URL结构与slug命名SEO全指南:7维设计与上线后铁律
本文目录
- URL设计为什么会被低估又被高估?
- 关键词在URL里的位置真的重要吗?
- URL长度的硬上限和软建议是什么?
- URL层级深度对抓取有什么影响?
- 参数URL怎么处理才不掉收录?
- 子域名vs子目录vs子文件夹的权重传递有差吗?
- trailing slash、大小写、编码这些细节会影响SEO吗?
- 已上线URL该不该改?什么情况是例外?
- AI搜索时代URL结构还重要吗?
- 常见问题解答
- URL里关键词位置真的影响排名吗?还是只影响点击?
- URL长度到底多少是上限?听说短URL排名更好?
- subdomain和subfolder选哪个?Google说一样真的吗?
- 已上线URL真的一个字都不能改吗?
- 中文URL到底能不能用?punycode还是直接中文?
- URL参数有那么可怕吗?所有参数都要canonical收口?
- AI搜索时代URL结构还重要吗?LLM不看URL啊?
- 权威参考资料
摘要:保哥早年给一家做电气控制柜的B2B工业自动化品牌做诊断,他们网站上线半年自然流量几乎为零,团队把锅扣在内容质量和反链上——其实最大的问题在URL:所有产品页slug全部是内部SKU编号如 /products/AC-7821-V3.html,整站搜索引擎拿不到一个能用的关键词信号。换一批slug后六个月内长尾词从0涨到日均1200进站。这种案例不是个例,URL设计被低估或被高估的团队都很多。本文按七个维度拆URL结构对SEO的真实影响:关键词位置、长度截断、层级深度、参数处理、子域名vs子目录、编码与trailing slash、改URL的代价——给的是判断设计决策的框架。
URL不只是一串地址字符,它同时承载Google抓取、索引、排名、SERP显示四个层面的信号。设计一个URL等于在这四层信号上做四个隐含决策。问题是大部分团队设计URL时只看第一层“能不能访问”,把后三层的信号能力完全浪费掉——或者反过来过度优化slug当成“SEO神技”。这两种偏差都来自同一个根因:把URL当字符串而不是当多层信号载体。本文要拆的就是这四层信号在七个具体维度上的实际表现。
URL设计为什么会被低估又被高估?
低估方的典型表现,是把slug当成“系统自动生成就行”的事。产品页用SKU、博客文章用ID、分类页用拼音首字母——所有这些选择都让URL在抓取索引环节失去关键词信号能力。Google不会因为URL难看而拒收,但SERP显示时无法把URL里的关键词加粗,CTR会比含核心词的URL低一个量级。
高估方的典型表现,是把改URL当成万能SEO操作。看到URL长就改、看到slug关键词不前置就改、看到层级嵌套就推倒重做。这种“持续优化”反而是破坏行为:每改一次URL就要重做301、清理sitemap、通知反链来源、等Google重新认。改五次以后基本上原页面所有积累的信号都被反复重置。
正确的视角是把URL当成一旦上线就接近不可改的资产。设计时投入足够的判断力一次做对,上线后只在极少数情况下才动。这要求设计阶段必须把七个维度全部判断清楚——长度、关键词位置、层级、参数、子域名结构、编码细节、与未来扩展的兼容性。设计阶段半小时的多想,上线后省一年的回头折腾。
URL信号在Google内部的权重相对小,但它的作用是“乘数”而不是“加数”——一个差的URL不会让一篇好文章排不上去,但它会让一篇好文章的CTR比应有水平低20-40%。乘上排名靠前位置的流量基数,这个折损是不容忽视的隐性损失。
这一点跟canonical标签机制与跨域冲突诊断是配套的:canonical决定的是“哪个URL算正本”,URL设计决定的是“正本本身长什么样”。两者顺序不能反——先把URL设计对,再用canonical处理变体。设计阶段不上心、靠canonical救场是最累的活。
关键词在URL里的位置真的重要吗?
