SEO实验设计与统计功效:单因素隔离最小可检测效应

本文目录
- SEO实验和CRO的A/B测试到底差在哪?为什么不能直接套
- SEO实验的5类核心场景是哪些?哪些值得花时间做
- 单因素隔离怎么做?SEO实验最容易踩的多因素混淆陷阱
- 统计功效怎么算?最小可检测效应(MDE)公式拆解
- 样本量怎么定?URL级、关键词级、流量段级三种粒度对比
- 实验周期怎么定?SEO反馈循环60到90天滞后的工程方案
- 页面分桶策略怎么设计?CUPED与分层抽样的实操做法
- 实验结果怎么解读?季节性、算法波动、外部信号怎么扣除
- SearchPilot与自建SEO实验平台怎么选?小团队和大团队的取舍
- 国内出海团队做SEO实验,比海外多踩哪几道坎?
- 实验还没跑满就被叫停推广,最后怎么收场?
- 常见问题解答
- 权威参考资料
摘要:SEO实验跟CRO的A/B测试是两件事——CRO在用户层面分流,SEO必须在URL或页面分组层面分流,因为同一个用户不会同时看到两个title。混淆这一点是大多数SEO实验翻车的根因。这篇拆解SEO实验的真实工程步骤:5类核心实验场景、单因素隔离、最小可检测效应(MDE)的计算、URL分桶策略、反馈循环60到90天的滞后处理、季节性扣除、SearchPilot与自建平台的取舍。读者锁定外贸独立站主、DTC品牌站内SEO负责人、做技术SEO的乙方咨询师。
保哥这几年帮DTC品牌和外贸独立站做过几十次SEO实验,越做越确认一件事——SEO实验做不好的根本原因不是技术不到位,是把CRO的方法论直接搬过来用。CRO的A/B测试有用户分流、有即时转化反馈、有清晰的成功指标;SEO实验全都没有。要在这种环境里得到可信结论,需要一整套不同的实验设计逻辑。本文把这套逻辑拆解开,重点说做SEO实验最容易踩的坑和最有用的工程化方案。
SEO实验和CRO的A/B测试到底差在哪?为什么不能直接套
多数人第一次做SEO实验时,会下意识打开Optimizely或者Google Optimize的逻辑——把流量分成A/B两组、跑一周、看转化率。这套方法在CRO场景下成立,在SEO场景下从第一步就错了。
第一个根本差异是分流单位。CRO在用户层面分流(同一个网页给不同用户看不同版本),SEO必须在URL或页面组层面分流——你不能让同一个title在Google索引里同时有两个版本。Google看到的永远是某一刻服务器返回的那一个HTML,没有“给50% 爬虫看新版、给50% 看旧版”的实操路径。所以SEO实验本质上是把站内的URL拆成两组——实验组改、对照组不改——而不是把用户拆两组。
第二个差异是反馈周期。CRO实验当天就能看出转化率差异,跑7到14天就能下结论。SEO实验的反馈链条至少有三层时滞——Google重新抓取需要3到14天、索引重排需要7到21天、稳定排名需要30到60天才能观察。一个完整可信的SEO实验通常需要跑60到90天,少于30天的SEO实验结论基本不可信。
第三个差异是噪音来源。CRO的噪音主要是流量波动,可以用统计方法清理。SEO的噪音多了一层——Google算法本身在持续变动(核心更新、垃圾内容更新、Helpful Content更新一年好几次),算法变动可能掩盖或放大你的实验效应,无法用对照组完全消除。
