增量测试是什么?别让本来就会买的人冒领广告功劳,预算才花得对
本文目录
- 点击率涨了,老板为什么还是问这钱花得值不值?
- 增量到底是什么?拿一个搜品牌词的老客户讲明白
- 归因、增量测试、营销组合模型,到底各管什么?
- 增量测试为什么从锦上添花变成了刚需?
- 一个增量测试是怎么设计出来的?
- 第一种方法:用户层holdout怎么跑?
- 第二种方法:地理实验为什么在Cookie之后更稳?
- 幽灵广告是怎么把对照组的成本压下来的?
- 品牌广告一直说不清效果,增量测试怎么给它正名?
- iROAS和普通ROAS差在哪?读结果别读错
- 样本量不够会怎样?为什么很多增量测试白跑了
- 测出来不显著,是广告没用还是测试没做对?
- 哪些坑会让增量测试的结论失真?
- 增量测试、A/B测试、归因,什么时候该用哪个?
- 增量测试该多久跑一次?怎么排进一年的衡量节奏?
- 出海便携榨汁机:一次地理holdout把投流预算砍对地方
- 增量的思路怎么和SEO、GEO、AI搜索对接?
- 想跑第一个增量测试,先把这几件事做对
- 常见问题解答
摘要:做投流和数据的人迟早会撞上同一道坎:后台的ROAS明明很漂亮,老板却问这笔钱到底花得值不值,你答不上来。问题出在归因只会把已经发生的转化分给某个广告,却回答不了一个更要命的问题——这单生意,没有这条广告它会不会照样成?这就是增量测试(Incrementality testing)要解决的事。它不靠追踪个人,而是把人群随机分成看得到广告的实验组和看不到广告的对照组,用两组转化的差值,把那些"本来就会发生"的销售剔出去,留下的才是广告真正撬动的新增价值。这篇不堆Google后台的按钮,而是把增量这件事讲透:增量到底是什么、它和归因与营销组合模型怎么分工、三种实验方法(用户层holdout、地理实验、品牌提升)各适合什么场景、iROAS和普通ROAS差在哪、样本量不够为什么白跑、测出来不显著该怎么读,最后用一个出海便携榨汁机品牌把投流预算砍对地方的复盘把整套思路串起来。一句话先撂这儿:归因告诉你功劳记在谁头上,增量测试才告诉你这功劳是不是广告挣来的。
