边缘SEO是什么?在CDN边缘改SEO的原理与落地形态
本文目录
- 边缘SEO到底是什么,又不是什么?
- 它解决的是“发版排队”,不是“网站太慢”
- 它和缓存刷新、JS渲染、A/B分流的边界在哪
- 边缘层到底能改什么,不能改什么?
- “能改”不等于“该改”,结构化数据是重灾区
- 边缘渲染是另一个话题,别和边缘改写混着上
- hreflang和canonical在边缘改,机制上有几个隐坑
- 状态码和响应头,是边缘改写里最干净的一类
- 三种落地形态,到底怎么选?
- 选型的真实顺序,是从“最笨的能不能解决”往上爬
- 别忽略供应商绑定,它是迁移期才会现形的隐性成本
- 一个真实的改造序列长什么样
- 为什么边缘改动迟早会变成隐性技术债?
- 源站真相和线上真相,开始对不上
- 没人记得这条规则当初为什么加
- 回滚、可观测、负责人,这三件套缺一不可
- 可观测具体怎么落地,比口号重要
- 灰度和渲染快照比对,是上线前最后一道闸
- AI爬虫来了,边缘这层要不要区别对待?
- 给不同爬虫返回不同内容,这条线不能踩
- 边缘真正该为AI流量做的,是协议层的精细化
- 什么时候该用边缘SEO,什么时候是在掩盖问题?
- 临时桥和永久建筑,从第一天就要分清
- 交接清单:人走了,规则不能变成孤魂
- 常见问题解答
- 边缘SEO和CDN缓存刷新是一回事吗?
- 没有开发资源,能不能纯靠边缘SEO把站做好?
- 在边缘注入结构化数据安全吗?
- 边缘改的title和源站自带的会冲突吗?
- 边缘SEO会不会被搜索引擎当作作弊?
- 小团队没有监控和文档能力,还能碰边缘SEO吗?
- 怎么判断我到底该不该上边缘SEO?
摘要:边缘SEO既不是黑科技,也不是“清一下CDN缓存”。它指的是把一部分SEO改动放到CDN的边缘节点上执行——在请求还没回到你那台老掉牙的源站之前,就把标题、规范链接、重定向、hreflang、robots、结构化数据这些东西改掉。它真正解决的不是性能问题,而是“改个meta都要排队等开发半年发版”这个组织问题。用对了能救命,用顺手了会埋下一种很隐蔽的技术债:线上看到的页面和源站代码里写的,是两套事实,而且没人记得那条边缘规则当初为什么加。所以这篇的重点不在“怎么写一个Worker”,而在边界、可观测和交接——什么时候该用,什么时候你只是在用边缘掩盖一个本该在源站修的问题。
这件事保哥是被逼出来的。早些年接过一个出海做工业检测设备的B2B站,整站跑在一套外包的老.NET框架上,原厂跑路、源码部分丢失,改一行模板要走甲方IT、外包、再到服务器管理员三方排期,最快的一次“把分类页title加上地区词”这种五分钟的活,走完流程用了十一周。期间自然流量该掉的一点没少掉。后来我们没有再去碰那套源码,而是在它前面的CDN上写了一层规则,把需要改的SEO字段在边缘改掉,两天上线,名次三周内回来。那次之后对边缘这层的态度彻底变了:它不是炫技,它有时候是唯一能在合理时间内动手的地方。但也正是那次,埋了个坑——一年后接手的人完全不知道线上那些title是边缘改出来的,对着源码查了三天找不到“代码在哪”。这篇要讲的,就是怎么吃到前半段的好处,同时不踩后半段的坑。
开篇先把边界划清楚,免得和站内已经讲透的东西混在一起。本篇不重复讲CDN缓存怎么刷新(那是缓存一致性问题,不是这里说的“改写”);也不重复JS渲染那篇讲的客户端渲染抓取问题——边缘渲染和它有关系但不是一回事,下面会专门说;涉及在边缘做爬虫拦截的部分,robots与抓取协议那篇已经讲过UA加IP反查的正确姿势,这里只讲它和SEO改写的协同;而把边缘改动当资产去管理、防止它变成无人认领的债,归到SEO技术债务那篇的框架里看。本篇只钻一件事:把SEO改动下沉到边缘层这个动作,机制、能改什么、风险在哪、怎么治理。
边缘SEO到底是什么,又不是什么?
