canonical标签到底怎么用?8种跨页场景与冲突诊断
本文目录
- canonical标签到底是什么信号?为什么Google可以忽略它?
- 2009年跨引擎联合声明是怎么来的
- 建议不是指令——这条边界决定一切
- canonical与301、noindex、robots的角色边界对照
- canonical信号是怎么合并的?Google从5类输入选规范网址的机制
- HTML标签里的rel=canonical
- HTTP Header里的Link rel=canonical
- sitemap.xml里的隐含信号
- 内链流向与重定向链信号
- 内容相似度的自动判定
- 自指canonical到底该不该写?什么场景必须写?
- self-referencing起源与争议
- 5种自指必须写的场景
- 2种自指不必要的场景
- 跨页canonical 8种典型场景该怎么选?
- 排序筛选与分页参数收口
- 移动版m.子域名(已逐步弃用)
- 跨语言区域版本与hreflang协作
- 联合发文syndicated content
- 跨域转载防御
- PDF与打印版收口
- 同内容多URL收口
- AMP与移动加速页配对
- 跨域canonical真的能传权重吗?合规vs风险
- 跨域canonical的机制与限制
- 合规场景:内容辛迪加syndication
- 合规场景:品牌跨站与多品牌矩阵
- 风险:被竞品挂canonical偷流量
- canonical为什么会被Google忽略?6大原因诊断
- 内容根本不重复——Google自己判断
- canonical链与循环
- 多个canonical标签共存
- 与noindex矛盾
- 与hreflang互相否定
- 与内链/sitemap/重定向信号反向
- canonical与sitemap/hreflang/noindex怎么协同?
- 不矛盾时各司其职
- 矛盾时Google的优先级
- 5步协同清单
- canonical错配怎么诊断?GSC加抓取审计4步实战
- URL Inspection看Google选了谁
- GSC索引覆盖canonical错配指纹
- 抓取工具批量验证
- 案例:DTC出海客户迁移后canonical全错
- AI检索时代canonical还重要吗?
- LLM训练抓取与canonical信号
- 内容指纹与canonical的双轨
- 常见问题解答
- canonical标签是不是排名因素?
- canonical和301重定向该用哪个?
- 自指canonical是必须写吗?
- canonical写了为什么还是不生效?
- 跨域canonical真能传权重吗?
- GSC怎么看Google到底选了哪个URL当canonical?
- 权威参考资料
摘要:canonical不是排名因素,是Google用来从一堆相似URL里选一个规范版本的合并信号。它是建议不是指令——Google可以忽略,且实战里被忽略的概率比大多数SEO人想的要高。本文拆8种典型使用场景、6大被忽略原因、与sitemap和hreflang和noindex的协同矩阵、GSC诊断4步,以及AI检索时代canonical的新角色。
