HTTP响应头SEO机制:X-Robots缓存Vary实战
本文目录
- HTTP响应头到底能怎么影响SEO?
- 响应头与HTML标签是两条通道
- 响应头不是单层的
- 响应头的SEO体检入口
- X-Robots-Tag和meta robots有什么区别?
- 作用域差异
- 优先级与组合
- 典型应用场景
- 反模式:robots.txt挡 + meta noindex
- Cache-Control与抓取预算到底什么关系?
- 304 Not Modified机制
- Cache-Control指令的SEO含义
- Last-Modified vs ETag
- Last-Modified与sitemap lastmod的一致性
- Vary头不写到底会出什么问题?
- Vary: User-Agent的场景
- Vary: Accept-Language的场景
- Vary: Accept-Encoding
- Vary滥用的陷阱
- Link头部传canonical是什么时候用?
- 语法与典型用法
- HTML文件也可以用Link头部传canonical吗
- 组合:Link rel + X-Robots-Tag
- Content-Type和Charset头部对索引有什么影响?
- Content-Type必须正确
- Charset与编码乱码
- JSON和图片的Content-Type
- HSTS和SEO有什么关系?
- HSTS preload列表的预跳转收益
- HSTS对HTTPS迁移的辅助
- HSTS配错的高风险
- HTTP/2和HTTP/3会不会带来排名收益?
- HTTP/2的多路复用
- HTTP/3和QUIC
- 什么时候不值得升级
- 怎么验证升级实际效果
- CDN会怎么改写我的响应头?
- 三家主流CDN的改写边界
- 常见的CDN改写陷阱
- 调试CDN改写的标准流程
- Robots.txt和HTTP响应头的CDN边界
- 响应头怎么做定期审计?
- 审计清单
- 自动化审计的简易实现
- 异常告警的阈值
- 把响应头审计接入CI/CD
- 常见问题解答
- HTTP响应头是不是Google的排名因子?
- X-Robots-Tag和meta robots有什么区别?
- Cache-Control会不会影响SEO?
- Vary头不写会出什么问题?
- Link头部传canonical是用来干什么的?
- HSTS和SEO有什么关系?
- HTTP/2和HTTP/3会不会带来排名收益?
- CDN会改我的响应头吗?
- 权威参考资料
摘要:大部分让人摸不着头脑的技术SEO灾难都不发生在HTML里,而是发生在HTTP响应头里:一行X-Robots-Tag写错让整片页面消失、Cache-Control全开no-cache把Googlebot抓取预算两周烧光、Vary漏写让移动优先索引看到桌面缓存版本。这些坑的共通点是肉眼看不见,必须主动curl -I去查。
本文按八条指令把机制讲透:X-Robots和meta robots的优先级到底谁说了算、Cache-Control与Last-Modified与ETag的304经济学、Vary多版本陷阱、Link头给PDF挂canonical、HSTS preload的不可逆风险、HTTP/2与HTTP/3对Core Web Vitals的间接影响、Cloudflare与CloudFront与Fastly各自的默认改写边界、响应头审计接入CI/CD的具体实施。每条都配上调试方法和真实失败案例。
大部分技术SEO问题不是出在HTML里,是出在HTTP响应头里。HTML写得再好,响应头一个X-Robots-Tag: noindex发出去,整页直接消失。Cache-Control一行写错,Googlebot反复重抓不变的内容,把抓取预算全烧光。Vary漏写一个User-Agent,桌面版被发给移动用户,移动优先索引看到一团糟。
响应头是技术SEO的“黑暗物质”——肉眼看不见但占了大半。下面按指令拆机制:X-Robots-Tag、Cache-Control、Vary、Link、HSTS、HTTP版本、CDN改写。
HTTP响应头到底能怎么影响SEO?
