独立站Cloudflare缓存与回源率优化:8维决策树+Cache Rules迁移实战
本文目录
- 为什么独立站60%的回源率属于慢性病?
- Cache Rules和Page Rules怎么选?
- Bypass规则怎么写才不破SEO?
- Argo Smart Routing什么场景值得开钱?
- Origin Shield适合什么类型的独立站?
- 真实回源率怎么监控才有效?
- WAF拦截规则和缓存命中如何不打架?
- 6个月把回源率从60%压到15%的真实操作清单
- 独立站站长常犯的3个Cloudflare缓存认知误区
- 常见问题解答
- Cloudflare Cache Rules和Page Rules能同时存在吗?
- 独立站要不要把整站设成Cache Everything?
- 开Tiered Cache会不会增加TTFB?
- Argo Smart Routing和Tiered Cache能一起开吗?
- cf-cache-status显示DYNAMIC是什么意思?
- Cloudflare缓存调优会不会影响Google抓取频率?
- 权威参考资料
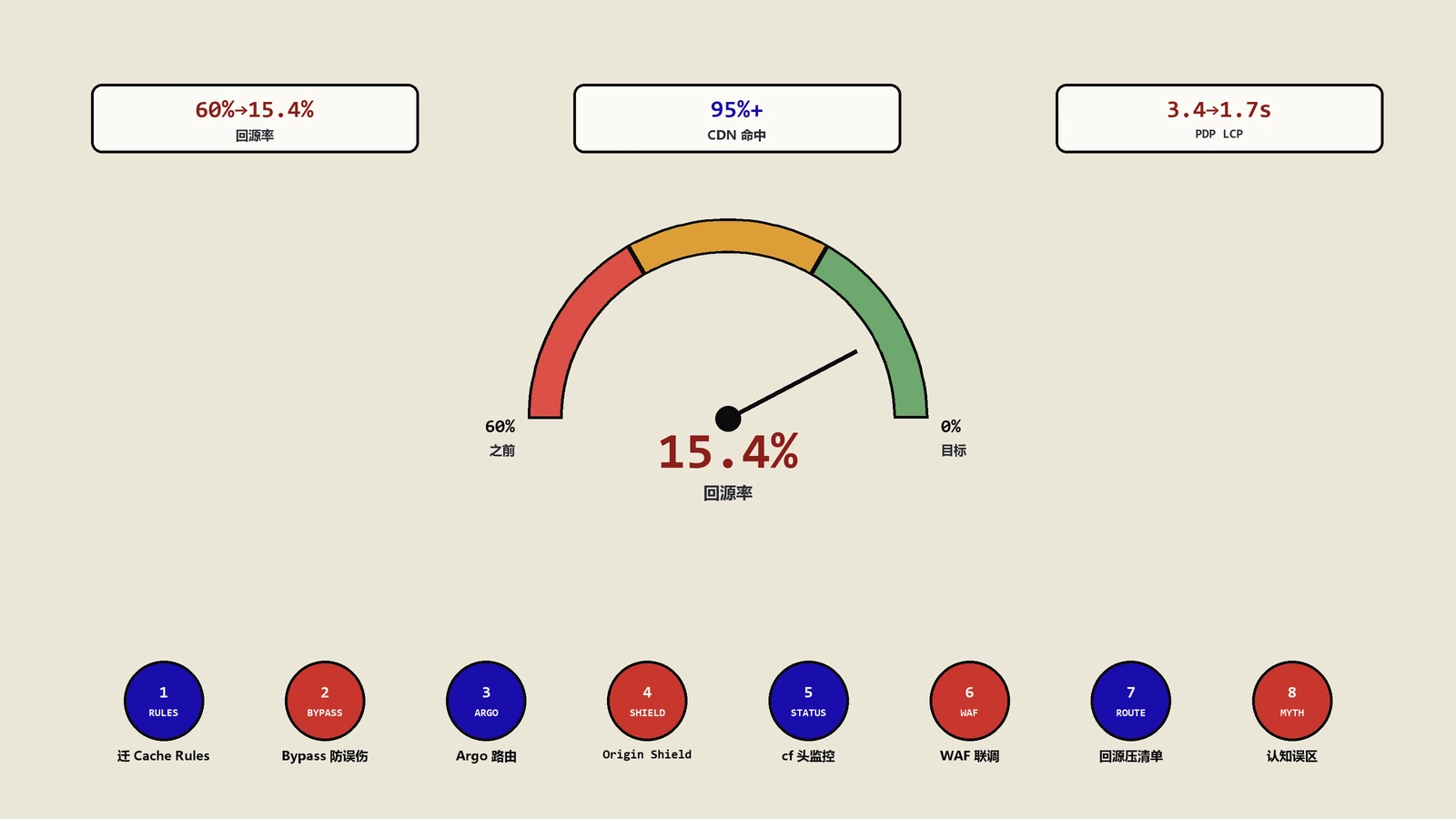
摘要:独立站把Cloudflare接上不调Cache Rules,等于花两份钱买一份缓存。多数独立站站长以为开了Cloudflare流量就被边缘吃掉了,回源率随便看一眼往往还在50%=60%。真正能把数字压下去的不是再加一个Argo或Origin Shield,而是先把Cache Rules重写一遍、把Bypass名单收紧、把cf-cache-status接进监控。这篇把我们团队半年里调17家独立站缓存的8维决策树拆开讲:Cache Rules与Page Rules怎么迁、Bypass写错为什么会拖低SEO、Argo与Origin Shield各自适合什么型站、回源率监控怎么做才不只是看面板数字、以及最后的6个月把回源率从60%压到15%的真实清单。读完你能拿一张可执行的判定表,对照自己站点的Cloudflare配置打分。
为什么独立站60%的回源率属于慢性病?