点击率涨了,老板为什么还是问这钱花得值不值?
很多投手都经历过这样的对话。月底复盘,后台ROAS做到5、6,数字好看得很,老板盯着报表问一句:你把这部分预算砍掉,销售额会掉多少?空气瞬间安静。
问题不在投手不努力,在于手里的工具答不了这个问题。曝光、点击、转化这些指标,记录的是发生了什么,却没法告诉你如果当初没投这条广告,结果会不会一样。报表里那一笔笔归到广告名下的转化,有多少是广告真正促成的,有多少是用户本来就要买、只是顺手点了一下广告?这两者在报表上长得一模一样,但对预算决策来说是天壤之别。
这就是为什么越来越多成熟的出海品牌开始把增量测试当成必修课。它换了一个提问方式:不问这笔转化该算谁的功劳,而是问广告到底让用户多做了些什么。搞清楚这一点,预算才知道该往哪儿加、从哪儿撤。
增量到底是什么?拿一个搜品牌词的老客户讲明白
先看一个再常见不过的场景。一位老客户准备回购你的产品,他在Google上搜了你的品牌词,看到排在最上面的搜索广告,点进去,下单。
传统的末次点击归因会怎么算?这一单100%的功劳,归给那条品牌词搜索广告。报表上它ROAS高得发亮。
但换个角度想:这位用户本来就是你的忠实客户,他主动搜了品牌词,说明购买意愿已经拉满。就算没有那条广告,他大概率也会点下面紧挨着的自然搜索结果,照样进官网、照样下单。那么这条广告带来的新增转化,其实接近于零。
这就是增量(Incrementality)的核心:把那些本来就会发生的转化识别出来、剔除掉,只计算广告真正多带来的那部分价值。一句话,增量回答的是广告有没有让用户多买、早买、买更多,而不是它有没有恰好记录下一笔本来就会发生的购买。想清楚这层,你就会明白为什么有些渠道ROAS高得离谱却不敢加预算——它可能只是在给本来就会成交的人发优惠券、冒领功劳而已。
