给内链加UTM参数为什么伤SEO?流量分析与抓取的取舍
本文目录
- 给内链加UTM,到底动了SEO的哪根筋?
- 追踪参数是怎么把抓取预算一点点烧光的?
- 抓取预算的真相,不是“爬虫来了多少次”
- 参数URL是怎么指数级膨胀的
- 怎么自己查出来有没有这个坑
- 为什么canonical补不上这个洞?
- 自然流量的功劳,怎么被内链偷走了?
- GA4为什么一遇campaign参数就重开会话
- 最后点击模型下,功劳是怎么搬家的
- 在GA4里怎么验证你中招了
- 被分享出去的脏URL,怎么把外链权重打散的?
- URL膨胀不只是SEO问题,还拖慢页面、挡住AI?
- 正解:把追踪从URL层搬进DOM层
- 用data属性承载追踪信息
- 用一个全局点击监听把数据送进分析工具
- 存量内链怎么批量迁移
- 不同参数不能一刀切:追踪参数、筛选参数、Google自家参数怎么分
- 千万别把外部活动的utm也一起误删了
- 落地之后怎么验证修对了?什么情况下可以不管?
- 常见问题解答
- 内链加utm参数Google会自动忽略吗?
- 给所有参数URL加自指canonical能解决问题吗?
- 不在URL里放utm,市场团队怎么知道哪个位置带来的点击?
- No-Vary-Search响应头能不能替代去参数?
- 能不能直接在robots.txt里Disallow掉带utm的路径?
- 这个问题对小网站也严重吗?
- 筛选器URL(如?color=red这种)也要按这套去掉吗?
- 权威参考资料
摘要:给站内链接挂上utm_source这类追踪参数,看着只是埋了个数据点,实际是在四个地方同时放血:搜索引擎把同一个页面当成无数个新URL反复抓、GA4把自然搜索来的会话重新归因给内链、被用户分享出去的脏URL把外链权重打散、CDN缓存被参数撑爆拖慢页面也拖慢AI抓取。canonical补不上这个洞,因为它管的是收录阶段不是发现阶段。真正的解法是把追踪从URL层挪进DOM层。这篇文章把这套机制和可落地的迁移方案讲透。
