电商SEO最重要的5点:从AI爬虫到accessibility 42步实战
本文目录
- robots.txt这一层比想象的复杂
- 具体robots.txt该怎么写
- 一个不在robots.txt里的特殊存在
- JavaScript渲染不再是优化是准入
- 具体怎么验证你站的SSR状态
- SPA迁移SSR的常见路径
- 结构化数据的AI加成不只是schema那么简单
- 哪些schema type权重最高
- "data-rich"vs"directory-style"的差距
- Princeton的那项研究值得记住
- accessibility tree是agentic browser看你站的方式
- accessibility tree审计要查什么
- 怎么实际测试
- WebAIM 2026报告里那个反常识数据
- 内容位置和可提取性这两个新维度
- Kevin Indig那个44.2%
- passage可提取性的实操
- 实操从哪一层开始改
- 这些都跟Google排名没直接关系——但你还是要做
- 常见问题解答
- llms.txt值得做吗
- 给AI爬虫提供raw markdown代替HTML可以吗
- Cloudflare的AI Audit dashboard能用吗
- SPA站迁SSR的预算和时间
- 已经被屏蔽的AI爬虫怎么解除
- schema验证有什么工具
- 站点内容怎么改才能放到top 30%
- accessibility audit应该多频繁做
- 权威参考资料
摘要:GPTBot、ClaudeBot、PerplexityBot、CCBot都不执行JS,ChatGPT Atlas读的是accessibility tree而不是HTML,研究还显示约44%的AI引用来自页面前30%。本文据此给五层技术SEO审计——robots、JS渲染从优化变准入、结构化数据的AI加成、accessibility tree、内容位置与可提取性,给从哪层开始改的优先级。
2026年Q1 Cloudflare的统计是这样:全网流量里30.6%来自bot,其中AI爬虫和agent占比持续涨。但你站的技术SEO审计还是2022年那套——查crawlability、indexability、CWV、移动友好、structured data,全部针对Googlebot设计。这套审计对GPTBot、ClaudeBot、PerplexityBot来说不够用。
保哥过去半年带客户做技术审计时反复遇到一个怪现象:站点Lighthouse满分、Googlebot抓取正常、结构化数据齐全,但在Perplexity和ChatGPT browsing里citation次数稳定为零。挖下去发现技术SEO要加一层"机器消费者"维度——AI爬虫看你站的方式跟Googlebot不一样,审计也得加新维度。
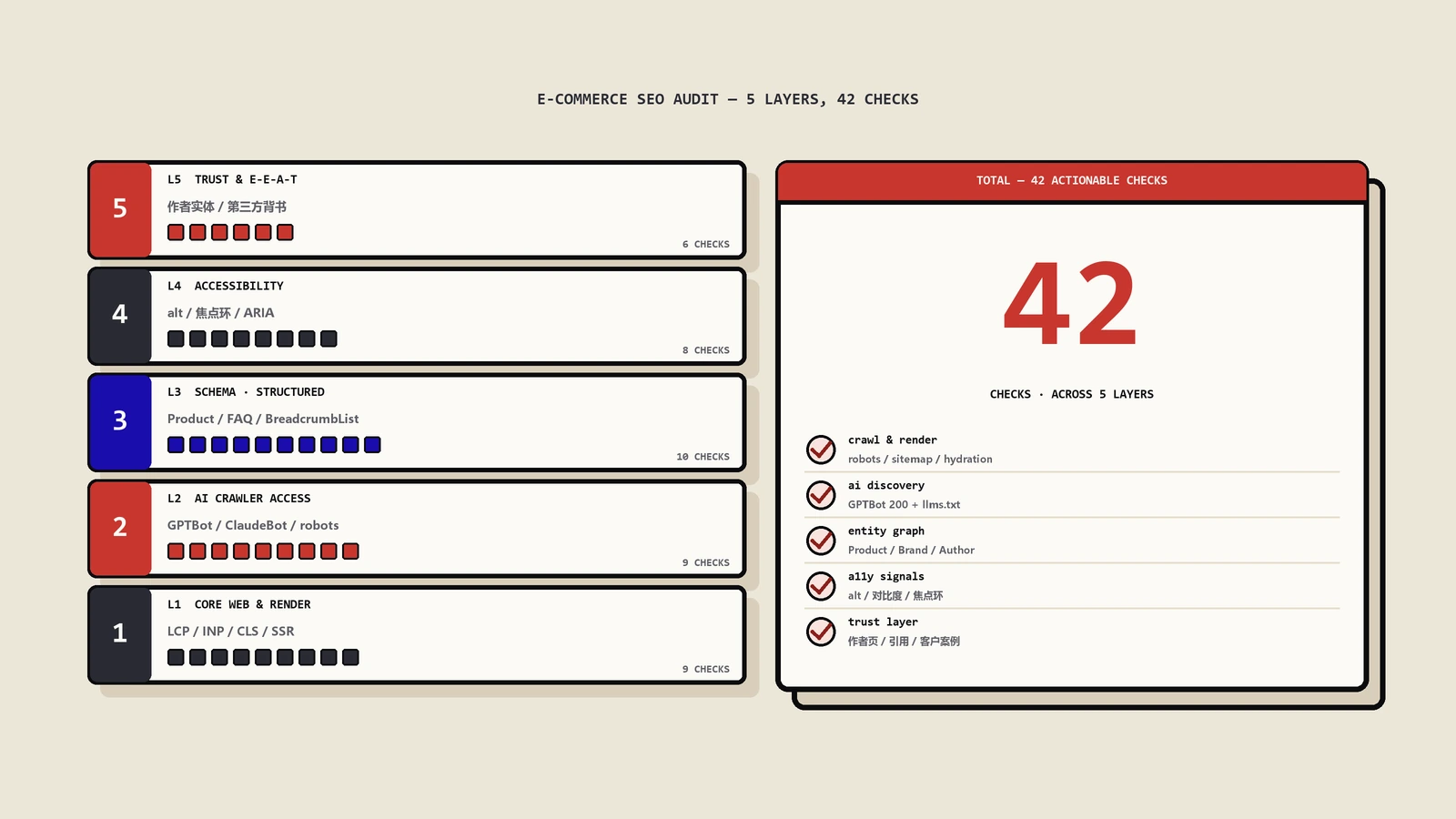
