Service Worker离线缓存怎么做?Cache API与PWA缓存策略实战
本文目录
- Service Worker到底是什么?和服务器端缓存差在哪?
- Service Worker的生命周期怎么走?register、install、activate讲清楚
- Cache API怎么用才能把离线缓存管明白?
- 几种缓存策略怎么选?Cache First还是Network First?
- App Shell和预缓存清单怎么设计?
- 缓存更新和版本控制怎么做才不会让用户卡在旧版本?
- Service Worker对SEO和抓取有什么影响?
- 实战里踩过哪些坑?
- 常见问题解答
- Service Worker和HTTP缓存(Cache-Control)有什么区别?该用哪个?
- 为什么我改了Service Worker代码,刷新后还是旧的?
- Service Worker会拖慢首次访问吗?对新用户有好处吗?
- 必须用Workbox这类库吗?手写Service Worker行不行?
- Service Worker能缓存API接口数据吗?会不会导致数据不更新?
- 权威参考资料
摘要:Service Worker是跑在浏览器里、独立于页面的一段脚本,它能拦下页面发出的每一个网络请求,决定是走网络、读缓存还是两者结合。它和Nginx页面缓存、Redis对象缓存、CDN那几层最大的不同,是缓存逻辑由你用JavaScript写死在客户端,连断网都能出页面。
保哥这篇把生命周期(注册、install、activate、fetch)、Cache API的几个核心方法、四五种常见缓存策略怎么选、版本更新怎么不把用户卡在旧页面,以及它对Googlebot抓取意味着什么,一次讲透。代码能抄走就用,坑也都标了出来。
先把一个误会说清楚:很多人一听“缓存”,脑子里只有服务器那几层——Nginx的fastcgi_cache把整页HTML存起来、Redis把数据库查询结果存起来、Cloudflare在边缘节点存一份。这些都对,但它们有个共同点:都发生在请求离开浏览器、到达服务器或CDN之后。
Service Worker不一样。它住在浏览器里,是页面和网络之间的一道可编程关卡。请求还没出门,它就先拦下来问一句:这个要不要走网络?要不要直接给缓存里的旧货?这意味着哪怕用户的网断了、信号烂到只剩一格,你的站点照样能把页面渲染出来。这一篇就专门讲它这一层,和服务器端那几层是泾渭分明的两件事。
Service Worker到底是什么?和服务器端缓存差在哪?
用一句话概括,Service Worker是一个注册到浏览器、在后台独立运行、能拦截网络请求的脚本。它不挂在某个页面的生命周期上——页面关了它还能活着(比如处理推送通知),页面没开它也能被唤醒。正因为脱离了页面主线程,它里面不能碰DOM,所有跨页通信都得靠消息传递。
它和服务器端缓存的分工,保哥喜欢用“四层各管一段”来理解。浏览器的 HTTP缓存头(Cache-Control、ETag)是最被动的一层,浏览器按响应头里的规则自动存、自动用,你只能配规则不能写逻辑。CDN(比如 Cloudflare的边缘缓存)在网络中间替你挡掉大量回源。服务器上的 Nginx fastcgi_cache把PHP生成的整页存成静态。这三层都不需要你写代码,配置好就生效。
