自夸式榜单被Google点名后怎么办?合规GEO改造实战

本文目录
- 什么是自夸式榜单,为什么这两年这么火?
- 2026年1月到底发生了什么?
- Google为什么现在才动手?
- 为什么“自我排第一”会被算法识别出来?
- 这件事会不会连累我的AI可见性?
- 更扎心的是:你引用了自家榜单,AI却把客户推给了竞品?
- FTC那条法律红线到底在哪里?
- 规则的核心禁令有哪些?
- 合规红线具体怎么判?
- 算法打击加上FTC监管,叠加成什么样?
- 不靠自夸式榜单,还能怎么做GEO?
- 策略一:争取第三方独立评测
- 策略二:发布真实的对比研究
- 策略三:投资原创研究内容
- 策略四:建立话题权威
- 策略五:强化结构化数据
- 怎么自查自己的站点有没有踩雷?
- 一篇高风险榜单,具体怎么一步步改造成合规对比?
- 三个真实的内容改造对照案例
- 竞品还在用、暂时没被打击,我该观望还是先改?
- 一套2026年合规GEO内容工作流
- 给出海品牌的特别提醒
- 常见问题解答
- 品牌在自己的博客写产品对比文章算违规吗?
- Google会惩罚所有包含best关键词的文章吗?
- 已经发布的自夸式榜单应该怎么处理?
- 互推联盟“你推我、我推你排第一”安全吗?
- 自夸式榜单被打击,是不是意味着GEO已死?
- 下线和301跳转该怎么选?
- FTC的合规披露声明应该怎么写?
- 竞品还在用自夸式榜单,我可以举报吗?
- 权威参考资料
摘要:2026年1月开始,一批SaaS和B2B品牌的自然流量在几周内掉了三到五成,掉得最狠的恰恰是堆满“最佳XX”自夸式榜单的blog、guide、tutorial子目录。Google今年没承认任何更新,但信号已经很清楚:把自家产品排第一、又拿不出独立测评证据的内容,正在从流量捷径变成负资产。叠加美国FTC那条可按每页罚53088美元的消费者评论规则,这条赛道是算法和监管双杀。这篇讲清它为什么被算法识别、会不会连累AI可见性、FTC红线在哪,以及第三方评测、原创研究、话题权威等5条合规且可持续的替代路径和3个真实改造案例。
你发布过“最佳XX工具推荐”这类文章,而且把自家产品排在了第一名吗?如果有,这篇值得认真读完。2025年,这种自夸式榜单是GEO(生成式引擎优化)领域最火的流量打法,没有之一——数据显示ChatGPT引用的网页里约44% 是“best X”格式的榜单。一篇“2025年最佳XX工具”把自己排榜首,就能同时在Google搜索结果和AI生成答案里拿到大量曝光,简单粗暴、立竿见影。
但2026年1月开始反转。多位资深SEO研究者在跟踪1月那波流量震荡时发现了一个高度一致的模式:受冲击最重的,是大量依赖自夸式榜单的SaaS和B2B品牌,它们的有机可见性在几周内下跌30% 到50%,而且损失高度集中在blog、guide、tutorial这几个子目录——那里正是这类“best”内容堆得最密的地方。与此同时,美国联邦贸易委员会的消费者评论规则已经生效,这类自吹自擂的伪评测可能面临每次违规高达53088美元的罚款。算法风险加上法律风险,游戏规则正在被彻底改写。
什么是自夸式榜单,为什么这两年这么火?
自夸式榜单(Self-Promotional Listicle)指的是:品牌以“最佳”或“Top10”这类评测形式发内容,却在榜单里把自家产品或服务排在第一。表面是独立评测,本质是披着评测外衣的营销软文。
典型操作很有套路:在自家博客发一篇“2026年最佳项目管理工具”,列8到10个竞品但把自己排第一,对竞品的描述要么蜻蜓点水要么刻意弱化,用一套自编评分体系确保自己得分最高,标题再加上年份制造新鲜感。它之所以流行,是因为结构上天然适合被机器提取——有序列表好解析、“best”类查询搜索量巨大、AI回答“最佳XX推荐”时又会优先引用这种结构化榜单。从2024到2025年,这类内容以接近每月15% 的速度增长,到2025年底成了内容营销行业最普遍的GEO战术。
背后的焦虑是真实的:行业普遍预期未来几年品牌从传统搜索拿到的流量会大幅缩水,于是大量品牌把GEO当救命稻草,而自夸式榜单当时看起来就是ROI最高的捷径。2025年甚至有专门的“自夸式榜单工业化生产”主题分享,传授怎么用AI批量生产。问题是,当一个套路全行业都在用,它就不再是套路,而是噪音——这种集体行为本身,已经预示了它的快速贬值。
2026年1月到底发生了什么?