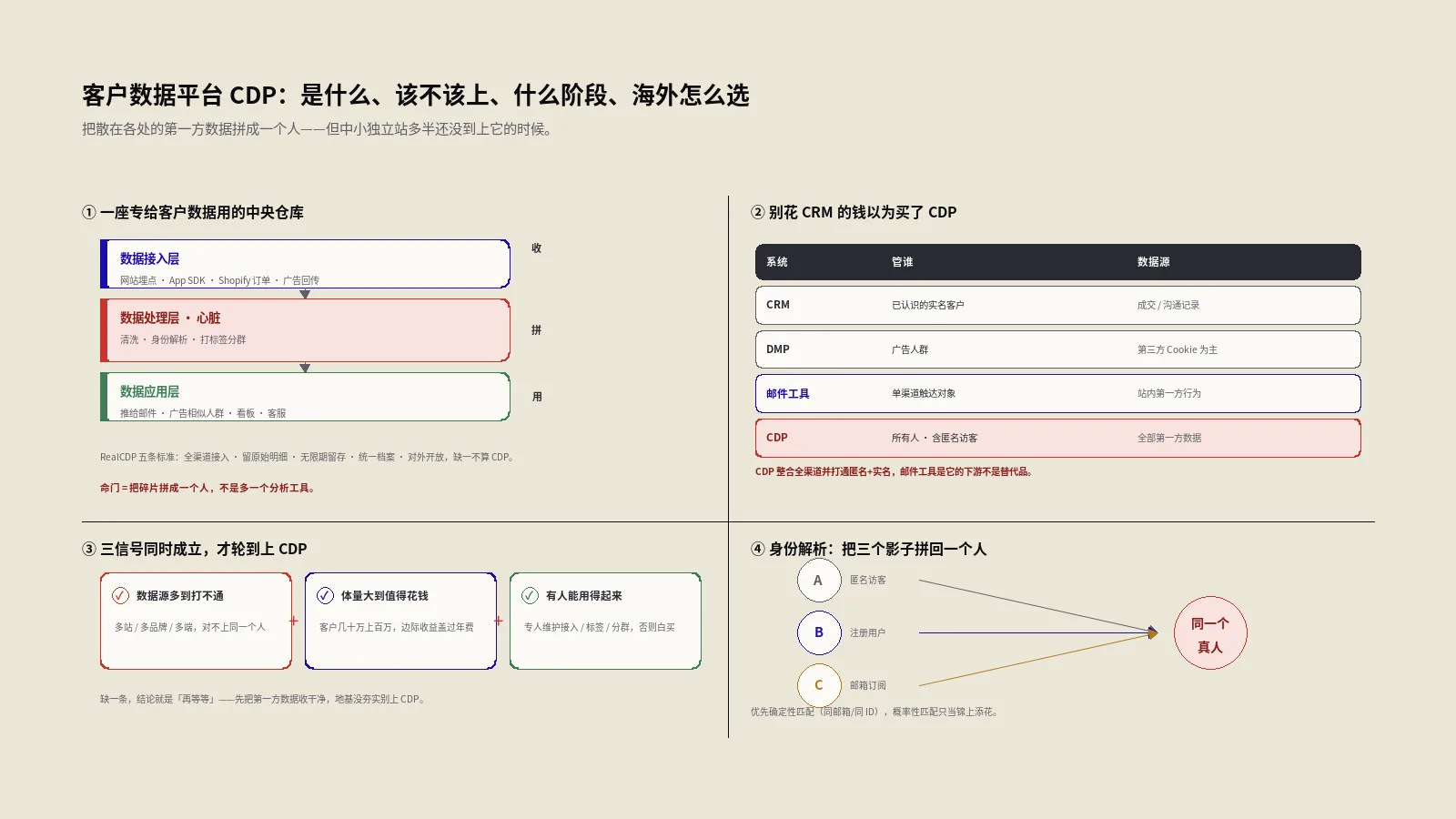
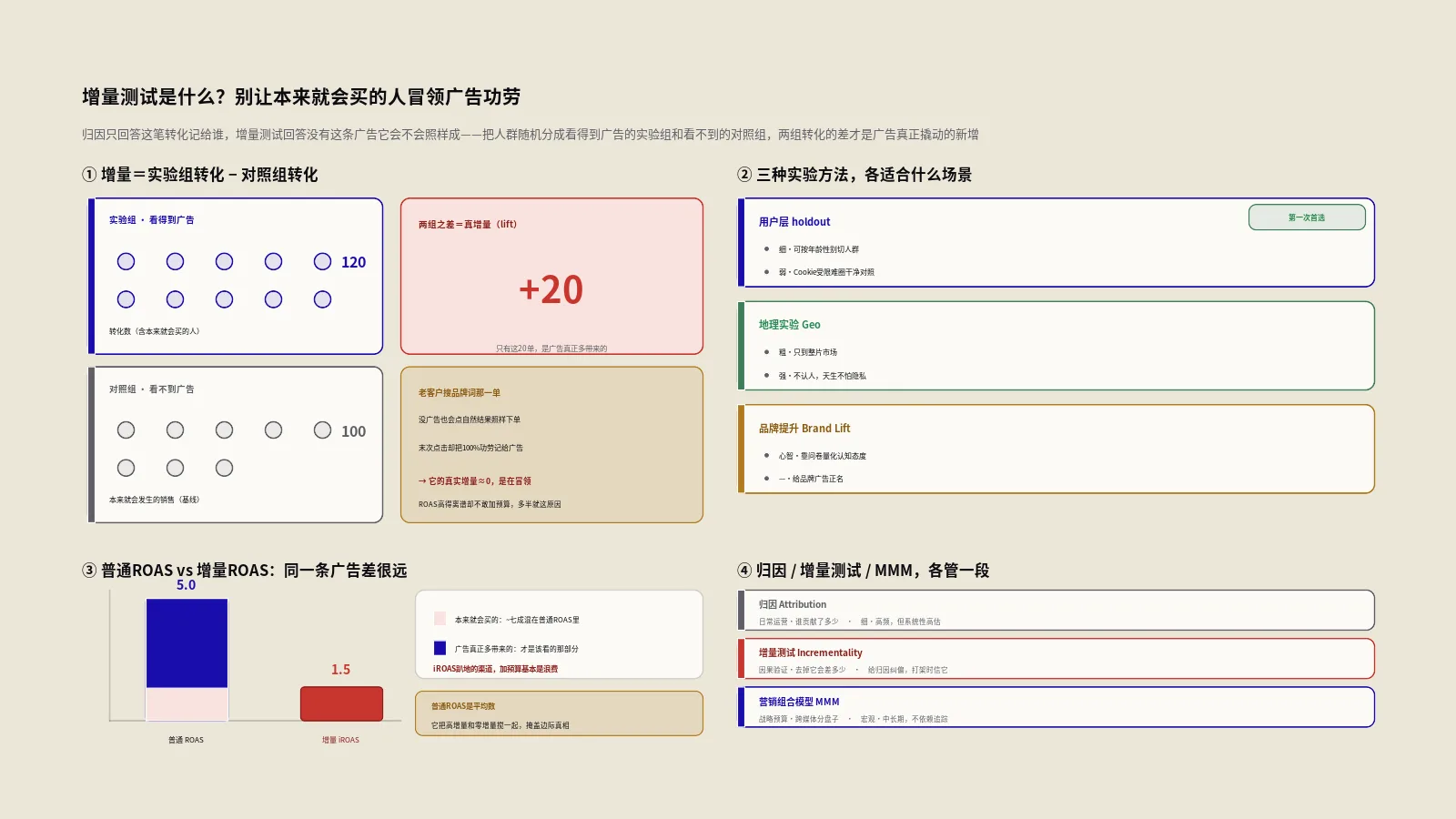
归因、增量测试、营销组合模型,到底各管什么?
很多人一听增量测试,第一反应是这跟我做的归因有什么区别?这里得把三件衡量工具的分工掰清楚,它们不是互相替代,而是各管一段、相辅相成。
归因(Attribution),管的是日常运营。它分析一次转化路径上各个广告触点谁贡献了多少,用来做每天每周的渠道和广告系列优化。它的强项是颗粒度细、能落到具体广告,弱点是它只会在你已经看得见的触点之间分蛋糕,回答不了这块蛋糕本来存不存在。至于多触点归因模型到底该选末次、线性还是数据驱动,这是另一道独立的题,保哥在多触点归因模型怎么选才不被最后一次点击骗走预算里专门拆过,这里不展开。
增量测试(Incrementality testing),管的是因果验证。它通过科学实验,验证某个广告活动到底有没有带来因果性的增长。它不关心功劳怎么分,只关心去掉这个广告,结果会差多少。它是用来给归因纠偏的——当归因说某渠道贡献巨大、增量测试却说它增量趋近于零时,该信后者。
营销组合模型(MMM,Marketing Mix Modeling),管的是战略预算。它分析历史销售额、各媒体投入、季节性等宏观数据,帮你做跨媒体的高阶预算分配,看的是中长期趋势。它不依赖个体追踪,适合在隐私收紧的大环境下做年度盘子的划分。
把三者串起来就是一个闭环:MMM在宏观上分盘子,归因在微观上做日常优化,增量测试在中间用实验给两者提供真实的因果校准。三条腿缺一条,预算决策都会瘸。
增量测试为什么从锦上添花变成了刚需?
