HTML转纯文本工具怎么用?把网页内容剥成干净文本做分析
本文目录
- HTML转纯文本工具到底是做什么的?
- 它是怎么把标签剥干净的?分三步走
- 为什么script和style要连内容一起删掉?
- 块级元素为什么要转成换行,而不是直接删?
- 标题的层级会丢吗?这条得心里有数
- 列表的圆点符号是怎么保下来的?
- 表格怎么变成能贴进Excel的格式?
- 链接是只留文字,还是连网址一起留?
- 图片没了,alt描述还能留住吗?
- 那些转义实体,是怎么还原成正常字符的?
- 三种换行模式,压缩、单行、正常该选哪个?
- 多余的空格和空行,是怎么清理干净的?
- 怎么用它做一次完整的HTML清洗?
- SEO场景一:采集竞品内容做拆解分析
- SEO场景二:把脏HTML洗成干净文本喂给AI
- SEO场景三:富文本编辑器导出纯文本做存档与邮件版
- 它处理不了JS渲染的内容,这条必须知道
- CSS隐藏的文字,它会照样提取出来吗?
- 复杂表格为什么会错位?
- 它和专业的正文提取算法有什么不同?
- 块级元素到底包括哪些标签?
- 输入有大小限制吗?太大的网页能处理吗?
- 为什么纯文本比HTML更适合做内容工作?
- 转换的统计数字里,藏着页面臃肿的信号
- 要拆解一批竞品页面,怎么提高效率?
- 实战案例:假发接发出海站的竞品页拆解
- 内容素材清洗三件套:剥文本只是第一步
- 常见问题解答
- HTML转纯文本和直接复制网页文字有什么区别?
- 转出来的文本里还有奇怪的乱码符号,是怎么回事?
- 它能保留文章的标题层级(一级标题、二级标题)吗?
- 用JavaScript框架做的网站,为什么转出来是空的?
- 清洗后的纯文本,下一步通常做什么?
- 权威参考资料
摘要:从网页上扒下来的内容,满是标签、脚本、样式和乱码实体,想拿来分析、存档或者喂给AI,第一步都得先洗成干净的纯文本。这篇用一个HTML转纯文本工具当例子,把它背后那套剥标签的逻辑讲透——它怎么把script和style整段删掉、把块级元素转成换行、把列表的圆点和表格的分隔保下来、把那些转义实体还原成正常字符。顺带掰扯清楚几件容易踩坑的事:标题层级为什么会丢、CSS隐藏的文字它会不会照样提出来、JS渲染的内容它为什么够不着,以及在SEO里它怎么帮你做竞品内容拆解、清洗素材喂AI、富文本导出存档这些活儿,又有哪些它根本做不到。
做内容、做SEO,免不了要跟网页源码打交道。你可能想把竞品的产品描述扒下来对比一下,可能想把一篇富文本编辑器里写的稿子导成纯文本备份,也可能想把一段网页内容塞给AI去分析。但凡涉及“从HTML里把文字抠出来”,你都会撞上同一个问题:原始HTML里塞满了标签、脚本、内联样式,还有一堆以和号开头的转义实体,直接看一团糟,直接用更是没法用。
这种把HTML洗成纯文本的脏活累活,交给一个HTML转纯文本工具最省心。你把网页源码贴进去,它一处理,标签没了、脚本没了、实体还原了,留给你的是一份干干净净、能直接读能直接用的文字。这篇就用一个这样的工具当例子,把它怎么剥标签、怎么保结构、在SEO里怎么用、又有哪些边界,一条条讲明白。
HTML转纯文本工具到底是做什么的?
