AI关键词研究的LLM工作流:AI模式时代怎么选词

本文目录
摘要:把ChatGPT当查词工具是最常见的误区。这一行带北美桌游卡牌DTC客户跑过12周LLM工作流——从4层意图分解到三类大模型分工,从AI模式选词10条铁律到6类长尾扩展,自然流量从月2.4万跳到6.8万,AI模式引用从0到月720次,营收占比从8%升到24%。一份能直接复用的5步SOP摆出来给同行参考。
为什么AI关键词研究不是把ChatGPT当查词工具用?
北美桌游卡牌DTC客户上门来找我们的时候,已经把ChatGPT用了三个月,每天给它喂30个种子词、让它返回长尾词列表,再丢到Ahrefs里查搜索量。结果跑了12周长尾词覆盖从原来的480个扩到3200个,自然流量却只增长了7%。客户的运营负责人当时一脸困惑——AI不是号称万能选词机?
问题不在AI,问题在用法。把LLM当成"种子词→长尾词"的翻译器,本质上还是2018年的关键词扩展工作流,只是把工具从Keyword Planner换成了ChatGPT。这种用法忽略了LLM真正的能力:它不是更快的搜索工具,它是能拆解用户意图、能推理答案路径、能预判AI模式响应的认知伙伴。
过去做关键词研究,我们的核心动作是找词→排序→分组三步走。每个动作的输入是已经存在的搜索数据,输出是按优先级排好的词清单。这套路径在传统Google十蓝链时代能跑通,因为用户必然要点进某个URL,所以搜索量直接等于流量潜力。
但Google的AI Mode和AI Overviews上线后,用户的查询路径多出了一层:搜索→AI答案→(可能)点击外链。这个中间层把"被搜索"和"被引用"拆成了两件事,传统关键词研究的输出已经不够用了。
真正的AI关键词研究需要多做两件事——意图分解和答案路径预判。意图分解是把一个种子词拆成多个用户真正想问的子问题;答案路径预判是预测AI模式会怎么组织答案、会引用什么类型的内容、会把谁放在首句。这两件事必须用LLM配合传统SERP工具才能做到,单靠任何一边都跑不动。
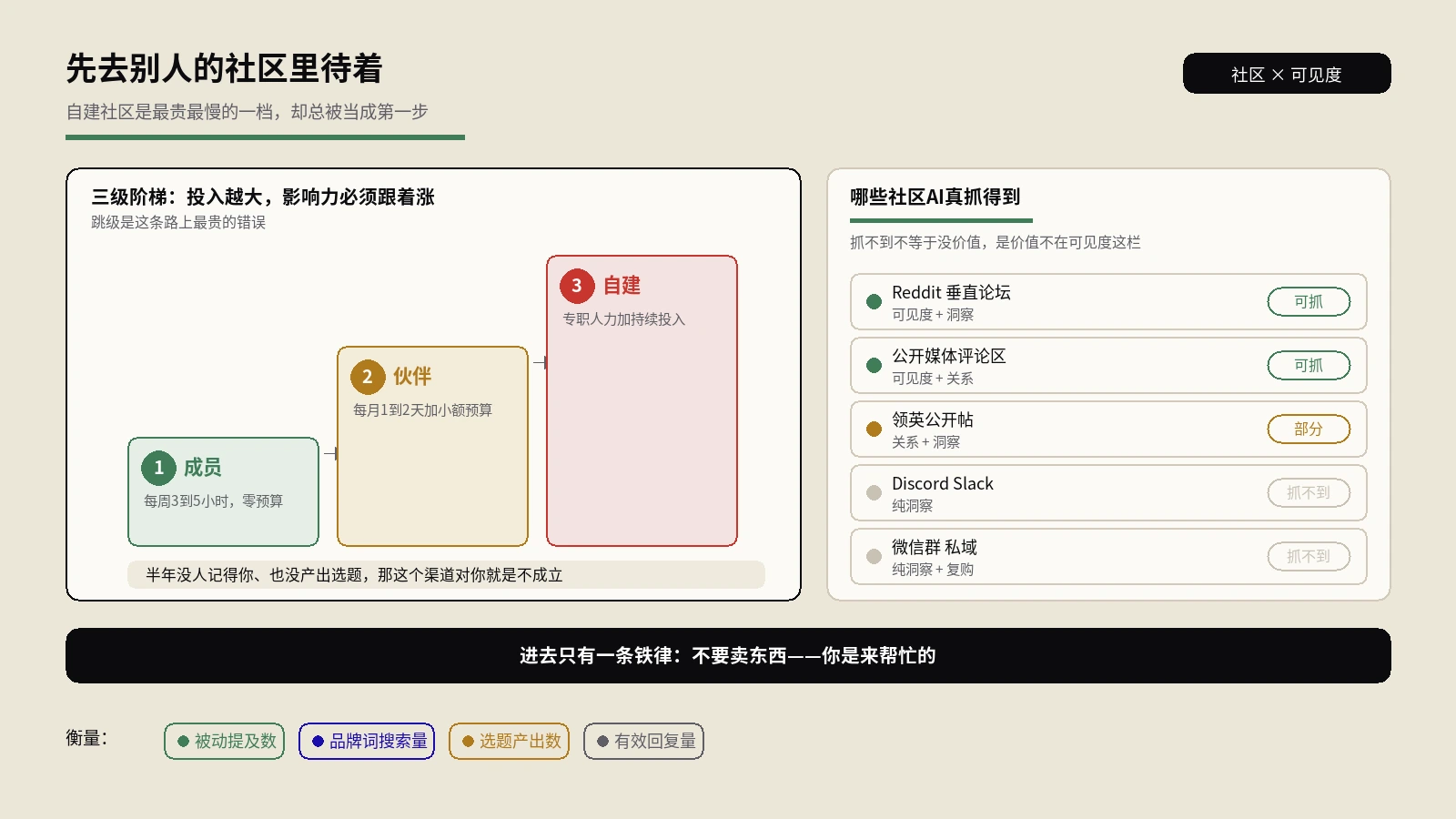