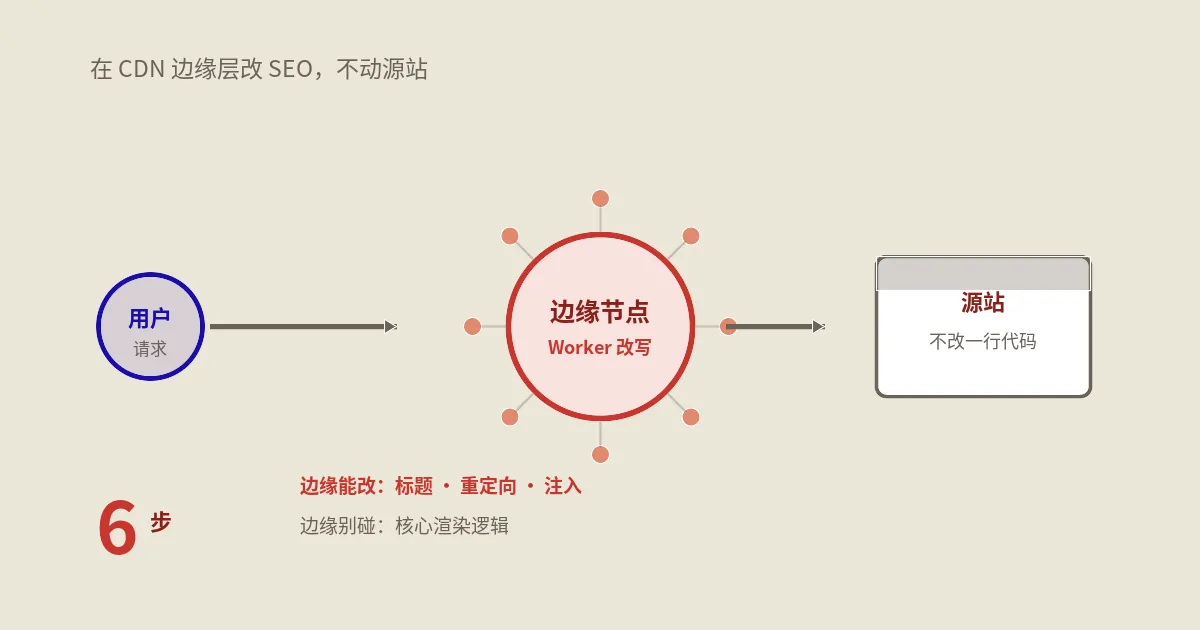
把名字拆开看最清楚。“边缘”指的是CDN分布在全球的那一圈节点,用户请求先打到离他最近的边缘节点,节点再决定是直接返回缓存、回源站取、还是先跑一段你写的代码。“边缘SEO”就是在这个“先跑一段代码”的环节里,对响应做SEO相关的改写。它的物理位置在用户和源站中间,所以它能改的,是请求进出这条链路上能被拦截的东西。
它解决的是“发版排队”,不是“网站太慢”
很多人第一次听到边缘,脑子里冒出来的是性能——边缘节点离用户近,所以快。这没错,但那是CDN本来就在干的事,不需要叫“边缘SEO”。边缘SEO真正的价值主张只有一个:把SEO改动的执行权,从受发版排期约束的后端,挪到一个你能独立、快速、低风险动手的地方。它是个组织和流程层面的解法,披着技术的外衣。判断你是不是真的需要它,标准不是“我想让网站快点”,而是“一个本该十分钟搞定的SEO改动,在我这要走多久流程、风险多大”。如果你的研发能在当天给你上线一个meta改动,你大概率不需要边缘SEO,老老实实在源站改更干净。
它和缓存刷新、JS渲染、A/B分流的边界在哪
这三件事经常和边缘SEO被混为一谈,分清楚才不会用错工具。缓存刷新解决的是“源站已经改对了,但边缘还缓存着旧版本”,方向是把正确的新版本推下去;边缘SEO正好相反,是“源站没改、也短期改不了,我在边缘把它改对”。JS渲染问题是内容靠浏览器执行JS才出现、爬虫可能抓不到,边缘可以参与解法(边缘预渲染、边缘注入关键标签),但边缘SEO本身不等于解决JS渲染,它能改的多数是HTML里已经存在的标签。A/B分流是按规则把不同用户导到不同版本,边缘是常见的分流位置,但分流的目的是实验,不是修SEO。一句话区分:缓存刷新是“推正确的下去”,边缘SEO是“在路上把错的改对”,两者的事实来源关系完全不同——这一点记不住,后面所有的债都从这儿来。
边缘层到底能改什么,不能改什么?
