分面导航的SEO怎么治理?筛选过滤产生的海量URL别拖垮抓取预算
本文目录
- 先把话说清楚:分面导航到底是什么
- 一组筛选能生出多少URL?先算笔账
- 这些URL为什么是SEO黑洞:四笔账
- URL长什么样,决定了治理难度
- 第一步不是技术,是搜索需求
- 动手前先盘一次家底:你的筛选到底生成了什么
- 治理工具箱之一:canonical能干嘛,不能干嘛
- 治理工具箱之二:noindex挡得住索引,挡不住抓取
- 治理工具箱之三:robots.txt是省抓取的核武器,但有两个坑
- 治理工具箱之四:nofollow与AJAX,从源头不生URL
- 别再找URL参数工具了,它退役了
- 给你一棵决策树
- 排序、分页、价格区间这类,基本永远别索引
- 把有需求的facet静态化成着陆页
- 平台落地:Shopify、WooCommerce、Magento分头说
- 怎么验证治理生效
- AI搜索时代:宝贝更值钱,噪声更要清
- 一个出海独立站的真实复盘
- 五个常见误区
- 常见问题解答
- 分面导航和分类导航到底有什么区别?
- 分面导航生成的URL,到底是该用robots.txt还是noindex?
- 用canonical把所有筛选页指回主分类页,是不是就万事大吉了?
- 哪些筛选组合值得单独做成可索引的着陆页?
- Google Search Console的URL参数工具去哪了?
- 都AI搜索时代了,分面导航治理还有必要吗?
- 权威参考资料
摘要:分面导航是电商独立站最实用的功能之一,让用户在分类页上叠加颜色、尺寸、价格、品牌等筛选条件快速找货。但同一套筛选器在URL层面能生出成千上万、甚至上百万个近重复地址,这些地址会悄悄吃光抓取预算、撑爆索引、把内链权重稀释到一堆没人搜的组合页上。治理的核心不是一上来就堵,而是先用搜索需求把筛选分成值得索引和纯属噪声两堆,再针对性地用canonical、noindex、robots.txt和AJAX各管一段。这篇把分面导航为什么是SEO黑洞、每件治理工具到底能干嘛不能干嘛、一棵可以照着走的决策树,连同平台落地和验证方法一次讲透。
先把话说清楚:分面导航到底是什么
很多人把分面导航(faceted navigation)和普通的分类导航混为一谈,其实差得挺远。分类导航是单一维度的层级,比如“男装 → 上衣 → T恤”,一条路走到底;分面导航是多维度的叠加筛选,用户进了“跑鞋”分类页之后,还能同时勾选“红色 + 42码 + 300元以下 + Nike品牌”,每勾一个条件,列表就实时收窄一次。
按维基百科对分面搜索(faceted search)的定义,它的本质是把每个信息元素沿着多个互相独立的维度(也就是facet)分类,让用户能从任意维度的任意组合去访问内容,而不是被困在一条预先定好的单一目录顺序里。对用户体验来说这是好事,找货效率高;可一旦这些筛选状态被写进URL,麻烦就来了。
说人话:分面导航是给用户用的放大镜,问题是这台放大镜每照一个角度,都顺手在你网站上多生了一个网页地址。用户只看到一个收窄后的列表,搜索引擎看到的却是一个不断膨胀的URL宇宙。
