Googlebot不读preload?5招实战指南
本文目录
- 资源提示是什么:4 种 Hint 详解
- 爬虫与浏览器的"两个世界"
- 元数据位置与 HTML 有效性:看似小事,实则致命
- 其他 AI 爬虫怎么对待资源提示
- 5 个真正有效的替代优化策略
- 用户体验优先,间接反哺 SEO
- 服务器端与爬虫预算优化
- 监控与诊断闭环
- SSR/SSG 而非纯 CSR
- 结构化数据与语义 HTML
- 2026 年新趋势加持
- SEO 站长的常见误区清单
- 结语:SEO 回归本质——以用户为中心
- TTFB / 抓取性能的工程级优化
- 与 Bing/DuckDuckGo 等其他搜索引擎的差异
- 对 PWA / Service Worker 的特别说明
- 国内云加速的"智能优化"正在偷偷改写你的 head
- 在国内验证 Googlebot 到底看到了什么,比你想的难
- 常见问题解答
- 权威参考资料
摘要:Googlebot为什么忽略preload、prefetch这些资源提示?根因是爬虫跑在Google数据中心,网络环境和用户设备上的浏览器是两个世界。本文讲清head元数据位置与HTML有效性这看似小事实则致命的陷阱、其他AI爬虫怎么对待资源提示,再给五条真正有效的替代优化和TTFB与抓取性能的工程级优化。
在日常 SEO 工作中,很多站长和开发者会在 HTML 头部精心添加 <link rel="preload">、<link rel="prefetch">、<link rel="preconnect"> 或 dns-prefetch 等资源提示标签,希望借此"讨好"Googlebot,让爬虫更快抓取关键 JS、CSS、字体或图片资源。但根据谷歌搜索团队资深工程师 Gary Illyes 和 Martin Splitt 在最新《Search Off the Record》播客中的明确表态,这些提示对 Googlebot 几乎完全无效。这不是 bug,而是爬虫与浏览器本质差异导致的必然结果。
本文按 Google 官方原话 + 实战拆解的方式,把这件事讲透:资源提示到底干什么的、Googlebot 为何不需要、Head 元数据位置陷阱、HTML 有效性是不是排名信号、5 个真正有效的替代优化方案、JS 框架 SSR/SSG 的实操要点、与 AI 爬虫的关系,最后附 FAQ。
资源提示是什么:4 种 Hint 详解
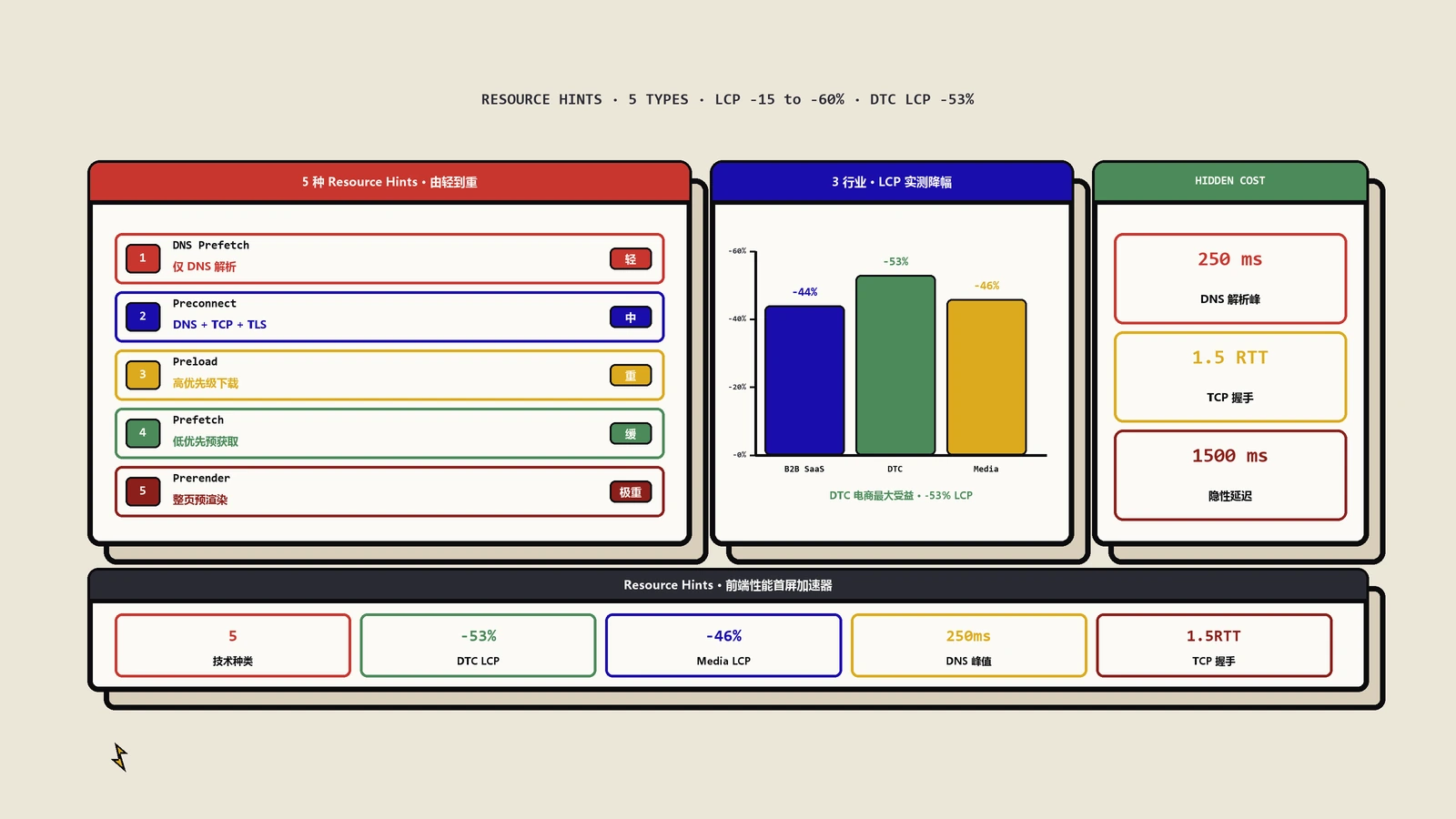
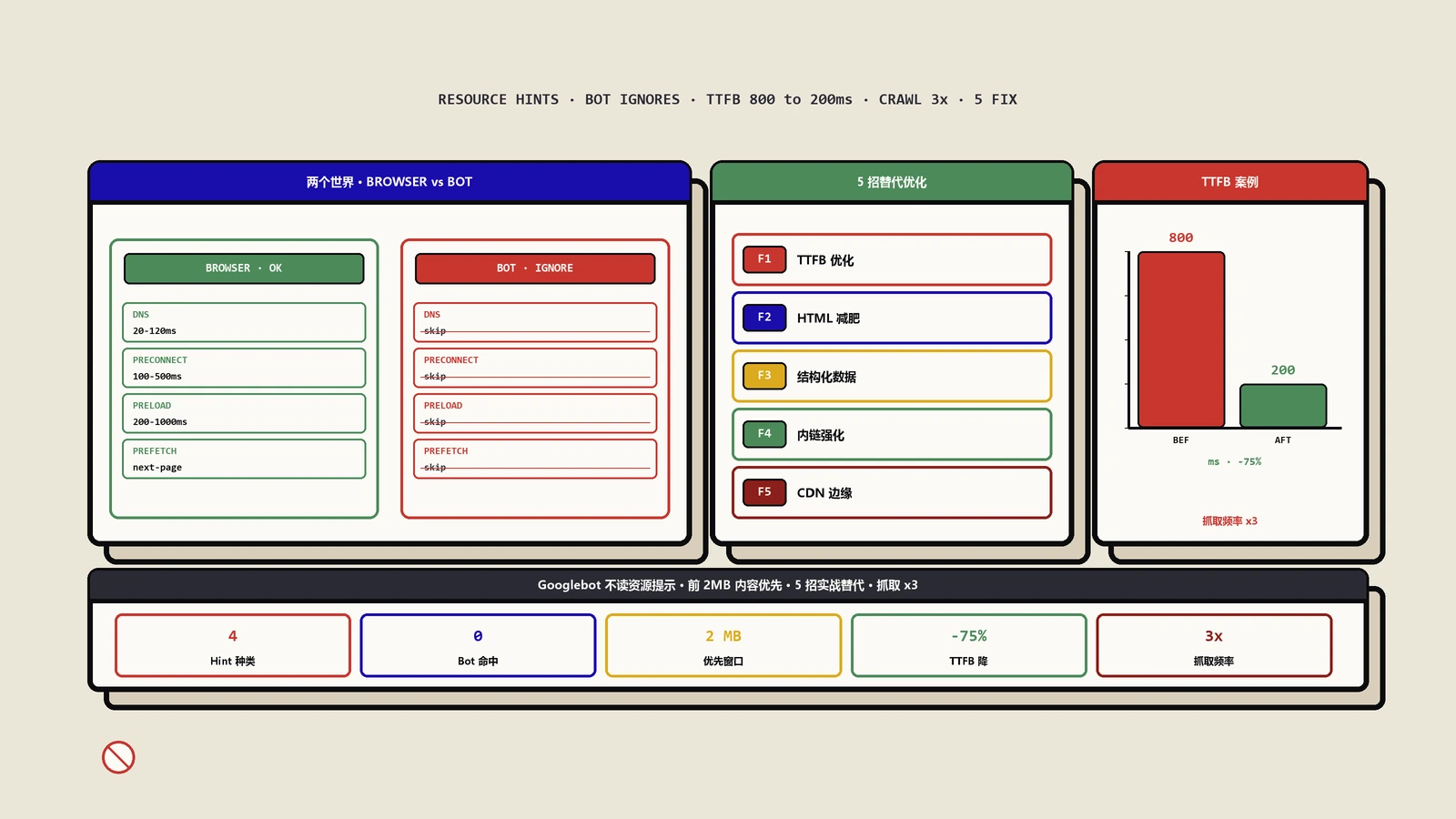
HTML 规范里的资源提示(Resource Hints)一共有 4 种,每种解决的问题不同:
<link rel="dns-prefetch" href="https://example.com">:提前做 DNS 解析。比如页面上引用了 fonts.googleapis.com 的字体,浏览器看到 dns-prefetch 后会提前把这个域名解析成 IP,等到真正请求字体时省掉 DNS 查询时间(通常 20-120ms)。<link rel="preconnect" href="https://example.com">:比 dns-prefetch 更进一步——除了 DNS 解析,还预先建立 TCP 连接和 TLS 握手。一次 preconnect 能省下 100-500ms。<link rel="preload" href="hero.jpg" as="image">:告诉浏览器"我马上要用这个资源,请提前下载"。常用于首屏关键资源(LCP 图片、关键 CSS、关键字体),可以让 LCP 提前 200-1000ms。<link rel="prefetch" href="next-page.html">:告诉浏览器"用户可能下一步会去这个页面,空闲时帮我下载"。常用于多步流程的下一步资源预取。
这 4 种提示在浏览器里都很有用,能直接影响 Core Web Vitals 评分。但放给 Googlebot 看几乎完全没用——这是本文的核心结论。
爬虫与浏览器的"两个世界"
普通浏览器运行在用户设备上,面对的是不稳定的移动网络、跨域延迟、DNS 解析瓶颈等问题,资源提示正是为了提前预加载、预连接,从而缩短白屏时间、提升 Core Web Vitals 得分。而 Googlebot 完全不同——它部署在谷歌全球数据中心集群,内部网络带宽极高、DNS 解析链路极短,几乎不存在"延迟"这一痛点。
谷歌专家举例:普通用户可能需要 dns-prefetch 来加速第三方域名解析,但 Googlebot"跟所有级联 DNS 服务器对话都非常快",根本不需要提示。另外,Googlebot 不会像浏览器那样同步实时抓取所有资源,而是采用异步、独立缓存机制,大幅降低服务器压力和带宽消耗。这意味着你辛苦加的 preload 指令,爬虫很可能直接跳过,只按自身爬取预算和优先级行事。
这背后还有一个工程权衡:Googlebot 每天要抓取数百亿个页面,如果对每个 preload/prefetch 提示都"听话执行",会引发巨大的额外资源消耗。Google 选择的策略是统一忽略提示,按自有算法决定抓取哪些资源——这种设计的好处是规模可控、行为可预期,劣势是对站长的"友好提示"显得无动于衷。
这里有个容易混的点:SEO 不能把"取悦爬虫"和"服务用户"当成一回事。资源提示是典型的"用户端优化",不是爬虫指令。盲目堆砌反而会让代码更臃肿,间接拖累渲染性能。
元数据位置与 HTML 有效性:看似小事,实则致命