它的定位很直接:输入一段HTML源码,输出一份格式化过的纯文本。所谓“格式化过”,是说它不只是粗暴地把尖括号里的东西全删光,而是带着点脑子——该删的脚本样式整段删,该换行的段落标题转成换行,列表的圆点、表格的分隔这些有意义的结构尽量保下来,让你拿到的文本既干净又不至于糊成一坨。
换句话说,它要解决的是“内容和噪声混在一起”的问题。一个网页里,真正有价值的是正文文字,但这些文字被埋在层层标签、脚本、样式之间。工具的活儿,就是把噪声剥掉、把内容留下,还顺手保留一点必要的结构感。对要反复处理网页内容的人来说,这是个能省下大量手工删改时间的工具。
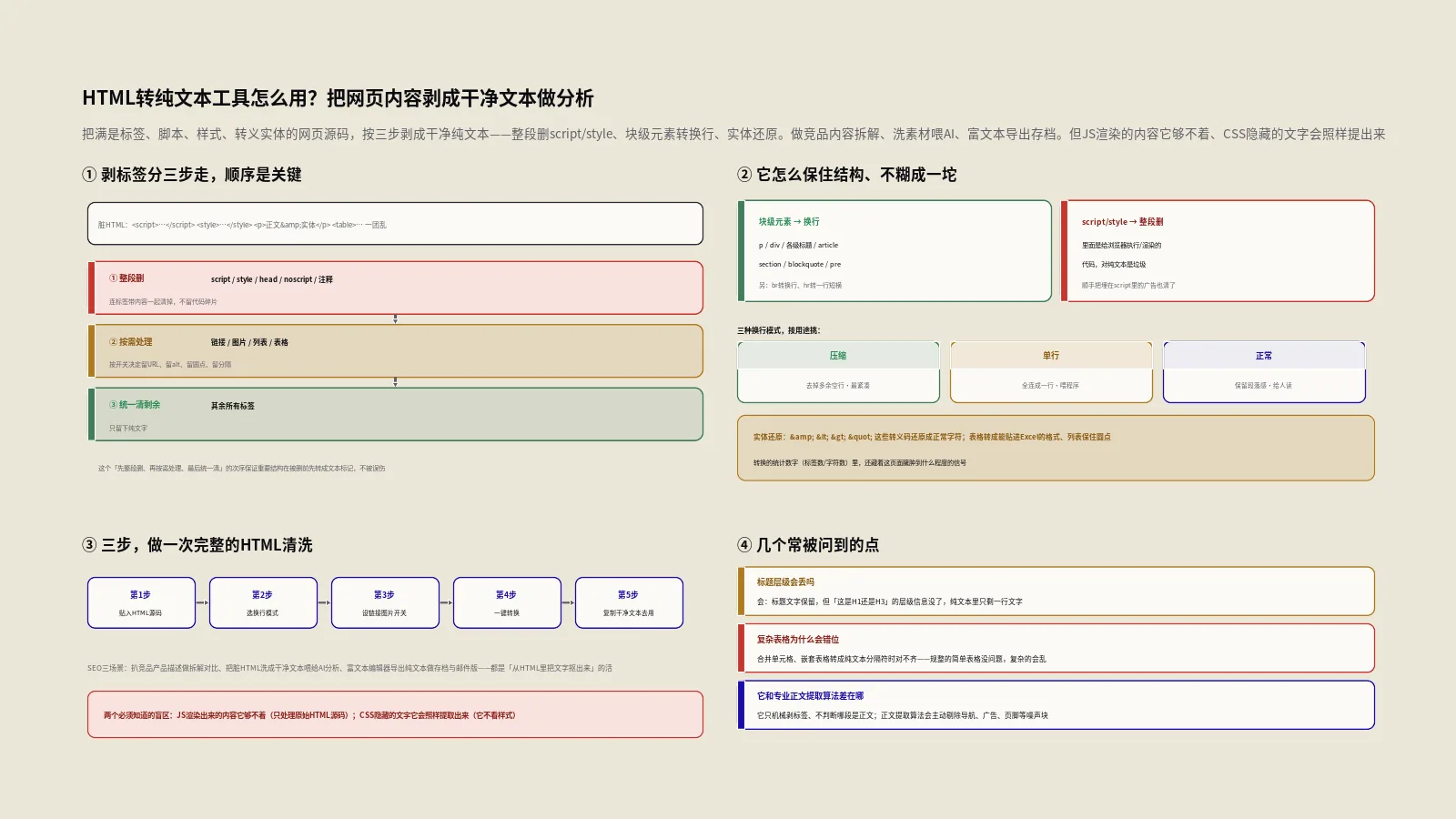
它是怎么把标签剥干净的?分三步走
这个工具剥标签不是一刀切,而是分阶段处理,顺序很关键。第一步,先用正则把那些“内容也不要”的标签整段删掉——script脚本、style样式、head头部、noscript,还有HTML注释。这些标签里的东西对纯文本毫无意义,连标签带内容一起清掉。
第二步,是按你的选项做有条件的处理——链接要不要保留URL、图片要不要留alt、列表要不要留圆点、表格要不要留分隔,这些都在这一步按开关决定。第三步,才是把剩下的所有标签统一清除,只留下纯文字。这个“先整段删、再按需处理、最后统一清”的三段式,保证了重要结构在被删之前先被转换成对应的文本标记,不会被误伤。
为什么script和style要连内容一起删掉?
有人会问:剥标签不就是去掉尖括号吗,为什么script和style要把里面的内容也一并删了?因为这两类标签里装的根本不是给人看的文字。script里是JavaScript代码,style里是CSS样式规则,它们是写给浏览器执行和渲染用的,对一份“给人读的纯文本”来说是纯粹的垃圾。
如果只删标签不删内容,你会得到一堆`function() { var x = ...}`的代码碎片和`.class { color: red }`的样式片段,混在正文里惨不忍睹。所以工具的处理是连标签带内容整段删除,一干二净。这也是为什么它能很好地去掉网页里的广告代码——大多数广告埋在script标签里,整段删掉的同时,广告也跟着没了。
块级元素为什么要转成换行,而不是直接删?
