Claude Code完全指南:从安装到工作流,一篇看懂整条主线
本文目录
摘要:Claude Code不是又一个代码补全插件,而是一个能自己读文件、跑命令、改多处、提交代码的终端智能体。真正决定它好不好用的,不是单个命令,而是一条工作流主线——先把环境装通,再用CLAUDE.md把项目规矩交代清楚,接着按需挂上MCP连外部系统、用Hooks兜住流程红线、把重复套路抽成Skill,遇到并行和大任务再请出worktree和子代理,最后用一套验证循环收口。本文把这条线从头到尾串一遍,每个环节都点到该深挖的专题,帮你判断自己卡在哪一段、下一步该补什么,而不是一上来就被几十个命令淹没。
很多人第一次打开Claude Code,是冲着“AI帮我写代码”来的,结果装完、问了两句、生成一段函数,就把它当成了一个住在终端里的补全工具。用上一周后开始觉得“也就那样”,甚至不如IDE里的补全顺手。
这是个典型的误会。Claude Code的价值不在“它能生成代码”这一点上——那是所有AI编程工具的及格线。它真正不一样的地方,是它能像一个junior工程师那样,自己读懂你的项目、自己跑测试看报错、自己改好几个文件再回来跟你汇报。而要把这种能力榨出来,靠的不是记住更多命令,而是搭好一条工作流。保哥这两年带团队落地AI编程,最大的体会就是:会用的人和不会用的人,差距几乎全在“有没有把流程理顺”上,跟谁记的快捷键多没关系。
所以这篇不打算做成命令字典。它更像一张地图,把Claude Code从安装到进阶工作流的整条主线铺开,告诉你每一段在解决什么问题、什么时候该往下走、哪些环节值得单独深挖。你可以顺着读一遍建立全局观,也可以拿它当索引,哪段卡住了就跳到对应专题。
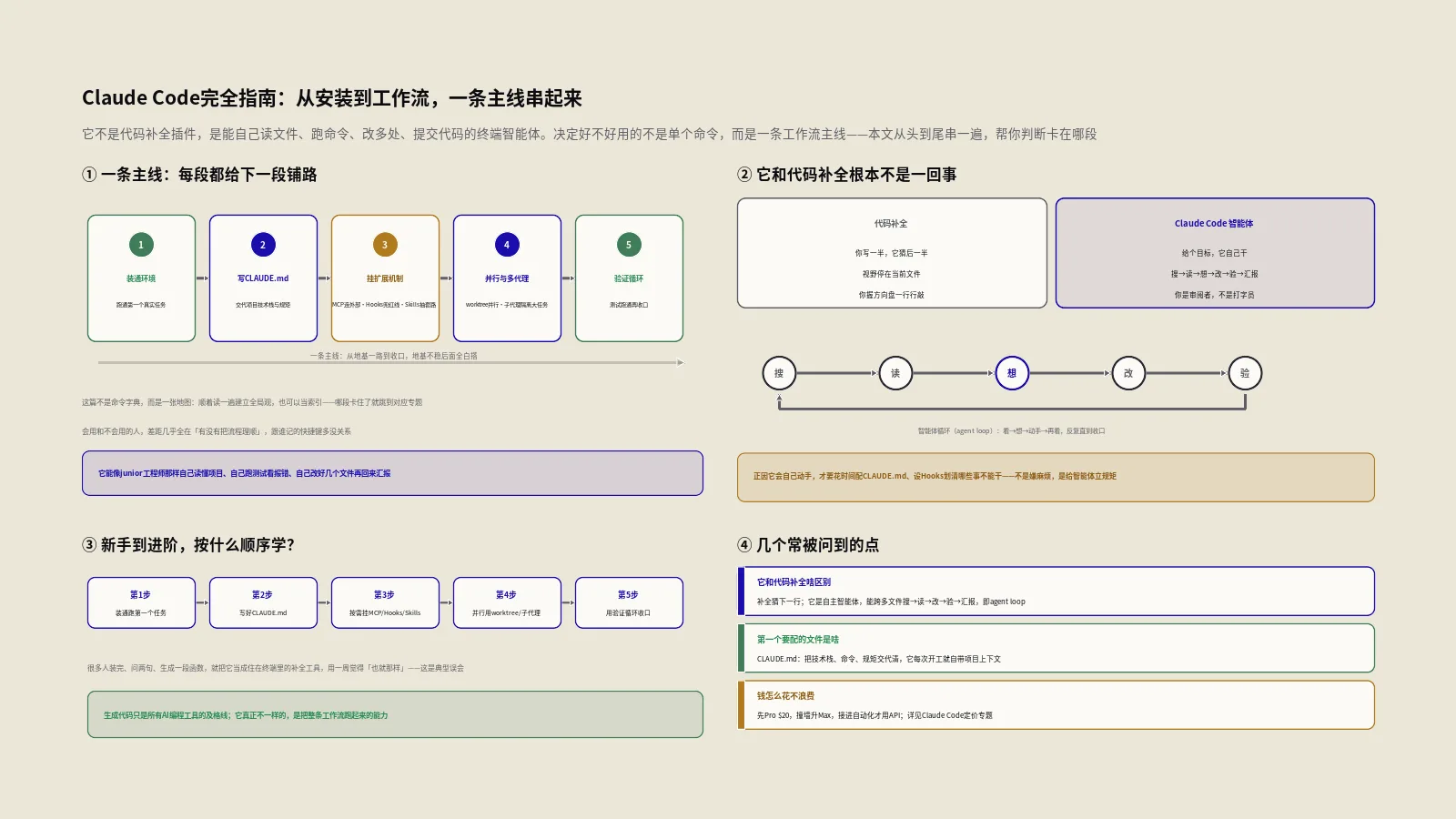
Claude Code到底是什么,跟代码补全有什么不一样?
先把定位摆正,后面的工作流才立得住。