Google多次官方表态“URL关键词权重很小”,这话是真的——但被很多团队误读成了“URL关键词无所谓”。真实情况是:URL关键词对排名影响小,但对SERP显示和点击率影响大。这两件事被混在一起谈,结论就走歪了。
SERP显示时,Google会把跟用户查询相关的slug关键词加粗。一个slug是 /best-running-shoes-women-2026的URL跟一个 /product/AC-7821-V3的URL,搜“women running shoes”时前者会显著高亮,后者完全无视觉信号。同一个排名位置下,加粗URL的CTR实测能比无关键词URL高15-30%。
关键词位置的常见误区有三个。第一个是“越靠前越好”。slug里关键词放在第一个词位置vs第三个词位置,实测差异不显著——Google抓的是整个slug里的关键词存在性,不是位置权重。第二个是“越多越好”。slug里堆5-6个关键词触发反向信号,Google会判定为关键词堆砌降权。第三个是“完全匹配最好”。其实partial match(部分匹配)跟exact match在排名上几乎没差别,slug写得自然就行不必死扣完全匹配。
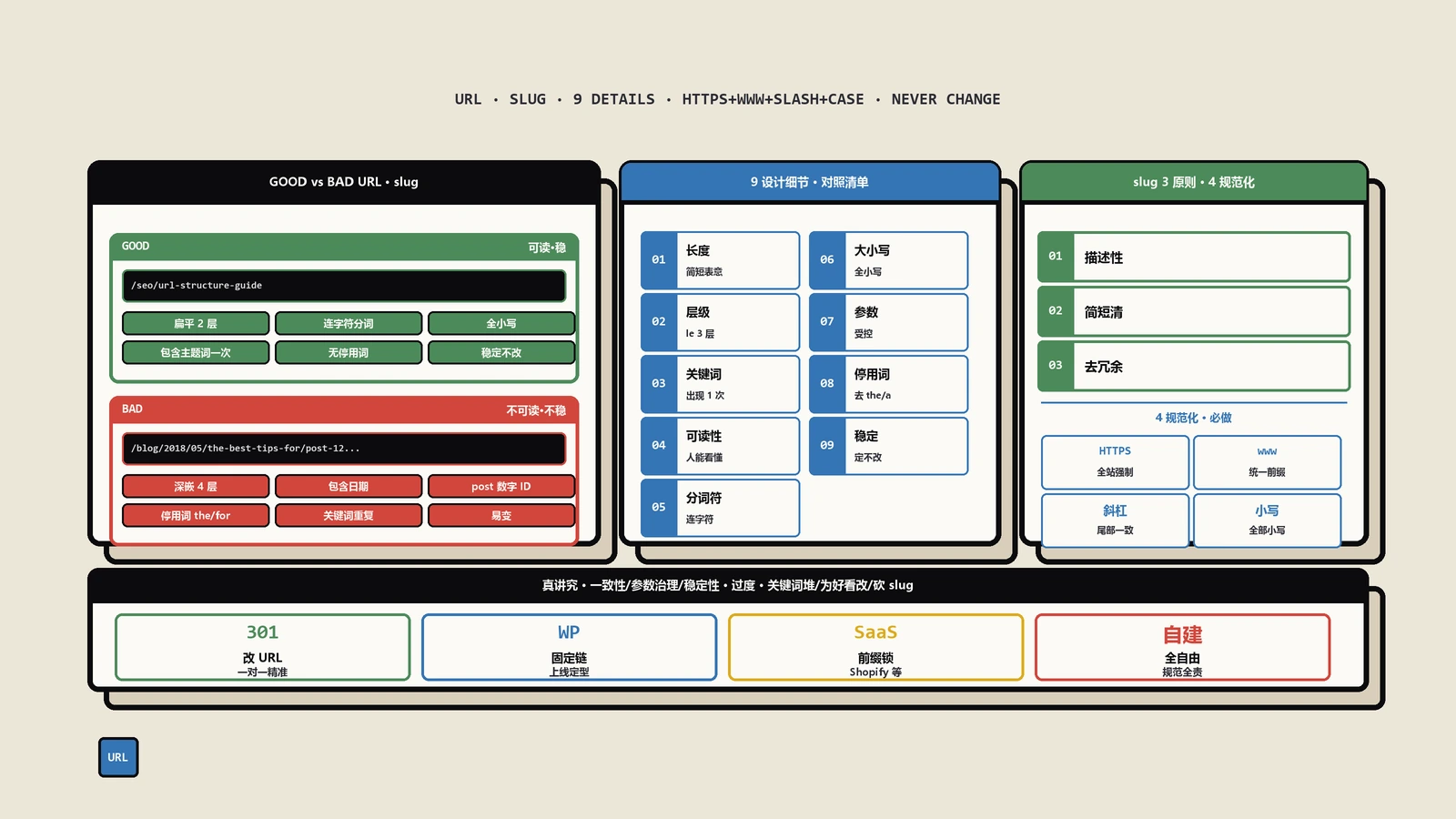
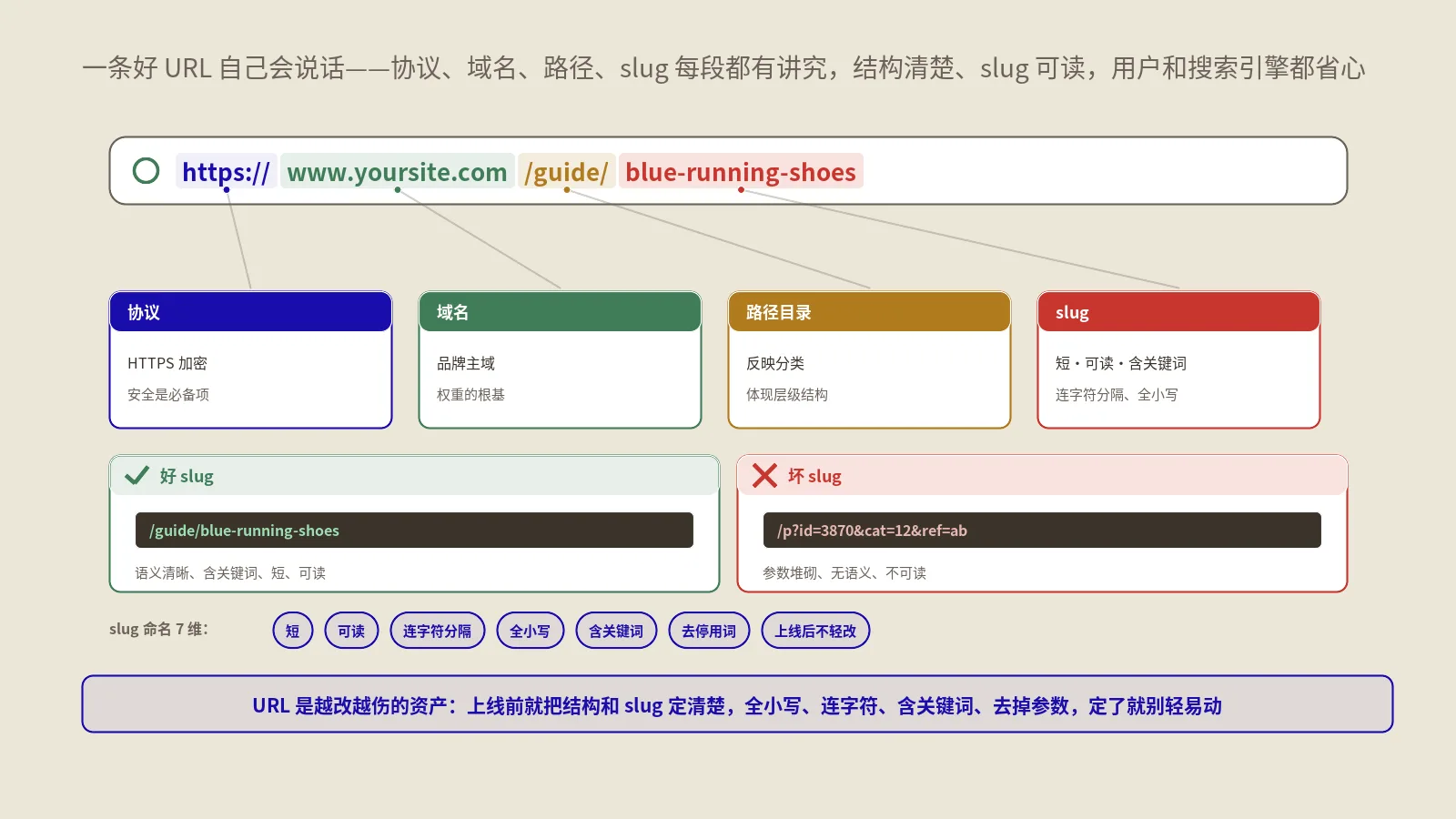
实操硬规则是每个slug含2-4个核心词、之间用连字符(hyphen)分隔、避免下划线和空格。Google早期对下划线和连字符处理不同,现在统一识别为分词符——但连字符仍是行业标准,跨工具兼容性更好。slug里全用小写、不用stop words(the/a/and这种)、不用日期数字(除非内容真的是年度特性如“2026 guide”)。
slug中关键词规范化(normalization)也容易被忽视。大写小写的混用、UTF-8编码与ASCII之间的差异、空格用 + 还是 %20还是hyphen——这些细节会导致同一篇内容产生多个变体URL都被Google收录但权重分散。设计阶段就把这些规则写死:全小写、连字符分词、纯ASCII、无trailing slash或统一带trailing slash二选一。
URL长度的硬上限和软建议是什么?
URL长度对SEO有两层硬约束。第一层是技术上限——HTTP协议规范没有强制上限,但绝大多数浏览器和服务器实际处理2048-8192字符以内的URL,超出可能不被支持。第二层是SERP显示截断——这才是真正影响SEO的层面。