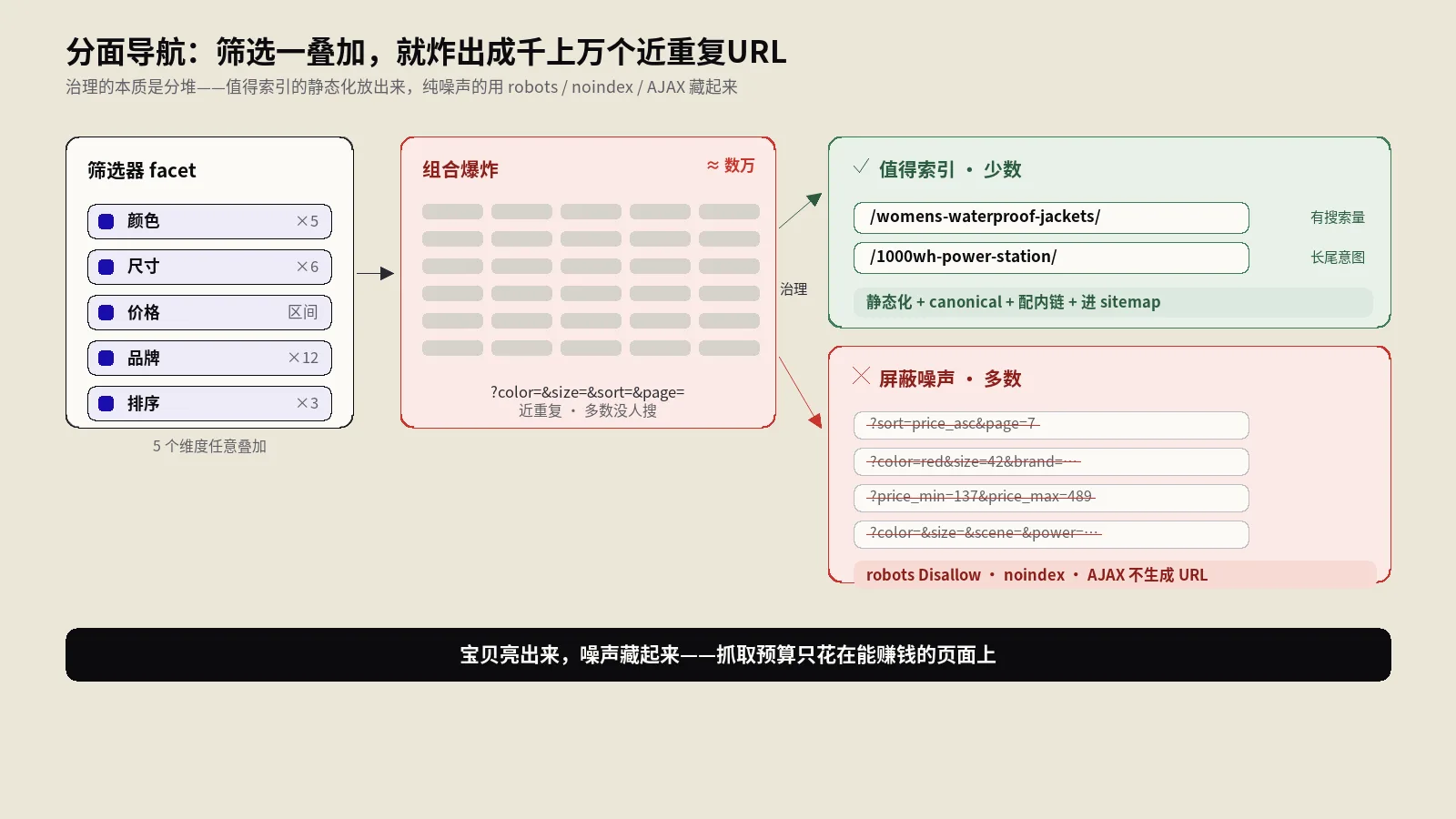
一组筛选能生出多少URL?先算笔账
组合数学在这里是会咬人的。假设一个分类页挂了5个筛选维度,每个维度平均5个可选值,光是“选或不选 + 选哪个”的组合,理论上就能逼近几千个变体;维度再多一点、值再丰富一点,配合排序方式(按价格、按销量、按上新)和分页(第1页、第2页……),URL总量轻松冲到几万、几十万。
Ahrefs在分面导航的SEO指南里把这件事说得很直白:分面导航会制造出“近乎无限数量的筛选组合和可索引URL”。这不是夸张修辞,而是大型目录站的日常——一个三五万SKU的独立站,分面导航生成的URL比真实产品页多出一两个数量级,是很常见的事。
更阴险的是,这些地址里绝大多数是近重复内容:红色42码的跑鞋页和红色41码的跑鞋页,正文骨架、模板、推荐位几乎一模一样,只有列表里的几个商品略有出入。搜索引擎得真的去抓一遍才知道“哦,又是一个差不多的”。这一抓,就是真金白银的成本。
这些URL为什么是SEO黑洞:四笔账
分面导航失控,损失不是单一的,而是四笔账一起亏:
- 抓取预算被吞:Googlebot把时间花在抓成千上万个近重复的筛选页上,留给新品页、博客文章的抓取份额就少了,新内容收录变慢。Oncrawl在规模化治理分面导航的文章里打的比方很到位:如果Googlebot忙着抓你男鞋分类那上千个几乎一样的版本,它就可能错过你刚上架的新品。
- 重复与近重复内容:海量相似页面摊薄了主分类页的排名信号,本该集中在一个权威页上的权重,被分散到一堆变体上。
- 索引膨胀(index bloat):低质筛选页被收录后,整站在Google眼里的“平均内容质量”被拉低,这对站点级的质量评估不是好事。
- 内链权益稀释:每个筛选链接都是一条内链,它们把PageRank一层层导向没有搜索价值的组合页,真正该被喂权重的产品页和主分类页反而饿着。这一点和关键词蚕食的处置逻辑是同源的——内部互相抢食,谁也排不上去。
把这四笔账叠起来,你就明白为什么技术SEO老手看到一个没治理的分面导航会眉头一皱:它不是某一处的小毛病,而是从抓取、索引到权重分配的整条链路都在漏。Search Engine Land在分面导航SEO最佳实践指南里也把这些问题归成一类系统性风险——孤立地补某一处,往往按下葫芦浮起瓢,得当成一套组合拳来打。
URL长什么样,决定了治理难度
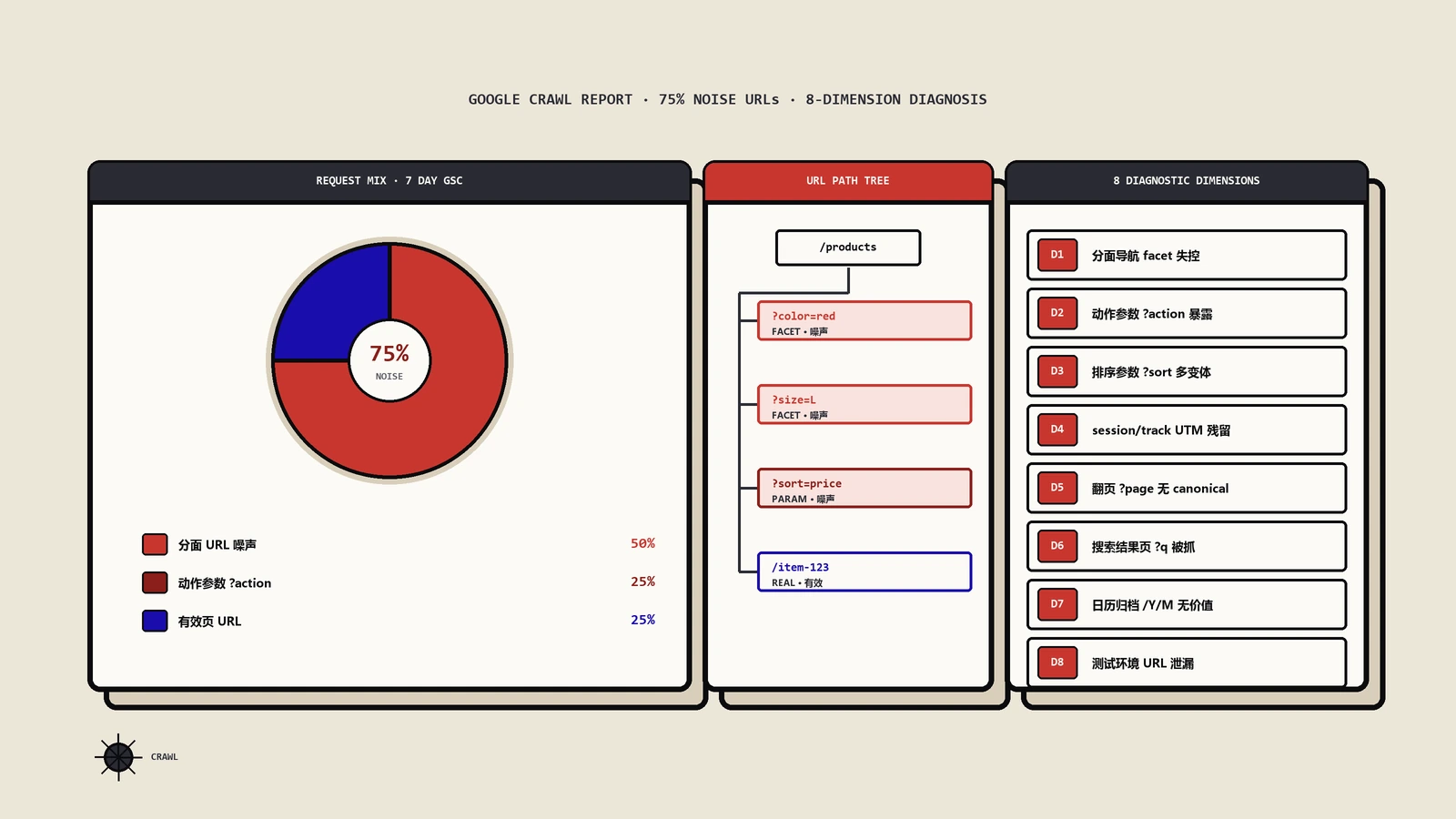
分面状态写进URL,主要有三种形态,治理手法各不相同:
| 形态 | 例子 | 抓取行为 | 治理要点 |
|---|---|---|---|
| 查询参数 | /shoes?color=red&size=42 | 会被抓取和索引 | 主流形态,靠robots/canonical/参数规范治理 |
| 路径静态化 | /shoes/red/42/ | 会被抓取和索引 | 看着干净,但组合一多更难控,需严格白名单 |
| URL片段 | /shoes#color=red | 井号后内容不参与抓取 | 天然不产生新可抓URL,但对可索引着陆页不友好 |
