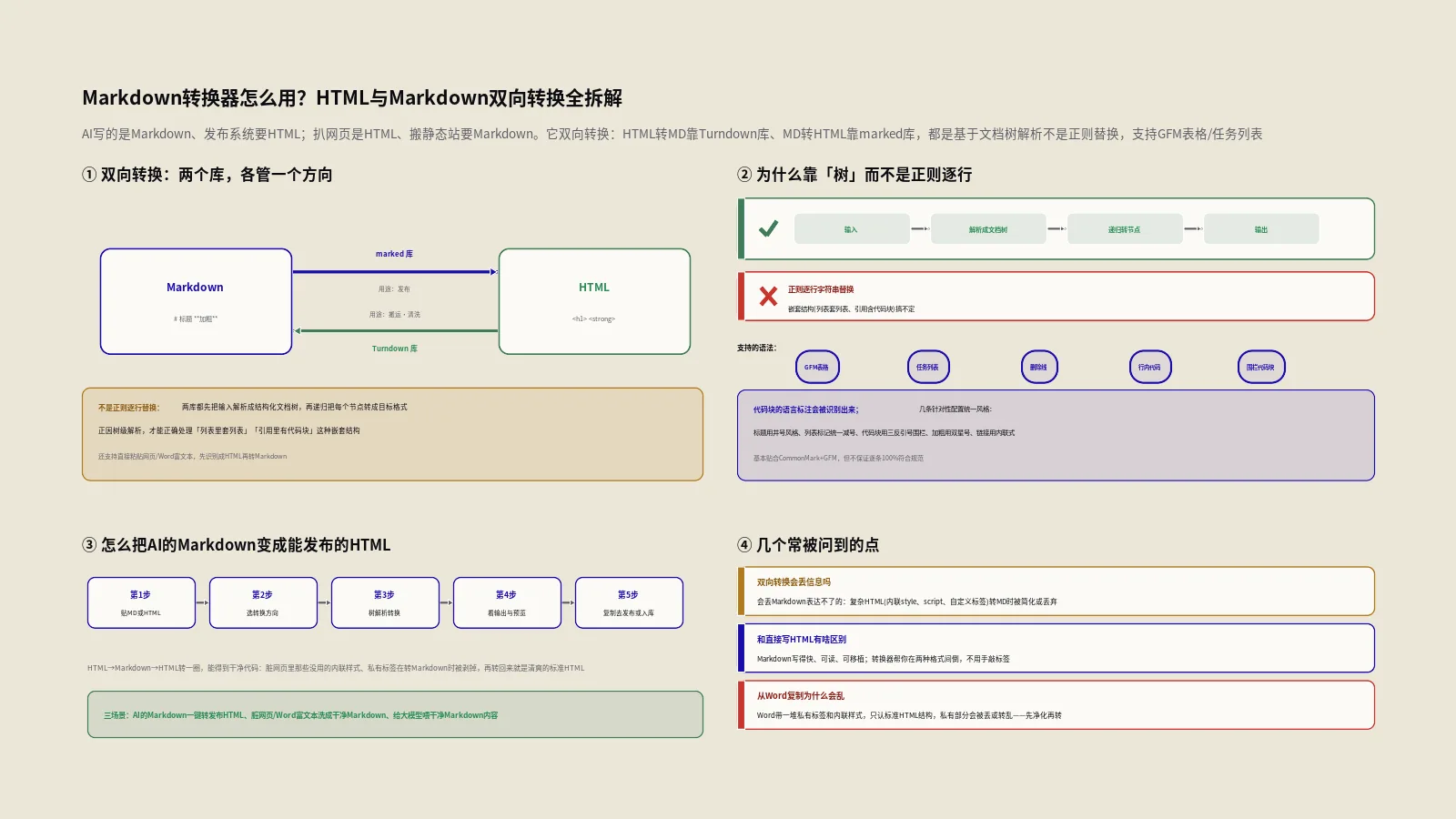
PDF怎么转成Word、Excel、PPT和图片才不乱版?格式互转实战

本文目录
- PDF为什么这么难“转”出去?先搞懂它的本质
- 转格式之前,有哪些准备动作能省下大量返工?
- PDF转Word怎么转才不乱版?
- PDF里的表格怎么准确转成Excel?
- PDF怎么转成PPT、图片和网页HTML?
- 扫描件PDF和原生PDF转出来差别为什么这么大?