桌面SERP上Google显示的URL长度约70-90字符(按字符宽度算,实际像素),超出会被省略号截掉。移动端更狠,约50-60字符就开始截。一个slug是 /best-running-shoes-for-women-with-flat-feet-and-knee-pain-2026-comprehensive-guide这种80+ 字符URL,在移动端SERP上用户只能看到前面50字符,后面30字符的关键词信号完全浪费。
实操硬规则是URL全长(含域名 + slug)控制在60-75字符,slug单独控制在50字符以内最稳。这个区间能保证桌面和移动端都不被截。超过这个区间也不会被Google降权,只是CTR折损——折损的程度跟超出量正相关。
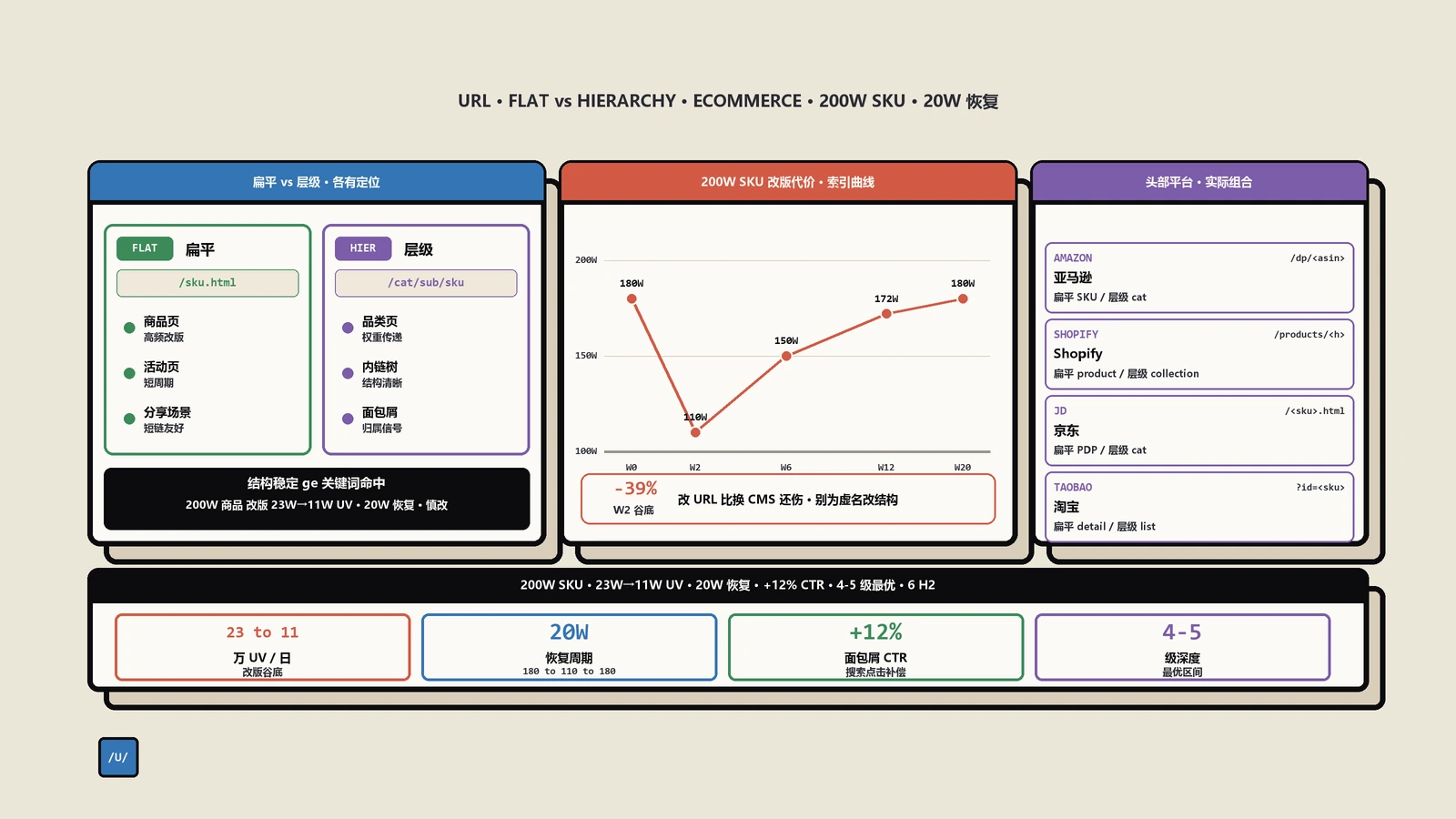
反模式有几种特别要避开。第一种是动态URL加上时间戳或会话ID:/article?id=12345&t=1701234567&sess=abc——这种URL没有任何SEO价值,应该全部canonical收口到一个稳定的静态slug。第二种是UTM参数泛滥:/post/123?utm_source=email&utm_medium=newsletter&utm_campaign=blackfriday——同样必须canonical收口,不然sitemap收上千万条变体浪费抓取预算。第三种是无意义的层级前缀:/website/articles/blog/post/2026/01/15/title——除最后一段外其他全是噪声,应该扁平化到 /title或 /blog/title。
那家DTC美妆品牌客户保哥服务过,上线初期sitemap一度爆到280万条URL,团队还以为是巨大优势。一查发现95% 都是utm_* 跟踪参数变体——一篇博客被19个不同的邮件营销活动转发就生成19个URL变体全被sitemap收。最后用canonical把所有utm变体统一收口到主URL,sitemap缩到15万条,抓取预算回流到真正的内容页面,三个月后核心页面的收录率从67% 升到94%。
URL层级深度对抓取有什么影响?
URL层级深度指的是URL路径里的“斜杠数”,比如 /a/b/c/d是4层。这跟“抓取深度”(crawl depth,即从首页跳几次能到这一页)是两个不同概念但经常被混淆。