这是落地前必须先想清楚的。能在边缘改的,本质上是“在响应离开CDN之前,不依赖业务数据就能确定的东西”;不能改或不该改的,是“需要源站的数据、状态、或业务逻辑才能正确生成的东西”。把这条原则记住,比记住任何一张能力清单都有用。
| 改动类型 | 边缘适不适合 | 为什么 | 典型翻车 |
|---|---|---|---|
| 响应头与状态码(X-Robots-Tag、缓存头、404转410) | 很适合 | 纯协议层,不碰内容,回滚干净 | 把该200的页判成404,整批掉出索引 |
| 整段重定向规则(301/302、合并域名、迁移过渡) | 很适合 | 边缘301比源站快、不回源,迁移期尤其有用 | 规则写成死循环或链式跳转,权重一路漏 |
| title、meta description、canonical、hreflang | 适合但要克制 | HTML里已有的标签,字符串替换即可 | 边缘的canonical和源站自带的两条并存,自己打架 |
| robots.txt、sitemap的小修补 | 适合 | 静态文件,边缘直接接管最省事 | 边缘版和源站版不一致,爬虫看到的飘忽不定 |
| 结构化数据(JSON-LD)注入 | 谨慎用 | 能注入,但数据准确性靠源站,边缘只是搬运 | 注入的Schema和页面可见内容对不上,被判操纵 |
| 首屏关键正文、价格库存等业务内容 | 不该用 | 需要实时业务数据,边缘没有可信数据源 | 价格滞后、内容与渲染不符,信任全失 |
| 需要登录态/个性化的内容 | 不该用 | 边缘缓存与个性化天然冲突 | A用户看到B的页面,事故级 |
“能改”不等于“该改”,结构化数据是重灾区
这张表里最容易出事的是结构化数据注入。技术上你完全可以在边缘往每个页面塞一段Product或FAQPage的JSON-LD,看起来很美——不用等开发,全站结构化数据一夜铺满。但结构化数据的生命线是“和页面可见内容一致”。边缘节点手里没有这页真实的价格、库存、评分,它只能从HTML里抠或者按模板硬填,一旦填的和用户看到的对不上,这就不是SEO优化,是在制造一个会被算法判为操纵的信号。边缘适合搬运已经正确的结构化数据(比如源站有但没输出到某些模板),不适合凭空生成需要业务数据支撑的结构化数据。这条边界,比“能不能做”重要得多。
边缘渲染是另一个话题,别和边缘改写混着上
有人会问:那能不能干脆在边缘把整个页面渲染好,JS抓取问题不就一起解决了?能,这叫边缘渲染(在边缘跑SSR或预渲染),但它的复杂度、成本、出错面,和上面那种“字符串改写”完全不是一个量级。边缘改写是改几个确定的标签,出错了影响面可控;边缘渲染是接管整个页面的生成,等于在边缘又养了一套渲染服务,缓存策略、数据新鲜度、降级方案都要重做。保哥的建议很明确:把这两件事分开决策。需要的是改几个SEO标签救急,就老老实实做轻量改写;真要解决JS渲染的系统性问题,那是渲染架构选型,应该回到源站和框架层面去定,不要顺手在边缘糊一个,那个糊出来的东西半年后没人敢动。
hreflang和canonical在边缘改,机制上有几个隐坑
