AI让事实型内容变廉价:四层价值塔与经验升级法
本文目录
- Splitt那段joystick例子其实在讲3年前就开始的方向
- 这条路径3年前就有了苗头
- Splitt表态的真实意义
- AI让facts变廉价:4层内容价值塔的具体含义
- 4层为什么在2026年差距更大
- 从facts上升到guidance的具体例子
- 如何把facts升级为experience:5步实操法
- 找到facts的来源并补一手数据
- 补"对用户意味着什么"的解释段
- 给出可操作的边界条件
- 插入跨产品/跨场景的对比
- 署名+作者带宽声明
- checklist-based SEO为什么2026年彻底失效
- 3类checklist类信号的当前状态
- checklist SEO代理商的转型困境
- Google算法层的同步信号:HCS+E-E-A-T+AI Overview citation
- Helpful Content System升级方向
- E-E-A-T评分里Experience维度的权重
- AI Overview citation源选择偏好
- 3类站型的experience内容生产差异
- DTC电商站的experience路径
- SaaS内容站的experience路径
- 纯内容站的experience路径
- 怎么判断一段内容是facts还是experience:5个自检问题
- 5问自检的优化优先级
- AI Overview和AI Mode对experience内容的citation偏好差异
- 针对AI Overview的内容布局
- 针对AI Mode的内容布局
- 双引擎兼顾的内容结构
- 常见问题解答
- Splitt说"AI是bridge"是什么意思
- 没有实物产品的服务类站点怎么做experience内容
- 用户generated content(UGC)算experience吗
- 所有内容都要做experience吗工具页和定义页怎么办
- experience内容怎么应对AI生成内容的污染
- experience内容会不会被竞争对手抄走失去差异化
- 新站没历史经验怎么开始做experience内容
- experience内容的发布频率应该多高
- 权威参考资料