这篇把"AI时代技术SEO审计"拆成5层:AI爬虫准入、JS渲染、结构化数据的AI加成、semantic HTML与accessibility tree、AI可发现性信号。每一层给具体审什么、用什么工具、踩什么坑。最后聊一个反直觉的事实——这些层级的优化对Google传统排名几乎没直接影响。
robots.txt这一层比想象的复杂
2026年的robots.txt不再是"allow Googlebot disallow一切"那么简单。AI爬虫有自己的user agent,每个的行为规则不同,你得逐个决定怎么对待。
主要的AI爬虫user agent现在有这些:GPTBot(OpenAI训练)、ClaudeBot(Anthropic训练)、PerplexityBot(Perplexity检索)、Google-Extended(Google AI训练)、Bytespider(字节跳动)、AppleBot-Extended(Apple AI)、CCBot(Common Crawl)、ChatGPT-User(ChatGPT user-triggered browsing)。每个的"训练/检索/用户触发"角色不同。
Cloudflare的数据揭示了一个反差很大的事实——AI爬虫的流量89.4%是训练用,8%是搜索检索用,2.2%才是user-triggered agent。三类的"对你站的回报"差距也很大:
ClaudeBot爬20600个页面只给你1个referral回流——拿你内容训练但不导流量。OpenAI的比例略好——1300:1,仍然是悬殊的"拿走多还回来少"。Meta的爬虫零referral——纯粹拿数据。你要不要让训练型爬虫拿走你内容、换零回报?这是商业决策不是技术决策。
具体robots.txt该怎么写
有几个常见策略:
策略一:开放检索/限制训练。允许ChatGPT-User、PerplexityBot、Google-Extended等检索/搜索类爬虫;屏蔽GPTBot、CCBot、ClaudeBot、Bytespider等纯训练类。这套适合内容站——你想被AI搜索引用拿曝光,但不想白送给AI训练。具体写法:
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: PerplexityBot
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
策略二:全开放。所有AI爬虫都不屏蔽。这套适合需要brand曝光大于内容保护的站(早期DTC品牌、新内容站)。被训练拿走是间接的品牌曝光(即便不直接导流,AI回答里偶尔提到你站名是有价值的)。
策略三:全屏蔽。所有AI爬虫都拒。这套适合内容是付费墙后的、有版权敏感性的、或纯B2B不在意AI流量的站。但屏蔽后AI Overview/Perplexity完全看不到你——这是有代价的。
大部分站点应该在策略一附近——不是默认全开也不是全关,逐个评估。
一个不在robots.txt里的特殊存在
2026年3月20日Google上线了一个新的user agent叫Google-Agent——AI系统代表用户在Google基础设施上browsing时用的标识。这个agent完全忽略robots.txt。想屏蔽得靠服务器端auth(基于IP或某些行为特征)。这个细节大部分技术SEO还不知道。