播客中另一重点是:<meta name="robots">、<link rel="canonical">、hreflang 等关键元数据必须严格放在 <head> 标签内。一旦页面脚本(如动态注入 iframe)导致浏览器提前关闭 <head>,这些标签就会"流落到" <body> 中,Googlebot 将直接忽略,造成索引异常、重复内容或国际化失效等问题。
谷歌工程师甚至警告:如果接受 body 中的 canonical,恶意注入代码就能轻易把页面从搜索结果中"踢出去",安全风险极高。所以这条规则没有妥协余地——必须把元数据严格控制在 head 里。
容易触发"head 提前关闭"的场景:
- 第三方分析脚本(GA、百度统计)在 head 里
document.write()。 - head 内嵌入了
<iframe>或者<img>等 body 才能有的元素。 - HTML 模板里
</head>标签前有未闭合的<script>。 - 使用某些 CMS 主题时,插件会在 head 里塞 noscript 内容(违反 HTML5 解析规则)。
- head 里使用了被弃用的元素(如老式的
<font>、<center>配置)。
同时,HTML 有效性(W3C 验证通过)也不是排名信号——有效性是二元判断(valid/invalid),没有"接近有效"的中间分值,缺失一个 </span> 并不会影响用户体验,因此谷歌不会以此作为算法依据。但缺失闭合标签可能导致 head 提前关闭——这是间接风险。
再补一个 2026 年的现实:Googlebot 的渲染能力已经更强(连复杂的 JS hydration 都能跑),但动态框架(Next.js、Nuxt 等)站点反而更要盯紧服务器端渲染(SSR)或静态生成(SSG),让关键元数据在首字节就输出。否则页面在浏览器里正常显示,爬虫看到的"源代码"照样可能缺关键指令。
其他 AI 爬虫怎么对待资源提示
既然 Googlebot 不读资源提示,其他 AI 爬虫呢?保哥实测了几家:
- GPTBot(OpenAI):完全忽略 preload/prefetch/preconnect。它的爬取策略类似 Googlebot 的简化版,只抓 HTML 主文档 + 少量关联资源(图片、视频缩略图)。
- ClaudeBot(Anthropic):同样忽略资源提示。Anthropic 的爬虫策略偏保守,只取必要的内容资源。
- PerplexityBot:实时类爬虫,处理用户实时查询时会跟随部分资源(特别是图片用于视觉回答),但不会因为 preload 提前加载。
- Bingbot:跟 Googlebot 类似,忽略大多数资源提示。
- Common Crawl 的 CCBot:纯文本抓取为主,资源提示完全无关。
- Bytespider(字节跳动):技术细节不公开,实测下来对资源提示也无响应。
结论是:没有任何 SEO 相关爬虫会读资源提示。这些标签纯粹是给真实用户浏览器看的。