段落、标题、div、列表项这些块级元素,如果只是简单删掉标签,你会发现原本分成好几段的文字全黏成了一行,读起来要人命。所以工具对块级元素的处理不是删,而是转——把它们转成换行符。
这背后是HTML对元素的一个基本分类:块级元素天生就会另起一行、独占一行的水平空间,段落与段落之间、标题与正文之间,视觉上本就是分开的。工具把这种“视觉上的分行”翻译成纯文本里的“换行符”,正文的段落感就保住了。它处理的块级标签是一长串,包括p、div、各级标题、article、section、header、footer、blockquote、pre这些,外加单独的br换行标签转成换行、hr分隔线转成一行短横线。这样转完,纯文本读起来还是一段一段的,不会糊成一团。
标题的层级会丢吗?这条得心里有数
这里有个要诚实交代的局限:标题会保留,但标题的层级信息会丢。工具把h1到h6全都一视同仁地转成换行,并不会像Markdown那样在标题前加井号、也不会用缩进来体现“这是一级标题、那是二级标题”的层级关系。
这意味着,如果你的目的是从网页里提取出一份带层级的大纲(比如想还原文章的目录结构、或者分析竞品文章的H标题骨架),这个工具帮不了你——它给你的是“标题文字独占一行”,但哪行是大标题、哪行是小标题,看不出来。要做标题层级分析,得用专门看HTML骨架的工具。这个工具的定位是“把内容洗成可读文本”,不是“解析文档结构”,两个目标不一样,别用错。想做HTML结构层级审计,可以看我们拆过的HTML结构分析器的方法,它专门干提取标题骨架这件事。
列表的圆点符号是怎么保下来的?
列表是网页里很常见的结构,一个个并列的要点,如果转纯文本时把列表标记全丢了,几个要点就黏成一段,读者分不清这是分点陈述还是一整段话。所以工具给了个选项:保留列表结构。
勾上之后,每个列表项前面会加上“两个空格加一个圆点”的标记,也就是常见的项目符号样式。这样转出来的纯文本里,列表项依然是一行一个、前面带圆点,视觉上的“这是一份清单”的感觉就保住了。这个细节看着小,但对保留内容的可读性很重要——尤其是产品页的卖点清单、教程的步骤列表这类内容,圆点一保留,结构立马清晰。如果你不勾这个选项,列表项就只剩纯文字,圆点和缩进都没了。
表格怎么变成能贴进Excel的格式?
表格是HTML里最麻烦的结构之一,二维的数据硬要塞进一维的纯文本,怎么处理都有损失。这个工具的做法是用制表符和换行来还原表格的行列关系:每个单元格之间用制表符(也就是Tab)分隔,每一行结束用换行。
这么处理有个很实用的好处——制表符分隔的文本,直接复制粘贴进Excel或者Google表格,会自动按制表符拆分到不同的列里,表格结构基本能还原。所以如果你想从网页上扒一个数据表格下来整理,用这个工具转一下,再贴进表格软件,比手工一格格抄快得多。不过要提醒,这个处理对简单的二维表格管用,遇到那种有合并单元格、嵌套表格的复杂报表,就会错位,这个后面单独说。
链接是只留文字,还是连网址一起留?
网页里的超链接,转纯文本时怎么处理是个选择题:是只保留链接的文字、把网址扔掉,还是把网址也留下来?工具给了个开关让你自己定。
不勾保留链接,那就只留下链接的显示文字,网址丢掉,文本最干净。勾上保留链接,工具会把链接转成“显示文字加上圆括号包起来的网址”这种格式,也就是文字后面紧跟一对圆括号、里面装着网址,这样你既看到了链接文字,也知道它指向哪。这里还有两个贴心的处理:如果链接没有显示文字,就只留网址;如果显示文字本身就是网址,那就不重复,只留一个。什么时候该保网址?如果你是要把内容存档、或者做成邮件的纯文本版,链接的目标地址往往很重要,勾上保留更稳妥;如果只是要正文文字做分析,不勾更清爽。
图片没了,alt描述还能留住吗?
纯文本里显然没法放图片,但图片的alt替代文字往往是有信息量的——它描述了图片的内容。工具给了个选项,让你决定要不要把alt留下来。
勾上保留图片,工具会把每个图片转成一个带方括号的标记,方括号里是“图片”二字加冒号再加alt文字,比如显示成“图片:红色连衣裙正面图”这样,这样图片的位置和它的描述就在文本里留了个痕迹。如果图片没有alt,就只留一个“图片”占位标记。要注意,它只提取alt这一个属性,图片的真实地址src、尺寸、标题title这些都不管。对SEO来说,alt文字本就是图片优化的重点,能把它单独提出来扫一遍,顺便也能检查竞品的图片alt写得怎么样。不勾这个选项,图片就彻底没了,一点痕迹不留。
那些转义实体,是怎么还原成正常字符的?