Google公布了Google-Agent的IP范围(user-triggered-agents.json文件),你可以在服务器层做白名单或黑名单。但因为这是user-triggered类爬虫,本质上代表了"你的潜在访客"——屏蔽前要慎重。
JavaScript渲染不再是优化是准入
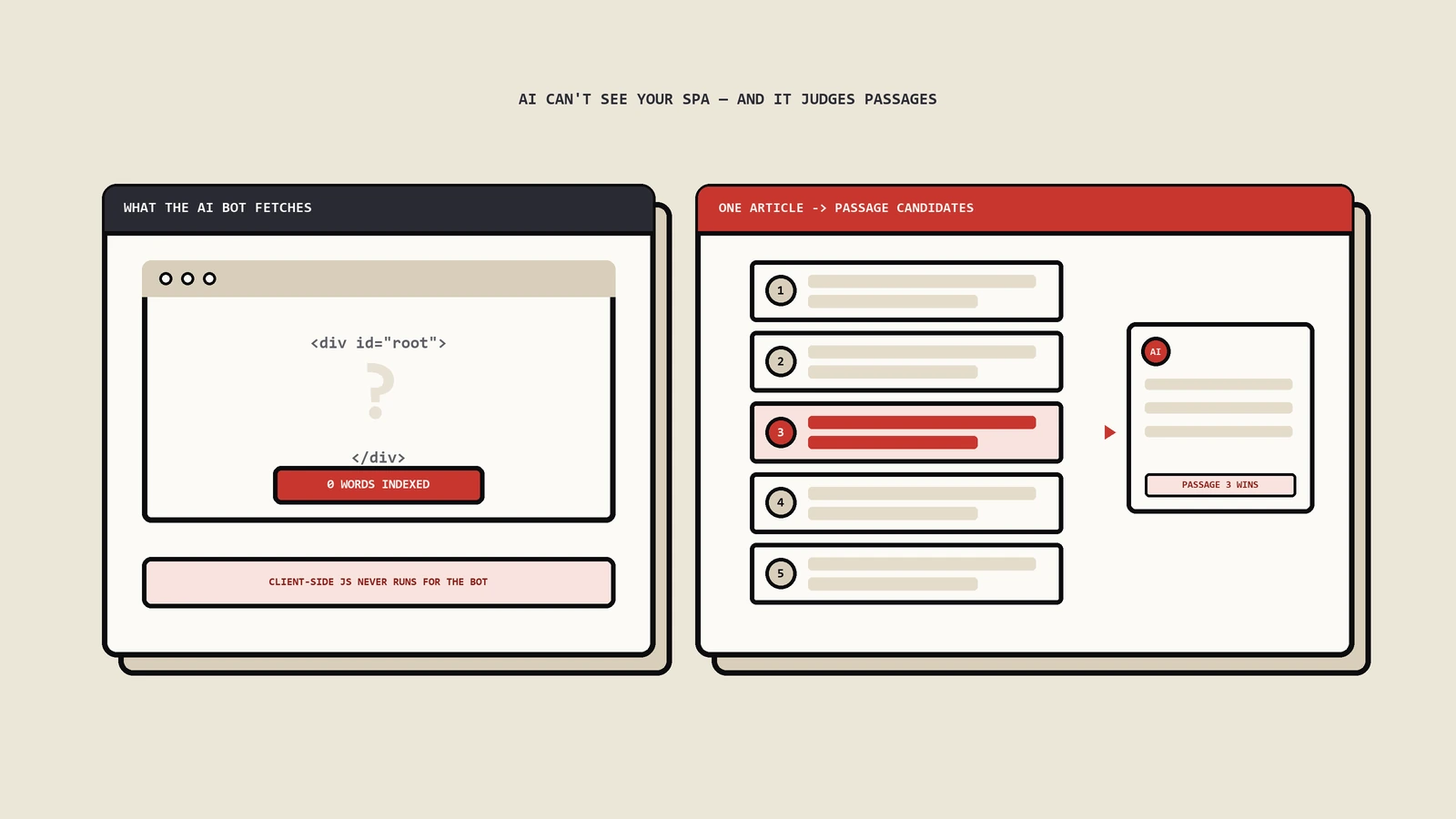
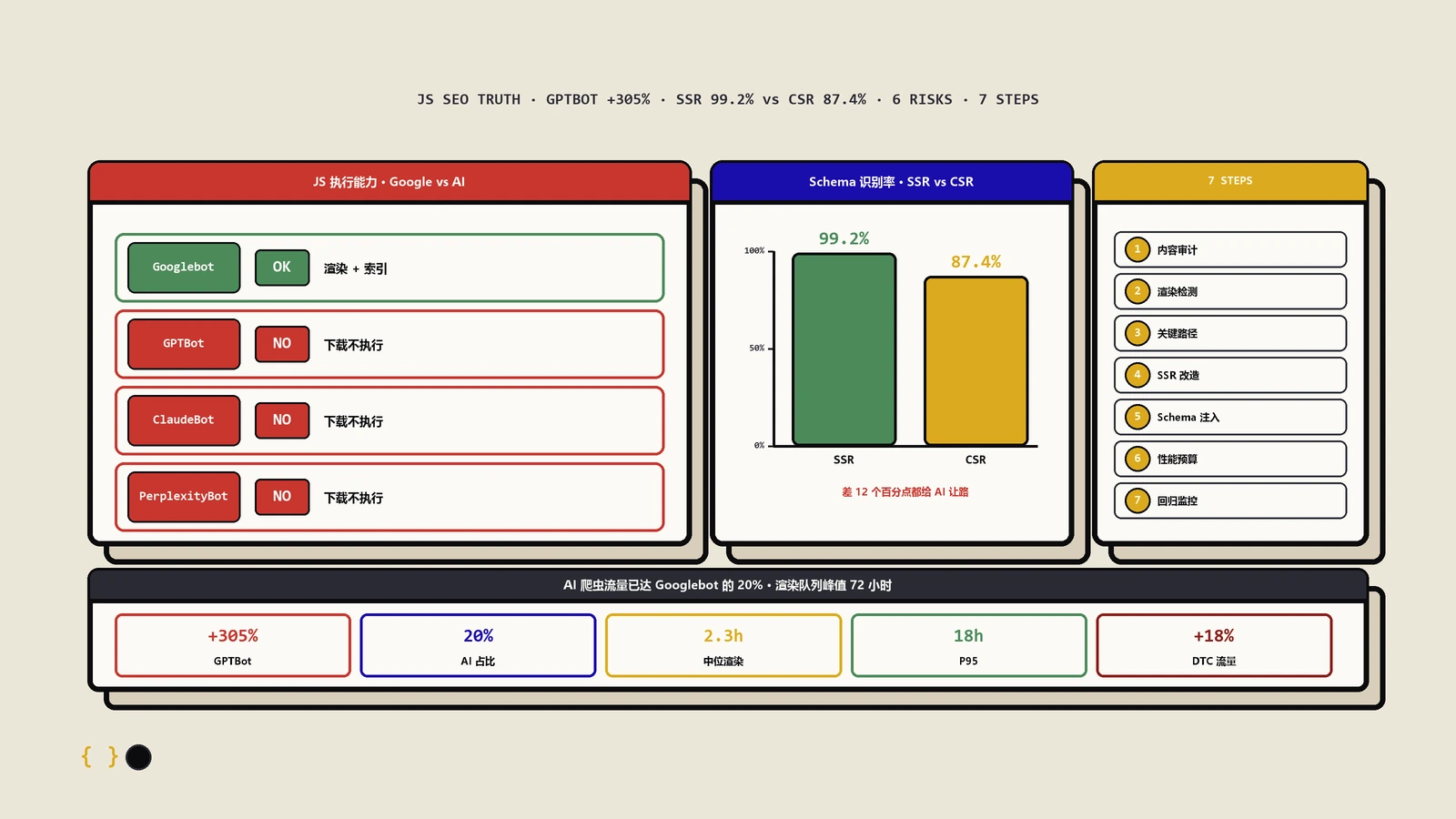
这个话题前面聊SPA那篇展开过——核心结论是4/6的主要AI爬虫不执行JavaScript:GPTBot、ClaudeBot、PerplexityBot、CCBot都只抓静态HTML。AppleBot和Googlebot执行JS。
对于CSR渲染的SPA站——首屏HTML空、内容靠JS填充——这4个爬虫看到的就是空白。这不是"性能优化"层面的问题,是"能不能被看到"的根本性问题。
"Four of the six major web crawlers (GPTBot, ClaudeBot, PerplexityBot, and CCBot) fetch static HTML only, making server-side rendering a requirement for AI search visibility, not an optimization." —— Cloudflare 2026-Q1 AI爬虫流量分析
具体怎么验证你站的SSR状态
最简单的方法是 curl -s [URL] 抓页面看返回HTML。如果返回的是一个空 <div id="app"> + 一坨JS引用,你就是CSR,AI爬虫看不到。如果返回的HTML里能找到你的核心内容(产品名、价格、文章正文),SSR是工作的。
第二个方法是Chrome DevTools里禁用JavaScript(Settings里有开关),然后访问页面看显示什么。能看到完整内容就OK,看到loading spinner或白屏就有问题。
第三个方法是用Lynx这种纯文本浏览器(命令行的)打开你站。这是最严格的"AI爬虫视角"模拟——AI爬虫看到的内容基本就是Lynx渲染出来的样子。
SPA迁移SSR的常见路径
React → Next.js(App Router或Pages Router)。Vue → Nuxt 3。Angular → Angular Universal。Svelte → SvelteKit。每个框架的官方文档都有迁移指南,渐进式迁移是可能的——不需要一次性重写所有页面。
最容易跳的坑:迁移过程中容易遗漏"客户端fetch的数据"——比如评论、产品评价、动态价格。这些数据如果迁移时仍然走客户端fetch,AI爬虫拿到的还是没有这些数据的HTML。SSR要把这些数据在服务端fetch完拼进首屏HTML,才算彻底迁移。
结构化数据的AI加成不只是schema那么简单