IDE里的补全工具,工作方式是“你写一半,它猜后一半”。它的视野基本停在当前文件、当前光标附近,本质是一个特别聪明的自动联想。你始终是那个握着方向盘、一行一行往下敲的人。
Claude Code是另一种东西。它是一个运行在终端里的自主智能体:你给它一个目标,比如“把这个接口的分页逻辑从偏移量改成游标”,它会自己去搜相关文件、读懂现有实现、动手改动涉及的好几处代码、跑一遍测试确认没崩、再把改了什么、为什么这么改讲给你听。整个过程里它会反复地“看—想—动手—再看”,这套循环官方叫智能体循环(agent loop),是它和补全工具最根本的分界线。
举个具体的例子能体会这套循环。假设你说“线上有个用户反馈下单后偶尔收不到确认邮件,帮我查一下”。补全工具对这种话束手无策,因为它根本不知道从哪开始。Claude Code的反应是:先去搜跟邮件、订单相关的文件,定位到发送邮件的那段代码;读懂之后发现是异步队列里偶发的超时没重试,于是它会去看队列配置、确认超时设置,提出“这里该加一次重试”的判断;动手改完,它会主动跑相关测试,看改动有没有把别的地方带崩;测试过了,再回头跟你说“问题在队列超时没兜底,我加了重试和日志,测试都过了,你看看”。这一整套“搜—读—想—改—验—汇报”,就是智能体循环。你全程是个审阅者,而不是打字员。
这个区别会一路影响你怎么用它。补全工具你不需要“配置”,装上就能用;而一个会自己动手的智能体,你得告诉它项目的规矩、给它接上该用的工具、划清哪些事不能干——这正是后面整条工作流要做的事。理解了“它是个会自己干活的家伙,不是联想引擎”,你才会明白为什么要花时间配CLAUDE.md、为什么要设Hooks兜底,而不是嫌麻烦。官方Claude Code概览文档里把它定义为“能在你的终端里理解整个代码库、跨多文件协同改动”的智能体,说的就是这个意思。
一条主线:Claude Code的工作流到底长什么样?