过去,增量测试常被当成进阶玩家才碰的奢侈品——又费钱又费事,中小卖家敬而远之。但这两年风向变了,它正在变成现代营销绕不过去的基础设施。最大的推手,是隐私和Cookie。
第三方Cookie的逐步淘汰,让传统那套基于个体追踪的归因越来越测不准。iOS的隐私新政一出,多少投手的Meta后台ROAS直接失真,这事保哥在Meta广告iOS 14归因失真怎么救里复盘过。当你没法再稳定地追踪单个用户从看到广告到下单的完整链路时,依赖这条链路的归因自然就站不住了。
而增量测试恰恰不吃这一套。它做的是群体对比的因果推断——只看实验组和对照组在结果上的差异,根本不需要知道具体是哪个人因为哪条广告下了单。不依赖个体追踪,只关注群体结果差异,这让它成为一种面向Cookie之后时代的、可持续的衡量方式。换句话说,别人的工具在隐私收紧里越来越糊,它反而越来越显出价值。
除了扛得住隐私变化,它还顺手解决了一个老大难:品牌广告的效果终于能量化了。视频、展示这类品牌广告,长期被诟病说不清效果、抢不到预算,增量测试里的品牌提升实验,能把品牌认知、购买意向这些虚的心智指标变成可衡量的数字,让品牌广告拿到它该有的地位。
一个增量测试是怎么设计出来的?
抛开平台的具体按钮,任何一个像样的增量测试,骨架都是同一套实验逻辑。理解了骨架,你在Google、Meta还是第三方工具里跑,心里都有数。
第一步,立一个清楚的假设。不是泛泛地问广告有没有用,而是具体到:我怀疑投在品牌词上的这部分搜索预算,增量很低。假设越具体,测试越好设计、结论越好落地。
第二步,选分组方式。核心就一件事——制造一个看不到广告的对照组,再拿它跟看得到广告的实验组比。分组可以在用户层做(随机让一部分人看不到你的广告),也可以在地理层做(整片区域停投当对照)。
第三步,估样本量和周期。对照组太小、测试时间太短,差异会淹没在噪音里,测了等于白测。这一步决定了你能不能检测出真实存在的增量,下面会专门讲。
第四步,跑实验,期间别手痒去改投放、改预算、改创意,任何中途变动都会污染结论。
第五步,读结果。看两组转化的差值是否显著,算出增量转化和增量ROAS(iROAS),再决定这部分预算是加、是减还是维持。整个流程下来,你拿到的不是又一个被高估的好看数字,而是一个经得起追问的因果答案。
第一种方法:用户层holdout怎么跑?
最直观的一种,是在用户层面做holdout。平台从你的目标人群里随机扣下一小批人,让他们看不到你的广告,这批人就成了对照组;其余正常看到广告的是实验组。两组在同一时间窗里的转化差异,就是广告带来的增量。
以Google为例,Google Ads官方对Conversion Lift的说明讲得很直接:转化提升是一种增量衡量工具,用来测算购买、网站访问以及其他转化中,有多少是直接由人们看到你的广告所驱动的。它把受众分成看到广告的实验组和看不到广告的对照组,两组转化的差,就是所谓的提升(lift)——也就是因为广告的存在而多出来的那部分转化。因为两组之间唯一系统性的差别就是有没有被广告触达,任何显著的结果差异,都能被因果性地归到广告头上。
用户层holdout的好处是颗粒度细,能按年龄、性别这类用户属性切开看不同人群的增量。它的天然短板也很明显:在Cookie和跨设备追踪受限的环境里,准确地把同一个人圈进对照组、并确认他确实没被任何渠道的广告触达,越来越难。这就引出了第二种更扛打的方法。
第二种方法:地理实验为什么在Cookie之后更稳?