给内链加UTM,到底动了SEO的哪根筋?
先说一个保哥在客户站上反复见到的场景:市场团队想知道首页那个促销横幅、导航栏里那个“新品”入口、文章底部那排推荐位,各自带来了多少点击。最省事的办法看起来是给这些站内链接的URL后面挂个?utm_source=homepage&utm_medium=banner,这样GA4里一拉报表就能看到每个位置的贡献。逻辑没毛病,工具也确实能跑出数。
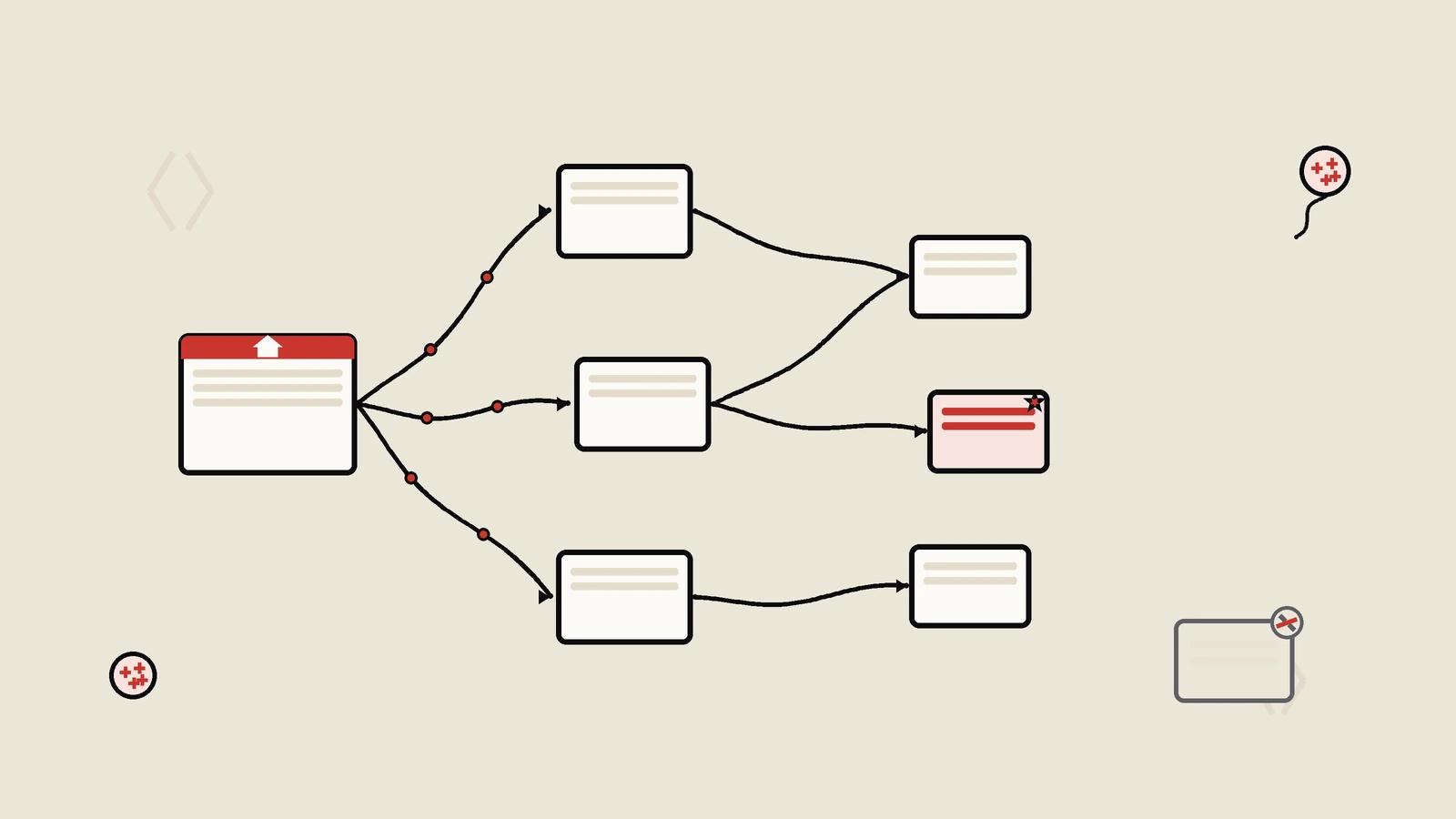
问题在于,URL不是只给分析工具看的,它同时是搜索引擎理解你整个网站结构的地址系统。你往内链上加的每一个参数,对市场团队是一个数据维度,对爬虫却是一个全新的、需要重新抓取和判断的网址。一个页面本来只有一个地址,现在因为站内不同位置链过去时挂了不同的utm组合,变成了几十个甚至几百个看起来不一样、内容完全一样的地址。
这件事的隐蔽性在于,它在小站上几乎没有症状,所以没人当回事;一旦站点规模上来——商品多、文章多、模板里到处是带参数的内链——它会在四条线上同时出问题:抓取预算被烧、归因数据被污染、链接权重被打散、页面性能和AI访问被拖累。更麻烦的是,团队第一反应往往是用canonical去“盖”一下,而canonical恰恰治不了这个病的根。
这篇文章不讲“要注意URL规范”这种正确的废话,而是把这四条线各自的机制拆开讲清楚:每一条到底是怎么坏的、怎么自己动手查出来你有没有中招、为什么常规补救(canonical、robots.txt)是错的方向,以及真正能规模化的修法长什么样。读完你应该能直接拿去排查自己的站,并说服市场和开发团队为什么这件事值得改。
追踪参数是怎么把抓取预算一点点烧光的?