把零散的功能点串起来,你会发现它们其实排在一条线上,每一段都在给下一段铺路:
- 装通环境——让Claude Code能在你的机器上跑起来、连上模型、跑通第一个真实任务。这是地基,地基不稳后面全白搭。
- 写好CLAUDE.md——把项目的技术栈、命令、规矩用一份文件交代清楚,让它每次开工都自带项目记忆,不用你反复解释。
- 按需接MCP——当任务需要碰外部系统(数据库、GitHub、监控平台)时,用MCP把这些数据源接进来,让它不只是改本地文件。
- 用Hooks兜底——把“提交前必须过lint”“禁止读密钥文件”这类不能松动的红线,做成生命周期钩子硬卡住,不靠它自觉。
- 抽出Skill——把反复出现的多步骤套路(比如一套完整的发布流程)打包成技能,需要时才加载,平时不占上下文。
- 请出并行能力——遇到要同时推进几条线、或者单个大任务,用worktree隔离工作区、用子代理把脏活累活分出去。
- 收口于验证——让它自己跑测试、自己看结果、自己改到通过,形成一个闭环,而不是改完就扔给你。
这条线不是必须一次性全搭完。新手把前两段(装通、CLAUDE.md)做扎实,就已经超过大多数人了;中间几段是按项目复杂度逐步加的;最后的并行和验证,是当你开始一天处理好几个任务时自然会用上的。下面就顺着这条线一段段拆。
先把环境装好,第一个任务怎么跑通?
地基这一段,卡住人最多的不是“装不上”,而是“装上了但没跑通一个真实任务,就以为自己会了”。
安装本身不复杂:装好Node运行环境后用npm全局安装,在项目目录里敲claude就进了交互界面。但有几个坑值得一开始就避开。一是别一上来就追最贵的模型——日常八成的活Sonnet就够了,又快又省,真正需要啃硬骨头的架构重构再切Opus,这个“按活选模型”的习惯越早养成越省钱。二是首次进项目,别急着让它改核心代码,先用只读的方式让它“给我讲讲这个项目的结构”,确认它真的读懂了,再放手让它动手。三是权限别一把梭全开,搞清楚哪些命令需要确认、哪些可以放行,是后面用得安心的前提。
真正的“跑通第一个任务”,标准不是生成了一段代码,而是完整走完一轮:你提需求→它读文件→它改动→它跑测试→你确认。这一整轮顺下来,你才算建立了对它的判断——知道它什么时候靠谱、什么时候会自作主张。这一段从零到跑通的全部细节,包括安装命令、模型别名、权限白名单、CLAUDE.md分层这些,站内有一篇完整的Claude Code安装配置指南,第一次上手照着走一遍就行,这里不重复铺。
为什么CLAUDE.md是你要配的第一个文件?
装通之后,整条工作流里投入产出比最高的一步,就是写CLAUDE.md。没有之一。
道理很简单:Claude Code每开一次新对话,上下文都是空白的,它不记得你昨天教过它什么。如果不给它一份项目说明,你就得每次重复交代“我们用pnpm不用npm”“组件文件名走kebab-case”“提交前先跑lint”——一天下来光解释这些就耗掉大把精力,它还经常忘。CLAUDE.md就是把这些“每次都要重说一遍的话”一次写进文件,放在项目根目录,它每次开工自动加载,相当于给它配了一份常驻的项目记忆。
官方记忆机制文档里把判断标准说得很清楚:什么时候该往CLAUDE.md里加内容?当它第二次犯同一个错、当code review挑出一个它本该知道的项目惯例、当你又一次把上次说过的纠正打进对话框——这些就是该写进去的信号。该写的是事实和规矩:构建命令、目录约定、“永远要做X”的硬规则;不该写的是长篇背景故事和只对某一小块代码有用的多步骤流程,前者属于README,后者该抽成Skill。
这里有几个新手常踩的反直觉点。一是越短越好,官方建议单文件控制在200行以内,不是越详细越好——它每次会话都全量加载进上下文,越长越稀释注意力、越费token。二是用祈使句,写“使用TypeScript严格模式”而不是“项目使用了严格模式”,因为它是指令不是说明。三是别重复linter已经强制的规则,那是浪费。CLAUDE.md还能分层——全局的个人偏好放~/.claude/CLAUDE.md,项目规矩放./CLAUDE.md提交进Git让全团队共享,纯个人的本地配置放CLAUDE.local.md并加进gitignore。这套作用域机制、自动记忆、以及配置模板,站内的CLAUDE.md记忆术那篇掰开讲过,想把这一步做到位的话值得专门读一遍。
MCP、Hooks、Skills这三个扩展机制各管什么?