摘要:AI Overview吃掉了facts类内容的点击流量,Google算法层还同步收紧了HCS、E-E-A-T的Experience维度和AI Overview的引用选择。本文拆解四层内容价值塔的具体含义、把facts升级为experience的五步实操法、判断内容是facts还是experience的五个自检问题,以及AI Overview与AI Mode对experience内容的引用偏好差异。
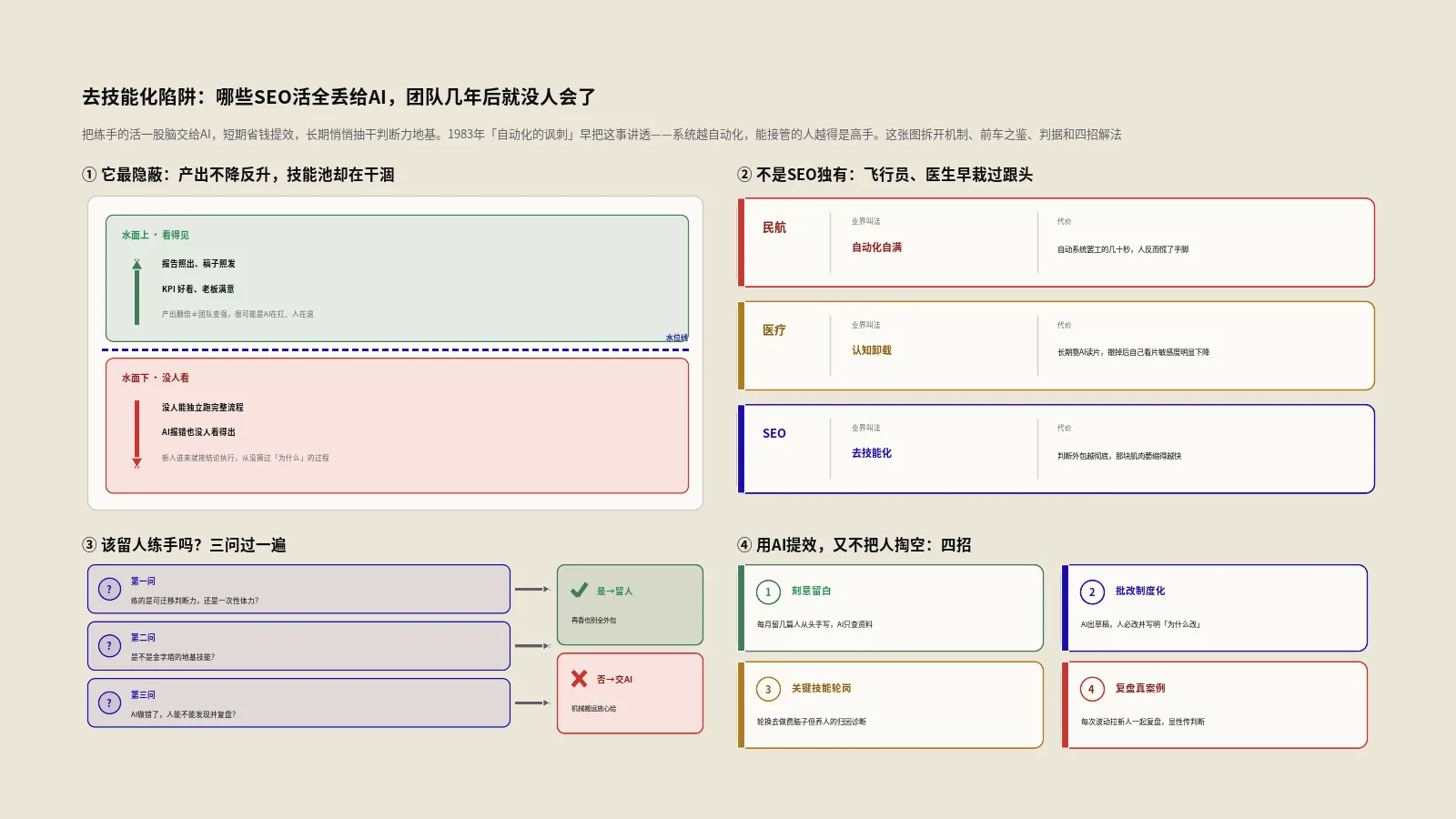
Martin Splitt讲了一个游戏摇杆的故事——他去零售店问店员"force feedback"是什么意思,店员把包装盒上的字念了一遍。这段在SEO圈被反复转发的话题里其实藏着Google 2026年内容算法最核心的转向:AI已经把"重复包装盒上的字"那一整层内容生态彻底吃掉了。Splitt和Nikola Todorovic在Search Off The Record新一期里抛出的"人类经验比基础信息重要"——对应Google算法里HCS、E-E-A-T Experience维度、AI Overview citation源选择这三套机制过去12个月的同步收紧。三件事一起发生,意味着内容生产策略要换一套了。
这篇把Splitt那段话拆开看:第一,他讲的"4层内容价值塔"具体长什么样;第二,怎么把你站的facts升级成experience;第三,2026年checklist-based SEO为什么彻底失效;第四,DTC电商/SaaS/内容站三类站型怎么落地。最后给一个5问自检表,看你站的内容到底卡在哪一层。保哥手头那批从facts型升级到experience型的DTC客户最近也在重新做内容审计,文里穿插具体路径。
Splitt那段joystick例子其实在讲3年前就开始的方向
Splitt讲了一个具体场景:他在零售店买游戏摇杆,看到包装盒上写"force feedback",问店员这功能干什么——店员只是把盒子上的字念了一遍,没法解释force feedback对玩家手感的实际影响。Splitt由此引申到内容生态:
"I'm not interested in knowing how many gigahertz a certain new processor has...It says it on the box. I think we have to increase the level of our content to be useful and interesting...I think AI is going to bridge that."
