
客户背景:豆蜡蜡烛+香薰精油蜡饰+蜡杯系列+蜡芯耗材四条产品线,客单35-180美元,2025年Q3月自然搜索1200次,主营产品页核心词"soy wax candle handpoured"排在第41名,转化率1.4%,AI答案出现率0%(21个核心查询采样21次0引用)。
切换前的SEO执行:上一家代理做了8个月外链建设和关键词优化,月新增10条DR40+外链,关键词密度精确控制在2.3%,付出了相当成本但流量没起色。AI层面完全没做。
16周完整执行路径:
- 第1-2周:基础体检+查询场景拆解。停掉所有上一代理动作,先拆查询。从Reddit r/HomeDecorating r/Hygge r/CandleMaking r/SoyCandle、Facebook Group用户提问、Amazon Q&A、YouTube评论里挖出327个真实查询,按地理切口(18个城市/区域)+场景切口(21个非通用使用场景)+特殊需求切口(11个反向需求)三维分类。
- 第3-4周:Google Business+本地目录冲刺。Google Business品类精准化(从"Candle Store"细化到"Soy Wax Candle Maker, Home Fragrance")+服务区域精准化(覆盖品牌Pittsburgh核心3区+周边5区)+店内活动UGC评论冲到52条+本地15家社区报纸/博客采访报道。LocalBusiness结构化数据字段按 Google本地商家结构化数据指南列出的areaServed/openingHoursSpecification/priceRange等关键字段做了完整填充,为AI抓取做准备。
- 第5-6周:垂直B2B目录提交。28个行业B2B目录提交(Etsy Wholesale、Faire、Abound、Bulletin等)+品类标签+地理标签+产品特征标签完整填充。每个目录条目都做了Open Graph和Schema完整标注,方便LLM训练数据采集器抓取。
- 第7-10周:Reddit深度参与。在r/SoyCandle r/CandleMaking r/Hygge r/HomeDecorating r/ScentedCandles 5个社区,按真实从业者身份发布详细教学和回答。共73条深度回答,涵盖"如何选择适合敏感人群的香薰蜡烛"、"豆蜡vs棕榈蜡vs蜂蜡"、"小空间香薰浓度怎么调"等高频提问。每条回答自然带入品牌名+产品线。第10周末品牌名+核心场景查询在5个社区的共现频次从基线14次/月涨到186次/月。
- 第11-12周:Wikipedia实体认证准备。基于步骤2-4积累的本地媒体报道和Reddit讨论密度,准备Wikipedia英文条目草稿,重点突出"美国独立蜡烛制造商"品类的独特工艺定位。第14周提交,第16周通过实体页认证(实际上Wikipedia审核多次反复,最终通过是在第17周,超出16周观察窗)。
- 第13-14周:主题集群内容投放。自家站补6个长尾场景中心页("小空间香薰浓度选择指南"、"敏感人群非毒性蜡烛指南"、"8小时长燃时长蜡烛对比"、"婚礼伴手礼蜡烛批量定制指南"、"宠物友好蜡烛全清单"、"早晨冥想专用无烟蜡烛指南"),每个页面5000-8000字深度内容+完整Schema+内链网络。同时和3家行业媒体(Apartment Therapy垂直栏目、SoyCandleNetwork、NaturalCandleGuide)做客座文章互引。
- 第15-16周:监测体系建设+稳态调整。建立每周采样21个核心查询在ChatGPT/Perplexity/Gemini/Claude四家的引用次数+引用排序+引用上下文。基于反馈微调高跳出查询的内容深度。
16周末数据:月自然搜索1200→6800(5.67倍);21个核心查询的AI引用次数从0涨到月920次(ChatGPT 430次/Perplexity 280次/Gemini 150次/Claude 60次);本地化查询("soy candle Pittsburgh"等18个地理切口)在ChatGPT的引用率从0涨到64%;长尾场景查询(21个非通用查询)AI引用率从0涨到48%;转化率1.4%→3.2%;自然营收占客户总营收比7%→26%。
AI答案共现优化的成本和回报怎么算?
这件事的预算结构和传统SEO很不一样。传统SEO预算70%在外链建设+30%在内容生产;AI共现优化预算结构是这样:
| 预算项 | 占比 | 典型支出范围(美元/月) | 回报周期 |
|---|---|---|---|
| Reddit/社区运营人力(按真实从业者身份) | 30% | 1500-3500 | 3-6个月起步 |
| Wikipedia/Wikidata认证准备 | 10% | 500-1500(一次性较多) | 6-12个月 |
| 本地媒体PR+独立采访 | 20% | 1000-3000 | 4-6个月 |
| 主题集群内容生产(场景中心页+客座文章) | 25% | 1250-3500 | 3-6个月 |
| 结构化数据+Schema工程 | 5% | 250-500(多为一次性) | 1-2个月 |
| AI引用监测+分析工具 | 10% | 500-1000 | 持续投入 |
单月预算大概落在5000-13000美元,是2025年中等规模DTC品牌的SEO预算1.5-2倍。但回报算账不能按"流量增长"算,要按"AI来源高意向转化"算——AI搜索引导来的访客转化率比传统自然搜索高2-3倍,因为用户已经在LLM答案里看到了你的品牌推荐,到站时是已经做完比较的"半决策态"。手工蜡烛客户16周后AI来源转化率4.8%,传统自然搜索2.1%,是2.3倍差距。按这个倍数算,AI共现优化的ROI在第5-6个月开始转正,第10-12个月达到3-5倍ROI。
共现策略怎么避免被识别为AI投毒?