抓取预算的真相,不是“爬虫来了多少次”
很多人理解的抓取预算是“Google每天愿意来抓我多少个页面”,于是优化思路就变成“想办法让它多来抓”。这个理解偏了。抓取预算真正的瓶颈不是请求总量,而是发现效率——爬虫花在“有用的新页面”上的比例。同样是每天抓一万个URL,一个站把这一万次几乎都花在真实内容页上,另一个站把六七千次花在同一批内容的参数变体上,后者的有效抓取其实只剩三四千,重要的新页面、刚更新的页面就排在队尾迟迟轮不到。
追踪参数干的就是把那一万次稀释掉的事。爬虫不会主动判断/product/x和/product/x?utm_source=nav&utm_medium=menu是不是同一个东西——在它眼里,URL字符串不一样就是两个待抓的地址,先抓回来、渲染、对比,才可能判断出重复。utm_、fbclid、gclid、还有各种自定义的vlid、ref串,每一种组合都是一条新的抓取路径。
参数URL是怎么指数级膨胀的
关键在于这个膨胀不是线性的。假设你有一个商品页,站内有五个不同位置会链到它(导航、首页推荐、相关商品、文章内链、面包屑),每个位置挂的utm组合不同,这一个页面就有六个地址(含原始)。再叠加上分页、排序、筛选偶尔也被带了参数,组合数会乘起来。保哥手上一个欧洲做骑行装备的DTC客户,SKU本身就两千多,第一轮全站爬下来的内链URL是三十多万;做了一次市场活动、把活动utm批量铺进了分类页和商品列表的内链模板之后,第二轮再爬,内链URL数直接翻到一百多万。多出来的七十多万,几乎全是同一批商品页挂着不同utm的影子。
这个客户的真实代价不是“多了一百万行数据”这么抽象,而是:新上架的应季商品(骑行是强季节性品类,旺季前两周上的新品最值钱)平均要五到七层抓取深度才被发现,原本两三天能进索引的页面拖到一周开外,等爬虫终于抓到时,旺季的搜索高峰已经过了一半。抓取预算被烧的真实损失,从来不是“浪费了带宽”,而是“最值钱的页面错过了它最值钱的那个时间窗”。
怎么自己查出来有没有这个坑
不用猜,三个动作就能确诊:
- 看服务器日志:把一段时间(建议至少两周)的访问日志里User-Agent是Googlebot/Bingbot/GPTBot的请求拉出来,按URL去重前先统计含
utm_、fbclid、?ref=等参数的请求占总爬虫请求的比例。超过15%就说明爬虫在帮你数自己的影子;超过30%基本可以确定抓取预算在严重失血。落地到命令上就是先按爬虫UA过滤出请求行,再统计带参数请求的占比,一个下午能跑完两周的日志,得到的不是感觉而是一个能直接甩到会议桌上的百分比。 - 看Search Console的抓取统计报告(设置→抓取统计信息):重点看“按响应分类”和“按文件类型”,再点进“已抓取-未编入索引”和“通过备用网页(包含规范标记)发现”这两类,里面如果大量是带参数的内链变体,问题已经实锤。
- 用爬虫工具复现:用Screaming Frog或Sitebulb全站爬一遍,配置上不要剔除参数,爬完按是否含查询参数过滤,再看这些参数URL里有多少是从站内链接被发现的(区别于外部链接带进来的)——站内自己制造的那部分,就是你能完全控制、也最该先清掉的。
这一步的意义在于:它把一个抽象的“最佳实践”变成了一个具体的数字。当你能对市场团队说“你们上次活动的utm让爬虫多抓了七十万个空地址,应季新品的收录晚了五天”,这件事才推得动。
为什么canonical补不上这个洞?