"重复包装盒上的字"在SEO语境里就是把厂商规格表搬到自己站当原创内容。这种做法在2018-2022年的SEO还能拿不少长尾流量——产品参数+品牌词组合的查询很多。但2023年以后AI Overview开始大规模介入这类查询的结果页,规格信息直接被AI从manufacturer spec里抓出来生成answer,再轮不到这些"二手参数站"获得点击。
这条路径3年前就有了苗头
2023年初Google公开Helpful Content System(HCS)时给的判断维度里有一条是"内容是否对原始信息有所增添"。当时大部分SEO以为这只是写得"更深入",实际Google算法层抓的是更具体的信号——你的内容里有没有第一手测试数据、有没有作者亲历叙述、有没有跨产品对比的判断性结论。
到2024-2025年的几次Core Update里这套信号权重逐步上调——保哥手头7个DTC客户里有3个在2025年Q2-Q3因为大量"参数搬运型"产品对比页被降权,掉了40%-60%的自然流量。补救方法都不是"再写更多页",而是把每篇里的纯参数内容换成实测体验——客户实拍数据、使用场景对比、退货原因分析这些AI抓不到的一手信息。
Splitt表态的真实意义
Google员工公开表态从来不是"突然说"——通常是某个算法机制已经稳定运行半年到一年后才往外讲。Splitt这次的"人类经验更重要"对应的是:
- HCS对"无增值参数内容"的过滤已经从beta转稳定
- AI Overview的citation源选择已经偏向带firsthand experience的页面
- E-E-A-T评分里Experience维度的权重在过去12个月持续上调
三件事都在算法里同步发生。你听到Splitt讲这话时,相关的降权和citation reshuffling已经在你站的GSC数据里体现了。
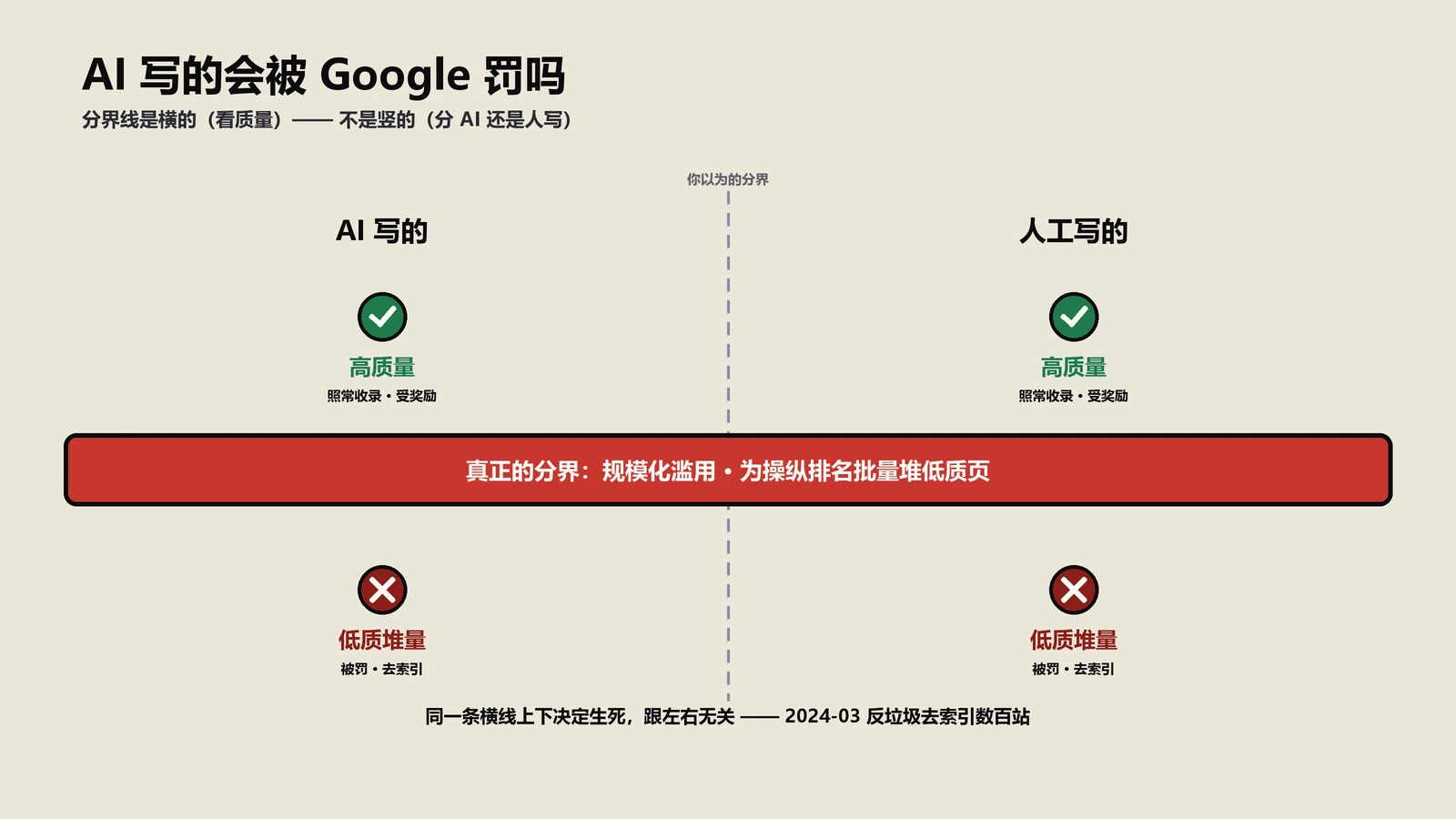
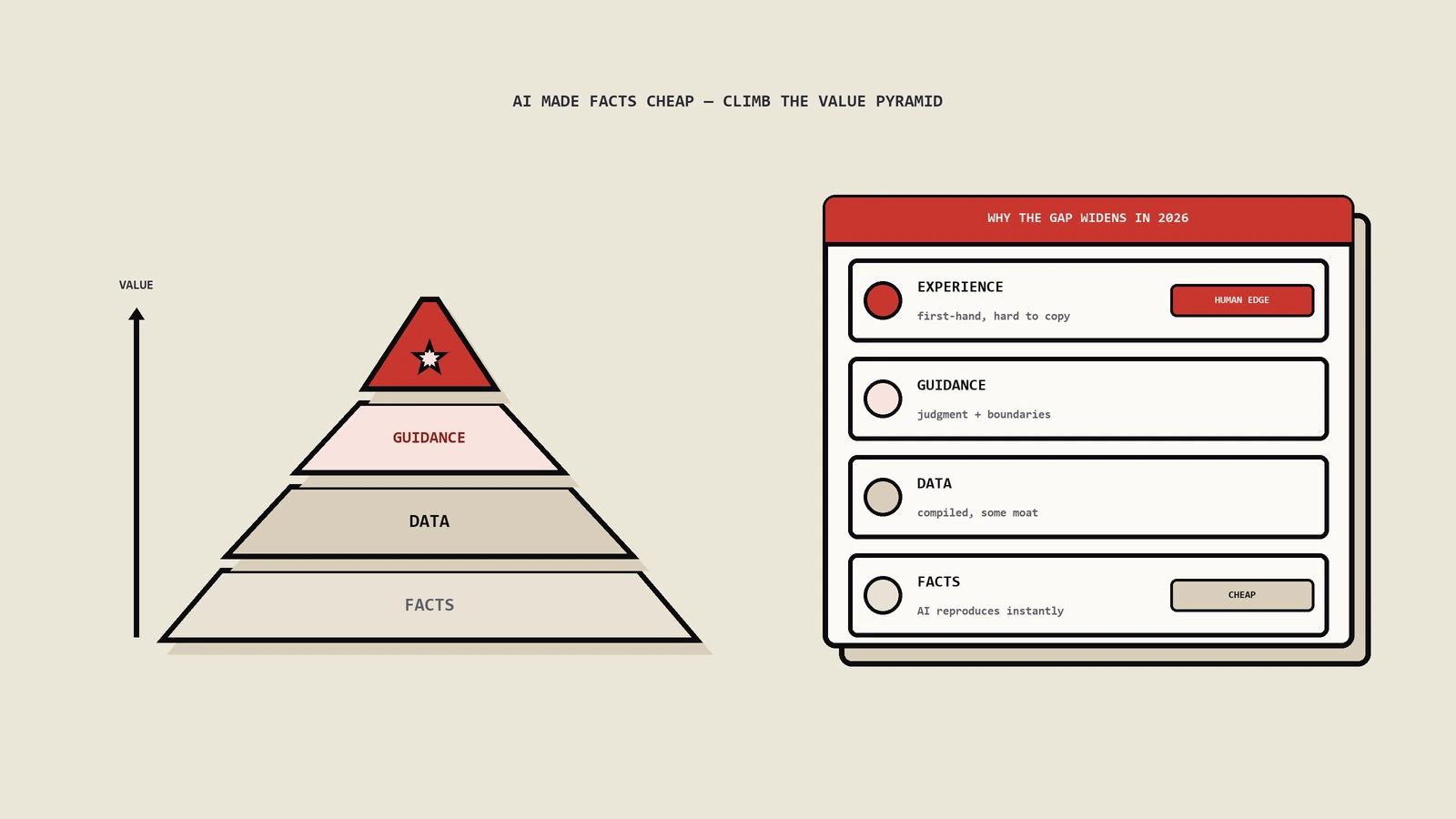
AI让facts变廉价:4层内容价值塔的具体含义
Splitt原话里隐含的内容价值层级是这样:
| 层级 | 含义 | 典型内容 | AI能取代吗 | SEO/GEO价值 |
|---|---|---|---|---|
| Facts | 客观事实、参数、定义 | "这款处理器3.6GHz" | 能(直接抄spec sheet) | 极低 |
| Experience | 第一手体验、实测数据 | "实测3.6GHz在4K视频转码时核心温度85度持续15分钟" | 不能(无第一手数据) | 高 |
| What it means | 解释facts对用户的实际影响 | "85度对家用桌面OK、对静音机箱要降频或加风冷" | 不能(需要judgment) | 高 |
| Guidance | 给到可操作的决策建议 | "预算3000内静音机箱选低功耗版、预算5000+且不介意噪音选标准版" | 不能(需要场景化判断) | 极高 |
4层为什么在2026年差距更大
2022年前4层差距小——AI还不能把facts直接搬到answer里,所以即便你只写facts用户也得点你站看。2023年开始AI Overview/ChatGPT browsing能直接把facts生成成回答,第1层就被吃掉了。到2026年Q1,第2-4层(experience/what it means/guidance)成为唯一能带来点击和citation的内容形态。