先回答最基本的:响应头本身不是排名因子,但它是搜索引擎理解你站的指令通道。配对了能避开各种诡异问题,配错了能让一整片页面集体消失。
响应头与HTML标签是两条通道
SEO圈习惯用HTML里的meta标签做指令(meta robots、meta canonical、meta description)。但HTML不是唯一通道,HTTP响应头是另一条平行通道。两条通道有不同的能力边界:
- HTML通道:只对能被浏览器或Googlebot渲染HTML的文件有效。PDF、图片、JSON、视频文件用不了。
- 响应头通道:对任何MIME类型都有效。可以对PDF做noindex、对图片做canonical、对JSON做cache控制。
这就是为什么响应头是大型站和文档密集型站(学术、政府、文档/帮助中心、电商资源站)的SEO必修课——非HTML文件占比一高,HTML通道就管不到了。
响应头不是单层的
响应头在从源服务器到浏览器的路径上会被多层改写:源站发一组、应用服务器(Nginx/Apache)可能改写一组、CDN加一组、边缘函数可能再改一组。最终Googlebot收到的是叠加结果。中文SEO圈常见的debug困惑都来自这里——你以为你设了Cache-Control,CDN默认改写覆盖了你的设置;你以为你发了X-Robots,应用服务器没透传。
响应头的SEO体检入口
检查响应头有几个常用工具:curl -I url(最快)、Chrome DevTools Network面板(最直观)、GSC URL检查工具的“查看抓取的页面”里的HTTP头(Googlebot视角最权威)。SEO体检必看的头部有:X-Robots-Tag、Cache-Control、Last-Modified、ETag、Vary、Link、Content-Type、HSTS、Server。看这九条头部是否有、是否符合预期,能解决80%的技术SEO诡异问题。
X-Robots-Tag和meta robots有什么区别?
这条是最常被混用又最容易栽的指令。两者用的指令值相同(index/noindex/follow/nofollow/noarchive/nosnippet等)但作用域和优先级完全不同。
作用域差异
meta robots只能放在HTML的