从网页扒下来的文本里,经常夹着一串以和号开头、分号结尾的转义码——比如表示不间断空格的那种、表示和号本身的、表示尖括号的、表示长破折号的,这些叫HTML实体,是网页里用来表示特殊字符的转义写法。如果不还原,纯文本里就会留着这些奇怪的代码,很碍眼。工具用两层处理来还原它们。
第一层是对最常见的一批实体做快速替换——把不间断空格的实体换成空格、把和号的实体换成普通和号字符、把尖括号的实体换成尖括号、把长破折号、省略号、版权符的实体都换成各自对应的字符,等等。第二层是兜底,调用一个标准的解码函数把剩下的、尤其是数字形式的实体(比如表示欧元符号的那种数字编码)也一并还原。
这个第二层兜底用的标准函数,就是PHP的html_entity_decode官方函数,它能把各种有效的命名实体和数字实体转回对应的字符。两层一配合,常见的快、生僻的也不漏,最后给你的文本里就不会再有这些转义代码了。
三种换行模式,压缩、单行、正常该选哪个?
转出来的纯文本,换行该怎么排,工具给了三种模式应对不同需求。第一种是正常模式,也是默认的——每行内部的多余空格折叠成一个,段落之间的空行保留但不让它无限多,超过三行连续空行会被压到两个空行,读起来既分段清晰又不至于到处是大片空白。
第二种是单空行模式,比正常模式更紧凑,段落之间最多留一个空行,把多余的空行进一步压掉,适合你想要内容连贯、不要太多留白的场景。第三种是压缩模式,最狠——所有换行和多余空格全合并成单个空格,整段内容挤成一行,适合你只要文字、完全不在乎排版,比如要把内容当成一个连续的字符串去处理的时候。日常做内容分析、存档,用默认的正常模式就好;要喂给AI做prompt、想分段清晰,单空行模式不错;要当数据处理,压缩模式最方便。
多余的空格和空行,是怎么清理干净的?
网页源码里,因为缩进、格式化的缘故,往往有大量多余的空格、制表符和空行,剥完标签如果不清理,纯文本里就会东一块空白西一块空行,乱七八糟。工具对此有专门的清理。
对行内的多余空格,它把连续的多个空格、制表符统一折叠成一个空格。对空行,它默认会把超过三行的连续换行压到两个空行(也就是中间留一个空行),避免出现大片空白。如果你嫌空行碍事,还有个“删除空行”的选项,勾上之后所有完全的空行都被清掉,只留有内容的行,文本最紧凑。这些清理逻辑加起来,保证了你拿到的纯文本是规整的——该分段的地方分段,不该留白的地方不留白。
怎么用它做一次完整的HTML清洗?
把这个工具用顺手,其实就几步,这里给一套可以照搬的流程。
- 拿到HTML源码。在浏览器里对着目标内容右键“查看页面源代码”或“检查”,把相关的HTML片段复制下来,贴进工具的输入框。
- 按需求设置选项。要做内容分析、不在乎链接图片,就都不勾,要最干净的正文;要存档或做邮件版,勾上保留链接;想留图片描述,勾上保留图片;内容里有清单、表格,勾上对应的保留选项。
- 选换行模式。常规清洗用默认的正常模式;要喂AI用单空行;要当数据处理用压缩模式。嫌空行多就再勾上删除空行。
- 点转换、看结果。工具会输出处理好的纯文本,同时给你一组统计——原始HTML多大、纯文本多大、压缩了多少、删了多少标签,对清洗效果有个量化的判断。
- 复制或下载。确认文本干净了,直接复制走,或者下载成txt文件存档。需要进一步分析字数、可读性的,再拿去下一个工具处理。
这套流程的核心是“先想清楚你要这份文本干嘛,再据此设选项”——目的不同,链接图片留不留、换行多紧凑,选择都不一样,没有一套设置能通吃所有场景。