JSON-LD结构化数据2026年的权重高于前几年。Microsoft的Fabrice Canel在2025年3月明确说schema markup帮助LLM理解内容供Copilot使用。Google Search官方2025年4月也确认结构化数据在search results里给优势。
但schema的"AI友好度"远不止"有标签就行"。具体看几个细节。
哪些schema type权重最高
从被引用频率和citation影响看(基于行业benchmark观察):
Organization schema是基础——任何站都该有。完整的Organization包含name/url/logo/sameAs(社交媒体链接)/foundingDate/address/contactPoint等字段。sameAs这个字段被低估——把你的LinkedIn、Twitter、Crunchbase、Wikipedia条目都链接进来,AI系统能从多源验证你的身份。
Article schema是内容站必备。每篇文章带author、datePublished、dateModified、headline、image等字段。author字段最好是嵌套的Person schema,含sameAs指向作者的LinkedIn等。
Product schema是电商必备。具体到offers价格、availability、rating、review数量。Schema越完整、AI在选citation时越偏好你。
FAQPage虽然在2024年Google下线了Rich Results展示但schema本身依然被AI使用——AI Overview选citation时偏好结构化的Q&A内容。
HowTo schema对教程类内容很有用——AI Overview在用户问"how to X"类查询时频繁引用带HowTo schema的页面。
"data-rich"vs"directory-style"的差距
Yext的一个分析数据:data-rich网站(结构化数据完整 + 含具体数字/规格/参数)的AI citation次数是directory-style listing(只有列表/链接)的4.3倍。差距比想象大。
这个数据告诉你两件事:第一,schema投入回报是非线性的——做到位的站收益陡增;第二,光有JSON-LD不够,内容本身也要"数据丰富"(含具体规格、参数、统计、数字)。两者都做到才进入"data-rich"类。
Princeton的那项研究值得记住
Princeton、Georgia Tech、Allen Institute for AI、IIT Delhi四家联合在2024年ACM KDD会议上发布的GEO研究有个有意思的发现:"adding statistics to content improved AI visibility by 41%"。给内容加具体统计数据让AI可见性涨41%。
这是少有的同行评审过的GEO研究——大部分行业benchmark没经过学术验证。具体动作:把你内容里的"很多/大量/普遍"换成具体数字(37%/4.3倍/82%等)。每段补一个数据点。这个改动成本低但效果显著。
