哈希生成工具怎么用?从MD5、SHA-256到ETag缓存键与SRI完整性
本文目录
- 这个哈希生成工具,到底在帮你算什么?
- 哈希到底是什么?为什么它能当内容的"指纹"?
- MD5、SHA-1、SHA-256该怎么挑,哪些已经不能再碰了?
- 这工具怎么用最顺手?从单条文本到文件再到批量
- ETag和缓存键,怎么用哈希算出来?
- 想给CDN脚本加SRI完整性,这工具的哈希能直接用吗?
- 文件哈希校验,它是真读文件字节还是糊弄你?
- HMAC和香农熵这些附加功能,分别有什么用?
- 批量哈希和那些"自动编码",藏着哪些容易忽略的坑?
- 哈希在技术SEO和运维里,到底用在哪几个地方?
- 一个户外储能出海站,怎么用哈希守住固件包不被掉包?
- 校验和与密码学哈希,CRC32和SHA到底差在哪?
- 同样一段内容,为什么不同算法算出的哈希长度差那么多?
- 盐值是什么,为什么存密码光靠哈希远远不够?
- 拿哈希做内容去重和抄袭识别,具体怎么落地?
- 哈希用错的几个典型翻车场景,怎么提前避开?
- 做软件发布和内容分发,哈希校验该嵌在流程哪一环?
- 为什么有时哈希值旁边还跟着一个签名文件?
- 在线哈希工具和命令行工具,分别什么时候用?
- 哈希碰撞到底是什么,日常会不会真撞上?
- 把哈希思维装进脑子,对技术人意味着什么?
- 常见问题解答
- 权威参考资料
摘要:这个哈希生成工具,干的核心活就一件:把你给的任意一段文本或一个文件,算成一串固定长度的十六进制"指纹"。它支持MD5、SHA-1、SHA-256到SHA-512、SHA-3、CRC32等十七种算法,全部走后端PHP的hash()函数算,不是浏览器本地算,所以你的内容会经HTTPS传到服务器再算回来。除了基本哈希,它还能做HMAC签名、文件哈希校验、批量哈希、两段文本对比、Base64与十六进制编码、香农熵估算。它最实用的几个落点是给HTTP响应生成ETag、做缓存键、校验文件下载完整性、给内容做去重指纹。但有三件事得先记死:一是MD5和SHA-1早已不抗碰撞,别再拿去做签名或存密码;二是它输出的是十六进制,而网页SRI子资源完整性要的是Base64编码,二者不能直接套用;三是批量超过500行会被悄悄截断、大文件会把浏览器卡住。把它当"内容指纹速查台",它好用;指望它当生产级密码学库,会出事。
做技术活,哈希这东西躲不开。你下载一个安装包,官网旁边挂着一串SHA-256值让你核对;你配Nginx缓存,响应头里那个ETag是用内容算出来的;你给CDN上的脚本加防篡改,要填一串integrity值;你排查两份看似一样的文件到底差在哪,最快的办法就是各算一次哈希一比。这些场景背后,都是同一个动作——把一段内容压成一枚独一无二的指纹。
哈希生成工具干的就是这件事。你把文本粘进去、或者把文件拖进去,它当场吐给你一串定长的十六进制字符。这篇我们团队就把它怎么用、哈希到底是什么、那十几种算法该怎么挑、哪些已经不能再碰、以及它在做缓存和完整性校验时藏着哪些坑,一次讲透,顺带把哈希在技术SEO和运维里的真实用法捋清楚。
这个哈希生成工具,到底在帮你算什么?
先把它的家底盘清楚。打开工具,你能粘文本、能拖文件,选一种算法,它就给你算出对应的哈希值。它支持的算法不少,常见的有MD5、SHA-1、SHA-224、SHA-256、SHA-384、SHA-512,还有更新的SHA-3系列、RIPEMD、Whirlpool,以及校验用的CRC32和Adler32,加起来十七种。每个哈希值它还顺手给你大小写两种写法。
有一点要特别说清楚:它的全部计算走的是服务端PHP的hash()函数,不是浏览器里用JavaScript算的。这意味着你粘进去的文本、拖进去的文件,会通过HTTPS发到服务器,在那边算完再把结果传回来。好处是算法齐全、性能稳定;代价是如果你处理的是高度敏感的内容,它并非"绝不离开本机"的那种纯前端工具,这一点心里要有数。
除了基本的文本哈希,它还堆了好几样配套功能:HMAC带密钥签名、上传文件算哈希、一次算一批文本的批量模式、把两段文本各算哈希做对比、把输入顺带做Base64和十六进制编码、再加一个估算输入信息量的香农熵。这些功能在源码里都真实实现了,不是摆设。后面我们一个个看它们能干嘛、又各自藏着什么边界。
哈希到底是什么?为什么它能当内容的"指纹"?
