A/B测试样本量怎么算:DTC独立站避免假胜利的3个公式
本文目录
- 为什么80% 的A/B测试胜利都是假阳?
- 样本量算错背后藏着哪5个统计陷阱?
- 公式1:经典Z检验样本量公式怎么用?
- 公式2:Sequential序贯检验为何能边跑边停?
- 公式3:Bayesian A/B检验和Frequentist区别在哪?
- 3套公式怎么按DTC场景挑?
- 样本量计算前必须诚实回答哪4个问题?
- DTC独立站90天A/B实验路线图怎么排?
- 常见问题解答
- Q1:小流量DTC站(日UV < 500)能跑A/B测试吗?
- Q2:Sequential检验和multi-armed bandit有什么区别?
- Q3:黑五、Prime Day之前能开新实验吗?
- Q4:能不能用ChatGPT帮我算样本量?
- Q5:实验跑满了但结果不显著,要不要再多跑一周?
- Q6:A/B测试和multivariate(MVT)应该怎么取舍?
- Q7:实验失败或无效的结果要不要给老板汇报?
- 权威参考资料
摘要:保哥见过太多DTC团队跑A/B跑出+18%加车率的喜报,三个月后业绩纹丝不动——根源不是文案,是样本量从一开始就算错。客单80美元、日UV 1000的母婴店套经典Z检验,单组最少要跑62天才有效,等不及的人提前看仪表盘看到的全是噪音。Sequential、Bayesian、Z三个公式按流量与决策风险分场景用,才不会被假阳骗。
为什么80% 的A/B测试胜利都是假阳?
保哥前段时间帮一家做婴儿益生菌的DTC独立站复盘,团队的实验仪表盘看起来非常漂亮——过去九十天跑了七场A/B,五场显著、三场+18%以上,剩下两场+9%。看上去PDP(产品详情页)换文案就能让销售翻倍,CRO团队当月奖金到位。
可三个月后再回看,整体加车率不仅没涨,还掉了两个点。原因不复杂:那五场所谓"+18%显著胜利"里,事后用Sequential重算样本量,四场的实际功效(statistical power)不到40%——意味着这些"胜利"里至少一半是噪音被误识别为信号。团队把没用的版本上线了,旧版本永远没机会回来。
