公众号文章抓取后灌进NotebookLM,我把吃灰收藏盘活成了SEO竞品情报库

本文目录
- 收藏夹为什么是SEO人的"情报坟场"?
- 卡住你的不是没时间,是反馈链路太长
- 第一步:竞品公众号文章怎么稳定抓下来?
- 抓公众号有哪些坑和红线?
- 同样一堆资料,为什么不直接喂给ChatGPT?
- 资料灌进去之后,第一个动作该做什么?
- 问题问不对,工具再强也白费:给SEO人的提问清单
- Discover Sources:怎么让它替你补齐找不全的一手英文资料?
- Studio九种形态,SEO人真正用得上哪几个?
- 数据表格:怎么把10篇竞品综述压成一张可溯源对比表?
- Audio Overview:让吵架的SEO观点替你吵一架
- 我的每周SEO情报工作流长什么样?
- 这套流程的边界在哪?哪些它做不了?
- 写在最后:把反馈链路缩短到7天
- 常见问题解答
- 权威参考资料
摘要:做SEO的人收藏夹最狠——竞品公众号、Google官方文档、英文研究报告,堆成山却从来不看。我把一套研究工作流跑通了:用Claude Code跑trafilatura脚本把竞品公众号稳定抓成干净Markdown,灌进NotebookLM,靠引用回溯零幻觉地问、对比、听。吃灰的收藏第一次变成可查询、可溯源的竞品情报底座。核心不是多读,是把"收藏到能用"的反馈链路从半年缩短到7天。
保哥做SEO二十多年,有个职业病:看到一篇好文章,手比脑子快,先收藏再说。竞品独立站的策略拆解、Google算法更新的官方解读、外贸大号公众号里那些藏着真货的长文,全进收藏夹。
前阵子我翻了一下自己的微信收藏,光2026年标记"必读"的SEO干货就40多篇。一篇没打开过。每一篇当时都说服了自己"这个对项目有用",然后集体烂在那儿。
这篇文章,就是我花一个下午打磨、现在每周都在用的那套流程。从稳定抓取竞品公众号文章,到灌进NotebookLM,再到一步步用它越来越深的功能,把一堆吃灰资料真正盘活成能查、能问、能溯源的研究底座。手把手,一次讲透。
收藏夹为什么是SEO人的"情报坟场"?
我先说个扎心的判断:对做SEO、做外贸独立站的人来说,收藏夹不是知识库,是坟场。
而且我们这行收藏得比谁都狠。原因很简单——SEO是个信息差生意。竞品上了什么新落地页、Google哪条政策悄悄改了措辞、某个AI搜索又开始影响点击,谁先消化谁先动手。所以看到一篇像样的拆解,第一反应永远是"先存下来,回头细看"。
问题就出在那个"回头"。它从来不来。
我后来想明白了,烦的不是没读,是骗了自己半年。点收藏那一下,心里以为自己已经掌握了竞品的打法,其实只是把焦虑搬了个家——从"我还不了解对手"搬到"我迟早会研究透对手"。然后那个"迟早"就一直不来,对手的排名却一天天往上走。
更要命的是,SEO资料有时效。你收藏的那篇"AI Overviews优化指南",半年后Google把触发逻辑改了,你那篇收藏连同你以为存下来的"认知",一起过期。AI Overviews对自然流量的冲击变化有多快,凡是盯过这块的人都有体会。资料躺在收藏夹里不消化,等于没收藏。
卡住你的不是没时间,是反馈链路太长
很多人把"收藏不看"归因于忙。我不这么看。
真正的卡点是反馈链路太长。从"我点了收藏"到"这条信息真正进入我的决策",中间隔着一道几乎不可能跨过的鸿沟:你得专门腾出整块时间,把一篇5000字的竞品长文从头读到尾,还要边读边记,读完还得自己归纳出"对我有什么用"。这套动作的启动成本太高了,高到你永远在等一个"等我有空"的完美时刻。
那个完美时刻不存在。于是收藏越攒越多,链路越来越长,最后整个系统瘫痪。
我这套流程要解决的,不是"逼自己多读书",而是把这条链路从"半年都跨不过去"压缩到"7天内一定兑现"。手段不是更强的意志力,是更短的反馈回路——让消化一篇竞品文章的成本,从"专门读两小时"降到"散步时随口问一句"。
下面我把那套流程,按由浅入深拆开,每一步都对应一个你现在就有的真实场景。
第一步:竞品公众号文章怎么稳定抓下来?