要用好这工具,得先把哈希这个概念想明白。哈希函数干的事,是把任意长度的输入,压缩成一段固定长度的输出。你给它一个字,它吐一串定长字符;你给它一整本书,它还是吐同样长度的一串字符。这串输出就叫哈希值,也叫摘要、指纹、校验和,叫法不同说的是同一个东西。
它能当"指纹",靠的是三个关键性质。第一是确定性:同样的输入,永远算出同样的输出,今天算和明天算一模一样。第二是雪崩效应:输入哪怕只改一个标点,输出也会面目全非,看不出和原来有半点关系。第三是单向性:从内容能轻松算出哈希,但从哈希几乎不可能反推回原内容。这三条凑在一起,让哈希成了内容身份的绝佳凭证。
正因如此,校验文件有没有被篡改、判断两份内容是不是完全一致、给一长串内容生成一个短小的唯一标识,这些活交给哈希再合适不过。你在工具里把同一句话算两遍,结果分毫不差;改动其中一个字再算,整串值全变——亲手验一次,你对"指纹"这个比喻的体感会一下子扎实起来。这种"内容一变指纹就变"的特性,正是后面讲ETag和缓存键时的地基。
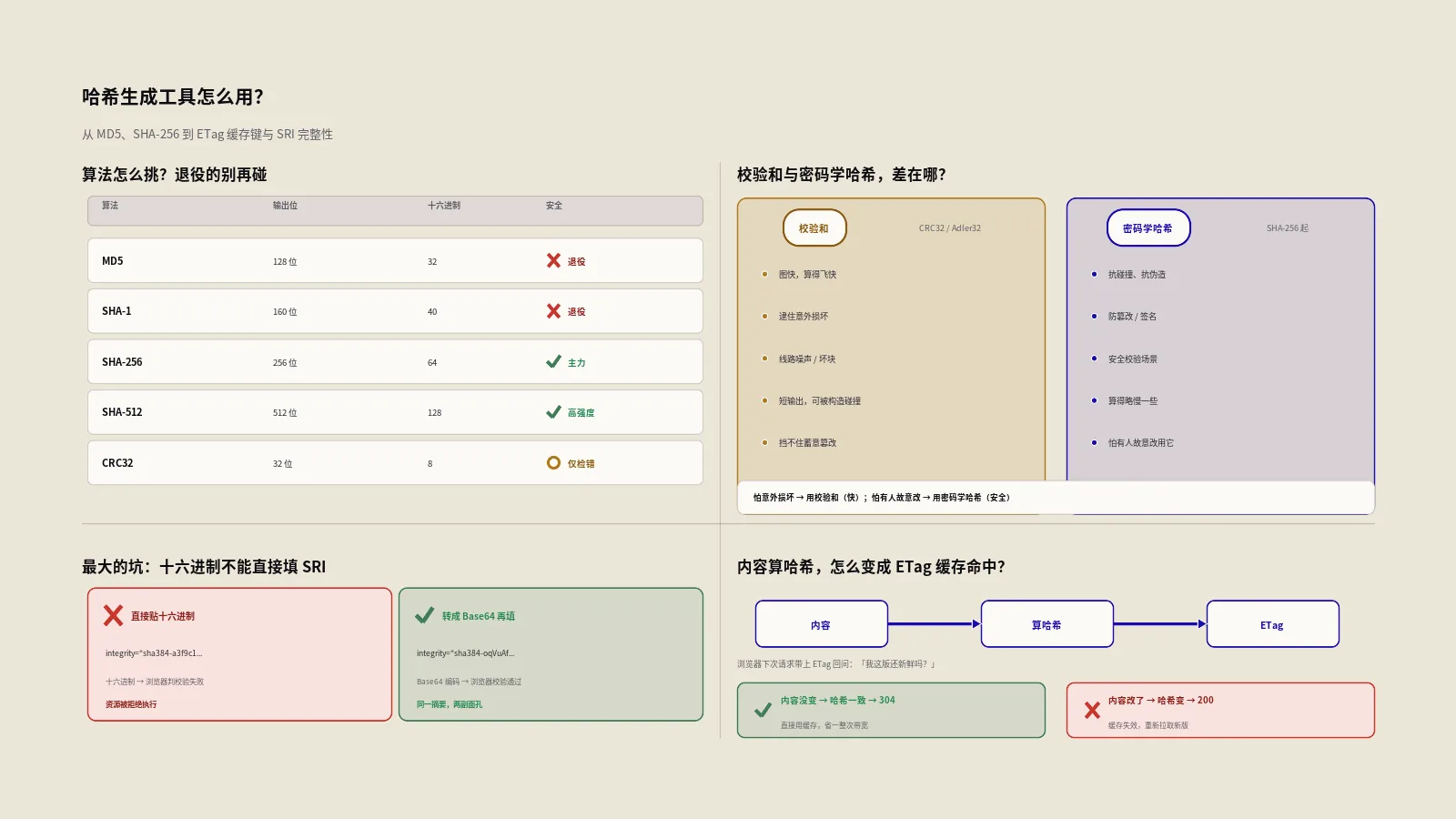
MD5、SHA-1、SHA-256该怎么挑,哪些已经不能再碰了?
这工具给了十七种算法,但你日常用得上的就那么几种,关键是搞清楚哪些还能用、哪些已经退役。这里面踩坑的人不少,值得单独讲清楚。
先说两个已经"出局"的:MD5和SHA-1。这俩当年是主力,但都已经被证明能被人为构造出碰撞——也就是能找到两份不同的内容,算出一模一样的哈希值。碰撞一旦可行,拿它们做数字签名、做防篡改校验就失去了意义,因为攻击者能伪造出哈希相同的假内容。这工具的算法说明里其实也给它们标了"已不安全"。权威依据可以看RFC 6151关于MD5安全性的更新说明,它明确写道,在需要抗碰撞的场景(如数字签名)里,MD5已经不再可接受。