Service Worker是唯一一层“可编程”的缓存。命中不命中、命中了走不走网络更新、断网了拿什么兜底,全是你用JavaScript一行行写出来的。HTTP缓存头你只能说“缓存一小时”,Service Worker你能说“先给缓存里的旧版本秒开,同时偷偷去后台拉新版本存起来下次用”。这种精细到每个请求的控制力,是它和前面几层的本质区别,也是它能做到真正离线可用的根本原因。
还有一个绕不开的硬门槛:Service Worker只能在HTTPS下注册(localhost例外,方便本地开发)。这不是建议,是浏览器的强制规定。理由也好理解——它有改写网络响应的能力,要是能在不安全的连接上被注入,那就是个现成的中间人攻击工具。
Service Worker的生命周期怎么走?register、install、activate讲清楚
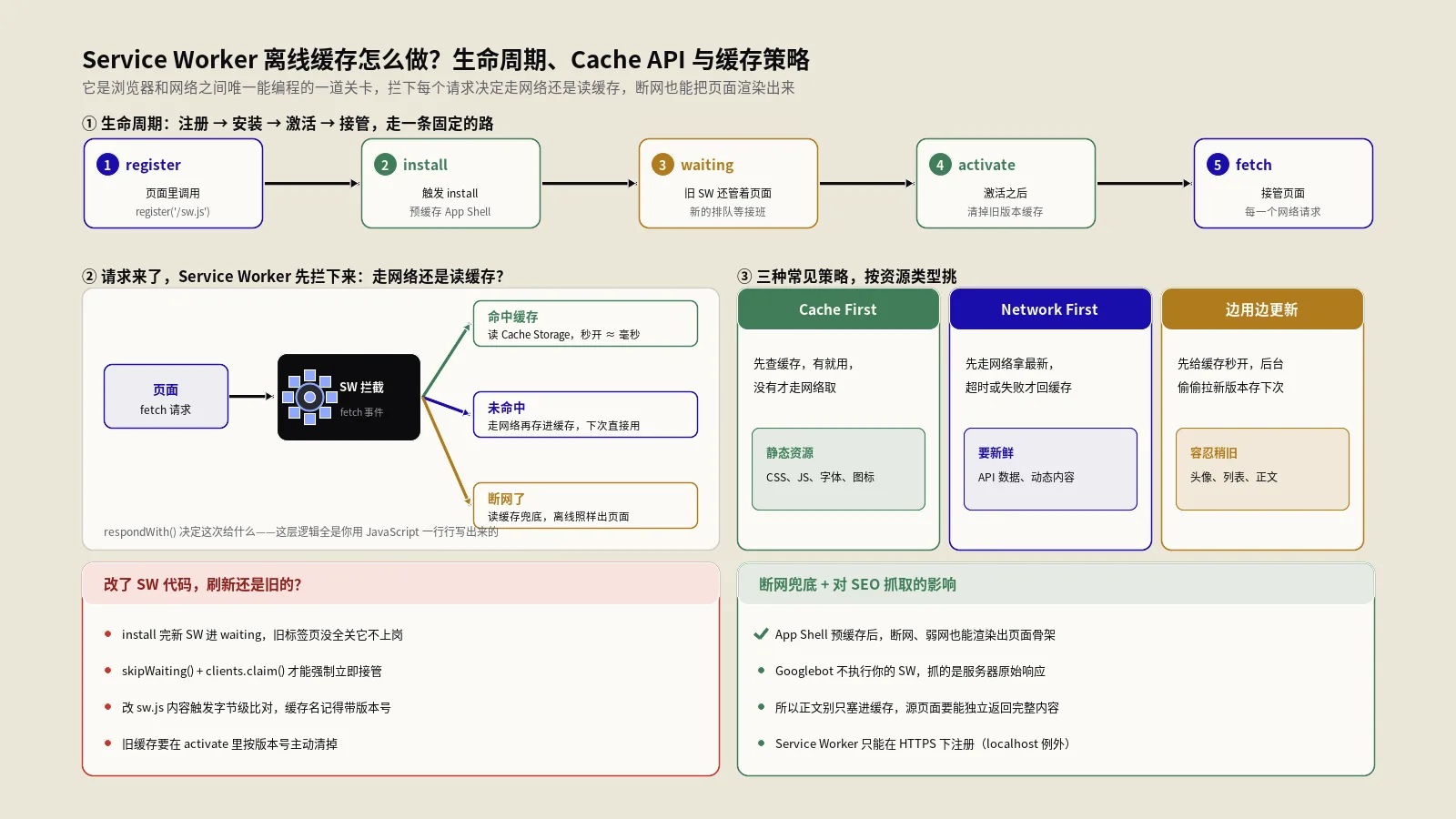
一个Service Worker从“被写出来”到“开始干活”,要走一条固定的路:注册 → 下载 → install → activate → 接管请求。这条路上每一步都有坑,搞懂了后面的缓存策略才有地方落脚。
第一步是在页面里注册。注意这段代码是写在普通页面脚本里的,不是写在Service Worker文件里:
// 写在页面的主脚本里
if ("serviceWorker" in navigator) {
window.addEventListener("load", () => {
navigator.serviceWorker.register("/sw.js", { scope: "/" })
.then((reg) => console.log("注册成功,作用域:", reg.scope))
.catch((err) => console.error("注册失败:", err));
});
}这里有个高频踩坑点——作用域(scope)。Service Worker只能控制它所在路径及以下的请求。你把 sw.js 放在 /js/sw.js,它默认就只能管 /js/ 下面的东西,根目录的页面它够不着。所以约定俗成把Service Worker文件放在网站根目录,让它能接管整站。想放深一点又要管根目录,得靠服务器响应头 Service-Worker-Allowed 放宽,多数人不知道这个,白白折腾半天。
注册成功后浏览器会下载这个脚本并触发 install 事件。这是预缓存的黄金时机——把页面骨架、关键CSS、JS、logo这些“无论如何都得有”的资源一次性塞进缓存:
const CACHE_NAME = "site-shell-v1";
const PRECACHE_URLS = [
"/",
"/offline.html",
"/css/app.css",
"/js/app.js",
"/img/logo.svg",
];
self.addEventListener("install", (event) => {
event.waitUntil(
caches.open(CACHE_NAME).then((cache) => cache.addAll(PRECACHE_URLS))
);
});event.waitUntil() 是个关键动作,它告诉浏览器“install还没完,等我这个Promise兑现了再说”。不写它,浏览器可能在缓存还没塞完就认为安装结束,预缓存就成了薛定谔的猫。
接着是 activate。这一步最重要的活儿是清理旧缓存。每次你改了缓存内容、把版本号从v1升到v2,旧的v1缓存就该被扫掉,不然用户的硬盘会被一代代旧缓存慢慢撑爆:
self.addEventListener("activate", (event) => {