2025年12月那次核心更新结束后,2026年1月整月搜索结果持续震荡。Google今年并没有官宣或确认任何更新,但时间点和一批知名SaaS、B2B品牌的陡峭可见性下跌高度吻合。研究者对受影响站点做系统比对后,几个特征反复出现,值得逐条看。
第一,跌幅集中在三类子目录。损失不是全站均匀分布,而是密集压在blog、guide、tutorial这些子目录,因为自夸式榜单恰恰最爱挂在这些路径下。这个“按子目录塌方”的特征,本身就是诊断信号——如果你的掉量也呈现这种结构,基本可以对号入座。第二,多数站点把自己排在第一。受影响样本里压倒性多数都是“自家产品在榜首加上对竞品描述失衡加上没有可验证测评方法论”,三个特征叠加。第三,大量文章只是把标题里的年份刷成了2026,正文几乎没有实质更新——用伪造的“新鲜度”信号去骗重新抓取,这个动作现在不仅没用,反而像是在主动举手告诉算法“我这是为排名而不是为用户写的”。
还有一个容易被忽略的点:自夸式榜单大概率不是唯一诱因。很多受影响站点同时还有内容快速规模化、自动化生产、激进的按年份批量翻新等其它算法风险因素。但在跌得最惨的那批站里,“自我排名第一”的内容如此一致地出现,强烈暗示这个信号在规模化场景下的权重被调高了。换句话说,它未必是压垮骆驼的唯一稻草,但它是那根最显眼、最容易被识别的。
Google为什么现在才动手?
有三层原因叠在一起。其一,规模效应触发了阈值。AI写作工具普及让这类内容的生产成本趋近于零,数量爆炸式增长,当一个策略被大规模滥用,就会进入反垃圾团队的视野。其二,搜索质量被严重破坏。用户搜“best project management tool”,前十全是不同品牌的自吹自擂,根本得不到有用参考,这直接损害Google的核心产品体验。其三,AI生态的连锁污染。Google的搜索结果是很多大语言模型的数据源,索引被低质自推广榜单污染,AI答案质量也会被同样的垃圾拖累,Google必须在源头治理。这其实是同一波核心更新里更大叙事的一部分——把流量从内容农场和聚合式套路,重新分配给真正有第一手价值的来源,这个方向上聚合站掉量、品牌站上涨的机制,和核心更新里聚合站掉量、原创品牌站上涨的原因是同一条逻辑线。
为什么“自我排第一”会被算法识别出来?
这一层是很多人没想透的机制,单独讲清楚。Google对“评测”类内容有明确指导:高质量评测应当体现第一手使用经验、原创性、以及有评估过程的证据。自夸式榜单几乎必然在这三点上同时缺失——没有真实测试竞品的第一手经验、评分体系是自编的没有原创方法论、也拿不出独立评估的证据。再叠上一条:内容暗示自己是客观评测,却没有披露发布方就是被排第一那家的利益关系。
把这几个特征合起来,算法要判别的其实不是“这篇有没有best这个词”,而是“这篇内容是为用户写的,还是为排名写的”。判别的抓手非常具体:自家在榜首、对竞品描述系统性失衡、缺可验证方法论、无利益披露、靠改年份刷新鲜度。任何一条单独出现也许还好,全部叠在一起,就是一个非常清晰的“为排名而非为用户”的指纹。这也解释了为什么有的站只有十来篇这类内容也照样掉——识别靠的是本质意图特征,不是单纯靠数量。算法层面这套判定,和有用内容系统对“为搜索引擎而非为人创作”的打击是同源的,被波及之后怎么系统恢复,可以参照有用内容系统掉量后怎么恢复那套机制诊断思路。
把这套判别落成一张可对号入座的表,比凭感觉判断靠谱得多。同样是“含自家产品的对比内容”,下面六个特征一过,是负债还是资产基本就清楚了:
| 特征维度 | 自夸式榜单(高危) | 合规对比(资产) |
|---|---|---|
| 排序结果 | 自家几乎必然第一 | 按客观标准排,自家可能不是第一 |
| 评测方法 | 自编评分体系,不可复现 | 公开方法论,第三方能复现 |
| 竞品描述 | 系统性弱化、一笔带过 | 优缺点对称,含自家短板 |
| 使用证据 | 无真实测试截图与数据 | 有第一手使用证据 |
| 利益披露 | 无,或藏在页脚不可见处 | 开篇显著位置明确披露 |
| 更新方式 | 只改标题年份,正文不动 | 有实质内容更新与复测 |
判断口诀就一句:六个维度里只要有三个落在左列,这篇就是高危负债,不管它现在排名多好——排名好只是还没轮到它被清算而已。
这件事会不会连累我的AI可见性?