这里有个常被忽略的细节:Google官方在管理分面导航URL抓取的文档里明确说,搜索引擎一般不抓取URL里井号(#)后面的内容,所以如果你的筛选机制是基于片段实现的,它对抓取既没有正面也没有负面影响。Oncrawl也确认了同一点:Googlebot会忽略 # 之后的一切。换句话说,片段式筛选是“对搜索引擎隐身”的——好处是不污染抓取,坏处是这些组合永远成不了能带流量的着陆页。
另外,Google还提醒:URL参数请老老实实用行业标准的 & 做分隔符,别用逗号、分号或方括号,那些字符爬虫很难识别成参数边界,容易把URL解析乱。这种地基级的规范,比你后面堆多少canonical都重要。
第一步不是技术,是搜索需求
治理分面导航,最容易犯的错是上来就一刀切——要么全堵,把有价值的着陆页也误伤了;要么全放,让垃圾组合泛滥。正确的起手式是先问一个问题:这个筛选组合,有人真的在搜吗?
判断标准很朴素:
- “红色连衣裙”“防水登山鞋”“1000瓦便携储能电源”这类有明确搜索量的组合,是宝贝,应该被索引,甚至单独做成优化过的着陆页去抢长尾流量。
- “红色 + 42码 + 周二上新 + 按价格倒序 + 第7页”这种没人会搜的多重叠加,是噪声,应该被挡在索引之外。
怎么验证有没有需求?用关键词工具拉一遍筛选维度的组合词,看搜索量;再翻Google Search Console的效果报告,看哪些筛选页已经在拿展示和点击。有数据支撑的留下、放大,没数据的果断屏蔽。这一步做对了,后面的技术动作才有的放矢,否则就是凭感觉乱堵。
保哥给出海客户做技术SEO诊断时,几乎每次都要先拉这张“筛选组合vs搜索需求”的对照表,因为它直接决定了哪些URL该进白名单、哪些该进黑名单,是整个治理方案的地基。
动手前先盘一次家底:你的筛选到底生成了什么
按搜索需求分堆的前提,是你得先知道自己到底有多少堆。现实里太多站连自家筛选生成了几种参数、铺出多少个URL都没数过,就照搬别人的robots规则,结果要么没堵住、要么误伤了有价值的页。动手治理前,花半天做一次家底盘点,能省掉后面一大堆返工。
盘点分三步走:
- 第一步,爬一遍全站。用Screaming Frog、Sitebulb这类爬虫工具按URL参数分组,看每个参数(color、size、sort、page等)各生成了多少地址、抓取深度有多深。这一步能直观揪出哪个维度是URL膨胀的元凶——往往就是那一两个被忽视的筛选项在疯狂造页。
- 第二步,翻服务器日志。统计Googlebot实际在抓哪些参数URL、频率多高。爬虫工具告诉你“理论上铺了多少”,日志告诉你“Google实际在浪费多少”,两者一对照,轻重缓急立刻清晰。
- 第三步,列一张facet清单。把每个筛选维度、它的取值数量、有没有搜索需求、当前URL形态、当前是否被索引,逐行填进一张表。这张表就是你后面决定下canonical、noindex还是Disallow的作业本。
没有这张家底表,治理就是盲人摸象,改完也说不清动了什么;有了它,每个动作都有据可依、可回溯。这半天投入,是分面治理里性价比最高的一步,别省。