里。对非HTML文件无效——PDF、图片、视频、JSON都用不了meta robots。X-Robots-Tag放在HTTP响应头里,对任何MIME类型都有效。要对PDF做noindex只能用X-Robots-Tag,没有第二条路。这是非HTML文件做SEO控制的唯一手段。优先级与组合
两者同时存在时按“最严”的那条执行。具体规则:
- meta是index、X-Robots是noindex → 结果noindex(最严赢)。
- meta是noindex、X-Robots是index → 结果noindex。
- meta是follow、X-Robots是nofollow → 结果nofollow。
- meta是noarchive、X-Robots没写 → 结果noarchive。
规则简单一句话:所有可用指令通道里只要有一条说不让,就不让。这是Google的设计哲学——指令通道的冲突不靠优先级而靠并集。
典型应用场景
| 场景 | 用meta还是X-Robots | 原因 |
|---|---|---|
| HTML页面想noindex | 都可以 | meta更直观、可被人在HTML里看到;X-Robots更便于运维批量设置 |
| PDF需要noindex | 只能X-Robots | PDF没有HTML head |
| 图片做nosnippet | 只能X-Robots | 图片没有HTML head |
| 大量页批量noindex | X-Robots | 在Nginx/Apache配置一次性对路径模式批量生效 |
| 分类页临时下线 | X-Robots | 不动HTML,避免缓存层不一致 |
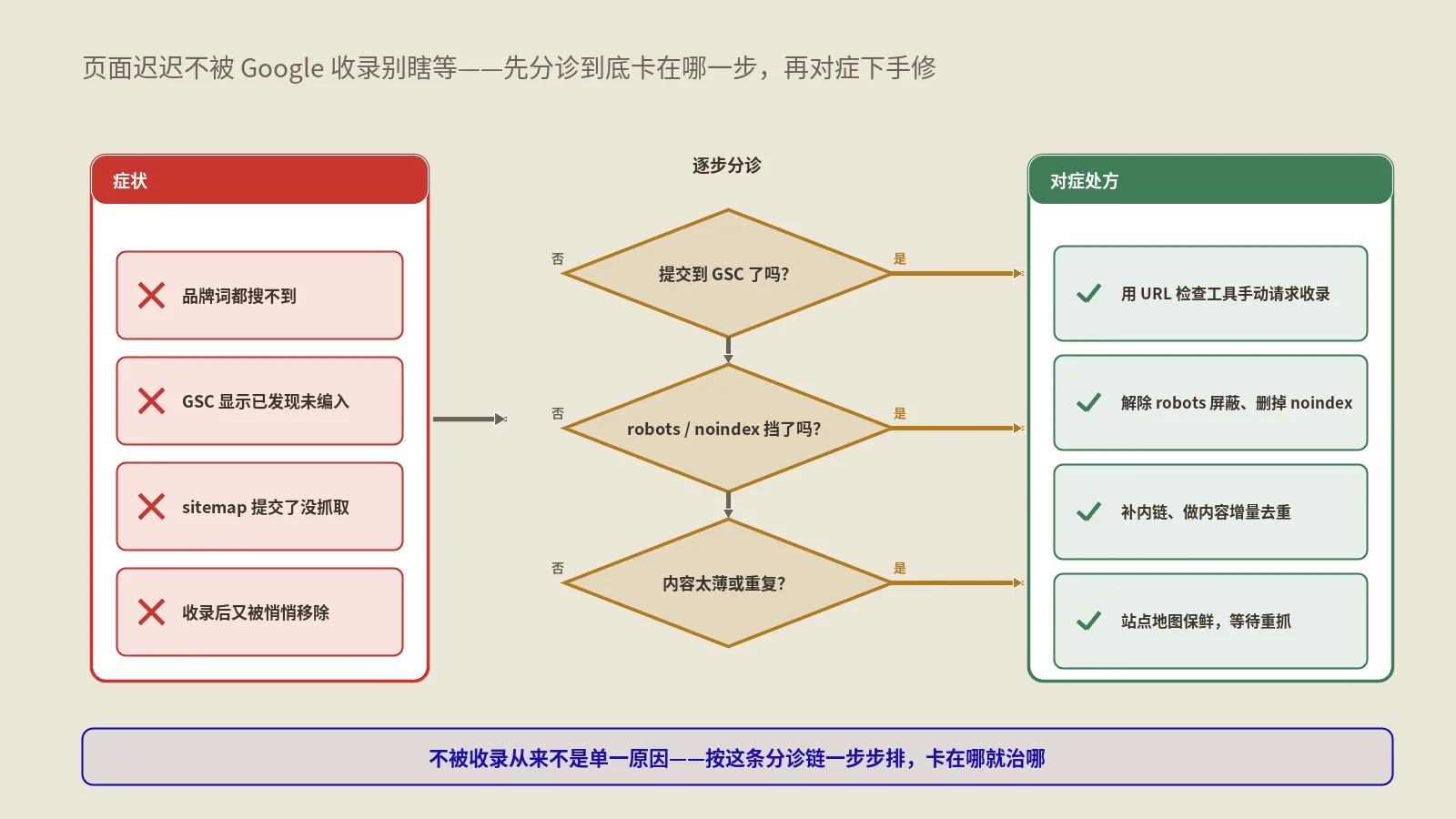
反模式:robots.txt挡 + meta noindex
常见错误:robots.txt里Disallow了某路径,又在该路径的HTML里加meta noindex。这两件事冲突——robots.txt不让爬,Googlebot就根本读不到meta noindex,结果是该路径页面被记在索引里但没内容显示(“已索引但被robots屏蔽”状态),SEO反而变差。要让一个已索引页面下线必须先放开robots、让Googlebot读到noindex,等真正消失了再决定要不要robots屏蔽。
Cache-Control与抓取预算到底什么关系?
