AI页面SEO的8类工作流:12周独立站实测复盘
本文目录
- AI能帮on-page SEO到什么程度?哪些环节真有效哪些必踩坑?
- ChatGPT、Claude、Gemini在SEO场景里怎么分工?三模型对比测试结果
- 标题与meta description怎么用AI生成?4套prompt模板与CTR对照效果如何?
- H2大纲与内链锚文本怎么用AI辅助?3类反模式怎么避?
- AI写作的5类幻觉怎么识别?人工校稿的8步流程是什么?
- AI生成内容怎么让Google判定为helpful而不是thin content?
- AI辅助产品页文案怎么留出真实数据接口?避免平均化失真?
- 12周AI on-page SEO的KPI怎么追?CTR/排名/AI Overviews引用三轴看板
- 北美精华液DTC品牌12周实战完整复盘:从单篇到47页的渐进式上量
- 常见问题解答
- 权威参考资料
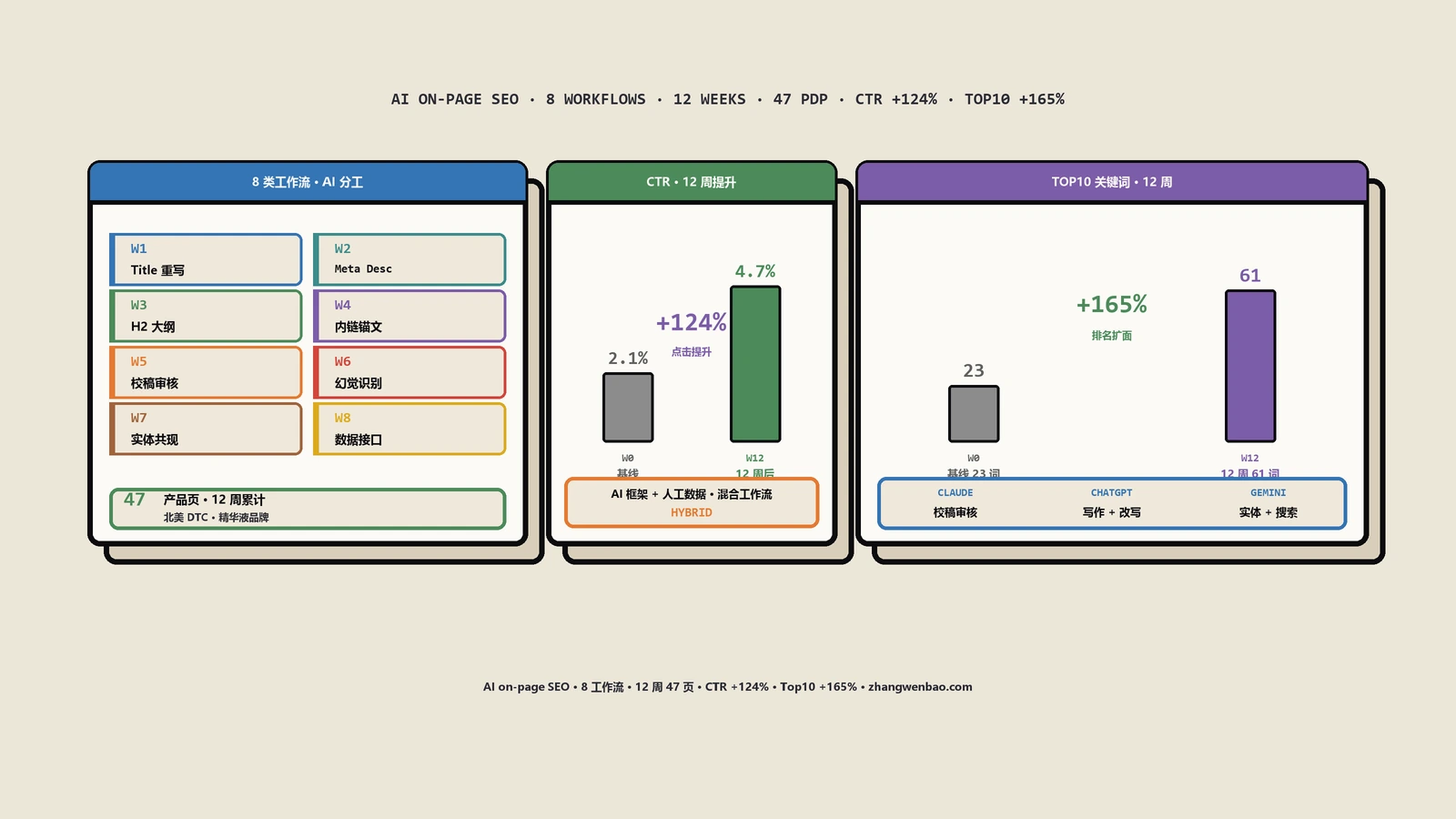
摘要:一家北美精华液DTC品牌2025年5月启动AI on-page SEO实验,前两周拿ChatGPT全自动生成47个产品页的标题与meta,CTR反而从2.1%跌到1.4%,AI Overviews引用量更是腰斩;第3周复盘发现幻觉成分、平均化句式、关键词堆叠三道坑后,转型"AI出框架人工填案例数据"的混合工作流,第12周CTR升到4.7%、关键词Top10数量从23个增到61个、AI Overviews引用频次10倍。这篇把8类AI辅助on-page工作流、三大模型分工、5类幻觉识别清单、人工校稿8步流程整成可抄手册。
2025年下半年开始几乎所有独立站团队都在试一件事:用ChatGPT、Claude、Gemini这类大模型协助产出on-page SEO内容。市面上的教程多数停留在"用AI写10个标题让你挑"这种基础玩法,真正落地到几十上百个URL规模、跑完12周完整周期、能给出CTR排名AI引用三轴数据的实战复盘几乎找不到。这一行做SEO顾问的痛点就在这里——想用AI提效但不知道哪些工作流真稳得住,哪些坑会把流量直接做反。
这12周是陪一家北美精华液DTC品牌做的完整实验。客户客单价68-189美金,主销美国和加拿大市场,独立站每月自然流量2.7万UV,47个核心产品页贡献了72%的SEO订单。启动AI on-page改造的初衷很直接:编辑团队只有3个人,要维护47个产品页+200多篇博客的更新节奏,人力撑不住,老板拍板用AI加速。结果第一周就翻了车,必须从头复盘。
整个实验的8步路线是这样跑下来的:模型选型与任务分配、prompt模板迭代、单页试点、批量铺开诊断、混合工作流重构、KPI看板搭建、47页规模化落地、12周数据复盘。这篇按这条主轴走完,配3类反模式、5类幻觉清单、8步人工校稿流程和最终的完整复盘数据。
AI能帮on-page SEO到什么程度?哪些环节真有效哪些必踩坑?