这两个标签是边缘改写里出事最集中的地方,因为它们都是“声明性”的——你写错了,搜索引擎不会报错,只会默默按错的来,等你发现已经掉了一截。canonical的坑在“叠加”:很多模板源站自己已经输出了一条canonical(往往指向自己),你在边缘又注入一条指向归一化后的URL,页面就有了两条。搜索引擎遇到冲突canonical的处理是“当作弱信号、自行判断”,于是你精心设计的归一化策略直接失效,等于没做。所以边缘改canonical必须是“先删后插”或精确替换,绝不能只追加。hreflang的坑更隐蔽:它要求一组互译页面之间双向声明且自洽,边缘如果只在被访问的那个语言版本上注入hreflang,而其他语言版本的源站没有对应声明,整组hreflang因为不自洽被整体忽略——你以为全站都标了,实际一个都没生效。声明性标签的共性是“错了不报错只默默扣分”,所以边缘改它们时,验证的不是“我有没有写上”,而是“这一组页面合在一起自不自洽”,单页视角必然漏判。
状态码和响应头,是边缘改写里最干净的一类
相对地,纯协议层的改动是边缘最该承接、风险最低的一类。把一批确实没用的页面用边缘返回410而不是404(410是明确的“永久没了”,能让爬虫更快彻底放弃,回收抓取预算)、给分页或筛选页在响应头上补X-Robots-Tag控制收录、把误配的缓存头纠正过来——这些都不碰一个字节的页面内容,不存在“内容和声明对不上”的风险,回滚也彻底。如果你刚开始用边缘SEO、还没建立起信心,建议从这类协议层改动入手,它几乎不会让你踩到内容一致性的雷,又能立竿见影地解决一批抓取层面的浪费。
这里有个常被忽略的杠杆:响应头上的X-Robots-Tag和页面里meta robots等价,但它能作用于HTML之外的资源(PDF、图片、接口返回的非HTML文档),而且改它完全不需要碰页面模板。一个站积累了大量被搜索引擎抓走收录、却毫无价值的PDF和参数页,靠改模板根本够不着这些非HTML资源,而在边缘按路径规则统一打X-Robots-Tag,几分钟就能把这批垃圾从索引候选里摘掉,是回报率极高又几乎零风险的一类边缘改动。把“低风险高回报”的协议层改动先吃干净,再考虑要不要碰内容改写,这个推进顺序本身就是降低边缘债的策略。
三种落地形态,到底怎么选?
落地边缘SEO,市面上能用的形态就三类:CDN自带的边缘函数(Cloudflare Workers、Fastly Compute、亚马逊的Lambda@Edge / CloudFront Functions、阿里腾讯的边缘函数)、CDN控制台里的规则引擎(Page Rules、Transform Rules这类,不写代码、配规则)、以及你自己在源站前面架一层反向代理(Nginx/OpenResty)来做改写。三者不是谁取代谁,是按“改动复杂度”和“你掌控哪一层”来分。
| 形态 | 适合的改动 | 优点 | 代价与风险 |
|---|---|---|---|
| CDN规则引擎(Transform Rules / Page Rules) | 重定向、改响应头、改robots这类规则化改动 | 不写代码、可视化、回滚一键、最不容易出大错 | 表达力有限,复杂条件做不了;规则多了同样难维护 |
| 边缘函数(Workers / Lambda@Edge / 边缘函数) | HTML改写、条件注入、按路径批量改title/canonical | 表达力强,能做精细逻辑 | 等于在边缘养代码,要测试、要日志、要版本管理,不然就是黑箱 |
| 自建反向代理(OpenResty等) | 改动量大、要深度定制、不想被某家CDN绑死 | 完全可控、可移植 | 自己要扛可用性,多一跳延迟,运维成本最高 |
选型的真实顺序,是从“最笨的能不能解决”往上爬