- 批量转换和在线工具到底能不能用?
- 转换后版式错乱、字体丢失怎么补救?
- 不同场景到底该转成什么格式?
- 转换里最容易踩的坑有哪些?
- 常见问题解答
- 为什么同样一份PDF,我转出来的Word全是乱的,别人转的却很整齐?
- PDF转Excel后数字总是错位、对不上,有什么办法?
- 用免费的在线PDF转换网站安全吗?合同能传上去转吗?
- 扫描的PDF想转成能编辑的Word,必须先做OCR吗?
- 我想把一份PDF产品手册放到独立站上让Google收录,是转成网页好还是直接挂PDF?
- 权威参考资料
摘要:PDF是一种“拍扁了”的固定版式格式——它把文字、字体、排版烧成了一张张定死的页面,好处是谁打开都长一个样,坏处是想再拿出来编辑、想搬进Excel算数、想拆成图片发群里,就得“转格式”。而转格式这件事,天生是有损的,转得好不好,七成取决于你手里这份PDF是“原生”的还是“扫描”的。
保哥这篇按外贸、独立站、跨境团队天天要干的活,把PDF转Word怎么不乱版、PDF里的表格怎么准确进Excel、怎么转成PPT和图片、怎么转成网页HTML、扫描件为什么要先OCR、批量转和在线工具能不能用、转完版式崩了怎么补救,一路讲到最容易踩的坑,最后给一张“什么场景转什么格式”的对照表。看完你就不会再对着一份发不出去、改不动的PDF干瞪眼。
先说几个你大概率遇到过的场景。客户发来一份PDF报价单,让你改两个数字再发回去,可PDF死活点不动;供应商给的产品参数全在PDF表格里,你要录进自己的Excel报价系统,难道一格格手敲?老板让你把一份30页的PDF方案做成PPT去提案;又或者你想把一份产品手册转成网页挂到独立站上让Google收录。
这些需求背后是同一个动作——把PDF转成别的格式。听起来简单,真转起来你会发现:有的转完跟原文一模一样,有的转完版式稀烂、表格散架、中文变乱码。差别到底在哪?该用什么工具、什么格式?这一篇保哥讲透。
PDF为什么这么难“转”出去?先搞懂它的本质
要想转得好,得先明白PDF是个什么东西。PDF的全称是“便携式文档格式”,它最核心的设计目标只有一个:不管在谁的电脑、手机、打印机上打开,看到的版式都分毫不差。为了做到这点,它把文字的位置、字体、字号、图片、线条,全都按坐标“钉死”在每一页上。
打个比方,Word文档像一锅还在煮的汤,你随时能加料、能搅动,文字会自动重排;而PDF是把这锅汤端上桌、拍了张照片——照片里每样东西的位置永远不变,但你也没法再往照片里加盐了。这就是PDF“好分享、难编辑”的根本原因。
所以“PDF转Word”这类操作,本质是一个逆向还原的过程:工具要去猜,这张“照片”里哪些是标题、哪些是正文段落、哪些是表格、哪些是图片,再把它们重新组装成一个可编辑的文档。猜得准不准,直接决定转换质量。这也解释了一个关键事实——格式转换天生是有损的,没有任何工具能保证100% 还原,越复杂的版式,还原越容易出岔子。
这里有个最关键的分水岭,决定了你这份PDF好不好转:它是“原生PDF”还是“扫描PDF”。原生PDF是从Word、Excel、设计软件直接导出的,里面的文字是真正的文字(可以选中、可以复制),转换工具能直接读取这些文字,转出来质量高。扫描PDF是拿扫描仪、手机拍纸质文件生成的,整页其实就是一张图片,里面根本没有“文字”这个东西,工具得先靠OCR(光学字符识别)把图片里的字“认”出来,才能转。
怎么快速判断手里这份是哪种?打开PDF,试着用鼠标去选中一段文字。能像在网页上那样选中、变蓝、复制出来的,是原生PDF;怎么拖都选不中、只能像框图片一样框住一整块的,是扫描PDF。记住这个判断,后面所有转换策略都从这里分叉。
转格式之前,有哪些准备动作能省下大量返工?