URL层级深度本身对排名几乎无影响——/a/b/c/d/page跟 /page在Google索引时同等待遇。但抓取深度有真实影响。如果一个页面从首页要点5次以上才能到(即使URL是 /page也好),Googlebot的抓取频次会显著低于2-3跳能到的页面,新发布也会延迟收录。
所以“URL层级浅vs深”这个老问题,真正该问的是“我的关键页面从首页几跳能到”——这跟URL层级数往往不一致。一个URL是 /products/category/subcategory/item-name看起来4层,但如果首页直接有“热门商品”模块链到这页,抓取深度是2跳。另一个URL是 /short-name看起来1层,但如果它只能通过站内搜索找到,抓取深度可能是7跳。
实操判据:关键页面抓取深度控制在3跳以内,长尾页面5跳以内,超过5跳的页面要么用内链补救要么放弃。补救方式是从首页或高权重页面加直接链接(不是面包屑、不是sitemap,是正文里的真实锚链)。
跟这部分相关的还有面包屑导航与BreadcrumbList结构化数据——面包屑跟URL层级是两个并行的导航维度,可以协同也可能冲突。面包屑给Google一个清晰的hierarchy提示,URL层级给crawler一个path提示,两者要保持逻辑一致:URL是 /blog/seo/url-design时面包屑应该是“首页 > 博客 > SEO > URL设计”而不是“首页 > URL设计”。
另一个常被忽视的层级问题是URL大小敏感关键词的"伪深度"陷阱。有些CMS会在slug前自动加 /category/ /tag/ /archive/ 等系统前缀,看起来层级合理但其实没有任何SEO含义——前缀本身不带关键词又增加了URL长度,平白浪费SERP显示空间。能去除的系统前缀都应该去掉,URL越接近 /page-slug越好;非要保留前缀的话也尽量短到只有一个词。
扁平vs嵌套这个老话题的判据其实简单:能用扁平就扁平,但不要为了扁平而牺牲信息架构。一个有5000个SKU的电商,所有URL都堆在 /shoe-name这种根目录下不仅难管理还容易跟其他类型内容冲突;分到 /products/men/running/shoe-name反而清晰。设计URL层级的真正约束不是SEO而是信息架构本身。
参数URL怎么处理才不掉收录?