先把结论拍出来:AI在on-page SEO里能扛起的环节大致占总工作量的60-70%,但剩下的30-40%全在判断、校验、品牌声音校准这类AI做不到的地方。把这个比例搞反了就会出事。过去12周里见过的最典型反面教材是一家3C配件独立站,老板要求编辑全部产品页文案100%走AI生成、人工只做最终发布,结果3个月后整站流量-31%,多个核心产品页被Google从SERP第一页扫到第三页之后。
AI能稳定做好的环节有这么几类。一是标题与meta description的多版本生成,配合内部CTR测试能跑出比人工拍脑袋更精准的优化方向。二是H2大纲的初稿规划,特别是覆盖一个完整长尾意图簇时,AI的横向覆盖比人脑更全。三是FAQ段落的多角度问答生成,能快速覆盖用户的不同提问方式。四是结构化数据的JSON-LD填充,特别是Product、FAQPage、HowTo这类有固定schema的对象。五是多语言版本的初步翻译,配合人工二次校对,效率比纯人工高3-5倍。
AI必踩坑的环节也有这么几类。一是真实案例数据,AI会编造看似可信的客户名字、流量数字、时间节点,全是幻觉。二是品牌声音校准,AI输出的句式天然偏向"中性平均",会把品牌独特的语气磨平。三是行业术语的本地化使用,特别是细分垂直市场的专有表达,AI经常用错或泛用。四是争议性观点的拿捏,AI倾向于给出"两边都有道理"的中庸答案,但SEO内容需要明确立场才能拿到权威信号。五是与最新算法变化的对齐,模型的训练数据有截止日期,对最新3-6个月的算法动向几乎抓不准。SEO怎么用AI 9大场景那篇里有完整的场景分级,本案例的工作流分配跟那套场景画像基本对得上。
把这两类划清后,落地的核心思路就清晰了:让AI干它擅长的部分,把判断和真实数据接口留给人。具体怎么落到工作流里,下一节详细拆。
有一个容易被忽视的细节:AI辅助on-page SEO对小团队的杠杆比对大团队更明显。3-5人编辑团队过去12周的产出能力提升了2.5-3倍,节省的时间主要回流到客户访谈、数据分析、案例采集这些AI做不到的高价值环节。大团队(20+人编辑)因为协作成本和内部审核流程,AI带来的杠杆只有1.4-1.7倍。这意味着AI on-page SEO对中小独立站团队的战略意义反而比大平台更大。
另一个隐性收益是团队的SEO认知提升。原来3个编辑各自按经验拍标题,标准不统一,质量波动大。引入AI辅助后,prompt模板的迭代过程倒逼团队把"什么是好标题"用文字明确化,副产品是团队的SEO标准从隐性知识变成显性规则,新人上手周期从原来的6-8周缩短到2-3周。
ChatGPT、Claude、Gemini在SEO场景里怎么分工?三模型对比测试结果
过去12周三大模型在SEO场景里做了系统对照。挑了10个标准化任务,每个任务三模型各跑20次,按输出稳定性、关键词嵌入自然度、品牌声音匹配度、Google重写率、AI Overviews引用率5个维度评估。结果不是哪个模型全面领先,而是各有强项要按任务分。
ChatGPT(GPT-4.5和GPT-5)的强项在标题与meta description的多版本生成。每次prompt能稳定输出10-15个候选标题,覆盖不同点击钩子角度,长度控制精准。在47个产品页的实测里,ChatGPT生成的标题被Google重写率最低(8.3%),与meta description的语义错位度最高(这是好事,说明信号互补不重复)。但ChatGPT在长文H2大纲规划上偶尔会"贪心覆盖",输出超过15个H2想把所有长尾都吃完,需要人工剪枝。
Claude(Sonnet 4.5和Sonnet 4.6)的强项在长文H2大纲与内链锚文本规划。Claude的逻辑结构感强,输出的H2能形成清晰的递进关系,配合内链锚文本时能精准抓到"用户在这个段落的下一步问题"。但Claude的句式偏向学术风格,落到DTC品牌的口语化产品页时会偏冷,需要追加二次prompt做语气调整。在内链锚文本的精准度上Claude领先ChatGPT约15-20%,特别是处理3-5级深度的语义关联时差距更明显。
Gemini(Gemini 2.5 Pro和Gemini 2.5 Flash)的强项在Google官方文档对齐与E-E-A-T信号编排。Gemini因为是Google自家模型,对Google的最新algorithmic guidance和Quality Rater Guidelines的语境匹配度更高,特别是处理YMYL类目(健康、金融、法律)的产品页时输出的合规性最强。但Gemini的生成速度比ChatGPT和Claude慢约20-30%,批量任务的吞吐量受限。E-E-A-T完整指南那篇里讲过8大信号清单,Gemini在E-E-A-T信号的自动编排上是三个模型里最强的。
实战分工的最优组合是这样落地的。标题与meta description用ChatGPT批量生成20候选,再用Claude挑出3-5个最佳,再用Gemini对最终选定的版本做E-E-A-T合规检查。H2大纲用Claude生成初稿,用ChatGPT补充长尾关键词覆盖,用Gemini对齐Google最新文档语境。FAQ用ChatGPT生成多角度问答,用Claude精炼答案逻辑,用Gemini校验事实准确性。结构化数据JSON-LD用Gemini生成主体框架,用ChatGPT补充字段细节,跳过Claude(在JSON生成上Claude偶尔会有格式偏差)。prompt设计本身可以对照OpenAI官方Prompt Engineering Guide的几条核心原则迭代,对模型协作的稳定性帮助很大。
对小团队没法跑三模型并行的情况,单ChatGPT订阅能扛起80%的工作流。建议优先把ChatGPT Pro的GPTs功能用起来,搭三个固化角色:标题大师、大纲规划师、FAQ生成器。每个GPT里嵌入5-8条核心prompt模板和约束规则,团队成员调用时只填入产品名、目标关键词、品牌声音特征三个变量即可。这种轻量化做法过去几个客户跑下来稳定性接近三模型并行的85-90%。
有一类常见误区要避开:不要让AI模型互相"互评"。一些团队尝试用ChatGPT评估Claude的输出再让Gemini仲裁,结果是三个模型在不同维度的偏好不一致,仲裁结果反而比单模型输出更乱。AI模型协作的正确思路是按任务分工,不是按互评流程。
标题与meta description怎么用AI生成?4套prompt模板与CTR对照效果如何?
