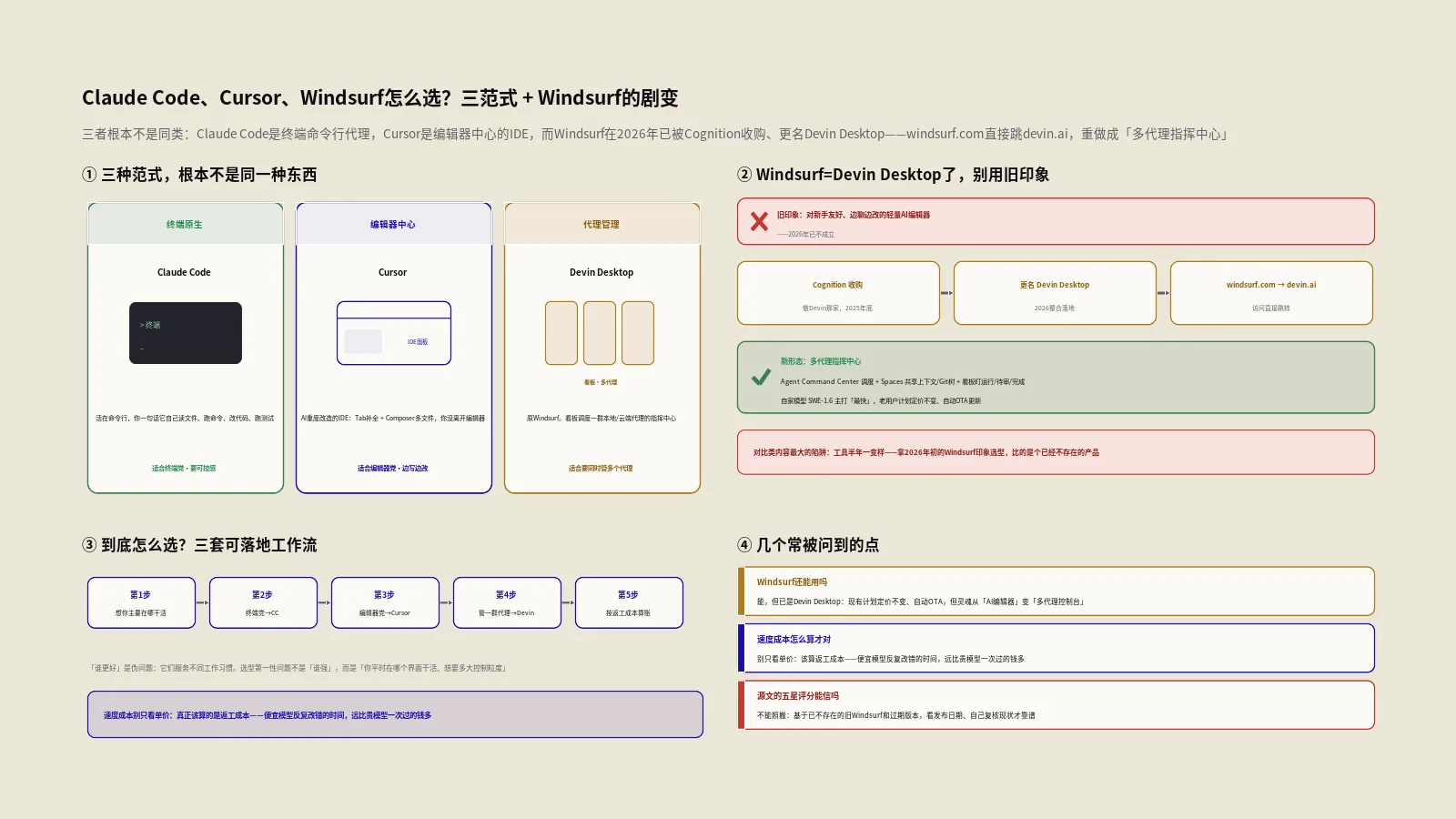
GPT-5.5和Claude Opus 4.8哪个写代码强?模型对比该怎么读

本文目录
摘要:“GPT和Claude Opus哪个写代码更强”是个看着简单、其实最容易被带偏的问题。源文那篇2026年3月的对比,比的是GPT-5.4和Opus 4.6——到6月,这两个版本号都翻篇了:OpenAI这边的当家是GPT-5.5,Anthropic这边是5月底发布的Opus 4.8(SWE-bench Verified 88.6%、Pro 69.2%)。但比谁分高从来不是重点。这篇文章想教你的是读榜单的方法:SWE-bench的Verified和Pro差在哪、为什么榜单分数约等于不了你的实测体感、统计误差范围内的领先没意义、以及Agent能力这个真正的主战场怎么看。最后给一套比盯榜单靠谱得多的做法——用你自己的任务建一个小评测集,让模型在你的真实场景里比,而不是在别人的题库里比。
每隔一阵就有新模型发布,紧跟着就是一波“X吊打Y”的跑分对比。保哥的建议一向是:这类文章看个热闹就行,别拿它做决策。原因很简单——跑分半年一换,版本号一翻篇,结论可能就反过来了。更重要的是,绝大多数人根本不知道那些分数到底在测什么、能不能套到自己的项目上。这篇不打算再给你甩一张“谁赢”的表,而是带你学会怎么读这类对比,让你以后看到任何模型横评都能自己判断含金量。
先把版本号对齐——源文比的还是2026年初那两个模型吗?
读任何模型对比,第一件事是核对它比的是哪个版本。这听着像废话,却是最常被忽略、也最致命的一步。
源文写于2026年3月,比的是GPT-5.4和Claude Opus 4.6。到2026年6月,这两个都已经不是各家的当家型号了。OpenAI这边推出了GPT-5.5(2026年4月23日发布,是它自GPT-4.5以来第一个完全重新训练的基座,专门为代理任务做了强化);Anthropic这边则一路迭代到了Opus 4.8(2026年5月28日发布)。也就是说,源文那张参数表上的每一个数字,现在都对应着一个过气版本。拿三个月前的版本号做今天的选型决策,等于在用一张过期的地图找路。