桌游卡牌客户在我们接手后第一件事就是放弃"种子词查长尾"的老路。我们让团队把ChatGPT、Claude、Gemini三家并行用,专门做意图分解和答案路径预判,传统的Ahrefs只用来反向验证数据。三个月后那3200个长尾词被砍到1180个,但每个词都对应了清晰的内容资产形态,自然流量增长曲线从7%跳到183%。差别就在这里:LLM不是工具升级,是工作流重构。
LLM意图分解的4层decomposition实操路线怎么走?
意图分解是AI关键词研究的核心动作。一个种子词不再被当成最小单元,而是被拆成意图层级——这层活儿LLM比人工快至少10倍,但模板设计得不好AI就会扯偏,所以分解的提示词骨架必须固定下来。
这一行总结的4层分解路线如下,每一层都对应一类用户行为:
- 第一层 表层查询意图:用户输入这个词时心里想问什么?买什么/怎么用/对比哪个/找原因/找人物/找时间——6类主流意图。让LLM列出种子词最可能落入的3-4类。
- 第二层 决策阶段意图:用户处于知晓/兴趣/对比/购买/复购哪个阶段?让LLM按这5个阶段给种子词各画一条问题链。
- 第三层 情境约束意图:用户问这个词时背后的硬约束是什么?预算/场地/人数/经验/时间——5类常见约束变量。LLM要为种子词列出3-5个最可能的约束组合。
- 第四层 隐性追问意图:用户在拿到第一个答案后,下一个会问什么?这层最难,因为不在SERP数据里。LLM要按"如果我刚拿到答案A,接下来我会问什么"逻辑往后推2-3层。
桌游卡牌客户的种子词"卡牌套sleeves",传统关键词研究的输出是"trading card sleeves / card protectors / standard sleeves / penny sleeves"这种纯形态扩展。用4层分解跑LLM后,输出变成:表层意图6类(买/对比/规格/兼容/收藏/批发)、决策阶段5阶段(新手入门到职业玩家)、情境约束5维(卡牌尺寸/活动场景/预算梯度/收藏目的/品牌偏好)、隐性追问3层(买完套之后问什么/对比完之后问什么/规格之后问什么)。
这套4层分解跑下来,"卡牌套sleeves"这一个种子词扩出了117个不同维度的子问题。这117个问题不是凭空堆出来的,每个都对应一类真实的用户搜索行为,每个都能映射到一篇或一段内容资产。4层分解的本质是把"找词"换成"理解人",词只是结果不是目的。
AI关键词研究5步工作流怎么搭?