事情得从把文章抠出来说起。公众号有很强的反爬机制,所以这是整套流程里技术含量最高的一步。但说出来你可能不信,我实际只花了15分钟。
第一个动作老老实实手动:把想研究的竞品公众号文章挨个点开,复制链接,黏到一个 links.md 文件里。40多个链接,大概10分钟。这一步没有捷径,也不需要捷径——你本来就只想研究自己筛过的这几篇,不是要爬人家整个号。
剩下的5分钟,我没自己写脚本。把 links.md 丢给Claude Code,说了一句话:
把links.md里所有URL抠出来,挨个抓网页正文,用trafilatura转成干净的Markdown,每篇按"文章标题_编号.md"存成单独文件,装好依赖直接跑。
回车。Claude Code自己装了trafilatura,写完脚本,跑完,40多个 .md 文件躺在文件夹里。我从头到尾没碰键盘上一行Python。如果你好奇它大概写了什么,核心就十来行:
#!/usr/bin/env python3
import re, sys, trafilatura
text = open(sys.argv[1], encoding="utf-8").read()
urls = re.findall(r"https?://[^\s)\]]+", text)
for i, url in enumerate(urls, 1):
html = trafilatura.fetch_url(url)
md = trafilatura.extract(html, output_format="markdown") or ""
open(f"{i:02d}.md", "w", encoding="utf-8").write(md)
print(f"[{i}/{len(urls)}] {url}")
说实话,这段你不用看懂。把上面那句话直接丢给Claude Code就完事了,丢给别的AI编程助手也一样,是个Agent就能干。如果你想把这类小任务用得更顺手,我之前专门写过用了一年Claude Code后只留下的6个高频命令,配合着看效率更高。
这就是2026年用AI的正确姿势:以前是"得先学会Python才能批处理一坨数据",现在是"把任务描述清楚扔给AI,自己看结果"。这十几行脚本省下来的不是十几行代码,是"我得先去学爬虫"那道挡了无数SEO人的门槛。trafilatura为什么能把网页正文抽得这么干净、还能直接吐Markdown,它的官方快速上手文档里讲得很清楚,感兴趣可以翻一翻。
为什么是Markdown不是PDF?我一开始也犹豫。NotebookLM两个格式都吃,但Markdown上传后它的"引用回溯"明显更准——回答时能精确引到第几段,PDF经常只能引到一整页。对SEO这种讲究"这句话到底出自哪、可不可信"的活儿,段落级溯源比页面级值钱太多。这个差别后面会反复用到。
抓公众号有哪些坑和红线?
这一节源文没讲,但我觉得比脚本本身更重要——尤其对靠内容吃饭的SEO人,合规这根弦得绷紧。
先说技术坑。公众号有几篇可能抓不下来:一是需要登录态才能看的,fetch_url 拿到的是登录墙;二是正文几乎全是图片的"图片号",trafilatura抽文字会抽到一堆空;三是被平台临时风控了,连续抓太快会返回异常。我的做法是抓完扫一眼每个 .md 的字数,明显偏短的几篇手动复制正文补上,不跟反爬机制硬碰硬,10分钟搞定的事不值得跟它死磕。
再说红线,这一条我必须讲清楚:
| 能做 | 不能做 |
|---|---|
| 抓自己筛选过、用于学习研究的少量文章 | 批量爬别人整个号当数据源 |
| 把抓来的内容喂给自己看、做笔记、提炼方法 | 把抓来的原文改头换面二次发布、洗成自己的稿 |
| 引用观点时注明出处、链回原文 | 把别人的图、数据、案例直接搬进自己的页面 |
说白了,这套流程是给你"读得更快"用的,不是给你"抄得更省事"用的。保哥做SEO二十多年,见过太多站靠搬运短暂起量、又被Google一轮原创性更新打回原形。你抓竞品文章是为了看懂对手怎么想,从而做出比他更好的东西——这是研究;把对手的文章换几个词发出去——这是找死。这条边界,比任何脚本都该刻在心里。
守住这条线,资料库就准备好了。下面进入真正的主角。
同样一堆资料,为什么不直接喂给ChatGPT?