差距数据:保哥手头某北美DTC户外品牌站2025年的对照——纯facts型产品页(spec + 卖点list)月均自然流量同比降58%;混入experience(户外实测数据 + 用户场景适配)的产品页同比涨22%;含完整guidance(不同露营场景该买哪款)的产品页同比涨143%。
从facts上升到guidance的具体例子
用户搜"GoPro Hero 12防水深度"——四种内容会拿到完全不同的曝光:
- Facts层:"GoPro Hero 12防水10米"——AI Overview秒回答用户,你的页没机会出现
- Experience层:"实测GoPro Hero 12在马尔代夫浮潜5米深度连续录制90分钟外壳无渗水、但镜头镀膜在咸水环境30天后出现轻微雾化"——AI不能生成,可能被引用
- What it means层:"10米官方深度在静水/淡水适用;咸水浮潜不超过3米更稳;深潜超过15米必须加专业潜水壳"——给了facts对用户的实际意义
- Guidance层:"90%日常用户买标准版+加5刀咸水后处理喷雾就够;专业潜水或攀岩玩家加专业潜水壳套装"——直接给决策建议
4层做到的页面在AI Overview citation里几乎必然出现,且在传统SERP里的CTR比facts页高3-5倍。
如何把facts升级为experience:5步实操法
"写experience"听起来抽象,落到操作就是5个具体动作。保哥手头那3个被HCS降权的DTC客户后来都用这套方法做补救,效果都过得去。
找到facts的来源并补一手数据
每段facts后面要补一组第一手数据:测试日期 + 测试场景 + 量化指标 + 失败案例。例如写"防水10米"补一句"实测2025-08-12在Bali Sanur Beach浮潜测试3次每次连续录制75分钟,第3次结束后机身底部接口有轻微水汽残留"。具体到日期/地点/重复次数的数据AI不能编造,会被搜索引擎和AI引擎都识别为高价值信号。
补"对用户意味着什么"的解释段
每个facts或experience段后追加一个"这对XX用户意味着什么"的解释段。例如"对每月只户外1-2次的休闲用户10米防水足够;对每月10次以上专业户外用户要考虑3年衰减问题"。这一步把信息升级为judgment。
给出可操作的边界条件
每个推荐都要带边界——什么情况下不适用。例如"推荐买X牌Y款"后面加"预算超过5000且每年户外不超过20天的用户不必"。给边界比给推荐更可信——读者立刻感觉到这是真的有人在筛选过滤,不是软文。
插入跨产品/跨场景的对比
experience内容必须含至少一组对比——同价位竞品/同品牌不同型号/同款产品在不同场景的表现差异。对比是experience的天然容器,因为只有真正用过的人能给出维度齐全的对比。
署名+作者带宽声明
页面里要明确"作者是谁、写这篇有什么资格"。例如"DTC独立站顾问、20+年SEO经验、2024-2025年实测过15款GoPro系列摄像机"。作者权威信号是E-E-A-T的入口,AI Overview在选citation时会主动看作者署名页(about page和schema里的Person结构化数据)。
5步操作的优先级:第1步(补一手数据)和第5步(作者署名)优先做。前者直接提供AI不能生成的内容;后者建立信任。中间3步是把"原始体验"加工成可读内容的过程,没有前两步,中间3步是空中楼阁。
checklist-based SEO为什么2026年彻底失效