event.waitUntil(
caches.keys().then((keys) =>
Promise.all(
keys.filter((k) => k !== CACHE_NAME).map((k) => caches.delete(k))
)
)
);
});这里要特别提醒一个生命周期的“延迟接管”特性:默认情况下,新的Service Worker装好后不会立刻接管已经打开的页面,它会进入“等待(waiting)”状态,要等所有用旧版本的标签页都关掉,新版本才上岗。这个设计是为了避免页面用着一半版本逻辑突然被换掉。但它也带来了那个经典抱怨——“我明明改了代码刷新了,怎么还是旧的”。这个问题怎么治,后面专门有一节讲。
Cache API怎么用才能把离线缓存管明白?
Service Worker自己不存东西,真正存缓存的是Cache API,全局对象叫 caches。它本质上是一个键值仓库,键是Request对象,值是Response对象。注意它和HTTP缓存是两套独立系统——Cache API完全不理会响应头里的Cache-Control,你存进去就一直在,什么时候删全凭你的代码说了算。这点MDN文档里写得很直白,也是新手最容易混淆的地方。
常用的方法就那么几个,记熟了基本够用:
caches.open(name):打开(不存在就新建)一个命名缓存,返回这个cache对象。cache.put(request, response):手动把一对请求-响应存进去,最灵活,适合在fetch里拿到响应后顺手缓存。cache.add(url)/cache.addAll([urls]):传URL进去,浏览器自己去抓取再存,预缓存清单最常用addAll。caches.match(request):跨所有命名缓存找匹配的响应,找不到返回undefined,这是取缓存的主力。cache.delete(request)和caches.keys():删条目、列出所有缓存名字,清理时用。
有个细节值得单独拎出来:Response对象是“一次性”的,它的body是个流,读一次就空了。所以你想既把响应返回给页面、又存一份进缓存,必须先用 response.clone() 克隆一份。忘了克隆,要么页面拿到空响应,要么缓存存进去个空壳,这是写fetch拦截时最常见的低级错误:
self.addEventListener("fetch", (event) => {
event.respondWith(
fetch(event.request).then((networkResponse) => {
const copy = networkResponse.clone(); // 先克隆
caches.open(CACHE_NAME).then((cache) => cache.put(event.request, copy));
return networkResponse; // 原件给页面
})
);
});还有个匹配上的细节值得知道:caches.match() 默认拿整个Request(含查询参数)当键去比对,所以 /list?page=1 和 /list?page=2 会被当成两条完全不同的缓存。要是你希望忽略查询参数、把它们当同一条处理,得传 { ignoreSearch: true } 选项。带时间戳、带随机参数的URL如果不管,很容易把缓存撑出一堆几乎一样的副本,白白占掉存储配额,这点在缓存第三方脚本、广告资源时尤其要留神。
几种缓存策略怎么选?Cache First还是Network First?