5 个真正有效的替代优化策略
既然资源提示对爬虫无效,把精力转向真正能影响爬虫行为的几条路径:
用户体验优先,间接反哺 SEO
把 preload/prefetch 留给真实用户:重点预加载 LCP(最大内容绘制)相关资源(如首屏英雄图、主 JS)。用 Lighthouse 或 PageSpeed Insights 审计,目标是 LCP < 2.5s。页面加载越快,用户停留越久、跳出率越低,Core Web Vitals 信号越强,排名自然受益。这才是资源提示该用的地方。
服务器端与爬虫预算优化
- 启用 ETag 或 Last-Modified 响应头,让 Googlebot 快速判断资源是否更新,减少重复抓取。响应 304 Not Modified 是最经济的状态。
- 控制 HTML 文件大小。2026 年谷歌已明确强调前 2MB 内容优先处理,把重要文本、结构化数据放在源码顶部,避免深层 JS 加载的内容被截断。
- 精简 sitemap,只提交高质量、新鲜 URL;结合内部链接结构,形成自然爬取路径。
- 使用 HTTP/3 + CDN 全球加速,降低 TTFB(首字节时间),让爬虫每次访问都"舒服"。
- 合理设置 robots.txt 与 X-Robots-Tag,避免爬虫在低价值页面浪费预算。
监控与诊断闭环
- 定期查看 Google Search Console 的"抓取统计"报告,关注"已抓取但未索引"和"发现但未抓取"页面。
- 用 Screaming Frog 或 Sitebulb 爬取"渲染后 HTML" vs"源代码",快速定位 head 闭合问题。
- 对 JS 重度站点,建议开启 prerender 或使用 Cloudflare Workers 等边缘渲染方案,确保元数据即时可用。
- 用
curl -A "Googlebot"模拟爬虫请求,检查响应是否与浏览器一致。 - 定期用 URL Inspection Tool 抽查关键页面,确认 Googlebot 看到的内容版本符合预期。
SSR/SSG 而非纯 CSR
纯客户端渲染(CSR)的 SPA 是 SEO 噩梦——Googlebot 拿到空壳 HTML,需要等 JS 执行完才能看到内容。即使 Googlebot 支持 JS 渲染,渲染队列的延迟通常是数小时到数天。建议:
- Next.js / Nuxt / Remix 等框架默认使用 SSR 或 SSG。
- 关键页面(首页、详情页、列表页)必须服务端渲染。
- 对动态性极强的页面(用户中心、个人 dashboard),可以保留 CSR——这类页面本来也不需要 SEO。
- 用
fetch as Google(旧称)或 URL Inspection Tool 验证渲染结果。
结构化数据与语义 HTML