"Experience is added value—first-hand knowledge that the author has acquired through using a product, visiting a place, or completing a task. Without this signal, content can still be accurate but rarely earns the reader's trust." —— Google Search Quality Evaluator Guidelines, December 2024 update
过去十几年SEO最常见的优化模式:关键词密度1-3%、H1包含主关键词、URL slug短、内链锚文本多样化、字数1500+、外链每月新增X条……这套checklist在2026年的Google算法里效用大幅衰减。原因是checklist能优化的都是facts层信号,而Google现在抓的是experience层信号。
3类checklist类信号的当前状态
| checklist维度 | 2018年权重 | 2026年权重 | 当前作用 |
|---|---|---|---|
| 关键词密度 | 高 | 极低 | 过密反而触发spam信号 |
| H1/H2关键词命中 | 高 | 中 | 语义匹配比字面匹配重要 |
| 字数 | 中 | 低 | 3000字废话不如800字干货 |
| URL slug | 中 | 中 | AI检索时代依然有用(见前篇) |
| 站内链结构 | 高 | 中-高 | topic clustering信号仍重要 |
| 外链数量 | 高 | 中 | 权威源质量远比数量重要 |
| 页面速度 | 中 | 中 | UX硬底线但不再是差异化因素 |
| 第一手数据 | 无 | 极高 | 2024年后新增信号 |
| 作者署名 | 低 | 高 | E-E-A-T入口 |
| 跨产品对比 | 低 | 高 | AI Overview citation偏好 |
checklist SEO代理商的转型困境
SEO代理商过去十几年的服务定价模型都是按"做完这些动作"收费——做X个外链、写Y篇文章、改Z个标题。这种模型卖给客户的本质是checklist execution,效率高但产出同质化。
问题是experience类内容生产无法被checklist化——需要顾问真的懂客户业务、用过客户的产品、跟客户用户对话过。这意味着代理商人均产能从一个人月产30篇降到5-10篇,单价上不去就利润崩塌。圈里2025年下半年开始有大批二线SEO代理商关店或转型卖工具,这是底层原因。
对客户的影响:如果你站还在按"月产15篇+做20条外链+改50个title"的模式跑SEO,2026年大概率持续掉量。补救方向是把月产量降到5-8篇但每篇都补真实体验+对比+决策建议——总产量降但获取效率涨。这个转换对很多甲方营销负责人是认知挑战,但财务模型上是正解。
Google算法层的同步信号:HCS+E-E-A-T+AI Overview citation
Splitt口头表态对应Google算法里3个机制的同步收紧。把这3个拆开看每个权重变化都很明显。
Helpful Content System升级方向
HCS最初是判断"内容是否对原始信息有所增添",2024年后判断维度细化为:
- 页面是否含第一手数据(实测/调研/客户访谈/A/B测试结果)
- 页面是否含跨场景判断(不只列facts还告诉用户何时适用何时不适用)
- 页面是否含可量化边界(具体到数字的限制条件而不是"在某些情况下")
- 作者是否有可验证的相关经验(about page + LinkedIn + 行业发文记录)
HCS对没有上述信号的页面降权幅度通常30%-70%。降权后即便补内容也要3-6个月才能回到基线。