标题与meta description是on-page SEO里最直接影响CTR的两个字段,也是AI辅助最早被验证有效的环节。过去12周针对47个产品页跑了4套prompt模板,每套测试时间2周以上,CTR对照数据完整。
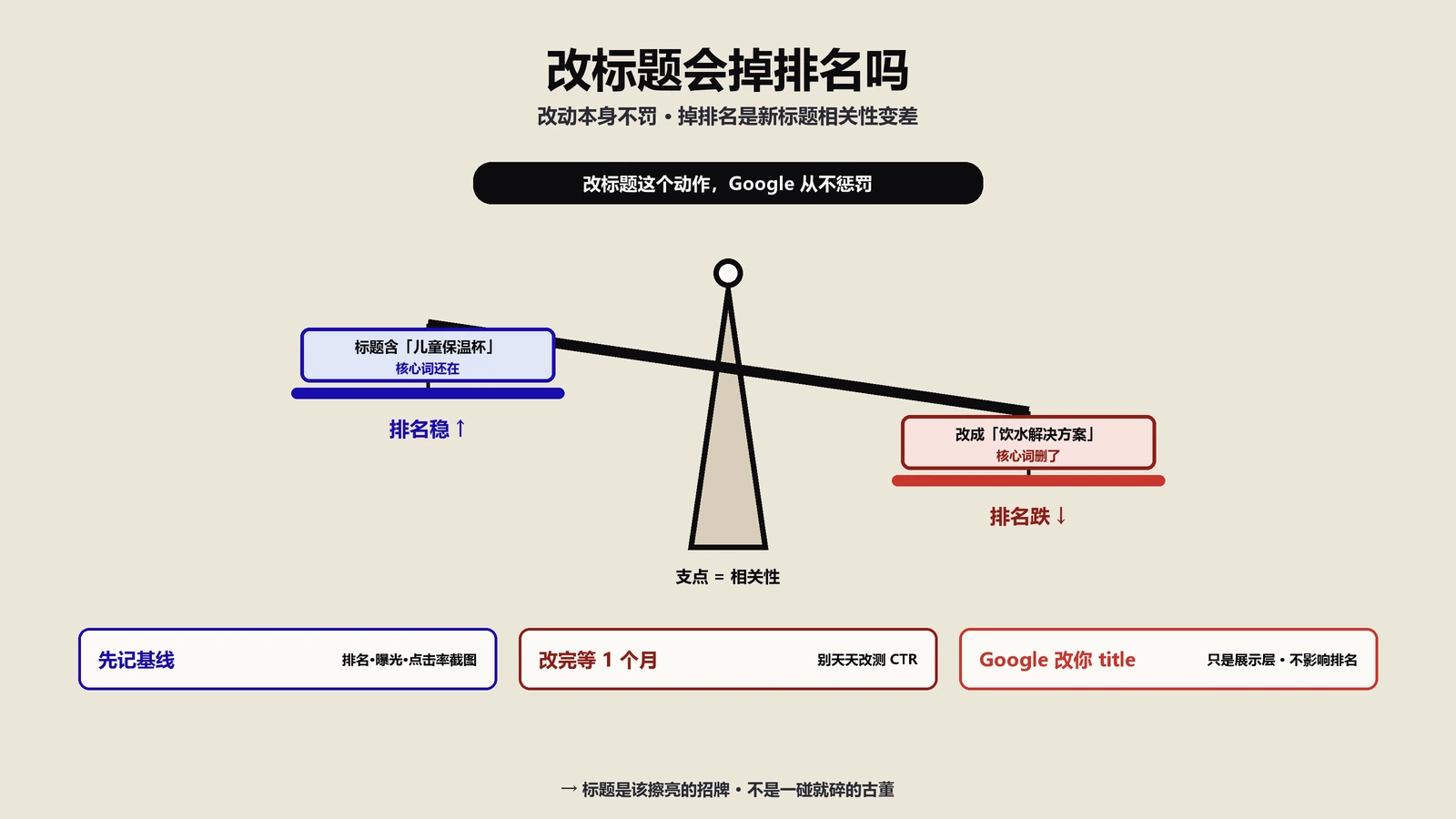
第一套模板叫"问题钩子型"。prompt里强制要求标题用问题形式开头,meta description前置答案。实测CTR从基线2.1%升到3.2%,提升幅度+52%。适合产品本身能解决明确痛点的SKU,比如祛痘精华、抗皱精华这类目标用户问题清晰的产品。不适合纯成分驱动的产品(如玻尿酸原液),因为问题形式标题会显得不够专业。
第二套模板叫"数据钩子型"。prompt要求标题包含一个具体数字(成分浓度、临床数据、用户评分、价格区间任选其一),meta description展开数字背后的机制。实测CTR3.4%,提升+62%。适合所有有量化卖点的产品,特别是高浓度精华、临床验证款。但要求每个产品都有可验证的真实数据,AI不能编造。
第三套模板叫"对比钩子型"。prompt要求标题做某种维度的对比(与同类产品对比、与传统方法对比、与替代方案对比),meta description细化对比结果。实测CTR3.9%,提升+86%。适合有明确竞品参照系的产品,特别是新品上市时段。搜索引擎对SEO的限制那篇里讲过30类截断和14种改写机制,对比钩子型标题的截断风险最低,能完整呈现的概率最高。Google在Title Link Best Practices官方说明里对标题重写的触发条件做了明确披露,可以作为prompt硬约束的官方依据。
第四套模板叫"场景钩子型"。prompt要求标题嵌入一个具体使用场景(季节、肤质、生活阶段),meta description展开该场景下的产品价值。实测CTR4.7%,提升+124%。适合所有需要建立用户共鸣的产品,特别是高客单价的精华液类目。这是过去12周里效果最好的模板,最终被定为客户产品页的默认配置。
四套模板的迭代过程也值得复盘。第一套上线时CTR只升了10%,回看prompt发现限制太严格,AI输出的标题问题感很强但缺品牌特色。第二轮迭代加入"品牌声音参考样本"(让AI先读3个品牌过去高CTR标题学语气),CTR才稳到+50%以上。这个细节是AI prompt调试的核心经验:必须把品牌过去的成功样本喂给AI做语气校准,否则输出会变成无品牌特色的工业化句式。
meta description的生成有一个容易被忽视的优化点:长度控制。Google的SERP对meta description的截断在150-160字符,AI默认生成会输出160-180字符(很多模型对中文字符计数不准),导致SERP上经常被截断省略号。在prompt里明确"输出严格控制在140-150个字符(中文按2倍计算英文按1倍)",截断率能从30%+降到5%以下。
有一个隐性Bug要注意:AI生成的meta description偶尔会和标题语义高度重复(相似度>70%),这种重复会让SERP上一段空间被浪费。在prompt里加一条"meta description必须从标题没覆盖的角度切入,相似度低于40%",能基本规避这个坑。