第四个差异是成功指标。CRO的指标是转化率(页面级,无歧义)。SEO的指标可以是排名、点击数、展现数、CTR、自然流量——选哪个作主指标会直接影响结论。这一点上Google自己也明确表态过A/B测试和SEO的关系,SEO如何处理A/B测试页面里详细拆过Google对A/B页面的5大风险判断,做CRO实验时也要注意别误伤SEO信号。
SEO实验的5类核心场景是哪些?哪些值得花时间做
不是所有SEO改动都值得做实验。多数微调(改alt文字、加面包屑、调字号)的预期效应小到不能测出来,做实验只是浪费时间。真正值得做实验的是下面5类:
第一类:Title与H1改写。这是SEO实验里ROI最高的一类——改动成本低(改个标签)、效应大(CTR直接受影响)、反馈快(3到14天能看到点击数变化)。典型做法是把一类相似的URL(比如1000个产品详情页)拆成500/500两组,一组改新title模板、一组保留旧模板,跑4到6周看CTR与排名变化。保哥去年帮一家北美户外装备DTC客户跑这类title实验,把1200个产品页title从“产品名+品类”模板改成“产品名+场景+用户痛点”模板,6周后实验组CTR从2.1% 升到3.4%、组内总点击数提升38%,结论清晰可推广全站。
第二类:Schema结构化数据。在某个页面类型上加Schema(FAQPage/Product/HowTo)或者改Schema字段结构,看富媒体卡片出现率和点击数变化。这类实验的反馈周期相对长(Schema重新被识别需要14到30天),但效应明显时差异极大(富媒体卡片能把CTR翻倍)。
第三类:内链密度与结构。改内链布局——增加某类页面的内链入口、改anchor text、调整内链锚定位置(顶部vs中部vs底部)。这类实验难度最大,因为内链变动会引发整站的权重重分布,不只影响实验组页面,还会影响对照组。设计实验时要刻意选PageRank流入路径相对独立的页面组做对照。
第四类:外链与anchor text。给一组目标URL集中做外链建设,对照组不做,跟踪4到12周后的排名差异。这类实验的难点是外链建设本身没法精确控制——你能控制发出去多少外链,控制不了多少被Google真正认可。具体的实验设计方法参考外链归因实验:哪条外链真撬动排名,那篇专门拆了6步外链实验设计与归因分析。
第五类:页面内容长度与深度。把一组短页面(500字)扩写到2000字以上,对照组保留原样,跟踪8到16周后的排名和长尾词覆盖变化。这类实验是SEO内容策略最核心的实验,但成本极高——扩写100个页面是一笔大工作量。
这5类之外的微调(meta description、面包屑、URL结构、image alt),可以做小规模试错但不必上严格统计实验,因为效应小、信噪比低、结论不可靠。
单因素隔离怎么做?SEO实验最容易踩的多因素混淆陷阱
这是SEO实验设计里最常翻车的环节。一个看起来很简单的实验——比如改title——往往伴随多个其他变量同时变化,导致结论无法归因。
陷阱一:同时改了title和description。很多团队改title时顺手把description也改了(因为感觉新title配旧description不协调)。结果实验组CTR提升了,但你不知道是title起作用还是description起作用,还是两者协同起作用。正确做法是只改title,description保留原文。
陷阱二:跨设备/跨地区/跨语言混合统计。同一个URL在移动端和桌面端的排名机制不同(移动优先索引)、在不同国家的Google排名不同(hreflang/地区性算法权重)、不同语言走的索引管线不同。把这些混在一起统计,方差会被噪音吞没。正确做法是按设备/地区/语言分别拆出对照组分析。