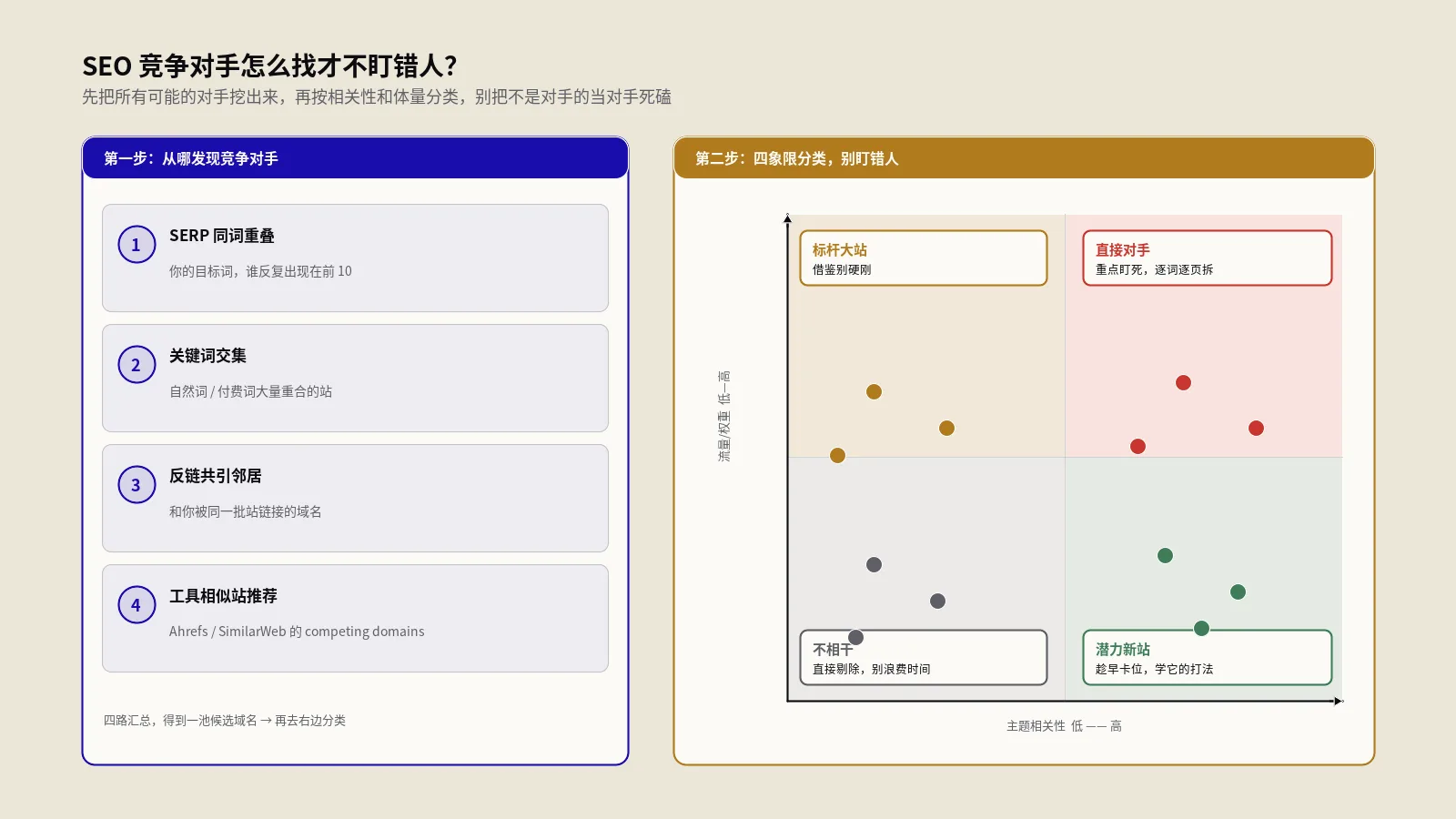
SEO场景一:采集竞品内容做拆解分析
做SEO,研究竞品是基本功。竞品的某个排名很好的页面,正文写了多少字、覆盖了哪些点、用了什么结构,都是值得拆解的情报。但你总不能对着满是标签的源码去数,得先把正文洗成纯文本。
用这个工具,把竞品页面的HTML贴进去,剥成纯文本,你就能清楚地看到它的正文内容,再拿去数字数、看结构、提关键词。这里要诚实划一条线:采集竞品内容来做分析、找差距、定选题,这是正当的研究;但如果你把扒下来的内容整段搬运、改头换面发到自己站上,那就触碰红线了。
Google明确把这种没有附加价值的整段复制定义为抓取式垃圾内容,Google搜索中心的垃圾内容政策里专门讲了,哪怕你做了改写、洗了稿,只要没有提供原创的见解、数据或视角,照样可能被判为重复或抓取内容而降权。工具是用来做研究的,不是用来抄的,这条底线得守住。
SEO场景二:把脏HTML洗成干净文本喂给AI
现在很多SEO工作都要借助AI——让AI帮你分析一段内容、总结要点、提炼大纲、甚至改写。但如果你直接把带满标签的HTML丢给AI,会有两个问题:一是标签噪声会干扰AI对内容的理解,二是这些标签白白占用了宝贵的token额度。
先用这个工具把HTML洗成纯文本再喂给AI,效果明显更好。AI对纯文本的理解准确度,本就高于对夹杂标签的源码。具体设置上有几个建议:保留链接可以打开,让AI知道内容里引用了哪些参考;保留图片建议关掉,图片的alt对纯文字分析意义不大,关掉能省内容;换行模式选单空行,段落之间清晰,方便你在prompt里做分段。洗干净再喂,AI给你的分析和总结质量会扎实不少,token也花得更值。
SEO场景三:富文本编辑器导出纯文本做存档与邮件版
用WordPress、Notion、语雀这类富文本编辑器写的内容,底层都是HTML。有时候你需要它的纯文本版——比如要做内容的长期纯文本存档、要生成邮件的text/plain版本、要把内容迁移到一个不支持富文本的系统里。这时候就需要把富文本的HTML转成纯文本。
把富文本编辑器里的HTML导出来贴进工具,转成纯文本,就能拿到一份不依赖任何格式的文字版。做邮件纯文本版时,建议保留链接,让收件人在纯文本客户端里也能看到链接地址;换行用正常模式,保留段落感,读起来舒服;勾上删除空行,压掉多余留白,邮件体积也小一点。一份干净的纯文本存档,不依赖任何编辑器和格式,几年后照样能打开能读,比锁死在某个平台里的富文本可靠得多。
它处理不了JS渲染的内容,这条必须知道
这是个根本性的局限,用之前必须心里有数:这个工具只处理你给它的HTML源码本身,它不执行JavaScript。它对script标签的处理是直接整段删掉,根本不会去解析、更不会去运行里面的代码。
这意味着什么?现在很多网站是用React、Vue这类前端框架做的,页面的正文内容不是写死在HTML源码里,而是靠JavaScript在浏览器里动态渲染出来的。这种页面,你“查看源代码”拿到的初始HTML里,正文位置可能是空的,真正的内容要等JS跑完才出现。把这种空壳HTML丢给工具,它转出来自然也是空的——因为源码里压根没有那些文字。遇到JS渲染的站,正确的做法是用浏览器的“检查”功能去复制渲染后的DOM,而不是“查看源代码”复制初始HTML,这样才能拿到真正的内容。
CSS隐藏的文字,它会照样提取出来吗?