参数URL(即带问号和键值对的URL)是SEO工程里最容易出事的一环。一个电商站如果不处理筛选参数,sitemap可能从5万条页面爆到5000万条变体——绝大部分都是同内容不同URL,浪费99% 的抓取预算还引发重复内容信号问题。
参数URL分两类要分别处理。第一类是改变内容的参数,比如 /products?category=shoes跟 /products?category=bags是不同内容。这类应该有清晰的canonical策略——要么各自有独立URL(重写成 /products/shoes和 /products/bags),要么明确选其中一个变体作为canonical其他指向它。
第二类是不改变内容的参数,包括跟踪参数(utm_*, fbclid, gclid)、排序参数(sort=price-asc)、视图参数(view=grid)、会话ID(sess=xxx)。这类必须无条件canonical收口到无参数版本,否则Google会把它们当独立URL收录浪费预算。
处理参数URL的工具链有三种。第一是canonical标签——最稳但需要每个页面都正确实现。第二是Google Search Console的URL Parameter Tool(已停用,2022年下线,曾经能告诉Google哪些参数忽略)。第三是robots.txt的Disallow规则——但要注意disallow不等于noindex,被disallow的URL还可能被收录只是不被抓取。最稳的组合是canonical主用 + robots Disallow仅用于明确无价值的参数(如sess=*)。
跟参数URL处理紧密相关的是XML Sitemap完全指南——sitemap是告诉Google “这些URL我希望被收录”的白名单,所有参数变体如果不希望被独立收录就不该出现在sitemap里。Sitemap整洁度本身就是站点级质量信号,sitemap里塞乱七八糟的参数URL会拉低整个站的画像。
参数URL与fragment(#锚点)的区别也常被混淆。# 后面的内容浏览器不发到服务器,Google默认也不当独立URL处理。所以 /page#section跟 /page是同一个URL,不需要canonical。但 /page?section=foo是不同URL,需要处理。
子域名vs子目录vs子文件夹的权重传递有差吗?
这是SEO圈最经典的争论之一。Google官方多次说“两者处理上一样”,但实际操作上有几个差别值得理清。
第一个差别是站点级质量画像。Google对每个站点(domain)有一个综合质量画像,影响整站排名。子目录example.com/blog跟主站example.com共享同一个domain因此共享画像;子域名blog.example.com在Google眼里是不同的站点画像(虽然权重传递机制存在)。所以一个高质量大站新开一个博客,放subfolder立刻能继承画像,放subdomain等于从零开始攒。
第二个差别是抓取行为。子目录跟主站抓取调度统一,子域名各自独立调度。如果子域名的内容质量平均水平比主站低,可能拖累子域名独立的抓取频次。
第三个差别是分析与监控分离。GSC里subdomain默认是独立属性需要分别验证,subfolder在主属性下统一看。运营复杂度差异挺明显。
那么什么时候选subdomain?保哥的判据是三种:第一是强业务隔离,比如shop.example.com是商店、blog.example.com是博客、help.example.com是文档,三者用户群跟内容性质显著不同。第二是多语言/多国家独立运营,jp.example.com / fr.example.com这种情况,但更推荐ccTLD即各国独立顶级域名。第三是技术栈隔离,比如主站是WordPress、博客是Hugo静态站、商店是Shopify——三个不同后端用subdomain方便DNS切换。
除这三种情况之外,默认选subfolder几乎永远是更稳的。这跟很多SEO教程的建议一致。subdomain有营销/品牌/技术维度的合理理由时再用,纯为SEO用subdomain是不必要的复杂度。
保哥的一个出海开发者工具SaaS客户曾经做过subdomain切subfolder的A/B实验,他们的博客原本在blog.product.com跑了18个月攒到日均800进站,迁移到product.com/blog后第一个月掉到600(迁移损失),第三个月反弹到1200,第六个月稳定在1400左右。这种增长不是因为subfolder “更好”,是因为主站之前积累的画像在切换后能直接服务博客内容,相当于免费搬了一次家。
trailing slash、大小写、编码这些细节会影响SEO吗?