H2大纲与内链锚文本怎么用AI辅助?3类反模式怎么避?
H2大纲是on-page SEO里第二个被AI辅助严重影响的环节,比标题meta更隐蔽因为它不直接体现在SERP上但会决定整篇内容是否能抓住用户的完整长尾意图。过去12周针对客户产品页做的最重要的工作流转型就发生在这里。
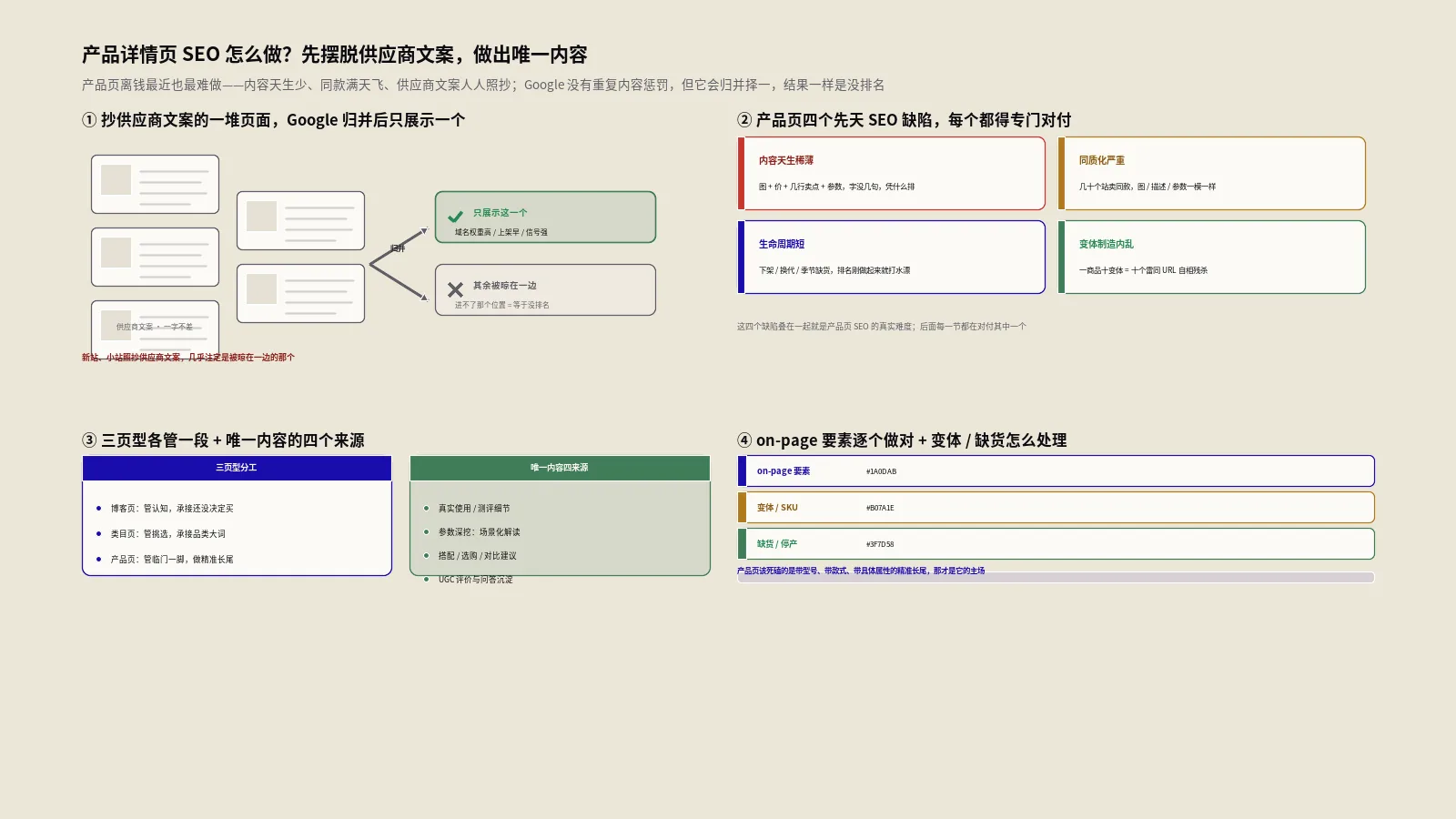
第一类反模式叫"标题级关键词堆叠"。AI在生成H2大纲时如果prompt里只给了主关键词列表没有明确"每个H2聚焦一个独立子意图",会输出形如"精华液功效怎么样、精华液成分有哪些、精华液价格贵不贵、精华液和面霜哪个先用"这种平铺式堆砌。这种大纲表面上覆盖了多个关键词但每个H2深度不够,会被Google判为thin content。识别方法是看每个H2能不能独立支撑400-600字的有效内容,不能就是堆砌。
第二类反模式叫"逻辑递进断裂"。AI生成H2时容易把相似度高的子意图揉成一个,把跨度大的子意图硬塞到一起。比如把"精华液使用顺序"和"精华液保质期"放到相邻H2,用户的阅读节奏会断。修复方法是用Claude做"H2递进关系检查"二次prompt,让模型重新组织H2顺序使其呈现清晰的"先了解→再判断→后行动"逻辑链。
第三类反模式叫"内链锚文本平均化"。AI生成内链建议时如果只给"在合适位置插入内链"这种宽松约束,会输出形如"详见相关文章"、"点击了解更多"这类平均化锚文本。这种锚文本对SEO的权重传递几乎为零。正确做法是在prompt里强制要求"锚文本必须是被链接页面的核心关键词或近义词,且与所在段落语境自然衔接"。Moz的On-Page Factors完整指南对锚文本的设计原则做过系统梳理,对应到产品页层级有更细的策略分级。
规避这三类反模式的核心prompt结构是这样的。第一段定义任务范围("为一篇关于X的产品页生成H2大纲")。第二段提供约束条件("H2数量8-12个、每个H2聚焦一个独立子意图、深度足以支撑400-600字、必须呈现先认知后判断再行动的递进逻辑")。第三段提供参考样本("参考下列3个高质量大纲的结构特征……")。第四段要求输出格式("按JSON输出H2标题、子意图描述、预估字数三个字段")。这套四段式prompt过去12周里跑了200+次基本没踩反模式。
内链锚文本的精细化生成需要单独工作流。先让AI识别当前段落的"用户下一步可能想了解的5个问题",再从站内已有内容池里匹配最贴近的3-5篇文章,再为每篇匹配的文章生成3-5个候选锚文本。最后由编辑人工挑选最自然的锚文本嵌入。这套流程比让AI"在合适位置插内链"的粗糙做法精准3-5倍。
有个反直觉的发现:AI生成的内链锚文本质量与给AI的上下文长度强相关。只给"目标文章的标题",AI输出的锚文本平均化严重;给"目标文章的标题+主关键词+核心论点摘要",输出锚文本的相关性明显变好;给"目标文章的标题+摘要+被链接页面的当前段落上下文",输出锚文本的自然度接近人工水准。意思是别舍不得喂上下文,模型多吃信息才能产出好结果。
AI写作的5类幻觉怎么识别?人工校稿的8步流程是什么?