团队意识到参数URL一堆之后,最常见的第一反应是:给所有页面加上自指的canonical标签,让Google知道?utm_source=nav那个版本应该归到干净URL名下。这个动作本身没错,但把它当成解决方案就错了,因为canonical作用在“收录/索引”阶段,而追踪参数的伤害发生在更早的“发现/抓取”阶段。
顺序是这样的:爬虫先得发现一个URL、把它抓回来、渲染出HTML,才能读到里面的canonical标签,然后才决定要不要把它合并到规范版本。也就是说,等canonical开始起作用时,抓取预算这笔钱已经花掉了。带参数的URL照样被发现、照样被抓、照样占用爬取深度,canonical只是在事后告诉Google“这些别单独收录”。你省下的是索引膨胀,省不下抓取浪费。GSC里那条“备用网页(包含适当的规范标记)”的曲线一直涨,正是这个机制的指纹——这些页面Google抓了、读了canonical、决定不单独收录,但抓取的成本一分没省。
那能不能换个思路,干脆在robots.txt里把带utm的路径全Disallow掉,让爬虫根本别去抓?这是另一个更深的坑,能不能在robots.txt里禁掉utm追踪参数这篇里专门拆过:robots.txt的Disallow是“别抓”,不是“别收录”——被Disallow的URL如果有内链或外链指过来,Google照样可能把这个光秃秃的URL(没标题没描述)放进索引;更要命的是,一旦Disallow了,爬虫读不到这些页面的canonical标签,反而切断了你把权重收回到规范URL的那条路。所以robots.txt治不了内链参数,它只在“纯外部来源、且你确定不需要这些URL进索引”的窄场景下成立。
结论很硬:canonical和robots.txt都是在URL已经脏了之后做的损害控制,治标。真正治本的方向只有一个——从源头上让站内链接根本不带这些参数。怎么做到既不带参数又不丢点击归因,是后面要讲的核心。
自然流量的功劳,怎么被内链偷走了?
GA4为什么一遇campaign参数就重开会话
这条线很多团队完全没意识到,因为它不报错、不掉排名,只是让你看到的数据是错的。机制是这样:GA4在判断一次会话归属时,只要URL里出现了它认的campaign参数(utm_source/utm_medium/utm_campaign等),就会把这当成一次“新的营销触点”,重启会话并重新计算流量来源。Adobe Analytics默认不这么干(它的会话切分逻辑不绑campaign参数),所以同一个站在两套工具里看到的来源分布能差出一大截,这本身就是个排查信号。
把这个机制放到一个真实路径上:一个用户在Google搜“防水骑行裤”,自然结果点进你的商品分类页——这一刻GA4正确记录了来源是organic search。他在页面上点了一个你埋了?utm_source=category&utm_medium=internal的相关商品链接,跳到具体商品页。就在这一跳,GA4看到campaign参数,重启了会话,把来源改写成了这个内链。他最后下单了。在最后点击(last-click)或基于会话的归因模型下,这笔订单的功劳记给了“内链”,而不是真正把人带来的自然搜索。
最后点击模型下,功劳是怎么搬家的
后果不是“数据不准”这么轻描淡写。它会直接误导预算决策:自然搜索的转化贡献被系统性低估,SEO在内部汇报里显得“没什么用”;与此同时某个内部位置的“转化”被虚高,可能让团队加大对某个其实没那么关键的位置的投入。保哥见过一个客户因为这个,差点砍掉一个实际在持续带自然流量的内容板块——报表上那个板块“转化贡献”很低,真相是它的功劳全被它自己页面里挂utm的内链截走了。归因被污染最危险的地方,不是数字错了,而是错的数字会驱动错的资源分配,而且没人怀疑报表。
在GA4里怎么验证你中招了
三个检查点:
- 在“流量获取”报告里按“会话来源/媒介”看,如果出现大量像
yourdomain.com / internal、(not set)、或你自己域名作为来源的会话,基本就是内链utm在重启会话。 - 在GA4的DebugView里,自己在站内点几个带参数的内链,观察是不是每次都触发了新的
session_start且session_source变了。 - 对比同一时段GA4和服务器日志/广告平台的来源构成,自然搜索占比如果在GA4里明显偏低、而“直接”或“站内引荐”偏高,就是这个问题的典型画像。
确认中招之后别急着在GA4里做来源排除(referral exclusion)——那又是一个事后打补丁、且容易引入新偏差的做法。根因还是URL里不该有这些参数。
被分享出去的脏URL,怎么把外链权重打散的?