很多团队一上来就写Worker,因为听起来高级。正确的顺序恰好相反:能用规则引擎配出来的,绝不写代码;非写代码不可的,把逻辑写到最小;实在是改动量大到代码也乱了,才考虑自建代理。原因很简单——这条链路上每多一层自己写的逻辑,就多一份“以后没人看得懂、没人敢删”的债。规则引擎的规则至少在控制台里看得见、能审计;一段Worker代码如果没有配套的日志和文档,三个月后对团队就是个黑箱。保哥处理过的边缘相关事故里,绝大多数不是代码写错了,是“没人知道这段逻辑存在、改别的东西时被它暗中影响了”。
别忽略供应商绑定,它是迁移期才会现形的隐性成本
选边缘函数还有一个很少被提前算的账:绑定。每家CDN的边缘函数运行时、API、配置方式都不一样,你把一套关键SEO逻辑写进某家的Worker,等于把这部分能力焊死在这家身上。平时无感,一旦因为价格、稳定性、合规要换CDN,这层逻辑要整套重写、重测、重新灰度,迁移成本里这块经常被严重低估。降低绑定的办法有两条:一是尽量把改动留在更标准化的那一侧——能用通用规则(重定向、响应头)表达的就别写专有代码,规则的概念在各家之间相对可平移,代码不行;二是如果改动量确实大、又特别在意可移植,自建反向代理反而是绑定最低的选项,代价是自己扛可用性。判断要不要写专有边缘代码时,成本不只是“现在写多久”,还要加上“将来换供应商时这段要重写一遍”的折现,很多团队只算了前一半,迁移时才发现边缘这层是搬家时最重的家具。
一个真实的改造序列长什么样
拿那个工业检测设备站的实际过程说。第一步不是写代码,是把所有要改的SEO问题列成一张表,标注每一项“源站能不能改、多久能改”,把真正卡在发版排期、且改动是规则化的,才划进边缘范围——最后进边缘的只有四类:分类页title模板补地区词、一批历史URL的301、给几个被误判的页面去掉源站硬写的noindex、统一全站canonical到带不带斜杠的一种形式。其余十几项看着也想改的,全被划回源站排期,不进边缘——这一步的克制比技术本身更决定成败,边缘范围划得越宽,后面的债越重。第二步,能用Transform Rules做的(301和响应头改写)全部用规则引擎,不碰代码。第三步,必须改HTML的(title模板、canonical),才写一段尽量短的边缘函数,且每条改写规则旁边强制写一行注释:为什么改、对应源站哪个待办、谁负责、计划什么时候下线。第四步,上线前先在一小撮路径上灰度,比对改写前后的渲染快照确认没误伤。第五步,也是最容易被跳过的一步——把这套规则登记进SEO技术债台账,标明它是临时桥、对应的源站修复才是终态。这套序列里,写代码只占很小一块,其余全是边界判断和交接,这恰恰是边缘SEO做得久不久的分水岭。
这套序列后来在另一个完全不同的场景里又验证了一遍:一个跨境消费电子品牌站做平台迁移,从老的自研系统切到新栈,URL结构整体变化,但新站上线和旧站下线之间有近两个月的并行期。这种过渡期是边缘的绝对主场——迁移期最怕的就是旧URL的权重在切换瞬间断掉,而网站迁移不掉量那篇讲的301映射、分批切换、信号承接,落地时最干净的执行位就在边缘:边缘301不回源、生效快、可按批次灰度,迁移完成后整层规则按计划一次性拆除,不在任何一边的源站留下永久痕迹。它从设计上就是一座临时桥,用完即拆,这才是边缘SEO最理直气壮的用法。和前一个案例的区别值得玩味:工业站那次边缘是“源站改不动”的无奈替代,债是被迫背的;迁移这次边缘是“本就该用临时手段过渡”的正解,用完无债。同样的技术,一个埋债一个无债,差别全在它对应的源站终态清不清楚。
为什么边缘改动迟早会变成隐性技术债?