这是个容易想当然的地方,得说清楚。有人以为,网页上用CSS隐藏掉的文字(比如设了display:none不显示的内容),工具会聪明地把它过滤掉。事实恰恰相反——它会照样把这些文字提取出来。
原因还是那条:它只处理HTML源码,不解析CSS。一段文字是不是被CSS隐藏了,得靠解析样式规则才知道,而工具不干这事。只要这段文字写在HTML源码里,哪怕它被CSS设成了不可见,工具照样会把它当正文提出来。这是它的工作方式决定的,不是bug。
这一点用的时候要留神:你转出来的纯文本,可能包含一些页面上肉眼看不到的隐藏文字。如果你是在分析竞品,这反倒可能帮你发现一些藏起来的内容;但如果你是在清洗自己的素材,就得手工把这些隐藏文字的残留删掉。诚实地说,工具做的是“源码层面的文本提取”,不是“所见即所得的可见内容提取”,这两者有区别。
复杂表格为什么会错位?
前面说了表格会用制表符和换行还原,但也提了一句复杂表格会错位,这里展开讲讲为什么。问题出在合并单元格上——HTML表格可以让一个单元格横跨好几列、或者纵跨好几行(也就是colspan和rowspan)。
但纯文本的“制表符分隔加换行”是个规整的二维网格,没法表达“这个格子占了三列”这种结构。工具遇到合并单元格,只能按它看到的标签老老实实地转,结果就是行与行之间的列对不齐,数据错位。嵌套表格(表格里还套着表格)就更乱了。所以这个工具的表格处理,适用范围是“规整的简单二维表”——没有合并、没有嵌套的那种。遇到结构复杂的报表,转出来多半要手工再调。知道这个边界,就不会拿它去硬啃复杂表格然后抱怨结果乱。
它和专业的正文提取算法有什么不同?
有一类更高级的技术叫正文提取(也叫去模板、去样板),代表是各种Readability类的算法,浏览器的“阅读模式”、稍后读应用背后用的就是这类技术。它们能从一个完整的网页里,智能地识别出“哪块是正文、哪块是导航栏、哪块是侧边栏广告”,只把正文抠出来。
这个HTML转纯文本工具,和那类算法不是一回事。它做的是“把你给的这段HTML里的所有文字都转成纯文本”,并不会去判断哪些是正文、哪些是导航。如果你把整个网页的源码贴进去,它会连导航菜单、页脚链接、侧边栏一起转出来,正文混在里面。所以用它做正文提取时,得靠你自己先把正文那块HTML挑出来再贴进去,它负责“转”,不负责“挑”。这是它和Readability类算法最大的区别——一个是听话的转换器,一个是智能的内容识别器,各有各的用处,别拿转换器去要求识别器的能力。
块级元素到底包括哪些标签?
前面反复提到“块级元素转换行”,那到底哪些算块级元素?这其实是HTML里一个挺基础但容易记混的分类。块级元素的特点是:它总是另起一行,并且在水平方向上会尽量占满父容器的宽度,从而形成一个独立的“块”。
常见的块级元素,包括段落p、各级标题h1到h6、通用容器div、列表和列表项、表格、引用块blockquote、预格式化块pre,还有HTML5里那些语义化的结构标签比如article、section、header、footer、nav、aside等等。
与之相对的是行内元素,比如强调em、加粗strong、超链接a、图片img,它们不会另起一行,只是嵌在文字流里。工具正是依据这个分类来决定“转换行还是不换行”的。想看块级元素的完整定义和它和行内元素的区别,可以查MDN关于块级内容的词条,它把这个分类讲得最权威清楚。
输入有大小限制吗?太大的网页能处理吗?
