Google抓取报告怎么读?五类问题URL的占比与排查顺序
本文目录
- Google把抓取问题拆成了哪五桶?
- 为什么是“两个URL错误”占了七成五?
- 你的站到底属于哪一桶?
- 分面导航那50%:为什么一上来就用robots封是错招?
- 动作参数那25%:最被忽视、其实最好治的一类
- 怎么把“加入购物车”从GET改成POST而不踩坑?
- 已经被爬烂了的动作URL怎么收尾?
- 无关参数那10%:会话ID、UTM和跟踪参数怎么处理?
- 插件挂件那5% 和“其它”那2%:占比小为什么也得治?
- 怎么按占比排修复优先级,而不是一上来就全封?
- 修完之后,怎么确认真的生效了?
- 修好了又被新功能打回原形,怎么防?
- 怎么从服务器日志算出每一桶各吃掉了多少抓取预算?
- noindex、canonical、robots在这五桶里到底各管什么?
- 拿不到服务器日志,只用GSC能诊断到什么程度?
- 常见问题解答
- 小站点没几个页面,需要管抓取问题吗?
- 直接在robots.txt写一行把所有带问号的URL全封掉,不行吗?
- 动作参数改成POST会不会影响用户体验或转化?
- 怎么快速判断我的站主要中了哪一桶?
- 修复后多久能看到效果?需要主动做什么催一下吗?
- 权威参考资料
摘要:Google自己把抓取问题的成因拆成了五桶——分面导航占五成、动作参数占两成半、无关参数一成、插件挂件半成、剩下两成是双重编码这类怪东西;七成五的麻烦就卡在前两类URL错误上。这篇不教你把带参数的URL一把梭全封掉(那恰恰是掉量最快的错招),而是教你按症状对号入座到自己属于哪一桶、按占比排修复优先级,并给出每一桶的具体处置,尤其是几乎没人认真治、却最好治的那25% 动作参数。
Google的Gary Illyes和Martin Splitt在年末那期播客里复盘了一整年收到的抓取与索引求助,给了一组很少见的内部分布数据:他们手上那些“站点被爬不动、收录上不去”的严重案例,绝大多数不是因为内容差、也不是因为服务器烂,而是因为站点自己造出了一堆机器没法处理的URL。更关键的是,这些麻烦高度集中在两个非常具体的URL错误上,加起来就占了四分之三。
很多人一听“抓取问题”就去查robots.txt、查sitemap、查服务器响应速度,方向全错了。真正的病根在URL结构——你的站在用户每点一次筛选、每加一次购物车、每带一个跟踪参数时,悄悄给搜索引擎生成了成千上万个长得几乎一样、却各自独立的网址。Googlebot不知道这些是垃圾,它会老老实实一个个去爬,爬到精疲力尽,真正值钱的页面反而轮不上。Illyes的原话大意是:发现阶段的爬虫“像个疯子”,会想把它看到的所有URL都抓一遍再做判断。