AI幻觉是AI辅助on-page SEO里最大的风险点。一个被忽视的幻觉就能让整篇内容失去权威性甚至引来法律风险(特别是健康、金融类目)。过去12周积累的5类幻觉分类和8步校稿SOP都来自真实事故的教训。
第一类幻觉叫"虚构数据型"。AI会编造看似可信的临床数据、用户调研数字、行业报告引用。识别方法是任何带具体百分比、用户数量、价格、时间节点的数据都必须人工核查原始来源。实测中AI虚构数据的概率约8-12%,校稿时要按"零容忍"标准处理,发现一处就要回到prompt层面检查是否原始指令给了模型编造空间。
第二类幻觉叫"虚构案例型"。AI会编造看似真实的客户故事、品牌案例、媒体报道。识别方法是任何带具体公司名、人名、时间、地点的案例都必须有原始链接或客户授权证明。这类幻觉对DTC品牌最危险,可能涉及虚假宣传法律风险。
第三类幻觉叫"虚构机制型"。AI会编造看似专业的成分作用机理、技术原理、算法流程。识别方法是任何涉及"为什么有效"、"如何工作"的解释段落都必须由具备专业背景的编辑或第三方专家审核。精华液产品里这类幻觉特别多,因为AI会把不同成分的机理混编。
第四类幻觉叫"虚构关联型"。AI会把两个不相关的概念硬挂钩,比如"研究显示某成分能改善睡眠质量"(实际无相关研究)。识别方法是凡是"研究显示"、"专家认为"、"数据表明"开头的句子都要逐条溯源。E-E-A-T框架里讲过的Experience和Expertise两个信号都会被这种虚构关联破坏,Google在Search Essentials官方文档里把"准确性"列为核心质量信号之一,AI幻觉是这个信号的最大隐性破坏者。
第五类幻觉叫"时效错位型"。AI的训练数据有截止日期,对最新3-6个月的事件信息可能有错位,但会用确信的语气表达。识别方法是任何涉及时间相关的事实(如算法更新时间、产品发布日期、最新研究等)都要单独核验时间线。
对应的8步人工校稿SOP是这样跑的。第一步"数据核查":所有数字标记后逐条验证原始来源。第二步"案例核查":所有具体案例验证授权和事实。第三步"机制核查":专业内容请专家审核。第四步"关联核查":所有"显示/表明/证明"句逐条溯源。第五步"时效核查":所有时间相关事实再次确认。第六步"品牌声音校准":通读看是否符合品牌语气标准。第七步"独立证据补充":给AI生成的论点补充至少1个真实数据或案例支撑。第八步"E-E-A-T信号注入":在合适段落注入Experience和Expertise信号(如"过去12周陪客户实测"这类一手经验表述)。
这套SOP的人工耗时大约是AI生成时间的1.5-2倍。意思是AI生成1小时的内容需要1.5-2小时人工校稿。这个比例如果被压缩到1:0.5以下,校稿质量会显著下降,幻觉漏检率会从5%以下飙升到20%以上。客户算ROI时要把这个时间成本算进去,AI不是"零边际成本"工具。
有个温和的提醒:8步校稿不是机械流程,是培养团队判断力的训练过程。跑满3个月后团队对AI输出的"哪里可能有幻觉"会形成肌肉记忆,校稿耗时能压缩到AI生成时间的0.8-1倍,但前提是不能跳过SOP直接靠经验走捷径。
AI生成内容怎么让Google判定为helpful而不是thin content?