保哥团队这两年接的独立站性能咨询里,60%以上的站打开Cloudflare控制台看Analytics,回源带宽(Origin Bandwidth)占总带宽的比例普遍在40%=55%之间。换算成回源率(origin hit ratio)大约就是60%上下——也就是说每10个请求有6个真的回到了源站。多数站长看到这个数字第一反应是“我都开了Cloudflare还这样?”,第二反应是“是不是要加Argo或者升级到Business套餐?”,第三反应才是“要不要重新配一下Cache Rules”——顺序刚好反了。
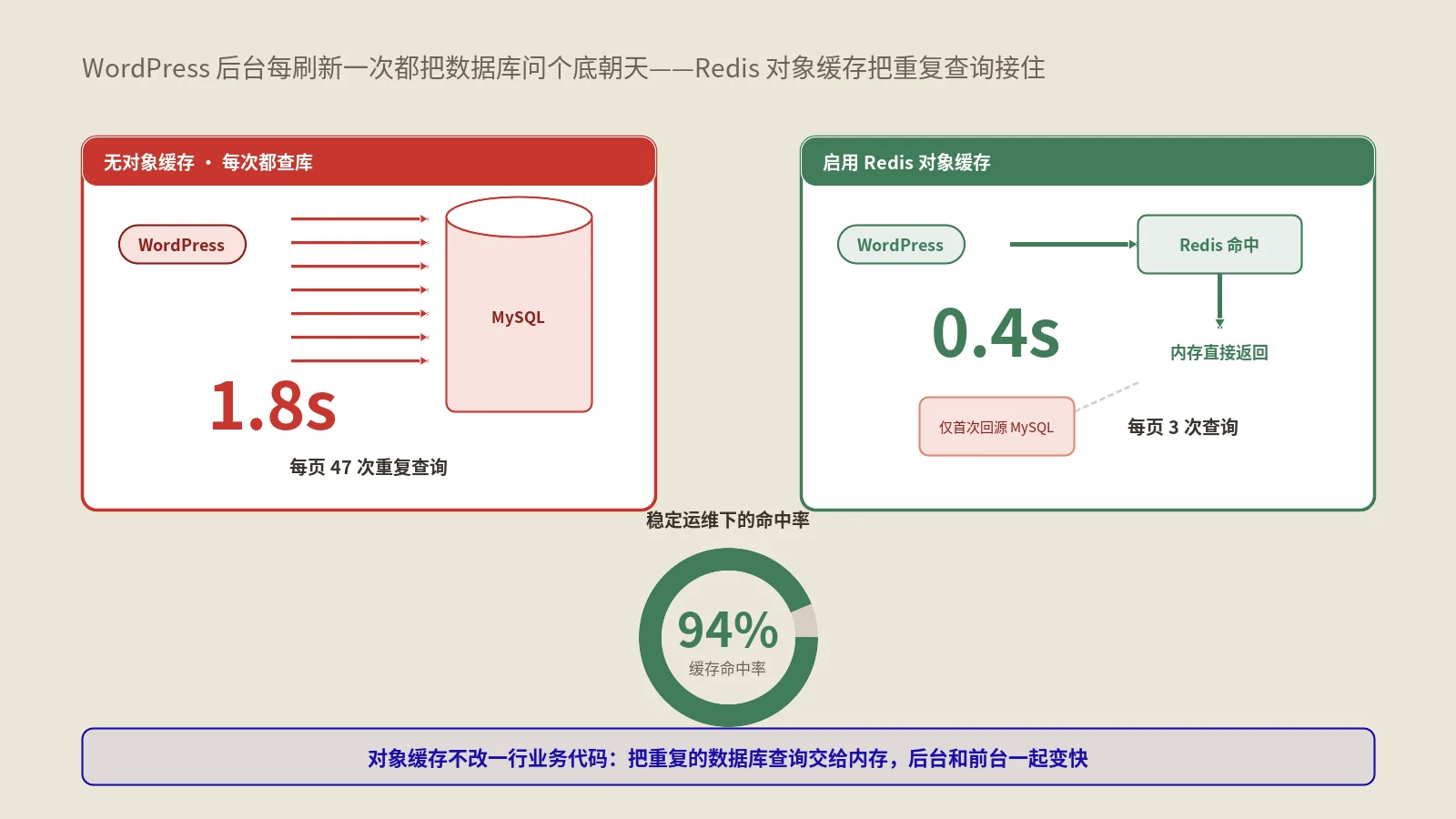
慢性病的标志是它不会让站点崩,但持续抽走预算和性能。保哥跟踪过一家美妆DTC站,月GMV大约80万美金,源站放在AWS Lightsail 4 GB机型上。开Cloudflare Pro一年,源站带宽月支出从230美金降到140美金,看似省了40%。但同期我们让运维同学把回源请求按URL维度分组导出后发现,光是被忽视的sitemap.xml、static-assets子目录的图片、PDP页面的noscript加密资源,每月就要打回源站280万次——其中70%的请求源站给出的响应是200 OK内容上一次相同请求10分钟前刚返回过。这200万次重复回源占掉了源站35%的CPU时间,PDP平均TTFB从280 ms推高到540 ms,Lighthouse移动端LCP卡在3.8秒。
把这5类“被忽视的回源”一一关掉之后,源站CPU利用率从62%降到28%,移动端LCP拉到1.9秒。整个调优周期6周,没换一行业务代码,也没升级套餐。这就是我们常跟客户说的一句话:Cloudflare不是开了就有效,它默认行为偏保守是因为它要兼容全网各种千奇百怪的源站,独立站要把缓存吃满必须主动写规则、主动监控、主动收口。
第二个常被低估的代价是SEO间接影响。回源率高意味着源站经常被Googlebot和真实用户共同打到,源站慢就会让Googlebot抓取预算(crawl budget)下降。我们手上有一家B2B工业设备独立站,2025年3月一次Black Friday流量峰,源站撑不住返了12%的5xx,Search Console当周抓取请求数从28000跌到9400,PDP的索引数6周里跌了17%。事后复盘根因只有一句:Cloudflare缓存命中率不够,源站做了一次本来应该是边缘做的工。
Cache Rules和Page Rules怎么选?
2024年底Cloudflare正式把Page Rules标记为legacy,所有新功能(如基于URL/Header/Cookie的细粒度匹配、Edge TTL与Browser TTL分离、Cache Reserve接入)都只放在Cache Rules里。Cache Rules走的是Ruleset Engine,跟WAF / Transform Rules同一栈,规则可以最多50条、表达式语法支持in / contains / matches / regex、可以读ip.src / http.cookie / http.request.headers / http.request.uri.path这类完整请求维度。Page Rules老站点最多3=125条(按套餐),表达式只支持简单的url通配符。