Google把抓取问题拆成了哪五桶?
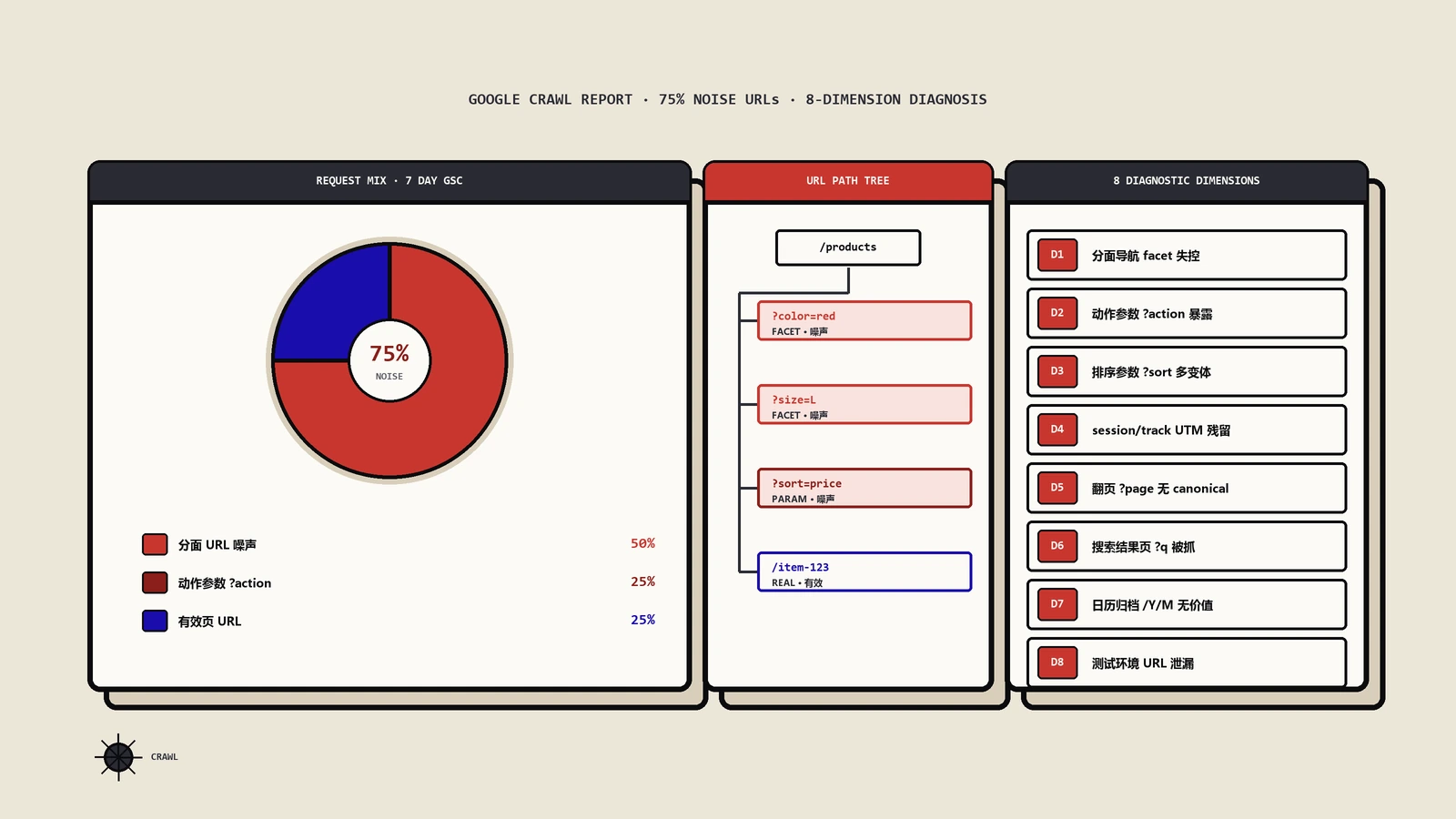
先把这组分布数据摆清楚。这不是某个第三方工具的统计,是Google抓取团队按自己一年里处理的严重案例归类出来的占比:
| 成因桶 | 占比 | 典型长相 |
|---|---|---|
| 分面导航(筛选器组合) | 约50% | 颜色、尺码、价格、品牌自由叠加,几百个商品炸出几百万个近重复URL |
| 动作参数 | 约25% | ?add_to_cart=true、?wishlist=add、?action=save、?sort=price 这类触发动作、不产生新内容的URL |
| 无关参数 | 约10% | 会话ID(?sid=12345)、UTM跟踪、广告点击参数,不改变页面内容却生成唯一网址 |
| 插件与挂件 | 约5% | 日历挂件能一路“下个月”点到3000年、第三方插件给链接乱挂参数 |
| 其它怪东西 | 约2% | 双重编码URL(%2520 这种)、相对路径拼错导致的无限嵌套等边缘情况 |
把第一桶和第二桶加起来,就是标题里那个75%。这两类的共同点是:都不是“写错了某一行配置”,而是站点的交互设计天然在批量生产无意义URL。这也是为什么单纯改robots、改sitemap不解决问题——你堵住的是水管末端,水龙头还在哗哗放。
为什么是“两个URL错误”占了七成五?
因为这两类都符合一个结构特征:用户的一次普通操作,会被前端翻译成一个带新参数的、可被爬虫发现的链接。筛选器是“多个维度自由组合”,组合数是乘法爆炸;动作参数是“每个商品 × 每种动作”,也是乘法。乘法一旦失控,几千个真实页面瞬间膨胀成几百万个URL,而其中99.9% 是搜索引擎根本不需要的。Googlebot在发现阶段没有上帝视角,它必须先把这些都排进抓取队列,才能慢慢判断哪些该丢。队列被垃圾占满,新品页、重要文章就只能干等。
剩下三桶占比小,但有个反直觉的点:占比小不等于危害小。一个把“下个月”点到3000年的日历挂件,理论上能造出无穷个URL,单点就能拖垮一个中小站的抓取预算。占比是“有多少站栽在这”,不是“栽进去有多惨”。
你的站到底属于哪一桶?