那MD5是不是彻底没用了?也不是。在不涉及对抗、只图快的场景里它还能用,比如给本地大量文件做去重、给缓存生成一个非安全的键、做个粗略的完整性自查。但凡场景里有"防别人作恶"这层含义,就必须换到SHA-256及以上。SHA-256是目前的安全主力,抗碰撞强度足够、性能也不差,做内容指纹、做完整性校验、做令牌,选它基本不会错;要更高强度就上SHA-384或SHA-512。一句话原则:图快且无对抗,MD5勉强能用;只要沾安全,SHA-256起步。
这工具怎么用最顺手?从单条文本到文件再到批量
把这工具用顺,其实就是摸清它几个模式的入口和各自的脾气。实战里最常走的流程是下面这几步,照着来基本不会乱。
- 单条文本哈希,先选准算法再粘内容。这是最常用的模式。把要算的文本粘进输入框,在算法里选好
SHA-256或你需要的那种,它立刻算出十六进制结果,还同时给你大写和小写两份。核对官网给的校验值时,注意对方用的大小写,照着选那一份对比就行。 - 要算文件指纹,直接把文件拖进文件区。它会真正读取文件的二进制内容来算哈希,不是拿文件名糊弄你。这一步常用来核对下载的安装包、镜像有没有损坏或被掉包:把官网公布的
SHA-256和你本地算出的一比,一致就放心,不一致就别用。 - 有一批文本要批量算,用批量模式一行一条。把多行文本贴进去,它逐行算哈希,还会帮你检测重复行。注意它一次最多处理500行,超出的部分会被静默丢掉,这点后面会专门提醒。
- 要做带密钥的签名,切到HMAC模式。填上密钥和内容,选一种HMAC算法(如HMAC-SHA256),它算出带密钥的签名值。这个值常用在校验接口请求有没有被篡改、确认数据来源可信的场景。
- 想确认两段内容是否完全一致,用对比模式。把两段文本分别贴进来,它各算一次哈希再比对,相同就说明两段内容逐字节一致。这比人眼逐字对快多了,尤其文本很长时。
这几个模式背后都是同一个服务端的hash()在干活,区别只是喂给它的是一段文本、一个文件的字节,还是一批文本。摸清了入口,剩下的就是理解每种结果该怎么用——这正是下面几节要展开的。
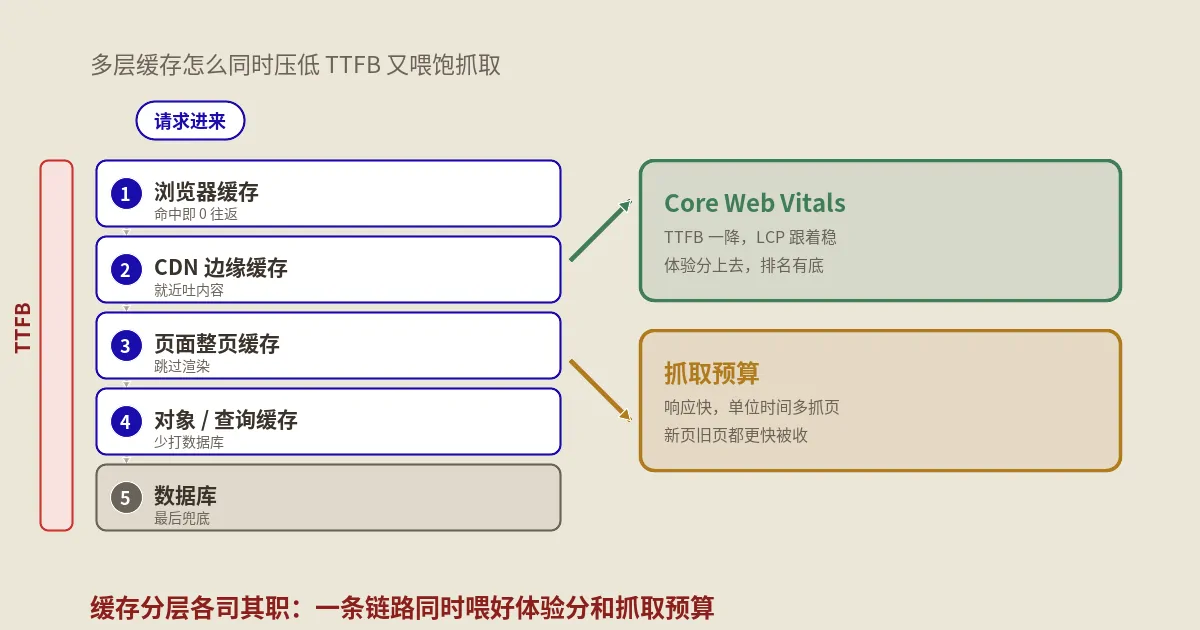
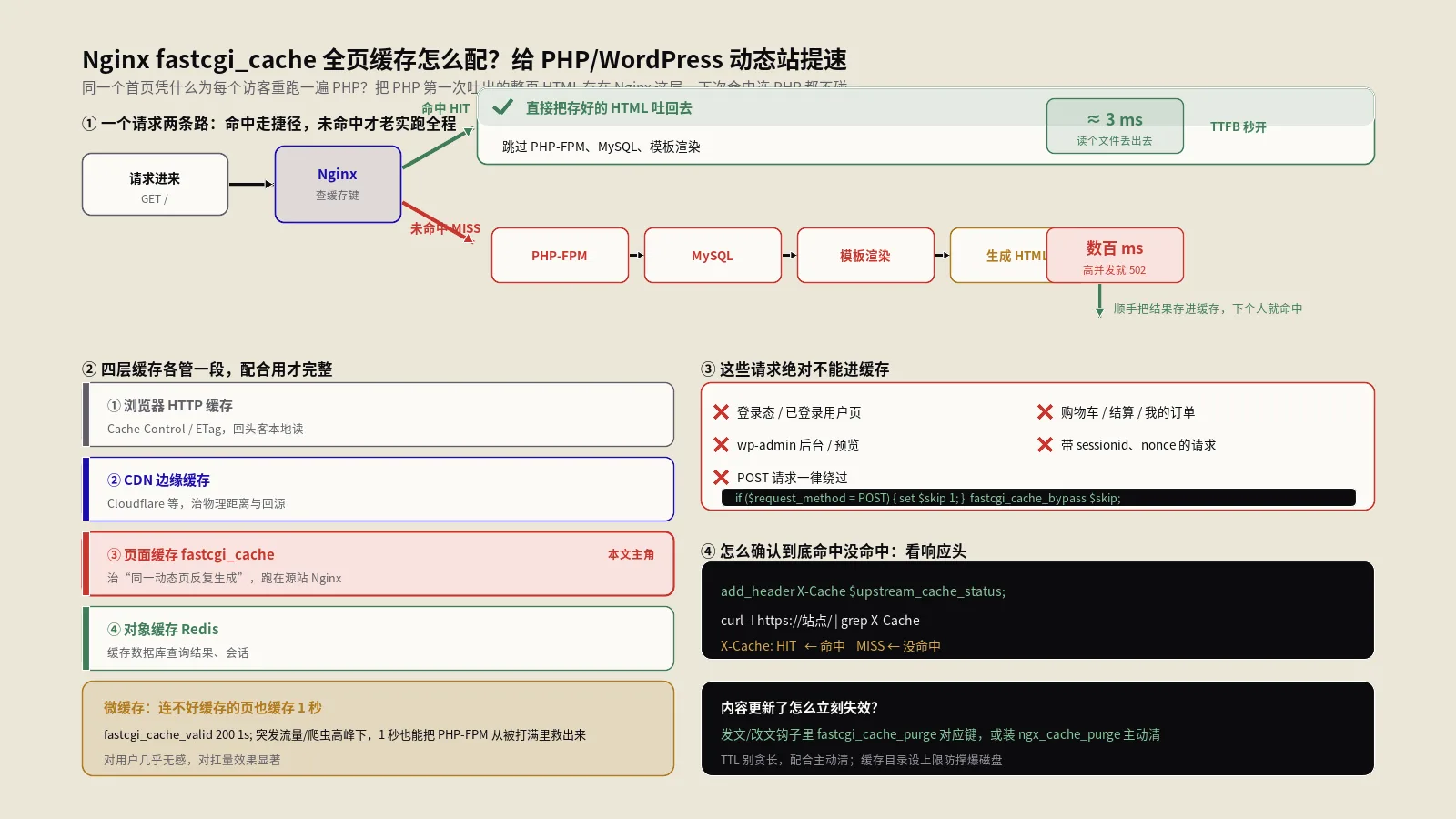
ETag和缓存键,怎么用哈希算出来?