有人会问:抓都抓下来了,直接丢给ChatGPT让它总结不就行了,何必多一个NotebookLM?
这正是我要重点讲的地方,也是NotebookLM跟通用聊天工具最大的区别——引用回溯。
我之前用通用大模型处理这类场景,最大的不爽是它会编造看起来很顺的回答。你问"这几篇竞品文章里关于外链策略的共识是什么",它给你一段四平八稳的话,但你根本没法验证哪句是真从你的资料里来的、哪句是模型自己脑补的通用知识。对SEO来说这是致命的:一个被幻觉出来的"Google官方建议",足以让你把整个季度的策略带偏。
NotebookLM把这个问题在产品层面解掉了。它的每一句回答,都只基于你上传的资料,而且后面跟着引用编号,像 [3][12] 这种。点一下编号,左侧资料面板自动跳到第3篇文章,对应那一整段高亮。也就是说,它告诉你的每句话,都能溯源到原文具体哪一段。
更妙的是反向信号:如果某个判断它死活不肯说,多半是因为你给的资料里确实没有支撑。这本身就是有用的情报——它在告诉你"这块是认知盲区,对手也没人写透"。
一句话,ChatGPT是"什么都敢答但你不敢全信",NotebookLM是"只答有据可查的,但答的你能拿去用"。对要拿数据和事实下决策的SEO人,后者才是研究工具该有的样子。
资料灌进去之后,第一个动作该做什么?
打开NotebookLM,新建一个笔记本,把抓好的Markdown全拖进左侧的Sources面板。面板唰唰跳出来,开始转圈,几十秒后每个文件前面一个绿点,上传完成。
先了解几个边界:单个source容量上限50万字、200MB,一篇公众号文章再长也撑不破;支持PDF、Word、Markdown、txt、网页URL(直接贴链接它自己抓)、YouTube(自动转字幕)、音频(自动转写)。Markdown优先,前面讲过,引用回溯精度高一档。
上传完先别急着用花哨功能。右侧那个对话框,直接问。我灌进去一批竞品独立站的SEO拆解后,问的第一个问题是:
这几篇里,关于"AI搜索时代独立站还要不要堆内容"的核心分歧是什么?分歧到底在哪?
不到10秒,一段大约400字的浓缩回来了,每个判断后面都跟着引用编号。我点开 [5],左侧直接跳到第5篇,对应段落整段高亮。等于它替你把几篇长文里散落的观点抽出来、对齐、还标好了出处。
这一步什么配置都没改,纯默认。光是"直接问加点引用看原文"这一条,已经能解决八成"我囤了一堆资料但读不完"的场景。至于问什么——了解全貌、提炼对方的关键词布局逻辑、找出你和对手的策略差异,凡是你想得到的都能问。但能问,不等于会问。
问题问不对,工具再强也白费:给SEO人的提问清单
NotebookLM再聪明,也只是个被动应答的助理。你问得敷衍,它答得也敷衍。我一开始踩过最大的坑,就是只会问"帮我总结一下"——它给你一段四平八稳的摘要,看着全,其实没用,因为这种问法等于没给它方向。
做SEO研究,提问得带着目的、带着角度。下面这几类问法是我日常用得最顺手的,你可以直接抄去改:
| 你想搞清楚的 | 该怎么问 |
|---|---|
| 对手的内容策略 | 这几篇竞品文章里,他们反复强调的内容打法是什么?有没有互相矛盾的地方? |
| 自己的认知盲区 | 关于本地SEO,这批资料里哪些角度被反复提到、哪些几乎没人讲透? |
| 一手数据清单 | 把文中所有提到的具体数字和它们的出处,列成一张清单。 |
| 观点分歧 | 关于要不要继续重仓外链,不同作者的立场和各自论据分别是什么? |
| 落地动作 | 综合这些资料,给一个刚上线的出海独立站,列出未来30天最该做的5件SEO动作。 |
这里头藏着三个让答案质量翻倍的小技巧。第一,逼它列清单、别让它写散文。同样问竞品的外链来源,"列成表格、每条标出处"比"介绍一下"得到的东西可用十倍——散文你还得自己拆,清单直接能进行动表。
第二,凡是涉及数字、结论,习惯性追一句"出处是哪篇、原话怎么说的"。NotebookLM会乖乖把引用编号摆出来,你点过去核一眼,假数据当场现形。SEO决策最怕的就是拿着一个二手转载、早就过时的数字当真。
第三,用"对比""分歧""矛盾"这类词去逼它找差异。它默认倾向于求同、给你一个和谐的综述,但对SEO人有价值的往往是分歧——对手们在哪件事上吵起来了,哪件事上达成了你没注意的共识。把问题往"差异"上引,比问"共同点"信息量大得多。
Discover Sources:怎么让它替你补齐找不全的一手英文资料?