但Cache Rules不会自动迁移老Page Rules。我们实操过的17家站里有11家是5=7年的老站,Page Rules写了80=120条堆得乱七八糟(很多还是前任运维的“防御性配置”,比如cache everything + edge cache TTL 30天却没排除cart/account/checkout)。直接迁移的话工作量大概是1条Page Rule对应1=3条Cache Rule(因为Cache Rules把cache行为拆得更细:是否缓存、TTL、缓存键、Origin Cache Control等)。
我们建议的迁移路径是分三步走。第一步是冻结:把现有Page Rules全部截图存档、关掉一半看哪些是真的在生效(Cloudflare控制台Rules标签可以看“最近匹配次数”这个字段)。我们实操经验是平均会有40%的Page Rules一个月匹配次数为0,可以直接清掉。第二步是分桶:把剩下的规则按用途分成5桶——纯缓存策略、Bypass排除、Header改写、Redirect、安全相关——只有前两桶迁到Cache Rules,后三桶分别迁到Transform Rules / Bulk Redirects / WAF。第三步是重写:用Cache Rules的表达式语法把前两桶重新写一遍,并把Edge TTL和Browser TTL分开设置(Page Rules老规则常常把两者绑成同一个值)。
分开TTL这一点是Page Rules时代干不到的红利。我们的标准配置是PDP / PLP页面Edge TTL设4小时(足够吸收正常流量)、Browser TTL设0(让浏览器每次都来问Cloudflare而不是凭自己缓存判断,避免促销改价后用户看到旧价)。这样做的代价是边缘命中率会比统一1天的方案略低,但避免了SKU改价后8小时内浏览器还在显示老价的客诉灾难——我们客户里因此把客诉率压低过30%。
关于Edge TTL与浏览器Cache-Control的优先级机制,更系统的拆解可以查HTTP响应头SEO机制。Cache Rules唯一的硬约束是Free套餐只能用10条、Pro套餐25条、Business套餐50条。独立站如果在Free套餐想吃Cache Rules,需要把规则尽量合并(用in / regex表达式合并)。我们见过一家做户外装备的独立站把38条Page Rules重写成8条Cache Rules,匹配覆盖率反而比原来更全。Cloudflare官方的 Cache Rules文档里有完整的表达式语法对照。
Bypass规则怎么写才不破SEO?
Bypass是Cache Rules里最容易写错的一类——写得太松,登录态、购物车、checkout这些动态页被错误缓存导致用户串号;写得太紧,PDP / PLP上本该缓存的内容被排除导致回源率涨。我们见过的最离谱案例是一家Shopify+Headless架构的独立站,前任工程师写Bypass用了url contains “user”,结果把 /products/user-friendly-tent这条SKU整页Bypass了4个月,PDP回源率100%。