地基和记忆搭好,接下来是按项目需要往上挂扩展。这里最容易让人犯晕的,是MCP、Hooks、Skills这三个名字听着都像“扩展”,到底各管一摊什么事分不清。一句话先记住分工:MCP管“连什么”,Hooks管“什么时候必须做什么”,Skills管“怎么把一套套路打包复用”。
MCP(模型上下文协议)解决的是“让它能碰到本地文件以外的世界”。默认它只能读写你项目里的文件,一旦任务需要查生产数据库、看GitHub上的issue、拉监控平台的报错,就得通过MCP把这些系统接进来。这两年MCP生态变化很大,最值得提醒的一点是:网上一堆教程里写的@anthropic/mcp-xxx这类包名,绝大多数是虚构的,Anthropic根本没发过这些npm包——真实的接法要么是连服务商自己的远程端点,要么用官方reference实现。这块怎么辨真假、怎么配本地还是远程、作用域怎么定,保哥踩过不少坑——一个常见的翻车场景是,照着某篇高赞教程把一长串包名敲进配置,结果全是装不上的幽灵包,折腾一晚上发现根本不存在。真实的接法其实简单得多,要接外部系统之前先搞清楚“这个能力到底有没有官方或厂商现成的端点”,再决定怎么连,能少走很多弯路。
Hooks解决的是“有些事不能靠它自觉”。CLAUDE.md里写的规矩是软约束,它读了会尽量遵守,但不保证每次都照做——官方自己都把CLAUDE.md定性为“上下文,不是强制配置”。可有些事是硬底线——比如提交前必须跑通测试、绝对不许读.env这类密钥文件。这种就该用Hooks,在工具调用的前后这些生命周期节点上挂一段脚本,强制执行,不给它发挥的余地。它和CLAUDE.md的分界很清楚:希望它“尽量这么做”用CLAUDE.md,要求它“必须这么做、做不到就拦下来”用Hooks。官方Hooks文档里把可挂的事件、配置结构讲得很全,要注意它的配置是matcher外层套hooks内层的两层嵌套,不少老教程写成扁平结构是错的,照着抄会直接报错。
Skills解决的是“同一套多步骤流程别每次手把手教”。你团队里那套完整发布流程——拉分支、跑测试、打tag、写changelog、推镜像——如果每次都在对话里一步步讲,既累又容易漏。把它写成一个SKILL.md打包好,需要时一句话触发,它就按流程走。Skill的好处是按需加载,平时不占上下文,这点和CLAUDE.md的“常驻”正好互补。
这里有个容易混的点值得点一句:什么该写进CLAUDE.md、什么该抽成Skill,分界是“事实还是流程”。一条短事实,比如“构建命令是pnpm build”,留在CLAUDE.md,每次都该让它知道;一套很长的多步骤流程,塞进CLAUDE.md会让每次会话都白白加载一大段平时用不上的内容,就该抽成Skill,只在真要发布时才加载。判断标准很实用:如果某段内容在CLAUDE.md里越长越像一份操作手册,那它多半该搬去做Skill。这条“事实留下、流程抽走”的原则,是把上下文用干净的关键之一,也是不少人CLAUDE.md越写越臃肿的根因——把本该是Skill的东西全堆进了常驻文件。
这三者到底怎么选、边界在哪,是新手最常问的,站内有一篇“MCP、Skills、Hooks怎么选”做了横向拆解,这里点到为止。记住那句分工口诀——连什么用MCP、什么时候必须做什么用Hooks、套路打包用Skills——大方向就不会错。
并行和多代理:worktree和子代理什么时候上?