这不是吹毛求疵。模型迭代的速度,已经快到“季度即过时”的程度。Opus从4.6到4.8,编程能力有实打实的提升——按官方数据,Opus 4.8在被业界当作硬骨头的SWE-bench Pro上拿到69.2%,比上一代4.7的64.3%高了近5个百分点。GPT这边同理,5.4到5.5之间也有代际更新。所以你看到任何模型对比,先翻到顶上看它比的是哪两个版本、发布于何时——如果版本已经换代,下面的分数再详细也只有考古价值。养成这个习惯,能帮你过滤掉八成的过期对比。
SWE-bench的Verified和Pro,到底差在哪?
编程模型对比里出现频率最高的指标就是SWE-bench。但很多人不知道它有好几个变体,混着用会得出完全不同的结论。搞懂这几个变体的区别,是读懂这类对比的基本功。
SWE-bench的核心思路是:从真实的GitHub开源项目里捞出实际发生过的issue和对应的修复,让模型尝试解决,再用项目自带的测试来判对错。它考的不是“写一段孤立的代码”,而是“在一个有历史包袱的真实代码库里,定位并修好一个真问题”,这比那些刷算法题的基准贴近实际工程得多。按SWE-bench官方的划分,它有Verified(人工核验过、确保任务可解且测试靠谱的子集,是目前最常被引用的版本)、Lite(精简版)、Multilingual(多语言)、Multimodal(含图像)等多个变体。你常看到的“SWE-bench 88%”这种说法,多半指的是Verified。
而源文和很多新对比里出现的SWE-bench Pro,是另一回事——它是一个刻意做得更难、更抗“背题”的变体,任务更复杂、更贴近企业级真实工程,专门用来在顶级模型之间拉开区分度。为什么需要Pro?因为Verified被刷得太高了:当几个顶级模型都能在Verified上拿到85%以上,这个榜单就快要“饱和”,大家挤在天花板附近,零点几个百分点的差距根本说明不了问题。这就是关键洞察——在快被刷满的榜单上比领先,意义很小;真正能区分模型的,是那些还有足够区分空间的更难基准。所以看对比时,与其盯着Verified上那点接近饱和的差距,不如关注Pro这种更难的榜单上的表现:Opus 4.8在Pro上是69.2%,明显高于GPT-5.5的约58.6%和Gemini 3.1 Pro的约54.2%——这个差距比Verified上的零点几个百分点有信息量得多。
榜单分数为什么不等于你的实测体感?