当个体追踪靠不住时,干脆把颗粒度抬高一层——不分人,分地区。地理实验(Geo experiment)的思路是:挑出若干个市场区域停投广告当对照组,其余结构相近的区域正常投放当实验组,比较两组的销售或转化走势,差出来的就是增量。它根本不需要知道任何单个用户的身份,因此天生不怕隐私限制。
这套方法这两年被做得相当成熟,Meta甚至把它开源了。Meta开源的GeoLift就是代表,它的官方定义是:GeoLift是一套端到端的地理实验方法论,基于合成控制法(Synthetic Control Methods)来衡量广告活动真正的增量效果(Lift)。所谓合成控制,简单说就是用一组没投广告的区域,加权拟合出一个本来如果不投广告、实验区域大概会长成什么样的虚拟对照,再拿真实结果去比这个反事实基准,差额就是增量。它还能帮你科学地挑选哪些市场适合拿来做测试,而不是拍脑袋选区。
地理实验的代价是颗粒度粗——它告诉你某渠道在整个市场上有没有增量,但没法细到具体某类人群。对大多数想搞清楚某条渠道值不值得继续砸钱的出海品牌来说,这个颗粒度足够用了,而且它在Cookie淘汰的大背景下尤其耐打。很多预算量级不算特别大的品牌,第一次跑增量测试,反而更适合从地理实验起步。
幽灵广告是怎么把对照组的成本压下来的?
做对照组有个绕不开的麻烦:怎么知道对照组里的人,在没有你广告的情况下,本来会怎么做?早期一种笨办法是给对照组投放公益广告(PSA)占位,但这既花钱又不精准。学界后来给出了一个更聪明的解法,叫幽灵广告(Ghost Ads)。
这套方法出自一篇拿过营销学界大奖的论文。Johnson、Lewis与Nubbemeyer发表在《市场营销研究杂志》(2017年)上的Ghost Ads研究,开篇就点破了整件事的本质:要衡量广告的效果,营销者必须知道消费者在没看到广告的情况下会如何行动。幽灵广告的做法,是在随机实验中识别出对照组里那些本来应该被广告触达、但实际被系统挡下的人,把他们当作实验组里被触达者的对照镜像。
相比公益广告占位和意向性A/B测试,论文指出幽灵广告能显著降低实验成本、提升衡量精度、给出真正具有战略意义的基准,并且能跟实时优化投放的现代广告平台兼容。论文里那次零售重定向实验,测出网站访问增加17.2%、购买增加10.5%,而拿到同等精度的成本,比传统方法至少低一个数量级。你不需要自己去实现这套算法——主流平台的增量测试工具底层用的就是这类思路,但理解它能帮你看懂为什么平台的对照组是这么搭的、结论为什么可信。
品牌广告一直说不清效果,增量测试怎么给它正名?
前面提了几次品牌提升,这里把增量测试常见的三种类型一并说清。它们分别卡在用户决策链路的不同环节:品牌认知、搜索兴趣、实际转化。
品牌提升(Brand Lift),问的是广告有没有改变受众对品牌的认知和态度。它通常靠问卷实现,比较看过广告和没看过广告的两组人对你熟悉哪些品牌、更喜欢哪个品牌这类问题的回答差异,把品牌知名度、好感度、购买意愿这些心智指标量化出来。
搜索提升(Search Lift),问的是广告有没有激发用户去主动搜索。它监测实验组看过广告后,在搜索引擎上搜你品牌词、产品词的频率,是否显著高于对照组。这里有个实操要点:选关键词要选具体到能锁定你、但又有一定搜索量的词。太宽泛的词(比如只搜你的品类大词)人人都在搜,淹没了广告的影响;太冷门的长尾词又没什么量,测不出显著差异。
转化提升(Conversion Lift),就是前面讲的那种,直接测实际购买、加购、注册等转化的增量,是最贴近生意结果的一种。
三种从认知到兴趣到转化层层递进,让原本一笔糊涂账的品牌广告,第一次有了能拿去申请预算的硬证据。
iROAS和普通ROAS差在哪?读结果别读错
跑完测试读结果,最容易栽的跟头是把增量ROAS(iROAS)当成普通ROAS来看。这两个数差得可能很远,混了就全乱套。