诊断比修复重要。不先定位就动手,最常见的结果是把好页面也一起误伤。判断属于哪一桶,靠两个数据源:Google Search Console的“抓取统计信息”报告,和服务器原始访问日志。GSC告诉你Googlebot这段时间都抓了些什么、按响应码和文件类型怎么分布;服务器日志更细,能让你按URL模式聚合,看清爬虫到底把时间烧在哪类参数上。
下面这张对照表,是按“你观察到的症状”反推“大概率属于哪一桶”:
| 症状 | 大概率属于 | 快速验证动作 |
|---|---|---|
电商站,新品类页几周才被抓一次,日志里全是带 ?color=?size= 组合的URL | 分面导航(50% 桶) | 日志按参数名聚合,看带筛选参数的请求占总抓取量比例 |
抓取量突然飙升,但抓的大多是 ?add_to_cart?compare?sort 这种 | 动作参数(25% 桶) | GSC抓取统计里“按用途”看“发现”占比是否异常高 |
同一篇文章被抓了几十个版本,区别只在 ?utm_?gclid?sid | 无关参数(10% 桶) | 抽一个高流量URL,site: 加inurl查它有多少带参变体被收录 |
| 日志里出现年份很离谱的日期URL、或某个第三方功能页的海量变体 | 插件挂件(5% 桶) | 按URL路径前缀聚合,找出非自己设计的高频路径 |
大量404/软404,URL里有 %25%2520 或路径无限重复嵌套 | 其它怪东西(2% 桶) | 过滤日志里响应码非200且含编码异常的请求 |
大多数站不是只中一桶。一个跑了几年的电商站,往往是50% 桶为主、混着10% 桶的UTM污染,再叠一个装多了插件带来的5% 桶。诊断的目的不是给站贴一个标签,而是算出每一桶各吃掉了你多少抓取预算,才能决定先治哪个。
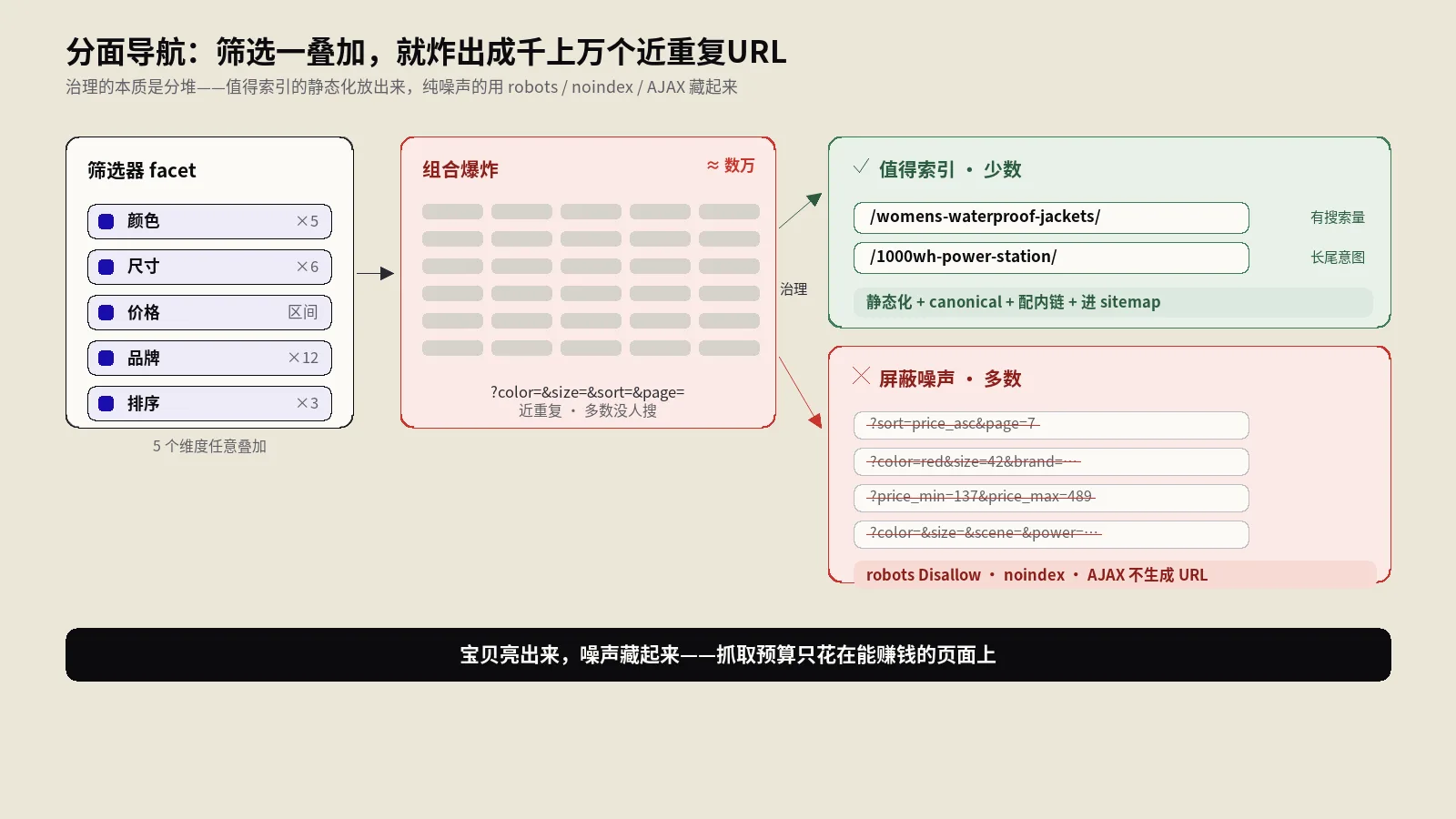
分面导航那50%:为什么一上来就用robots封是错招?