Googlebot 不读 preload,但读 JSON-LD 结构化数据。每个页面都应该有:
- Article / NewsArticle / BlogPosting Schema(内容类页面)。
- Product Schema(电商页面)。
- FAQPage Schema(FAQ 段)。
- BreadcrumbList Schema(面包屑)。
- Organization Schema(站点首页)。
这些标记不仅帮助 Google 理解内容,也让 AI Overviews 更容易引用。比起 preload 这种无效操作,结构化数据才是真正能提升曝光的"指挥棒"。
2026 年新趋势加持
随着 AI 概览(AI Overviews)和 Discover feed 的权重提升,页面不仅要被抓取,更要"被理解"。保持语义化 HTML(正确 H1-H6、schema.org 结构化数据)虽然不直接加分,却能大幅提高被 AI 摘要抓取的概率,同时提升无障碍访问性——这在欧盟 DMA 和全球可访问性法规下,已成为隐形竞争力。
另一个值得关注的方向是从"被抓取"到"被理解"再到"被引用"。Googlebot 抓取只是 SEO 链条的第一步,AI 答案引擎(AI Overviews、ChatGPT、Perplexity)越来越倾向于把网站内容拆成独立的"事实块"作为引用依据。这要求每段文字都自带明确的事实陈述、数据点、可验证来源。
同时,llms.txt 协议正在被 AI 引擎广泛采纳。在站点根目录放一份 llms.txt(类似 robots.txt 但专门给 LLM 看),列出 API 入口、关键页面、知识库结构,对未来的 AI Agent 集成大有帮助。
SEO 站长的常见误区清单
除了"以为资源提示对爬虫有用"之外,保哥过去几年发现客户常见的几个误区:
- 以为 PageSpeed 100 分就有 SEO 加成:PageSpeed 是用户体验信号的一部分,不是直接的排名因子。100 分跟 90 分对 SEO 几乎无差。
- 以为关键词密度越高排名越好:2026 年 Google 早已用语义模型判断相关性,关键词堆砌只会被反作弊系统标记。
- 以为有 robots.txt 屏蔽就万事大吉:被 Disallow 的 URL 仍可能因外链而被索引(无内容快照)。要不索引必须用 noindex。
- 以为 Sitemap 提交了就一定被收录:Sitemap 是建议而非强制。Googlebot 仍会按自有算法决定优先级。
- 以为给图片加 alt 就完事:alt 是 SEO 必备,但图片本身的尺寸、格式、加载速度同样关键。
- 以为外链越多越好:低质量外链反而拖累排名,宁缺毋滥。
- 以为发文越多越好:长尾关键词覆盖确实有用,但没质量的文章会拉低站点整体权威度。