Cache-Control的SEO意义被严重低估。它通过条件请求机制直接影响Googlebot的抓取经济学,对大型站尤其关键。
304 Not Modified机制
Googlebot抓页面时会带两个条件头部:If-Modified-Since(基于上次抓取时间)、If-None-Match(基于上次的ETag)。如果服务器响应这两个条件认为内容未变,可以返回304 Not Modified——空响应体、几乎零字节。Googlebot收到304就知道页面没变、不浪费抓取预算重读全文。
304对Googlebot来说不算“跳过抓取”,算“高效抓取”——抓取计数会减,但页面仍被视为活页。这条机制是大型站节省抓取预算的最大杠杆。我见过的最有效的实施:把全站的静态资源和不常变的内容页配置正确的Last-Modified和ETag,6周后GSC抓取统计里的“总下载字节”降了70%,同时“被抓取的不同URL数”升了40%。等于Googlebot用同样的预算抓了更多新内容。
Cache-Control指令的SEO含义
- public/private:对Googlebot而言两者大体等价,Googlebot不缓存代理。private更多影响CDN行为。
- max-age=N:浏览器缓存最大秒数。对Googlebot不直接影响。
- s-maxage=N:CDN缓存最大秒数。Googlebot通过CDN取数时被影响。
- no-cache:每次都要校验(仍可能304),不是“禁用缓存”。
- no-store:完全不缓存,每次重抓。SEO上几乎永远不用,会烧光抓取预算。
- must-revalidate:缓存到期必须校验,不能用过期版本。
错配的典型:全站发no-store(“为了让用户总是看到最新”),Googlebot没有304可走,每次都重抓全文,大站的抓取预算两周内被烧光。
Last-Modified vs ETag
两者都用于条件请求,但适用场景不同:
| 机制 | 适用 | 失效情况 |
|---|---|---|
| Last-Modified | 内容真实有“修改时间”概念 | 动态生成页(每次响应时间都不同)会失效 |
| ETag | 任何内容,按响应体哈希 | 多机部署的服务器ETag不一致时失效 |
实操经验:静态资源(图片、CSS、JS)用ETag最稳;HTML页面用Last-Modified(与sitemap的lastmod呼应);动态接口尽量两者都不发,让Googlebot重抓——动态接口本来也不该被Googlebot抓。
Last-Modified与sitemap lastmod的一致性
这是一个低调但高ROI的细节:sitemap里的lastmod应该与该URL响应头里的Last-Modified一致或非常接近。两者不一致时,Googlebot会按响应头为准、忽略sitemap。Google的John Mueller多次说过,sitemap的lastmod被Google视为“站方声称的修改时间”,必须与服务器实际响应一致才有价值。两者长期错位的站,sitemap会被Google降低信任度。
Vary头不写到底会出什么问题?
Vary头是告诉CDN和Googlebot:这个URL在“某些请求条件”下会返回不同的响应。漏写或写错会出严重的串扰问题。
Vary: User-Agent的场景
当同一URL会按User-Agent返回不同内容(典型是有独立移动端模板、或者动态服务),必须设Vary: User-Agent。否则CDN可能把桌面版缓存的响应直接发给移动用户,Googlebot移动优先索引看到的就不是该URL在移动设备上的真实内容。移动优先索引那篇讲过Googlebot的渲染管线对移动版的依赖,Vary: User-Agent漏写在那个语境下会被放大成系统性灾难。
Vary: Accept-Language的场景
对多语言站如果用同一URL按浏览器语言返回不同语言版本(不推荐这种做法,但确实有站这么干),必须发Vary: Accept-Language。否则会出现“A语言的缓存被发给B语言用户”。但更好的做法是不要做IP/语言自动跳转,而是为每种语言用独立URL(子目录或子域),靠hreflang告诉Google。这是Google多次官方推荐的方式。
Vary: Accept-Encoding
当服务器按客户端能力发送gzip/br/deflate压缩内容时,必须发Vary: Accept-Encoding。这条几乎所有现代服务器默认就发,但偶尔会被自定义CDN规则覆盖掉。漏发会导致中间代理把压缩响应发给不支持压缩的客户端、或反之,造成乱码或解码失败。SEO上Googlebot不会因此抓不到,但用户体验受损会通过停留时长间接拉低排名信号。
Vary滥用的陷阱
反过来,Vary也不能乱发。Vary: *(对所有头部都vary)会让CDN完全无法缓存,等于关掉缓存。Vary: Cookie会让每个有不同Cookie的请求都被视为不同响应(基本上每个登录用户都触发一次回源),CDN命中率掉到接近零。这两种配置都是高频踩坑——为了避开某个特定问题写了一个全局开关,结果把缓存层完全废掉。
Link头部传canonical是什么时候用?