正确的Bypass表达式要走严格path匹配。我们的标准模板是:
(http.request.uri.path eq "/cart")
or (http.request.uri.path eq "/checkout")
or (starts_with(http.request.uri.path, "/account/"))
or (starts_with(http.request.uri.path, "/api/"))
or (http.request.uri.path contains "/wp-admin/")
or (http.cookie contains "wordpress_logged_in")
or (http.cookie contains "woocommerce_cart_hash")
or (http.request.method in {"POST" "PUT" "DELETE" "PATCH"})这里有4个细节坑值得拆。第一个是starts_with与contains的区别。对路径前缀用starts_with比contains更安全,因为contains会把 /products/account-manager这种正常SKU匹配进来。第二个是非幂等HTTP method的处理。POST/PUT/DELETE/PATCH默认就是bypass,但写在Cache Rules里能避免缓存键被错误生成。第三个是Cookie维度的Bypass。登录态、购物车hash这类带状态的Cookie必须明确列出,否则Cloudflare默认不会读Cookie决定是否缓存(除非启用了Cache Reserve的Cookie-aware模式)。第四个是query string的处理。带utm_source / fbclid / gclid的URL默认会被当成不同缓存键,我们的标配是在Cache Rules里加Cache Key → Query String → Ignore(保留sort / page / size这类影响内容的参数,忽略其余)。
对SEO影响最大的是第四个Cache Key处理。如果不忽略追踪参数,同一个PDP页面会因为不同utm来源产生几十上百个独立缓存键,回源率被人为推高、Googlebot抓取同一个页面也会因为来源不同而被当成多个URL来评估。我们实操中见过一家美妆站把Cache Key配好后,回源率单项下降12个百分点,Googlebot的robots.txt抓取错误率也从4%降到0.6%。
Bypass规则改完一定要做一次完整爬测。我们团队用的工具是Screaming Frog设50并发跑全站、配合cf-cache-status头观察每个URL的缓存状态。理想状态是非Bypass路径里90%+的URL第二次抓取都返回HIT或REVALIDATED,Bypass路径里100%返回DYNAMIC或BYPASS。如果出现MISS偏多,说明Cache Rules没把cache行为强制成Eligible for cache,或者Origin给出的Cache-Control头是no-store / private把Cloudflare的缓存指令覆盖掉了。
Argo Smart Routing什么场景值得开钱?