这不是个案。Ronny Kohavi(前Microsoft实验平台负责人)在 HBR那篇The Surprising Power of Online Experiments 里复盘的内部统计显示,Bing与Office等产品上线实验里只有大约10%-20% 真正带来正向业务指标,其余要么flat要么负向。DTC独立站的样本量比Bing小得多,但跑A/B的人却往往更乐观——这就是假阳的温床。
要看清这事,得先理清三个统计学参数:
- alpha(α,显著性水平):你愿意接受的假阳率。行业默认5%,意思是"如果没有真实差异,我有5%概率会被噪音骗,把变体当胜利上线"。
- power(1-β,统计功效):你能检出真实差异的概率。默认80%,意思是"如果变体真的好10%,我有80%概率能识别出来"。
- MDE(Minimum Detectable Effect,最小可检测提升):你愿意为之投入实验时间的最小业务增量。比如转化率从2.5%涨到2.75%(相对+10%)。
这三者绑死样本量。任何一项松动,结果就开始可疑。最常见的松动是power——很多DTC团队为了赶节奏,把power偷偷调到60%,再加上早停,假阳率从5%飙到30%-40%都不奇怪。
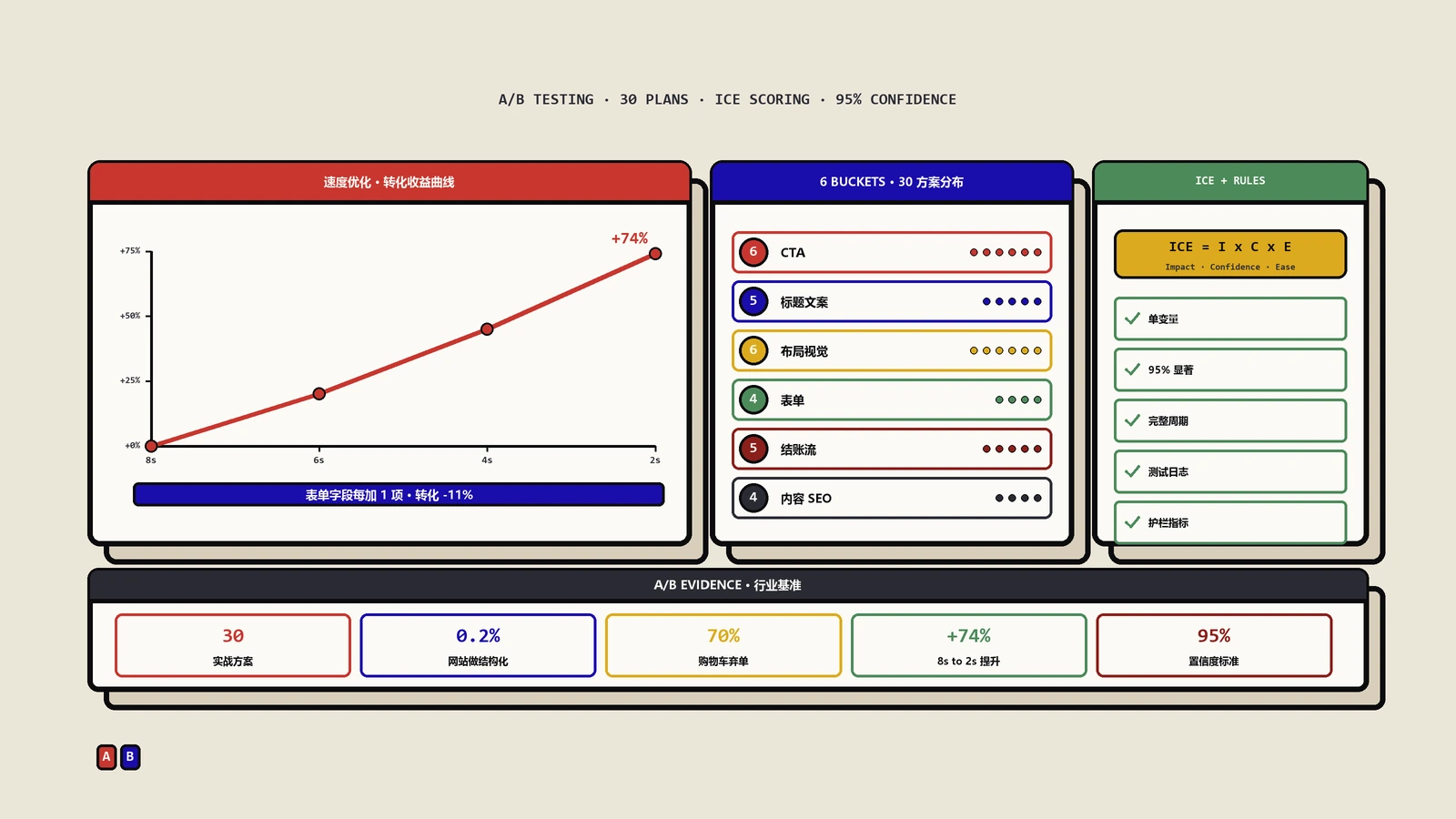
来个反直觉数字:一家日订单30单(约月900单)、转化率2.5%的独立站,按alpha 5%、power 80%、MDE相对10%算下来,单个A/B实验单组需要约31000单UV——折算下来,一年最多跑4场真正有统计意义的实验。你刷X上各种"我一周做了8个A/B测试"的炫耀帖,要么是数据造假,要么是统计噪音被当成捷报。
DTC团队不是不能跑A/B,是必须接受"低流量站点高频实验=高频假阳"这个物理约束。逃出物理约束的唯一办法,是换公式而不是换文案。这也是为什么结账页放弃率诊断那类问题,文案侧再怎么A/B都救不回来——根因不在文案,在数据样本本身。
样本量算错背后藏着哪5个统计陷阱?