会,而且这是整个故事里最反讽的地方。自夸式榜单这套打法,初衷恰恰是为了在AI答案里拿到曝光(GEO)。但很多AI搜索引擎大量依赖Google的搜索结果作为数据源——研究者的判断很直接:这些在Google自然结果里的下跌,大概率会同步影响它们在那些借用Google结果的大语言模型里的可见性。
于是形成了一个闭环式的自伤:你为了AI可见性去做自夸式榜单,榜单被Google算法降权,而AI又依赖Google的排名,结果你的AI可见性反而因为这个策略本身被打击而下降。它要解决的问题,被它自己制造的风险放大了。这也提醒一件事:GEO不等于自夸式榜单,把内容做到能被AI引用、却始终换不来品牌被推荐,本身是另一个独立课题,AI只引用内容却不推荐品牌怎么破那篇专门拆过它,和本文是“别用错战术”与“战术之外怎么真正被推荐”的关系。
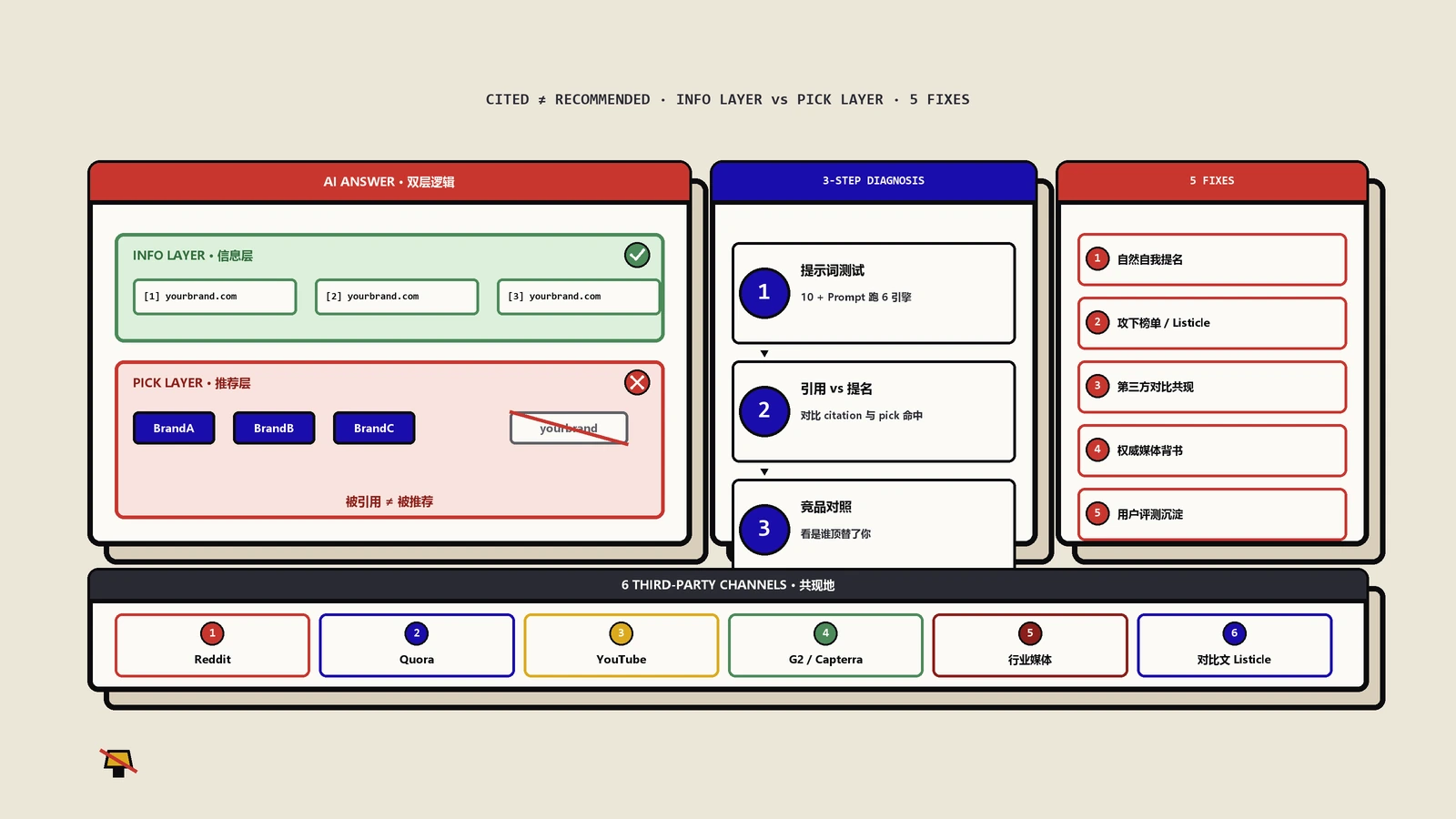
更扎心的是:你引用了自家榜单,AI却把客户推给了竞品?