HTML有canonical link元素(link rel canonical写在head里)。但非HTML文件没有HTML head,怎么传canonical?答案是用HTTP响应头里的Link字段。
语法与典型用法
响应头里发:Link: <https://example.com/canonical-url>; rel="canonical"。Google会按这个值确认该非HTML文件的canonical URL。典型应用:
- PDF白皮书被索引,但canonical应指向同主题的HTML页(让HTML获取权重、PDF做附件)。
- 图片资源被索引,canonical指向图片所在的产品/文章页。
- API JSON端点被Googlebot抓到,canonical指向有HTML文档化页面。
- 多份PDF(中文版、英文版)通过canonical指向同一英文版canonical集中权重。
HTML文件也可以用Link头部传canonical吗
可以,但不推荐。HTML文件的canonical建议放在HTML head里,因为Googlebot渲染时直接读取,CDN/代理改写HTML head的概率远低于改写HTTP响应头。两者同时发时按最严或最一致的处理(Google会综合考虑发现的所有信号)。混发只会增加调试难度。
组合:Link rel + X-Robots-Tag
响应头里可以同时发多个指令:Link: <canonical-url>; rel="canonical" + X-Robots-Tag: noindex。两者不冲突,可以并列。常见组合:PDF做noindex + canonical指向HTML——告诉Google不要把这个PDF进索引、但任何关联到这个PDF的信号要归到HTML页。
Content-Type和Charset头部对索引有什么影响?
这条容易被当成“纯技术配置”忽略,但它直接影响Googlebot能否正确解析内容。
Content-Type必须正确
HTML文件必须发Content-Type: text/html; charset=utf-8。如果错发成application/octet-stream,浏览器会触发下载而不是渲染,Googlebot也会按二进制处理、不抽取内容。JS渲染那篇讲过Googlebot的两阶段抓取流程,Content-Type在第一阶段就被读取,错配直接决定第二阶段渲染是否启动。
Charset与编码乱码
中文站如果charset漏发,Googlebot会按UTF-8默认解析。如果内容实际是GBK/GB2312(老CMS常见),就会被乱码处理,索引时只能抓到不完整的中文。这条对老CMS站(DEDECMS、ECShop老版本)尤其关键,迁移到UTF-8之前要先排查全站Content-Type是否一致。
JSON和图片的Content-Type
JSON要发application/json,图片按格式发image/jpeg/image/png/image/webp等。错发会让Google Image Search无法识别图片格式,影响图片索引和Rich Results展示。
HSTS和SEO有什么关系?
HSTS(HTTP Strict Transport Security)告诉浏览器“这个域名只能用HTTPS访问”,浏览器会自动把所有HTTP请求转成HTTPS。和SEO的关系主要在三个层面。
HSTS preload列表的预跳转收益
HSTS的max-age生效需要用户访问过一次。如果加入Chrome的HSTS preload列表,所有Chrome用户在第一次访问前就强制HTTPS,省下一次301跳转。对301连环跳的站这是真实收益。但加入preload不可逆——一旦加入,移除要等几个月甚至更久,期间想回滚HTTPS基本不可能。
HSTS对HTTPS迁移的辅助
从HTTP迁到HTTPS时,HSTS能保证已经访问过的用户不会因为输入了HTTP地址而被中间人攻击。SEO上这间接保护了已有的HTTPS权重。但HSTS不能替代301——301是告诉Googlebot URL变了,HSTS是告诉浏览器协议变了,两者目的不同必须都做。
HSTS配错的高风险
HSTS的max-age最高可以设到2年。配错了想回滚极难——所有曾经访问过站的浏览器都会在缓存期内强制HTTPS,回HTTP需要等所有浏览器缓存过期。线上配HSTS必须先用短max-age(60秒到1天)试运行,确认整站HTTPS没有任何资源会失败,再逐步把max-age拉到推荐值(6个月)。preload只在长期稳定后再考虑。
HTTP/2和HTTP/3会不会带来排名收益?