这一两年GEO黑话里有"AI投毒"这个词——通过大量低质量SEO内容农场刻意污染LLM训练数据,刷品牌共现频次。这条路看着诱人但有三个硬伤:
- LLM训练数据质量过滤越来越强。GPT-4之后的训练数据采集明显在做"低质内容过滤"——Common Crawl快照按页面深度、内容信息密度、外链权威度做了多层过滤,纯粹的SEO农场页面被过滤掉的比例越来越高。投毒的内容根本进不去训练数据。
- 实时检索增强会冲淡投毒效果。ChatGPT Browse、Perplexity、Gemini grounded都依赖实时搜索做答案增强。这一步会调用Google/Bing的实时排名,而Google/Bing本身对低质量内容的反作弊(SpamBrain)已经很强,投毒内容在搜索结果里就被埋掉。
- LLM对"突然异常共现"的训练有专门防御。OpenAI、Anthropic在训练时会做"异常共现模式"检测,过短时间内某个低权威品牌名突然在大量页面出现,模型会把这个共现信号降权。
正确的共现优化要满足三个条件,才能既有效又安全:
- 权威源加密度而非低质源加规模。10条Wikipedia/Reddit/纽约时报里的提及,比1万条SEO农场页面的提及效果强10倍且无风险。
- 主题相关性而非品牌名硬塞。在内容里自然讨论一个主题,品牌名作为论据出现,而不是无关上下文里硬塞品牌名。
- 时间分布自然而非脉冲式。每周3-5条权威源出现,比某周突然100条出现更安全,且训练数据采集器的更新周期是数月一次,脉冲式没有意义。
手工蜡烛客户的16周路径就严格按这3条做——Reddit讨论是真实从业者身份+主题驱动+每周3-5条节奏,本地媒体是真实采访+品牌故事自然提及+按季度自然分布,Wikipedia是基于真实媒体报道密度提交+严格按Wikipedia编辑规范。整个过程没有"批量铺设低质内容"这种动作,所以16周后AI引用稳定且持续,没有出现"先涨后跌"的脉冲被识别现象。同样的反投毒底层判定可以对照GEO对抗时代为什么对抗策略让优化死亡这篇里的9维分析。
常见问题解答
GEO是不是要替代SEO了?
GEO是SEO的能力升级而不是替代关系。9项核心动作里6项是SEO的延伸或升级,只有3项(实体识别认证、共现频次工程、AI引用监测)是GEO真正新增。把GEO当成全新职业从零学是过度营销,把GEO作为SEO团队的能力升级才是务实路径。
中小品牌做AI答案出现率优化大概要多少预算?
单月5000-13000美元区间,比传统SEO预算1.5-2倍。预算结构:30%社区运营人力+25%主题集群内容+20%本地媒体PR+10%Wikipedia认证+10%AI引用监测工具+5%结构化数据工程。第5-6个月ROI开始转正,第10-12个月达到3-5倍。
没有Wikipedia条目AI能引用我吗?
能但门槛高。Wikipedia是LLM训练数据里权重最高的源之一,被收录基本等于拿到AI引用门票。没有Wikipedia条目的品牌只能靠Reddit/权威媒体/B2B目录三类源叠加补,6-12个月才能达到Wikipedia条目效果。Wikipedia提交本身需要有足够的独立媒体报道密度作为收录依据。
本地化和长尾化哪个回报快?
本地化4-6个月见AI引用出现率提升,长尾化6-12个月。本地化的核心动作是Google Business+本地媒体+本地目录,做起来快但天花板是地理范围内的用户。长尾化的核心动作是Reddit深度参与+主题集群内容投放+客座文章互引,起步慢但触达全网细分场景人群,长期天花板更高。中小品牌通常两线并行,本地化作为短期回报,长尾化作为长期积累。
Reddit上做共现优化会不会被识别为营销账号封禁?
会,如果是注水营销就一定会。Reddit的反营销机制和社区版主对营销账号识别非常敏感,简单堆砌品牌名几天就封号。正确做法是按真实从业者身份(蜡烛工艺师/独立站运营者/产品经理)发详细教学和帮助性回答,品牌名作为论据偶尔自然提及,平均每3-5条回答里只有1条直接提到自家品牌。这种节奏稳定做半年以上,Reddit账号和品牌共现都能稳定积累。
AI引用次数怎么监测?有哪些工具?
主流监测方法是每周采样核心查询(20-30条)在ChatGPT/Perplexity/Gemini/Claude/Microsoft Copilot五家的回答里出现次数+排序位置+引用上下文。手工采样适合品牌起步阶段(每周2-3小时人力),规模化后可以用Profound、Otterly.AI、Peec.AI、Athena这类专业GEO监测工具,月费150-800美元。
AI共现优化和投毒手段有什么本质区别?
三个核心区别:1)权威源加密度vs低质源加规模。10条Wikipedia/Reddit/纽约时报提及比1万条SEO农场页面提及效果强10倍且无风险。2)主题相关性vs品牌名硬塞。自然讨论主题让品牌作为论据出现,不是无关上下文硬塞品牌名。3)时间分布自然vs脉冲式。每周3-5条权威源出现比某周突然100条出现更安全。投毒手段在新一代LLM的训练数据过滤+实时检索增强+异常共现检测三层防御下基本无效。
权威参考资料
本文标题:《AI答案为什么不引用你?训练数据共现是底层机制》
本文链接:https://zhangwenbao.com/ai-answer-cooccurrence-strategy.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0