有个常被忽视的功能叫Discover Sources,对做国际SEO、出海独立站的人尤其值钱。
你给它一个主题词,它会自己去网上搜相关的一手资料,补进你的Sources列表。我研究AI Overviews优化时,让它围绕这个主题自动补料,它一口气补了好几篇英文的官方说明和第三方研究进来——这些是手动一篇篇搜绝对搜不全的。它会一次给最多10条推荐,每条带一句"为什么跟你的主题相关"的标注,具体怎么用,NotebookLM官方的Discover Sources说明里有详细步骤。
我的经验是,做SEO研究最该用它补的,是一手官方文档。比如你研究站点结构,与其看十篇二手解读,不如让它顺手把 Google官方的SEO入门指南这类原始资料拉进来,跟你抓的中文竞品文章放在一起对照。中文大号怎么转译官方说法、哪里转译跑偏了、哪里加了私货,一对照全看出来了。
半年的"以后再看",第一次被一次性管理起来。每一个加载好的文件,对应当时那个"我以后会研究透对手"的承诺,现在它们终于不再只是承诺。
Studio九种形态,SEO人真正用得上哪几个?
聊几轮之后,看右下角的Studio面板,这是NotebookLM真正的工作台。一键就能把同一批资料转成多种形态。我不打算把九种全吹一遍,只挑做SEO真正用得上的几个,按场景告诉你怎么配。
- 思维导图:可点击展开的主题树。我那批竞品资料被它自动归到几个分支,比如"内容策略""技术SEO""外链打法"。这是我找认知盲区的主力工具——哪条主线下面只挂着一两篇,说明这块对手也没研究透,恰好是你的机会缺口。
- 简报(Briefing Doc):约1500字的结构化摘要,浓度最高,要给团队同步一个领域的全貌用这个。
- 常见问题(FAQ):自动从资料里抽问答,覆盖核心争论。"快速过一遍"的最佳形态。
- 学习指南:章节梳理加重点提炼,系统补一个陌生领域(比如你刚接触本地SEO)用这个。
- 时间线:按时序抽取事件,最适合理顺一个概念的演变。比如想看AI Overviews从去年到今年怎么一步步影响点击,把相关报道丢进去生成时间线,脉络一目了然。
- 数据表格:从一堆非结构化文字里抽出结构化对比表。这个是SEO竞品分析的硬核武器,下一节单独讲。
- 音频概览:杀手功能,单独成章讲。
我自己的搭配习惯,给你抄作业:
| 场景 | 搭配 |
|---|---|
| 快速吃透一个SEO领域综述 | 简报 + 思维导图 |
| 系统学一个陌生新方向 | 学习指南 + 测验 |
| 给同事同步一份情报 | FAQ + 简报 |
| 跨多篇竞品做策略对比 | 数据表格 |
| 通勤路上消化对立观点 | 时间线 + 音频概览 |
到这一步都还是"点一下出结果"的级别,没碰任何高级配置。如果你只想把吃灰收藏快速盘活,到这儿基本够用了。
数据表格:怎么把10篇竞品综述压成一张可溯源对比表?