第三条线比前两条更隐蔽,因为它的损害发生在站外。设想用户在你站内点了一个挂着?utm_source=blog&utm_medium=internal的内链,落到一个不错的商品页或指南页,他觉得有用,复制地址栏的URL发到了论坛、社群、或自己的博客里。他分享出去的,是那个带着你内部utm参数的非规范URL,而不是干净的规范地址。
于是你辛辛苦苦挣来的一条外链,指向的是一个本不该独立存在的参数版本。Google对外链权重的归集依赖canonical和URL一致性,当指向同一内容的外链分散在/guide/x、/guide/x?utm_source=blog、/guide/x?utm_source=email&utm_medium=internal等好几个变体上时,这个页面本该集中的链接权重被切成了好几份,每一份都比合并后弱。canonical能帮你把一部分权重最终收拢回规范URL,但这个过程有损耗、有延迟,而且依赖Google愿意听你的canonical建议(它并不总听)。
更扎心的是,内链架构本来的使命是把权重精准导向最该排名的页面,结果因为内链自己带了参数,它不仅没在站内高效传导权重,还在把站外回来的权重往外漏。一个被反复转载分享的优质页面,本来是资产,参数一掺,资产的复利效应被打了对折。这个损害是慢性的、累积的,等你某天发现某个明明很多人引用的页面排名就是上不去,回头查才发现外链全散在十几个utm变体上,已经损失了不止一个季度。
URL膨胀不只是SEO问题,还拖慢页面、挡住AI?
前面三条都还在传统SEO范畴,第四条把问题推到了性能和AI访问层面,而这恰恰是2026年最该重视的一条。
缓存层面:CDN和浏览器缓存默认是按完整URL(含参数)做缓存键的。/product/x和/product/x?utm_source=nav在缓存眼里是两个不同的资源,会各自占一个缓存条目。同一份内容因为挂了几十种utm组合,被缓存系统当成几十份,命中率被稀释,源站被迫反复回源渲染同一个页面,服务器和CDN都在做无用功,页面响应也跟着变慢。配置规范的CDN其实可以在缓存键里主动剥掉utm参数(很多企业级CDN支持),但这要专门配,默认不会帮你做。
这里有个值得单独说的新机制:No-Vary-Search响应头。它允许你显式告诉浏览器“带这些指定参数的URL,请当成同一个资源缓存,不要分开存”。这是专门为utm这类“不改变服务端返回内容、只给客户端做分析用”的参数设计的。目前Chrome 141+已支持,Android端144版本跟进中。它能缓解浏览器侧的缓存碎片,但要注意:它解决的是缓存,不直接解决搜索引擎的抓取发现问题——爬虫该抓的参数URL还是会抓。所以它是补充手段,不是替代“源头不带参数”的方案。
AI访问层面,问题更尖锐。越来越凶的AI爬虫(GPTBot、ClaudeBot、PerplexityBot这类)在大量抓取网页喂给大模型,而这些AI爬虫普遍出于成本和架构原因不做或只做极有限的JavaScript渲染,对URL膨胀比传统搜索引擎更敏感——它们的抓取预算更紧、容错更低。当你的站内充斥着同一内容的参数变体,AI爬虫的有限预算被大量耗在重复影子URL上,真正该被它读进检索语料的规范页面反而抓得不全。
这件事的下游后果直接关联到现在所有人都在焦虑的GEO/AI可见度:进不了AI的检索语料库,就不可能在AI答案里被引用。AI爬虫抓取量已超Googlebot数倍后SEO策略要怎么变这篇里展开过这个新现实——当AI爬虫成了你站点最大流量来源之一,URL卫生从一个“技术洁癖”变成了直接决定你在AI时代有没有声量的基础工程。换句话说,内链参数这个老问题,在AI检索时代被重新标价了,而且贵了很多。