这些“细节”听起来无关紧要,但累积起来能让同一个内容产生5-10个不同URL变体全被Google收录权重分散。一个页面被四五个变体瓜分排名,相当于把单页流量打了70-80% 折扣。
第一组细节是trailing slash(末尾斜杠)。/page跟 /page/ 在HTTP层是两个不同的URL,Google当作不同页面处理。设计时必须二选一:要么全站带trailing slash、要么全站不带,然后用服务器301重定向把另一种统一过来。常见错误是首页带 /、内页不带,或者技术上没强制重定向导致两种都存在并被收录。
第二组是 大小写敏感性。HTTP协议里URL path部分是大小写敏感的(domain部分不敏感)。/Page跟 /page在多数服务器配置下是不同URL。最稳是设计阶段约定全小写slug,并在服务器层做301把大小写变体统一过来。
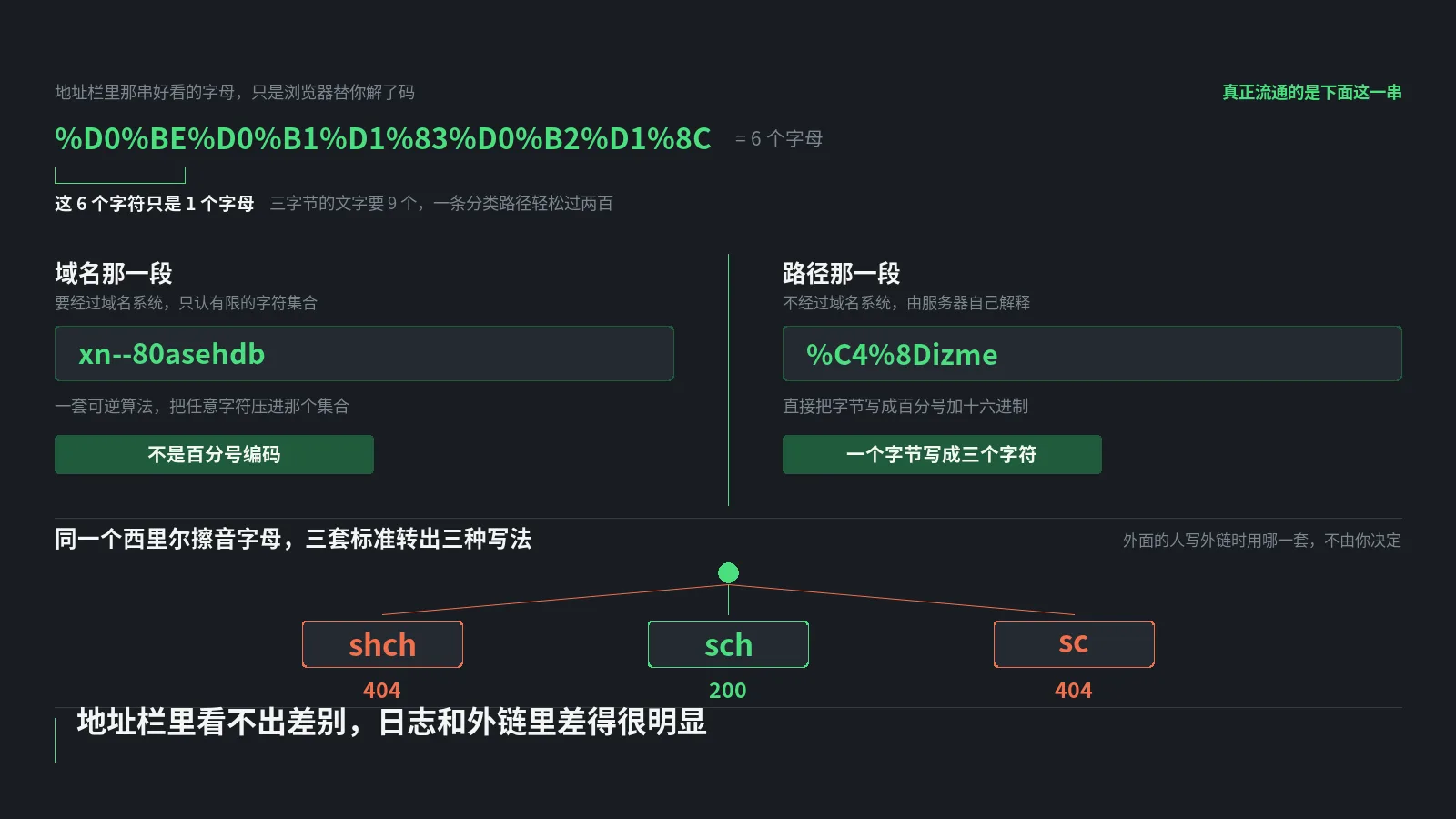
第三组是URL编码与UTF-8。/中文 跟 /%E4%B8%AD%E6%96%87是同一个URL的两种表达方式。Google都能处理但用户复制粘贴URL时会变成encoded版本,看起来乱码。出海独立站默认slug用ASCII英文最稳,国内站若决定用中文URL要测试主流浏览器/邮件客户端/社交媒体的URL显示是否乱码。
第四组是www与非www子域名。example.com跟www.example.com是不同host,Google当不同站点处理。设计阶段必须二选一并301强制统一。这跟HTTP/HTTPS二选一是同样性质的问题——必须统一收口到一个canonical host。
跟HTTP状态码深度相关的是HTTP状态码SEO完整图谱——URL变体统一收口的核心工具是301(永久重定向),偶尔用302(临时重定向)和308(保留方法的永久重定向)。误用状态码会让重定向不被信任,Google不会把权重完整传过去。
第五组是 查询参数顺序。/page?a=1&b=2跟 /page?b=2&a=1在Google处理上可能不一样,是否被当同一URL取决于canonical标签。最稳是服务器端规范化参数顺序输出,避免变体。
这五组细节加起来,一个没设计好的网站可能让一个核心内容页同时有8-16个不同URL都被收录。统一收口是SEO基础工程的第一步,做不好上层任何优化都是事倍功半。
已上线URL该不该改?什么情况是例外?