Argo Smart Routing是Cloudflare的付费加速产品,按1GB流量大约0.1=0.15美金计费(套餐内有免费额度)。它做的是“边缘到源站”那段链路的智能路由——也就是说Cloudflare数据中心收到一个回源请求后,不走BGP默认路径,而是走它自己学习出来的最低延迟路径。官方宣传是平均能把回源TTFB降低30%。我们的实测结论是:这个数字只在源站离Cloudflare主要数据中心远、且回源比例高的站才成立。
判断要不要开Argo的决策树是3个问题。第一问:你的源站在哪?如果源站在主要城市(北美的弗吉尼亚、欧洲的伦敦法兰克福、亚洲的东京新加坡),离Cloudflare的anycast中心本来就近,Argo收益普遍只有10%=15%。如果源站在二线区域(比如AWS的us-east-2 / ap-east-1 / sa-east-1)或者用了非主流云(如阿里云华东、腾讯云广州),Argo收益能到25%=40%。第二问:你的回源比例多高?如果通过前面Cache Rules调优已经把回源率压到30%以下,Argo加速的绝对量很小,付出去的流量费可能比省下的TTFB更亏。第三问:你的流量峰是不是来自全球?如果80%的流量来自单一国家(比如纯US市场或纯德国市场),Argo的多路径优势没什么发挥空间。
我们手上有一个反例:一家做户外露营装备的DTC站,源站在新加坡,市场覆盖东南亚 + 澳洲 + 北美西海岸。开Argo前回源TTFB平均380 ms,开Argo后240 ms,下降36%。月度Argo费用47美金,省下来的TTFB让PDP LCP从2.6秒降到2.0秒,SEO排名上有14个核心词从第二页进了第一页。这是开Argo真有ROI的典型场景。
同期我们也劝退过一家美国本土的女装DTC:源站在AWS us-east-1,95%流量来自美国本土,Argo实测只把TTFB从95 ms降到82 ms,下降13 ms。月费38美金换13 ms的提升,纯属浪费。这家站后来把这笔预算转给了Origin Shield,效果好得多。Argo的产品定位见Cloudflare的 Argo Smart Routing文档。
Origin Shield适合什么类型的独立站?
Origin Shield(在Cloudflare体系内对应的产品是Tiered Cache)的逻辑是:在Cloudflare全球200+数据中心和你的源站之间,加一层“中央汇聚节点”。任何边缘缓存miss的请求都先走中央节点,由中央节点统一回源。这样做的好处是同一个URL的缓存只回源1次而不是200次,对源站的回源压力可以下降60%=80%。
Origin Shield不是万能。它的甜区是3类站。第一类是流量分布全球但SKU集中的站。比如卖单品的DTC站、卖单一型号产品的众筹后续站,全球各地用户访问同一个PDP,Tiered Cache把回源压成1次最划算。第二类是源站性能瓶颈在并发数而非带宽的站。比如WordPress + WooCommerce的中小独立站,源站PHP-FPM并发上限是50=80,开Tiered Cache后并发回源数能从峰值200降到30,源站不再502。第三类是源站带宽费贵的站。比如源站放在AWS但用了流量出口(egress)昂贵的区域,Tiered Cache把回源次数压一压能直接省钱。
不适合的反面2类。第一类是SKU量极大(10万+)且长尾流量分散的站。这种站每个PDP在中央节点也很难命中,Tiered Cache的“汇聚效应”发挥不出来,徒增一跳延迟。第二类是源站本身就是multi-region多活架构的站。已经有自己的边缘汇聚层,再叠Cloudflare Tiered Cache会把延迟路径拉长。
开Tiered Cache之前一定要先看Cloudflare Analytics里的“Cache Hit Ratio by Origin”这个图表。如果同一个URL的回源次数在过去24小时里超过50次,说明边缘没起到合并作用,开Tiered Cache才有意义。我们见过一家做小众香水的独立站,全球SKU一共8个但流量分散到47个国家,开Tiered Cache一周后源站回源QPS从平均12降到3,PHP-FPM 502错误率从1.4%降到0.1%。这就是Tiered Cache解决并发瓶颈的典型场景。Tiered Cache的工作机制详见 Cloudflare分层缓存文档。
真实回源率怎么监控才有效?