陷阱三:实验期间撞上Google核心更新。如果你的实验从9月15日开始跑到10月30日,期间撞上9月底的核心更新,你看到的排名变化里有多少是实验导致的、有多少是核心更新导致的,没法分清。规避方法是订阅Google官方更新日历(@searchliaison推特账号),核心更新发布前1周到发布后2周都暂停启动新实验。
陷阱四:竞对同期改动。你改了title,竞对刚好同期也改了title或者上了一波外链,你的排名变化里夹杂着竞对动作的影响。完全规避不可能,但可以用更长的时间窗口(90天以上)+ 更大的样本量(300个URL以上)来稀释。
陷阱五:技术改动同期发生。SRE改了robots.txt、Cloudflare改了cache策略、CMS升级了渲染逻辑——这些技术改动都会影响SEO,跟你的实验混在一起就分不清归因。最务实的做法是建立一个“SEO实验冻结日历”——技术团队所有可能影响SEO的发布在实验期间都要走SEO评审,避免误伤。
真正干净的单因素实验,需要做到:实验组只改1个变量(不是1类变量是1个具体变量)、对照组所有维度都和实验组保持一致(除了被改的那个变量)、外部环境在实验期内尽量稳定。这一套做下来比看起来难得多,能做到80% 就算高质量实验。
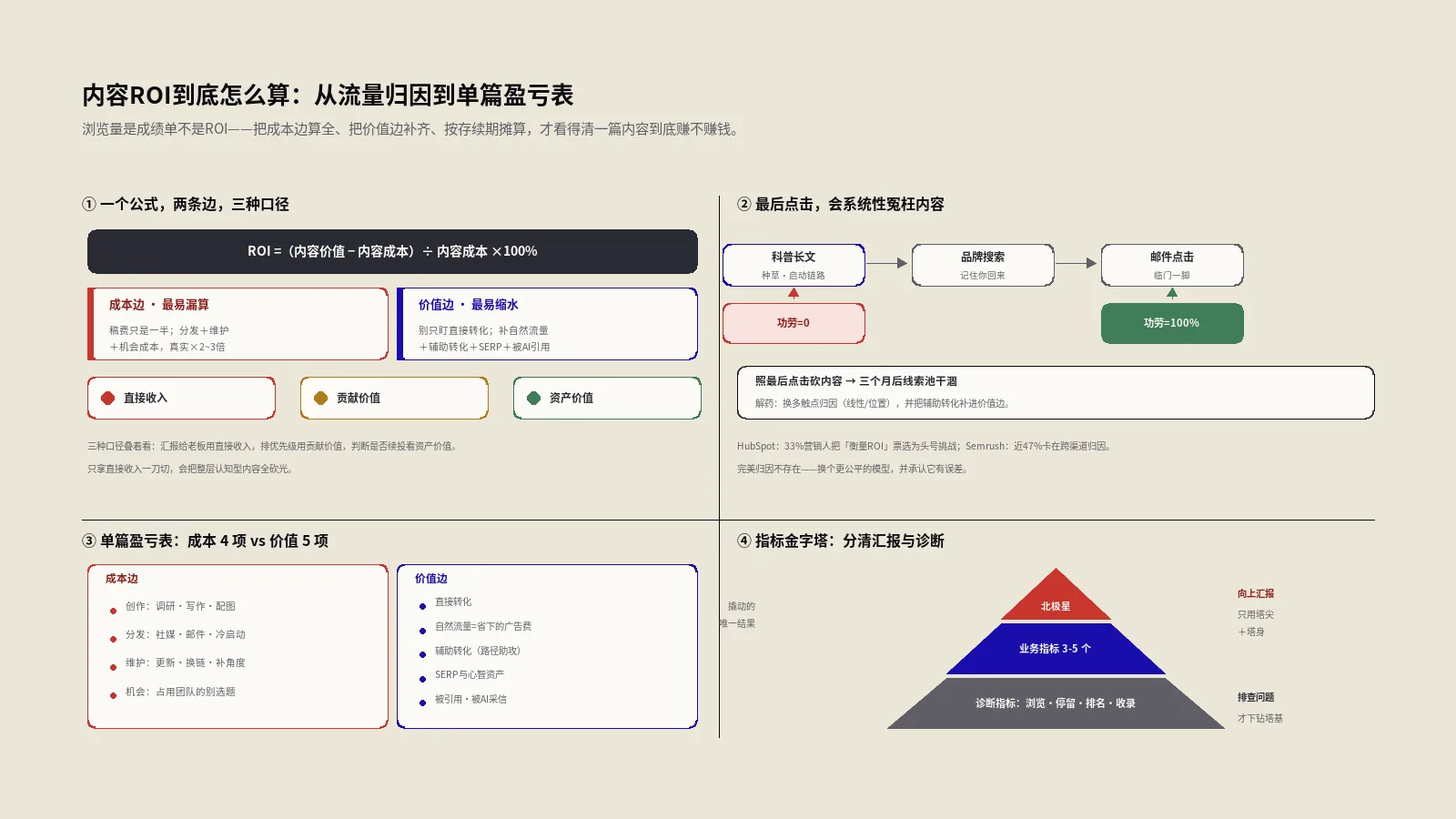
统计功效怎么算?最小可检测效应(MDE)公式拆解
多数SEO实验失败不是因为效应不存在,而是样本量不够、检测不出来。这就是统计功效(statistical power)问题。功效 = 实验真有效应时正确检测出来的概率,行业标准是0.8(80% 概率不漏报)。
统计功效的核心公式包含4个变量——样本量n、最小可检测效应MDE、基线指标的方差 σ²、显著性水平 α(通常0.05)。这4个变量里只要确定3个,第4个就被锁死。SEO实验最常用的算法是给定n和 σ²,反推这次实验能检测出的最小MDE是多少;如果反推出的MDE大于你预期的效应(比如反推MDE是20%、你预期的实验效应是5%),那这次实验注定测不出结果,做了也是白做。
MDE的简化公式(双侧z检验、α=0.05、power=0.8):MDE ≈ 2.8 × σ / √n。其中 σ 是基线指标的标准差,n是样本量(URL数量)。举个具体例子——你的对照组1000个产品页面,平均每天每页1.2次点击、标准差0.8次点击,跑30天数据。MDE = 2.8 × 0.8 / √(1000×30) ≈ 0.013,相当于平均每页每天提升1.3% 才能检测出。这个MDE偏小,说明这次实验设计样本量足够。
反过来如果你的样本量只有100个URL、跑14天,MDE = 2.8 × 0.8 / √(100×14) ≈ 0.06,相当于平均每页每天提升6% 才能检测出。如果你预期的实验效应是3%,这次实验就是无效的——做完会得到“没有显著差异”的结论,但这个结论不能证明效应不存在,只能证明你的样本量太小测不出来。这两种情况经常被混淆。
实操上,做SEO实验前要先做power analysis(功效分析)——给定预期效应大小,反推需要多少样本量、需要跑多少天。如果反推出的样本量大于你能拿到的URL总数,那这个实验就别做了,省下时间做别的事。这一步比实验本身更重要。这部分跟数据归因方法论的内容深度相关,更系统的统计校验流程参考数据驱动SEO决策:归因建模与假设检验。