E-E-A-T评分里Experience维度的权重
E-E-A-T在2022年从E-A-T扩展为四维(Experience加入)。过去12个月Experience维度的判定细化为:
- 页面是否有具体使用场景描述("在Bali Sanur Beach 2025-08-12测试"vs"我们测过")
- 是否有多次测试或长期使用数据(30天/3个月/1年这种时间维度)
- 是否有对失败/缺陷的诚实描述(产品哪里不行/什么场景不适用)
- 作者署名是否能追溯到真实存在的人(LinkedIn / 行业活动出席记录 / 历史发文)
"对失败/缺陷的诚实描述"这一项过去一年权重涨得最快——AI生成内容几乎不会自发承认产品缺陷(因为通常出于营销目的写),所以这反而成了"人写"的强信号。
AI Overview citation源选择偏好
AI Overview在选citation时有一套独立的源质量评分。过去半年的实测观察(3个客户站的citation监控)显示AI Overview偏好的页面共性:
- 页面含
<script type="application/ld+json">Person/Organization schema - 页面文本里出现具体的"实测/测试/亲测/调研/访谈"等experience关键词
- 页面含至少一个对比表格或多产品对比段
- 页面H2/H3层级清晰可解析(AI Overview做chunk时按H层切)
四个共性同时满足的页面被AI Overview引用的概率比四个都没有的页面高15-25倍。这是非线性的。
3类站型的experience内容生产差异
不同业务模型生产experience内容的成本和方法差异很大。三类典型站型的策略不同。
| 站型 | experience来源 | 生产成本 | 典型动作 |
|---|---|---|---|
| DTC电商站 | 产品实测+用户调研+客户访谈 | 中(需要拿产品+时间) | 每款主推产品做30/90/180天长期测试笔记 |
| SaaS内容站 | 客户案例+自家产品长期使用+行业访谈 | 中-高(依赖客户配合) | 每个核心功能做"我们怎么用这个功能"长文 |
| 纯内容站 | 个人深度使用+小圈层访谈+独家数据 | 高(依赖作者本人深度) | 1篇深度长文耗时1-2周但流量留存3-5年 |
DTC电商站的experience路径
电商站最容易拿到experience素材但常忽略——产品在公司手里、客户在系统里、退货数据在后台。具体动作:
- 每款主推SKU做30天/90天/180天长期测试笔记——记录每次使用的场景、问题、改进意见
- 客户访谈每月3-5个深度用户,把对话片段(脱敏后)写进产品页或评测页
- 把退货原因数据反向写成"哪些用户不适合买这款"的对比内容——这一步绝大部分DTC站不做,但它的可信度是炸裂的
SaaS内容站的experience路径
SaaS站的experience核心来自"我们自己怎么用这个功能"——这个角度比客户案例更有说服力。具体:
- 每个核心功能写一篇"我们团队怎么用这个功能解决XX问题"——内部dogfooding日志整理
- 客户访谈选3-5个不同行业的深度用户,每个写一篇独立案例
- 给出具体的失败案例——什么样的客户用这个产品反而效果不好(这是E-E-A-T最强的诚实信号)
纯内容站的experience路径
没有产品也没有客户的纯内容站,experience来源是作者本人的深度+小圈层独家访谈。具体:
- 选3-5个垂直主题做"作者带宽内的深度"——写自己真的懂的东西,不写广而泛的
- 每篇深度长文采访2-3个圈内一线从业者,引用具体话(带attribution)