这个功能我要重点夸,因为它直接对应SEO里最费时的活儿之一——竞品横向对比。
以前做竞品分析,我得开十个标签页,一篇篇翻,手动在Excel里填"这家目标词怎么布的、外链来源什么结构、内容多久更一次、有没有上Schema"。光填表就半天,填完还经常忘了某个数据是从哪篇看来的。
现在把这十篇竞品综述灌进NotebookLM,让它生成一张数据表格,指定要抽的维度:目标关键词布局、外链来源结构、内容更新频率、结构化数据使用情况。它唰一下把十家拉成一张表,关键是——每个格子里都带着回溯引用。你看到"A家每周更3篇",点一下就跳到原文那句话,不用担心是它编的。
这张表拉出来,对手的打法差异就摊在你面前了。接下来怎么把这些差异变成你自己的行动清单,我之前写过四层逆向拆透竞品、变成行动清单的完整框架,数据表格正好是那套框架最省力的第一步。
这里有个读表的诀窍:最该盯的不是"他们都做了什么",而是那些大多数对手都没填、或者填得很弱的格子。比如十家里有八家压根没上产品结构化数据,这就是一块没人抢的技术SEO洼地;又比如所有人内容更新都卡在每月一两篇,你把频率和质量提上去,就有机会靠新鲜度甩开他们。竞品分析真正值钱的洞察,往往藏在那一列列空白里,而不是密密麻麻填满的地方。
2026年起Studio还多了一件事:每次生成不再覆盖前一份。同一张表你可以基于不同资料子集、不同指令生成好几个版本,全留在历史里。这意味着Studio不只是即时生成器,更是一个迭代过的情报归档。
Audio Overview:让吵架的SEO观点替你吵一架
Audio Overview也在Studio面板里,但它配得上单独一章,是NotebookLM真正的杀手功能。
我做的第一件事,不是让它总结,是让它吵架。
点Audio Overview,默认生成一段约10分钟的双主持人对话播客。但默认不是它最强的形态。点旁边的Customize,可以做三件事:指定只用哪几篇资料、写自定义生成指令、选时长(从约2分钟到最长约50分钟的深度版)。
保哥的收藏里,正好有三篇立场完全对立的文章,主题都是"AI搜索到底会不会杀死SEO"。一篇某海外工程师写的"自然流量已死,赶紧all in投放";一篇国内一位独立站老炮写的"零点击是伪命题,被看见的方式变了而已";第三篇更狠,标题大意是"别慌,Google自己的总访问量这几年还涨了,缩水的是没价值的内容站"。
这三篇我半年前各自收藏时都点了头。三个时刻三个我,从没串过。