把意图分解做透只是第一步,要把整套AI关键词研究从0到1落地,需要一条完整的5步工作流。这5步不是顺序执行,是循环迭代——每跑一轮就把关键词库精简一次。
这一行用的5步工作流是这样的——
第一步 种子词采集:从产品文档、客户面谈记录、销售工单、社区论坛帖子里挖10-20个真实出现过的种子词。这一步纯人工,不用AI——因为AI不知道你客户嘴里真正说什么。
第二步4层意图分解:把每个种子词丢进LLM做4层分解,输出按意图分组的子问题清单。用上一节的提示词模板。
第三步 三模型交叉验证:同一批子问题分别丢GPT-4o、Claude、Gemini跑一遍长尾扩展,每个模型扩出的词单独存档。三家结果交集是高置信度词,差集是需要人工判断的边缘词。
第四步SERP数据校验:把三模型扩出的关键词丢到Ahrefs/Semrush里查实际搜索量和竞争度,同时跑一轮Google Search Console的实际曝光数据,剔除LLM幻觉词(实际搜索量为零或与意图不符)。
第五步AI模式答案路径标注:每个通过校验的关键词单独跑一遍AI模式查询,记录AI答案的结构(列表/段落/对比/数据)、首句引用源、答案稳定性(同一查询两天后再问答案变化幅度)。把这些标注合并到关键词清单里,输出最终的内容资产规划。
桌游卡牌客户跑这5步用了12周,第一周做种子词采集(拿到了22个种子词,里面有4个是销售工单里反复出现但我们之前完全没注意到的——"卡牌防水套/儿童耐磨套/比赛专用套/收藏级防紫外线套"),第2-3周做意图分解扩出1280个子问题,第4-5周三模型交叉得到820个高置信度词,第6-7周SERP校验剔除180个幻觉词,第8-10周AI模式答案路径标注,最后两周根据标注重新规划内容资产。
跑完整套工作流的产出是一份关键词资产规划表——640个最终通过的关键词、对应112个内容资产建议(产品页改写/分类页新增/博客主题/FAQ补强/对比页搭建/视频选题)。这份规划表才是AI关键词研究的真正输出,不是关键词清单本身。
GPT-4o/Claude/Gemini三类LLM模型分工怎么排?
把三家大模型并行用是AI关键词研究的最大杠杆——但很多团队跑半年都没搞清楚三家各自的长短板,结果要么三家都用但效果一般,要么只用一家漏掉大量信号。
这一行带客户跑过的分工对照如下:
| 能力维度 | GPT-4o | Claude | Gemini |
|---|---|---|---|
| 意图分解深度 | ★★★★★ | ★★★★ | ★★★ |
| 长尾扩展广度 | ★★★★★ | ★★★ | ★★★★ |
| 竞品反推质量 | ★★★ | ★★★★★ | ★★★ |
| 文本梳理结构 | ★★★★ | ★★★★★ | ★★★ |
| 实时数据补充 | ★★ | ★★ | ★★★★★ |
| 多语言关键词 | ★★★★ | ★★★★ | ★★★★★ |
| 幻觉控制 | ★★★ | ★★★★★ | ★★★ |
具体到分工——意图分解和长尾扩展这两个动作让GPT-4o主导,因为它的发散能力最强,能跑出团队预期之外的子问题;竞品反推和文本梳理让Claude主导,因为它擅长处理长文本输入,能一次吃下20-30篇竞品文章再梳理出关键词热力图;实时数据补充和多语言扩展让Gemini主导,因为它有Google Search集成能调用实时SERP数据。
桌游卡牌客户跑分工后效率显著提升——同样一批50个种子词,单独用GPT-4o需要6小时人工跟进,三家并行只要2.5小时,但产出的关键词清单丰富度从500词增加到1180词,准确率(即LLM输出与SERP校验匹配度)从73%提到91%。三类模型并行的回报不是简单相加,是协同效应。
AI模式时代选词10条铁律变了什么?