- 独家数据—自己跑实验、自己做调研、自己整理冷门数据集
怎么判断一段内容是facts还是experience:5个自检问题
给自己每段内容做5个判断,全部"是"才算真正的experience层:
- 这段里有具体的日期/地点/规模/数字吗——没有就是facts
- 这段里有"对XX用户意味着什么"的解释吗——没有就是facts
- 这段里有失败/缺陷/不适用场景的承认吗——没有大概率是facts
- 这段里有作者亲历的句式(实测/试过/调研过/客户告诉我)吗——没有就是facts
- 这段里有跨产品/跨场景的对比维度吗——没有就是facts
把站内月流量top 30页面拿出来按这5问跑一遍——每页5问能拿几个"是"。平均≥3个"是"的页面才算experience内容,平均≤1个的页面就是HCS降权高危。
5问自检的优化优先级
实操上不要一次改完所有"是少"的页面——按月流量×当前转化率排序,先改流量大且转化弱的页面(improve potential最大)。再改流量大且转化强的页面(保护现有产出)。流量小的页面排到最后或者直接删——HCS降权时低质量低流量页是先被处理的target。
AI Overview和AI Mode对experience内容的citation偏好差异
同样是Google的AI产品,AI Overview和AI Mode(2025年扩展的对话式AI搜索)对experience内容的citation规则不完全一样。理解这两套差异能让你的内容布局更精准。
| 对比维度 | AI Overview | AI Mode |
|---|---|---|
| 触发场景 | 传统SERP头部位置 | chat会话内多轮 |
| citation数量 | 1次回答3-5个源 | 整个会话累计10-30个源 |
| 偏好的内容类型 | 结构化清晰、表格/列表多的页面 | 叙述深度强、长context的页面 |
| 对experience信号的权重 | 高(且偏好对比型) | 极高(且偏好叙述型) |
| 对作者署名的依赖 | 中 | 高(多轮对话中"who said this"权重大) |
| citation的URL展示形式 | 页面URL+title | 页面URL+title+短摘要 |
针对AI Overview的内容布局
AI Overview在SERP头部位置展示,回答里3-5个citation。结构化清晰的页面(强H2/H3 + 表格 + 列表)被引用率更高。每篇内容里至少1个对比表格 + 3-5个明确H2节点能显著提升AI Overview引用机会。
针对AI Mode的内容布局
AI Mode是chat会话内的多轮检索。长context、强叙事的内容在AI Mode里citation率更高——因为AI Mode在多轮对话中需要从同一页面提取不同角度的信息。这意味着3000-5000字带具体故事+具体场景+具体数字的长文比800字的清单文更适合AI Mode。
双引擎兼顾的内容结构
既要被AI Overview引用又要被AI Mode引用的内容长这样:
- 开篇200-300字含具体场景的导入段——AI Mode抓叙事
- 每个H2下有1-2个表格或列表——AI Overview抓结构
- 每个H2下至少1段亲历叙述——两边都用
- 明确的作者署名 + Person schema——AI Mode看who
- FAQ段 + FAQPage JSON-LD——AI Overview直接抽答案
常见问题解答
Splitt说"AI是bridge"是什么意思