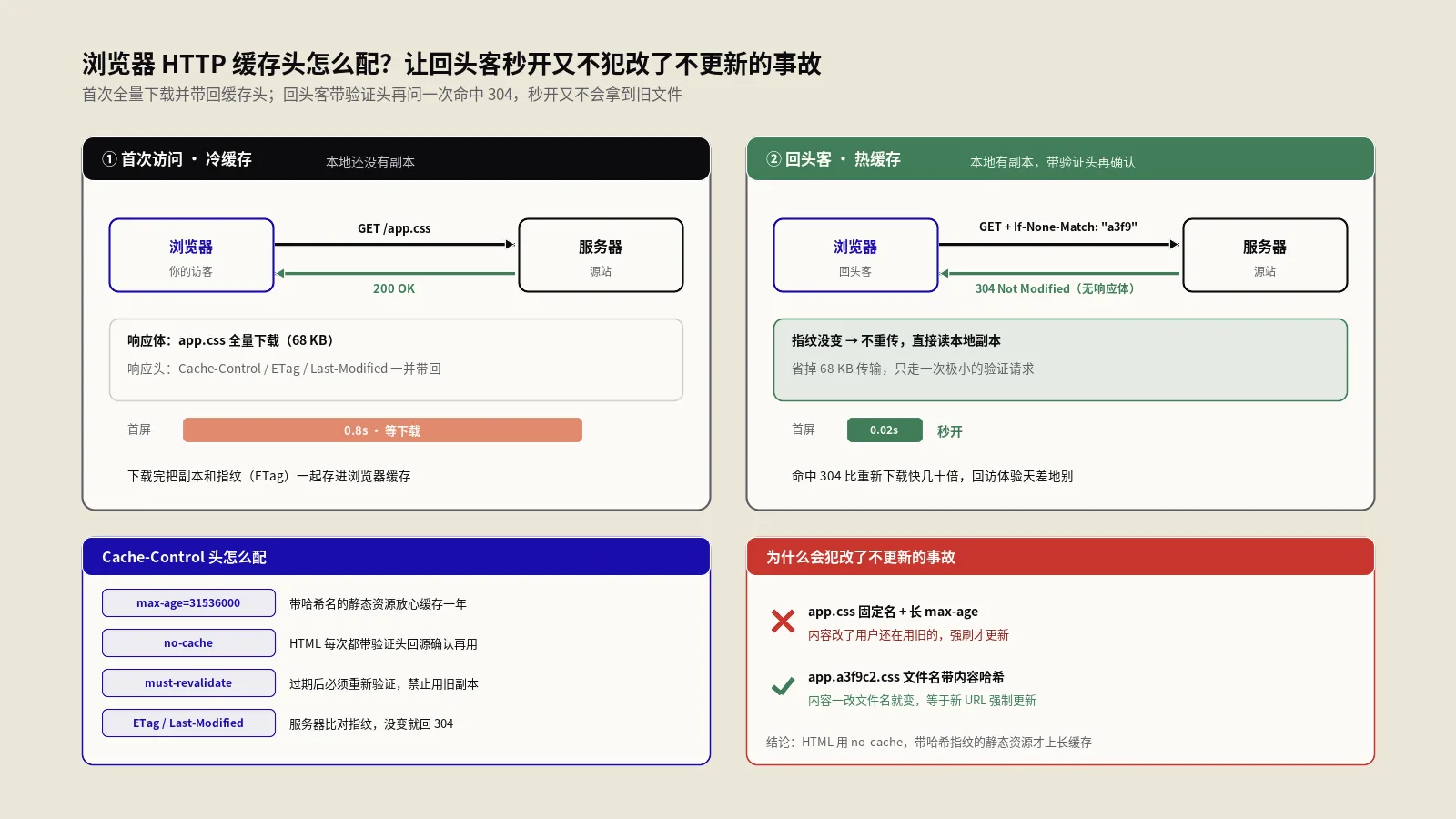
哈希在Web性能上最经典的用途,是生成ETag。ETag是HTTP响应头里的一个字段,作用是给某个资源的某个版本贴一个唯一标识。浏览器下次再请求这个资源时,会带上手里这个ETag问服务器:"我这版还新鲜吗?"如果内容没变,服务器回一个304,让浏览器直接用缓存,省下重新传一遍的带宽。
这个标识怎么生成最稳妥?拿内容算哈希。MDN的ETag响应头文档里就直说,ETag的值通常是内容的哈希、或最后修改时间的哈希、或一个版本号。用内容哈希的好处显而易见:内容一改,哈希就变,ETag跟着变,缓存自然失效;内容没动,哈希不变,缓存就稳稳命中。这工具算出的十六进制哈希,拿去填ETag是完全够用的——ETag对格式没有Base64那种硬要求,十六进制直接用即可。
同样的道理也适用于各种缓存键。你做页面缓存、做CDN缓存、做接口结果缓存,常常需要把一组参数或一段内容压成一个短小唯一的键。拿它们算个MD5或SHA-256当键,既短又不会撞,是非常常见的做法。想系统地理解ETag和缓存头怎么配合,可以读我们团队这篇HTTP浏览器缓存与ETag头详解,把缓存的整套机制串起来看会更清楚。
想给CDN脚本加SRI完整性,这工具的哈希能直接用吗?