普通ROAS,分子是归因到这条广告名下的全部转化金额,里面混着大量本来就会发生的销售。iROAS,分子只算增量转化金额——也就是剔掉本来就会买的那部分之后,广告真正多带来的销售。同一条广告,普通ROAS可能是5,iROAS可能只有1.5,因为它名下七成的转化,没有广告也会发生。
这个差值才是预算决策真正该看的东西。一条普通ROAS很高、iROAS却趴在地上的渠道,说明它大部分时间在给本来就会成交的人重复曝光,加预算基本是浪费;反过来,一条普通ROAS看着平庸、iROAS却很健康的渠道,才是真正在帮你拉新增长、值得加码的地方。看错这个数,很可能把钱越投越歪还不自知。
这也解释了一个让很多投手困惑的现象:为什么某些渠道你越加预算,整体的实际营收增长却越不成比例?因为你加的钱大部分流向了那些iROAS很低的曝光,边际增量在快速衰减。普通ROAS是个平均数,它把高增量和零增量的转化搅在一起算,掩盖了边际上的真相。只有把增量单拎出来看,你才知道下一块钱投进去,到底还能不能换回真实的新增,而不是又一次给老客户发了张他本来就会用的优惠券。
样本量不够会怎样?为什么很多增量测试白跑了
增量测试翻车,十有八九不是方法错,而是样本量和周期没估够。增量本身往往是个不大的数——广告带来的真实新增可能只占总转化的一两成,要在一堆自然波动的噪音里把这一两成的差异稳稳地测出来,对照组的规模和测试时长必须撑得住。
对照组太小,两组的差异就会被随机波动盖过去,你看到的不显著,可能只是没测出来,不代表真的没增量。测试时间太短,又容易撞上某次促销、某个节日的扰动,把短期波动误当成广告效果。这背后是一整套统计功效和最小可检测效应的计算,跟做A/B测试估样本量是同一套底层逻辑,保哥在A/B测试样本量怎么算里给过三个能直接套的公式,做增量测试前值得先过一遍。
实操上记住一条朴素的原则:宁可少跑几个测试,把每个测试的对照组和周期给够,也别贪多铺一堆样本量不足的测试,最后拿一堆似是而非、谁也不敢信的结论去拍预算。
测出来不显著,是广告没用还是测试没做对?
很多人跑完测试看到结果不显著就慌了,要么草率下结论说这渠道没用、赶紧砍,要么干脆不信、当没测过。这两种反应都不对。不显著是个需要拆开看的信号。
先排查测试本身。对照组够不够大?周期够不够长?测试期间有没有撞上促销、断货、大改投放这类污染?把这些问号一个个排掉,再谈结论。很多不显著,根子在测试没做扎实,而不在广告。
排干净了还是不显著,那才是个有价值的结论——它在告诉你,在你能投入的样本量和周期下,这个广告的增量小到测不出来。对预算来说,这往往等价于增量很有限,这部分钱该考虑优化方向或挪去别处了。换个心态看,一个干净的不显著,比一个被高估的好看ROAS有用得多,它至少帮你避免了继续往一个没有真实增量的渠道里砸钱。读懂不显著,是用好增量测试的分水岭。
哪些坑会让增量测试的结论失真?
除了样本量,还有几个隐蔽的坑专门毁结论,跑之前最好心里有数。
外溢效应(Spillover)。地理实验里,如果对照区域的人通过口碑、社交、跨区物流接触到了你实验区域的广告影响,两组就不再干净,增量会被低估。挑测试区域时要尽量选相互独立、不容易串味的市场。
季节性污染。测试期撞上黑五、大促、节日,整体盘子被外部因素推着走,很容易把季节红利误算成广告增量。要么避开这些窗口,要么确保对照组同样经历了这些波动来对冲。
对照组被偷偷触达。用户层holdout里,对照组的人如果在别的渠道、别的设备上还是看到了你的广告,对照就破了。这也是Cookie淘汰后用户层方法越来越难做干净的原因。
新鲜度效应(Novelty)。一个新创意刚上线时的提升,可能只是因为新鲜,跑长了会衰减。测试周期太短,容易把一时的新鲜当成持续的增量。
这些坑的共同点是,它们都让对照组不再是一个干净的反事实。守住对照组的纯净,是增量测试一切结论的地基。
增量测试、A/B测试、归因,什么时候该用哪个?