我让NotebookLM只用这三篇做资料,自定义指令写成"两位主持人针对'AI搜索是不是SEO末日'做13分钟对抗性辩论,每人必须引用具体观点"。戴上耳机出门散步,回来时听完了——我听到了自己半年来对这个话题的全部摇摆,被两个声音替我吵了个明白。比自己闷头读三篇,留下的东西多得多。最关键的是,散步这段时间本来就是空的,它没多占我一分钟正经工作时间,却把三篇打架的长文嚼碎喂给了我。
Audio Overview已经支持50多种语言,把默认声音切到中文,同样的方式能生成中文播客,语气节奏都符合中文习惯。2026年还出了视频版概览,自动配幻灯片和字幕,把那段辩论变成视频后,视觉锚定让信息留存又高一档,适合发给团队。
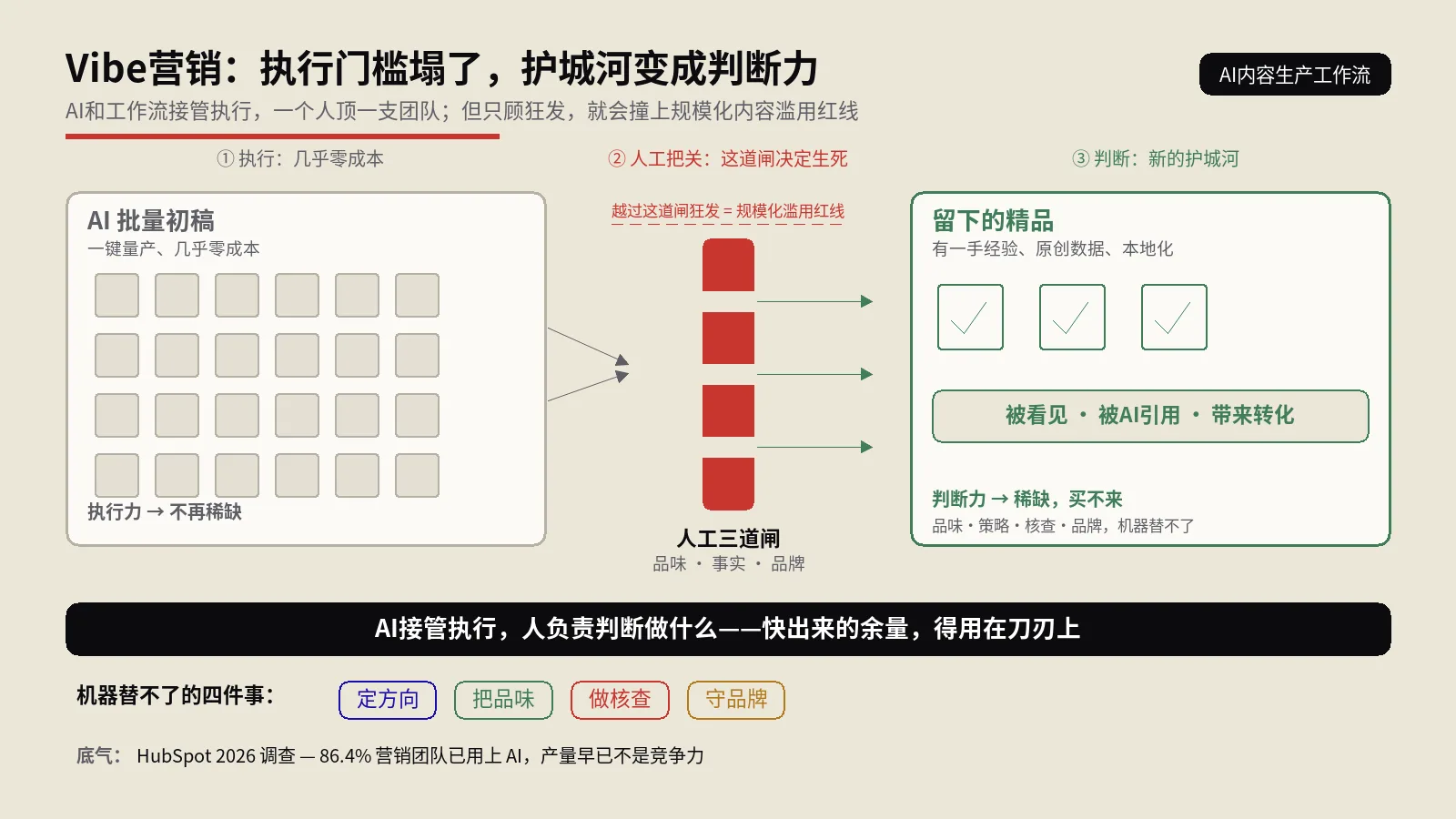
说到底,Audio Overview不是帮你省读的时间,是把几篇互不相干、甚至互相打架的孤岛文章,接成一场有来有回的对话。你那些对立的收藏,第一次产生了化学反应。这种把碎片观点拼成完整认知的活儿,跟AI内容生产工作流是接力关系——前者帮你把别人的东西吃透,后者才轮到你产出自己的。
我的每周SEO情报工作流长什么样?
把上面这套打通之后,我现在每周日下午,固定半小时,做一件事。
把这一周新收的竞品文章和行业资料导出成Markdown(还是那句话丢给Claude Code),直接塞进对应的笔记本。整个动作不超过10分钟。
工作日里突然想到一个问题——比如"上次那家竞品提到的内链做法,到底跟我们差在哪"——打开笔记本直接问,看引用回原文,10秒解决,不用再满收藏夹翻。
周末有空要写一篇综述或者定下个季度策略,就在Studio里先生成简报加思维导图看全局,再用数据表格把竞品差异拉成表,最后用学习指南或测验把核心知识点固化下来。读过的东西,第一次真的留在了脑子里,而不是停在"我收藏过"。
不用再担心收藏吃灰了。因为收藏从"我以后会看",变成了"我下周日会被一起处理"——一个明确的、最多7天就兑现的承诺。每周30分钟,换来一周对竞品动向的清爽掌控。
为什么非得固定到周日下午、固定半小时?因为靠"想起来再弄"那套,等于又把链路交还给意志力,迟早回到收藏吃灰的老路。把它焊死成一个雷打不动的时段,研究这件事才从"需要下决心的大工程",退化成刷牙一样的日常动作。反馈链路能不能真正缩短,关键从来不在工具多强,而在这个动作会不会自动发生。
这套流程的边界在哪?哪些它做不了?