这些误区都跟"想取悦爬虫"的思维一脉相承。真正的 SEO 高手会反过来思考:用户需要什么、用户停留多久、用户是否愿意分享——这些才是 Google 算法的最终目标。
结语:SEO 回归本质——以用户为中心
谷歌这次澄清再次证明:想靠几行 link 标签"指挥"Googlebot 的时代已经过去。真正有效的优化,是让网站对真实用户极致友好、对爬虫足够透明。把精力从"提示爬虫"转向"提升体验 + 固化基础",你会发现爬取预算自然更充裕,索引质量也水到渠成。
建议大家去听听原播客完整对话,结合自身站点数据动手实践。播客资源可以在 YouTube 和 Apple Podcasts 上找到《Search Off the Record》节目。
说到底,2026 年能跑出来的,不是代码写得最"聪明"的那批站,而是分得清哪些是给用户看、哪些是给爬虫看的那批人。
TTFB / 抓取性能的工程级优化
资源提示对爬虫无用,但 TTFB(Time To First Byte,首字节时间)对爬虫和用户都至关重要。Googlebot 在每次抓取时会记录 TTFB,长期 TTFB 偏高会让爬取频率自动下降——这意味着新内容被发现的速度变慢、整站索引更新滞后。保哥过去几年针对 TTFB 的几条核心优化:
- 启用 HTTP/3。基于 QUIC 协议,相比 HTTP/2 在网络抖动场景下握手快 50-100ms。Cloudflare、Fastly、AWS CloudFront 都已支持,多数情况下 1 个开关就启用。
- 边缘缓存策略。把静态 HTML 缓存到 CDN 边缘,TTFB 可以从 300ms 降到 30ms 以内。Cloudflare Cache Rules、Vercel Edge Cache 都是好工具。
- 数据库连接池。后端 PHP/Node 应用每次请求建新数据库连接是 TTFB 杀手,建议用连接池(如 PHP-FPM 的 OPCache + 持久连接、Node 的 mysql2 pool)。
- OPCache / 字节码缓存。PHP 应用必开 OPCache,CPU 密集场景再加 APCu 缓存计算结果。
- 预渲染 + 增量静态。Next.js ISR、Nuxt nitro 的混合模式,让动态内容也能享受静态文件的低 TTFB。
- 选靠近用户的机房。如果业务在中国大陆,托管在境内 CDN 比海外节点 TTFB 快 100-300ms。
- 关闭非必要中间件。WAF 规则、地理 IP 检测、A/B 测试 SDK 等中间件叠加会拉长 TTFB,按需取舍。
这些工程优化的回报远大于在 head 里堆 preload。保哥服务过的客户里,TTFB 从 800ms 降到 200ms 的,3 个月内 Googlebot 抓取频率涨了 3 倍。
与 Bing/DuckDuckGo 等其他搜索引擎的差异
Googlebot 不读资源提示是行业标准做法,但其他搜索引擎呢?