这几个工具经常被混着叫,但用错场景就会得出误导性的结论。给一张简单的对照,帮你快速对号入座。
想知道某个渠道或活动到底带来了多少真实新增、值不值得继续投——用增量测试。它回答的是因果性的有没有用、有多大用。
想在两个具体版本之间分高下,比如落地页A和B哪个转化高、CTA按钮红色还是绿色更好——用A/B测试。它比的是变体之间的相对优劣,背后的实验设计和统计功效逻辑,保哥在SEO实验设计与统计功效里讲过单因素隔离怎么做才干净。
想做日常的渠道优化、看每天每周各触点的贡献排序——用归因。它颗粒度细、响应快,但记得它的数会系统性高估,关键决策要拿增量测试来校准。
一句话记忆:归因做日常排序,A/B测试比版本优劣,增量测试验真实因果。三者配合,而不是拿一个去替所有。
增量测试该多久跑一次?怎么排进一年的衡量节奏?
很多人把增量测试当成一锤子买卖:跑一次、拿个结论、然后束之高阁。这是浪费。渠道的增量不是一成不变的,它会随着市场饱和度、季节、竞争对手动作、创意疲劳一起漂移。今天测出来某渠道增量健康,半年后可能因为投得太狠、人群被打透,增量已经悄悄掉下来了。所以增量测试该是一套有节奏的常态动作,而不是临时起意的项目。
给一个能落地的节奏参考。日常每天每周,靠归因看渠道排序、做投放微调,这是高频低成本的动作。每个季度,挑一两个预算占比最大、或者你最拿不准的渠道,跑一轮增量测试做因果校准,重点盯品牌词、重定向这些最容易ROAS虚高的地方。每年,用营销组合模型从宏观上重新审视一次整体预算盘子怎么切,再拿这一年里积累的几次增量测试结论去喂它、校准它的参数。三个频率叠在一起,就构成了一套从日常优化到战略分配的完整衡量节奏。
至于一轮测试要花多久,没有铁定数字,但有个朴素的下限逻辑:周期至少要覆盖你产品一个完整的购买决策周期,外加足够长的观察窗口让增量从噪音里浮出来。客单价低、决策快的快消品,可能两三周就够;客单价高、用户要反复比价的耐用品,可能得拉到一个月甚至更长。宁可一次给够时间,也别为了快拿结论而把周期压到测不准。把增量测试排进固定的衡量日历,它才能真正持续地帮你把预算钉在有真实价值的地方。
出海便携榨汁机:一次地理holdout把投流预算砍对地方
讲个把这套思路用起来的复盘。一个做便携榨汁机的出海品牌,主攻北美,投流以Meta和Google为主。后台ROAS常年好看,品牌词搜索广告的ROAS尤其高,团队一直把相当一部分预算压在品牌词和重定向上,逻辑是这两块ROAS最高、最划算。
问题是,整体增长卡住了。钱投得不少,新客却起不来,复盘时谁也说不清到底是哪块预算在真正拉动生意。团队决定不再只看后台归因,跑一次地理实验。他们把结构相近的几个州配成两组,在对照组那批州里,暂停了品牌词搜索广告投放,其余照旧,跑了一个完整的、避开大促的周期。
结果挺扎心:停掉品牌词广告的对照州,整体销售几乎没掉——大部分本来要买的人,照样通过自然搜索找到了官网下单。换句话说,那部分ROAS高得发亮的品牌词预算,iROAS趴在地上,大半是在给本来就会买的人冒领功劳。而另一头,他们顺势测了拉新向的prospecting广告,对照州的销售明显低于实验州,证明这部分才在实打实地带来新增。
拿着这个结论,团队把品牌词那块的预算大幅压缩、挪给被验证有真实增量的拉新渠道,整体的真实新增客户开始往上走,而总投放额没怎么变。这里没有编任何夸张的业绩数字,机制本身就够说明问题:如果他们继续只信后台ROAS,那笔钱会一直歪着投下去,自己还以为投得很精。增量测试做的,就是把这层窗户纸捅破。
增量的思路怎么和SEO、GEO、AI搜索对接?