Splitt原话"AI is going to bridge that"是指AI能帮内容生产者把experience信息加工成更易读形态——比如帮你把30天测试笔记整理成清晰的对比表格、帮你把客户访谈转写成可发布的案例段。AI不是替代experience本身,是降低把experience转化为可读内容的成本。理解这点能让你正确使用AI工具:让AI做整理和润色,不让AI编造体验和数据。
没有实物产品的服务类站点怎么做experience内容
服务类站点的experience来自客户案例+服务过程的具体细节。例如咨询公司可以写"为某北美电商客户在2025-Q3做SEO诊断时发现的3个常见误区"——具体到时间、行业、问题类型、解决方法。别写"我们帮过很多客户"这种没有attribution的总结句。
用户generated content(UGC)算experience吗
算且权重高。Reddit、知乎、小红书这类UGC平台在AI Overview citation里占比逐月上升——因为内容天然带有"用户亲历"信号。在你自己站集成UGC的几个动作:评论区开放(不要关);产品页放真实用户评价(带评价时间和用户名);引用客户访谈片段(脱敏后)。
所有内容都要做experience吗工具页和定义页怎么办
不是所有内容都要experience。工具页(计算器/转换器)、定义页(什么是XX)、参考页(API文档)这类内容本来就是facts层、用户来找答案不是找观点。这类页面的优化重点是结构化清晰+加载速度快+可链接到深度experience内容,本身不需要硬塞experience。但站内要有相应的experience深度内容做内链支撑,否则整站会被算法识别为"只做facts没深度"。
experience内容怎么应对AI生成内容的污染
AI生成内容大规模污染SERP是真问题。应对方法:(1)在内容里加入AI难以模仿的特征——具体的客户名/产品型号/带时间戳的截图(在主题中渲染)/具体的失败描述;(2)作者的真实身份链路(LinkedIn、行业活动记录、过往发文);(3)Person schema结构化数据明确署名。这些信号AI生成内容可以伪造但很难大规模伪造,留下的指纹少。
experience内容会不会被竞争对手抄走失去差异化
表层数据能抄但深层判断和场景判断很难抄。竞争对手抄你的"测试数据"时通常做不到抄你的"对XX用户意味着什么"和"哪些场景不适用"——因为这些需要真的懂业务。更重要的是保持内容更新——每3-6个月把测试做一遍,新数据自然把抄袭者甩开。
新站没历史经验怎么开始做experience内容
新站可以从"作者的非站点经验"切入——你过去工作里的客户案例、过去项目里的失败教训、行业里你接触过的人和事。这些都是合法experience来源,写时给出attribution(时间、客户类型、行业)即可。新站不要装"我们站有10年数据",但作者本人的10年经验完全可以用。
experience内容的发布频率应该多高
没有固定数字。每月3-5篇深度experience内容对大部分内容站够用;DTC电商站每周1-2篇产品深度测试;SaaS站每月2-3篇功能深度+客户案例。质量远比频率重要——一篇真深度的experience文长尾流量价值是10篇浅facts文的总和。
权威参考资料
本文标题:《AI让事实型内容变廉价:四层价值塔与经验升级法》
本文链接:https://zhangwenbao.com/ai-makes-human-experience-content-value-pyramid.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0