这是整篇最该划重点的一处坑,因为它最容易让人想当然。当下很多站点把JS、CSS挂在公共CDN上,为了防CDN被入侵后偷偷替换文件,会给<script>和<link>加一个integrity属性,也就是SRI子资源完整性。浏览器加载资源时会自己算一遍哈希,和你填的值比对,不一致就拒绝执行。这是一道很硬的防篡改防线。
那能不能拿这工具算个SHA-384填进integrity?不能直接用。问题出在编码格式上。MDN的子资源完整性文档讲得很清楚:integrity的值是算法前缀加一个短横线、再接Base64编码的哈希值,形如sha384-后面跟一长串Base64。注意,是Base64编码,不是十六进制。而这工具输出的SHA-384是十六进制字符串,两种编码表示的虽然是同一段二进制摘要,但写法完全不同,直接把十六进制贴进integrity,浏览器会判定校验失败。
所以正确的姿势是:要么用命令行工具一步到位生成SRI格式(比如先算出二进制摘要再做Base64编码),要么把这工具算出的十六进制先转成二进制、再Base64编码一道。这工具本身没给"输出SRI格式哈希"这个选项,是它一个没明说的边界。关于十六进制和Base64到底是怎么把字节换装成文本的,可以看我们团队的Base64工具教程,理解了这层,你就明白为什么同一个摘要能有十六进制和Base64两副面孔。
文件哈希校验,它是真读文件字节还是糊弄你?
有些在线工具号称能算文件哈希,实际只是拿文件名算了个数,纯属糊弄。这工具不是这种,它确实读取文件的真实二进制内容来算哈希,这点在源码里能确认。所以拿它核对下载文件的完整性,是靠谱的。
具体怎么用?最典型的是核对安装包、系统镜像、固件包有没有损坏或被掉包。官网一般会在下载链接旁公布一个SHA-256值,你把文件拖进工具算一次,两个值一字不差就说明文件完整可信;只要差一个字符,就说明文件在传输中损坏了、或者更糟——被人动过手脚。这一步在分发重要文件、给客户传固件升级包这类场景里,是道不该省的保险。
不过它有两个限制要记牢。一是文件大小卡在50MB,超过就直接拒绝。二是它读文件的方式是先在浏览器里把文件转成Base64再上传,Base64会让体积膨胀约三分之一,加上服务端再算哈希,碰上接近上限的大文件,整个过程可能把浏览器卡得没反应。所以它适合校验中小文件,真要给几个GB的大镜像算哈希,还是用系统自带的命令行工具更稳,那是本地直接读字节、不经过浏览器和网络的算法,又快又不挑大小。
HMAC和香农熵这些附加功能,分别有什么用?
这工具除了纯哈希,还塞了HMAC和香农熵两个稍微进阶的功能,用对了挺有价值,但也各有讲究。
先说HMAC。普通哈希谁都能算,所以光有哈希没法证明"这串数据确实是某个知道密钥的人发的"。HMAC在哈希的基础上掺进一个只有收发双方知道的密钥,算出的签名值别人没密钥就伪造不出来。它的典型用武之地是校验接口请求:服务端和客户端约定一个密钥,请求方拿密钥对参数算HMAC一起发过去,接收方用同样的密钥重算一遍,对得上才认。
支付回调、Webhook通知这类怕被伪造的场景,几乎都靠HMAC把关。这工具能算HMAC-SHA256等几种,做调试、对接口签名很方便。要提醒的是,密钥的安全全靠你自己保管,工具不替你管密钥,调试完别把真实生产密钥留在公共工具里,免得密钥泄露让整套签名形同虚设。
再说香农熵。它估算的是一段内容里信息的"混乱程度",值越高说明内容越随机、越没规律。这东西能拿来做什么?判断一段字符串够不够随机很实用——比如你想看某个口令、某个token是不是足够杂乱不好猜,熵值能给个参考。一段全是重复字符的文本熵很低,一段真随机的字符串熵很高。它给的是个量化的"随机感"指标,帮你对内容的随机性有个数,而不只是凭感觉。
批量哈希和那些"自动编码",藏着哪些容易忽略的坑?
这工具有几个用着顺手但藏着边界的地方,提前知道能少踩坑。
第一个是批量模式的静默截断。它一次最多处理500行,你要是贴进去600行,它只算前500行,剩下100行被悄悄丢掉,不报错也不提示。界面上虽然标了"最多500行",但忙起来很容易没注意。所以批量算之前先数一下行数,超了就分批来,别让一部分数据无声无息地漏算了。
第二个是算法的环境依赖。它支持的十七种算法里,像SHA-3、Whirlpool这种较新或较冷门的,依赖服务器的PHP装了对应的哈希扩展。绝大多数现代环境都齐全,但万一某种算法在当前环境缺失,它的处理方式是直接跳过,而不会明确告诉你"这个算法这儿没有"。所以你选了某个冷门算法却没出结果时,先怀疑是不是环境不支持,换个主流算法(如SHA-256)验证一下。
第三个是它附带的Base64、十六进制、URL编码这些"自动展示"。这些是对你输入做的编码转换,方便你顺手拿到不同表示,但要分清楚:编码不是加密。Base64只是把字节换一种文本写法,谁都能解回去,它不提供任何保密性。别把"编码了一下"误当成"加密了",这是个常见的认知误区。想搞懂编码和加密、哈希到底是三回事,把这工具的哈希和编码功能各试一遍,对比着看最有体感。
哈希在技术SEO和运维里,到底用在哪几个地方?