治理工具箱之一:canonical能干嘛,不能干嘛
rel=“canonical” 是最常被误用的工具。它的作用是告诉搜索引擎“这些近重复页面里,请把权重和排名归到我指定的那个主页面上”。对于排序变体、轻微的参数差异,让筛选页canonical指回干净的主分类页,确实能把重复内容的权重收拢回去。
但请记住它的天花板:canonical是一个提示而非指令,而且它根本不省抓取预算。搜索引擎要先抓到这个页面、读到canonical标签,才知道“哦这是个副本”——抓取的成本一分没省。所以canonical适合解决“权重稀释”,对解决“抓取浪费”几乎无能为力。把这两个问题混为一谈,是分面治理翻车的头号原因。
治理工具箱之二:noindex挡得住索引,挡不住抓取
noindex这个meta标签(或HTTP头)告诉搜索引擎“别把这个页面收进索引”。它比canonical更强硬,能把已经被收录的低质筛选页慢慢挤出索引。
可它和canonical共享同一个软肋。Botify在分面导航最佳实践里一句话点破:noindex标签发出的信号是不要索引这个页面,但它不阻止爬虫抓取这个页面,所以它解决不了抓取预算浪费的问题。爬虫还得先抓进来,才能读到那句“别索引我”。
所以noindex的正确定位是:当某些筛选页确实需要被爬虫发现并传递一点内链信号、但你不想让它出现在搜索结果里时,用noindex,follow。如果你的核心痛点是抓取预算被吃光,光靠noindex是治标不治本的。
治理工具箱之三:robots.txt是省抓取的核武器,但有两个坑
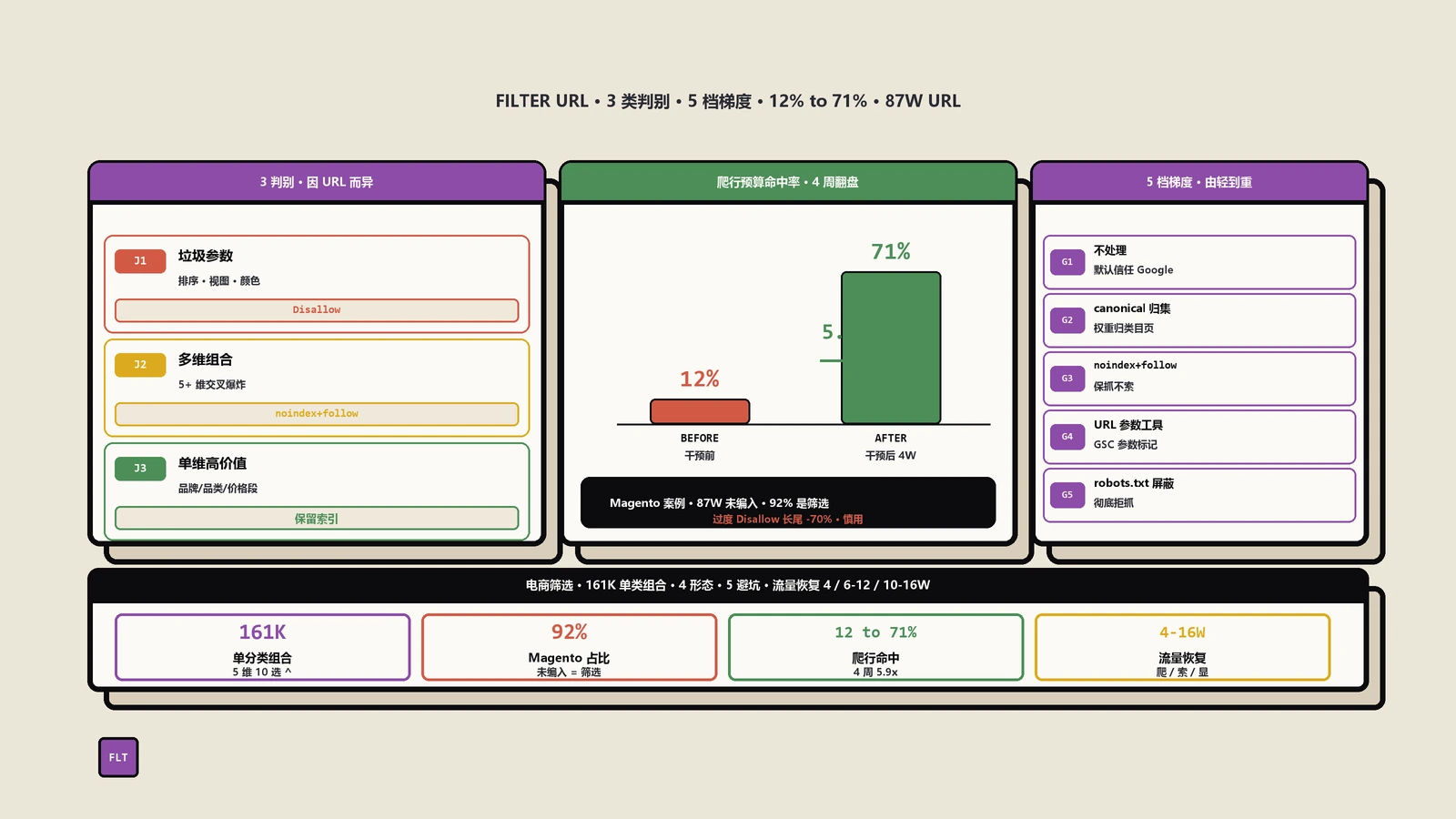
真正能从源头省下抓取预算的,是robots.txt的Disallow。Google官方文档直接建议:通常没有理由允许抓取这些筛选后的页面,因为那只会消耗服务器资源、换不来什么收益,所以可以用robots.txt把分面URL的抓取禁掉。Ahrefs给的写法也很具体,比如用 Disallow: /*size=* 一条规则就能把所有带size参数的URL拦在抓取门外。
但robots.txt有两个坑,踩中了比不治理还糟:
- 坑一:Disallow不会让已经索引的页面掉出去。robots只是禁止抓取,不是禁止索引。一个已经被收录的URL被你Disallow之后,Google抓不进去了,反而读不到你后加的noindex,结果它可能继续挂在索引里(有时显示为“已编入索引,但被robots.txt屏蔽”)。正确顺序是:要清的页面先放noindex让它掉出索引,等掉干净了,再用robots Disallow省抓取。
- 坑二:robots会切断链接权益。Botify提醒,robots.txt彻底挡住爬虫的同时,也意味着这些页面如果有外链,那份链接权益传不进来了。所以只对“零搜索需求、确实在浪费抓取”的facet下重手,别误伤可能有外链的页面。
治理工具箱之四:nofollow与AJAX,从源头不生URL
前面三件工具都是“URL已经生出来了再补救”,更高明的做法是从一开始就不生成可抓取的URL。