所谓缓存策略,说白了就是在fetch事件里,你决定“先问网络还是先问缓存、问不到怎么兜底”的那段逻辑。web.dev那本《Offline Cookbook》把常见套路总结得很全,落到实战里就这么几种,按资源类型对号入座即可。
Cache First(缓存优先):先查缓存,命中就直接返回,没命中才走网络并顺手存起来。适合那些“几乎不变”的资源——带哈希指纹的CSS/JS、字体、logo。它的好处是秒开且省流量,代价是更新得靠换文件名触发。
// Cache First
event.respondWith(
caches.match(event.request).then((cached) => {
return cached || fetch(event.request).then((res) => {
const copy = res.clone();
caches.open(CACHE_NAME).then((c) => c.put(event.request, copy));
return res;
});
})
);Network First(网络优先):先走网络,拿到新内容就用并更新缓存,网络挂了才退回缓存。适合对“新鲜度”敏感的内容——商品价格、库存、新闻列表。它保证联网时永远是最新的,断网时还有个旧版本兜底,不至于白屏。
Stale-While-Revalidate(先旧后新):这是体验最讨喜的一种。立刻把缓存里的旧版本返回去让页面秒开,同时在后台偷偷发请求拉新版本存起来,下次访问就是新的了。代价是用户这次看到的可能是上一版,适合那些“稍微旧一点也无所谓但要快”的内容,比如头像、非关键的配置数据。
// Stale-While-Revalidate
event.respondWith(
caches.open(CACHE_NAME).then((cache) =>
cache.match(event.request).then((cached) => {
const fetching = fetch(event.request).then((res) => {
cache.put(event.request, res.clone());
return res;
});
return cached || fetching; // 有旧的先给旧的,后台照样更新
})
)
);另外还有两种极端:Network Only(只走网络,适合不能缓存的接口,比如下单、支付回调)和 Cache Only(只读缓存,适合明确预缓存过、保证存在的资源)。真实项目里很少全站用一种策略,更常见的是按请求类型分流:HTML文档用Network First,静态资源用Cache First,API数据看情况用Stale-While-Revalidate或Network Only。
Network First还有个实战增强很值得加——超时兜底。纯Network First在网络极慢(不是断网,是龟速)时会傻等服务器响应,那种体验比直接断网还煎熬。老练的写法是给网络请求套一个两三秒的超时,一旦超时就主动退回缓存,让用户先看到旧内容也别干等转圈。这种“网络优先但限时”的变体,在移动端弱网、跨境高延迟的场景下特别管用,保哥给做跨境的客户配PWA时几乎都会默认加上,实测能把弱网下的“感知卡顿”砍掉一大截。
保哥之前帮一个做户外装备的独立站排查“断网就白屏”的问题,根子就是他们图省事全站套了Cache First,连商品库存接口都被缓存死了,用户看到的库存永远是第一次访问时的快照,下单老是超卖。改成按类型分流——页面壳Cache First、库存价格Network First——白屏没了,超卖也治住了。策略选错比不选还麻烦,这是真金白银的教训。
App Shell和预缓存清单怎么设计?
App Shell(应用外壳)是PWA里一个很实用的模型:把页面里“每一页都长一样”的部分——顶部导航、底部页脚、侧边栏、基础样式——抽出来当成一层稳定的骨架预缓存掉,内容区再按需从网络或缓存填进去。这样第二次访问时,外壳直接从缓存秒出,用户感觉“唰”地就开了,剩下的内容慢慢补。
设计预缓存清单有几条经验。第一,清单要克制,只放真正的关键路径资源,别把整站几百个文件全塞进去——install阶段 addAll 是“全有或全无”,里头任何一个URL抓取失败,整个install就失败,Service Worker装不上。第二,清单里的每个资源最好带版本指纹(文件名带哈希),这样配合Cache First既能长缓存又能在内容变了时自然失效。第三,准备一个 offline.html 兜底页,当用户彻底断网又访问了没缓存过的页面时,至少给个体面的“当前离线”提示,而不是浏览器那个难看的恐龙。
还要分清预缓存和运行时缓存这两个概念,混淆它们是后期缓存失控的根源。预缓存是install阶段一次性塞进去的固定清单,是离线兜底的地基,内容稳定、随版本号整体更新;运行时缓存是用户实际访问过程中、由fetch拦截按策略动态存下来的内容,比如用户翻过的某篇文章页、看过的某张图片。这两类最好用不同的缓存名分开管理——预缓存跟着版本号走,运行时缓存设个数量上限定期淘汰最老的,避免它随用户浏览无限膨胀吃掉配额。要是把两者混在一个缓存里,清理时极容易误删掉本该常驻的外壳资源,离线兜底跟着崩。
清单的版本管理直接绑在缓存名字上是最省事的做法——site-shell-v1、site-shell-v2。版本号一变,activate里的清理逻辑就会把旧缓存扫掉,新清单重新预缓存。手动维护清单容易漏,规模大了建议上Workbox这类工具自动生成预缓存清单(它会扫描构建产物、自动算指纹、自动注入清单),但原理还是这一套,工具只是把体力活自动化了。
缓存更新和版本控制怎么做才不会让用户卡在旧版本?