样本量算错只是入口,真正的死亡陷阱在实验执行阶段。按出场频率排序,DTC站最常踩的5个坑如下。
陷阱1:peeking(早停偷看)让alpha失控。
这是DTC实验里最常见的死法。Evan Miller 2014年那篇经典文 How Not to Run an A/B Test 拿数学算过:本来alpha=5%、power=80% 的实验,如果你每天看一次结果、看到显著就停手,实际假阳率会涨到14%-26%。看得越勤,假阳越多。
为什么?每一次peek都是一次独立的假设检验,每次都付alpha代价。看5次,相当于做了5个独立检验,family-wise error rate按1-(1-0.05)^5≈22.6%。看10次,错误率升到40%。这跟你跑赌场,每盘下注5%输的概率不一样——盘数越多,输的总概率越高。
保哥见过最离谱的一个客户,CRO团队每两小时刷一次Optimizely仪表盘。重算之后给团队定了铁律:Sequential框架以外,谁也不许在样本量达成前看结果,仪表盘锁后台,只发周报。
陷阱2:多重比较稀释显著性。
你在一个实验里同时看加车率、结账率、AOV、回访率、邮件打开率5个指标。每个指标alpha=5%,看似各自显著,但至少一个出现假阳的概率高达23%。这就是为什么"多个指标都微涨就上线"是个统计骗局。
正确做法:实验前pre-register(预登记)一个主指标(primary metric)和最多两个secondary。其它指标只用来诊断,不参与决策。多变体(A/B/C/D 4个版本)同期实验也吃这个亏,要么把alpha按Bonferroni除以变体数(5%÷3≈1.67%),要么换Bayesian。
陷阱3:异常值不剔除。
DTC站经常被一个"客单5000美元的批发订单"砸进AOV实验里,把方差搞飞。结果就是变体看起来+120%,其实是一个outlier在搞鬼。这种事黑五前后特别多——你的零售客户群里混进了一两个团购买家,统计上就翻车。
实战规则:连续变量(AOV、停留时长、页面深度)一定要winsorize(缩尾),把1%与99%分位以外的值压回分位边界。或者直接用Mann-Whitney U这种rank-based非参检验,对异常值天然鲁棒。GA 4里没有内置缩尾,要落BigQuery后SQL处理。
陷阱4:季节性混淆 + 周中/周末效应。
跑A/B跨了双11、Black Friday、退货政策调整或者邮件群发节点,实验组和对照组的"日内分布"开始失衡,结果失真。最经典的踩坑:周一上线变体B,到下周一停手——变体A完整覆盖一个周末,B少了周日下半场。结账率本来就周日晚上飙升,B就被低估了。
防御:实验周期至少覆盖完整1-2个业务周(含完整周末)。重大节点前后48小时不开始新实验,宁可推迟。可逆改动可以跨季节继续跑,不可逆改动季节前一个月就开始freeze。
陷阱5:受众污染(contamination)。
DTC独立站经常有同一用户多设备访问、邮件+广告+SEO多触点回访的情况。如果A/B分流是按session而不是按user,同一个用户可能在变体A加车、变体B结账,数据就脏了。