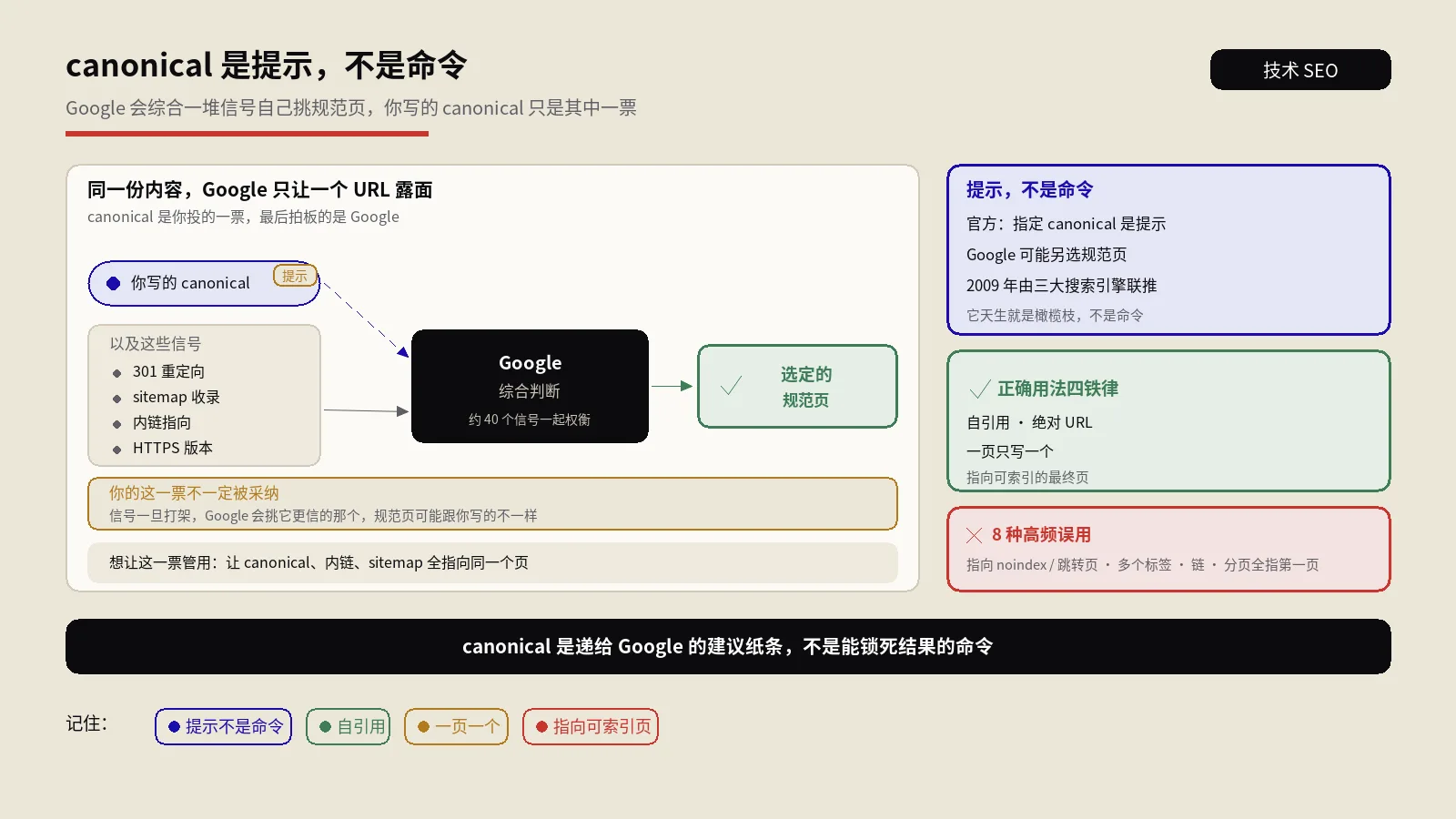
canonical标签到底是什么信号?为什么Google可以忽略它?
很多人把canonical当成开关用——以为加了就能强制Google把权重归到某个URL。这是十年里SEO人最常见的认知错位之一。保哥早期带团队时也踩过坑:某个DTC出海客户的产品筛选页加了一整套canonical指回主类目,半年后查GSC才发现Google根本没采纳,索引了几千个参数页吃掉了抓取预算。所以拆canonical前,先拆它在Google算法里的真实身份。
2009年跨引擎联合声明是怎么来的
2009年2月,Google、Yahoo、Live Search(Bing前身)三家联合宣布支持rel="canonical"标签。这是搜索引擎史上少有的跨厂商协议,起源就是为了解决电商和CMS站点天然产生的大量近重复URL问题——同一商品挂多个分类路径、参数排序产生几十种变体、追踪链接污染、www与非www版本并存。在此之前,搜索引擎只能靠自己的算法判断哪些URL是重复的,误判率不低。
这次联合声明把“哪个版本是主版本”的判断权部分让渡给了站长。但关键词是“部分让渡”——三家从一开始就明确说这是hint(建议),不是directive(指令)。这条边界在2024年依然成立,Google John Mueller反复在Search Central公开问答里强调过。
建议不是指令——这条边界决定一切
canonical是Google说“你告诉我你认为哪个是主版本,我会优先参考,但最终选择权在我”。这和robots.txt里的Disallow(指令、强制)、meta noindex(指令、强制不索引)有本质区别。canonical更像在一组候选URL之间打分时,你给Google提供一个高权重的提示信号。
实战里这条边界意味着什么?意味着加了canonical之后,你必须验证Google是否真的接受了你的声明。不验证的SEO等于盲飞——下面会展开GSC的URL Inspection怎么用。
canonical与301、noindex、robots的角色边界对照
这四个工具新手最容易混用,实际上职责完全不同。做技术SEO审计时,90%的问题来自这四个工具的边界认知模糊。下面这张表是2024年的现行边界,放在团队Wiki里能省掉大量重复争论。
| 工具 | 性质 | 权重传递 | 用户能访问吗 | 典型场景 |
|---|---|---|---|---|
| canonical | 建议(可被忽略) | 会归集到主版本 | 所有版本都能访问 | 参数页、排序、追踪链、跨域同内容 |
| 301重定向 | 指令(强制) | 几乎全量传递 | 旧URL自动跳到新URL | 页面永久搬家、合并旧URL |
| noindex | 指令(强制) | 不传递 | 用户能访问,但不进索引 | 内部页、感谢页、过滤页 |
| robots.txt Disallow | 抓取指令(强制不抓) | 不能合并,可能仍被索引 | 用户能访问,Google不抓 | 大批量URL止血、敏感目录 |