边缘SEO最大的风险,不在技术,在认知。它天然制造一种分裂:源站代码是一套事实,线上用户和爬虫看到的是另一套事实,中间隔着一层很少有人会主动去翻的边缘逻辑。这层分裂如果没有被显式管理,时间会把它变成债,而且是带复利的债。
源站真相和线上真相,开始对不上
这是所有边缘债的根。开发去源站查“为什么这页title是这样”,查不到,因为真相在边缘。新人接手看代码,以为自己完全理解了页面,做了个改动上线,结果被边缘那层悄悄覆盖或叠加,行为完全不符合预期。边缘改写一旦上线,就意味着任何人单看源码都不再能确定线上长什么样——这个认知成本会摊到之后每一次排查、每一个新人身上,且只会越摊越厚。救急省下的那几周,会在后面以更高的利率还回来。
没人记得这条规则当初为什么加
边缘规则的典型死法不是写错,是“活太久”。当初为了过渡加的301,源站半年后其实已经修好了,但没人记得去边缘把那条桥拆掉,于是变成一条永久的、来路不明的跳转,迁移、改版时反复制造诡异问题。规则越积越多,每一条单独看都有道理,合在一起没人能讲清全貌。
有个很典型的复利样本值得讲。一个SaaS站三年里陆续在边缘加过大约二十条规则,每一条当初都有正当理由:某次活动页的临时301、某批被误判页面的noindex剥离、某次改版前的canonical兜底。三年后他们要换CDN供应商,迁移团队对着这二十条规则集体懵了——没有一条有文档,写规则的三个人走了两个,剩下那个也只记得自己加的那几条。最后只能用最笨的办法:把每条规则在测试环境逐一关掉、跑全站抓取比对、看哪些页面行为变化,再反推这条规则在保什么。这个考古工作做了三周,比当初写这二十条规则的总时间还长。这就是边缘债的复利本质——省下的是写的时候那点时间,还的时候是连本带利、且利率随时间和人员流动单调递增。解药不在技术,在纪律:每一条边缘规则从写下的第一天起,就必须带上“为什么、对应的源站终态是什么、谁负责、预计何时下线”,并且进一个会被定期回看的台账。没有这条,边缘SEO的复利债是必然的,只是早晚。
回滚、可观测、负责人,这三件套缺一不可
把边缘SEO做得可持续,技术上其实就三件事。回滚要快:每条规则都能在分钟级单独关掉,且关掉后行为可预测,绝不能是“一关全站炸”。可观测要有:边缘改了什么,要有日志或抽样能查证,最低限度也得有一个外部监控定期抓取关键页、比对边缘改写后的实际输出与预期是否一致——边缘最怕的就是悄悄改错了且没人发现。负责人要明确:每条规则挂一个人名,人走了规则要交接,不能变成组织里的无主孤魂。这三件做到,边缘SEO是利器;缺任何一件,它就是定时炸弹,区别仅在引信长短。
可观测具体怎么落地,比口号重要
“要可观测”说起来容易,落到能用的程度有几个具体动作。第一是双视角抓取比对:用一个外部监控,对一批关键页同时抓“绕过边缘的源站原始响应”和“经过边缘的最终响应”,把两者的title、canonical、hreflang、meta robots、状态码做字段级diff,任何一个字段的差异都应该能在台账里找到对应规则解释——出现解释不了的差异,就是有人在你不知情时动了边缘,或某条老规则在意外路径上误伤。第二是规则归因:监控报警时,第一时间要能回答“这个异常是哪条边缘规则造成的”,做不到归因的边缘层,排障就是大海捞针。第三是定期对账:每季度把所有边缘规则拉出来过一遍,逐条问“它对应的源站终态修好了没、修好了能不能拆”,把已经无效的桥及时拆掉。没有这套对账机制,边缘规则只增不减是热力学第二定律级别的必然——熵只会自己增加,秩序得靠人持续投入维持。
灰度和渲染快照比对,是上线前最后一道闸
边缘改写最容易出的事故,是“在测试的少数页面上看着对,铺到全站后在某些没想到的页面形态上出错”。原因是边缘改写多数靠匹配HTML里的字符串模式,而真实站点的页面模板往往比你以为的多——活动页、专题页、老版残留模板、不同语言版本,结构常常不一致,一个在主模板上完美的title替换正则,到了某个老模板上可能匹配不到、匹配多个、或匹配到错误位置。所以铺开前必须做两件事:一是按路径灰度,先放一小撮、覆盖尽量多的页面形态,不是只测首页和一个商品页就以为稳了;二是渲染快照比对,对灰度范围内的页面,抓改写前后的渲染结果做结构化比对,确认目标标签“有且只有一个、值是预期的、没有连带改坏别的”。这道闸花的时间不多,省下的是“全站title被某个边角模板带歪、一周后才从流量曲线发现”的那种大事故。
AI爬虫来了,边缘这层要不要区别对待?