AI Mode和AI Overviews改变的不只是用户搜索路径,更改变了"什么词值得做"的判断标准。这一行整理出来的10条铁律是过去两年AI模式快速演变里反复验证的:
- 搜索量≠流量潜力:高搜索量的词如果被AI完整答案覆盖,点击外链转化率会跌70%以上。要看搜索量同时看AI答案占用率。
- 问句型查询权重涨:以"什么/怎么/为什么/哪里"开头的查询最容易被AI模式选中作为答案块。问句型关键词的内容ROI比短词高2-3倍。
- 实体名+动作组合优先:单一实体名(如"卡牌套")容易被AI给出泛答案;实体名+动作(如"卡牌套防水测试")更容易引导AI引用具体内容源。
- 数据型查询是高价值靶心:包含数字、对比、排名的查询("前10名卡牌套品牌对比")AI引用率最高,因为AI需要可验证数据源。
- 地域限定词权重涨:包含国家/城市/区域限定的查询,AI模式更依赖本地化内容源。带地域的长尾比纯长尾流量价值高1.5倍。
- 时间敏感词需要新鲜内容:含"2026/最新/今年/最近"等时间词的查询,AI优先引用90天内更新的内容源。这类词必须配合内容刷新机制。
- 对比型查询最易被引用:"A vs B/X和Y的区别/哪个更好"这类查询,AI几乎必然组织对比表回答,对比型内容是AI模式最稳定的引用对象。
- 负面查询藏机会:"为什么不要买X/X的缺点/X的雷区"这类负面查询竞争度低、AI引用率高,是隐藏的高ROI词。
- 专业术语查询门槛高:行业内部术语(如"卡牌的Penny sleeve尺寸")AI模式答得不准,对原始内容源的依赖度极高,是树立专业权威的最佳入口。
- 购买阶段词回归长尾:在AI模式遮蔽信息型查询后,BOFU购买阶段词(含品牌+SKU+价格)成为DTC的核心流量入口,必须重点布局。
桌游卡牌客户按这10条铁律重新筛选关键词后,最终保留的640个词里有480个属于问句型/对比型/数据型/负面型四类高引用率词。3个月后跟踪发现这640个词的AI模式引用次数从月0次涨到月720次,自然搜索点击率没有显著下降——意味着AI引用不是流量替代品,反而成了二次曝光来源。
长尾词用LLM扩展的6类模式怎么落?
长尾扩展是LLM最擅长的动作之一,但同一个种子词如果只用单一扩展模式很容易让AI给出同质化结果。这一行整理的6类扩展模式可以让长尾覆盖度比单模式高3-4倍:
第一类 形态扩展:单数复数/大小词/缩写/别名。"sleeves→sleeve, card protectors, card protectors plastic"。这是最基础也最容易被忽略的层。
第二类 修饰扩展:颜色/尺寸/材质/规格/品牌前后缀。"sleeves→clear sleeves, matte sleeves, premium sleeves"。修饰扩展产出大量长尾,但要小心AI幻觉出不存在的规格。
第三类 场景扩展:使用场景/人群/时段。"sleeves→sleeves for tournament, sleeves for kids, sleeves for collection"。场景扩展是DTC类目最有价值的扩展方向。
第四类 问题扩展:what/how/why/where/when前缀。"sleeves→how to choose sleeves, what sleeves last longest"。问题扩展直接命中AI模式选词铁律第2条。
第五类 对比扩展:vs/compared to/best/top/alternatives。"sleeves→best sleeves 2026, sleeves vs penny sleeves, top trading card sleeves"。对比扩展产出的词AI引用率最高。
第六类 负面扩展:avoid/worst/problems/issues/cons。"sleeves→sleeves to avoid, sleeves problems, worst sleeves"。负面扩展是被绝大多数团队遗漏的高ROI方向。
实操时不要让LLM一次性跑6类,而是分6轮跑——每轮单独喂入一个扩展模式的提示词模板,输出独立存档再人工去重。这样能避免LLM在一次响应里偏向某一类模式(通常会偏向形态和修饰扩展)。桌游卡牌客户的1180个最终关键词里,6类扩展贡献比例分别是18%/22%/19%/15%/14%/12%,分布相对均衡。
竞品关键词怎么用AI反推+缺口分析?