不是直接排名信号,但通过Core Web Vitals间接影响Page Experience评分。
HTTP/2的多路复用
HTTP/1.1是每个连接一个请求一个响应,浏览器要并行下载多资源得开多个连接。HTTP/2在同一连接上多路复用多请求,减少了TCP连接开销和head-of-line blocking。对一页有几十上百个小资源的站(电商、媒体),LCP和INP的改善是可测量的。
HTTP/3和QUIC
HTTP/3跑在QUIC(基于UDP)上而不是TCP,对高丢包率移动网络的TTFB有明显改善。对出海站(用户分布在东南亚、印度、拉美等基础设施不均的市场)收益最大。CDN开启HTTP/3一般在Cloudflare/Fastly这类供应商一键启用。
什么时候不值得升级
小型站、流量集中在北美/欧洲、用户网络稳定的场景,HTTP/3的实际收益较小。升级HTTP/3的工程成本(监控、调试、回退预案)可能超过收益。SEO视角下,先把HTTP/2拿稳、配套缓存和图片优化做对,是性价比更高的路径。
怎么验证升级实际效果
用WebPageTest或Chrome DevTools的Network面板看具体资源的Protocol列。绿色h2/h3意味着确实跑在新协议上。GSC的Core Web Vitals报告会在升级后2-4周反映出LCP/INP的趋势变化,不要看一两天的波动。
CDN会怎么改写我的响应头?
这条是中文SEO圈最容易被坑的地方,因为CDN的默认改写策略很激进且不透明。
三家主流CDN的改写边界
| CDN | 默认会改的头 | 默认会加的头 | 能否完全透传 |
|---|---|---|---|
| Cloudflare | Cache-Control(按配置规则改)、Server | CF-Ray、CF-Cache-Status | 能,但需在Page Rules显式设置 |
| CloudFront | 按behavior policy改Cache-Control、Vary | X-Amz-Cf-Id、Via | 能,需在Behavior里禁用 |
| Fastly | 按VCL规则改写 | Fastly-Debug-Path | 能,VCL完全可控 |
常见的CDN改写陷阱
- Cloudflare的Browser Cache TTL会覆盖源站的Cache-Control max-age。如果源站发的是1小时、Cloudflare设的是“Respect Existing Headers”以外的选项,最终发给浏览器的会是Cloudflare的设置。
- CloudFront的MinTTL会强制Cache-Control至少为某个值。如果源站想发no-cache,CloudFront的MinTTL=300会覆盖成300秒缓存。
- Fastly的Surrogate-Control会被剥离不传给浏览器,所以源站可以用Surrogate-Control单独控制Fastly而Cache-Control控制浏览器。但要明确两者分工,不要混用。
调试CDN改写的标准流程
三步法:
- 直接curl源站(绕过CDN)拿响应头,记下源站发了什么。
- curl CDN节点,对比浏览器实际收到什么。
- 差异部分逐条对应到CDN控制台的对应规则,要么改源站发对、要么改CDN别改写。
这套流程跑通的团队,响应头debug时间能从平均2-3小时压到20分钟以内。
Robots.txt和HTTP响应头的CDN边界
robots.txt本身是HTTP响应一种,CDN可能也会缓存。如果你刚改了robots.txt但Googlebot还在按旧规则爬,先检查CDN是否还在发旧版本。robots排除协议那篇讲过robots.txt的解析机制与缓存周期,CDN这一层是该篇没展开但实际会影响生效时延的关键变量。
响应头怎么做定期审计?