很多人一拿到PDF就急着点“转换”,结果转完一堆问题再回头补救,费时费力。保哥的经验是,转之前花一两分钟做几个准备动作,能把后面的返工量砍掉一大半。
第一件事就是前面说的,先判断原生还是扫描,选一段文字看选不选得中。这个判断决定了你接下来是“轻松搬文字”还是“要跟OCR的错误较劲”,心里有数,预期也对。
第二,文件太大或只需要其中几页时,先拆分、瘦身再转。一份200页的手册你只要中间10页的表格,没必要整本转,先把那几页拆出来单独转,又快又准,还不会被其余几百页的杂乱版式拖累。文件体积大得吓人时,也可以先压缩一道再处理。怎么把PDF拆分页面、压缩瘦身、合并整理,保哥在 PDF压缩瘦身、合并拆分与页面管理那篇里讲得很细,转换前先用这套把文件收拾干净,事半功倍。
第三,扫描件先把质量整一整。歪了的页面先摆正、太淡的调一下对比度,OCR的识别率会明显提升。一份拍得歪歪扭扭、还带阴影的合同照片,直接转出来准是一团糟,花一分钟修一下源头,比转完逐字纠错划算得多。
第四,也是最该想清楚的——转出去到底要干嘛。要改文字、要算数、要发图、要上网,目的不同,转的目标格式和该用的工具完全不一样,本文最后那张决策表就是帮你把这一步定下来的。把目的先想明白,工具和格式的选择自然就收窄了,不会盲目乱试。
PDF转Word怎么转才不乱版?
PDF转Word是最高频的需求,目的几乎都是“要改里面的内容”。合同要改条款、报价单要改数字、方案要改措辞。方法有好几种,质量和适用场景差别很大,保哥按从好到差排一遍。
第一种,用Adobe Acrobat的导出功能。这是质量最高的官方途径。在Acrobat里打开PDF,选“转换/导出PDF”,目标格式选Word(DOCX),点转换就行。Acrobat是PDF的“亲爹”,对自家格式的解析最到位,原生PDF转出来的Word,段落、标题、字体、甚至大部分表格都能保住,是要交付、要正式编辑时的首选。缺点是Acrobat是付费软件。
第二种,直接用Word打开PDF。很多人不知道,新版的Microsoft Word本身就能打开PDF——文件 → 打开 → 选中PDF,Word会弹个提示说“要把它转成可编辑的Word文档”,确定即可。微软官方管这叫“PDF重排”。它对纯文字、简单排版的PDF处理得不错,胜在不用装额外软件。但遇到多栏排版、复杂表格、大量图片时,重排出来容易错位,更适合应急和简单文档。
第三种,在线转换工具。各种“PDF to Word”的网站,上传、转换、下载,方便快捷不要钱。质量参差不齐,简单文档够用,复杂的照样崩。但这里有个保哥必须重点提醒的红线:涉及合同、报价、客户信息、内部数据的PDF,绝对别往不知底细的在线工具上传。你的文件传到了别人的服务器,会不会被存、被看、被泄露,你完全不知道。外贸人手里的报价单、客户名单,一旦泄露后果很严重,这种文件要么用本地软件转,要么用大厂可信的服务。
无论哪种方法,转完都要做一件事:从头到尾过一遍,重点检查表格有没有散架、图片有没有错位、中文有没有变乱码、页眉页脚有没有串行。转换工具再聪明也会犯错,尤其是中英文混排、带复杂表格的文档。养成转完必检的习惯,能避免你把一份版式崩了的文档直接发给客户的尴尬。
PDF里的表格怎么准确转成Excel?