合规风险还只是明面上的账,自夸式榜单在AI搜索里藏着一笔更亏的暗账。业内有一份针对100个B2B“best软件”类查询的实测,覆盖了4月到6月三个时间点,专门盯着这些“自己写自己排第一”的榜单在AI概要里的命运。结论让不少品牌方后背发凉:当这类自家榜单被AI概要引用时,约69%的情况下,AI压根没推荐写榜单的这个品牌本身,反而把榜单里顺手列出来的竞品给推了出去。
举个实测里的典型场景。一个做在线学习系统的品牌,写了篇“最适合卖课的LMS”榜单,自然把自己摆在第一,后面礼节性地列了几家同行。结果AI概要确实引用了这篇文章当来源,可它转头推荐给用户的,是榜单里那几个被你拿来当陪衬的竞品,写榜单的你反倒被晾在一边。你以为自己在主场带节奏,实际上是给对手开了场免费推介会。
问题的根子,在于很多人把被引用和被推荐当成了一回事,其实差着十万八千里。被引用只说明你的内容被系统当成了一条信息来源;被推荐才意味着系统愿意把生意往你这边导。在这套机制下,已经是品类龙头、被第三方反复提及、外链更扎实的品牌,天然更容易站上推荐位——而你那篇自夸榜单里列出的竞品,往往恰恰是这些龙头。等于你用自己的内容,给对手的权威性又补了一刀。
那份实测里还有两个数字值得记下来。一是这些自家榜单被引用了好几百次,但其中相当大一部分都是“被当来源引用了、却没被推荐”的尴尬状态;二是一批重度依赖自夸榜单策略的B2B品牌,自然可见度掉了30%到50%,赶上核心更新之后还在接着往下走。引用量的虚假繁荣,掩盖不了推荐位上的节节败退。
保哥的判断很直接:自卖自夸的榜单,本质上是花钱花精力写了一篇给竞品导流的软文,两头不讨好——FTC那边嫌你拿自控内容冒充独立评测,AI这边嫌你不可信、顺手还把你的潜在客户分给了对手。要破这个局,要么干脆别自评,把“best某某”这类榜单让真正中立的第三方去写;要么写就写成对自己也敢挑刺的真对比,敢承认自己在哪些场景不如别人,反而更可能让AI觉得这份清单可信到值得连你一起推出去。说到底,能被AI推荐的从来不是嗓门最大的那个,而是看上去最不像在自卖自夸的那个。
FTC那条法律红线到底在哪里?
除了算法风险,自夸式榜单还踩着一个很多出海品牌完全忽视的雷——美国联邦法律风险。2024年10月21日,FTC的《消费者评论和证言使用规则》(16 CFR Part 465)正式生效,直接针对在线评论和推荐中的欺骗行为,多条规定与自夸式榜单高度相关。
规则的核心禁令有哪些?
核心禁令有四类:创建、购买或传播虚假评论(未实际测试竞品却发布评测内容);把公司控制的内容伪装成独立评论(品牌在自有博客发看似客观的“最佳榜单”);内部人员撰写评论却不披露关系(员工写把自家排第一的评测);有条件的激励评论(互推联盟里互相排第一的安排)。FTC有权对每次违规处以最高53088美元的民事罚款,而且“每次违规”可以按每个页面单独计算——一个发了200篇自夸式榜单的品牌,理论最大罚款能到千万美元量级。监管已经形成了明确的执法信号,不再只是纸面规定。
合规红线具体怎么判?