正解:把追踪从URL层搬进DOM层
讲完四条线的伤害,核心解法其实只有一句话:内链指向永远是干净的规范URL,追踪信息不放进URL,放进HTML元素本身。具体落地分三块。
用data属性承载追踪信息
把原来塞进URL的位置信息,改成挂在<a>标签的data属性上。原来是:
<a href="/product/x?utm_source=homepage&utm_medium=hero">立即查看</a>
改成:
<a href="/product/x" data-track-location="homepage" data-track-module="hero">立即查看</a>
href回归干净的规范地址,搜索引擎看到的是唯一URL,缓存只存一份,分享出去也是规范URL。位置信息一点没丢,只是换了个不污染地址系统的地方放。
用一个全局点击监听把数据送进分析工具
在标签管理器(GTM)或全站JS里挂一个委托式点击监听,捕获带data-track-*的链接点击,把这些属性读出来推进dataLayer或直接发给分析工具:
document.addEventListener('click', function (e) { var a = e.target.closest('a[data-track-location]'); if (!a) return; window.dataLayer = window.dataLayer || []; window.dataLayer.push({ event: 'internal_link_click', link_location: a.dataset.trackLocation, link_module: a.dataset.trackModule || '', link_url: a.getAttribute('href') }); });
市场团队要的“哪个位置带来多少点击”一个不少,全在自定义事件里,报表照常出,而且比原来更干净——因为它现在记的是站内交互行为,不再伪装成流量来源,GA4也就不会再错误重启会话、不会再偷自然搜索的功劳。
存量内链怎么批量迁移
新链接好办,难的是历史上散落在模板、CMS字段、富文本正文里的存量脏内链。可行的推进顺序是:
- 先扫存量:在代码库和数据库正文里用正则
href="[^"]*[?&]utm_[^"]*"把带utm的内链全部捞出来,区分“模板/组件生成的”和“编辑手写进正文的”。 - 先改模板,覆盖面最大:导航、推荐位、相关商品、面包屑这些是组件统一渲染的,改一处生效全站,优先级最高、收益最快。
- 正文里的手写脏链批量替换:写个脚本把正文里内链URL的utm段剥掉,保留路径,跑前务必全表备份、小批量灰度。
- 301只用于已被外部引用的脏URL:对那些已经被分享出去、有外链指着的参数URL,加301指回规范地址把权重收回来;纯站内从未外泄的参数URL不需要301,改了内链让它自然消失即可。
下面这张表把这套方案对每个团队的好处摊开,方便你拿去对内沟通——这件事最难的从来不是技术,是说服市场团队“不用URL参数你照样能拿到你要的数据”。
| 受益方 | 原来用URL参数的痛点 | 改成DOM追踪后的收益 |
|---|---|---|
| SEO / 数据分析 | 抓取浪费、归因断裂、权重稀释 | URL唯一、归因干净、权重集中,数据反而更可信 |
| 前端 / 产品 | URL被参数撑长,重构样式时易误改链接 | 追踪层和DOM结构解耦,改样式不碰追踪 |