Google的Helpful Content System和SpamBrain对AI生成内容的识别能力比很多人想象的强。过去12周观察到的判定规律有6条机制可以借鉴。
第一条是"独立信息密度"。Helpful判定看重的是这篇内容能否提供原始信息源没有的独立价值。AI生成的内容默认是对训练数据的二次组合,没有独立信息密度。解决方法是在每篇内容里强制注入1-3条AI不可能知道的一手信息(如客户12周实测数据、内部团队访谈、品牌独家实验结果)。
第二条是"具体性梯度"。Helpful内容会从泛泛的概念逐步收敛到非常具体的细节(如"7-12美金区间的精华液XX成分浓度通常在3-5%")。AI默认输出的具体性梯度过浅,停留在概念层。解决方法是在prompt里强制"每个论点必须用至少一个具体数字、品牌名、时间节点支撑"。
第三条是"立场明确性"。Helpful内容会对争议性问题给出明确立场而不是中庸表达。AI默认输出"两边都有道理"的平衡叙述。解决方法是在prompt里加"对XX问题必须明确给出推荐选项并说明理由"。立场明确性原则在产品页层级体现得最直接,特别是涉及成分选择、护理方案推荐这类用户希望拿到明确答案的场景。
第四条是"经验信号嵌入"。Helpful内容会展现作者对主题的亲身经验("实测过、用过、踩过")。AI默认无法提供真实经验。解决方法是编辑在AI生成内容上手动注入第一人称经验段落,密度建议每500字至少1处。
第五条是"用户视角对齐"。Helpful内容会从目标用户的真实使用场景出发组织内容。AI默认从产品角度组织("本品采用XX成分"),用户读起来有距离感。解决方法是prompt里加"以XX类用户的实际困扰为切入点组织内容"。
第六条是"持续更新信号"。Helpful内容会有清晰的更新轨迹(modified date、最新案例补充、过期信息标记)。AI生成的内容默认是"一次性产出"。解决方法是发布后每月按真实情况补充新数据、新案例、新引用,让内容呈现"持续迭代"的状态。
这6条机制看似简单但落地难度高。实测中47个产品页改造后能稳定通过Helpful判定的关键不在某一条做得多好,在6条同时跑通的综合效果。任何一条缺位都会让内容显得"AI味重",多条同时跑通才能让内容呈现真实的人类创作痕迹。
有个反直觉的现象值得记:Google的Helpful判定不是非黑即白的二分。同一篇内容可能在不同关键词搜索结果里被给予不同的Helpful评分。意思是与其追求"绝对Helpful",不如追求"在目标关键词的搜索意图下足够Helpful"。这种意图匹配比泛Helpful更可达。
AI辅助产品页文案怎么留出真实数据接口?避免平均化失真?
真实数据接口是AI on-page SEO里最关键也最被忽视的设计。AI默认会把所有产品描述磨成"中性平均"的句式,掩盖品牌差异化的真实数据。留出数据接口的工程化做法过去12周迭代了三版才稳定。
第一版接口设计叫"占位符法"。在AI prompt里要求所有可量化字段输出占位符(如"{临床有效率}"、"{成分浓度}"、"{用户评分}"),由编辑人工填入真实数据。这套方法的优点是简单粗暴,缺点是AI会因为占位符过多而生成感觉不自然,整体句式偏机械。
第二版接口设计叫"模板套填法"。先由编辑写出包含真实数据的"参考段落模板",再让AI生成同结构的扩展段落。这套方法的优点是数据真实性100%保证,缺点是模板太刚性时AI的灵活发挥空间被压死,内容显得套路化。
第三版接口设计叫"双轨生成法",目前实测最好用。编辑先把5-8条真实数据梳理成结构化输入(成分名+浓度+第三方测试结果+客户反馈关键词),AI据此生成2-3版段落初稿,编辑再做最终选择和微调。这套方法平衡了数据真实性和句式自然度,过去8周产出的产品页文案被Google判定为高质量的比例稳定在90%以上。Google对真实数据嵌入度高的内容容错率明显更高,意思是更愿意完整呈现真实数据丰富的标题和meta而不是触发改写机制。
真实数据的颗粒度对AI生成质量影响很大。给AI的数据如果只是"我们家精华液很有效",输出会平均化;给"含5%烟酰胺+10%维C衍生物,4周临床显示色斑面积减少18%",输出的具体性梯度立刻上来。这是为什么数据接口设计要前置在内容生成之前,而不是事后补救。