我从不卖"银弹"。这套流程很顺手,但有清晰的边界,认不清边界比不用还危险。
第一,它只活在你给的资料里。你问它"我这个词今天排第几",它一脸茫然——它没有实时数据,它的世界就是你上传的那几十个文件。要看实时排名、抓取日志、最新收录,老老实实回GSC和你的工具。它负责帮你想清楚"该往哪个方向使劲",但"现在到底使到什么程度",只有实时数据能回答,这两件事千万别混为一谈。
第二,料错它也跟着错。引用回溯能保证它没编,但保证不了原文是对的。你抓进去一篇数据本身就过时的竞品文,它会忠实地引用那个过时数字。涉及关键数据,单一来源永远要交叉验证,这一点AI帮不了你。
第三,它不替你做判断。它能告诉你三篇文章吵什么、各自论据是什么,但"我们到底该跟哪派",这个决策永远是你的。工具负责把信息嚼碎摆好,下咽和消化还得自己来。
第四,一个现实问题:NotebookLM是Google的产品,国内访问需要自己解决网络可达性。如果条件不便,这套"抓取加引用回溯"的思路同样成立,你可以把抓好的Markdown喂给国内能用的、同样支持引用溯源的工具,方法论是通用的,工具只是壳。
认清这四条边界,你才不会把它当成不会犯错的神,而是当成一个嘴严、肯标出处、但不替你拿主意的研究助理。这恰恰是它最该有的样子。
写在最后:把反馈链路缩短到7天
写到这儿,我真正想说的,其实不是"怎么抓公众号"。那只是动作。
我们这行最熟练的句子之一,叫"下次一定"。收藏一篇竞品拆解,"下次一定研究";关注一个不错的外贸号,"下次一定追";存了一套GEO课程,"下次一定学"。但"下次"从来不会自己来。它不是承诺,是自我安慰,是把"我还没动手"翻译成"我准备动手",好让心里那个"我还在进步"的错觉再撑一晚。
收藏夹之所以是坟场,不是因为文章不好,是因为我们一直在用"收藏"这个动作,替代"研究"这个动作。手指点一下心就安了,对手却没在等你。
NotebookLM替不了你研究。但它给了一个兜底——一个让"读完"真的发生的兜底。我这篇做的,就是帮你把竞品的认知取出来,再放进你自己的脑子里。
学习和研究这件事,其实没那么神圣。它需要的不是更多的决心,是更短的反馈链路。把链路缩短到7天,然后,去建你的第一个笔记本。
常见问题解答
抓取竞品公众号文章,会不会有法律或封号风险?
只抓自己筛选过、用于个人学习研究的少量文章,不批量爬整个号、不二次发布,风险很低。真正的红线是把抓来的内容改头换面当原创发出去——那不只是封号问题,更会被Google的原创性更新打击。我的原则很清楚:抓来是为了看懂对手、做出更好的东西,不是为了搬运。
不会写Python,能跑通抓取这一步吗?
完全可以。整个抓取脚本你一行都不用自己写,把链接整理进一个文本文件,连同一句自然语言指令丢给Claude Code这类AI编程助手,它会自己装依赖、写脚本、跑完。你只负责看结果。这正是2026年用AI的方式——描述清楚任务,而不是亲手实现。
NotebookLM和直接用ChatGPT总结,到底差在哪?
最大的差别是引用回溯。NotebookLM的每句回答只基于你上传的资料,且标注来源、可点击跳回原文段落;ChatGPT会调用通用知识填充,容易产生看似合理实则编造的内容,你无法验证。对要拿数据下决策的SEO人,可溯源这一点格外要紧。
为什么强调用Markdown而不是PDF上传?
NotebookLM两种格式都支持,但Markdown的引用回溯精度更高——它能精确引用到具体段落,PDF往往只能引到一整页。做SEO研究讲究"这句话出自哪、可不可信",段落级溯源比页面级实用得多。
国内用不了NotebookLM怎么办?
NotebookLM是Google产品,国内访问需自行解决网络可达性。如果不便,这套"抓取干净Markdown加引用回溯研究"的方法论本身是通用的,可以换成国内能用、同样支持来源溯源的工具,核心是流程而非具体软件。
本文标题:《公众号文章抓取后灌进NotebookLM,我把吃灰收藏盘活成了SEO竞品情报库》
本文链接:https://zhangwenbao.com/wechat-article-scraping-notebooklm-seo-research-workflow.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0