accessibility tree是agentic browser看你站的方式
这一层是2026年新冒出来的——agentic browser(ChatGPT Atlas / Chrome auto browse / Perplexity Comet等)不像Googlebot那样parse HTML,它们读accessibility tree。
accessibility tree是浏览器从HTML生成的一个"平行表示"——剥离视觉样式和布局,只保留语义结构:headings、links、buttons、form fields、以及它们之间的关系。这本来是给屏幕阅读器和辅助功能用的,现在被AI agent借来作为"页面理解"的入口。
Microsoft的Playwright MCP(连接AI模型到浏览器自动化的标准工具)用accessibility snapshot代替raw HTML或截图。OpenAI官方文档明确说"ChatGPT Atlas uses ARIA tags to interpret page structure when browsing websites"。
accessibility tree审计要查什么
H层级是否规范——H1/H2/H3按语义层次而不是按视觉大小用。一个常见错误是因为想让某段文字大就用H2,结果accessibility tree里这段被识别为"二级章节标题"——其实只是一段强调文字。
语义化元素是否用对——nav包导航、main包主内容、article包独立内容块、aside包补充信息、header/footer包页眉页脚。直接用 <div> 装一切的站在accessibility tree里是一团乱麻。
表单元素是否有label——每个input绑label、每个button有描述性文本。 <button onclick="...">X</button> 里"X"必须有意义不能只是图标。
交互元素是否用对tag—— <button> 用作可点击元素,不要用 <div onclick=>。前者在accessibility tree里是button、后者是div。AI agent看到div onclick的元素根本不知道这是可以点击的。
怎么实际测试
Playwright MCP直接生成accessibility snapshot——一个JSON结构展示AI agent看到的页面。这是最准的"AI agent视角"。
更简单的方法是用屏幕阅读器(macOS的VoiceOver、Windows的NVDA)走一遍页面——你听到的内容就是AI agent能"看到"的内容。如果某些核心功能用屏幕阅读器走不通,AI agent也走不通。
另外axe DevTools和Lighthouse的Accessibility检查能给你一份issue list。每条都修——这些issue大部分也是accessibility tree的可识别度问题。
WebAIM 2026报告里那个反常识数据