样本量怎么定?URL级、关键词级、流量段级三种粒度对比
SEO实验的样本单位至少有三种粒度,选哪种粒度直接决定实验设计。
URL级:把单个URL当作一个观察单位,1000个URL拆成500/500。优点是最直接、统计模型最简单。缺点是URL之间差异极大——首页跟一个分类页跟一个产品详情页根本不是同类样本,强行混在一起会拉爆方差。所以URL级实验必须先做严格的URL分层(按页面类型、流量级别、PageRank、收录天数)再分桶。
关键词级:把单个关键词当作一个观察单位,目标KW池里200个KW拆成100/100。优点是直接对应业务关心的“排名变化”,能直接看到KW排名提升数。缺点是KW跟URL不是一对一映射——一个URL可能命中几十个KW,几个URL也可能争同一个KW,分桶时要把整个KW cluster一起拆,否则实验会污染。
流量段级:把流量分成几个层级(头部KW、长尾KW、品牌KW),按层级分别做实验。优点是承认SEO不同流量段的行为规律不同。缺点是每个层级的样本量都会缩水,需要更大的总样本量才能跑出统计显著性。
实操上多数有规模的SEO实验是这样:先按页面类型分层(产品页/分类页/文章页分开做实验),每一层内部再用URL级分桶。这种“先分层再分桶”的策略叫做分层抽样(stratified sampling),是SEO实验最常用的设计。
关于样本量的另一个常见误区——以为对照组越大越好。其实对照组和实验组同样大(1:1分桶)是统计功效最优的。1:2分桶(对照组2倍于实验组)的样本利用效率比1:1分桶低11%。除非有特殊业务约束(比如怕实验组负效应影响营收,故意把实验组缩小到1:4),否则都用1:1。
实验周期怎么定?SEO反馈循环60到90天滞后的工程方案
SEO实验最让人崩溃的就是反馈周期长。CRO实验跑2周下结论,SEO实验老老实实跑60到90天起步。这个周期不是拍脑袋定的,是反馈链条的客观限制决定的。
第一段时滞:Google重新抓取实验组URL。新闻类站点可能1天内重新抓,电商产品页3到7天,长尾内容页14到30天才被重抓一次。这一段的时滞可以用GSC的URL检查工具加速(手动请求重新索引),但每天有配额限制,1000个URL全部手动push不现实。
第二段时滞:索引重排。Google重新抓到新版本后,并不是立刻调整排名——会先把新版本进索引、然后下次算法评估时才更新排名。这一段通常需要7到21天。
第三段时滞:排名稳定。新排名出现后会有一个波动期(升一升再掉一掉),需要30到60天才能稳定。如果你在波动期就下结论,结论很容易反复。
实操的工程方案是把实验周期分成4个阶段——重抓期(第1到14天,不看数据,只确认GSC显示新版本被抓取)、过渡期(第15到30天,开始记录数据但不下结论)、观察期(第31到60天,每周看一次趋势)、决策期(第61到90天,做统计检验、出最终结论)。少于60天就下结论的SEO实验,反转率高达40% 以上——前期看着有效,跑满90天却发现是噪音。
页面分桶策略怎么设计?CUPED与分层抽样的实操做法
SEO实验的分桶不能随机抓,因为URL之间差异巨大,简单随机抽样会让对照组和实验组的基线就不一样。常见的分桶策略有3种。
分层抽样(Stratified Sampling):先按几个关键维度(页面类型、流量级别、收录时间、内链深度)把全部URL分成若干层,每一层内部按1:1随机分桶。这样能确保对照组和实验组在每个维度上的分布都一致。这是最常用的方法,工程实现也简单——一段Python脚本搞定。