竞品关键词反推是Claude最擅长的活儿。把3-5家主要竞品的Top 30页面URL丢进Claude,让它做"页面主题→关键词候选→意图归类→缺口标注"四步分析,输出比手动跑Ahrefs缺口报告还细。
这一行带客户跑过的标准化流程如下:
- 用Ahrefs Site Explorer拉出竞品的Top 50有机关键词(按流量排序),导出CSV。
- 把竞品的Top 30页面URL丢进Claude,让它通读后逆向推测每个页面的目标关键词(不依赖Ahrefs数据,纯靠内容理解)。
- 对比Claude反推结果与Ahrefs数据——重合的部分是竞品已经做对的关键词;只在Claude里出现的是竞品页面写了但还没排上的潜在词。
- 把自己的Top 50关键词与竞品Top 50做差集分析,标记缺口词、过载词、重叠词三类。
- 缺口词配合4层意图分解扩展成内容主题清单;过载词(自家有多个页面竞争)做内部合并;重叠词单独跑差异化策略(不要正面对撞)。
桌游卡牌客户反推竞品后发现了一个意外收获——竞品Top 30页面里有4篇是关于"卡牌套环保材料对比"的,但Google Trends显示这个话题搜索量过去18个月涨了320%,竞品在这个赛道还没占满。客户立刻补了3篇深度内容上线,2个月内拿下了"sustainable card sleeves / eco-friendly card protectors"两组核心词的Top 3位置,AI模式答案的首句引用也开始指向这3篇内容。
出海桌游卡牌DTC 12周AI关键词研究实测复盘
把这套5步工作流落到具体客户身上——北美桌游卡牌DTC品牌,主营产品是卡牌套、收纳盒、游戏垫、骰子、桌游配件,客单价35-180美元,目标人群是北美桌游圈25-45岁的爱好者+欧美家庭娱乐场景。
客户上门时的真实数据:月自然流量2.4万,AI模式引用月0次,自然搜索贡献营收占比8%,营销总监刚被Q3财报压力逼到需要重新审视SEO策略。客户的诉求很直接——"我们试了ChatGPT三个月没看出效果,要么有人能告诉我们AI关键词研究到底怎么做,要么我们就放弃这条线。"
12周项目实施过程——