这是Service Worker的头号疑难杂症,也是保哥被问得最多的问题:明明发了新版本,部分用户怎么死活还是旧页面?根源就在前面提过的“延迟接管”——新Service Worker装好后默认在旁边等着,非要等所有旧标签页关掉才上岗。可现在的人谁还关标签页?几十个标签页挂着,旧Service Worker就一直赖着不走。
想让新版本尽快接管,有两个动作要成对使用。self.skipWaiting() 让新Service Worker跳过等待、装完立刻激活;clients.claim() 让它激活后立刻接管所有已打开的页面,而不是等下次导航:
self.addEventListener("install", (event) => {
self.skipWaiting(); // 别在旁边等了,直接上
});
self.addEventListener("activate", (event) => {
event.waitUntil(clients.claim()); // 立刻接管现有页面
});但这俩也不是无脑加就好。skipWaiting 会让页面在没刷新的情况下,前后两半请求由不同版本的Service Worker处理,万一新旧版本的缓存结构、接口契约对不上,可能出现样式错乱、接口报错。所以更稳妥的做法,是检测到有新版本就绪时弹个提示条——“有新版本,点此刷新”——让用户主动触发刷新,而不是偷偷换。要快还是要稳,看你的站点能不能接受瞬间的版本不一致。
另外一个常被忽略的点:浏览器对Service Worker文件本身(sw.js)也会做HTTP缓存。要是你的服务器给 sw.js 配了长缓存,浏览器可能拿着旧的Service Worker文件不更新,你改了半天它压根没下载新的。所以约定俗成给Service Worker文件单独配 Cache-Control: no-cache,让浏览器每次都去校验有没有更新。这个坑很隐蔽,排查“代码改了不生效”时一定要先看这里。
Service Worker对SEO和抓取有什么影响?
做技术的容易只盯着功能,但保哥做了二十多年SEO,必须提醒一句:Service Worker用得不对,是能伤到收录的。最核心的一条原则——首屏内容绝对不能依赖Service Worker才能出来。
原因是Googlebot抓取页面时,基本上是“全新访客”的身份,没有任何已注册的Service Worker,更不会等你的离线缓存生效。它要的是服务器直接吐出来的、首次请求就完整的HTML。如果你的页面把关键内容藏在“等Service Worker接管后再从缓存渲染”的逻辑里,爬虫第一次来看到的就是个空壳,收录自然出问题。
所以Service Worker是“锦上添花”的体验增强层,渲染兜底必须靠服务器端渲染(SSR)或静态生成(SSG)扛住。关于Service Worker和PWA对抓取索引的具体影响机制,保哥单独写过一篇拆解,想深挖的可以去看。
第二个角度是性能。Google早就把页面速度、Core Web Vitals当成排名信号,而Service Worker配合缓存策略,恰恰能显著拉低回头客的LCP(最大内容绘制)。这一点和服务器端的缓存优化是同向用力的——你想把 TTFB和整体加载速度压到底,多层缓存得协同工作,Service Worker是离用户最近、最后那一道。它管不了首次访问的TTFB(那是服务器的事),但回头客的体验它能托起来。
说到底,Service Worker在SEO这件事上的定位很清楚:它优化的是“已经认识你的人”再次访问的体验,对“第一次来的爬虫”几乎没有正面贡献,用错了反而帮倒忙。把这条边界守住,剩下的就是放开手脚优化体验了。
实战里踩过哪些坑?