配对抽样(Matched Pairs):找特征极相似的URL对子(比如URL A和URL B都是产品详情页、月流量都在500-700、收录都超过6个月、内链入口数都在3-5之间),然后两两配对,一个进实验组一个进对照组。这种方法对方差控制最严,但实操成本高——配对算法本身要写、配不上对的URL要丢掉。
CUPED(Controlled-experiment Using Pre-Experiment Data):用实验前的基线数据做协变量调整,把实验后的指标y替换成y' = y - θ × x(x是pre-period同一URL的基线、θ 是回归系数)。这种方法能把方差降低30% 到50%,相当于免费扩大样本量。实操难度中等,需要团队懂点统计。CUPED是Microsoft、Booking、Airbnb等公司在A/B测试上的标准做法,SEO实验里用的人少但效果一样好。
分桶策略的选择要看团队的统计成熟度。刚开始做SEO实验,分层抽样足够;做了一年以上、有BI团队配合,可以升级到CUPED;配对抽样只在样本量极小(200 URL以下)的特殊情况下用。
实验结果怎么解读?季节性、算法波动、外部信号怎么扣除
跑完90天,你拿到一组数字——实验组流量提升8%、对照组提升3%、净效应5%。这个5% 能不能下结论说“title改写有效”?不能直接下,要先扣三层外部影响。
第一层:季节性。如果你的实验从11月跑到次年2月,期间穿越了双11、感恩节、圣诞节、春节等多个流量高峰,实验组和对照组都会被季节性放大。扣除方法是把每周的实验组流量除以对照组流量,看比值变化而不是看绝对值。如果实验组/对照组的比值在实验前是1.0、实验后稳定在1.05,那5% 的效应才是真的;如果比值在实验后波动(1.10、0.95、1.08)说明有未控制的因素。
第二层:算法波动。实验期间如果撞上Google核心更新,要把更新前后2周的数据剔除,只看更新前4周和更新后4周(更新窗口外)的稳定数据。如果剔除后样本量太小,那这次实验需要延长跑——多跑30天,等市场重新稳定。
第三层:外部信号。竞对动作、外链自然增长、品牌词搜索量变化都属于外部信号。无法完全控制,但可以用SEMrush/Ahrefs同步监控竞对,发现竞对在实验期间有大动作(比如发了50篇新内容、上了一波外链),在报告里要注明并降低结论可信度。
三层扣除完之后,如果效应还在3% 以上,且p值小于0.05,才算真正可信的实验结论。许多团队第一次跑实验时跳过这三层扣除,直接看绝对数字下结论,结果三个月后效应消失发现是季节性带来的。保哥见过最离谱的一次是一家美妆DTC客户,第一次跑schema实验看到SQL直接得出实验组流量 +47% 的“奇迹结论”,开会拍板全站推广。3个月后流量回归基线发现实验期间撞上节日大促 + 一波品牌广告投放,实际schema改动效应只有2%。SEO实验报告必须明确写清三层扣除过程,不然只是数据展示不是科学结论。这部分跟数据治理底子也直接相关——指标层不统一会让实验结论无法跨团队复用,SEO指标层与单一可信源专门拆了5大指标治理框架。
SearchPilot与自建SEO实验平台怎么选?小团队和大团队的取舍
SEO实验做到一定规模后,需要专门的实验平台。市面上的选择主要是SearchPilot(前身Distilled ODN)和自建。