WebAIM Million 2026年报告显示平均每个网页有56.1个accessibility error,比2025涨了10.1%。更有意思的是:用了ARIA的页面平均有59.1个error,没用ARIA的页面平均只有42个error。
结论很反直觉——加了ARIA不一定让accessibility更好,反而经常更差。原因是ARIA用错了——比如 role="button" 加到 <div> 上但忘了加 tabindex 和键盘事件;或者 aria-label 和实际内容矛盾。ARIA是补充不是替代——能用原生HTML语义元素就用原生,ARIA只在原生不够时补。
一个反常识结论:accessibility tree优化对AI检索的影响可能比CWV优化更大,但大部分团队还在死磕LCP/INP/CLS,忽略accessibility。原因是accessibility的"可量化指标"少(不像LCP那样有具体毫秒数)。在AI agent时代谁先做对accessibility谁先吃到红利。
内容位置和可提取性这两个新维度
"44.2% of all AI citations come from the top 30% of a page. The bottom 10% earns only 2.4-4.4% of citations regardless of industry. The middle of long-form content is the most dangerous place to put your strongest claims." —— Kevin Indig, analysis of 98,000 ChatGPT citation rows across 1.2 million AI responses, 2025-Q4
这一层不是技术配置,是内容结构。但它影响AI citation的程度跟前4层一样大。
Kevin Indig那个44.2%
Kevin Indig分析了98000条ChatGPT citation(来自120万条AI回答)发现:44.2%的AI citation来自页面顶部30%的内容。页面底部10%只贡献2.4%-4.4%的citation。
这个pattern被Duane Forrester叫做"dog-bone thinking"——开头和结尾权重高、中间塌陷。Stanford研究者用了另一个名字"lost in the middle phenomenon"。无论叫什么名字,结论一样:把你最想被AI引用的核心内容放页面顶部30%,不要藏在第10段。
这对长文影响很大。一篇3000字的文章前900字(30%)承担44%的citation权重;后300字(10%)只承担3%。如果你把"具体的方法/数据/独家洞察"藏在文章中后部,等于把高价值内容放在低权重位置。
passage可提取性的实操
AI检索把页面切成多个passages后,每个passage独立参与召回。一个passage如果依赖pronouns("this/it/the above"),被独立抽出后就无法理解。每段内容要能"自包含读懂"。