并非所有含自家产品的对比内容都违规,关键看三条。风险升高的情形:内容暗示客观性却在推广自有产品、评测不基于真实使用体验、未清晰披露评测者与被评品牌的利益关系。相对安全的做法:明确标注“本文由某品牌发布”、提供可验证的测试方法论、在显著位置披露利益关系、基于真实使用体验撰写。在该规则正式落地前,已有公司因发布数百篇“最佳榜单”把自家排第一、同时在第三方平台用伪造评论,被美国商业改进局公开谴责——没有直接罚款,但被列入负面记录后,B2B客户在尽职调查阶段会直接淘汰这个供应商,这种声誉损害比罚款更难恢复。需要说明的是,这里讲的是合规思路而非法律意见,真要动这类策略,务必先咨询专业法律顾问。
算法打击加上FTC监管,叠加成什么样?
把两类风险放一起,自夸式榜单面对的是一个四层叠加的局面,而且这四层是叠加不是互斥:
| 层级 | 伤害 | 典型表现 |
|---|---|---|
| 第一层 | Google算法降权 | 有机可见性大幅下降,直接损失搜索流量 |
| 第二层 | AI可见性连锁下跌 | 依赖Google结果的大语言模型同步减少引用 |
| 第三层 | FTC合规风险 | 即使侥幸逃过算法,法律合规问题随时可能成为监管目标 |
| 第四层 | 品牌信誉损伤 | 用户发现“客观评测”全是自说自话,E-E-A-T评价根本性受损 |
一个不主动改策略的品牌,理论上会在两三年内完整经历这四个阶段——先是Google排名下降,再是AI引用减少,再是潜在的FTC调查,最后是用户信任崩塌。正是这种叠加伤害,决定了正确的应对不是“再观望一下”,而是立刻停止生产、启动改造。
不靠自夸式榜单,还能怎么做GEO?
如果这条路堵了,品牌该往哪走?下面五条是可落地、且不会被算法和监管双杀的替代路径,每条都给到“做什么、怎么验证”。
策略一:争取第三方独立评测
这是目前最有效的路径。当权威平台在它自己的独立对比里提到你的产品,这种引用在AI系统眼里的权重远高于自我推荐。做法:主动给行业媒体提供产品测试机会、在第三方评价平台积累真实用户评价、向行业权威网站投稿客座文章、和科技媒体记者建立长期关系。这类引用的获取周期通常6到12个月,需要持续投PR预算,但护城河一旦建立,收益可以持续数年不衰减。怎么验证:跟踪权威来源对你品牌的提及数量、以及这些提及是否开始出现在AI答案的引用来源里。
策略二:发布真实的对比研究
如果确实要发含自家产品的对比,做到五点:公开测试方法论、提供真实使用证据(截图与数据)、客观呈现优缺点(包括自家不足)、在文章开头显著披露利益关系、尽量引入独立测试人员或行业专家。这种“诚实对比”做得好不仅不被打击,反而会因质量高拿到高排名和高引用。怎么验证:改造后跟踪这些页面3个月内的搜索表现和被AI引用的频率,对比改造前的曲线。
策略三:投资原创研究内容
行业报告、调查数据、原创分析天然具备E-E-A-T要求的权威性,AI对这类高信息密度内容的引用率远高于模板化榜单。最高效的形式是年度行业报告——每年发一份覆盖某垂直赛道的权威数据,把自己做成行业认知里的“基准”。这类内容怎么进一步强化权威信号、拿到稳定的AI引用,可以对照怎么强化E-E-A-T信号拿到AI引用那套清单逐项落地。怎么验证:看报告发布后是否被同行、媒体、以及AI答案反复引用为数据源。
策略四:建立话题权威
与其写100篇浅层榜单,不如在一个垂直领域深耕10篇真有深度的内容。Google和AI都在向话题权威倾斜——谁在某领域提供了最全面专业的内容集群,谁就被优先引用。方法:用关键词工具圈定一个垂直话题的全部子话题,按重要度排序,每月产出2到3篇深度文章覆盖核心子话题,12到18个月形成内容护城河。怎么验证:跟踪该话题集群整体的自然流量与引用占比,而不是单篇排名。
策略五:强化结构化数据
确保内容用了正确的Schema,帮AI更精确理解你的内容、提高被引概率。但要清醒:结构化数据是“正确做法的放大器”,不是“错误做法的遮羞布”——内容本身没价值,再完美的Schema也救不了。优先部署Article、HowTo、FAQPage,评测类内容用Review时必须如实标注作者身份。怎么验证:用富媒体测试工具确认标记无误,并观察对应内容在AI答案里的抽取是否更准。
怎么自查自己的站点有没有踩雷?