工具对单次输入的HTML大小是有上限的,大约是两兆字节。这个限制是为了防止超大的输入把处理拖垮,对绝大多数场景来说完全够用——一个普通网页的HTML源码通常也就几十到几百KB,离两兆还差得远。
什么时候会撞上这个限制?如果你想一次性处理一个内容极多的页面,或者把好几个页面的源码拼在一起贴进去,有可能超。遇到这种情况,拆开分批处理就好。日常清洗单个页面的内容,根本碰不到这个天花板。顺带一提,工具还支持直接抓取一个URL的内容来转,但抓的是服务器返回的初始HTML,对前面说的JS渲染的站同样无能为力——抓回来还是空壳,这点要记着。
为什么纯文本比HTML更适合做内容工作?
绕了这么大一圈,值得退一步想想:我们费劲把HTML转成纯文本,图的到底是什么?核心是纯文本的“干净”和“通用”。干净,是说它剥掉了所有跟内容无关的噪声,剩下的全是文字本身,无论是人读、机器分析还是AI处理,都不受干扰。
通用,是说纯文本不依赖任何特定的软件、格式、平台,任何系统、任何年代都能打开能读,是信息最稳妥的保存形态。做内容分析时,纯文本让你能专注于文字本身去数字数、看结构、提要点;做存档时,纯文本是最抗时间的格式;喂给AI时,纯文本噪声最低、token最省。HTML适合展示,纯文本适合处理——当你的目的是“处理内容”而不是“展示内容”时,先转成纯文本几乎总是对的第一步。这也是为什么内容清洗会成为很多SEO工作流的起点。
转换的统计数字里,藏着页面臃肿的信号
工具转换完,除了给你纯文本,还会附一组统计数字:原始HTML有多大、转出的纯文本有多大、压缩了百分之多少、删掉了多少个标签。这组数字别看着不起眼,里面藏着对SEO有用的信号。
最值得关注的是压缩比——纯文本占原始HTML的比例。如果一个页面剥完标签,纯文本只剩原始体积的零头,说明这个页面的HTML里,真正的文字内容占比极低,绝大部分都是标签、脚本、内联样式这些“壳”。HTML越臃肿,浏览器要下载和解析的东西越多,页面加载就越慢,而加载速度是实打实影响SEO和用户体验的。所以这个压缩比可以当成一个粗略的页面臃肿度指标:压缩比特别夸张的页面,值得去查查是不是内联了过多的脚本样式、是不是该做精简。它不能替代专业的性能工具,但能给你一个“这页是不是太重了”的第一直觉。
要拆解一批竞品页面,怎么提高效率?
做竞品研究,往往不是看一个页面,而是要批量看几十个。一个个手工复制源码、贴进工具、设选项、转换,重复几十遍很枯燥也容易出错。这里有几个提效的小办法。
第一,先把选项设定好再批量处理——确定了这批页面都用“不保留图片、保留链接、单空行模式”,就固定这套设置,每个页面贴进去直接转,不用每次重设。第二,善用工具的URL抓取功能,对那些不是JS渲染的静态页面,直接喂URL让它抓,省去手工复制源码的步骤。第三,转出来的纯文本统一存成带编号的txt文件,方便后续批量丢进字数统计、或者一起喂给AI做横向对比。批量竞品拆解的诀窍,是把流程标准化、把设置固定化,让重复劳动尽量自动化,把省下的精力放在真正需要judgment的分析判断上。
实战案例:假发接发出海站的竞品页拆解
我们团队去年帮一个做假发、接发产品的出海站做内容优化,过程里这个HTML转纯文本工具用得很频繁。这站卖各种真人发、化纤发、接发片,目标市场是欧美,竞争对手里有几个独立站把产品页和教程内容做得相当扎实,排名常年压在前面。
我们的第一步就是系统地拆解这些竞品页。挑出排名好的几十个页面,把每个页面的正文HTML复制下来,用工具洗成纯文本——保留链接选项打开,方便看它正文里引到了哪些参考;保留图片打开,因为假发这类产品,图片的alt里常藏着“人鱼姬色”“无痕接发”这类长尾词,值得单独扒出来看。洗成纯文本后,再把内容丢进字数和结构分析,我们发现竞品的爆款教程页普遍在三千字以上,而且都用大量的分步骤列表和对比表格——这些结构在纯文本里因为保留了圆点和制表符,一眼就能看出来。
拆解清楚之后,我们没有去抄,而是据此重写了自己站的产品教程:补足了竞品覆盖到、我们却漏掉的护理知识,把硬邦邦的参数描述改成了带步骤的实操指南,图片alt也按扒出来的长尾词思路重写了一遍。三个月后,几个核心教程页陆续进了第一页。这个案例的要点是:工具的价值不在“扒内容”这个动作本身,而在它把竞品的内容结构洗得清清楚楚,让你能看明白人家强在哪、自己缺在哪,再用原创的方式补齐——研究是为了超越,不是为了复制。
内容素材清洗三件套:剥文本只是第一步
把HTML洗成纯文本,是处理内容素材的第一道工序,但往往不是最后一道。一份内容从原始素材到能用、能发、能审,通常要走完一条流水线,剥文本只是开头。
剥成纯文本之后,常见的下一步有两个方向。一是格式流转:你可能需要把纯文本或HTML转成Markdown,方便在各种平台之间搬运、或者交给AI处理,这就要用到Markdown转换器,它能在HTML和Markdown之间双向转换。
二是篇幅质检:洗干净的文本到底有多少字、够不够竞争词要求的篇幅、读完要多久,这些得量化,就要用到字数统计工具去做字数和阅读时长的审计。剥文本、转格式、数字数,这三件套串起来,正好是内容素材从“脏HTML”到“干净可用、心里有数”的完整清洗流水线。这篇讲的是第一步,把噪声剥干净,后面两步在干净文本的基础上才好做。
常见问题解答
HTML转纯文本和直接复制网页文字有什么区别?