修复:分流必须user-level(用hashed user_id或device fingerprint),不是session-level。Klaviyo自动化流跟广告投放重叠时,把同时被两套规则触达的用户在分析阶段单列剔除(或单列分析)。GA 4 + BigQuery + Stape服务器端跟踪是把跨设备拉直的最稳基础设施,没这层user_id拼接,A/B分流污染基本无解。
这5个陷阱有一个共同点——没有一个能靠"换文案、换图片"修复,只能靠样本量公式 + 实验设计修复。这就是下面三套公式要解决的事。
公式1:经典Z检验样本量公式怎么用?
第一个公式是frequentist(频率学派)的经典做法,叫two-proportion Z-test sample size。对DTC来说,最常用的版本是这样的:
n_per_group = (Z_{α/2} + Z_β)² × [p₁(1-p₁) + p₂(1-p₂)] / (p₂ - p₁)²
人话翻译:
- p₁是对照组(A)的基线转化率(baseline conversion rate)
- p₂是变体(B)你预期达到的转化率
- Z_{α/2}是alpha=5%(双尾)对应的临界值,约1.96
- Z_β是power=80%对应的临界值,约0.84
来个实际计算。母婴DTC独立站当前PDP加车率2.5%(=0.025),你打算测试新文案,期望相对提升10%(即p₂=0.0275,绝对提升0.25pp):
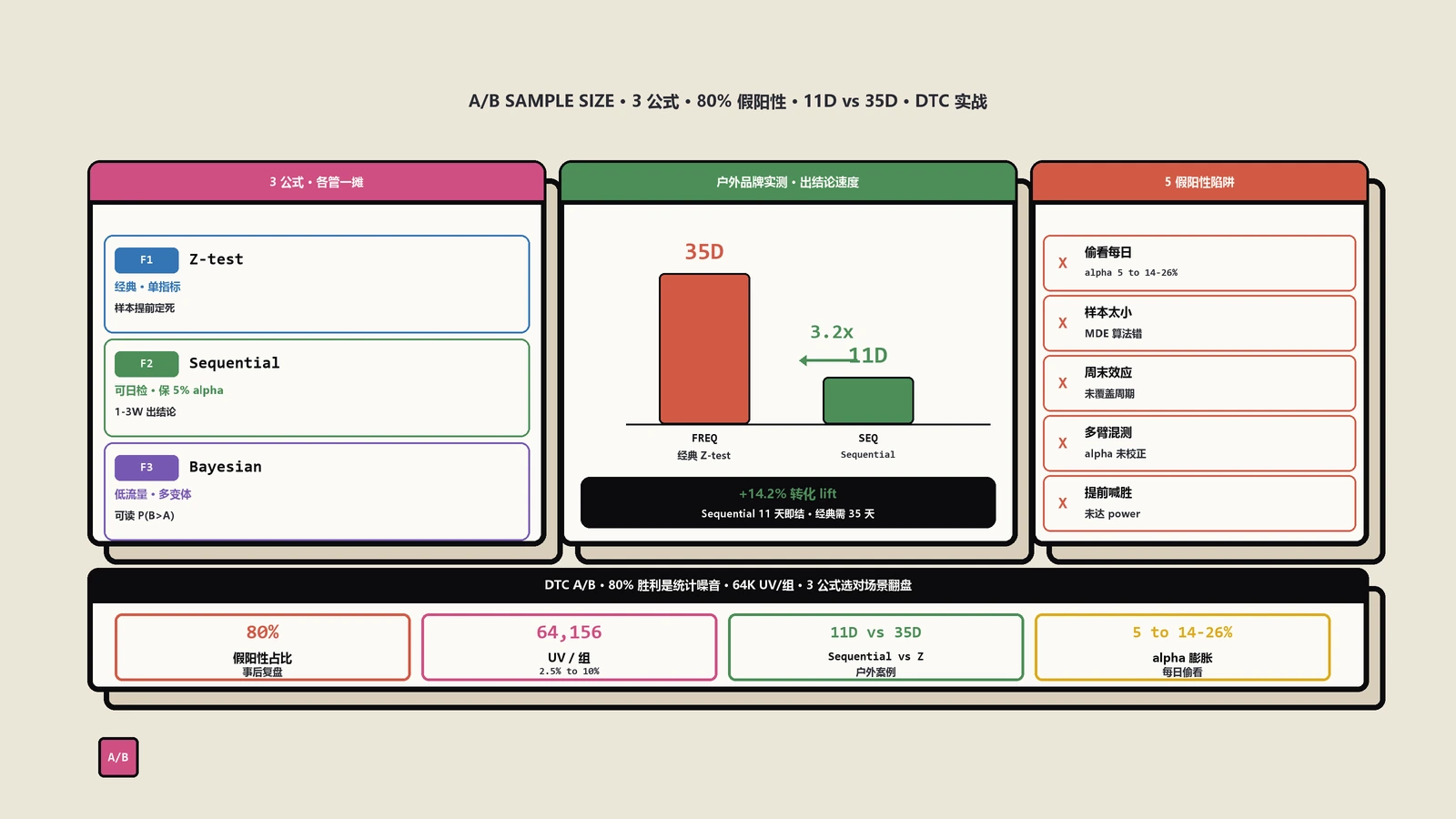
n = (1.96 + 0.84)² × [0.025 × 0.975 + 0.0275 × 0.9725] / (0.0025)² ≈ 64156
注意:这是单组样本量。两组合计需要约128000次曝光(PDP UV)。
如果你的站日PDP UV是2000,单组64000单需要:64000÷(2000÷2)=64天。这就是为什么大量DTC团队跑不了真正frequentist严格的A/B——流量物理上撑不起sample size。
Evan Miller的样本量在线计算器是行业事实标准,输入baseline、MDE、alpha、power就直接给你sample size,连续13年没改过页面。每次起新实验之前都先在那里填一遍,确认下限再决定是否开跑。把它当成飞机起飞前的checklist——少了哪个数据,原地等而不是硬起飞。
Z检验的局限:
- 必须预设固定样本量。中途停手就破坏alpha控制。
- 转化率太低(<1%)或样本量太小(n<30/组)时,正态近似失效,要改用Fisher's exact test或chi-square with continuity correction。
- 多变量(A/B/C/D 4个版本)需要Bonferroni修正alpha,公式更严格。
- 必须双尾。如果你听到有人推荐单尾省一半样本量,99%是工具销售员话术。
什么时候用Z检验?