第一种是给筛选链接加rel=“nofollow”,少给这些链接传递抓取信号。不过nofollow如今只是个提示,效果被Google弱化了不少,单靠它不保险。
第二种才是Ahrefs推崇的理想方案:用AJAX实现筛选,筛选动作不带 <a href> 链接,列表在前端动态刷新,URL压根不变。这样Google连可抓的地址都发现不了,自然谈不上浪费抓取。代价是这些筛选状态没法被单独收录——所以它要和下面这招搭配:对那些有长尾搜索价值的高价值筛选,单独建静态可索引的分类页,配好内链,让它们正常参与排名。一句话,噪声用AJAX藏起来,宝贝用静态页亮出来。
别再找URL参数工具了,它退役了
有些老教程会教你去Google Search Console的“URL参数”工具里配置参数行为。打住——这个工具早在2022年3月就被Google正式退役了。官方给的理由是:这些年Google自己猜参数用途的能力大幅提升,工具里只有约1%的配置还真正派得上用场,价值太低,索性下线。
这意味着今天治理参数,得靠站点自己的结构化信号说话:规范的参数分隔符、清晰可被算法识别的URL模式、canonical、robots.txt、以及前面说的AJAX。指望在控制台里点几下让Google听话的时代,已经过去了。照着过时教程白忙活一通,是很多人没意识到的隐性坑。
给你一棵决策树
把上面的工具串成一套可执行的判断流程,每遇到一类facet,照着问下去:
| 这类facet的情况 | 处置动作 |
|---|---|
| 有明确搜索需求(如“防水跑鞋”) | 静态化成独立着陆页 + 可索引 + 配内链 + 优化TDK |
| 近重复、无搜索需求,但可能有外链 | canonical指回主分类页(保住权重) |
| 零搜索需求、确认在浪费抓取、无外链 | 先noindex清出索引,再robots Disallow省抓取 |
| 排序方式、每页数量等纯展示参数 | canonical指回默认视图,或直接AJAX不入URL |
| 多重叠加的长尾组合(3个以上facet叠加) | AJAX实现,不生成可抓URL |
Botify把这套逻辑归纳成两条主线,很值得记:如果你的主要问题是抓取预算被撑爆,就侧重robots.txt、nofollow和参数处理这类“堵”的手段;如果主要问题是链接权益被稀释,就从canonical和noindex入手,robots.txt只留给那些被证实纯浪费抓取、且零搜索需求的facet。先诊断你到底亏在哪笔账上,再决定下哪味药。
排序、分页、价格区间这类,基本永远别索引
有几类参数几乎不存在被索引的理由,可以直接划进黑名单:
- 排序参数(sort=price_asc、sort=newest):同一批商品换个顺序,内容完全重复,没有任何独立搜索价值。
- 分页之外的展示参数(每页显示24件还是48件、网格还是列表视图):纯交互偏好,不该产生独立索引页。
- 开放式价格区间(price_min=137&price_max=489):用户随手拖出来的任意区间能生成无穷无尽的组合,是抓取黑洞的重灾区。