不确定的话,先用一条Google搜索命令快速体检:用site限定到你的域名下blog路径,再用intitle限定best,加上带引号的“1. 你的品牌名”。如果返回结果多,说明你站上把自己排第一的榜单内容不少,风险已经在累积。
进阶动作是数据驱动的审计:用Ahrefs或Semrush导出过去24个月所有blog文章的排名数据,按月对比2026年1月之后的变化,跌幅大于20% 的页面优先审计——大概率就是被识别为自夸式榜单的目标。再叠一个前面提过的子目录视角:把掉量按blog、guide、tutorial子目录分别聚合,如果某个子目录整体塌方而其它目录无恙,这个“按目录塌方”的形状本身就是强证据,比逐篇人工浏览高效十倍。审完按风险分三档:高风险(自家排第一加无披露加无方法论)、中风险(有自家产品但相对客观)、低风险,分档处置。
一篇高风险榜单,具体怎么一步步改造成合规对比?
前面反复说“改写为客观对比”,但到底怎么改,是最多人卡住的地方——多数人要么不敢动(怕一改排名全没),要么改得太轻(只加一句免责声明)。两个极端都不对。给一套可照做的六步,针对的是那种“内容本身有真实信息、只是排序和披露有问题”的页面(纯为排名拼凑、没有任何真实信息的,别改,直接下线更省事)。
第一步,把利益关系挪到开篇显著位置。不是页脚一行小字,而是标题下方第一屏就能看到的一段,写清发布方是谁、文中哪个产品是自家的。这一步成本最低、合规收益最大,先做。第二步,重做排序逻辑。把自编的、确保自己第一的评分体系,换成一个用户真正关心、且第三方能复现的标准(比如按某个公开可测的性能指标、或按特定使用场景的适配度),排完自家是第几就是第几——这一步是心理上最难的,但它恰恰是算法和监管同时在看的核心信号。第三步,补竞品的真实优点。把那些被一笔带过的竞品,按和自家同样的颗粒度写清楚它们强在哪,让对称性肉眼可见。第四步,加第一手使用证据。哪怕只是几张真实操作截图、一组可验证的实测数据,也比纯文字断言强一个量级,这是Google评测指南明确要的“评估证据”。第五步,把标题里的年份去掉或改成中性表述,停止用伪新鲜度去骗重抓——内容真有实质更新时,让更新本身去触发,而不是改个数字。第六步,留好改造留痕,记录改了什么、什么时候改的,方便后面判断恢复是不是这次改造带来的。
改造后最容易焦虑的是“怎么知道有没有用”。判断恢复是不是真的,别只看流量数字本身,要做区分:把改造页面的曲线和同站未改造、同样掉量的对照页面一起看——如果改造页开始回升而对照页继续躺平,才说明是改造起的作用,而不是大盘自己波动。Google重新评估通常要4到8周,这期间最忌讳反复改、反复观察,那样根本分不清是哪次动作的效果。改完就稳住,按4到8周的节奏,用对照组的方式读结果。如果一个周期后改造页和对照页一起趴着没动,说明这一页的问题不只在排序和披露,多半是内容本身就没有独立价值,那就别再抢救了,按下线处理。
三个真实的内容改造对照案例
抽象方法论不如真实案例好理解。下面三个是保哥实际跟踪的站点,时间跨度覆盖了从被算法打击、到主动改造、再到流量恢复的完整周期。这里只讲机制和方向,不写具体百分比——恢复幅度高度依赖品类和执行,给精确数字反而误导。
案例一,一家北美项目管理SaaS。2025年发了一百多篇自夸式榜单,每篇都把自家排第一。2026年1月后自然流量和AI引用同步陡降。它走的是三步改造:先对全部内容审计分级,高流量页优先、中流量延后、低质量页直接下线;再对优先改造的页面加详细利益披露、补真实测试数据、改为不把自家排第一的客观对比;最后在原有体系里新增一批深度技术文章建立话题权威。几个月后流量和引用都恢复到接近崩盘前的水平。这个案例的价值在于证明:算法降权可以靠主动改造恢复,但前提是快速行动加系统执行,拖着不动只会越陷越深。
案例二,一家出海跨境电商。两百多篇榜单覆盖各种工具品类,更新后流量明显下跌。它没有逐篇改,而是把所有自夸式榜单整体noindex处理,集中全部资源做一份年度行业报告。报告发布后几个月内成为该垂直赛道里AI答案的高频引用源,AI搜索带来的曝光反而超过了崩盘前。它的启示是:当历史包袱太重、无法逐篇改造时,把资源集中砸到一个权威级原创内容上,反而能更快建立新护城河。
案例三,一家中型B2B工业设备出海商。只发了20篇榜单,跌幅不算大但已触发警报。它的应对最彻底:20篇全部直接下线(404不做301),同时把内容策略整体转向第三方评测合作——拿出相当一部分原blog预算去推动权威评价平台上的真实评价积累,并主动给行业媒体和分析机构提供产品试用。半年后第三方评价数量大幅增长,行业媒体发了独立测评,分析机构在年度报告里提及了它。从“自卖自夸”转向“借势权威”,让它在GEO时代建立了远比榜单稳固的护城河。三个案例换三种打法,没有一招通吃,关键是按自己的历史包袱和资源选路径。
竞品还在用、暂时没被打击,我该观望还是先改?