响应头是动态的、易变的,必须有定期审计机制。手工抽查不可持续,要自动化。
审计清单
- 核心页(首页/分类页/详情页代表样本)的X-Robots-Tag值。
- 核心页的Cache-Control + Last-Modified + ETag三件套是否齐全。
- 核心页的Vary头是否符合预期(最少应有Accept-Encoding;多版本场景应有User-Agent或Accept-Language)。
- 非HTML资源(PDF/图片/视频)的X-Robots-Tag和Link rel canonical。
- Content-Type和charset正确性。
- HSTS的max-age和includeSubDomains/preload配置。
- HTTP版本(h2/h3)的覆盖率。
- CDN层是否有意外的头部覆盖或剥离。
自动化审计的简易实现
写一个简单脚本(100行Python或bash)定期抓全站sitemap里的样本URL,curl -I收响应头,按上面清单校验是否符合预期。每周跑一次,结果写入数据库,对比上周看是否有突然变化。突然变化的根因常是:CDN规则被改、应用服务器配置被改、新部署引入了未预期的头部行为。
异常告警的阈值
响应头变化的告警阈值要设得敏感:
- X-Robots-Tag从无变成有noindex:立即告警,可能是误配。
- Cache-Control从有Last-Modified变成无:告警,抓取预算面临浪费。
- Vary头变化:告警,可能影响多版本识别。
- Content-Type在HTML页变成非text/html:紧急告警,可能整页失踪。
把响应头审计接入CI/CD
更进一步,把响应头校验当作前端/后端发布的CI/CD检查项。每次新部署先在staging环境跑响应头校验,关键头部偏离预期就阻断发布。这能在响应头错配真正影响线上索引之前就拦下来。SEO自动化那篇讲过CI/CD视角下的SEO维护,响应头校验是其中一个高ROI的具体项。
常见问题解答
HTTP响应头是不是Google的排名因子?
不是直接打分项,是搜索引擎的指令通道。响应头通过控制可索引性、抓取预算、内容版本识别这些机制间接影响排名,但本身不被算成正向加分。它更像是“能让搜索引擎听懂你想干什么”的协议层,配错了会出现各种诡异的索引和抓取问题。
X-Robots-Tag和meta robots有什么区别?
meta robots只能放在HTML的head元素里,对PDF/图片/视频/JSON这类非HTML文件无效;X-Robots-Tag放在HTTP响应头里,对任何MIME类型都生效。两者同时存在时按“最严”的那条执行,比如meta是index、X-Robots是noindex,结果是noindex。要对PDF做noindex只能用X-Robots。
Cache-Control会不会影响SEO?
会,通过抓取预算这条路径。Cache-Control + Last-Modified/ETag决定Googlebot能不能返回304 Not Modified跳过重抓。设置合理时,大型站的抓取预算可以节省30%-60%;设置错(比如所有页都no-cache)时,Googlebot会反复重抓相同内容,把抓取预算烧在不变的页面上。
Vary头不写会出什么问题?
会出现“同一URL不同版本被识别为重复”或“缓存把A用户的版本发给B用户”的诡异问题。最常见的是Vary: User-Agent漏写,导致桌面版被发给移动用户、或者多语言版本被错发。Google抓取时也会被误导,对移动优先索引尤其敏感。
Link头部传canonical是用来干什么的?
用于非HTML文件的canonical指定。PDF、图片、Office文档无法在内容里写canonical link,只能在响应头里发Link字段把目标URL挂上rel canonical指令。这是PDF被索引但又想把权重集中到HTML版本时的标准做法。
HSTS和SEO有什么关系?
HSTS本身不是排名信号,但HSTS preload列表能让浏览器在第一次访问前就强制HTTPS,消除HTTP到HTTPS的301跳转开销。这对301连环跳的站有性能与抓取信号收益。HSTS配错会导致回滚HTTPS失败,是高风险操作,要先用短max-age试运行。
HTTP/2和HTTP/3会不会带来排名收益?
不是直接排名信号,但通过LCP/INP等Core Web Vitals间接影响Page Experience评分。HTTP/2的多路复用、HTTP/3的QUIC对TTFB和LCP有可测改善,对流量大、连接多的站收益明显。小站的实际收益较小,性价比要按流量规模评估。
CDN会改我的响应头吗?
会,而且改得很激进。Cloudflare、CloudFront、Fastly各有不同的默认改写策略,可能添加自己的Cache-Control、覆盖你的Vary、剥离自定义头。配置pSEO项目或多语言站时,必须在CDN控制台显式设定哪些头部不能被改写、哪些头部要透传,否则会出现“源站发的是A,浏览器收到的是B”的诡异问题。
权威参考资料
本文标题:《HTTP响应头SEO机制:X-Robots缓存Vary实战》
本文链接:https://zhangwenbao.com/http-response-headers-seo-x-robots-cache-vary-canonical-mechanism.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0