把坑都说透了,回头看它的价值。哈希在SEO和运维的日常里,是个不起眼但用处极广的基本功,搞懂它能让你在好几类问题上更有底气。
最直接的是缓存与性能。前面讲的ETag、缓存键,都是靠哈希撑起来的。一个站点的缓存命中率高不高、改了内容缓存能不能及时更新,背后常常就是ETag生成策略对不对的问题。能用内容哈希生成稳定的ETag,是把缓存玩明白的基本功之一。
第二是内容指纹与去重。给每篇内容、每个资源算一个哈希当指纹,你就能快速判断两份内容是不是完全一样,这在排查重复内容、识别采集抄袭、做资源去重时很有用。第三是完整性校验,给客户分发文件、做部署发布时,用哈希确认文件没在传输中损坏或被替换,是一道该有的保险。第四,你日常遇到的Git提交ID、各种数字指纹、令牌,底子也都是哈希,看得懂它们是什么、为什么这么长,是技术SEO读懂底层世界的入场券。
一个户外储能出海站,怎么用哈希守住固件包不被掉包?
讲再多原理,不如顺一个真实场景来得实在。一个做户外储能电源的出海站,产品要靠固件升级不断优化,官网会提供固件包给用户下载刷机。固件这东西最怕的就是被掉包——一旦用户下到被人动过手脚的固件,轻则设备变砖,重则埋下安全隐患,砸的是品牌口碑。哈希正是守这道关的工具。
具体怎么做?发布固件时,团队先用SHA-256给固件包算一个哈希值,连同下载链接一起公布在官网。用户下载后,自己用哈希工具对文件算一次SHA-256,和官网公布的值核对,一致才放心刷机。这一步就把"文件在传输途中被损坏或被中间人替换"这个风险挡在了门外。运营在写下载页文案时,把"请核对SHA-256校验值"这句加上、附上具体值,既专业又让懂行的海外用户更信任。
更进一步,如果官网把固件挂在CDN上加速下载,团队还会给页面上的关键脚本加SRIintegrity,防CDN被入侵后替换脚本。这时候就用得上前面那条提醒了:SRI要的是Base64格式的哈希,不能直接拿十六进制填。整套下来,从固件文件本身的校验值、到页面资源的SRI,哈希在不同环节各司其职,把"用户下到的东西就是我们发的东西"这件事用密码学方式坐实。这种对完整性的较真,恰恰是出海品牌建立技术信任感的细节。
校验和与密码学哈希,CRC32和SHA到底差在哪?
这工具的算法列表里,除了MD5、SHA这些,还有CRC32和Adler32。很多人把它们和SHA混为一谈,其实它们是两类东西,用途完全不同,搞混了会用错地方。
CRC32和Adler32属于"校验和",它们的设计目标是检错,不是防篡改。它们算得飞快,能高效地发现数据在传输或存储中有没有因为线路噪声、磁盘坏块这类意外而损坏。网络协议、压缩文件格式里大量用它们做完整性自查,就是图它们快、且能逮住偶然的位翻转。但它们的输出很短、容易被人为构造出碰撞,所以挡不住蓄意的篡改——攻击者能轻松改了内容还让CRC32不变。
而SHA-256这类密码学哈希,设计目标里就包含了抗碰撞、抗人为伪造,所以它们才能用在防篡改、做签名、做安全校验的场景。代价是算得比校验和慢一些。一句话区分:怕"意外损坏"用校验和(快),怕"有人故意改"用密码学哈希(安全)。你校验一个下载文件有没有传坏,CRC32够了;你要确认文件没被中间人替换,必须上SHA-256。这工具把两类都给了你,但什么场景该用哪类,得你自己拎清楚。
同样一段内容,为什么不同算法算出的哈希长度差那么多?
你在工具里把同一句话分别用几种算法算一遍,会发现结果的长度差别很大:MD5是32个十六进制字符,SHA-1是40个,SHA-256是64个,SHA-512是128个。这个长度不是随便定的,背后是算法的"摘要位数"。
道理是这样:MD5输出128位二进制,每4位二进制对应一位十六进制,128除以4正好是32,所以MD5是32位十六进制;SHA-256输出256位,256除以4是64;SHA-512输出512位,就是128位十六进制。摘要的位数越多,可能的取值空间就越大,两份不同内容撞出相同哈希的概率就越低,抗碰撞强度也就越高。这就是为什么安全级别从SHA-256往SHA-512走,强度更高。
那是不是越长越好?也不尽然,得看场景权衡。摘要越长,存储和传输的成本越高、算起来也略慢。做安全签名、长期防篡改,选长的值;只是做个缓存键、做个非安全的去重标识,MD5那32位足够短又够用,没必要上SHA-512把键撑得老长。理解了"长度对应安全强度"这层,你选算法时就不会盲目,而是按"这个场景到底要多强"来挑。十六进制和二进制位数之间的这层换算关系,如果想理解得更透,可以看我们团队的十六进制编解码工具教程。
盐值是什么,为什么存密码光靠哈希远远不够?
前面提过存密码不能用MD5,但问题不止"MD5太快"这么简单,哪怕用SHA-256直接哈希密码也是不安全的。这里藏着一个很多人没想透的点——盐值。
设想一个网站把所有用户密码直接SHA-256存进数据库。问题来了:两个用户如果碰巧用了同一个密码,它们的哈希值是一模一样的,攻击者一眼就能看出来谁和谁密码相同。更糟的是,攻击者手里有现成的"彩虹表"——把海量常见密码预先算好哈希存成的大字典,数据库一旦泄露,他拿你的哈希去表里一查,常见密码瞬间就被反查出明文。直接哈希密码,等于没怎么设防。
盐值就是来破这个局的。给每个用户的密码额外拼一段随机的"盐"再去哈希,这样即便两人密码相同,因为盐不同,哈希也完全不同;攻击者的彩虹表也彻底失效,因为他没法为每一种盐都预先算一张表。再配合前面说的慢哈希(bcrypt、Argon2这类故意拖慢、又内置加盐的算法),让攻击者每试一个密码都要付出可观的算力,暴力破解就变得极不划算。所以存密码的正确姿势是"慢哈希加盐",而不是拿这工具的SHA-256直接算。这工具能帮你理解哈希是什么,但生产环境存密码,得交给专门的密码哈希算法。
拿哈希做内容去重和抄袭识别,具体怎么落地?