记住一个判断公式:页面应该被用户访问吗?——不应该,用301或404/410;应该被访问但不该单独排名吗?——用canonical合并到主URL或用noindex让它不进索引。这两个维度交叉得到的决策矩阵,比记十条规则有用。
canonical信号是怎么合并的?Google从5类输入选规范网址的机制
Google官方文档2020年后逐渐公开了一个事实:它不是只看<link rel="canonical">一个信号,而是综合5类输入做合并判断。把这5类信号都讲清楚,canonical才不再是黑箱。
HTML标签里的rel=canonical
最常见的形式,放在<head>里的<link rel="canonical" href="...">。要求是绝对URL(含协议和域名)、目标URL返回200状态码、不能指向被noindex的页。指向404、301、noindex的canonical会被Google直接忽略,且GSC会在覆盖率报告里抛错。
HTTP Header里的Link rel=canonical
非HTML资源(PDF、图片、视频)无法在文档里写<link>,这时用HTTP响应头里的Link: <https://example.com/main>; rel="canonical"声明。这是PDF白皮书最容易被忽略的一处:你的研究报告PDF被无数站点直接热链时,Header canonical能把权重归回原始页面。保哥手头一个B2B SaaS客户靠这一招把行业白皮书的引用权重从0%回收到了约35%。
sitemap.xml里的隐含信号
sitemap里出现的URL,Google视为站长认可的“应该被索引”版本——是一种弱canonical暗示。如果你的sitemap里只放主URL不放变体,Google更可能选主URL当规范版。反过来,sitemap里混入了带参数的URL或者老URL,会给Google错误信号。电商分面导航导致sitemap污染是最常见的失误之一。
内链流向与重定向链信号
站内绝大多数内链指向哪个URL,Google会把它当成默认主版本信号。你嘴上说canonical指A,但全站90%的内链都指向B,Google会困惑——通常会权衡内链信号更重。301重定向也类似:如果A 301到B,那么B事实上是A的canonical,即便你在某个孤立位置宣称canonical指向A,也会被覆盖。
内容相似度的自动判定
Google自己跑一套近重复检测算法——把多个URL的主内容(去掉模板的真正不同部分)做指纹化对比,相似度高于阈值的会被聚成一个cluster,然后从cluster里挑一个canonical。这套自动判定与你声明的canonical并行运行,两者一致时收敛,不一致时就是被忽略的高发场景。
把这5类信号合并理解后,你就知道为什么单写<link rel="canonical">常常不够——你得把sitemap、内链、重定向、内容差异同时往一个方向调整,五个信号一致时canonical才稳定生效。
自指canonical到底该不该写?什么场景必须写?