前面几段都是“把一条线干好”。当你开始同时推进好几件事,或者碰上一个特别大的任务时,就轮到并行能力出场了。
先纠一个流传很广的错。很多教程里说并行开发用claude -w,这个写法是过时的——官方现在的原生标志是--worktree,后面跟的是工作区名字,不是任务描述。worktree的本质是借Git的工作树机制,给每条任务一个互相隔离的代码副本,让Claude Code能在好几个分支上同时干活而不互相踩脚。比如你想让它一边修bug、一边试一个重构方案,两条线各自一个worktree,互不污染。它默认从你的主分支拉出副本、自动命名分支,干完合并或清理都有规矩。
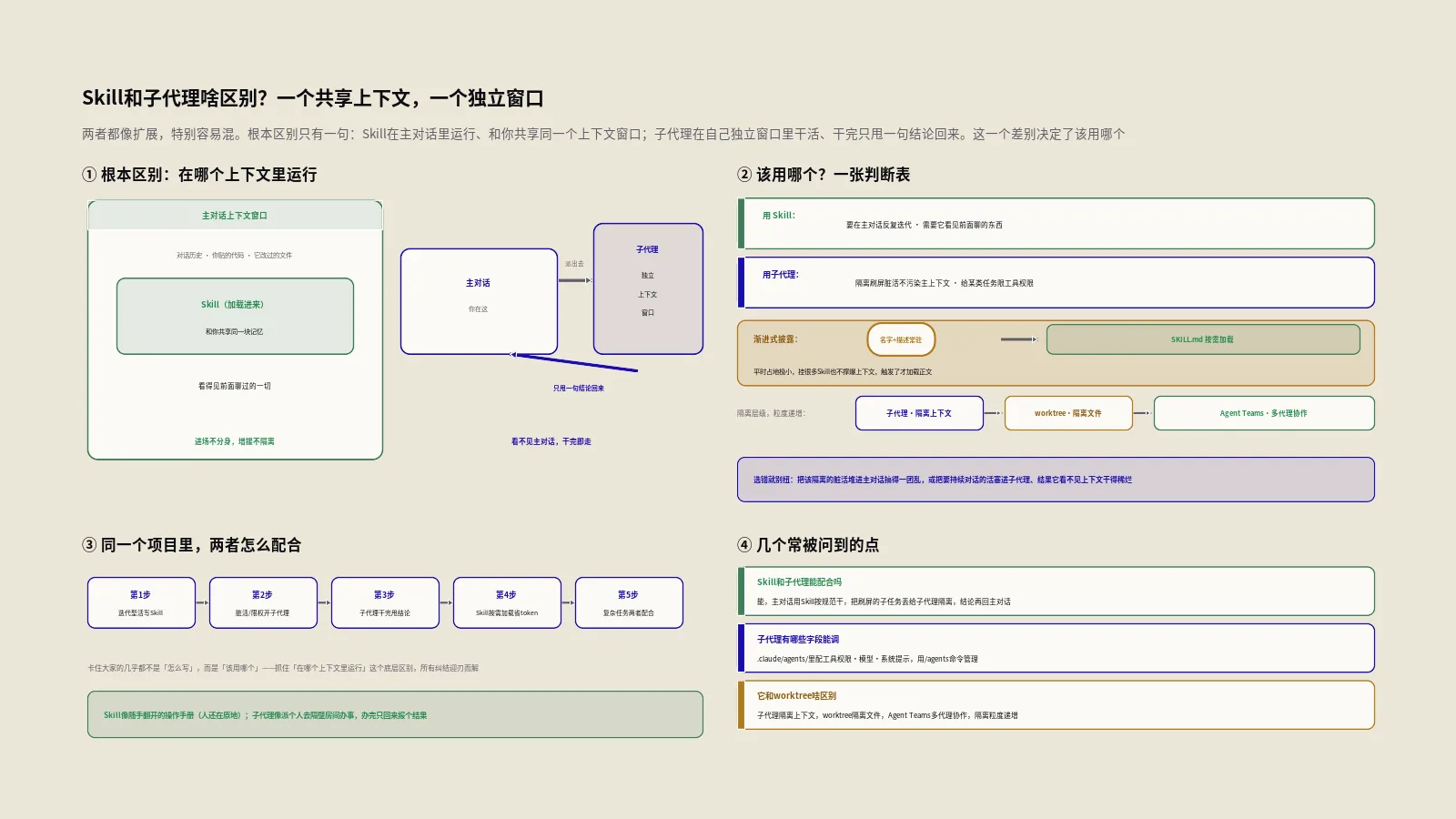
子代理(subagent)是另一种并行思路,解决的是“别让一个脏活把主对话的上下文搞乱”。当一个边角任务会产生一大堆你后面根本不会再看的输出——比如跑整个测试套件刷出几百行日志、或者翻一大段文档——把它丢给一个子代理去干,子代理在自己独立的上下文窗口里处理,干完只把一句话的结论甩回来,你的主对话窗口始终干净。Claude Code内置了Explore、Plan、general-purpose几个现成的子代理,你也能在.claude/agents/里自定义有特定职责和工具权限的专用代理。
为什么这件事对长任务特别关键?因为上下文窗口是有限的,而它装的东西越多、越杂,模型的注意力就越分散、判断越容易飘。一个典型的反面例子:你让它做一件需要持续好几十轮的大重构,中间穿插着“跑一下测试看看”“搜一下这个函数在哪被调用”这类查询,每次查询都往主对话里灌一堆日志和文件内容,几轮下来上下文就被噪音塞满,它开始忘记最初的目标、重复读已经读过的文件。把这些查询型的脏活分给子代理,主线对话里只留“目标、决策、改动”这些真正要紧的东西,它就能在长任务里保持清醒。这也是为什么越是复杂的活,越要懂得把工作拆给子代理,而不是一股脑全堆在主对话里。
这里要分清子代理和worktree、还有更重一级的Agent Teams的关系:子代理是在同一个会话内开几个独立上下文分头干活;worktree是隔离文件层面的工作区;Agent Teams则是开几个能互相通信的独立会话协作。复杂度从低到高,按需往上加,别一上来就上最重的。子代理和Skill到底怎么选、它俩的上下文管理差在哪,是个很值得单独琢磨的话题,站内另有专文细讲。
钱怎么花才不浪费?方案、限额和省钱组合