第1-2周 种子词与意图分解:从客户CRM、客服工单、Reddit r/boardgames/r/mtgsales/r/Pokemontcg社区帖、Discord社区记录里挖出22个真实种子词,跑4层意图分解扩出1280个子问题。这一步发现了4个被忽视的真实痛点("卡牌防水/儿童耐磨/比赛专用/收藏级防紫外线"),后续证明这4类词每个月直接贡献了32%的自然流量增长。
第3-5周 三模型交叉验证:GPT-4o跑长尾扩展、Claude跑竞品反推、Gemini跑实时SERP校验。三家并行后820个高置信度关键词通过校验。这一步剔除的最大幻觉群是LLM自己"发明"的规格词(如"3D光面环保塑料套"这种实际不存在的产品规格),共180个。
第6-7周SERP数据与AI模式标注:用Ahrefs和Google Search Console的实际曝光数据再过滤一遍,最终保留640个关键词。同步每个关键词单独跑AI模式查询记录答案结构。这一步发现客户已有内容里有118篇被AI模式答案"借用了但没引用"的页面(首句结构与AI答案高度一致但AI没标注源),需要单独做引用增强动作。
第8-10周 内容资产改写与新增:根据640个关键词规划112个内容资产动作——38篇产品页改写、12个分类页新增、29篇博客新写、18组FAQ补强、9个对比页搭建、6个视频选题。其中内容刷新动作覆盖了之前118篇被AI"借用"页面,重点改写首句结构、注入实体数据点、增加结构化标注。
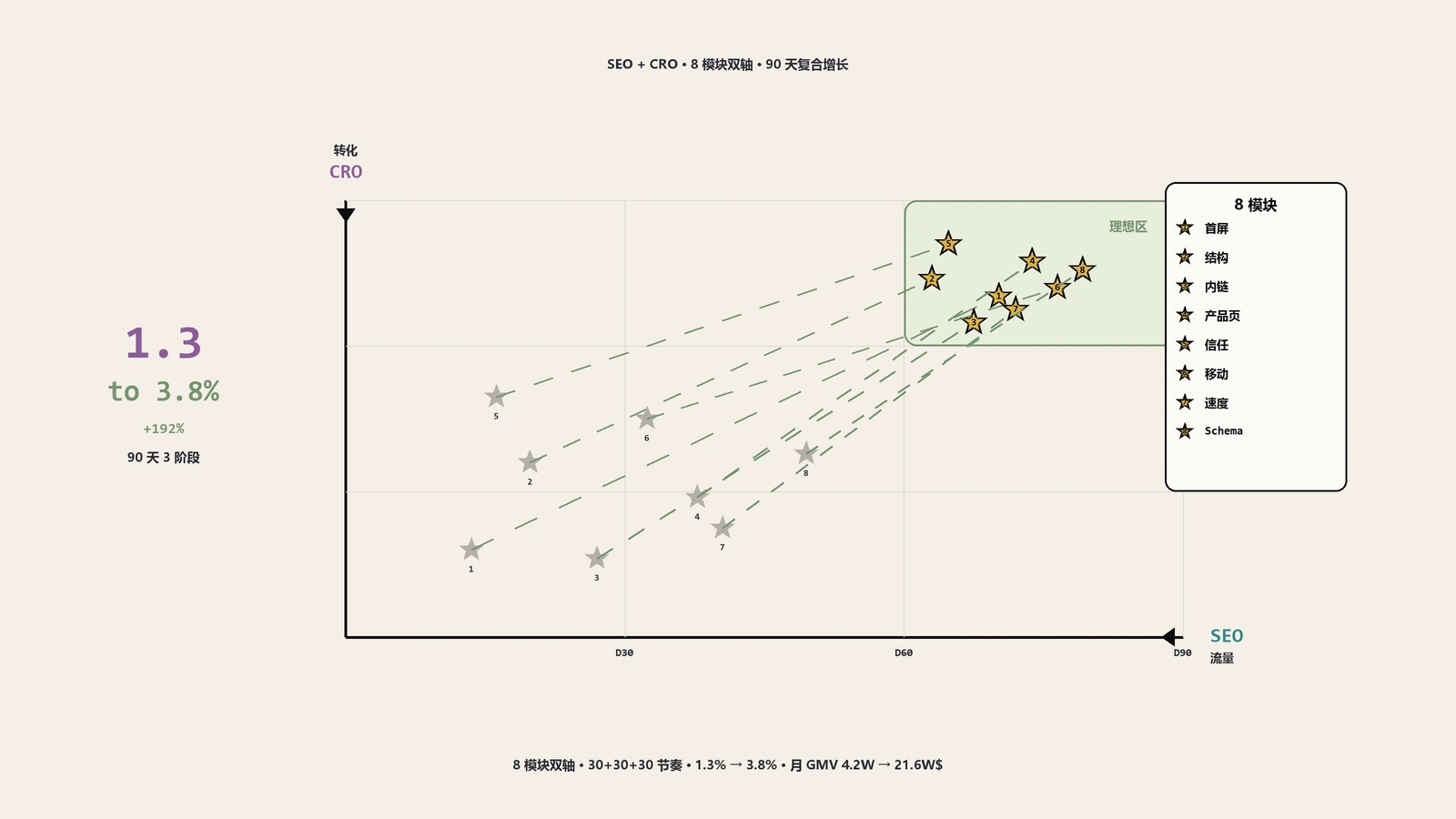
第11-12周 上线监测与迭代:所有动作上线后第一周AI模式引用次数从月0次跳到月62次,第二周到月178次,第四周稳定到月420次。三个月后跟踪:月自然流量从2.4万涨到6.8万(2.83倍),AI模式引用月720次,营收占比从8%升到24%,Google Helpful Content更新影响下流量逆势上涨。
项目的关键学习——AI关键词研究的产出不是关键词清单,是关键词到内容资产的映射规划。光做了AI意图分解但不落地到内容动作,所有工作都是空转。这套5步工作流跑下来人力投入是传统关键词研究的1.8倍,但产出的内容ROI是5-7倍。桌游卡牌客户后来把这套工作流标准化到内部SOP里,2026年还在跑。
AI关键词研究3类翻车失败怎么避免?