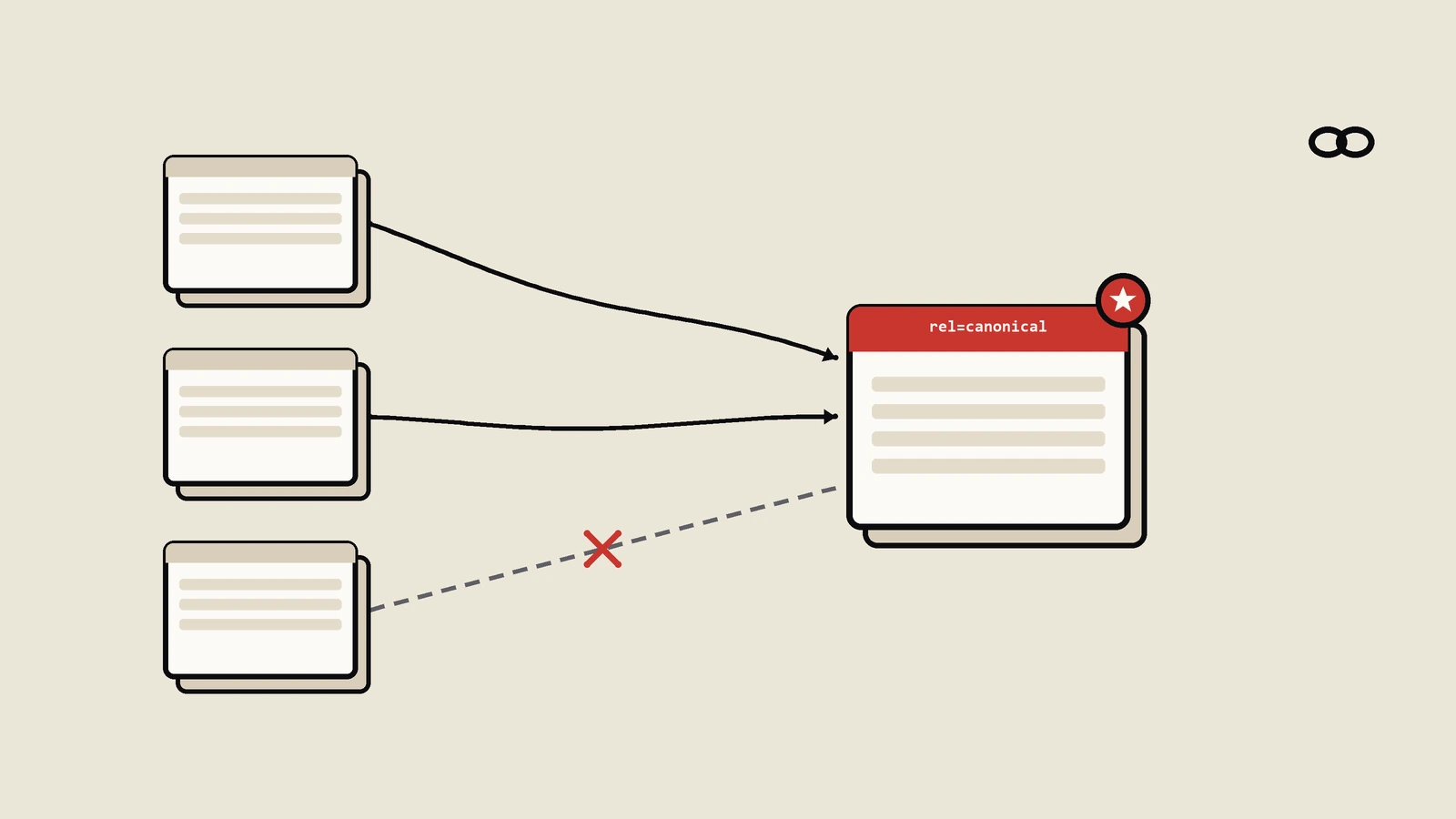
自指canonical(self-referencing canonical)是https://example.com/page的页面里写<link rel="canonical" href="https://example.com/page">。从字面看像废话——指向自己有啥用?但这件事强烈建议默认全站开启,几乎零成本。
self-referencing起源与争议
早期SEO圈对自指有过争论:有人认为多此一举,Google默认就会把页面自身当canonical。后来Google官方明确表态:推荐写自指canonical,因为它能挡住带参数的URL变体(追踪参数、社交分享UTM、内部测试参数)被当成不同URL处理。自指相当于给Google一个权威锚点:不管你怎么带参数访问我,主版本就是这个干净URL。
5种自指必须写的场景
第一类是带UTM追踪的入口页——营销活动一带就是几十种参数组合,自指能把全部回归到主URL。第二类是有用户排序/筛选的列表页——主URL自指、子参数页指向主URL,体系清晰。第三类是会被社交平台改写的页面——Facebook、Twitter、LinkedIn分享时常常带fbclid、__hssc等参数,没有自指会污染。第四类是同站多模板版本(打印版、AMP版、移动版)——主版本必须自指明确身份。第五类是任何被反向链接的页面——你没法控制外站怎么链你,自指能挡掉被链接URL的怪异变体。
2种自指不必要的场景
第一类是动态搜索结果页(站内搜索)——本身就不该被索引,用noindex而不是canonical。第二类是已经用301跳走的旧URL——你都跳走了,canonical无意义,且会和301信号互相干扰。除这两类,默认全站开启自指基本零风险高收益。
跨页canonical 8种典型场景该怎么选?
跨页canonical是真正的工作量所在——指向不是自己的URL。这一节展开8类实战场景,每类给出决策依据。
排序筛选与分页参数收口
电商类目页是最大场景。/category?sort=price-asc、/category?color=red、/category?page=2这类参数变体如果都被索引,等于把权重分散到几十个近重复页。决策:全部参数化变体指向干净的主类目URL。但分页(page=2以上)是个例外——按2024年共识,分页页不应该canonical到第一页(那是早期Google建议、2019年已撤回),让分页自指、靠内容自然差异和内链区分。
移动版m.子域名(已逐步弃用)
2010年代很多站做了m.example.com独立移动站,这时主域desktop页用canonical指自己,移动版m页用canonical指主域desktop页,并配上rel="alternate"双向声明。2018年Google宣布移动优先索引后,新建站基本都改用响应式或动态服务,m.子域逐渐成为遗产架构。但很多老站还在用,迁移成本高,这套canonical-alternate对位是核心保权重手段。
跨语言区域版本与hreflang协作
多区域多语言站常见误用:把所有区域版本都canonical指回en-US主版本。结果是hreflang整套失效,因为每个区域版本应该是canonical指自己、用hreflang声明对位关系。国际化SEO与hreflang完整指南里详细拆过这个头号杀手,这里只提结论:跨区域用hreflang,canonical让每个区域版本自指。
联合发文syndicated content