哈希在内容运营上有个很实用的落点——给内容做指纹来去重和查重,这对做SEO的人尤其有价值,值得展开说说怎么落地。
最基础的玩法是精确去重。给每一篇内容、每一段文本算一个SHA-256当指纹,存进一张索引表。下次再来一篇内容,先算指纹去表里查,撞上了就说明是逐字节完全相同的重复内容,可以直接拦掉。站内有大量自动生成或用户提交的内容时,这招能高效挡住完全重复的页面,避免它们稀释你的索引、拖累SEO。原理就是哈希那条"内容一致则指纹一致"的铁律。
但精确去重有个软肋:内容只要改一个标点,指纹就全变了,它认不出"只改了一个字的近似抄袭"。这正是哈希的雪崩效应带来的两面性——对防篡改是优点,对模糊查重是局限。要识别"洗稿"式的近似重复,得用更高级的相似度算法(比如SimHash这类局部敏感哈希,让相似内容的指纹也相近),那已经超出这工具的能力了。所以拿这工具的哈希做去重,定位要准:它擅长揪出"一模一样"的重复,揪不出"改头换面"的洗稿。把这个边界认清,你才知道它在内容查重链条里站在哪一环。
哈希用错的几个典型翻车场景,怎么提前避开?
用哈希多了,会发现翻车的就那么几类。提前知道,能省下大把排查和补救的功夫。
第一类是拿MD5存用户密码。这是经典错误。MD5快得很,但正因为快,攻击者能用现成的彩虹表或暴力撞库飞快地反查出原文,而且它不抗碰撞。存密码该用的是专门的慢哈希(如bcrypt、Argon2这类加盐又故意拖慢的算法),不是MD5这种通用快哈希。这工具能算MD5,但绝不意味着你该拿它的MD5去存密码。
第二类是把十六进制哈希直接当SRI用,前面已经反复讲过,编码格式不对,浏览器会判校验失败,记死SRI要Base64。第三类是误以为编码等于加密,拿Base64"加密"敏感数据,结果谁都能一键解开,等于没保护。第四类是用它算超大文件,浏览器卡死还以为工具坏了,其实是文件超了它的舒适区,大文件该用命令行。把这四类坑刻进肌肉记忆,你用哈希就稳得多。
做软件发布和内容分发,哈希校验该嵌在流程哪一环?
哈希校验不该是个临时想起来才做的动作,而该固化进发布流程里成为标准一环。理解了它在流程中的位置,你才能把"完整性"这件事做得系统而不是碰运气。
标准的做法是:每次发布一个文件——安装包、固件、压缩包、数据导出,在文件最终定稿、即将对外的那一刻,立刻给它算一个SHA-256哈希,把这个值和文件一起公布。注意时机很关键,哈希要在文件确定不再改动后算,且要和文件走不同的渠道或显眼地标注出来,这样用户拿到文件后能独立核对。很多开源项目的下载页旁边那一串校验值,就是这么来的。
到了用户或下游这端,流程是反过来的:拿到文件先别急着用,先算一遍哈希和官方公布的值比对,一致才进入下一步。在自动化的部署流水线里,这一步常被写成脚本自动执行——下载、校验哈希、校验不过就中止部署,把"传输损坏或被掉包的文件"挡在上线之前。把哈希校验嵌进发布和部署的固定环节,完整性就从"靠自觉"变成了"靠机制"。
这套机制对内容型站点同样适用。你给客户分发资料包、给合作方传数据文件,附上哈希值让对方核对,既显专业又能在出问题时快速定位是不是文件在传输中坏了。完整性校验花的力气很小,但它在关键时刻能帮你撇清"到底是不是我发的文件有问题"这类扯皮,是个性价比很高的习惯。
为什么有时哈希值旁边还跟着一个签名文件?
你下载一些重要软件时,会发现官网除了给哈希值,旁边还挂着一个签名文件(常见的是GPG签名)。既然有哈希了,为什么还要签名?这俩到底什么关系?搞懂这个,你对"完整性"和"真实性"的区别才算通透。
哈希解决的是"完整性"问题——文件有没有在传输中损坏或被改动。但它有个前提漏洞:如果攻击者既能替换文件、又能同时替换掉网页上公布的那个哈希值,那你拿被改过的文件去比被改过的哈希,照样"一致",你被骗了还浑然不觉。哈希自己证明不了"这个公布的哈希值本身是可信的"。
签名补的就是这个洞,它解决"真实性"问题——确认这东西确实出自你信任的那个发布者。发布者用自己的私钥对文件(或文件的哈希)签名,你用发布者公开的公钥去验签,验过了就说明这文件确实是他发的、且没被动过。攻击者没有发布者的私钥,伪造不出有效签名。所以"哈希加签名"是黄金搭档:哈希保证内容完整,签名保证来源可信,两者合起来才能既挡住意外损坏、又挡住蓄意冒充。这工具能帮你算哈希这一半,但签名那一半涉及私钥体系,得靠专门的签名工具,这也是它作为轻量工具的能力边界。
在线哈希工具和命令行工具,分别什么时候用?
这工具是个在线工具,用着方便,但它不是所有场景的最优解。搞清楚什么时候用它、什么时候该切到命令行,能让你既享受方便又不踩坑。
在线工具的优势是即开即用、零安装、界面直观,特别适合临时性的小任务:调试时算一小段文本的哈希、核对一个不大的文件、对接接口时手动验一下HMAC签名、教学演示时直观看哈希怎么随内容变。这些场景图的就是快和方便,在线工具最合适。这工具的多算法对比、批量、编码展示,也都是命令行不那么顺手而它很顺手的地方。
但有几类场景该用命令行。一是处理大文件——前面讲过在线工具受上传和浏览器内存限制,几个GB的镜像用系统自带的命令(如Linux的sha256sum、Windows的certutil)本地直接读字节,又快又稳。二是敏感内容——既然在线工具要把内容传到服务器,真正机密的数据就该在本机用命令行算,绝不出网络。三是自动化——要把哈希校验写进部署脚本、定时任务,那必须是命令行能跑的程序,而不是手点的网页。
所以理想的姿势是两者搭配:日常调试、学习、临时核对用这种在线工具,图省事;上生产、碰大文件、处理机密、做自动化,切命令行,图稳妥和安全。它们不是替代关系,是分工关系。把这工具当成"理解哈希、快速验证"的台子,把命令行当成"生产作业"的主力,各取所长。
哈希碰撞到底是什么,日常会不会真撞上?