这是另一个超高频、也超容易翻车的需求。供应商的价格表、银行的对账单、报关单据,数据全在PDF表格里,你要把它弄进Excel去算、去筛选、去对账。手敲几百行又慢又错,必须靠转换。
原理上,PDF转Excel比转Word更难。因为Word只要还原“文字流”,而Excel要还原“行和列的网格结构”——工具得准确判断出哪些数字属于同一行、哪些属于同一列,一旦判错,几百个数字就全错位了,比不转还麻烦。
质量最高的依然是Acrobat的导出,目标格式选Excel(XLSX)。它对规整的、有清晰边框线的表格识别得相当准,能把每个单元格对应到Excel的行列里。Adobe官方文档里专门讲了PDF转Excel的设置,比如可以选择“把每页转成一个工作表”还是“整个文档一个表”,按你的对账单结构选。
但有几类表格是转换的老大难,保哥提醒你心里要有数:
- 没有边框线的表格:靠空格对齐的“伪表格”,工具很难判断列的边界,转出来经常错列。
- 有合并单元格的表格:一个格子跨了好几行或好几列,转换后结构容易乱。
- 跨页的长表格:表格从这页延续到下页,表头重复出现,转出来会夹进一堆多余的表头行。
- 扫描的表格:本质是图片,必须先OCR,识别错一个数字,整笔账就对不上了,金额类数据尤其要逐格核对。
保哥的实战建议是:转完别急着用,先拿几个关键数字跟原PDF核对一遍,尤其是金额、数量这种错不起的。转换是帮你省下敲键盘的体力,但核对的责任省不掉。保哥帮一个做工业品的客户处理过一份几百行的供应商报价PDF,转进Excel后表面看挺整齐,抽查才发现有几行因为原表格有合并单元格,价格和型号对错位了——要是没核对直接拿去报价,少不了一场扯皮。
如果你的PDF表格本身就是扫描件,或者夹在发票、单据里需要批量提取,那不只是“转格式”这么简单,更接近“从图片里把数据抠出来再结构化”,这套涉及OCR识别、批量处理和数据校验的工作流,保哥在 PDF扫描件批量OCR提取数据那篇里讲得很细,要处理发票对账单这类活的可以去看。
PDF怎么转成PPT、图片和网页HTML?
除了Word和Excel,还有几种常见的转换目标,各有各的门道。
转成PPT(PowerPoint)。需求通常是:手里一份PDF方案或报告,要拿去做提案演示。Acrobat可以把PDF导出成PPTX,每一页PDF大致对应一张幻灯片。
但说实话,PDF转PPT的还原度是几种里最不稳的——因为PPT的内核是“一个个独立的文本框和对象”,跟PDF的页面结构差得远,转出来的文字往往挤成一坨、图片错位,往往需要大量手动调整。保哥的经验是,除非原PDF本身就是从PPT导出来的,否则与其转,不如把PDF里的内容当素材、在PPT里重新排版,反而更快更好看。毕竟提案PPT讲究的是视觉和节奏,照搬一份为打印排版的PDF,演示效果通常很糟。怎么把数据和内容在PPT里排得专业、让客户一眼看懂,是另一门功夫,值得单独花时间打磨。
转成图片(JPG / PNG)。这个需求很实在:把PDF的某一页转成图片,方便发微信、发群、插进文章、做封面。Acrobat、各种工具都能把PDF按页导出成图片,能选分辨率(DPI)——发网络用72-96 DPI就够小够清晰,要打印或放大看就调到300 DPI。
转图片有个天然好处:它把内容“锁死”成了死图,谁也改不了、也没法复制里面的文字,所以也常被当成一种轻量的“防编辑”手段,比如把不想被别人改的对外文件转成图片再发。当然,真要保密还得靠加密和权限设置,这是另一回事,保哥在 PDF加密、权限与脱敏那篇里专门讲过。这里也提醒一句反面用法:把别人的文字内容转成图片再贴到网页上,搜索引擎读不到图里的字,对SEO是减分的,做内容时别图省事这么干。
转成网页HTML。这个需求相对小众但对做独立站、做内容的人很关键。比如你有一份内容很扎实的PDF白皮书、产品手册,与其让它躺在那只能下载,不如转成网页内容挂到站上,让Google能索引、能给你带搜索流量。
PDF转HTML工具会把文字、图片提取出来生成网页代码。但保哥要泼盆冷水:机器自动转出来的HTML通常很脏,一堆冗余的定位样式、语义乱七八糟,直接用对SEO和移动端体验都不友好。更稳的做法是把PDF里的文字内容提取出来,在CMS里重新排成干净的网页。至于PDF本身要不要、怎么做SEO,让Google直接收录你的PDF,保哥在 PDF怎么做SEO那篇里有完整清单。
扫描件PDF和原生PDF转出来差别为什么这么大?