这是收到最多的真实问题,背后是一个很自然的侥幸:既然竞品也在用、它也没全掉,那我是不是再等等看?这个观望诱惑必须正面拆掉,因为它本身就是最贵的决策。
先看观望的成本结构。算法这波是滚动的、不是一次性事件——它没有“更新结束”这个时点,而是随着评测系统的持续调整一批批波及。你今天没被波及,不代表安全,只代表还没轮到。观望期里你什么都没省,风险敞口一天不少地挂着,FTC那条按页计的罚则更是只增不减(你多留一篇、多挂一天,潜在违规计数就多一份)。也就是说,观望不是“零成本等信息”,而是“持续付费买一个迟早要还的风险”。
再看早改的结构性收益,这一点最反直觉、也最值钱。当算法在重新分配“best”类查询的流量时,这部分流量不会凭空消失,它会从被清算的自夸式榜单,流向那些做了第三方评测、原创研究、话题权威的合规玩家。换句话说,你的竞品在用自夸式榜单、且迟迟不改,对你恰恰是个窗口——它掉下来的那部分需求,谁先把合规内容铺好,谁就接得住。早改的人不只是“避免了损失”,而是在对手还在侥幸时,主动去接对手让出来的流量。这就是为什么这件事不是“风险管理”,而是“弯道超车”:观望者在等一个不会到来的“安全确认”,行动者在抢一个正在打开的再分配窗口。
给一个简单的决策口径:用前面那张六维判别表过一遍自己的内容,只要有页面落进“高危”档,就别观望,按风险分档立刻启动改造或下线;竞品改不改和你无关——它不改,是把流量让给你,不是给你一起拖的理由。唯一值得等的,只有“某一篇是真客观对比、只是披露没做好”这种轻症,那种补个显著披露即可,不需要伤筋动骨。
一套2026年合规GEO内容工作流
结合替代策略和实战,下面这套工作流可以直接作为团队内部SOP,分五个阶段。保哥团队跑这套流程九个多月,所有发布内容在历次算法波动中保持稳定,没有一篇遭降权。
| 阶段 | 关键动作 | 卡点 |
|---|---|---|
| 选题立项 | 明确:是否涉及自家产品对比、是否有真实数据或独家观点、是否需合规审查 | 涉对比的必须先过合规审查才能立项 |
| 写作与采集 | 凡竞品对比必须有可验证方法论和真实数据截图,凡引用必有原始链接 | 原创观点必须能溯源到真实经验或访谈 |
| 结构化优化 | 部署对应Schema,FAQ覆盖对话式提问变体,标题做截断测试 | Schema不能掩盖内容空洞 |
| 发布前审查 | 过自查清单:有无披露、有无真实证据、有无第三方来源、有无误导表述 | 每季度合规抽查一次 |
| 发布后监控 | 4周内盯展示量、点击量、AI引用频率、品牌提及 | 4周无表现就启动改写或推广 |
整套流程每篇内容大概要走两到三周,远比批量生产慢,但产出的每篇都是长期资产,而不是随时可能被清算的负债。慢,是因为它在给每篇内容上合规和质量的双保险。
给出海品牌的特别提醒
对中国出海企业,这个话题有额外紧迫性。其一,FTC的管辖覆盖任何面向美国消费者的商业行为,公司注册在中国、内容面向美国市场,照样可能被监管。其二,很多出海团队对FTC规则完全不了解,保哥在行业交流里发现,大量跨境电商和SaaS出海团队仍在大规模生产自夸式榜单,对法律风险毫无意识。其三,合规成本远低于违规成本——加披露声明、改透明评测方法论,执行成本几乎可以忽略,但一旦被盯上,罚款足以让初创公司破产。
最具体的两个动作:立刻在所有面向美国市场的blog文章顶部加固定的利益披露模块,写清发布方身份和潜在利益关系,这一个动作就能把合规风险降一大截;其次建立内部审查流程,新发布的对比类内容必须先过合规这一关,避免无意识踩雷。
常见问题解答
品牌在自己的博客写产品对比文章算违规吗?