把这些年趟过的雷集中列一下,照着避能省不少头发:
- 非HTTPS注册失败:本地用localhost没问题,一上测试环境用了IP或HTTP域名,注册直接静默失败,控制台还不一定有明显报错,先查协议。
- scope没覆盖到目标路径:Service Worker文件位置决定能管的范围,要管全站就放根目录,别放
/assets/里还纳闷为什么首页不受控。 - 缓存爆掉存储配额:浏览器给每个站点的存储是有上限的,无脑缓存大文件、视频,容易触发配额上限导致写入失败。该清的旧缓存一定在activate里清干净。
- HTML被长缓存死:和HTTP缓存一个道理,HTML文档别用Cache First长缓,否则用户永远停在某个旧版本。文档类走Network First或Stale-While-Revalidate。
- 第三方资源的不透明响应(opaque response):跨域且没开CORS的资源(比如某些第三方CDN的图片)缓存进去是opaque的,你读不到状态码,没法判断是不是真的成功,还特别占配额,缓存第三方资源要当心。
- 忘了用DevTools的Application面板调试:Chrome开发者工具的Application → Service Workers能看注册状态、强制更新、模拟离线,Cache Storage能直接看缓存了什么。不会用这个面板,调Service Worker等于盲人摸象。
- 开发时被自己的缓存骗:调试时勾上DevTools里的“Update on reload”和“Bypass for network”,否则你会被自己写的缓存逻辑反复戏弄,改了代码看不到效果。
Service Worker这东西,原理不复杂,但它运行在一个“脱离页面、有自己生命周期、还能拦网络”的特殊语境里,新手最容易栽在生命周期和缓存克隆这些机制细节上。把本文这几节的机制吃透,配合DevTools反复观察,基本就能驾驭它了。
常见问题解答
Service Worker和HTTP缓存(Cache-Control)有什么区别?该用哪个?
两者是独立的两套系统,不是二选一,而是配合用。HTTP缓存是浏览器按响应头自动管理的,你只能配规则、改不了逻辑,且对每个资源生效;Service Worker配合Cache API是你用JavaScript完全掌控的可编程层,能做到断网出页面、按策略精细分流。一般做法是:常规静态资源交给HTTP缓存头管就够了;需要离线可用、需要复杂缓存策略(比如先旧后新)、需要断网兜底时,才上Service Worker。web.dev有专门一篇讲两者如何协同,建议读一读。
为什么我改了Service Worker代码,刷新后还是旧的?
两个最常见原因。一是“延迟接管”机制——新版本装好后默认在waiting状态等所有旧标签页关闭才激活,你只刷新没关页面,旧的还赖着。可以用 skipWaiting() 加 clients.claim() 让它尽快接管,或在DevTools里手动点“skipWaiting”。二是 sw.js 文件本身被HTTP长缓存了,浏览器压根没下载到新文件,给它配 Cache-Control: no-cache 即可。
Service Worker会拖慢首次访问吗?对新用户有好处吗?
首次访问时Service Worker还在注册和预缓存,那一次基本享受不到加速,甚至预缓存还会占用一点带宽。它的价值几乎全在“回头客”身上——第二次起,缓存生效,加载速度和离线能力才显现。对搜索引擎爬虫这种“永远的首次访客”更是几乎没有正面作用,所以千万别让首屏内容依赖它渲染。
必须用Workbox这类库吗?手写Service Worker行不行?
完全可以手写,本文的代码就是原生写法,小站点手写反而更可控、包更小。Workbox的价值在于把预缓存清单生成、缓存策略封装、版本管理这些重复劳动自动化了,项目大、资源多、构建流程复杂时能省很多体力,但它底层用的还是本文讲的这套机制。建议先手写理解原理,再决定要不要上工具。
Service Worker能缓存API接口数据吗?会不会导致数据不更新?
能缓存,但要挑策略。读多写少、新鲜度要求不高的接口(比如分类列表、配置)适合Stale-While-Revalidate,秒出旧的同时后台更新。新鲜度敏感的(价格、库存、订单状态)要用Network First,联网时永远拿最新,断网才退缓存。绝对不能缓存的(下单、支付、登录态相关)直接用Network Only。把不该缓存的接口也缓存了,是导致“数据不更新”事故的最常见原因,按接口性质分流是关键。
权威参考资料
本文标题:《Service Worker离线缓存怎么做?Cache API与PWA缓存策略实战》
本文链接:https://zhangwenbao.com/service-worker-cache-api-offline-pwa-strategies.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0