这是占比最大的一桶,也是最多人治错的一桶。绝大多数人的第一反应是:在robots.txt里写一行 Disallow: /*?,把所有带参数的URL全挡掉。这个动作短期看抓取量是降下来了,但它同时把Googlebot挡在了门外——爬虫根本读不到这些页面,也就读不到你给它们设的canonical、noindex这些处置信号。结果是:已经被收录的薄筛选页继续挂在索引里出不来,新的处置又传不进去,站点反而进退两难。
分面导航的正确解法不是“封”,而是“按维度判断哪些筛选组合真有人搜、用什么手段分别处理”,这套机制比较长,单独展开会喧宾夺主。它的系统化拆解(组合爆炸原理、三类危害、robots / noindex / canonical / 源头不可爬的边界与决策矩阵)站内有一篇专门的分面导航筛选器URL爆炸的系统治理,这里只给本文的定位结论:分面导航是占比最大的成因,但它的处置最讲究分场景,绝不是一刀切能解决的;如果你诊断下来主要问题在这一桶,按那篇的决策矩阵走,别在这里图省事。
本文真正要重点补的,是另外那25% ——动作参数。这一桶的占比仅次于分面导航,却几乎没有专门的治理内容,大多数站点甚至不知道自己中了招。
动作参数那25%:最被忽视、其实最好治的一类
动作参数指的是:用户在页面上做了一个“动作”,前端用一个带参数的GET链接来实现它,而这个链接对搜索引擎没有任何内容价值。最典型的就是“加入购物车”被实现成 <a href="/product/123?add_to_cart=true">,类似的还有收藏(?wishlist=add)、对比(?compare=add)、保存(?action=save)、排序(?sort=price_asc)、切换视图(?view=grid)。
它最被忽视的原因是:这些URL用户点了确实“有反应”,开发觉得没问题,SEO又很少去看前端怎么实现交互。但Googlebot不会真的去“加购物车”,它只看到一个能点的链接,于是把每个商品 × 每种动作都排进抓取队列。一个有一万SKU的站,光“加购”这一个动作就能凭空多出一万个被爬的垃圾URL,再乘上收藏、对比、排序,量级直接上去了。
说它最好治,是因为它的根因单一、处置明确,不像分面导航那样要分场景权衡。核心就两条原则:能不暴露成可爬链接的就别暴露;已经暴露了的就明确告诉爬虫别浪费时间。
| 动作参数类型 | 例子 | 推荐处置 |
|---|---|---|
| 购物车/收藏/对比 | ?add_to_cart ?wishlist=add | 改成POST提交,根本不生成可爬GET链接 |
| 排序/视图切换 | ?sort= ?view= | 保留交互但加 rel="nofollow" + canonical回无参版 |
| 分享/打印 | ?share= ?print=1 | robots.txt精确Disallow该参数(不是全参数一把封) |
| 历史遗留、已被大量收录的动作URL | 站内任何旧的动作链接 | 先canonical收口,确认重新抓取后再考虑robots |
怎么把“加入购物车”从GET改成POST而不踩坑?