前面反复提到这个分水岭,这里专门讲透,因为它是“为什么我转出来全是乱的”这个问题的头号答案。
原生PDF里的文字是“活”的——它是真正的字符数据,工具一读就知道这里写的是“产品名称”四个字。转换时直接搬运文字,又快又准。所以从Word、Excel导出的PDF,再转回去,质量通常很高。
扫描PDF完全是另一回事。你扫描一张纸、手机拍一份合同生成的PDF,每一页本质上就是一张照片,里面没有任何“文字数据”,只有像素。这时候你想转成Word去编辑,工具得先干一件事——OCR,光学字符识别,也就是让程序“看图认字”,把图片里那些笔画识别成真正的文字。认对了,才谈得上转换。
OCR这一步会引入新的错误,而且这些错误很隐蔽。常见的翻车点有这么几类:
- 形近字认错:数字0和字母O、数字1和字母l、中文里的“未”和“末”,OCR经常分不清,金额、型号、单号里出现这种错,杀伤力极大。
- 扫描质量差:原件有污渍、折痕、字迹模糊、扫描歪了,识别率断崖式下跌。
- 复杂版式认乱:多栏排版、表格、手写体,OCR容易把阅读顺序搞错,把两栏文字串成一行。
- 中文识别难度高于英文:汉字字形复杂、字库大,中文OCR的准确率天然比英文低一截,中英混排更考验工具。
保哥就吃过这个亏的反面教材:一个客户把供应商的扫描版价格表转进Excel,里面一个型号“SKU-1008”被OCR认成了“SKU-l00B”(数字1认成字母l、数字8认成字母B),导入系统时这条死活匹配不上,排查了半天才发现是识别错了一个字符。金额、单号、型号这些“一个字符都错不起”的数据,扫描转换后必须逐个核对,这不是谨慎,是必须。
所以结论很明确:如果你能拿到原生PDF,千万别用扫描件去转。保哥见过有人手里明明有电子版报价单,嫌找麻烦,直接把打印件扫描了再转,结果一堆数字识别错,反而花更多时间核对。能要到电子原件,永远是上策。实在只有扫描件,那转换后必须逐字逐数核对关键信息,把它当成“OCR给的草稿”,而不是“可信的结果”。
批量转换和在线工具到底能不能用?
实际工作里经常不是转一份,而是一堆。比如几十份供应商PDF报价单要统一转成Excel,上百张扫描发票要批量提取。一份份手动转,人会疯。这就涉及批量转换。
批量转换的能力,主要看工具。Acrobat的“批处理/动作向导”能设定一套动作,对一整个文件夹的PDF挨个执行同样的转换。一些专业的文档处理软件、甚至命令行工具,也支持批量。对于跨境团队天天要处理大量单据的场景,搭一套批量转换流程,能省下大把人力。
保哥帮一个做家居出口的客户理过一回这种活:他们每月从十几家供应商收来报价PDF,格式各不相同,原来靠人一份份手敲进Excel比价,两个人干两天还出错。后来发现其中有八家供应商的报价单是固定模板生成的、结构一致,就对这八家走批量转换,剩下几家版式乱的才人工处理,整体效率翻了几倍。这就是批量的正确打开方式——把结构一致的归一拨批量处理,把版式杂乱的挑出来单独搞,而不是指望一套设置吃掉所有文件。
但批量转换有个前提常被忽略:这批PDF的结构得足够一致。如果它们版式五花八门——有的有边框有的没有、有的单栏有的双栏、有的是原生有的是扫描,那一套统一的转换设置不可能对每份都奏效,批量转完还是得一份份检查,省不了多少事。批量最适合“同一个模板生成的一批文件”,比如同一个系统导出的一批对账单。
再说在线工具。它的最大优点是零门槛——不用装软件、跨平台、手机也能用,临时转一份特别方便。但保哥要把那条红线再划一遍,而且加重:
- 敏感文件绝不上传:合同、报价、客户名单、财务数据、含个人信息的文件,传到陌生服务器等于把家底交出去。涉及客户隐私的,还可能踩GDPR这类数据合规的雷。
- 认准来源:要用在线工具,也尽量用大厂、口碑可信的服务,看清楚它的隐私政策怎么说处理你的文件,是不是用完即删。
- 本地优先:但凡文件涉密、或者要长期高频处理,老老实实用本地软件,文件不离开你的电脑,最安心。
保哥的原则很简单:不重要、不敏感的文件,在线工具随便用图个方便;但凡沾一点商业机密或客户隐私,一律本地处理。这条线划清楚,能帮你躲掉很多看不见的风险。
转换后版式错乱、字体丢失怎么补救?