媒体行业经典场景:原创新闻网站把文章授权给Medium、Yahoo News、商业转发平台,转发方写<link rel="canonical" href="原始URL">指回源站。这是跨域canonical最合规也最成熟的用法。Forbes、TechCrunch、Inc.com这些大站都接受作者把内容同步到自家专栏页,关键是转发方主动设canonical指回作者域,源站才能保住排名信用。
跨域转载防御
不是合作的转载——别人爬走你的内容挂他自己的站。这种情况下你没办法让对方加canonical指回你。防御手段不是canonical,而是抓快(Google索引你的版本早于对方)、原始发布时间戳、内链流量基础。canonical在这一场景里是“对方愿意配合时的合规工具”,不是“反盗版武器”。
PDF与打印版收口
同一份白皮书既有HTML网页版又有PDF下载版,PDF应该用HTTP Header的Link canonical指向HTML版。这样PDF被外部直接热链时,反链权重归到HTML页面。打印版页面(?print=1)类似处理,canonical指向标准阅读版。
同内容多URL收口
CMS常见问题:一篇文章既挂在/blog/路径又挂在/news/路径,产生两个完全相同的URL。这种情况第一选择是301合并(物理上消灭一个URL),但如果业务上两条路径都要保留(比如导航栏入口都要),用canonical把次要路径指向主路径。
AMP与移动加速页配对
AMP页(/amp/article-slug)与主页面(/article-slug)是典型pair:AMP页canonical指向主版本,主版本用<link rel="amphtml">声明AMP版位置。2021年后AMP在Top Stories里的特权被取消,新建站很少做AMP,但既有AMP站这套对位是保权重关键。
跨域canonical真的能传权重吗?合规vs风险
跨域canonical是canonical里最被滥用也最被低估的子集。“跨域”是指canonical指向不同域名,本质上是声明“我这个域上的这个URL,内容版权和搜索权重应归属另一个域”。
跨域canonical的机制与限制
Google确实支持跨域canonical,但实际生效率比同域canonical更低——因为跨域风险更高,Google会更严格地用内容相似度算法做二次校验。如果两个跨域URL内容差异超过阈值(比如转发方加了大段评论、广告、相关推荐),Google会忽略跨域canonical,把两个版本都索引。
合规场景:内容辛迪加syndication
最稳的合规用法是商业转载授权:原创站发表后,授权媒体伙伴整篇转发,转发方在<head>里写canonical指回原始URL。Google的Search Quality Rater Guidelines里专门写了这种情形——原创署名应当传递到转发方,搜索结果里通常显示原始站。前提是转发方真的把<link rel="canonical">放对位置,而不是只在文末加一行“转载自XX”。
合规场景:品牌跨站与多品牌矩阵
大集团旗下多品牌站之间内容互通也常用跨域canonical。比如美妆集团旗下A品牌站和B品牌站共用一套教育内容(护肤知识库、成分百科),这种共用内容选一个站当主版本、其他站canonical指过去。比每个站各自重复发更稳——既挡住了内部站点之间的内容相似度检测,又把权重归集。
风险:被竞品挂canonical偷流量