工作流搭起来了,绕不开的现实问题是:这玩意儿一个月要花多少、怎么花才不浪费。
订阅档位上,目前是免费档之外,Pro每月20美元、Max分5倍和20倍两档(100美元和200美元),再往上是团队版和企业版。一个重要的、很多老文章没跟上的变化是:Opus现在所有付费档都能用了,不再是Max专属——这意味着Pro用户也能用上最强模型,省钱的关键就从“能不能用Opus”变成了“该不该用Opus”。绝大多数日常任务用Sonnet就够,Opus留给真正需要深度推理的硬骨头,这一条能帮你把开销压下一大截。
限额这块有两个变化要知道。一是机制:它是5小时滚动窗口加每周上限的双层结构,不是单一的总量池,短时间猛用会先撞5小时窗口,持续高强度会撞每周帽。二是额度本身——2026年5月官方把Pro、Max、团队版的5小时窗口额度整体翻了一倍,还取消了之前加的高峰时段缩减,等于变相涨了不少配额。如果你还按半年前的限额印象在用,其实手里的额度比你以为的宽。撞墙之后怎么办、缓存读为什么不计入消耗、便宜模型该用在哪,这些省钱细节整理在了速率限制与省钱那篇里,按月预算紧的话值得照着调一遍用法。
具体怎么选档,给个粗略的判断。个人开发者、一天断断续续用几个小时,Pro的20美元基本够,偶尔撞5小时窗口等一等就过去了。如果你是全职靠它干活、一天高强度跑好几个任务,Max的5倍档(100美元)会舒服很多,额度宽出一截、撞墙明显少。只有那种把它当主力生产力、几乎全天候在跑、还经常并行多个worktree的重度用户,才需要考虑20倍档。一个常见的误区是上来就冲最贵的档,其实先用Pro跑一两周、看自己实际多久撞一次窗口,再决定要不要升,比拍脑袋买贵的理性得多。档位是可以随时调的,没必要一步到位。
真正决定花销的,其实不是订阅档,而是用法。同样一个Pro账号,会用的人和不会用的人,月底的额度消耗能差出几倍。差距主要在三处:一是模型选择,无脑全程Opus和“默认Sonnet、按需切Opus”,token消耗不是一个量级;二是返工率,不用计划模式、让它理解偏了闷头干,改崩了重来,等于花两倍的额度办一件事;三是上下文管理,把刷屏的脏活都堆在主对话里,上下文越塞越满、每轮请求越来越贵,而懂得用子代理隔离的人,主对话始终精简、每轮都便宜。所以与其纠结买哪个档,不如先把用法理顺——这也是这篇反复在讲工作流的原因,流程顺了,省下的不只是时间,还有真金白银的额度。
一套能复制的进阶工作流是什么样?