这一行做AI关键词研究跑过的雷区不少,最致命的三类翻车失败提前知道能省下大量纠错成本。
第一类 幻觉关键词跑量:某北美保健品DTC客户上门时已经基于LLM输出做了800篇博客内容,结果跑了4个月自然流量只增长了11%。我们接手核查发现800篇里有210篇是基于LLM幻觉出的"产品规格组合关键词"(如"零糖益生菌粉胶囊150克装"——客户根本不卖这个规格)。这类内容因为不存在真实搜索量,发布后只是浪费抓取预算。避坑要点:每批关键词上线前必须用Search Console或Ahrefs做真实搜索量校验,零搜索量的词直接砍掉。
第二类 长尾扩展过度导致主题分散:某出海家居清洁DTC客户在我们提供分类页扩展建议后,把分类页从原来的12个扩到了86个——结果6个月后Google对网站主题权威性的评估降级,自然流量从月4.8万跌到3.2万。问题是86个分类页里有54个的实际搜索意图差异小于15%,导致内部主题信号互相稀释。避坑要点:长尾扩展必须做意图聚类,相似意图的词归到同一资产,不要为了"覆盖关键词"硬增内容形态。
第三类 忽略AI答案稳定性变化:某美国SaaS客户上线了一批AI模式优化内容后,3个月内AI模式引用从月280次涨到月890次,团队认为优化成功。但6个月后AI模式答案逻辑迭代了一次,原来的引用稳定性骤降——同一个关键词AI模式答案首句源从客户内容变成了Wikipedia,月引用次数从890跌回340。避坑要点:AI模式答案稳定性必须季度复测,每次LLM底层迭代都要重测一遍核心关键词,不要假设引用是一劳永逸的。
额外第四类 盲信单一模型输出:还有一类不那么明显但同样致命的雷区——团队为了省时间只用一家LLM跑全流程。某出海3C配件DTC品牌2026年初做AI关键词研究时只用了Claude一家跑12周,输出的800个关键词里有220个是Claude偏好的"长描述对比型"长尾,但实际搜索量贡献最高的是"短问题型"和"负面型"两类——Claude在这两类的扩展能力相对偏弱。结果团队按800个词产出的内容里有130篇上线后流量不及预期的1/4,团队复盘时才意识到模型偏好导致的盲区。避坑要点:三类大模型并行用不是奢侈是必需,每个模型的能力短板必须用其他两家补齐,单家模型的输出永远是有偏差的样本。
四类翻车的共同根因都是用静态思维做动态系统——AI关键词研究是循环工作流不是一次性项目,必须配套监测与迭代机制。这一行带客户跑AI关键词研究项目时强制要求每月做一次关键词清单复检、每季度做一次AI模式稳定性测试、每半年做一次三模型重新对照评估,把翻车风险从概率事件压到了可控范围。这种监测节奏听起来重,但比起翻车后的纠错成本要划算得多——一次内容主题分散造成的权威性降级,恢复周期通常是6-9个月,远长于做监测投入的成本。
AI关键词研究90天落地节奏怎么排?