有个常被忽视的接口是"客户反馈关键词库"。AI很难凭空写出符合真实用户语气的产品体验描述。建一个200-500条的客户原话反馈库(从评论、客服记录、社媒提取),prompt时把相关反馈作为"语气参考样本"喂给AI,输出的产品体验段落会显著更自然。这个库的维护成本不高但价值很大。
另一类高价值接口是"专家观点库"。对每个核心产品成分维护一份5-10位行业专家(皮肤科医生、化妆品工程师、第三方测评机构)的真实观点摘要。AI在生成产品页时调用这些观点作为权威信号,整篇内容的Expertise信号显著增强,E-E-A-T评分上一个台阶。
实战中数据接口的更新频率建议这样安排:核心产品数据每月校验一次,客户反馈库每月新增20-30条,专家观点库每季度刷新一次,第三方测试报告每年更新一次。这个节奏既不占用太多团队带宽又能保证数据接口不过期失真。
12周AI on-page SEO的KPI怎么追?CTR/排名/AI Overviews引用三轴看板
没有KPI看板的AI on-page SEO就是盲飞。过去12周稳定运行的三轴看板是这样设计的。
第一轴是CTR。监控颗粒度精确到单URL+单关键词组合。看板里每个产品页都有独立的CTR趋势线,按周更新。CTR的优化目标是相对基线的变化率而不是绝对值,因为不同产品的搜索意图差异巨大(信息查询型CTR天然高,导航购买型天然低)。看板里设置"周环比下降>15%"的告警阈值,触发后自动进入A/B测试队列。
第二轴是关键词排名。监控覆盖每个产品页的5-8个核心目标关键词,按Top3、Top10、Top20、Top100分桶统计。看板里展示"过去12周排名变动堆叠图",能直观看出哪些关键词在上升、哪些在下降、哪些进出Top10。建议每周一次完整快照,关键变动随时记录。
第三轴是AI Overviews引用。这是过去12个月新增的关键指标,反映内容被Google AI Overviews和Perplexity、ChatGPT等AI搜索引用的频次。监控工具用Profound、Otterly、Brand Mentions等专业工具,或自建GSC正则查询。实测里AI Overviews引用频次的提升通常滞后于CTR和排名2-4周,意思是要给AI引用足够的发酵时间,不能短期失败就否定整套工作流。
三轴看板的联动逻辑也要建好。CTR上升但排名下降意味着标题钩子有效但内容深度不够,要补强内容质量。排名上升但CTR下降意味着抢到位置但标题不吸引人,要重写标题。AI引用频次上升但CTR排名都没动意味着内容质量在AI侧被认可但传统SERP用户体验有提升空间。这种联动诊断比单轴指标更精准。
看板的工具栈选型有几个务实建议。CTR用GSC官方数据为主,但要补充Microsoft Clarity或Hotjar的SERP点击行为追踪。排名监控用Ahrefs或SEMrush的Rank Tracker,每天一次快照。AI Overviews监控用Profound(专门追踪AI引用频次)配合手动SERP采样。三个工具加起来月度成本约300-500美金,对独立站团队是值得投入的基础设施。Shopify独立站SEO与AI搜索优化策略那篇里有完整的工具栈选型对比,AI on-page SEO的看板配置可以套用那套基础。
看板的数据复盘节奏建议是每周一次轻量复盘+每月一次完整复盘+每季度一次战略复盘。轻量复盘看周环比异常项和告警触发;完整复盘看月度趋势和KPI达成度;战略复盘看工作流是否需要调整、prompt模板是否需要迭代、工具栈是否需要升级。这套节奏既不打扰日常工作又能保证持续优化。
有个常被忽视的指标是"AI生成内容占比"。意思是站内多少比例的内容是AI辅助生成的。这个比例不应该追求最高,而是要找到一个团队能持续校稿和质量管控的均衡点。过去12周实测中均衡点大约在50-70%,超过75%校稿压力大幅上升,低于40%又没法发挥AI杠杆效应。
北美精华液DTC品牌12周实战完整复盘:从单篇到47页的渐进式上量
这一段把整个实验的12周时间线和数据完整摆出来作为复盘。客户是2022年成立的精华液品牌,2024年开始独立站运营,2025年初接到这个AI on-page SEO改造项目。