把前面所有环节拼起来,就是一套能直接抄的进阶工作流。我们团队日常跑的大概是这个样子:
开工前,项目里已经有一份精简的CLAUDE.md,把技术栈、命令、关键规矩交代好;该连的外部系统通过MCP接好;提交前过lint、跑测试这类红线用Hooks卡死;团队那套发布流程抽成了Skill。这些是一次配好、长期吃利息的基础设施。
干活时,先用计划模式让它把要改的东西梳理成一个方案,你过一遍确认方向对了再放手——这一步能拦掉大量“它理解偏了闷头改一通”的返工。改动量大或者要试不同方案,就开worktree并行;边角的脏活丢给子代理。它改完之后,靠验证循环自己跑测试、看报错、改到通过,最后才回来跟你汇报。
收尾时,用/cost这类命令瞄一眼这轮花了多少,心里有数。如果发现某类任务反复出现,就考虑把它沉淀进CLAUDE.md或抽成新Skill,让下次更省事。
举个跑顺了之后的真实节奏。某次要给一个独立站加“弃单挽回邮件”功能,涉及订单状态监听、邮件模板、定时任务三块。开工时项目里CLAUDE.md已经写好了技术栈和命名规矩,数据库通过MCP接着。第一步不是让它写代码,而是用计划模式让它把方案列出来——它给了个分四步的计划,其中“监听订单状态”那步它打算改一个核心的订单服务文件,保哥看出来风险大,就让它改成新增一个独立的监听器、不动核心服务。方向对齐后放手,它在一个worktree里把三块都实现了,期间跑测试刷出来的一长串输出走的是子代理,主对话里干干净净。改完Hooks自动拦了一道——发现邮件模板里硬编码了一个测试邮箱,提交被卡下来,改掉才放行。整件事从对齐到验证完,比纯手写快了不止一倍,关键是没出那种“它自作主张改崩核心逻辑”的事故。
对比一下没搭流程的样子:直接甩一句“加个弃单挽回功能”,它可能理解偏了闷头改一通,改完你发现它动了不该动的核心服务、还把一个测试邮箱写死提交了上去,返工的时间比省下的还多。同样的工具,有没有这条流程,结果天差地别。这也是这篇反复强调“工作流比命令重要”的原因。
这套流程的精髓不是某个具体命令,而是几个判断:什么活用Sonnet、什么活才值得切Opus;什么时候该用计划模式先对齐、什么时候可以直接放手;哪些规矩软约束就够、哪些必须Hooks硬卡。这些判断怎么练、五个核心实践具体怎么落地,保哥写在了最佳实践那篇,可以当这套工作流的操作手册配着看。
新手到进阶,应该按什么顺序学?
地图铺完,最后给一条不会乱的学习路径,照着走就不会被一堆功能淹没。
第一阶段,先能跑通。装好环境,跑通一个完整任务,养成“按活选模型、先看懂再动手、权限不一把梭”这三个习惯。这一阶段别碰MCP、Hooks这些,太早学用不上反而添乱。
第二阶段,把项目记忆配好。给主力项目写一份精简的CLAUDE.md,用上一两周,看它哪里还在犯重复错误、就往里补对应的规矩。这一阶段你会明显感觉到它“懂你项目了”,提效最直观。
第三阶段,按需加扩展。任务真的需要碰外部系统了,再学MCP;有了不能松动的红线了,再上Hooks;发现某套流程反复手把手教了,再抽Skill。永远是“遇到问题再加对应工具”,不是先囤工具再找场景。
第四阶段,上并行和多代理。当你一天要处理好几个任务、或者开始接大活时,自然会需要worktree和子代理。到这一步你已经对它的脾性很熟了,加并行是水到渠成。
这条路径的核心逻辑是:每一步都解决你当下真实碰到的痛点,而不是提前学一堆暂时用不上的东西。Claude Code的功能确实多,但你不需要一次性全会——顺着工作流主线,缺哪段补哪段,半年下来自然就从把它当补全工具的新手,长成了能用一套流程驾驭它的熟手。这篇地图的作用,就是让你随时知道自己走到了哪、下一步该往哪儿迈。
这套工作流能落到外贸和独立站的哪些活上?