- 单一二元主指标(转化率、加车率、点击率)
- 流量充足,能跑满sample size不偷看
- 决策周期允许等2-8周
- 团队统计成熟度低,需要"按表填空"式工具
DTC的标准场景里,Z检验适合PDP文案、CTA颜色、价格锚定这种"高频曝光+二元指标"的实验。结账页流程改版、PDP重新设计这种"低频复杂改动+多指标",下面两套公式会更香。
另外提醒一句:实验跑Z检验之前,归因链路得先干净。Meta、Google、TikTok三路广告的iOS 14之后归因失真问题如果没修,PDP上A/B看的"转化率"本身就是带噪信号——Meta广告CAPI归因重建那一套要先压稳,再开A/B。
公式2:Sequential序贯检验为何能边跑边停?
Z检验的最大痛点是"不能偷看"。Sequential testing(序贯检验)直接把偷看合法化——你每天看,甚至每小时看,依然能保证alpha不超5%。
数学魔法叫Always Valid p-values,背后是Wald 1947年的SPRT(Sequential Probability Ratio Test)+ Robbins 1970年的mSPRT(mixture SPRT)。Evan Miller 2015年那篇 Sequential A/B Testing 是工程角度最易懂的介绍,强烈建议起项目前花40分钟读一遍。读完你会感觉之前看仪表盘的紧张感全消失——不是变佛系了,是终于知道哪些peek是合法的。
它的核心思想:每次peek都付alpha代价,所以每次peek时把判定阈值动态提高(boundary随时间放宽显著阈值),让累计alpha始终≤5%。
实操上,你不需要自己推导。Optimizely Stats Engine、Statsig、Eppo、Convert全部内置Always Valid框架,前端dashboard会直接给你"can stop now"信号。直接看那个绿灯,比研究底层数学更生产力。
来一个保哥客户实战数据。DTC户外装备站做结账页加号优化(去掉一个非必填字段),按frequentist算需要18000单/组、约35天。改用Statsig的Sequential之后,第11天数据:变体 +14.2%、Always Valid p-value=0.012,直接判定胜出。省了24天迭代速度——更重要的是,节省的不是时间,是机会成本:这3周里CRO团队又跑完了2个PDP实验。
但Sequential不是免费午餐:
- 更大的"最坏情况"样本量。同样alpha+power下,Sequential在没真实效应时单组样本量大约比Z检验大30%-60%。换句话说,你赢得了快速胜出的能力,代价是没效应的实验跑得更长才能确认"无效"。
- MDE不能太小。如果你想检测+2%这种微提升,Sequential帮不上忙,最坏情况会跑很久。
- 需要user-level分流。session-level分流配Sequential会污染显著性。
- p-value监控要看趋势不只看终值。中途p-value一路从0.4稳定降到0.012是真信号;从0.6跳到0.03再回弹0.2,是噪音波动,别上钩。
什么时候用Sequential检验?
- DTC站日UV ≥1000、月单 ≥500,流量足够每天产生informative data
- 决策时效紧(季前上新、广告活动跑7天就要决策)
- 实验平台原生支持Always Valid(不要自己手撸,错一行就破功)
- 团队接受"边跑边停"+"无效实验跑更久"的非对称收益
实战搭配:把PDP实验留给Z检验,把结账页和广告lander实验留给Sequential。前者要确定,后者要快。两套并行,年实验吞吐量能从4场拉到12-16场。
公式3:Bayesian A/B检验和Frequentist区别在哪?
前两个公式都是frequentist学派的,逻辑是"假设变体没用,看看数据多大概率出现这种或更极端的差异(p-value)"。Bayesian不一样,它直接告诉你变体优于对照的概率是多少——P(B > A | data)。
对DTC运营来说,Bayesian的语义比p-value直观一万倍。"B优于A的概率是96%"是任何PM都能秒懂的话,"p<0.05单尾"则需要解释半天还容易踩base-rate fallacy。换种说法:Bayesian用的是人话,frequentist用的是法律文书——你跟一线运营开会,谁说人话谁赢。
实操上,Bayesian A/B的流程是:
- 给p_A、p_B各设一个先验分布(prior)。默认Beta(1,1)等价于均匀分布——"我对真实值毫无偏见"。
- 跑实验,每天用观测数据更新后验(posterior):α' = α + 转化次数, β' = β + (曝光 - 转化次数)。
- 抽样:从两个后验各采100000个样本,看B>A出现的比例,就是P(B>A | data)。
- 设定决策阈值,比如95%后验概率+expected loss小于业务可接受值,就上线。
Statsig 2023年那篇 Bayesian A/B Tests工程博客讲了他们怎么把这套搬进生产、怎么避免新手用informative prior把实验玩坏。客户搭Bayesian框架前,建议CRO团队读一遍这篇做对齐,避免后面争论"prior怎么选"。
Bayesian的优势:
- 不需要预设样本量。每天都能更新后验,看到阈值就停。本质和Sequential一样能边跑边停,但语义更友好。
- 小样本表现好。低流量DTC站(日UV <500),frequentist经常要等几个月,Bayesian用合理prior能在2-3周给出actionable决策。
- 支持expected loss decision rule。除了"哪个变体更好",还能算"选错的代价是多少"。对低单价高SKU数的DTC来说,能避免追着+1%的胜利上线但实际带来-3% AOV的灾难。
- 可叠加业务先验。你已经知道"换图片基本不会带来+20%转化"——这个常识可以变成prior,让模型不那么轻易接受夸张胜利。
Bayesian的代价:
- 数学门槛高。团队没人懂prior、conjugate distribution的话,很容易选错prior导致后验失真。
- 计算资源大。每次更新都要MCMC或大批量蒙特卡洛采样,DIY不友好。
- 审计难。frequentist给你一个p-value,监管/合规审计能复算;Bayesian给你一个后验概率,prior选择本身就是争议点。
- 容易过度自信。看到"96%胜出概率"很多人当作96%真的会胜出,忽略expected loss——这是Bayesian用户最常翻的车。
什么时候用Bayesian?