就算你看的是最新版本、最难的榜单,还有一道坎:榜单上的分数,和你在自己项目里的实际体感,往往对不上。这不是模型在骗人,而是榜单的测法和你的真实场景之间,天然隔着几层。
第一层是数据分布的错位。SWE-bench取的是开源项目的issue,多以Python为主、以某些活跃大仓为样本。如果你的项目是冷门语言、是有十年祖传屎山的私有代码库、或者业务逻辑特别刁钻,那榜单的“平均表现”就未必能代表它在你这儿的表现。模型在它见多了的题型上分高,不等于在你这种它没怎么见过的场景里也一样强。
第二层是数据污染的隐忧。这些榜单的题目大多来自公开的GitHub,而模型的训练数据也来自公开互联网——理论上存在模型“见过答案”的可能。这正是Pro这类新基准要不断推陈出新、用更新更私密的任务的原因:就是要防止模型靠“背题”虚高。但对你来说,污染的影响很难量化,所以榜单分数始终该打个问号。
第三层是评判维度的单一。SWE-bench只判“测试过没过”这个二元结果,但你在乎的远不止于此——代码可不可维护、风格合不合团队规范、有没有埋下隐患、注释清不清楚。一个能让测试变绿但写得一团糟的修复,在榜单上是满分,在你的代码评审里可能直接被打回。所以榜单分数最多告诉你“这个模型大概在什么水平段”,绝对替代不了你拿自己的真实任务跑一遍的体感。把榜单当粗筛、把实测当定夺,才是正确的用法。
除了写单点代码,Agent能力怎么比?
还有一个更大的盲区:单点的代码能力,已经不是2026年模型竞争的全部,甚至不是最重要的部分。真正的主战场,是Agent能力——模型能不能在一个工具环境里,自主地连续干完一长串活。
这件事和“写一段代码写得好不好”是两回事。Agent能力考的是:模型能不能自己规划多步骤、能不能正确地调用工具(读文件、跑命令、查文档)、能不能在长时间任务里不跑偏不失忆、出错了能不能自己发现并纠正。一个单点代码写得漂亮但一让它自主多步就乱套的模型,做不了真正的代理工作。这也是为什么各家现在都在拼“为代理而生”的训练——GPT-5.5主打的就是代理强化,Anthropic则在Opus上叠了上下文压缩、自适应思维这类专为长任务设计的机制,还在Claude Code里上了能扛超大规模任务的动态工作流。
怎么比Agent能力?专门的基准(比如考终端多步交互的那类)是一个参考,但更实在的还是看它在真实代理工具里的表现:交给它一个需要十几步、要反复读写文件和跑测试的任务,看它能不能稳稳干完。Anthropic和OpenAI在Agent能力上的取向略有不同——一个更强调单个代理把长任务做深做稳,一个更强调多代理并行和工具编排。哪种更适合你,取决于你的活是“一个深任务”还是“一堆可并行的活”。想看这两种取向具体怎么落地,可以参考Agent Teams那篇。选模型时只看代码跑分、不看Agent能力,在2026年已经是抓小放大了。
为什么“平均提升X%”这种说法要警惕?