区别在“可控”和“干净”。直接在浏览器里选中网页文字复制,你拿到的往往带着隐藏的格式——粘贴到别处可能字体、颜色、链接样式都跟过来了,而且复制的范围受限于你能选中的部分,导航、广告之间的文字常常一起被选进来。用HTML转纯文本工具,你是拿源码来处理,能精确控制要不要保留链接、图片、列表、表格,剥出来的是真正的纯文本,没有任何隐藏格式残留。更重要的是,它能批量、规整地处理,还附带字数、压缩比这些统计,比手工复制可控得多。要的就是干净、可控的纯文本时,用工具比直接复制靠谱。
转出来的文本里还有奇怪的乱码符号,是怎么回事?
最常见的原因是HTML实体没被完全还原,或者原始内容的编码有问题。这个工具有两层实体解码,常见的空格实体、与号实体这些会被还原,生僻的数字实体也有兜底处理,正常情况下不该留乱码。如果还有,先检查你贴进去的源码是不是完整的、编码是不是UTF-8——从一些老网站或者编码不规范的页面扒下来的内容,可能本身就是乱码,那不是工具的问题。另外,如果你看到的是一些方块或问号,可能是字符本身在你的环境里没有对应字体显示,换个地方看可能就正常了。实在有顽固的特殊符号,转完之后手工查找替换一下即可。
它能保留文章的标题层级(一级标题、二级标题)吗?
不能,这是它的一个明确局限。工具把h1到h6所有标题都转成换行,标题文字会保留、会独占一行,但“这是几级标题”的层级信息会丢失——它不会像Markdown那样加井号,也不会用缩进体现层级。所以如果你的目的是提取文章的大纲、还原目录结构、或者分析竞品的标题骨架,这个工具满足不了,你得用专门解析HTML结构、能识别标题层级的工具。这个工具的定位是把内容洗成可读的纯文本,不是解析文档的结构层级,两个需求不一样,要选对工具。
用JavaScript框架做的网站,为什么转出来是空的?
因为这个工具只处理HTML源码本身,不执行JavaScript。React、Vue这类前端框架做的页面,正文内容是靠JS在浏览器里动态渲染出来的,并不写死在初始HTML里。你用“查看页面源代码”拿到的初始HTML,正文位置可能是空的,真正的内容要等JS跑完才出现,把这种空壳源码贴给工具,它自然转不出内容。解决办法是:别用“查看源代码”,改用浏览器开发者工具的“检查”功能,复制渲染完成后的DOM元素,那里面才有真正的文字。简单说,要复制“跑完JS之后的页面”,不是“刚下载下来的源码”。
清洗后的纯文本,下一步通常做什么?
看你的目的。如果是做内容分析,下一步通常是数字数、看篇幅够不够、估阅读时长,这要用字数统计工具。如果是要在不同平台之间搬运内容、或者交给AI处理,下一步往往是转成Markdown格式,这要用Markdown转换器。如果是存档,那转成纯文本本身可能就是终点,下载存好即可;如果是要喂给AI做分析,洗干净直接贴进对话框就行。HTML转纯文本是内容处理的第一道工序,它把素材洗干净,后面的字数审计、格式转换、AI分析都在这份干净文本上才好做,几乎所有跟网页内容打交道的活儿,都该从这一步开始。
权威参考资料
本文标题:《HTML转纯文本工具怎么用?把网页内容剥成干净文本做分析》
本文链接:https://zhangwenbao.com/html-to-text-clean-content-extraction-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0