反向场景是真实存在的:有人用爬虫复制你的内容,然后在自己的站上挂canonical指向他自己的URL(而不是你)——这是单向操作,他不需要你配合。理论上Google会因为内容相似度判断他不是原创而忽略,但实战里如果对方的站权重比你高、或者你的站抓快慢于他,Google可能选他的URL当canonical。保哥手头一个B2B SaaS客户2023年遇到过类似问题:技术博客的几篇核心文被对手镜像、对手挂canonical到自己域,GSC里看到“Indexed, but not selected as canonical”——一查Google-selected canonical指向了对手。处置是:加强首发时间戳证据(Schema里写datePublished)、内部加密水印、向Google提交DMCA下架请求,三个月后逐步纠正。
canonical为什么会被Google忽略?6大原因诊断
“我加了canonical为什么Google没采纳”是技术SEO咨询里最高频的问题之一。归因到6大原因,逐项排查就能定位。
内容根本不重复——Google自己判断
最高发原因。你以为两个页面重复所以加了canonical,但Google通过内容相似度算法判断它们其实差异显著(标题不同、主体段落不同、产品attributes不同),所以忽略你的canonical把两个都索引。处置方向是先确认两个页面是否真的重复——如果真重复但Google误判,补强内容相似度信号(让模板差异变小、主体内容一致);如果其实不重复,撤掉canonical让两个页面各自存在。
canonical链与循环
A canonical到B、B canonical到C、C又canonical回A——形成循环。或者A canonical到B、B canonical到C、C canonical到D——形成链。Google对canonical链有忍耐上限(通常2-3跳),超过会全部忽略。处置是审计后让所有非主URL直接指向最终主URL,不要中转。
多个canonical标签共存
页面<head>里出现两个不同的<link rel="canonical">(比如CMS主模板和插件各加一个、JS渲染时又注入一个),Google遇到这种冲突会全部忽略。常见在WordPress装多个SEO插件或Shopify主题与SEO app冲突时。处置是审计所有产生canonical的源头,只留一个。
与noindex矛盾
页面同时声明canonical指向某主URL和meta robots noindex,Google会判断你既想合并又不想索引——通常优先noindex,canonical失效。处置是想清楚意图:想合并权重用canonical(去掉noindex),想让本页消失用noindex(去掉canonical,因为合并目标本身就该被索引)。
与hreflang互相否定
多区域站常见:en-US版canonical指向en-CA版,但hreflang又声明en-US和en-CA是两个独立区域版本。Google面对这种自相矛盾会忽略canonical,优先hreflang保持区域分立。处置是确认区域策略——如果真的独立,canonical让每个区域自指;如果其实是同一内容仅区域营销差异,合并到一个区域版本+301其他变体。
与内链/sitemap/重定向信号反向
canonical指向URL-A,但站内90%的内链指向URL-B、sitemap只放URL-B、URL-A还301跳到URL-B——Google会按多数信号选URL-B当canonical,忽略你的声明。处置是把5类信号统一调整到同一目标URL,不能光靠canonical孤军作战。
canonical与sitemap/hreflang/noindex怎么协同?