原理是:搜索引擎默认只跟GET链接,不会主动去触发POST表单。把动作类操作从 <a href> 改成一个POST表单(或前端用fetch发POST异步请求),爬虫就根本发现不了这些URL,从源头掐断。这是治本,比任何事后封堵都干净。
但有两个坑要避开。第一,改造后务必保证无JavaScript环境下功能仍可用或至少优雅降级——有些站把加购全塞进前端JS,结果爬虫看到的是个死按钮,反而影响对页面本身的理解。第二,别忘了站内已经存在的旧链接、邮件营销里的旧链接、外站可能挂着的旧动作链接,这些不会因为你改了前端就消失,需要配合后面那条收尾动作一起处理。
已经被爬烂了的动作URL怎么收尾?
很多站的情况是:动作参数已经被Googlebot爬了几个月,索引里积了一堆。这时候直接robots封掉是错的——封了之后Google读不到你的canonical,这些垃圾URL会在索引里赖很久。正确顺序是:先给所有带动作参数的URL加canonical指回干净版本,并对其中无内容价值的返回noindex;等GSC的覆盖率报告显示这些URL被重新抓取、状态变成“替代网页(有适当的规范标记)”或被移出索引后,再在robots里精确Disallow这些参数,彻底关掉抓取入口。顺序反了,等于把处置信号也一起封死。
无关参数那10%:会话ID、UTM和跟踪参数怎么处理?
这一桶是会话ID(?sid=?PHPSESSID=)、UTM系列(?utm_source= 等)、广告点击ID(?gclid=?fbclid=)、以及Google购物自己挂的 ?srsltid=。它们的共同特征是:完全不改变页面内容,纯粹为了追踪,但每一个不同的值都让搜索引擎看到一个“新URL”。
会话ID是其中最危险的,因为它每个访客每次会话都不同,理论上能把一个页面炸成无穷个变体——这种站现在已经少了,但老系统、某些Java老站还在用,一旦Googlebot撞上会非常惨。处置上:会话ID最好从架构上彻底干掉,改用cookie;UTM和广告参数则统一靠canonical指回无参版本,并确保站内链接本身绝不挂跟踪参数——很多站的流量自残正是出在“内链上图省事挂了UTM”,这个隐形漏洞站内单独拆过内链挂追踪参数的隐形伤害,电商站尤其常踩。
这里有个很多人不知道的冷门点:参数顺序不一致本身也会炸URL。?color=red&size=l 和 ?size=l&color=red 在搜索引擎眼里是两个不同URL,内容却完全一样。如果你的前端在不同入口生成的参数顺序不固定,等于把同一个页面的变体数又翻了几倍。规范做法是后端统一把参数按字母序排序后再301到规范形式,或者至少保证canonical一致。canonical到底怎么被Google选取、什么时候会被忽略,是处理这一桶的关键前置知识,站内有Google到底怎么挑规范网址那篇,遇到canonical不生效先去那篇对照排查。
插件挂件那5% 和“其它”那2%:占比小为什么也得治?
这两桶占比加起来只有7%,但前面说过,占比是“多少站栽在这”,不是“栽进去多惨”。它们的特点是单点爆破力强:一个设计不良的日历挂件,允许用户无限点“下个月”,爬虫顺着能一路爬到公元3000年,单这一个组件就能把一个中小站的抓取预算全吃光。第三方插件也是重灾区——某些WordPress插件会在每个链接后挂上自己的追踪参数,Google抓取团队甚至专门给一些插件提过bug。
“其它”那2% 是各种边缘情况:双重编码URL(%2520 实际是把已经编码过的 %20 又编码了一次)、相对路径拼错导致的 /a/b/a/b/a/b/... 无限嵌套、错误的链接生成逻辑造出的畸形地址。这些靠肉眼几乎发现不了,只能在服务器日志里按响应码和URL特征过滤:把非200、含异常编码、或路径段数远超正常值的请求拉出来,基本就能定位到是哪个组件在作妖。
处置原则统一是:先在日志里定位是哪个具体组件/插件生成的,能从配置里关掉这个行为最好;关不掉的,针对它生成的特定路径或参数做精确robots屏蔽,并给已收录的部分加noindex收口。不要因为占比小就放着不管——这一桶的特点恰恰是“平时没事,一旦触发就是断崖”。
怎么按占比排修复优先级,而不是一上来就全封?