这是2024年之后边缘SEO新增的一道题。除了Googlebot,现在还有一大批AI相关的抓取——做训练语料的、做实时检索增强的、用户在AI助手里点了链接由代理实时去取的,行为模式各不相同。边缘正好是这条流量的咽喉位置,能看到全部、能分流、能改写,于是一个很自然的诱惑冒出来:要不要在边缘给AI爬虫和给搜索引擎返回不一样的东西?
给不同爬虫返回不同内容,这条线不能踩
结论先放这:在边缘按客户端身份做内容层面的差异化投放,是危险动作,性质上就是隐藏式伪装,和黑帽时代“给爬虫看一套给用户看一套”没有本质区别,只是换了对象。边缘可以按客户端做的,是协议和访问策略层面的事——比如对明显是训练型抓取的UA配合IP反查后限流或拦截、给不同爬虫不同的缓存与抓取节奏——但绝不能是“同一个URL,对AI返回经过美化的内容,对用户返回另一套”。判定作弊从来不看你在哪一层做,只看“爬虫拿到的和用户拿到的是不是同一套、和页面真实内容符不符”。这条边界在AI时代不仅没松,因为可操作的位置更多了,反而更要守住。
边缘真正该为AI流量做的,是协议层的精细化
正向的用法是有的,且很有价值。AI类抓取的访问特征和传统搜索引擎不同——有的极其密集、有的只取一次、有的根本不执行JS。在边缘对它们做分客户端的策略,是合理且只能在这一层高效完成的:按已验证身份给训练型抓取与检索型抓取不同的速率与缓存策略,保护源站不被瞬时打爆;把对所有客户端一致的关键事实信息确保在不依赖JS的首屏HTML里就完整(不执行JS的抓取拿到的就是它判断你的全部依据);用响应头而非内容欺骗去表达收录与使用偏好。这些动作不制造内容分叉,只是把“同一份真实内容,按访问者的技术特征做合理的投递策略调整”,和伪装有本质区别。把这条想清楚,AI时代的边缘层就是资产;想歪了顺手做差异化投放,它就是下一轮人工处罚的入口。
什么时候该用边缘SEO,什么时候是在掩盖问题?