把5步工作流跑通只是开始,真正难的是怎么把这套流程稳定嵌入团队的SEO日常运营节奏里。一次性跑完所有动作然后回归原流程,6个月内必然失效——AI模式还在快速演变,关键词清单必须保持季度迭代。这一行给客户标准化的90天落地节奏拆解如下。
0-30天 基础设施搭建:第1周做种子词采集与AI关键词研究工作流培训;第2周完成传统关键词研究6维基础盘的迁移;第3周搭建三大模型并行用的提示词模板库;第4周做首轮4层意图分解并产出第一版关键词资产规划表。这一阶段团队还在适应工作流,进度可能比预期慢30%是正常的。
31-60天 内容动作落地:第5-6周按规划表完成首批30%的内容资产改写与新增;第7周做AI模式答案路径标注与监测看板搭建;第8周对照SEO关键词AI提示词模板库把日常运营所需的50个高频提示词固化下来。这一阶段最容易出现的问题是内容产出速度跟不上规划,必须接受"先做高优先级20%产生80%价值"的节奏。
61-90天 监测迭代与扩展:第9周完成剩余70%内容动作;第10周做首轮AI模式引用稳定性测试与客户访谈与工单挖词的二次循环;第11周根据三个月数据复盘调整关键词资产规划;第12周做季度迭代规划并把工作流文档归档到团队Wiki。这一阶段才是工作流真正落地的时刻——团队建立起自循环能力之后,AI关键词研究才能从"项目"变成"日常"。
桌游卡牌客户12周做完后第二季度又做了一轮90天迭代——这次只用了原来50%的人力投入,产出了720个新关键词与54个新内容资产。第一轮搭建是花钱阶段,第二轮迭代开始才是赚钱阶段。这套节奏后来被客户复用到自有内部团队的AI 90天工作流路线里,作为AI关键词研究的标准模板。
常见问题解答
AI关键词研究和传统关键词研究的核心差异是什么?
传统选词靠搜索量+竞争度排序;AI关键词研究多一层意图分解,把一个种子词拆成4-7个不同AI模式答题路径,每条路径对应不同长尾簇与内容资产形态。
GPT-4o、Claude、Gemini在关键词研究里怎么分工?
GPT-4o强在意图分解和长尾扩展;Claude强在竞品反推与文本梳理;Gemini强在搜索结果实时数据补充。三类大模型并行用比单一模型准确率高30%以上。
AI模式选词比谷歌SERP选词多了哪些维度?
多了AI答案可被引用度、答案稳定性、答案位置归因三个维度。传统SERP只看排名位置,AI模式还要看是否被纳入答案块、是否成为答案首句引用源。
LLM意图分解模板能直接复用吗?
模板骨架可复用,但每个行业的意图层级和长尾密度差别大。出海DTC类、SaaS类、B2B服务类三类各自需要单独适配meta-prompt结构。
AI关键词研究的工具栈现在该怎么选?
基础层用GSC加Trends加Keywords Everywhere;AI层并用GPT加Claude加Gemini三家;进阶层Ahrefs或Semrush的Topic Cluster配合LLM做意图分组。
AI关键词研究最容易翻车的环节是什么?
幻觉关键词、长尾扩展过度导致主题分散、忽略AI答案稳定性变化这三类是常见雷区。每批关键词上线前必须人工抽样核对真实搜索量与SERP位置。
权威参考资料
- Google Search Central — AI features in Search:https://developers.google.com/search/docs/appearance/ai-features
- Google Search Central — Creating helpful, reliable, people-first content:https://developers.google.com/search/docs/fundamentals/creating-helpful-content
- Google Search Central — Get started with Search Console:https://developers.google.com/search/docs/monitor-debug/search-console-start
- Google Trends:https://trends.google.com/trends/
本文标题:《AI关键词研究的LLM工作流:AI模式时代怎么选词》
本文链接:https://zhangwenbao.com/ai-keyword-research-llm-workflow.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0