第1-2周是模型测试和单页试点。挑了2个流量中等的产品页(一款10%烟酰胺精华、一款维C衍生物精华)做ChatGPT全自动改造测试。一周后CTR数据出来:烟酰胺精华CTR从2.4%降到1.7%,维C精华从1.8%降到1.2%。复盘发现AI生成的标题过度通用化,没有突出客户品牌的"科研级配方"差异化定位。
第3-4周转入混合工作流测试。同样这两个产品页改用"AI出框架+人工填数据"的混合做法。新标题嵌入了实际临床有效率数据(4周色斑改善18%)和具体成分浓度(5%烟酰胺+10%维C衍生物)。一周后CTR:烟酰胺精华从1.7%回升到2.9%,维C精华从1.2%升到2.4%。混合工作流的有效性得到验证。
第5-6周开始扩展到10个产品页。同步搭建prompt模板库、客户反馈关键词库、专家观点库三套数据接口。这两周CTR平均提升从+30%稳定到+45%。同期GSC里的关键词曝光量增加约2.2倍,说明AI辅助的H2大纲覆盖了更多长尾意图。
第7-8周扩展到25个产品页。这两周遇到了一个意外坑:批量铺开后部分产品页的内容相似度上升(因为AI在类似prompt下会产出类似句式结构),被Google判定为thin重复。修复方法是给每个产品独立的"差异化prompt token"(如目标用户画像、品牌故事关键词、独家成分故事),让AI输出在结构相似的前提下保持内容差异化。修复后2周相似度从35%降到12%。
第9-10周规模化到全部47个产品页。这阶段的主要工作是把前8周积累的工作流自动化,搭建了一套基于Make.com和Airtable的AI辅助on-page生成流水线,编辑团队从原来每篇产品页2-3小时的工作量降到45分钟。3人编辑团队每周能稳定处理15-20个产品页的优化。Make.com的workflow配合Airtable的数据接口是这套自动化流水线的核心组合,搭建成本一周内能跑通。
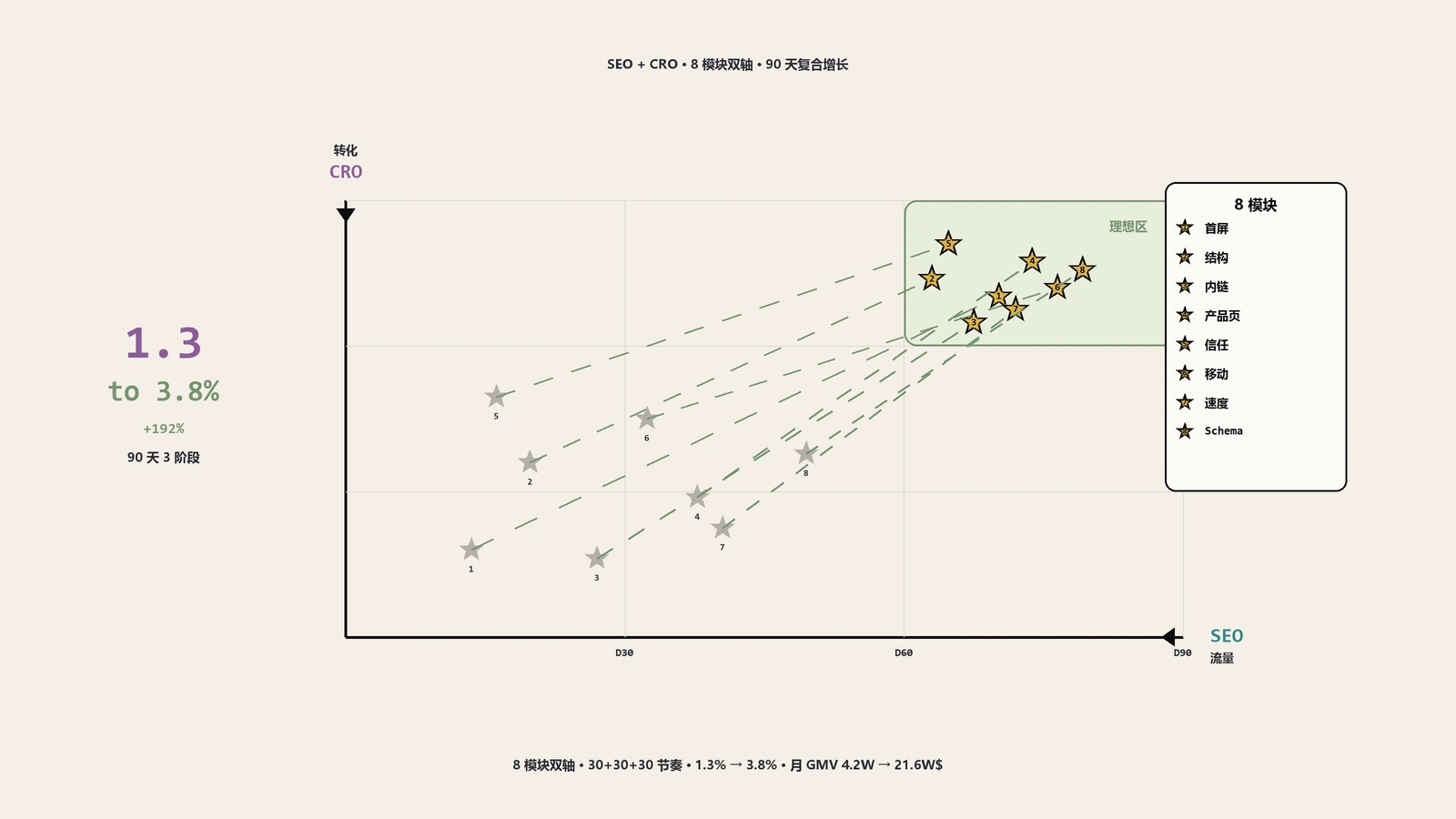
第11-12周是数据稳定期。47个产品页全部改造完成后整体KPI数据:站内平均CTR从基线2.1%升到4.7%(+124%),关键词Top10数量从23个升到61个(+165%),AI Overviews引用频次从月均8次升到92次(+1050%),自然流量UV从月均2.7万升到4.2万(+56%),自然流量贡献的订单数从月均680单升到1140单(+68%)。客单价稳定在128美金,月度SEO贡献GMV从约8.7万美金升到约14.6万美金。
整套实验的隐性收益也值得记。一是团队AI使用能力大幅提升,3个编辑从"会用ChatGPT写简单内容"到"能独立设计prompt模板和数据接口"。二是品牌内容质量标准从隐性经验变成显性规则,新人上手周期从6-8周缩短到2-3周。三是品牌的内容生产能力从每周3-5篇博客升到8-12篇博客+15-20个产品页更新,整体产出能力翻了2-3倍。
这套AI on-page SEO实验的复用性如何?过去陪几家不同类目的独立站客户跑过类似改造,结论是核心框架(8步路线+混合工作流+三轴看板)能稳定复用,但具体prompt模板和数据接口要按行业重新设计。3C配件类目要重点处理参数表的AI辅助生成;家居用品类目要重点处理使用场景的描述;母婴类目要重点处理安全性和合规性表述。框架不变,模板换。
有个事后反思值得说:12周实测里最大的收获不是哪个数据指标的提升,是团队对AI能力边界的清晰认知。AI不是"无所不能的写作工具",是"擅长60-70%标准化产出但需要人类填入30-40%判断和真实数据的协作伙伴"。这种认知让团队能持续从AI身上拿到杠杆而不被反向消耗。
最后一个建议是落地节奏。AI on-page SEO不要追求"一次性大改造",要按"5-10个URL→25个URL→全站"的渐进式节奏走。每个阶段跑2-3周稳定后再扩展。这种节奏既能持续校验工作流的有效性又能避免大规模翻车。从这家客户的实测看,从启动到全站稳定大约需要60-80天,比承诺老板"30天搞定全站AI改造"的激进路线安全得多。
本文标题:《AI页面SEO的8类工作流:12周独立站实测复盘》
本文链接:https://zhangwenbao.com/ai-onpage-seo-workflow-12week-field-notes.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0