前面说了转换天生有损,那转完发现版式崩了、字体变了、表格散了,该怎么救?保哥按常见问题给几个实用招。
版式整体错乱、文字框乱跑。这通常是原PDF版式太复杂、工具还原不到位。补救的思路不是去一点点挪文本框,而是换个方法或工具重转一遍——比如Word直接打开转得乱,换Acrobat导出试试;这家在线工具转崩了,换一家。不同引擎对同一份PDF的处理能力不一样,多试一个常有惊喜。实在不行,就只把文字内容复制出来,在新文档里重新排版,比硬改一份崩掉的文档快。
中文变成方框或乱码。这几乎都是字体问题——原PDF用了某种字体,转换或打开的设备上没装这个字体,就显示成方框(俗称“豆腐块”)或乱码。解法:在转换设置里勾选“嵌入字体”,或者转完后把文字字体统一改成系统都有的常见字体(比如宋体、微软雅黑、思源黑体)。做对外文件时,字体兼容性要特别留意,别在你电脑上好好的,发给客户全是方框。
表格散架、数据错位。如果是没边框的表格转崩了,一个实用技巧是:先给原PDF想办法加上表格边框线(或在转换工具里手动框选表格区域、标出列的位置,很多专业工具支持),再转,识别率会高很多。要是数据量不大,错位几个格子,手动挪回来反而最快。
图片丢失或变模糊。转换时图片被压缩或丢失,检查转换设置里有没有“图片质量/分辨率”选项,调高再转。
说到底,补救的核心心法就一句:转换不是一锤子买卖,转得不好就换工具、换方法重来,或者退一步只保内容、重排版式。别在一份已经崩掉的文档上死磕。
不同场景到底该转成什么格式?
讲了这么多,最后给一张保哥常用的决策对照表,帮你按目的快速选对转换方向,少走弯路。
| 你的目的 | 转成什么 | 注意事项 |
|---|---|---|
| 要改文字内容(合同、报价、方案) | Word(DOCX) | 原生PDF用Acrobat导出质量最高,转完通检版式 |
| 要算数、筛选、对账(价格表、对账单) | Excel(XLSX) | 转完必核对关键数字,警惕无边框/合并/跨页表格 |
| 要做提案演示 | PPT或干脆重做 | 还原度最差,多数情况重排比转更快更好 |
| 要发群、插文章、做封面 | 图片(JPG/PNG) | 按用途选DPI,网络用72-96,打印用300 |
| 要挂到独立站做SEO | 提取内容重排成HTML | 别用机器转的脏代码,CMS里重新排干净 |
| 要长期归档、保证不变样 | 保持PDF不转 | 归档就用PDF/A,PDF本就是为此而生 |
这张表背后有个一以贯之的逻辑:先问清楚“转出去要干嘛”,再决定转成什么、用什么工具。很多人一上来就纠结“哪个转换工具最好”,其实工具是次要的,目的才是第一位的。要改内容就转Word,要算数就转Excel,要锁死就转图片——目的对了,工具的选择自然就收窄了。
再叠加那条贯穿全文的判断:手里是原生还是扫描?原生的放心转,扫描的先掂量OCR的坑、转完逐字核对。把“目的”和“原生还是扫描”这两个判断刻进脑子,PDF转格式这件事你就基本不会翻车了。
转换里最容易踩的坑有哪些?
把保哥这些年自己踩过、帮人填过的坑集中列一遍,转之前对一遍,能少走特别多弯路:
- 有电子原件却拿扫描件转:能要到原生PDF或Word/Excel源文件,永远别用扫描件折腾OCR,这是最大也最常见的自找麻烦。
- 转完不核对就用:尤其是Excel里的金额、数量,OCR和表格识别都会错,不核对直接用会出大事。
- 敏感文件传在线工具:合同、客户数据、财务信息上传陌生网站,泄露风险和合规风险一起来。
- 字体没嵌入,对外发全是方框:自己电脑显示正常,到了客户那中文变豆腐块,转换和导出时留意字体兼容。
- 指望PDF转PPT一步到位:还原度最差,多数情况重排比硬转划算。
- 无边框表格直接转Excel:列边界判不准,数据错位还不易察觉,先加边框或手动框选列。
- 跨页长表格转出一堆重复表头:转完记得删掉夹在数据里的重复表头行。
- 用机器转的脏HTML直接上线:代码冗余、不利SEO和移动端,内容提取出来重排更稳。
- 图片分辨率没设,转出来发虚或文件超大:按用途调DPI,网络和打印的标准不一样。
- 在崩掉的文档上死磕:版式严重错乱时,换工具重转或只保内容重排,比硬修快得多。
PDF转格式这件事,门槛看着低——上传、点转换、下载,三步谁都会。但要转得又快又对,关键就在这几个判断上:搞清PDF的本质是“拍扁的固定版式”、分清原生还是扫描、按目的选对目标格式、对敏感文件守住本地处理的底线、转完该核对就核对。把这几条养成肌肉记忆,你处理PDF的效率和靠谱程度,会和那些只会“上传转换下载”碰运气的人,拉开明显的差距。
最后保哥多说一句心法:PDF之所以是PDF,就是为了“不被改、到哪都一样”而生的。所以最省事的策略,其实是从源头上少制造“需要回转”的麻烦——重要的可编辑文件,自己手里始终留一份Word/Excel源文件,别只存PDF;要长期归档不变样的,就让它安心待在PDF里别折腾。真正非转不可时,再用上面这套判断认真转。把功夫下在源头,比事后跟一份崩掉的转换结果较劲,聪明得多。
常见问题解答
为什么同样一份PDF,我转出来的Word全是乱的,别人转的却很整齐?