知道了五桶,下一个问题是先治哪个。答案不是“占比最大的先治”,而是“占比 × 你站实际中招程度 × 修复成本”三者权衡。一个没有筛选器的纯内容站,分面那50% 跟它无关,它的主要矛盾可能在插件那5%。所以前面诊断阶段算出的“每桶各吃掉多少抓取预算”才是排序依据。
下面这张矩阵是保哥给客户做抓取问题诊断时实际用的排期框架:
| 成因桶 | 止血动作(当周) | 治本动作(1-2个月) | 验证口径 |
|---|---|---|---|
| 分面导航50% | 给确认无搜索价值的组合页加noindex,先别动robots | 按搜索需求保留少数组合页、其余从源头不可爬,详见专篇决策矩阵 | 日志里筛选参数请求占比下降,品类页抓取频次回升 |
| 动作参数25% | 高频动作URL加canonical + nofollow | 加购/收藏/对比类改POST,旧链接canonical收口后再robots封 | GSC“发现”占比回落,动作URL移出索引 |
| 无关参数10% | 站内链接清掉所有UTM;UTM/广告参数加canonical | 会话ID改cookie,后端统一参数排序后301 | 同一页带参变体收录数收敛到1 |
| 插件挂件5% | 关掉无限空间型挂件的越界点击 | 审计所有第三方插件的URL生成行为,精确屏蔽 | 离谱日期/非自有路径请求归零 |
| 其它2% | 日志定位畸形URL来源组件 | 修链接生成逻辑,编码统一 | 非200 + 编码异常请求归零 |
贯穿所有桶的一条铁律:先止血、再治本,绝不一上来就robots一把梭全封。一把梭封掉所有带参数URL,是这个领域最经典的自伤动作——它让爬虫读不到你正在做的所有处置,等于把急救包也锁进了保险柜。robots永远是最后一步,是在canonical和noindex的处置信号已经被Google重新抓取确认之后,才用来彻底关闭入口的工具。这五桶里除了纯架构层面的会话ID和畸形URL,几乎没有一桶应该把robots当第一招。抓取预算本身怎么测、怎么按GSC抓取统计和服务器日志系统优化,是这套诊断的下游配套,站内另有一篇抓取预算到底怎么优化,治完成因后用它来做长期监控。
修完之后,怎么确认真的生效了?
抓取问题的修复最难受的一点是:它没有立竿见影的反馈。改完代码不会第二天就看到排名涨,Googlebot重新评估一个站的抓取模式通常要4到8周。所以不能凭感觉,得盯三个客观指标。
第一,GSC的抓取统计信息报告:看“总抓取请求数”里花在垃圾URL模式上的比例有没有下降,看“按响应”里200占比是否回升、4xx/5xx是否收敛,看“按用途”里“发现”相对“刷新”的占比是否回到正常区间——发现占比异常高,正是爬虫在追逐新生成的垃圾URL的特征。第二,服务器日志做修复前后对比:按参数模式聚合Googlebot的请求,垃圾模式的绝对请求数应该明显下掉,重要页面(品类页、核心文章)的抓取频次应该相应上来。第三,索引覆盖率报告:被处置的URL应该逐步从“已编入索引”转到“替代网页(有适当的规范标记)”或被移出,而你真正想收录的页面“已编入索引”数量应该稳中有升。
同时要盯几个典型失败模式。最常见的是 robots封早了:处置信号还没被读到就把入口关了,结果垃圾URL在索引里赖着不走,你看着覆盖率报告里那一堆“已被robots.txt屏蔽但仍编入索引”干着急。第二种是 canonical被忽略:canonical是建议不是命令,如果你给一个内容差异明显的页面canonical到另一个页面,Google会直接无视——这时候要回到canonical选取逻辑那篇去排查,多半是信号自相矛盾。第三种是 只治了一桶就以为完事:站点往往多桶并发,治完分面导航抓取量降了一截,但动作参数那25% 没动,过两个月又涨回去。诊断阶段那张“每桶吃掉多少预算”的账,修完要重新跑一遍核对。
修好了又被新功能打回原形,怎么防?
这是真实项目里最高频的复发剧情:花两个月把动作参数那25% 治干净,半年后产品上了个“一键分享到各平台”的功能,每个分享按钮又挂一串带参URL,悄悄把这一桶重新撑起来,等下次发现已经是又一轮掉量。根因不是修得不彻底,而是修复没有沉淀成一道关。
有效的做法是把“URL卫生”塞进上线流程,做成一个不依赖人记性的检查关:任何新功能、新插件、前端交互改动上线前,过一遍三个问题——这个改动会不会生成用户操作触发的新URL?这些URL对搜索引擎有内容价值吗?如果没有,是用POST、还是nofollow+canonical、还是精确robots处理掉了?三个问题任一答不上来就不准上线。再配一个低成本的回归监控:定时跑一个脚本扫站点新出现的参数模式,发现没见过的参数名就告警。这两道关加起来,能把“修好又回退”这个最耗人的循环基本掐死。说到底,抓取问题不是一个修一次就好的技术债,而是一个需要随站点演进持续盯的健康指标——把这五桶做成一张季度体检清单,再加一道上线关,比出了事再救火省太多。
怎么从服务器日志算出每一桶各吃掉了多少抓取预算?