到这一步,技术都不难,难的是判断。同一个边缘改写,可能是教科书级的救急,也可能是在给一个本该在源站解决的烂摊子糊墙。区别它们的,是问对几个问题。
| 场景 | 判断 | 该怎么做 |
|---|---|---|
| 源站短期内确实改不了,改动规则化、可回滚、有时限 | 合理救急 | 用边缘,但登记台账、设下线条件 |
| 迁移/换域名/换框架的过渡期,需要平滑承接旧URL | 边缘的主场 | 边缘做301过渡,迁移完成后按计划拆桥 |
| 源站当天就能改,只是嫌走流程麻烦 | 在掩盖问题 | 回源站改,别给自己埋债 |
| 同一类问题反复在边缘打补丁,越补越多 | 危险信号 | 停手,根因在源站或流程,回去修根 |
| 改动需要业务数据、个性化、登录态 | 不该用边缘 | 边缘没有可信数据源,强行做必出事故 |
临时桥和永久建筑,从第一天就要分清
判断的核心就一句话:边缘SEO的健康用法几乎都是“临时桥”——它存在的意义是争取时间让源站把根因修好,而不是替源站永久承担这个职责。每写一条边缘规则前先问自己:这条规则对应的源站终态是什么?如果答不上来,说明你不是在救急,是在用边缘掩盖一个还没想清楚的问题,这种规则上线即是债。反过来,迁移过渡这类场景,边缘是当之无愧的主场——它本来就该是座临时桥,迁完拆掉,干净利落,这种用法越多越好。
交接清单:人走了,规则不能变成孤魂
最后落到最实际的——交接。边缘SEO最常见的崩盘方式,是当初写规则那个人离职了,留下一堆没文档的逻辑,谁也不敢动谁也不敢删,最后整层边缘逻辑变成一个组织都绕着走的雷区。一份够用的交接清单不复杂:每条规则的目的与对应源站终态、触发条件与影响范围、回滚方式与回滚后的预期行为、负责人与下线条件、最近一次验证的时间和结果。这份清单不是文档洁癖,它是边缘SEO能不能活过一次人员变动的唯一保险。保哥见过太多技术上做得很漂亮的边缘方案,最后死在没人交接,实在可惜。
常见问题解答
边缘SEO和CDN缓存刷新是一回事吗?
不是,而且方向相反。缓存刷新是“源站已经改对了,把正确的新版本推到边缘覆盖旧缓存”;边缘SEO是“源站没改也短期改不了,我在边缘这一层把响应改对”。一个是推正确的下去,一个是在路上把错的改对,两者的事实来源关系完全不同,混着理解就会出维护事故。
没有开发资源,能不能纯靠边缘SEO把站做好?
能救急,不能长治。边缘适合改规则化、不依赖业务数据的东西;真正的内容质量、信息架构、需要实时数据的部分,边缘碰不了。把它当长期主力,等于把一堆债一直滚着不还,迟早在某次迁移或人员变动时集中爆雷。它是争取时间的桥,不是地基。
在边缘注入结构化数据安全吗?
搬运安全,凭空生成危险。如果源站本来就有正确数据、只是某些模板没输出,边缘把它补上没问题。但如果边缘手里没有真实价格、库存、评分却按模板硬填,注入的Schema和页面可见内容对不上,这会被算法判为操纵信号,比不做还糟。
边缘改的title和源站自带的会冲突吗?
会,而且是高发坑。如果改写逻辑是“追加”而不是“替换”,页面就会出现两个title或两条canonical,搜索引擎自行取舍,结果往往不是你要的。规则必须写成精确替换并在灰度时用渲染快照确认页面里目标标签有且只有一个。
边缘SEO会不会被搜索引擎当作作弊?
技术手段本身中性,判作弊看的是结果一致性。边缘改出来的页面,如果对用户和对爬虫返回的是同一套、且和页面真实内容一致,就是正常优化。一旦用它对爬虫和用户做差异化投放,那是隐藏式伪装,性质就变了,这和在哪一层做无关。
小团队没有监控和文档能力,还能碰边缘SEO吗?
能,但只碰最安全的那一档。规则引擎里的重定向、响应头、robots小修这类协议层改动,回滚干净、不制造内容分叉,小团队完全可以用。真正要回避的是写边缘代码改HTML——那一档没有日志、灰度、台账兜底,出错你既发现不了也回不去。能力撑不起的复杂度,本身就是不该上的信号。
怎么判断我到底该不该上边缘SEO?
就问一个问题:这个SEO改动在源站要走多久流程、风险多大?当天能上线就回源站改,别埋债;卡在长排期、改动又是规则化可回滚的,才用边缘,并且从第一天就登记台账、写明对应的源站终态和下线条件。判断标准永远是流程成本,不是技术新鲜感。
本文标题:《边缘SEO是什么?在CDN边缘改SEO的原理与落地形态》
本文链接:https://zhangwenbao.com/edge-seo-cdn-worker-no-deploy-implementation.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0