- 会话ID、追踪参数(sid=、utm_):跟内容无关,必须规范掉。
对这些,最干脆的做法是在前端就用AJAX或POST处理掉、不写进URL;退一步也要canonical指回干净版本。分页本身要不要索引是另一个话题,处理逻辑和分类页分页SEO的几种方案各有取舍,这里不展开。
把有需求的facet静态化成着陆页
治理不全是做减法。分面导航真正的SEO红利,在于把有搜索需求的筛选组合升级成正经的着陆页。比如“女士防水冲锋衣”这个组合明明有不小的搜索量,那就别让它停留在一个动态参数URL上自生自灭,而是:
- 给它一个干净、静态、语义清晰的URL(如
/womens-waterproof-jackets/); - 写一段独有的分类描述,别只甩个商品列表,加上选购要点、材质科普,制造信息增益;
- 在主分类页、相关产品页用描述性锚文本主动链向它,把内链权重喂过去;
- 让它进sitemap,确保被发现。
这样一来,原本会变成噪声的筛选组合,反过来成了捕获长尾的资产。选哪些组合值得这么做,回到前面那张“组合vs搜索需求”的对照表——有量的才上,没量的别硬造,否则又造出一批薄页面,得不偿失。这套“哪些深做、哪些收口”的取舍,本质上和独立站网站架构里抓取深度的权衡是一脉相承的。
平台落地:Shopify、WooCommerce、Magento分头说
原理通用,落地要看平台脾气:
- Shopify:集合页(collection)的标签筛选默认会生成
?constraint=之类的参数URL。新版主题多用AJAX刷新,但仍要检查标签链接是否产生可抓地址;有价值的组合建议用单独的智能集合(automated collection)做成静态集合页,这和Shopify集合页要主动优化去抢AI购物推荐的思路一致。 - WooCommerce:默认的属性筛选靠
?filter_color=这类查询参数实现,量一大就容易失控,通常要配合robots.txt规则 + canonical,并谨慎决定哪些属性归档页放开索引。 - Magento:分层导航(Layered Navigation)是分面治理的硬骨头,涉及EAV属性、URL Rewrite和参数白名单,水很深。这块保哥单独写过Magento分层导航治理的完整方案,要做Magento的可以直接对着抄。
不管哪个平台,第一件事都是先搞清楚“我这套筛选到底生成了什么样的URL”,再谈治理。很多人连自家筛选产生几种参数都没数过,就开始照搬别人的robots规则,结果要么没堵住、要么堵错了。
怎么验证治理生效
方案上线不等于生效,得有监测闭环:
- GSC收录覆盖报告:看“已抓取 - 尚未编入索引”“已编入索引,但被robots.txt屏蔽”这些状态的URL数量是涨是跌,定位治理有没有按预期走。
- 服务器日志:这是最实诚的证据。直接看Googlebot还在不在大量抓那些本该被Disallow的参数URL——日志不会骗人,它告诉你抓取预算到底花在了哪。配合抓取预算优化的整体打法一起看,效果更清楚。
- site: 抽查:用
site:yourdomain.com inurl:sort=这类指令粗略估一估垃圾参数页还在不在索引里,作为快速体检(注意site: 是估算值,别当精确数)。