前面反复说“按每桶吃掉多少预算来排序”,这一步到底怎么落地,是整套诊断里最实操、也最少有人讲清的环节。GSC抓取统计只能给你粗分布,真正能精确到“筛选参数吃了百分之多少”的,只有服务器原始访问日志。方法不复杂,关键是先把Googlebot的真实请求摘干净,再按参数模式归桶。
第一步,从日志里只过滤出Googlebot的请求,并且要反查IP——现在伪装成Googlebot的垃圾爬虫非常多,User-Agent带Googlebot不代表真是Google,得对来源IP做反向DNS解析确认落在Google的地址段,否则你算出来的分布是被脏数据污染的。第二步,把过滤后的请求按URL里的参数特征归类:含 color/size/brand/price 等筛选词的归分面桶,含 add_to_cart/wishlist/sort/compare 等动作词的归动作桶,含 utm_/gclid/sid/sessionid 的归无关桶,路径命中已知插件前缀的归插件桶,剩下响应码异常或编码畸形的归其它桶。第三步,每桶的请求数除以Googlebot总请求数,就是这一桶在你站实际吃掉的抓取份额。
举个保哥经手过的真实形态(数字按机制说明,不写具体业绩):一个出海3C数码配件独立站,主营手机壳、充电器这类强“机型兼容”属性的品类。它的筛选维度是“适配机型 × 颜色 × 接口类型 × 价格区间”,四个维度自由组合。日志反推下来,Googlebot的请求里压倒性多数都砸在带 compatible_model= 组合的URL上,真正的品类页和产品页加起来抓取频次低得可怜——新品上架两周还没被抓到。这个站之前的“优化”恰恰是最典型的错招:技术同学嫌乱,直接在robots里 Disallow: /*? 一把封了,结果筛选页全留在索引里出不来,新品又因为站整体抓取信号差迟迟不收录,两头堵。解法不是封得更狠,而是先按日志确认“适配机型”这个维度是真有搜索需求的(用户确实在搜“某机型 手机壳”),把这一个维度做成可被收录的干净路径页,其余三个维度的组合从源头不暴露成可爬链接。机制讲透了,动作是确定的,没有玄学。
另一个对照形态是B2B SaaS的文档站,它没有电商那种筛选器,主要矛盾在动作参数和插件桶:文档页带了一个“反馈是否有用”的挂件,每篇文档生成 ?helpful=yes?helpful=no 两个可爬变体;还有一个活动日历挂件能无限翻月份。这类站日志反推出来,动作桶 + 插件桶能占到一大半。处置思路完全对应前面的矩阵:反馈挂件改POST,日历挂件关掉越界翻页,两个动作就把大头解决了。同样是抓取问题,电商站和文档站的主桶完全不同,这就是为什么不能套模板、必须先按日志归桶。
noindex、canonical、robots在这五桶里到底各管什么?
这三个工具被混用是抓取问题治不好的头号原因。它们解决的是完全不同的事,放错位置不仅没用还会互相打架。一句话区分:robots管“爬不爬”,noindex管“收不收”,canonical管“算谁的”。
| 工具 | 它真正做什么 | 挡不住什么(常见误解) | 在本文场景里的正确用法 |
|---|---|---|---|
| robots.txt Disallow | 阻止爬虫抓取该URL | 挡不住已被外链发现的URL进索引;挡了之后读不到canonical/noindex | 永远是最后一步,等处置信号被确认后才用来彻底关入口 |
| meta noindex | 允许抓取但不收录,已收录的会被移出 | 挡不住抓取,仍消耗抓取预算;被robots封住时根本读不到 | 给确认无搜索价值的筛选页/动作页收口,让它退出索引 |
| canonical | 告诉引擎“这些近重复算到主版本头上” | 是建议非命令;内容差异大时会被直接忽略 | 处理无关参数、参数顺序变体、轻度近重复的首选 |
组合使用的正确时序也是固定的:先canonical或noindex把处置信号铺下去 → 等Googlebot重新抓取、GSC覆盖率报告确认信号被读到并生效 → 最后才用robots关闭抓取入口。这个顺序背后的逻辑只有一句话:robots一旦先行,爬虫连你后铺的canonical/noindex都读不到,处置就永远卡在半路。这五桶里只有两种情况可以让robots当第一招——一是会话ID这种从架构上就该彻底消灭、根本不存在“想保留收录”诉求的;二是双重编码、无限嵌套这种纯畸形、留着只有害处的。除此之外,先动robots几乎都是错的。
拿不到服务器日志,只用GSC能诊断到什么程度?