九成的差别在两点。第一,你那份很可能是扫描件(图片型PDF),别人那份是原生PDF(文字可以选中复制)。扫描件得靠OCR认字,版式和文字都容易出错;原生PDF直接搬运文字,自然整齐。你可以试着选中文字,选得中就是原生、选不中就是扫描。第二,用的工具不一样。Adobe Acrobat这类专业工具的还原引擎,比一些免费在线工具强不少,尤其是复杂版式。如果你确定是原生PDF转出来还乱,换个工具(比如Acrobat导出,或Word直接打开)重试一次,结果常常天差地别。
PDF转Excel后数字总是错位、对不上,有什么办法?
这通常是表格结构没被正确识别。重点排查几类:表格有没有边框线(没边框的“伪表格”最容易错列)、有没有合并单元格、是不是跨页长表格(会夹进重复表头)、是不是扫描件(OCR认错数字)。补救办法:用Acrobat等专业工具,转换时手动框选表格区域、标出列的位置,识别率会高很多;或者给原PDF先加上边框线再转。最关键的一条铁律是:转完一定要拿几个关键数字跟原PDF核对,金额、数量这种错不起的,逐格核对。转换帮你省敲键盘的力气,但核对的责任省不掉。
用免费的在线PDF转换网站安全吗?合同能传上去转吗?
不重要、不敏感的文件可以用,图个方便;但合同、报价单、客户名单、财务数据这类,绝对别传。你的文件上传后会到对方的服务器,会不会被存储、被查看、被泄露,你完全无法控制。外贸场景里报价、客户信息一旦外泄后果很严重,涉及个人信息的还可能踩GDPR这类合规红线。保哥的原则:沾一点商业机密或客户隐私的,一律用本地软件转,文件不离开自己电脑。非要用在线工具,也认准大厂可信服务,看清它是不是用完即删。
扫描的PDF想转成能编辑的Word,必须先做OCR吗?
是的,没有捷径。扫描件每一页本质是张图片,里面没有真正的文字数据,工具必须先用OCR把图片里的字识别成文字,才谈得上转换和编辑。现在很多转换工具(包括Acrobat)已经把OCR集成进去了,你选转换它会自动先OCR,但你要清楚这一步引入了新的错误风险——形近的0和O、1和l容易认错,中文识别率天然比英文低,扫描质量差时更糟。所以扫描件转出来的内容,一定要当成“草稿”逐字核对,尤其是数字、单号、金额。能拿到电子原件的话,永远别用扫描件折腾。
我想把一份PDF产品手册放到独立站上让Google收录,是转成网页好还是直接挂PDF?
两条路都行,但各有讲究。转成网页(HTML)的好处是体验好、移动端友好、SEO可控性强,但别用工具机器自动转——转出来的代码很脏,冗余样式一堆,反而不利于SEO和移动端。正确做法是把PDF里的文字内容提取出来,在你的CMS里重新排成干净的网页。如果就想让PDF本身被Google收录、带来下载,那也完全可行,PDF是能被搜索引擎索引的,但要做对一些优化(文件名、标题、内部有真实文字而非扫描图、被站内链接指向等)。保哥在PDF怎么做SEO那篇里列了完整的6条优化清单,按目的选一条路走就行。
权威参考资料
本文标题:《PDF怎么转成Word、Excel、PPT和图片才不乱版?格式互转实战》
本文链接:https://zhangwenbao.com/pdf-convert-word-excel-ppt-image-html-format-conversion.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0