治理是个持续过程,不是一锤子买卖。新增了筛选维度、改了主题、上了新功能,都可能让URL宇宙重新膨胀,得定期回头复查。
AI搜索时代:宝贝更值钱,噪声更要清
有人问,都AI搜索了,还纠结这些参数URL干嘛?恰恰相反,AI时代两头都被放大了。
一头是,AI搜索的查询扇出机制会把一个购物意图拆成更细的子查询去检索,有需求、结构清晰的分面着陆页更容易被命中和引用——一个优化好的“500瓦便携储能电源”集合页,在AI购物推荐里的露脸机会,比埋在参数堆里的同款组合高得多。
另一头是,AI爬虫和传统爬虫一样有抓取上限,你那几十万个垃圾筛选页只会让它更快地耗尽耐心、更难抓到你真正想被引用的核心页。所以分面治理在AI时代不是过时了,而是更要紧了:把宝贝亮出来、把噪声藏起来,这条原则在GEO语境下同样成立。换个角度看,一个结构干净、该索引的索引、该屏蔽的屏蔽的站,本身就是在向AI表明“这家的内容值得信任、值得抓”,这种信号在AI决定引用谁时,分量只会越来越重。
一个出海独立站的真实复盘
说个保哥手边的切片。一家做户外储能的出海独立站,产品线不算特别大,三千多个SKU,但分类页挂了容量、功率、电池类型、适用场景、价格五个筛选维度,全用查询参数实现,且每个筛选链接都是带href的普通链接。
问题表现是新品收录奇慢——上架两周还没被收录,而抓取日志里Googlebot每天大把时间在抓 ?capacity=*&power=*&scene=* 这类三四重叠加的组合页,GSC里“已抓取 - 尚未编入索引”的数字一路飙到六位数。这就是典型的抓取预算被分面URL吃光。
治理动作分三步:先拉关键词数据,确认只有容量和场景两个单维度筛选(如“1000Wh储能电源”“房车储能电源”)有真实搜索量,把这十几个组合静态化成可索引着陆页、配上内链;其余多重叠加组合一律改AJAX加robots Disallow,已收录的先挂noindex清出去;排序和价格区间参数全部canonical指回默认视图。两个多月后,新品平均收录时间从两周压到三天内,那十几个着陆页里有几个开始稳定吃长尾流量。账算下来,省下的抓取预算全回流到了真正能赚钱的页面上。
这个案例的关键不在用了多高深的技术,而在先用搜索需求把筛选分成两堆,再分别下手——这正是前面反复强调的那一步。很多人一上来就纠结该用canonical还是robots,工具选型反倒成了次要矛盾,真正决定成败的是前面那张家底表和需求判断有没有做扎实。
五个常见误区
- 误区一:canonical能省抓取预算。不能。canonical只收拢权重,爬虫照抓不误。省抓取得靠robots.txt或干脆不生成URL。
- 误区二:robots Disallow能让已索引的垃圾页掉出去。不能。Disallow后Google反而读不到noindex,页面可能继续挂在索引里。要先noindex清干净,再Disallow。
- 误区三:GSC的URL参数工具还能用。它2022年就退役了,别再到处找它。