具体动作:
每段开头给一个self-contained的主题句。"这点对DTC站尤其重要"——开头的"这点"会让被抽出的段失去上下文。改成"DTC站要尤其注意以下这点"——主题明确,上下文不依赖。
实体关系显式化。不要用代词指代——用名词。"它的影响是X"改成"Preferred Sources的影响是X"。AI抽出来后能直接理解。
关键论点用"quotable anchor statements"——一句话能完整表达观点的句子,方便AI直接引用。例如"用户query长度从2.4词涨到9.6词"是quotable anchor;"这个变化非常显著"不是。
实操从哪一层开始改
5层都做完投入不小。如果你站现在连Googlebot基础都没做好——先不要碰AI层,把传统SEO的Layer 0先搞定。如果传统SEO基础已经稳定,按下面顺序推:
第一步先做JS渲染。这是准入门槛——不解决后面4层都白搭。CSR站迁SSR/SSG,老的内容管理系统站升级到能动态生成完整HTML的版本。
第二步做robots.txt配置。决定你站对每个AI爬虫的态度。30分钟能改完,影响立竿见影。
第三步做结构化数据完善。Organization/Article/Product这几个核心type做齐,sameAs字段填全。这是一次性工作,做完几乎不用维护。
第四步做accessibility tree优化。这个工程量较大(要逐页修semantic HTML),可以按页面流量优先级渐进推。
第五步做内容位置和可提取性。这是持续工作,每篇新内容按这个原则写、老内容按流量优先级逐篇优化。
这些都跟Google排名没直接关系——但你还是要做
关于这个5层框架最有意思的事实——这5层的优化对Google传统排名几乎没直接影响:robots.txt里的AI爬虫规则不影响Google排名;accessibility tree优化不会让你关键词排名涨;内容位置评分跟搜索索引没关系。
那为什么要做?因为未来几年的可见性不再只靠Google关键词排名。被AI Overview引用、被Perplexity推荐、被Chrome auto browse打开、被ChatGPT Atlas理解——这些场景的"被发现"路径跟传统SERP完全不同。一个内容好但技术基础是2022年标准的站,AI时代会逐步被淘汰。
反过来——技术基础调好了但内容还是平庸的站也不会赢。技术基础是必要条件不是充分条件——content quality和E-E-A-T信号同样重要。但没有技术基础的话其他怎么做都没用。先把地基打好。
常见问题解答
llms.txt值得做吗
值得。llms.txt是一个markdown文件帮AI agent理解你站的目的、结构、关键内容。10分钟能写完一个,放站根目录。目前还没有大规模采用数据但成本极低,没有不做的理由。范例可以参考anthropic.com/llms.txt等已经实施的站。
给AI爬虫提供raw markdown代替HTML可以吗