- 流量小的高客单DTC(家居、奢侈品、母婴、3C配件)
- 团队需要"以业务语言沟通实验结果",而不是统计语言
- 多变体(A/B/C/D/E)实验,frequentist修正后样本量爆炸
- 实验平台原生支持(Statsig、VWO、Optimizely现在都有Bayesian模式)
顺带一提,AI工具栈在DTC实验里的真实用法那篇里聊过,GPT类工具能帮你快速生成5-10个变体假设、压缩选题阶段时间,但样本量决策、prior选择这些核心工作还是要人来扛,AI现在还顶不上来。
3套公式怎么按DTC场景挑?
把三个公式按"实验流量×决策风险×团队成熟度"切成决策矩阵:
| 场景 | 日PDP UV | 决策可逆性 | 推荐公式 | 备选 |
|---|---|---|---|---|
| PDP文案/CTA微调 | ≥1500 | 高(随时回滚) | Z检验 | Sequential |
| PDP视觉重设计 | ≥1500 | 低(涉及品牌资产) | Z检验 + 二次复核 | — |
| 结账页字段优化 | ≥800 | 高 | Sequential | Bayesian |
| 结账页支付方式增删 | 任意 | 低(影响营收链路) | Z检验 + 长周期 | — |
| 广告lander文案 | ≥500/广告 | 高(广告每周换) | Sequential | Bayesian |
| Klaviyo邮件subject line | ≥3000收件 | 高 | Z检验 | Bayesian |
| 高客单家居/奢品全站测试 | <500 | 中 | Bayesian | — |
| 多变体A/B/C/D同期 | ≥2000 | 任意 | Bayesian | Sequential + Bonferroni |
| 季节性测试(黑五前) | 任意 | 任意 | 不开新实验 | — |
矩阵之外还有4条经验法则:
- 流量是物理约束,不是选择题。日UV <300的站,强行跑frequentist等于浪费时间,直接上Bayesian + 业务先验。
- 可逆性比统计严格度更重要。可逆改动(文案)容错率高,Sequential / Bayesian都行;不可逆改动(支付方式、退款政策)必须Z检验+跑满样本量。
- 团队没人懂prior就别玩Bayesian。Statsig / VWO的Bayesian模式只是降低了实操门槛,没降低理解门槛。看不懂后验分布图就会把"60%概率胜出"当作可上线。
- 多变体首选Bayesian。frequentist多变体修正后样本量爆炸,Bayesian通过后验概率排序天然支持。
很多团队把"哪个公式最严格"当作选型逻辑,结果选了最严格的然后做不到样本量、偷看、假阳——还不如一开始就选个不那么严格但守得住的。严格度是约束不是KPI。一个能守住的弱约束,胜过一个守不住的强约束。
样本量计算前必须诚实回答哪4个问题?
不管你最终选哪套公式,开跑前先把这4个问题写进PRD(实验设计文档)。不写就跑的实验,事后复盘90%找不到原因。
问题1:基线转化率是多少?数据从哪取?