- 误区四:所有筛选页都该被索引,多多益善。恰恰相反,绝大多数筛选组合是噪声,索引得越多越拖累整站质量评估。该索引的是少数有搜索需求的精华。
- 误区五:用nofollow给筛选链接做权重雕刻就够了。nofollow如今只是提示,靠它单打独斗既挡不住抓取也清不掉索引,必须和canonical、noindex、robots组合使用。
常见问题解答
分面导航和分类导航到底有什么区别?
分类导航是单一维度的层级路径,比如“男装 → T恤”,一条路走到底;分面导航是多维度叠加筛选,用户能在分类页上同时勾选颜色、尺寸、价格、品牌等多个条件。前者结构稳定、URL可控,后者每多一个筛选维度,URL组合就指数级膨胀,治理难度天差地别。
分面导航生成的URL,到底是该用robots.txt还是noindex?
看你的主要痛点。如果是抓取预算被吃光,robots.txt Disallow才省抓取;如果只是想让低质页不出现在搜索结果、又想保留一点内链信号,用noindex。两者的关键顺序是:要清掉已收录的页面,先用noindex让它掉出索引,等掉干净了再robots Disallow省抓取,反过来做会让页面卡在索引里出不来。
用canonical把所有筛选页指回主分类页,是不是就万事大吉了?
不是。canonical能把重复内容的权重收拢回主页面,解决“权重稀释”,但它根本不省抓取预算——爬虫得先抓到页面才能读到canonical。如果你的站很大、抓取预算紧张,光靠canonical解决不了根本问题,还得叠加robots.txt或AJAX从源头控量。
哪些筛选组合值得单独做成可索引的着陆页?
有明确搜索需求的组合,比如“女士防水冲锋衣”“1000Wh储能电源”这类有搜索量的词。判断方法是用关键词工具拉组合词看搜索量,再翻GSC效果报告看哪些筛选页已经在拿展示点击。有量的静态化、配内链、优化描述去抢长尾;没量的多重叠加组合直接屏蔽,别硬造薄页面。
Google Search Console的URL参数工具去哪了?
2022年3月被Google正式退役了。官方说这些年自己识别参数用途的能力大幅提升,工具里只有约1%的配置还有用,价值太低就下线了。今天治理参数得靠站点自身的结构化信号:规范的 & 分隔符、清晰的URL模式、canonical、robots.txt和AJAX,没有控制台里点几下就让Google听话的捷径了。
都AI搜索时代了,分面导航治理还有必要吗?
更有必要。一方面,AI搜索的查询扇出会把购物意图拆得更细,有需求、结构清晰的分面着陆页更容易被命中和引用;另一方面,AI爬虫同样有抓取上限,满站垃圾筛选页只会让它更快耗尽耐心、抓不到你真正想被引用的核心页。把宝贝亮出来、把噪声藏起来,这条原则在AI时代只会更重要。
权威参考资料
本文标题:《分面导航的SEO怎么治理?筛选过滤产生的海量URL别拖垮抓取预算》
本文链接:https://zhangwenbao.com/faceted-navigation-seo-crawl-budget-index-control.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0