SearchPilot:业界最成熟的SEO实验平台,主打“edge-deployed split test”——通过CDN边缘节点把不同版本分发给不同的Googlebot请求,做到真正的URL级实验。优势是开箱即用、统计严谨、有大量真实案例(耐克、ASOS、宜家都是客户)。劣势是价格高(年费在5万到30万美元区间)、对站点架构有要求(需要支持CDN edge logic)、做实验前要先把站点接入。适合月预算1万美元以上的中大型站点。
自建:基于自家CMS做实验调度。优点是完全可控、不限实验数量、长期成本低(一次性开发100万人民币左右)。缺点是工程团队投入大(至少2个工程师专职6个月)、统计模型要自己设计、数据采集要自己接(GSC API + 自建日志),第一次跑出可信结论可能要1到2年。适合月流量100万UV以上、有专门SEO团队的大型站点。
轻量替代方案:完全没预算的小团队可以用Excel + Python半人工做。把URL拆成实验组对照组、改完之后通过GSC API每周拉一次数据、用t检验或z检验算显著性。这种做法精度差(无法控制CDN edge层差异)、效率低(每个实验都要重新搭一遍)、但能跑通基础实验。建议作为入门工具用1到2年,积累统计经验后再决定上SearchPilot还是自建。
选型的决策点其实不是预算而是“实验频率”——一年跑10次以下实验用Excel够、一年跑30次以上用SearchPilot划算、一年跑100次以上必须自建。多数DTC品牌站和外贸独立站的实验频率在5到15次之间,Excel + Python完全够用,没必要被SaaS销售忽悠。保哥服务的中小型独立站客户里,没有一家上了SearchPilot——年实验频次都没到需要付那个钱的门槛。
国内出海团队做SEO实验,比海外多踩哪几道坎?
前面这套实验方法论是通用的,但保哥得提醒一句:国内出海团队照搬过去,会比海外团队多踩好几道额外的坎。这些坎不是方法论问题,是国内特定的工作环境带来的,不提前想清楚,实验从一开始就跑歪。
第一道坎是数据管道。SEO实验全靠GSC(Google Search Console)的数据做判断,可国内访问GSC本身就不稳定,团队里没有稳定可达环境的,连每周拉一次数据都成问题。更麻烦的是GSC的数据本身有2到3天延迟、还会做隐私阈值过滤(低展现量的查询直接不显示),样本本来就小的实验,再被这层过滤一削,能用的数据所剩无几。务实做法是搭一套GSC API的自动化采集,每天定时拉、本地存全量,别靠人工到网页端手抄。
第二道坎是缺edge层实验能力。海外成熟团队用SearchPilot这类平台,能在CDN边缘节点把不同版本分发给不同的Googlebot请求,做到真正的URL级分流。国内出海站的技术栈五花八门,很多还在用国内云厂商的CDN,根本没有edge logic的开发能力。这意味着国内团队多数只能退回到“直接改一组URL、不改另一组”的笨办法做实验,分桶的干净度天然打折,结论的可信度也要相应保守。
第三道坎是组织对周期的耐心。这是最致命的一道。SEO实验要跑60到90天才有可信结论,但国内很多出海团队是“增长黑客”那套文化,老板和营销负责人习惯了投流“今天投明天看ROI”的节奏,让他们等90天再下结论,几乎不可能。保哥后面要讲的翻车案例,根子就在这道坎上。在国内推SEO实验,一半的功夫得花在“管理老板的预期”上——开跑前就把90天周期、三层时滞、为什么不能提前下结论这些写进立项文档,让所有人签字确认,比实验本身的统计设计更重要。
实验还没跑满就被叫停推广,最后怎么收场?