新手常犯的错:拍脑袋说"我们PDP加车率大概3%"。
正确做法:从GA 4或Shopify analytics拉过去30天(最少)该PDP的真实加车率,按user去重(不是session)。如果该PDP日UV <100,基线本身就不稳定,把样本周期拉到90天再算,或者放弃单页测试改测分类页。
标准工具链是GA 4 + BigQuery + Stape服务器端跟踪。BigQuery直接SQL拉用户级转化率,比GA 4 UI拉的更准(GA 4 UI有sampling)。这套工具链怎么搭,前面那篇GA 4 + BigQuery + Stape部署里讲了完整流程,CRO团队照着搭就行。
问题2:MDE你愿意为多少业务价值买单?
MDE不是越小越好。MDE越小,sample size越大,实验跑得越长,机会成本越高。把MDE设得过小,等于让团队半年内只能做一个实验——这比假阳还致命。
实战定MDE的方法:算"如果这个改动真带来X%提升,未来12个月预计带来多少GMV增量"。把GMV增量除以"实验消耗的工程师+设计师+CRO工时折算成本",看ROI ≥3才值得做。
举例:日GMV 5000美元的站,PDP文案改如果带来+5%转化(即+250/日GMV、+91250/年),团队投入5万元成本,ROI=1.8不够看。MDE拉到+10%才到ROI 3.6——这才是值得做的下限。
问题3:单尾还是双尾?
双尾(two-tailed):假设变体可能更好也可能更差。这是默认推荐。
单尾(one-tailed):假设变体只可能更好。比双尾省一半样本量,但前提是你100% 确定变体不可能更差。
实战里99%的DTC实验都该用双尾。除非你已经在另一个站、另一个时段、用同样人群跑过一模一样的实验且只有正向结果,否则别用单尾——它就是SaaS销售员鼓动你买他工具的话术,不是科学。Evan Miller那篇How Not to Run an A/B Test末尾专门吐槽过这事,可以一并读了。
问题4:假阳代价vs假阴代价哪个更贵?
把这两个代价用钱量化:
- 假阳代价:你上线了一个其实没用的变体,未来一年损失多少?包括开发回滚成本、用户体验劣化、品牌资产损耗。
- 假阴代价:你拒掉了一个其实有用的变体,未来一年放弃多少GMV增量?
如果假阳代价远大于假阴代价(不可逆改动、品牌敏感改动),alpha调严到1%、power保持80%。
如果假阴代价远大于假阳代价(可逆 + 高潜力收益),alpha放到10%、power拉到90%。
DTC独立站90%的实验里,假阴代价更贵——错过一个+15%提升比误上一个无效变体痛得多。但你PRD里要明确写下你的判断,让团队对齐,不要默认5%/80% 一路用到尾。
DTC独立站90天A/B实验路线图怎么排?
很多DTC团队读完前面7个H2觉得很有道理,但回到工位不知道下周一干啥。按客户落地路径整理一份90天起步路线图,从0到能跑Bayesian实验:
Week 1-2:搭基础设施。
- 实验命名规范:[bucket]_[hypothesis]_[date],比如pdp_copy_value-prop_2024-12
- 实验PRD模板:背景+假设+主指标+次指标+MDE+样本量+周期+决策阈值+回滚方案
- 工具选型:日UV >2000选Statsig或Optimizely,日UV <1000选VWO或Convert,预算敏感选Google Optimize替代(GO已下线,替代品Vercel Edge Config + Posthog)
- 数据后台:GA 4用户级事件+BigQuery离线复算+实验平台原生dashboard三路对账
Week 3-4:跑第1个PDP实验。
- 选最容易上手的:CTA文案("加入购物车" vs "立即获取")
- 用Z检验,按上面4问题填PRD
- 不偷看,等样本量跑满
- 跑完做完整复盘:实验设计哪里能更好、数据有没有异常、决策依据是否充分
Week 5-8:扩展到结账页 + Klaviyo。
- 结账页用Sequential(流量低但可逆改动多)
- Klaviyo subject line用Z检验单测(邮件曝光大、二元指标干净)——具体怎么搭Klaviyo自动化流,7种高ROI Klaviyo自动化流里有完整骨架,A/B直接挂到现有flow里跑
- 每周一固定时间复盘上周所有实验,记录lesson learned
Week 9-12:引入Bayesian + 团队培训。
- 选一个高客单低流量产品页跑Bayesian
- 团队读Statsig Bayesian工程博客 + 做2小时内部workshop
- 季度末交付:实验白皮书(含工具栈、流程、命名规范、决策模板)
90天硬指标:
- 至少跑完8个well-designed实验(pre-register + 跑满样本量 + 完整复盘)
- 至少2个不同公式(Z + Sequential起步)
- 至少1个ship上线 + 1个明确reject
不卷数量、卷质量。一个跑得严谨的A/B实验,胜过十个看仪表盘拍脑袋的"显著胜利"。如果你站日UV <500,把硬指标减半:跑完4个,1个ship + 1个reject就算完美起步。
常见问题解答
Q1:小流量DTC站(日UV < 500)能跑A/B测试吗?