这四个工具的协同矩阵是技术SEO的核心地基。错配比单独错用更危险——单独错用是局部问题,错配会让整个区域板块的索引混乱。
不矛盾时各司其职
正常情况下,canonical管“哪个是主版本”、sitemap管“我推荐你抓哪些URL”、hreflang管“这个URL在其他语言/区域的对位版本”、noindex管“这个URL不要进索引”。四个工具职责清晰、互不冲突。常见正确配置:主URL自指canonical、放入sitemap、声明hreflang对位、不带noindex。
矛盾时Google的优先级
当信号冲突时,Google的优先级大致是:noindex > 301重定向 > 内容相似度自动判定 > 内链流向 > sitemap > canonical声明。理解这个顺序对诊断“canonical为什么没生效”很关键——你的canonical信号在所有信号里其实是较弱的一环,被任何更强信号覆盖都会失效。
5步协同清单
第一步:确认每个URL的index意图(进索引还是不进),进的用canonical自指+放入sitemap+不加noindex,不进的用noindex+不放sitemap+不需要canonical。第二步:确认重复关系,真重复的次要URL用canonical指主URL,不重复的各自自指。第三步:确认跨区域关系,区域版本各自自指+互相hreflang对位,不要跨区域canonical。第四步:确认重定向链,任何301链路上的URL不应该出现canonical到链外URL。第五步:确认内链与sitemap指向与canonical一致,不一致先调整内链和sitemap而不是反复改canonical。这五步过一遍,90%的canonical误配能解决。
canonical错配怎么诊断?GSC加抓取审计4步实战
诊断的核心是验证Google到底接受了什么canonical,而不是验证你声明了什么canonical。这两件事是两码事。
URL Inspection看Google选了谁
GSC的URL Inspection工具是最直接的判断手段:输入任一变体URL,看Coverage部分的两行——User-declared canonical(你声明的)和Google-selected canonical(Google实际选的)。两者一致=Google接受你的声明,两者不一致=Google忽略了你的声明、用了它自己的判断。不一致时,看Google-selected指向哪里,然后沿着6大原因逐项排查。
GSC索引覆盖canonical错配指纹
覆盖率报告里有几个状态专门反映canonical问题:“Duplicate without user-selected canonical”=你没声明canonical,Google自己选了一个;“Duplicate, Google chose different canonical than user”=你声明了但Google选了别的;“Alternate page with proper canonical tag”=Google接受了你的canonical,本URL作为变体被合并。每周看这三个状态的URL数量趋势,涨幅大就要查。
抓取工具批量验证
Screaming Frog、Sitebulb或Ahrefs的Site Audit跑全站,导出“canonical指向”列表。批量过滤几种异常:canonical指向404/301/noindex的URL、canonical循环或链、多个canonical标签共存、相对URL写法(必须绝对URL)、canonical指向非同协议(http指https或反向)。这一轮过完能挑出绝大多数声明层错误,然后才有意义去GSC验证Google侧接受度。
案例:DTC出海客户迁移后canonical全错
2024年保哥接手一个DTC出海家居客户的诊断,他们刚做完Shopify到Shopify Plus的换主题迁移,流量掉30%。GSC URL Inspection随手查几个产品页,全部显示“Google chose different canonical”——Google把产品页的canonical选成了主类目页。深挖原因是新主题模板里产品页的canonical标签写错了相对URL,且全部硬编码指向类目页(模板开发者把这当成了某种“权重归集策略”)。修复路径:第一步纠正模板里产品页canonical指向自身URL(self-referencing);第二步重新提交sitemap触发重新抓取;第三步GSC逐批Request Indexing核心SKU。三周后流量回升80%,六周完全恢复。这一案例之后,团队更确信一件事:技术SEO问题里,canonical误配的破坏力被大多数团队严重低估,因为它不像404那样显眼,但能让整个站的权重分配长期错乱。
AI检索时代canonical还重要吗?