这条几乎是所有SEO实操的最高原则之一:已上线URL默认不改。理由是URL上线后会成为多种系统的“地址锚点”——内链指向它、反链锚定它、社交分享存它、用户书签收它、GSC数据归属它、AI引擎引用它。改URL就是把所有这些锚点同时移位,必然损失。
但“原则上不改”不等于“绝对不能改”。改URL的几种合理例外是:第一种是法律合规要求,比如商标争议、GDPR删除请求、政府监管。第二种是重大业务调整,公司改名、品牌重塑、站点结构性整合。第三种是严重设计错误,比如slug含敏感词、含PII(个人识别信息)、含明显错误关键词导致SERP错位严重。第四种是系统性技术迁移,比如HTTP升HTTPS、www改非www、CMS换架构。
改URL必经五步流程,缺一步都会造成不可逆损失。第一步是全站301重定向,旧URL永久跳新URL,必须是服务器301不是JS重定向也不是meta refresh。第二步是更新所有内链,站内所有指向旧URL的链接改成新URL(虽然301能传权重但直接链接体验和效率更好)。第三步是重新提交sitemap,新URL加入、旧URL移除,并ping通知Google。第四步是通知主要反链来源,最重要的20-50个反链联系对方更新链接(不是所有反链都要改,重点20% 即可)。第五步是耐心等待30-90天,让Google完整把信号迁移到新URL,期间不要做其他大动作。
跟改URL紧密相关的网站迁移完全指南把整站级别的URL大改造程序化了——单页改URL跟整站改URL性质上一致但工程量差三个数量级。整站级改造必须先做规划阶段的URL映射表,每个旧URL对应一个新URL,再批量301。
“改URL让排名涨”这种想法基本是误导。实测改URL后短期排名都会掉(迁移损失),三到六个月才能恢复,最终结果跟“不改”持平或略低——除非改URL同时配合了真正实质性的内容/结构/质量升级,那种情况下涨的是内容部分不是URL部分。所以判断“该不该改URL”的核心问题是:这次改动的ROI高到值得付出三个月排名波动吗?多数情况下答案是否。
AI搜索时代URL结构还重要吗?
有些团队听说LLM不直接用URL信号做训练,就推断“URL在AI时代不重要了”——这个推断是错的。真正的情况更复杂:URL在AI搜索时代对训练贡献变小,但对引用稳定性要求变高。
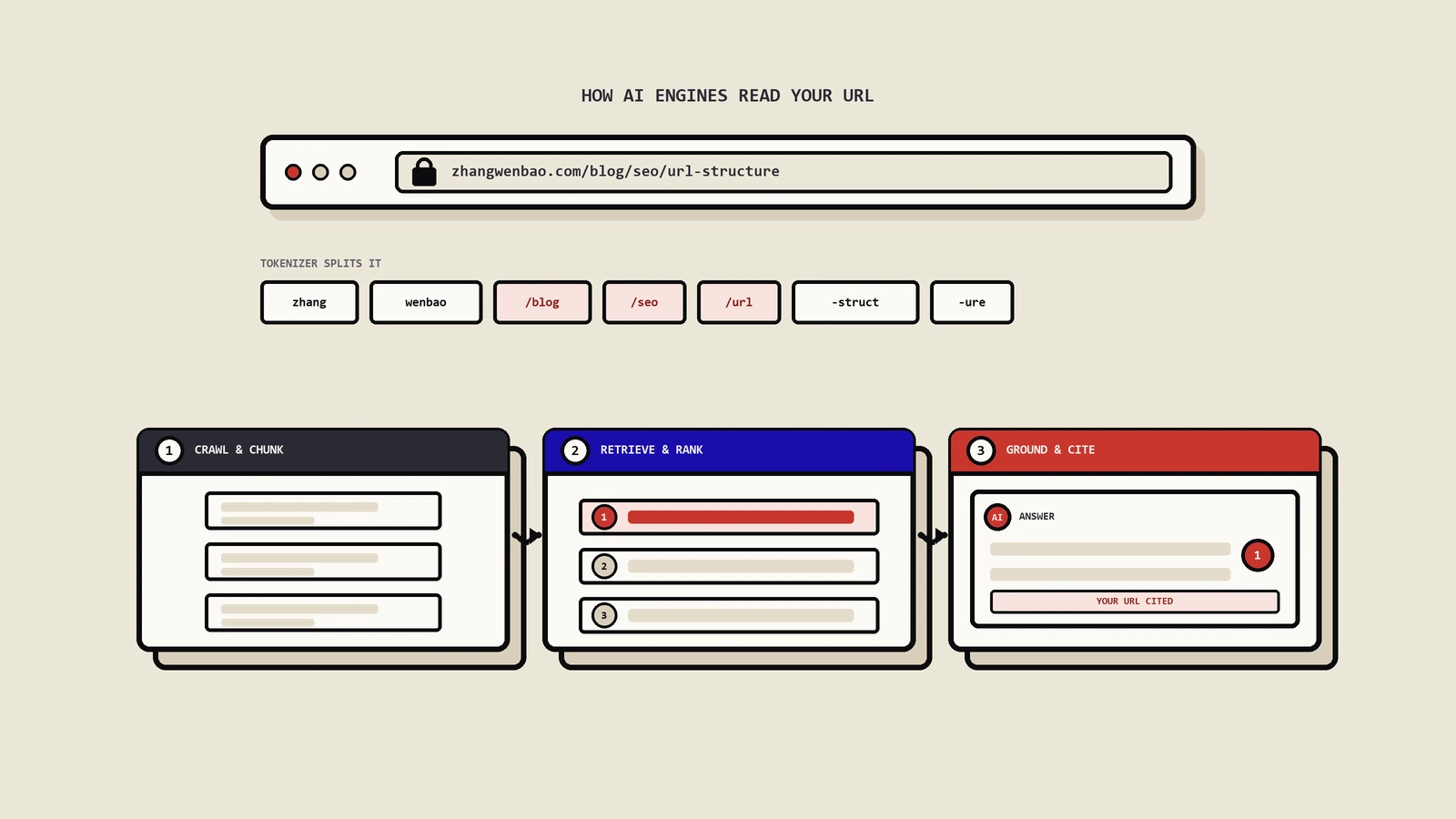
LLM训练阶段不直接把URL当排名信号,但训练数据来自爬虫抓取的页面,URL决定了页面能不能被抓到、被抓后能不能被准确归类。一个slug模糊的页面(如 /article/12345)跟一个slug清晰的页面(如 /best-running-shoes-2026),LLM训练时对前者的“主题归属”判断难度更高,可能在embedding空间分类错位。
更重要的是实时引用阶段。AI引擎如ChatGPT/Perplexity/Claude/Gemini引用页面时会显示原页URL作为来源。这时URL起到三个作用:用户点击查看原文的入口、AI内部“引用关系图”的节点ID、品牌曝光的视觉载体。URL改了等于这三个作用全部断链——AI引擎下次更新时可能直接把你的页面从引用网络剔除。
所以GEO时代URL稳定性的要求比SEO时代更高。SEO时代改URL损失反链和老GSC数据,新URL经过30-90天还能恢复;GEO时代改URL不仅有这些损失,还会让原本积累的“AI引用资产”消失——而AI引擎重新认URL的周期目前不透明,可能要几个月,可能更久。
URL设计在GEO时代有几个新关注点。第一是URL中关键词稳定性,slug里的核心词最好选不会随时间变化的稳定主题词(不要用“2024 guide”这种有年份的)。第二是URL的“被引用友好度”,slug短而有意义比长slug更容易被AI引擎完整保留在引用句子里。第三是URL作为entity identifier,schema.org的 @id字段越来越多被AI引擎用来跨页关联实体,URL同时承担entity ID的角色。