模型对比里还有一类特别有迷惑性的数字:各种漂亮的百分比。“开发时间缩短40-60%”“token用量减少47%”“虚假概率降低33%”——源文里就堆了一串这样的数据。它们看着精确、可信,但恰恰是最该打问号的地方。
第一个要问的是:这个百分比的基准是什么?“提升40%”是相对谁、在什么任务、什么条件下测的?“开发时间缩短一半”是对哪类任务、由谁、用什么流程测出来的?这些前提一旦不交代清楚,百分比就是个悬空的数字。同一个“缩短60%”,换个任务、换个对照组,可能就变成“缩短10%”甚至不升反降。脱离了基准和场景的百分比,参考价值接近于零。
第二个要问的是:这个数字是谁给的?模型厂商在自家发布材料里给的提升数据,天然带着营销倾向——他们会挑对自己最有利的任务和对照来测。这不是说厂商在撒谎,而是这些数字本就是为了好看而精选出来的最佳case,不代表你的平均体验。看到任何精确的提升百分比,别急着信,先问它的基准、场景和来源;问不出来,就当它是个营销话术,别写进你的决策依据。
第三个陷阱是“精确的假象”。“47%”比“大约一半”看着科学多了,但小数点后的精确度,常常只是把一个粗糙的、场景受限的测量,包装成了像是严谨实验的结论。真正严谨的数据会附上测试方法、样本量、置信区间;只甩一个光秃秃的百分比而不交代怎么测的,那个精确度就是装出来的。学会对这类数字保持警惕,是读懂模型对比的一项核心能力——它能帮你过滤掉大量看着唬人、实则没营养的“数据”。
幻觉和准确性,对比里该怎么看?
除了能力和速度,模型的准确性——也就是它会不会一本正经地胡说——是编程场景里一个绕不开的维度。但这块同样不能只看厂商给的“幻觉率降低多少”的数字,得理解它在编程里具体怎么表现。
在写代码这件事上,幻觉最典型的形态是“编造不存在的东西”:调用一个根本不存在的API方法、import一个查无此名的库、记错某个函数的参数签名、或者笃定地引用一份过时的文档。不同模型的幻觉表现还不太一样——有的爱编造API,有的偶尔记错函数签名。这些错误的隐蔽性在于,它们往往语法正确、看着合理,能骗过快速浏览,要等真跑起来或者仔细审查才暴露。
所以对准确性,正确的态度不是去比谁的“幻觉率”官方数字更低(那同样是精选出来的),而是认清一个现实:没有任何模型的准确性高到可以让你省掉验证这一步。不管它榜单多漂亮、宣称幻觉率多低,它写的代码都必须过测试、过代码评审、过实际运行这几关,才能进你的生产环境。把模型当成一个能力很强但偶尔会信口开河的junior,你的工作流里必须有一道“不管它说得多笃定都要验证”的硬关卡。这道关卡怎么搭进Claude Code的工作流——用测试、用Hooks、用验证循环——完全指南里讲过具体做法。说到底,模型再强,验证这一环都省不掉,这也是为什么前面反复强调“自建评测、实测定夺”——你信不过任何单方面的准确性承诺,只信得过自己跑出来的结果。
价格和速度,这半年变了什么?
能力之外,价格和速度是另一组实际变量,而且这半年也有不小变化,源文的数字同样需要更新。
先说Claude这边的现状:Opus 4.8的API价格是每百万token输入5美元、输出25美元,100万token的超长上下文不额外加价。更值得一提的是2026年新上的Fast模式——它能让Opus以约2.5倍的速度跑,而价格比上一代的快速模式便宜了约三分之二,等于“又快又没那么贵”。GPT这边则把更便宜的输入价格作为卖点,主打大批量、成本敏感场景的性价比。具体到Claude Code这类工具里怎么把模型成本压到最低——缓存、批量、按任务分层选模型那几招——定价指南里有完整拆解。另外要提醒,模型的速度和你的实际产出还隔着一层额度限制——再快的模型,撞上订阅档的用量上限也得停,这块的机制可以看速率限制那篇。
但价格对比有个常见误区要点破:单价便宜不等于总花费便宜。一个单价低但容易出错、需要你反复重试的模型,把试错的token和你的时间算进去,未必比单价高但一次做对的模型省钱。尤其是难任务,用便宜模型反复磨,常常不如直接上强模型一把过。所以价格该和能力、和你的任务难度一起看,单拎出来比每百万token几美元,意义不大。这套“按任务难度选模型”的思路,本质上就是把贵的算力用在刀刃上。
那到底该用哪个模型?