能跑,但要换公式与节奏。frequentist Z检验在日UV <500的站基本跑不出严格显著(要等几个月),强行跑就一定会偷看、就一定会假阳。正确路径:Bayesian + 业务先验 + expected loss decision rule,把决策周期压到2-3周。同时把实验粒度从"单页测试"上升到"分类页测试"或"邮件流测试",集中样本量。能拉的杠杆是把高单价产品聚类成1-2个组测试,而不是每个SKU单测。
Q2:Sequential检验和multi-armed bandit有什么区别?
Sequential testing本质还是A/B,目的是做"上不上线"的二元决策,所有流量按固定比例(通常50:50)分到变体。Multi-armed bandit(MAB)目的不是决策、是优化收益——它会动态把更多流量倾向到当前表现好的变体,最大化总体回报。MAB适合"广告创意优化、新闻推荐"这种持续选优场景;A/B决策适合"要不要把变体B永久上线"这种里程碑式决策。DTC独立站90%的实验场景是后者,先把A/B做好再考虑MAB。
Q3:黑五、Prime Day之前能开新实验吗?
大节点前48小时与节点期间不开新A/B,是行业铁律。原因:(1)受众结构突变,平时不会买的用户涌入,基线漂移;(2)流量峰值打破样本量预算,原本规划30天的实验3天就跑完,但数据偏向"促销周期用户",结论不可推广到日常;(3)回滚成本飙升,万一变体B挂了,黑五期间没人有时间救火。正确做法:节点前1个月所有in-flight实验完结,节点期间运维稳态,节点后2周回归实验节奏。
Q4:能不能用ChatGPT帮我算样本量?
能算,但只能用来verify不能用来decide。ChatGPT / Claude / Gemini都能给你Z检验样本量公式,输入参数也能算对。但它没法验证你的baseline是否准、MDE是否合理、是否考虑了Bonferroni修正、是否考虑了季节性。把它当成"checklist计算器"用——算完后让AI复算一遍核对数字,可以;让AI决定实验该不该开跑,不行。Evan Miller那个13年不改的页面比任何LLM都靠谱。
Q5:实验跑满了但结果不显著,要不要再多跑一周?
不要。这是最经典的"加时偷看"陷阱:原本alpha=5%的实验,跑满后看到不显著再多跑一周决定,实际alpha已经爆到10%以上。正确处理:实验跑满后立刻按预定计划做决策——不显著就reject,不要纠结"差一点点就显著了"。如果你确实觉得MDE设得太大错过了真效应,下次实验把MDE调小、样本量重算、重新跑一轮新实验,而不是继续延长旧实验。每次延长都是在赌博。
Q6:A/B测试和multivariate(MVT)应该怎么取舍?
A/B测试同时只测一个变量,MVT同时测多个变量组合(比如标题×按钮颜色×图片3因素2水平=8个组合)。MVT优点是能识别因素间交互作用,缺点是样本量按组合数翻倍,需要的UV是A/B的4-8倍。DTC独立站的标准建议:日UV < 2000只跑A/B,日UV 2000-10000可以尝试2因素MVT,日UV > 10000才考虑3因素以上MVT。Shopify大店实测,MVT在团队还没把A/B做扎实之前就上,结论可信度反而比A/B还低。
Q7:实验失败或无效的结果要不要给老板汇报?
必须汇报,而且要专门汇报。原因:(1)老板不知道你跑了无效实验,就会以为"你只做有用的事",导致后续KPI设定脱离实验真实成功率(行业基准10%-20%);(2)reject实验本身就是知识资产——"这个改动没用"的结论值得团队记下来避免再犯;(3)汇报无效实验是CRO团队成熟度的标志,能赢得高管对实验文化的长期投入。失败实验的复盘文档,有家客户团队起名叫"暗物质档案"——专门收录跑出来没效果的假设,年底翻看是最有价值的学习材料。
权威参考资料
本文标题:《A/B测试样本量怎么算:DTC独立站避免假胜利的3个公式》
本文链接:https://zhangwenbao.com/dtc-ab-test-sample-size-3-formulas.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0