前面的归桶方法默认你能拿到服务器原始日志。现实里相当一部分站点跑在托管型主机或被代运营卡着权限,根本摸不到原始日志。这种情况不是没法做,只是精度差一档,得换一套打法,把GSC几个报告榨干。
第一个要榨的是“抓取统计信息”里的按用途拆分。它把Googlebot的请求分成“发现”和“刷新”两类。健康的站应该是刷新为主、发现占小头;如果发现长期占大头,几乎可以断定有URL爆炸源在持续生成新链接让爬虫追,这时候虽然GSC不告诉你是哪一桶,但“有爆炸源”这个结论已经成立,足以触发下一步排查。第二个是按响应:200占比掉、3xx或4xx异常高,通常意味着大量参数URL在被抓后跳转或报错,对应无关参数桶或畸形桶。第三个是按文件类型:如果HTML抓取占比被压得很低、其它类型占比异常,说明爬虫的预算被非内容资源分走了。
GSC之外还有两个不需要日志权限的土办法。一是 site: 加 inurl: 抽查:挑几个高流量页面,查它带各种参数的变体被收录了多少,如果一个页面带 ?utm?sort 的变体收录了几十条,无关参数桶和动作参数桶的问题就坐实了。二是看GSC的“网页索引”报告里那些“已抓取但未编入索引”和“重复网页”的样本URL,把它们的参数模式拉出来归类,本质上是用Google替你聚合了一份简版日志。这套GSC-only打法的精度做不到“筛选参数吃了37%”这种量化,但完全够支撑“有没有问题、大概在哪一桶、先治哪个”的决策——而决策本来就是诊断的真正目的。
要补一句预期管理:GSC抓取统计的数据有2到3天延迟,且是采样汇总,不能指望它像日志一样实时精确。它适合判趋势和方向,不适合抠绝对数字。真要量化精度,还是得想办法弄到日志,哪怕只是让运维导出最近两周的一段也好。
常见问题解答
小站点没几个页面,需要管抓取问题吗?
需要,但优先级判断不一样。Google确实说过几千页以内的小站一般不用操心抓取预算,但那说的是“正常结构的小站”。如果你的小站装了会无限生成URL的插件或日历挂件,几十个真实页面照样能炸出几十万个垃圾URL,这时候问题跟站大小无关,跟“有没有URL爆炸源”有关。先做诊断,确认没有爆炸源就可以不操心,有的话再小也得治。
直接在robots.txt写一行把所有带问号的URL全封掉,不行吗?
短期降抓取量有效,长期是错的。robots屏蔽只是不让爬,但挡不住已经被发现的URL留在索引里,更挡不住你给这些URL设的canonical、noindex被读到。结果常常是:你想清的没清掉,处置信号又传不进去。正确做法是canonical/noindex先行,等Google重新抓取确认处置生效后,robots才作为最后一步关闭入口。
动作参数改成POST会不会影响用户体验或转化?
正确实现不会。加购、收藏这类操作本来就更适合用POST(它们是“改变状态”的请求,语义上就不该是GET)。改造时保证有无JavaScript都能用、按钮反馈即时即可。真正影响体验的是改造偷懒——比如全塞进前端JS又没做降级,导致部分用户点了没反应,那是实现问题不是POST本身的问题。
怎么快速判断我的站主要中了哪一桶?
最快的办法是看服务器日志:把最近一两周Googlebot的请求按URL参数模式聚合,看哪类参数(筛选类、动作类、跟踪类)的请求数占比最高,占比最高的那类基本就是你的主要矛盾。没有日志权限的话,退而求其次用GSC抓取统计的“按用途/按文件类型”做粗判,再配合site: 加inurl抽查带参变体的收录量。
修复后多久能看到效果?需要主动做什么催一下吗?
Googlebot重新评估抓取模式通常4到8周,急不来。能做的“催”很有限:保证服务器响应稳定(让爬虫敢多抓),用sitemap把真正想收录的重要页面递清楚,重要页面适度更新内容触发重抓。但别指望Indexing API或反复在GSC点“请求编入索引”能加速整体抓取健康——那些是单页级别的工具,解决不了结构性的URL爆炸。耐心盯前面说的三个指标,按4到8周的节奏复盘。
权威参考资料
本文标题:《Google抓取报告怎么读?五类问题URL的占比与排查顺序》
本文链接:https://zhangwenbao.com/google-crawling-issues-url-mistakes-diagnosis.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0