不一定,关键在透明度和真实性。如果你明确披露了发布方身份、基于真实测试数据、客观呈现了所有产品(包括自家)的优缺点,这类内容在FTC框架下是合规的。问题出在那些伪装成独立客观评测、实际是营销软文的内容上。一个简单的自检:如果让独立第三方读这篇,他能不能立刻看出这是品牌方发布的?如果答案是肯定的,合规风险就很低。
Google会惩罚所有包含best关键词的文章吗?
不会。Google打击的不是best这个词,而是自推广意图过于明显、缺乏独立评测证据的内容。如果你是独立评测媒体、基于真实测试发布榜单,不在打击范围内。核心判别标准是“内容为用户服务还是为排名服务”——真正独立、有方法论的评测媒体的best榜单,排名一直很稳。
已经发布的自夸式榜单应该怎么处理?
分三步。第一步对所有best类内容审计分类。第二步对高风险内容加明确的利益披露、补真实测试数据、或改写为不把自家排第一的客观对比。第三步对无法改善的内容做noindex或直接下线,优先处理流量最高、曝光最大的页面。改造后的内容在Google重新评估周期(通常4到8周)后会逐步恢复,整站的E-E-A-T信号也会同步回升。
互推联盟“你推我、我推你排第一”安全吗?
这是2025年很流行但风险极高的做法。一方面,这种互推在FTC看来本质是一种有条件的背书,未披露互推关系可能构成欺骗性行为;另一方面,Google算法已经能识别这种链接农场式的互推网络,网络中一个节点被识别,整个网络的参与者都可能受牵连。建议立刻退出所有互推联盟,把PR预算转向真正独立的第三方评测。
自夸式榜单被打击,是不是意味着GEO已死?
GEO没死,死的只是GEO里一种有操纵性质的特定战术。通过第三方评测拿引用、投资原创研究、建立话题权威、优化结构化数据——这些合规打法不仅不会被打击,反而会因为竞争对手的自夸式榜单被清理而获得更大曝光空间。从某种意义上说,2026年1月这波,是合规GEO玩家的一次集体红利。
下线和301跳转该怎么选?
看内容性质。如果内容确实有价值、只是排序错误(自家排第一),应改写后保留URL,避免外链权重流失。如果内容本身没有独立价值、纯为排名而写,应直接404下线,不要301到主页或无关页面——Google对大量无关301有识别机制,乱跳会被解读为操纵信号。
FTC的合规披露声明应该怎么写?
核心是位置显著、内容明确、易于理解。位置上必须放在用户开始阅读内容前能立刻看到的地方(通常是标题下方或第一段)。内容上必须包含发布方品牌名、文中哪些是自家产品、是否有商业利益关系。语言上用普通用户能懂的表达,不要用法律术语包装。一个合规范例是:“本文由某某品牌发布,文中提及的产品X为本品牌自有产品,其余产品为第三方公开数据汇总,本品牌与第三方品牌不存在合作关系。”
竞品还在用自夸式榜单,我可以举报吗?
可以但要谨慎。Google接受垃圾内容举报,可通过Search Console的Spam Report提交;FTC接受消费者投诉,可通过其官方举报渠道提交。但更值得做的是把精力放在自家内容改造和合规GEO落地上——竞品早晚会被算法清理,主动改造的品牌才能在这波洗牌里弯道超车。
权威参考资料
本文标题:《自夸式榜单被Google点名后怎么办?合规GEO改造实战》
本文链接:https://zhangwenbao.com/self-promotional-listicles-ftc-google-crackdown.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0