讲了这么多方法,落到实际选择上,保哥的答案可能让期待“一锤定音”的人失望:别只用一个,按任务分层混着用,才是2026年最务实的策略。
具体的分层逻辑是这样的。最难的活——复杂的多文件重构、大型代码库的深度调试、需要长时间自主推进的代理任务——用最强的模型,比如Opus 4.8,它在难基准上的优势和长任务的稳定性在这里能回本。日常的活——普通功能开发、写测试、改bug——用中端模型(比如Sonnet档)就够,又快又省。琐碎的活——格式化、简单问答、批量小改——用最便宜的小模型,把成本压到地板。这种“好钢用在刀刃上”的分层,比全程死磕一个模型,性价比高得多。
至于GPT和Claude之间怎么选,与其纠结谁绝对更强,不如看你的具体场景偏好哪种取向。需要长时间自主、深度重构、把一个复杂任务做透,Claude系的长任务稳定性口碑更好;需要大批量、成本极度敏感、或者要和桌面自动化这类能力打通,GPT系有它的场景优势。对做出海独立站、要批量处理内容和数据的团队,保哥见过的成熟做法往往是两边都接:核心的、要质量的活走一条线,海量的、可批量的活走另一条线,按账和按效果动态调,而不是站队某一家。模型是工具,能用顺手、能算得过账的组合,就是对你最好的组合。
这里再点破一个心理误区:很多人选模型时,潜意识里想找一个“最强的、一劳永逸的、选了就不用再操心的”答案。但这个心态本身就和模型领域的现实拧着——它迭代太快,今天的最强半年后就是中游,你越想一锤定音,越容易被某次营销话术绑死在一个很快过时的选择上。真正稳健的姿势恰恰相反:保持工具的可替换性,把自己的工作流和某个具体模型解耦,让换模型像换螺丝刀一样轻松。你的核心资产不是“押对了哪个模型”,而是那套能快速评测、快速切换的能力。把这个想明白,你就不会再为“到底谁更强”这种本质上没有恒定答案的问题焦虑了。
怎么自己测,才比看榜单靠谱?
说了半天“榜单不可全信、实测才算数”,那到底怎么实测?这里给一套保哥用过、不复杂但有效的土办法,比盯着别人的跑分靠谱得多。
核心思路是:建一个属于你自己的小评测集。具体做法是,从你过去真实处理过的任务里,挑出五到十个有代表性的——最好覆盖你最常干的几类活,比如一个典型的功能开发、一个棘手的bug修复、一次模块重构、一段需要读懂上下文才能改对的逻辑。这些任务你已经知道“正确答案长什么样”,因为你当初就是这么解决的。然后把同一批任务分别交给你在考虑的几个模型,跑完后用统一的标准打分:测试过没过只是及格线,更要看代码质量、可维护性、有没有理解对意图、有没有埋坑。
举个具体的例子感受下这套评测集长什么样。一个做出海独立站的团队,可以挑这么五个任务:一是给商品页加一个新模块(考常规功能开发和对现有代码风格的遵循);二是修一个已经定位到、但根因刁钻的结算bug(考调试和对复杂逻辑的理解);三是把一段塞了太多职责的工具函数重构成可复用模块(考架构判断);四是给一个第三方支付回调写完整的异常处理和单测(考严谨度和边界覆盖);五是读懂一段没有注释的祖传逻辑并安全地改一处行为(考上下文理解)。这五个任务你都亲手处理过、知道好的答案长什么样,把它们分别丢给几个候选模型,再按统一标尺打分,一轮下来谁更适合你的活,比任何榜单都清楚。
这套土办法的好处是它直接命中你的真实分布——测的就是你将来真要它干的那类活,没有数据分布错位、没有污染疑虑、评判维度也由你说了算。跑下来你会发现,结果常常和公开榜单的排名不完全一致,因为你的场景和榜单的题库本就不同。花半天搭这么个小评测集,得到的选型依据,比读十篇“谁吊打谁”的横评都扎实——因为它测的是你的活,不是别人的题。而且模型更新后,你随时能用这套评测集重测一遍,几个月一迭代也不慌。这种“自建评测”的习惯,是把选型主动权握在自己手里的关键,远比被动等别人出对比报告强。
看到下一篇模型对比,该怎么快速验货?