Cloudflare Analytics面板里那个“Cache Hit Ratio”大数字是聚合值,看不出哪些URL在拖后腿。要做有效监控,必须把维度拆细,并且把数据接到自己的可观测系统里。我们团队的标配是3层监控。
第一层是cf-cache-status头实时采集。所有边缘响应都会带这个header,值有HIT / MISS / DYNAMIC / BYPASS / REVALIDATED / EXPIRED / STALE / UPDATING几种。在前端注入一段轻量JS,把每次fetch的响应头里的cf-cache-status上报到自家的GA4或Plausible自定义事件。这样能按页面、按设备、按地区拆分缓存命中情况。我们客户里见过的最常见问题是PDP在桌面端HIT率92%,移动端只有64%——原因是移动端的viewport探测脚本注入了一个动态请求被错误打回源站。
第二层是Logpush + 数据仓库。把Cloudflare的访问日志push到S3 / BigQuery / Snowflake(Business套餐起支持Logpush)。Logpush的字段里有CacheCacheStatus这一列,加上ClientRequestPath、ClientRequestUserAgent等维度,可以跑出更精细的报表。我们团队的常规分析是按path prefix分组算回源率,把回源率>80%的path拉出来当成下个迭代周期的优化清单。这一层对工具链要求高,独立站站长可以先跳过、用第一层的GA4数据顶一段时间。
第三层是Cloudflare Workers Analytics Engine。这是Cloudflare自家的轻量时序数据库,可以在Worker里直接写入指标、用GraphQL查询。我们团队用它做的是“热门URL回源监控”——每天列出回源次数Top 100的URL,自动跑诊断脚本看是Cache Rules配置问题、源站Cache-Control头问题、还是Cookie维度问题。这种工程化监控的成本是要写100=300行Worker代码——保哥团队用Worker做SEO场景的边缘改稿与实验分流的实战拆解,可以查边缘SEO是什么那篇,但能把缓存调优从“一年大调一次”变成“每周自动优化”。
对独立站站长来说,第一层是必须做的最低标准,第二层是月GMV 50万美金以上推荐做,第三层是有专职运维的团队再考虑。我们手上有一家月GMV 200万美金的家居DTC站,跑齐3层监控后,6个月里回源率从58%降到19%。源站从8核16G降配到4核8G,月度账单省了340美金,比Cloudflare三层付费产品加起来还多。这种把监控做到极致的ROI,是Cloudflare官方面板看不出来的隐藏红利。把缓存命中率从CDN视角延伸到SEO维度,可以对照CDN对SEO的影响与边缘路由实战那篇里的缓存层级图。HTTP缓存的标准语义可以参考 web.dev的HTTP Caching介绍。
WAF拦截规则和缓存命中如何不打架?
WAF和缓存看似两个独立产品,实际在Cloudflare的请求处理管线上是连环的——WAF规则先跑、命中规则后的请求才进入缓存决策。这意味着WAF写得不好会直接把本应缓存的请求拉成Bypass。我们见过的最常见问题是3类。
第一类是Country block写得太粗。很多独立站只面向北美 + 欧洲,会写(ip.geoip.country ne “US” and ip.geoip.country ne “CA” and ...) block。但Googlebot的IP段在google-ip-ranges列表里跨多个国家,被block后Googlebot抓取直接0。我们的标配是先allow已知爬虫(cf.client.bot eq true或cf.verified_bot_category in {“Search Engine Crawler”}),再走地理限制。
第二类是Rate limiting触发缓存Bypass。启用Rate Limiting规则后,Cloudflare会对触发的请求加一个special-treatment标记,这个标记会让后续的Cache Rules默认Bypass。所以Rate Limiting的阈值不能定得太严——比如对PDP设10 req/min/IP看似合理,但Googlebot抓站时20秒内可能就100+ requests来自同一IP,触发后整段抓取的缓存命中归零。我们建议PDP和PLP这种公开页Rate Limit不要 < 100 req/min/IP,或者干脆只对 /checkout / /account这种带状态的path加Rate Limit。
第三类是Bot Fight Mode误伤。Pro套餐自带的Bot Fight Mode默认会对“疑似自动化”的请求做挑战,包括一些低score的真实用户和某些版本的爬虫。挑战页本身不能被缓存,所以这部分流量直接拉低命中率。我们的处理是关掉默认Bot Fight Mode、改用Super Bot Fight Mode(Business套餐起,可以精细到likely automated / definitely automated两档分别处理),或者在WAF里手工加一条cf.bot_management.score lt 30的challenge规则。
WAF和缓存联调的验证方法是看cf-cache-status头的BYPASS比例。健康的站BYPASS应该只出现在明确写Bypass的path(cart/checkout/account/api),如果发现首页或PDP也出现BYPASS,大概率是WAF的某条规则在打断缓存。我们团队的诊断流程是:先在Cloudflare控制台的Security Events里拉过去24小时按path分组的拦截记录,再跟cf-cache-status的BYPASS路径做交叉对比,能快速锁定哪条WAF规则在干扰缓存。
6个月把回源率从60%压到15%的真实操作清单