前面讲的都是通用骨架。落到出海独立站、外贸这类场景里,它能干的远不止改业务代码,下面几类活是团队里跑得最实的。
建站和主题二开。独立站尤其是Shopify、WordPress这套,日常一大半工作是改主题、调模板、写小功能。这类活的特点是涉及好几个文件、还得保证不把现有版式搞坏,正好是Claude Code的主场。把项目的技术栈、文件结构、命名约定写进CLAUDE.md,它改起Liquid模板或PHP主题就有谱多了,不会动不动用错钩子、改崩布局。
SEO相关的批量活。给几百个产品页补结构化数据、按规则批量改meta、检查站内链有没有断、把一批旧文的格式统一——这些重复又枯燥的活,是最该交给它的。把一套处理规则抽成Skill,一句话触发就能成批跑,比手工一个个改靠谱得多。涉及读取站点数据、对接搜索后台的,再用MCP把数据源接进来。这块怎么把官方技能用到SEO自动化上,站内的Claude Skills拆解那篇有具体例子。
数据和报表。外贸团队常要从订单库、广告后台拉数据做分析。通过MCP接上数据库后,你可以直接让它“查上个月各渠道的转化成本,按ROI排个序”,它写SQL、跑查询、整理结果一条龙。脏活——比如刷出几百行的查询日志——丢给子代理去消化,主对话只收一份干净的结论。
合规和踩坑排查。出海绕不开各地的合规红线,代码层面有些事是绝对不能犯的(比如把用户数据写到不该写的地方、漏了某个地区要求的同意弹窗)。这种硬底线就该用Hooks卡死,而不是指望每次都记得检查。把“提交前必须过这几项检查”做成钩子,比写在文档里让它自觉靠谱一个量级。
这些场景的共性是:它们都不是“写一个孤立的函数”,而是“在一个有规矩、有上下文、有红线的真实项目里干一连串相关的活”。这恰恰是Claude Code相对补全工具的优势所在,也是为什么前面那条工作流主线值得花时间搭——场景越复杂、越重复,把流程理顺的回报就越大。
常见问题解答
Claude Code和GitHub Copilot这类补全工具能互相替代吗?
不是替代关系,是两种活。补全工具强在你逐行写代码时的即时联想,手不离键盘;Claude Code强在把一个完整目标整段交给它自己去拆解、跨文件改动、跑测试。很多人两个一起用:写细节时靠补全,做整块功能或重构时交给Claude Code。按任务性质选,别指望一个全包。
新手第一步最该做什么,是先把所有命令背下来吗?
恰恰相反。第一步是装通环境、跑通一个真实任务,把“按活选模型、先看懂再动手”这两个习惯养成。命令用到了自然会记住,一开始背命令表是最低效的学法。把CLAUDE.md写好的收益,远大于多记十个命令。
CLAUDE.md、MCP、Hooks、Skills这些是不是都得配齐才能用?
完全不用。CLAUDE.md建议尽早写,投入产出比最高;MCP、Hooks、Skills都是按需加的——任务需要连外部系统才上MCP,有硬底线才上Hooks,有反复套路才抽Skill。没遇到对应场景就先放着,硬凑反而增加复杂度。
worktree和子代理有什么区别,新手要学吗?
worktree隔离的是文件工作区,让它能在多个分支并行改动不打架;子代理隔离的是上下文,把会刷屏的脏活丢出去、只收一句结论。两个都属于进阶能力,新手阶段用不上,等你开始一天处理多个任务时再学也不迟,别一上来就钻这块。
一个月的开销大概怎么估,怎么压成本?
Pro每月20美元能覆盖个人中等强度使用。压成本的第一招是默认用Sonnet、只在硬骨头上切Opus;第二招是用计划模式减少跑偏返工;第三招是了解5小时加每周的双层限额、避开无谓的重复跑。2026年5月限额翻倍后,多数人其实够用,先按这几招调,不够再升档。
本文标题:《Claude Code完全指南:从安装到工作流,一篇看懂整条主线》
本文链接:https://zhangwenbao.com/claude-code-complete-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0