实操建议是:已上线URL在GEO时代铁律变得比SEO时代更严,能不改就不改、必须改时同步通知AI引擎(部分如Perplexity/Bing有IndexNow之类的接口)、改后监控AI引用回归速度。这不是把SEO规则套到GEO,是GEO在SEO基础上加了一层新约束。换个角度想:URL在SEO时代就是页面入口,在GEO时代它额外成了LLM训练库里的一个稳定引用坐标——坐标飘了,引用就找不到归宿了。这是设计URL时新增的远期考虑。换言之,今天写的slug不只服务这一年的SEO,它要服务接下来五到十年里跨SEO+GEO双引擎的引用关系网络——稳定才是真正的设计目标。
常见问题解答
URL里关键词位置真的影响排名吗?还是只影响点击?
Google多次说URL关键词权重很小,但实测影响的不是排名而是SERP点击率。同一个排名下,URL里前置的核心词加粗显示会让CTR比SKU编号的URL高15-30%。所以slug设计的核心ROI在点击不在排名,看待方式不一样优化动作就不一样。
URL长度到底多少是上限?听说短URL排名更好?
桌面SERP显示截断在60-75字符左右,移动端更短。所以URL控制在60字符内最安全,超过部分会被省略号截掉影响CTR。短URL排名更好这个说法没有官方依据,更多是“短URL通常对应更短主题=更聚焦”的相关性,不是因果。
subdomain和subfolder选哪个?Google说一样真的吗?
Google官方说权重传递“处理上一样”但站点级质量画像是分开的——大站example.com高质量也不会自动把blog.example.com一起拉上。所以新博客/新业务线放subdomain等于从零开始攒画像。除非有强业务隔离需求(不同语言/不同品牌),默认选subfolder稳。
已上线URL真的一个字都不能改吗?
原则上别动,因为反链/书签/内链/sitemap/老GSC数据全是基于旧URL的。改URL必经301 + 更新所有内链 + 重新提交sitemap + 通知主要反链来源 + 等Google重新认30-90天五步,每一步漏掉都会掉流量。例外只有三种:法律合规、重大业务调整、严重设计错误。
中文URL到底能不能用?punycode还是直接中文?
技术上都能用,Google都能正常抓取。但中文URL在分享到其他平台会被URL编码成 %E4%B8%AD%E6%96%87这种字符串,反链锚文本里就成乱码、可读性差。出海独立站默认用英文slug最稳,国内站若用户全在中文环境可以中文URL但要做好编码兼容测试。
URL参数有那么可怕吗?所有参数都要canonical收口?
看参数类型。改变内容的参数(如 ?category=shoes)该有独立URL或筛选页处理;不改变内容只跟踪用的参数(?utm_source=xxx)必须canonical收口到主URL,否则sitemap收100万条没意义的URL,浪费抓取预算。区分对待,不是一刀切。
AI搜索时代URL结构还重要吗?LLM不看URL啊?
LLM训练时不直接用URL信号,但抓取页面进训练库和实时引用的爬虫还是要URL稳定的。被ChatGPT/Perplexity/Claude引用的页面URL改了就是断链,引用关系会随之消失。所以GEO时代URL稳定性的要求比SEO时代更高,因为AI引用的“资产”绑在URL上。
权威参考资料
本文标题:《URL结构与slug命名SEO全指南:7维设计与上线后铁律》
本文链接:https://zhangwenbao.com/url-structure-slug-naming-seo-design-framework-7-dimensions.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0