| 无障碍 / 语义 | 参数URL对屏幕阅读器和爬虫都是噪音 | 链接语义干净,对辅助技术和搜索引擎都更友好 |
| 市场 / 增长 | 位置数据靠脏URL,代价是SEO失血 | 位置数据照拿,不再以SEO为代价 |
| PR / 联盟 | 外发链接暴露内部参数结构 | 追踪藏在JS层,分享出去的是干净URL |
不同参数不能一刀切:追踪参数、筛选参数、Google自家参数怎么分
必须强调一个边界,否则容易矫枉过正:“内链不要带参数”这条规则只针对追踪/营销参数,不能无差别套到所有带参数的URL上。不同性质的参数处置完全不同。
| 参数类型 | 典型例子 | 是否改变页面内容 | 内链里的处置原则 |
|---|---|---|---|
| 追踪/营销参数 | utm_*、fbclid、gclid、ref | 否 | 内链里彻底不要,迁移到DOM |
| 筛选/分面参数 | ?color=red&size=l | 是(改变了展示的商品集合) | 另一套治理逻辑,按抓取价值取舍 |
| 分页参数 | ?page=2 | 是(不同内容) | 保留,配合规范的分页处理 |
| Google自家参数 | srsltid | 否 | 不是你内链加的,单独处置 |
| 会话ID | ?sid=abc123 | 否 | 历史遗留,应彻底从架构里去掉 |
筛选参数是另一个完全不同的难题——它真的改变了页面呈现的内容,不能简单粗暴地“去掉”,得按每个筛选组合有没有真实搜索需求和抓取价值来分类治理。电商筛选器制造的URL爆炸该怎么系统处理,是一套独立的方法论,别和追踪参数混为一谈。
还有一类你控制不了的:Google自己往购物结果链接上挂的srsltid参数,那不是你内链加的,处置思路也和本文不同(重点在canonical一致性和GA4配置,而不是改你自己的内链)。把这几类分清楚,才不会把一个精准的修复做成全站误伤。
千万别把外部活动的utm也一起误删了
这是落地时最容易翻车的一步,必须单独拎出来强调。本文从头到尾针对的是站内链接上的追踪参数——页面A里那个指向页面B的<a>。但utm这套东西当初被发明出来,本来就是给外部入站用的:你发出去的邮件营销里那个链接、投放的Google Ads落地页、社媒贴文里的短链、和联盟伙伴约定的带参链接——这些URL上的utm不仅不该删,删了你才真的两眼一抹黑,因为那是你区分“这波流量到底来自这封邮件还是那条广告”的唯一依据。
规则其实一句话能讲清:utm用来把外部流量带进站,不用来标记站内位置之间的跳转。用户从一封邮件点进来,落地页URL带着utm_source=newsletter,GA4正确地把这次会话归给邮件,这完全没问题;问题只发生在他进站之后——再去点站内导航或推荐位时,那些站内链接不该再叠加新的utm。判断标准也很直白:这个带参链接是“别人会从站外点进来的入口”,还是“用户已经在站内、从一个页面走到另一个页面的通道”?前者必须保留,后者才是要清掉的对象。
落到操作上,做存量清理的正则一定要把作用域死死框在站内链接上——只扫模板里渲染出的内部href、只扫正文里指向本站域名的链接,绝不要写一个全局脚本把数据库里所有utm一把抹平,那会连带把记录在订单来源、用户首次来源字段、归因日志里的历史外部来源数据一起搞坏。动手之前先在脑子里分清楚:你要改的是“站内导航的链接”,不是“流量来源的历史记录”。这两件事一旦混为一谈,修一个不大的SEO问题,换来的会是一个很大的数据事故,得不偿失。
落地之后怎么验证修对了?什么情况下可以不管?