- Bingbot:Microsoft 在 2024 年的官方文档里也确认 Bingbot 忽略 preload/prefetch。理由跟 Google 类似——内部网络无瓶颈。
- DuckDuckGo:使用 Bingbot 索引,所以同样不读资源提示。
- Yandex / Baidu:技术细节不公开,但实测下来对 preload 也无响应,行为接近 Google。
- Naver(韩国):使用 Yeti 爬虫,主要按内容相关性抓取,资源提示同样不影响。
结论是:所有现代主流搜索引擎都不读资源提示。这是搜索引擎工程实现的共识。
对 PWA / Service Worker 的特别说明
有同学会问:如果站点是 PWA(Progressive Web App),用 Service Worker 做了离线缓存,资源提示对 SEO 还有意义吗?答案是对 SEO 仍然没影响,但对用户离线体验有影响。
Service Worker 拦截网络请求时会按自己的逻辑决定从缓存还是网络读取,preload 提示在这一层不参与决策。如果你想让 PWA 的核心资源在第一次访问时被预加载到 Service Worker 缓存,正确的做法是在 install 事件里显式 cache.addAll() 你想要的资源列表。
对 Googlebot 来说,PWA 站点和普通站点没本质区别——它抓取 HTML、解析内容、跟随链接,不会触发 Service Worker。所以 PWA 的 SEO 优化跟普通站点一致:SSR 输出关键内容、合理 sitemap、结构化数据齐全、TTFB 控好。
国内云加速的"智能优化"正在偷偷改写你的 head
保哥这两年帮出海客户做技术审计,踩得最多的坑不是站长手写的 preload,而是国内云加速厂商的"智能优化"开关。百度云加速、又拍云、阿里云 DCDN、腾讯云 EdgeOne 这类服务,控制台里常默认开着"页面优化""智能预加载",会在回源后自动往 HTML 里塞 preload、preconnect,合并压缩脚本甚至前移脚本——听着很美,却常常不讲究 head 的结构完整。
保哥遇过最典型的一次:一家 3C 出海独立站开了某国内 CDN 的"极速优化"后,多语言 hreflang 全部失效,英文站、德文站在 Google 里互相抢排名、自我打架。站长查了两周代码都没发现,因为本地源码里 head 写得好好的。最后用 GSC 的 URL Inspection 看 Google 实际抓到的渲染版本,才发现 CDN 把一段内联脚本前移到了 hreflang 之前,触发浏览器提前闭合 head,hreflang 和 canonical 全被甩进了 body——按本文前面讲的规则,Googlebot 直接当它们不存在。
教训很直接:上了国内云加速,别只看本地源码,一定要以 Google 实际渲染的 HTML 为准。把控制台里"自动优化 head""智能注入资源提示"这类开关逐个关掉复测,canonical、hreflang、meta robots 这三样必须确认还稳稳待在 head 里。这点自动提速对真实用户可能只值几十毫秒,可一旦把关键元数据搞丢,代价是整段时间的索引混乱。
在国内验证 Googlebot 到底看到了什么,比你想的难
本文反复强调"以 Google 实际抓到的 HTML 为准",但保哥得提醒一句:在国内做这件事本身就有坑。第一道坎是 GSC 的 URL Inspection 工具境内访问极不稳定,经常数据加载一半就卡住、渲染截图刷不出来,你很容易误判成"页面没问题",其实只是工具没加载完。
第二道坎更隐蔽。很多人会用 curl -A "Googlebot" 在自己服务器上模拟爬虫请求,对比返回的 HTML 和浏览器是否一致。但如果你的站挂在国内高防或 WAF 后面,国内出口 IP 发出的这种裸 UA 请求很可能被风控直接拦下,返回一个 JS challenge 页或验证码页。保哥就见过一次:站长本地 curl 拿回一堆 challenge 代码,急得以为站点对 Googlebot 隐身了,差点重做整套渲染架构,实际上线上对真正来自 Google IP 段的 Googlebot 放行得好好的,被拦的只是他那台国内机器的 curl。
保哥的稳妥做法是:验证渲染结果优先信 GSC 的实测视图,不信本地 curl;要用命令行模拟就换一台境外 VPS 发请求,并用反向 DNS 确认对方 IP 是否归属 googlebot.com;WAF 白名单务必按官方 IP 段而不是 UA 字符串放行 Googlebot——光按 UA 放行既容易被伪造,也容易误伤真用户。把这几步理顺,你才有资格说"Googlebot 看到的和我想的一样"。
常见问题解答
Q1:保留资源提示对 SEO 完全无影响吗?