这篇讲的方法,可以收成一份随手就能用的自查清单。下次再刷到“某模型吊打某模型”的文章,按这五步过一遍,三十秒就能判断它值不值得认真读。
第一步,核版本和日期。翻到顶上看它比的是哪两个版本、文章发于何时。版本已经换代、或者发布超过两三个月的,分数基本作废,直接降级当背景资料看。这是最快的过滤器,能筛掉一大半过期内容。
第二步,看它用的哪个基准。是接近饱和的Verified,还是更难、更有区分度的Pro之类?在快刷满的榜单上比零点几个百分点的领先,没有意义;要看的是还有区分空间的难基准。如果通篇只甩一个笼统的“SWE-bench多少分”却不说哪个变体,作者多半自己也没搞清。
第三步,给每个百分比验明正身。遇到“提升X%”“降低Y%”,追问基准是什么、谁测的、什么场景。交代不清、又来自厂商自家材料的,当营销话术处理,别采信。
第四步,看它谈不谈Agent能力。一篇2026年的模型对比如果只比单点代码、对自主多步的代理能力只字不提,说明作者的认知还停在上一个时代,参考价值有限。
第五步,问它有没有让你自己测。真正负责任的对比,会告诉你“以上仅供参考,最终请用你自己的任务验证”,而不是替你拍板“就选这个”。鼓吹唯一正确答案、不提实测的,警惕它在替谁带货。把这五步内化成本能,你就再也不会被任何一篇模型横评牵着走了——你不是在记别人的结论,而是掌握了自己判断的能力。
常见问题解答
源文比的GPT-5.4和Opus 4.6,现在还是最新的吗?
不是了。源文写于2026年3月。到6月,OpenAI的当家是GPT-5.5(4月23日发布的全新重训基座,主打代理能力),Anthropic是Opus 4.8(5月28日发布)。这两个版本号都已经换代,源文那张参数表上的分数现在只有考古价值。读任何模型对比,第一步都该核对它比的是哪个版本、发布于何时。
SWE-bench Verified和Pro有什么区别,该看哪个?
Verified是人工核验过的常用子集,但已经快被顶级模型刷满,大家挤在85%以上的天花板附近,零点几个百分点的差距没意义。Pro是刻意做得更难、更抗背题的变体,专门在顶级模型间拉区分度。比顶级模型时,更难的Pro比接近饱和的Verified有信息量得多,该重点看Pro这类还有区分空间的榜单。
榜单分数高的模型,用起来一定更顺手吗?
不一定。榜单和你的实测之间隔着几层错位:榜单的题目分布(多Python、多活跃大仓)未必匹配你的项目;存在模型见过公开题目的污染疑虑;而且它只判测试过没过,不管代码可维护性、风格、隐患这些你真正在乎的。榜单最多告诉你模型大概在哪个水平段,替代不了你拿自己的真实任务跑一遍。
2026年选编程模型,除了代码能力还该看什么?
重点看Agent能力——模型能不能在工具环境里自主连续干完一长串活:自己规划多步、正确调用工具、长任务不跑偏、出错能自纠。这和单点代码写得好不好是两回事。一个代码漂亮但一自主多步就乱套的模型做不了真代理工作。只看代码跑分、不看Agent能力,在2026年是抓小放大。
便宜的模型是不是不如贵的,能省则省吗?
该按任务难度分层,而不是一味图便宜。最难的活(复杂重构、深度调试、长自主任务)用最强模型一把过,反而比用便宜模型反复试错省钱省时;日常活用中端模型;琐碎活用最便宜的小模型。单价便宜不等于总花费便宜——把试错的token和你的时间算进去,难任务上便宜模型常常更贵。好钢用在刀刃上才是正解。
到底GPT和Claude哪个写代码强?
这个问题没有脱离场景的答案。按当前的难基准,Opus 4.8在SWE-bench Pro上领先,长任务稳定性口碑也好,适合深度重构和长自主任务;GPT系在大批量、成本敏感和桌面自动化场景有优势。最务实的不是站队,而是按任务分层、两边都接,核心活和海量活走不同的线。与其问谁强,不如用自己的真实任务建个小评测集,让它们在你的场景里比。
本文标题:《GPT-5.5和Claude Opus 4.8哪个写代码强?模型对比该怎么读》
本文链接:https://zhangwenbao.com/gpt-vs-claude-opus-coding.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0