改完不验证等于没改。四个验证动作,对应前面四条伤害线:
- 抓取侧:改完后持续看GSC抓取统计,2到6周内“已抓取-未编入索引”和“包含规范标记的备用网页”这两类的绝对量应该掉下来;服务器日志里爬虫请求中带参数的占比应明显下降。保哥那个骑行客户清完模板脏内链大约两周后,GSC里那条备用网页曲线肉眼可见地往下走,应季新品的平均收录时间也从一周多压回两三天。
- 归因侧:GA4“流量获取”里以自己域名/internal为来源的会话应该大幅减少,自然搜索的会话占比回升到和服务器日志、广告平台口径一致的水平。
- 权重侧:抽样几个被外部引用多的页面,用反链工具看指向它的外链是否开始向规范URL收敛(这个变化最慢,按季度看)。
- 性能侧:CDN缓存命中率上升、源站回源请求下降,核心网页指标里的TTFB有改善空间。
反过来,也得说清楚什么情况下不值得大动干戈,避免你为了一个理论问题过度工程:如果你的站总共就几十到一两百个页面、内链里那点参数对爬虫预算根本构不成压力、且GA4归因偏差小到不影响任何决策,那这件事的优先级可以往后排。这套治理的收益和站点规模强正相关——规模越大、内链模板复用越多、SKU越多,收益越显著;小站把它当作“以后别再往内链加参数”的习惯约束就够了,不必回头大规模重构。判断标准很简单:先做前面那三个诊断动作,参数URL占爬虫请求不到一成、GA4来源分布没明显异常,就先放着,把精力花在更要紧的地方。
最后一句忠告:这件事真正的阻力99%在沟通而不在技术。开发改个模板半天的事,难的是让市场团队相信“放弃URL参数不等于放弃数据”。把本文那张受益方表格和你自己站的诊断数字摆出来——“爬虫多抓了多少影子URL、应季新品晚收录几天、自然搜索功劳被偷走多少”——用他们听得懂的损失说话,比讲一百遍SEO原理都管用。
常见问题解答
内链加utm参数Google会自动忽略吗?
不会。Google早年的URL参数工具已下线,现在它对参数URL是先抓取再判断,参数URL照样消耗抓取预算和爬取深度。它不会替你“自动忽略”,只会在抓完后靠canonical决定要不要单独收录。
给所有参数URL加自指canonical能解决问题吗?
只能缓解索引膨胀,解决不了根本问题。canonical作用在收录阶段,参数URL在更早的发现和抓取阶段已经把预算花掉了。canonical是损害控制,不是修复,真正的修法是源头上内链不带参数。
不在URL里放utm,市场团队怎么知道哪个位置带来的点击?
把位置信息改挂在链接的data属性上(如data-track-location),用一个全局点击监听读出来推给GTM或分析工具。市场要的位置点击数据一个不少,且记的是站内交互而非伪造的流量来源,数据反而更准。
No-Vary-Search响应头能不能替代去参数?
不能替代,只能补充。它解决的是浏览器缓存碎片,让带指定参数的URL复用同一缓存条目;但搜索引擎该抓的参数URL还是会抓,归因污染也不归它管。它是缓存层的优化,不是内链参数问题的解药。
能不能直接在robots.txt里Disallow掉带utm的路径?
不推荐。被Disallow的URL如果有链接指向,仍可能以无标题形式被索引;而且爬虫读不到这些页面的canonical,反而切断了权重回收路径。robots.txt只在“纯外部来源且确定不需进索引”的窄场景成立,治不了内链参数。
这个问题对小网站也严重吗?
不一定。收益和站点规模强正相关。几十到一两百页、内链参数对抓取预算构不成压力、GA4归因偏差不影响决策的小站,把它当作“以后别再往内链加参数”的习惯即可,不必回头大规模重构。先做诊断再决定优先级。
筛选器URL(如?color=red这种)也要按这套去掉吗?
不能照搬。筛选参数真实改变了页面呈现的内容,属于另一套治理逻辑,要按每个筛选组合有没有搜索需求和抓取价值来分类,不能像追踪参数那样无差别清除,否则会误伤有价值的分面页面。
权威参考资料
本文标题:《给内链加UTM参数为什么伤SEO?流量分析与抓取的取舍》
本文链接:https://zhangwenbao.com/tracking-parameters-internal-links-seo-damage.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0