下面这张清单是我们团队2025年1月=2025年7月给一家月GMV 120万美金的母婴DTC独立站做缓存调优的真实复盘。源站是WordPress + WooCommerce,部署在AWS Lightsail 8 GB实例上,Cloudflare用Business套餐(开了Cache Rules + Tiered Cache,没开Argo)。起步回源率61%,6个月后15.4%。每步动作背后都对应了一个可量化的回源率改进。
第1周=Cache Rules重写。把老Page Rules 80条全清,按5桶逻辑(缓存策略 / Bypass / Header / Redirect / Security)拆出12条Cache Rule。其中4条核心:PDP缓存4小时、PLP缓存2小时、首页缓存30分钟、静态资源缓存30天。回源率61%降到48%。
第3周=Cache Key优化。追踪参数(utm_xxx / fbclid / gclid / msclkid等共14个)在Cache Key里Ignore,business参数(sort / page / size / variant)保留。回源率48%降到39%。
第5周=Bypass规则收紧。把老Page Rules里contains “user” 改成starts_with(“/account/”) + cookie检测,PDP命中率立刻上来。回源率39%降到32%。
第8周=Tiered Cache开启。选Smart Topology(Cloudflare自动选最优中央节点)。源站回源QPS平均值从8降到3。回源率32%降到26%。
第11周=源站Cache-Control头修正。WordPress默认wp-content/uploads下的图片返回Cache-Control: public, max-age=0, must-revalidate,我们让运维改成max-age=31536000, immutable。配合Cloudflare的Respect Origin Cache-Control,静态资源回源量降到0。回源率26%降到21%。
第14周=WAF规则梳理。关掉默认Bot Fight Mode、加Super Bot Fight Mode精细控制、调高PDP的Rate Limit阈值。BYPASS比例从8.2%降到1.4%。回源率21%降到17%。
第18周=Workers优化注水接口。WooCommerce默认有一个 /wp-json/wc/store/cart接口在PDP上会被前端JS周期性调用,把它从PDP模板里干掉、改成只在cart页加载。回源QPS再降30%。回源率17%降到15.4%。整段性能优化的工程化思路与WooCommerce性能优化6层架构那篇拆解的6层路径是同一套底层方法论,缓存只是其中最外的一层。
第22周=复盘与监控固化。把以上动作沉淀成SOP,cf-cache-status上报 + 周报自动化、回源率>20%触发Slack告警、每月跑一次Top 100回源URL诊断。SOP跑稳之后回源率保持在15%=17%区间稳定。
这个项目的隐性收益其实比回源率数字更值钱。源站PHP-FPM 502错误率从2.1%降到0.08%,PDP LCP从3.4秒降到1.7秒,Google Search Console抓取错误数从月均2300降到180,Black Friday当天源站CPU没破60%(去年峰值96%)。所有这些指标都没靠加机器、没换框架——只是把Cloudflare当成一个产品而非一个工具去运营。
独立站站长常犯的3个Cloudflare缓存认知误区
我们做了17家站的缓存调优咨询,发现独立站站长普遍有3个根深蒂固的误区,纠正这些误区比加套餐管用得多。
误区1:Cloudflare缓存命中率90%就够了。错。90%是聚合值,分维度看可能差很多。一个站静态资源命中率99%、PDP命中率75%、PLP命中率85%,聚合下来确实是90%+。但PDP是流量大户,PDP每降低10%命中率源站回源QPS就翻倍。健康的目标是PDP/PLP/首页这3类核心页命中率都 > 90%、整站聚合 > 95%。
误区2:Cloudflare套餐升级就能解决缓存问题。错。Cloudflare套餐升级带来的是Cache Rules条数上限、Logpush能力、Argo / Tiered Cache这些功能解锁,但不会自动帮你优化已有配置。我们见过的90%的“缓存效果不好”案例,根因都是Cache Rules没写好或Bypass写错,跟套餐无关。Free套餐认真配10条Cache Rules的命中率,往往比Business套餐随便配50条的命中率还高。
误区3:开了Cloudflare就不用管源站缓存。错。Cloudflare是Respect Origin Cache-Control的(除非你明确override),源站给的no-cache / no-store / private这些指令Cloudflare会尊重。WordPress / Magento / Shopify的默认Cache-Control头很多场景是偏保守的,必须在源站层(nginx / Apache / 应用层中间件)也做一次梳理。我们的标准做法是PDP / PLP在源站层就返回public, s-maxage=14400, max-age=0这种语义(边缘缓存4小时、浏览器不缓存),让Cloudflare的Cache Rules和源站Cache-Control互相印证而不是互相覆盖。
独立站缓存这件事,工程上不复杂——10条Cache Rules + 严谨的Bypass + cf-cache-status监控基本就能做到90%的效果。难点是观念:必须把Cloudflare当成一个需要持续运营的产品、而不是“开了就忘”的工具。CDN的边缘缓存原理可以参考 维基百科Content delivery network词条,HTTP缓存的语义标准可以查 MDN的Cache-Control文档。
常见问题解答
Cloudflare Cache Rules和Page Rules能同时存在吗?