增量测试看着是投流的事,但它那套反事实思维,对做SEO和GEO的人同样是醍醐灌顶。
做SEO最常见的自欺,是看到某批页面有自然流量、有转化,就认定SEO很值。可换个增量的问法:如果这些词我不做SEO,这些用户会不会通过别的入口照样找到我、照样转化?品牌词的自然排名尤其要这么追问——很多品牌词流量本来就是你的,做不做SEO它都在。把增量思维带进SEO复盘,你会更冷静地区分哪些是真正靠内容和排名抢来的新增量,哪些只是记录了本来就属于你的流量。
到了GEO和AI搜索时代,这层更要紧。AI概览和各类AI搜索带来的访问,后台常常一片空白、难以追踪,正是因为传统归因在零点击场景里彻底失灵。这时候群体对比、看整体增量的思路,反而比纠结单次点击归因更现实。你没法精确追踪每一次AI引用带来的转化,但你可以通过有没有被AI引用的前后对比、不同策略组合的整体差异,去逼近它的真实增量。衡量的底层逻辑是相通的:别问这笔转化记给谁,问没有它结果会差多少。
想跑第一个增量测试,先把这几件事做对
如果你看到这儿想动手,别一上来就追求高大上。增量测试的价值不在于一次做得多漂亮,而在于它能不能成为你预算决策里一个稳定的纠偏机制。从一个能落地的小测试起步,把流程跑通、把团队对结果的解读口径统一,比纠结方法论是否完美重要得多。
第一,挑一个你最怀疑在浪费钱的渠道当突破口。最经典的就是品牌词搜索广告和重定向,这两块往往ROAS虚高、最值得第一个验。
第二,量级不大就先选地理实验。它不依赖个体追踪、不怕隐私限制,对第一次做的团队更友好,也更容易跑干净。
第三,先把对照组和周期给够,再开跑。宁可这次只测一件事,也要把它测扎实,一个可信的结论顶十个似是而非的数字。
第四,结果出来无论显著与否,都先排查测试本身有没有被污染,再下决策。把不显著也当成有价值的信号去读。
第五,把增量当成长期习惯而不是一次性项目。渠道的增量会随市场、季节、竞争变化,定期复测,预算分配才能一直踩在真实价值上。一句话收尾:归因让你知道功劳记给谁,增量测试让你知道这功劳到底是不是广告挣来的——后者,才是花对钱的前提。
常见问题解答
增量测试和A/B测试到底是不是一回事?
不是。A/B测试比的是两个具体版本之间的相对优劣,比如落地页A和B哪个转化高,它默认这个东西要做,只是问哪个版本更好。增量测试问的是更上游的问题——这个广告或渠道到底要不要做、它带来的因果性新增有多少。一个比版本,一个验存在,背后虽然都是对照实验的逻辑,但回答的是完全不同的问题。
我预算不大,跑增量测试是不是太奢侈了?
过去确实是,但现在门槛降了不少。地理实验这类不依赖个体追踪的方法,对中小品牌相当友好,Meta还把GeoLift开源了。更现实的算法是:你与其继续把一大笔钱押在一个从没验证过真实增量的渠道上,不如先花一个测试周期搞清楚这钱值不值。测试的成本,往往远低于你在一个零增量渠道上持续浪费的预算。
后台ROAS已经很高了,为什么还要费劲测增量?
恰恰是ROAS越高的渠道越值得测。后台ROAS高,很可能是因为它名下混着大量本来就会发生的转化,尤其是品牌词和重定向。增量ROAS(iROAS)会告诉你剔掉这部分之后,广告真正多带来了多少。很多团队就是栽在只看普通ROAS,把大把预算压在iROAS其实趴在地上的渠道上,自己还以为投得很精明。
对照组让一部分人或地区看不到广告,会不会损失销售?
短期会损失一点点,这是做因果实验必须付的学费。但要算总账:你用一个测试周期里很小的一点机会成本,换来的是对整个渠道增量的清晰判断,避免在错误的地方长期浪费大得多的预算。把对照组的代价当成一次性的诊断费,而不是纯损失,账就算得过来了。
测出来结果不显著,是不是说明这个广告完全没用?
先别急着下这个结论。不显著有两种可能:一种是测试本身没做扎实,对照组太小、周期太短、或者被促销断货污染了,这种要先修测试;另一种是排查干净后依然不显著,那才说明在你的样本量和周期下,这个广告的增量小到测不出来,对预算而言往往等价于增量有限、该优化或挪走。读懂这两者的区别,比测试本身更重要。
增量测试能不能完全取代归因?
不能,它们是分工不是替代。归因颗粒度细、响应快,适合做每天每周的渠道优化和日常排序;增量测试成本高、周期长,适合隔一段时间做一次重大决策的因果校准。正确姿势是用归因跑日常,用增量测试定期给归因纠偏——当两者打架时,相信增量测试。再加上营销组合模型管宏观预算,三件套配合才是完整的衡量体系。
本文标题:《增量测试是什么?别让本来就会买的人冒领广告功劳,预算才花得对》
本文链接:https://zhangwenbao.com/incrementality-testing-marketing-measurement-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0