前面反复提到"抗碰撞",那碰撞到底是什么、日常用哈希会不会真的撞上导致出错?这是个常被误解的点,值得说清,省得你要么过度担心、要么毫无戒备。
碰撞,就是两份不同的内容,算出了完全相同的哈希值。理论上一定存在碰撞,因为输入是无限的、而哈希输出是固定长度的有限种,无限往有限里塞,必然有挤到同一个格子的。但"存在"不等于"容易遇到"。对一个好的密码学哈希(如SHA-256),它的输出空间大到什么程度呢?是2的256次方那么多种,这是个超出日常想象的天文数字,靠随机去撞中两个相同的,概率小到可以当成不会发生。
所以日常正常使用SHA-256,你完全不用担心两份不同内容意外撞哈希——这种事在实践中几乎不可能自然发生。真正的问题不在"意外撞上",而在"被人为构造"。MD5和SHA-1的麻烦正在于此:攻击者已经能用数学方法主动构造出哈希相同的两份不同文件,这才是它们不能再用于防篡改的原因。换句话说,碰撞的风险不是来自运气,而是来自"算法弱到能被人为攻破"。
这就把前面的算法选型串起来了:你用SHA-256及以上,既不会意外撞、也挡得住人为构造,放心用;你用MD5、SHA-1,意外撞依然几乎不可能,但挡不住有心人主动构造碰撞来骗你,所以只能用在没有对抗的场景。理解了碰撞的真相,你对"为什么安全场景非要用强算法"就不只是死记,而是真懂了。
把哈希思维装进脑子,对技术人意味着什么?
聊到这里,值得把视角抬高一点。会不会用一个哈希工具本身不算什么,但脑子里有没有"内容可以被压成一枚唯一指纹"的意识,是区分技术熟手和半吊子的一道隐形门槛。
很多人面对ETag、SRI、文件校验值、Git提交ID这些东西,是当成一个个孤立的、需要死记的概念在记。而真正懂哈希的人,看到的是同一套底层逻辑在不同场景的不同表达——它们背后都是"拿内容算指纹"这一个动作。这种"看穿外衣看本质"的视角一旦建立,缓存、完整性校验、版本标识、防篡改这些看似不相干的话题,底层就通了。学一处,通一片。
而这工具的真正定位,是帮你建立这种体感的速查台。你不用它当生产级密码学库,也别指望它替你管密钥、做SRI格式转换,你用它的方式应该是:遇到一个哈希相关的问题,把内容敲进去、把文件拖进去,看它算出什么、改一个字结果怎么变,把抽象的密码学概念变成眼睛能看见的对应关系。
看得多了,ETag为什么这么设、SRI为什么要Base64、密码为什么不能用MD5存,你心里就有数了。把这门基本功在轻量工具里练扎实,再去啃更硬的安全和性能话题,会顺很多。要给后台、数据库配一套够强的访问凭据,可以接着看我们团队的密码生成工具教程,把"内容指纹"和"凭据安全"这两块拼成完整的一面。
最后留一句给那些觉得哈希"离自己很远"的人。哈希看着是个偏底层、偏安全圈的概念,似乎只有写代码、搞加密的人才用得上。可一旦你开始往技术的深处走——优化缓存命中、给资源加防篡改、排查重复内容、校验分发的文件,它就会一次次冒出来。
那些能在这些场合从容应对的人,不是天生懂密码学,往往只是早早把"内容可以被压成唯一指纹"这个朴素的念头想透了,于是面对一串SHA-256、一个ETag、一段integrity,看到的是同一套逻辑的不同应用,而不是一堆吓人的术语。这工具帮你算,但帮不了你建立这种洞察,那得靠你自己多敲、多看、多琢磨。
常见问题解答
这工具算哈希是在我电脑本地算的吗,内容会上传吗?不是纯本地。它的全部计算走服务端PHP的hash()函数,你粘的文本、拖的文件会经HTTPS传到服务器算完再传回结果。日常调试、校验公开文件没问题,但要算高度敏感的内容,就别用在线工具,改用本地命令行算,那才是真不出本机。
我能直接拿它算出的SHA-256填到网页的SRI integrity里吗?不能直接用。SRI的integrity要的是Base64编码的哈希,形如sha384-加一串Base64,而这工具输出的是十六进制。两者表示同一段摘要但写法不同,直接贴会校验失败。得把十六进制转成二进制再做Base64编码,或者用专门生成SRI格式的命令行工具。
存网站用户密码,能用它的MD5吗?绝对不能。MD5太快又不抗碰撞,攻击者能用彩虹表飞快反查。存密码要用bcrypt、Argon2这类专门加盐又故意拖慢的算法。这工具的MD5适合做非安全的去重、缓存键,绝不能用来存密码。
批量算哈希,行数多了会有问题吗?会。它一次最多处理500行,超出的部分被静默丢掉,不报错也不提示。界面上虽标了上限但容易忽略。批量前先数行数,超过500就分批处理,免得一部分数据无声无息地漏算。
算大文件的哈希为什么浏览器会卡死?因为它读文件是先在浏览器里转成Base64再上传,Base64让体积膨胀约三分之一,加上文件上限50MB,接近上限的大文件会把浏览器卡住。中小文件用它没问题,几个GB的大镜像建议用系统命令行工具,本地直接读字节又快又不挑大小。
本文标题:《哈希生成工具怎么用?从MD5、SHA-256到ETag缓存键与SRI完整性》
本文链接:https://zhangwenbao.com/hash-generator-md5-sha256-etag-sri-fingerprint-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0