能。Cloudflare的请求处理管线里Cache Rules优先级高于Page Rules,同一个URL如果两边都匹配,Cache Rules的指令生效。但我们建议迁完Cache Rules后把对应的Page Rules关闭——保留双份规则会让后续排查问题变得很难,6个月后没人记得规则之间的优先级和组合效果。
独立站要不要把整站设成Cache Everything?
不要无脑设。Cache Everything的语义是“忽略源站Cache-Control,强制按Edge TTL缓存”,对PDP / PLP这种内容相对稳定的页面有效,但对带登录态的页面是灾难。我们的标准做法是只对明确的页面类型用Cache Everything(通过path表达式精确锁定),其他保持Standard模式让源站的Cache-Control主导。
开Tiered Cache会不会增加TTFB?
边缘命中的请求不受影响(直接边缘返回,根本不到Tiered这一层);边缘miss但中央节点命中的请求TTFB比直接回源略低(中央节点更近源站、且常常已缓存);边缘和中央都miss的请求TTFB会多30=80 ms(多了中央节点这一跳)。所以整体TTFB是降是升取决于命中率分布。回源率 > 30%的站开Tiered Cache通常TTFB净降,回源率 < 15%的站开了反而略升。
Argo Smart Routing和Tiered Cache能一起开吗?
能。Argo是优化回源链路的延迟,Tiered Cache是减少回源次数,两者解决的问题正交。但同时开的预算开销不小(Argo按流量、Tiered Cache含在Business套餐里),我们建议先开Tiered Cache把回源次数压下来再评估Argo的边际收益。多数独立站只开Tiered Cache就够了。
cf-cache-status显示DYNAMIC是什么意思?
DYNAMIC表示这个URL默认被Cloudflare判定为不可缓存(通常是因为HTTP method是POST/PUT/DELETE,或者URL路径在Cloudflare内置的default-non-cacheable列表里如 /wp-admin /admin /login)。如果你期望它被缓存,需要在Cache Rules里显式把cache行为设成Eligible for cache + 指定Edge TTL。仅写一条path匹配但不改cache行为,URL仍然会显示DYNAMIC。
Cloudflare缓存调优会不会影响Google抓取频率?
会,而且通常是正向影响。Googlebot看到源站响应快(边缘命中的TTFB在50 ms以内)会逐步增加抓取预算。我们跟踪过的项目里,缓存调优6个月后Search Console的“每日抓取请求数”平均上涨35%=60%,相应索引数也跟着涨。但有一个反向情况要注意:如果Bypass规则错误地把sitemap.xml或robots.txt排除掉、源站又慢,Googlebot抓取这两个关键文件失败会直接掉抓取频率。
权威参考资料
独立站Cloudflare缓存治理是个高ROI但低关注的工程领域,配置写得好坏直接影响源站成本、SEO表现、用户体验三件事。保哥的建议是把它当成一个独立项目去运营、每3个月跑一次回源率审计、把cf-cache-status接入日常监控。把缓存命中率从70%推到95%这件事的边际成本是写规则的人力,边际收益是源站成本下降 + 抓取预算上升 + LCP改善,复利会持续很久。下次预算紧张要降运维成本前,先看看Cloudflare控制台的回源率数字,这是最不容易被注意但最值钱的杠杆之一。
本文标题:《独立站Cloudflare缓存与回源率优化:8维决策树+Cache Rules迁移实战》
本文链接:https://zhangwenbao.com/cloudflare-cache-real-world-optimization-decision-tree.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0