讲个保哥亲历的翻车案例,正好接上面那道“周期耐心”的坎。一家做家居用品出海的DTC客户,团队跑了个产品页title改写实验,500个页面改新模板、500个对照。设计得相当规范——单因素、1:1分桶、power analysis也算过。问题出在第28天。
第28天,实验组的CTR数据看着特别漂亮,比对照组高了将近20%。营销VP一看坐不住了,当场拍板:“效果这么好还等什么,立刻全站推广。”SEO负责人据理力争,说实验才跑了不到一个月、Google索引都没完全重排、这个数字大概率是噪音,但架不住VP一句“流量就是钱,多等一个月少赚多少你算过吗”。结果对照组也被一并改成了新模板,实验被强行终止。
后面的事很打脸。全站推广之后,整体CTR不升反降,回落到比实验前还低一点的水平。复盘才发现,第28天那个漂亮数字,撞上了那一周一个海外购物节的搜索高峰——实验组里恰好有几个热卖品类的页面吃到了节日流量,把组内均值整个抬了上去,纯粹是季节性噪音。等节日一过、Google索引重排完成,真实效应只剩个位数,还不一定为正。最要命的是,对照组没了,这个实验再也无法验证真实效应到底是多少,等于三个月的工夫全打了水漂。
这个案例的教训不在统计、在流程。事后保哥帮他们立了三条硬规矩:一是实验立项文档里写死“最早下结论日”,不到日子谁来了都不许动对照组;二是给老板的周报只报趋势、不报可以被断章取义的单点峰值,避免“一个好看的数字引发一次冲动决策”;三是真遇到中途疑似强效应,宁可再开一组小样本快速验证,也绝不动正在跑的对照组。SEO实验最贵的从来不是跑实验那点成本,是一次冲动叫停毁掉的、再也补不回来的对照基线。
常见问题解答
问:我能不能只挑头部KW做SEO实验?毕竟头部KW的流量大、变化快、好看出效应。
答:不建议。头部KW的方差特别大——单个KW的排名波动可能从第3位掉到第8位再回到第5位,全是正常噪音。这种高方差会吃掉你的统计功效。长尾KW反而更稳定(排名变化慢、噪音小),更适合做实验。具体做法是按KW流量分桶,头部KW单独看(小样本观察、不下严格统计结论),长尾KW作为主样本跑统计实验。如果只有头部KW可选,那必须把样本量加大到至少500个KW、跑满120天才能稳。
问:实验跑了60天,p值是0.12,是不是说明实验失败?
答:不一定。p值0.12高于常用阈值0.05,但低于0.2——属于“弱信号”区间。这个区间下不能说“实验有效”,但也不能说“实验无效”,只能说“样本量不够下结论”。务实做法是把实验再延长30到45天,重新算p值。如果延长后p值降到0.05以下,说明效应确实存在只是初期样本不够;如果延长后p值还在0.1以上,那说明效应即使存在也很微弱(远小于MDE),实操上不值得推广。
问:实验组和对照组都掉量了,但实验组掉得少,算不算实验有效?
答:算。SEO实验的核心比较是“实验组vs对照组的相对差异”,不是“实验组的绝对增长”。整个市场冷下来或者算法更新打压时,实验组掉量更少就是正向信号。这种情况在Google核心更新窗口期特别常见——你可能避免了10% 的流量损失,等同于10% 的提升。出报告时要明确写“在X算法更新背景下,实验组相对对照组保护了10% 的自然流量”,而不是用绝对数字说话。
问:可不可以同时跑多个SEO实验?
答:可以但要满足两个条件——实验之间无重叠URL、影响指标无相互干扰。比如你在产品详情页跑title实验,同时在分类页跑schema实验,两者不相干,可以并行。但如果你在同一组URL上同时跑title实验和schema实验,那会发生相互污染,结论无效。同期跑实验的上限通常是3到5个(互不重叠),超过这个数管理成本会爆炸。
问:cid 1761那篇讲Google怎么处理A/B测试页面,跟SEO实验是不是冲突?
答:不冲突,是两个不同的话题。Cid 1761讲的是用CRO工具(Optimizely之类)在用户层做A/B测试时,怎么避免被Google当成cloaking——这是SEO风险管理。本文讲的是为了改进SEO本身而做的实验设计——这是SEO实验方法论。前者是规避Google处罚,后者是用统计方法判断SEO改动的真实效应。两件事都重要但不冲突——做CRO时要懂规避SEO风险,做SEO实验时要懂统计设计。
问:我手上只有50个URL能做实验,样本量太小怎么办?
答:50个URL做不出有统计意义的SEO实验,强行做只能拿到“没有显著差异”的无效结论。3个备选方案:第一,把实验扩展到KW级(50个URL上跑200-300个KW),用KW当观察单位;第二,延长实验周期到180天以上(用时间换样本),但要扣除中间的算法更新影响;第三,放弃严格统计实验,改成案例研究——把改动细节记录下来、每周观察一次趋势、6个月后写一份描述性报告。这种报告不能下因果结论,但可以作为后续大规模实验的假设来源。
权威参考资料
本文标题:《SEO实验设计与统计功效:单因素隔离最小可检测效应》
本文链接:https://zhangwenbao.com/seo-ab-testing-experiment-design-statistical-power-single-factor.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0