对 Googlebot 直接行为无影响——爬虫看到 preload/prefetch 也不会按提示去抓取。但对 Core Web Vitals 评分有间接影响:用户浏览器读到这些提示后会优化加载速度,LCP/INP/CLS 改善后属于 Page Experience 信号的一部分,会间接帮助排名。所以保留资源提示是为了真实用户,不是为爬虫。
Q2:head 提前关闭怎么排查?
用浏览器 DevTools 的 Elements 面板查看实际 DOM 结构,看 head 里有没有该有的标签。或者用 curl https://yoursite.com/page 抓取原始 HTML,搜索 </head> 出现的位置,确认 canonical、meta robots 等都在它之前。还可以用 Search Console 的 URL Inspection Tool 看 Google 解析后的 head 内容。
Q3:用了 Cloudflare Rocket Loader 会影响 head 元数据吗?
会。Rocket Loader 会把所有 JS 异步化,包括 head 里的 JSON-LD(如果你用 <script type="application/ld+json"> 写)。建议在 JSON-LD 标签上加 data-cfasync="false",告诉 Rocket Loader 跳过这段。或者直接关闭 Rocket Loader——它对现代 JS 优化收益有限,且容易触发各种边缘问题。
Q4:Next.js 站点用 next/head 添加 preload 还有意义吗?
有意义,但不是为了 SEO,是为了用户体验。next/head 加的 preload 会出现在最终 HTML 里,浏览器读到后会优化加载顺序。这对真实用户的 LCP 有帮助,间接利好 Page Experience 评分。但不要指望 Googlebot 因此抓得更快。
Q5:HTML 有效性既然不是排名信号,是不是就不用管了?
不是。HTML 有效性虽然不是直接排名因子,但无效 HTML 会引发各种间接问题:head 提前关闭导致元数据失效、未闭合标签让 DOM 解析异常、被废弃属性触发兼容模式。建议站点上线前用 W3C Validator 跑一遍,把严重错误(特别是结构性错误)修干净。
Q6:JS hydration 失败会影响 SEO 吗?
影响内容理解。Googlebot 现在能跑 JS,但 hydration 失败时它看到的是首次渲染的 HTML(通常是部分内容 + 加载中骨架)。如果 hydration 失败的原因是依赖了浏览器特定 API(如 window.matchMedia),需要在服务端做兼容处理。建议主要内容用 SSR 输出,hydration 只用于交互增强而非内容渲染。
Q7:怎么判断 Googlebot 是否真的读了某个标签?
用 Search Console → URL Inspection Tool → "View crawled page",看 Google 实际抓到的 HTML。这是最权威的判断依据。如果你看到 canonical 在 body 里、或者 meta robots 缺失,说明渲染或解析出了问题,需要回到模板层修复。
Q8:以后 Googlebot 会不会改变策略开始读资源提示?
从工程角度看可能性不大。Googlebot 的设计目标是规模化抓取数百亿页面,对每个页面的提示都"听话"会引发指数级资源消耗。除非有压倒性的业务需求,否则这个策略不会变。所以建议把资源提示永远视为"给浏览器的指令"而非"给 Googlebot 的指令",未来若干年都成立。
把这些理解贯彻到日常 SEO 工作里,就能避免大量无效操作,把精力真正用在能产生回报的地方。资源提示属于面向浏览器的优化技术,跟爬虫的世界是两条平行赛道——理解这一点之后,技术 SEO 的判断标准会清晰很多,不再被各种"取悦爬虫"的小技巧带偏方向。下次再有人推荐你给站点加一堆 preconnect 来提升 SEO 排名分数时,可以自信地告诉对方:那东西爬虫从来不会看,把精力花在内容质量、TTFB、Schema 结构化标记上才是正路。
权威参考资料
本文标题:《Googlebot不读preload?5招实战指南》
本文链接:https://zhangwenbao.com/why-googlebot-ignores-resource-hints.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0