2024年AI Overviews、Perplexity、Claude等AI检索接入Google索引,canonical信号有了新的下游消费者。
LLM训练抓取与canonical信号
GPTBot、ClaudeBot等LLM训练爬虫的抓取策略目前看是不完全尊重canonical——它们抓的是URL级原始内容,不像Google索引会做canonical合并。这意味着如果你的内容有多个URL副本(参数版、转载版),LLM训练数据集里可能同时存在多份。后果是:AI回答引用你的内容时,可能引用任意一个URL变体,而不是你希望的主版本。
内容指纹与canonical的双轨
对策是双轨并行:第一轨继续按搜索引擎canonical规范做(让Google把权重归集到主版本),第二轨在内容本身加入显式品牌标识与原始URL声明(JSON-LD的sameAs、url字段、文章footer明确“本文原文链接为...”),让LLM抓取时即便没尊重canonical,也能从内容文本里识别原始来源。这一层是JS渲染与SEO那篇里反复强调的同一逻辑:重要信号别只放一处,多通道冗余声明。
常见问题解答
canonical标签是不是排名因素?
不是。它是一个合并信号,告诉Google哪个URL是规范版本,让重复或近重复页的权重归集到主版本。它不会给单页加分,也不会扣分,但用错会让权重分散、错的URL被选成规范版反而拖累流量。
canonical和301重定向该用哪个?
用户和搜索引擎都能正常访问、希望多个URL都保留为可访问入口,用canonical(参数页、排序、追踪链接);页面应该永久消失或归并到唯一URL、不需要旧URL存在,用301。canonical保留多版本,301合并为一份。
自指canonical是必须写吗?
建议每个可索引页都自指,虽然不是强制,但能挡住Google把带追踪参数、用户分享链等变体当成不同URL处理。技术成本几乎为零、收益是稳定的规范信号一致性,值得当成基础设施全站默认开启。
canonical写了为什么还是不生效?
六大原因里最常见的是Google判断两个页面内容不够相似(不重复),所以忽略你的canonical指向。其次是canonical链/循环、与noindex冲突、与hreflang互否、多个标签共存、内链与sitemap信号反向。
跨域canonical真能传权重吗?
可以但有条件:必须是真正的同一内容(媒体辛迪加常见),源站和目标站都需要技术配合,且Google保留忽略权(看相似度+其他信号)。被竞品挂跨域canonical偷流量是真实风险,需要每周监控反向canonical指向自己的站。
GSC怎么看Google到底选了哪个URL当canonical?
用URL Inspection工具输入任一变体URL,看Indexing部分的User-declared canonical(你声明的)和Google-selected canonical(Google实际选的)。两者不一致就是被忽略,沿着六大原因逐项排查。
权威参考资料
本文标题:《canonical标签到底怎么用?8种跨页场景与冲突诊断》
本文链接:https://zhangwenbao.com/canonical-tag-mechanism-cross-domain-self-conflict-diagnosis.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0