不要。John Mueller在2026年2月明确说这是"a stupid idea"。他的理由:"Meaning lives in structure, hierarchy and context. Flatten it and you don't make it machine-friendly, you make it meaningless." 写得好的semantic HTML本身就是机器可读格式——把它扁平化成markdown反而损失了语义层级。
Cloudflare的AI Audit dashboard能用吗
能。如果你用Cloudflare托管DNS和WAF,AI Audit dashboard免费提供AI爬虫流量统计——按user agent分组、按时间趋势、按URL热点。没用Cloudflare的话可以从nginx/apache的access log里grep出来——脚本约30行。
SPA站迁SSR的预算和时间
看代码复杂度。简单的React/Vue站(200-500个组件,无大量第三方集成)迁Next.js/Nuxt 3通常2-4周一个高级前端能搞定。复杂的enterprise应用(含5000+组件、大量legacy代码、SSO/auth集成)可能要2-4个月。预算从小几万到几十万人民币不等。
已经被屏蔽的AI爬虫怎么解除
改robots.txt后等下次爬取——通常2-4周AI爬虫重新尝试抓取。如果是WAF/防火墙规则屏蔽的,先确认在Cloudflare/Sucuri等控制台移除规则。改完后可以主动去Perplexity的index请求工具或OpenAI的GPTBot页面submit URL让它优先抓取。
schema验证有什么工具
Google的Rich Results Test(测试是否被Google识别)+ Schema Markup Validator(测试schema.org合规性)。两个都免费、都好用。建议每次更新schema后跑一遍。复杂站可以集成到CI/CD里——每次部署前自动跑一遍schema检查。
站点内容怎么改才能放到top 30%
每篇文章前30%(约900字内)必须包含:(1)核心结论的明确陈述;(2)至少一个具体数据点;(3)至少一个差异化观点。把"我们要讲X"换成"X的真实情况是Y"——结论前置。把"案例后面会讲"改成"具体案例如下"——案例前置。导言段不要写"接下来你会学到"那种铺垫——直接给观点。
accessibility audit应该多频繁做
大改版前后做完整audit(每年1-2次);日常用axe DevTools的浏览器插件随时扫;CI/CD集成axe-core或Pa11y做每次部署自动检查。最重要的是新内容/新页面发布前必查——否则accessibility债务越积越多。
权威参考资料
本文标题:《电商SEO最重要的5点:从AI爬虫到accessibility 42步实战》
本文链接:https://zhangwenbao.com/technical-seo-audit-five-new-layers-ai-era.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0