Meta标签检测器怎么用?10项加权评分一次体检整页SEO
本文目录
- 为什么meta标签值得单独做一次体检?
- 检测器的算法核心:10项加权,不是简单打勾
- 逐项拆解:每一项怎么打分、扣在哪
- Title与Description:走长度分段函数
- Canonical:一致性分三档
- Robots:noindex是重罚区
- Open Graph与Twitter Card:按齐全比例给分
- Lang、Charset、Hreflang、Schema:各有各的脾气
- scoreTag公式:长度怎么换算成分数
- 抓取那一关:检测器怎么把页面HTML弄到手
- 第一道坎:反爬拦截
- 第二道坎:编码转换
- 怎么用检测器跑一次完整体检?
- 第一步:输入URL抓取解析
- 第二步:读总分,定基线
- 第三步:按权重从高往低修
- 第四步:修完复测,确认进区
- 串进工具链:体检之后该修什么
- 十项之外:权重0的那些“顺手一查”
- 三种分数画像:同样80分,问题可能天差地别
- 中文站要注意的字节数陷阱
- 从单页到全站:怎么把体检规模化
- 常见问题解答
- Meta标签检测器和普通的SEO检查工具有什么区别?
- 总分多少算及格?要追求100分吗?
- canonical显示70分、提示和当前URL不一致,要紧吗?
- 页面抓取失败、返回403怎么办?
- Schema检测到了就一定能拿富媒体吗?
- Open Graph和Twitter Card缺失,会影响Google排名吗?
- 权重0的“其他SEO元素”能直接忽略吗?
- 检测器给了满分,是不是就完全不用管这个页面了?
- 抓回来的中文是乱码,是工具的问题吗?
摘要:Meta标签检测器不是简单地“有没有打个勾”,而是把整页的title、description、canonical、robots、Open Graph、Twitter Card、hreflang、lang、charset、Schema十项按权重加权打一个0到100的总分。每一项的分数都不是非黑即白——标题长度走一条分段函数、canonical一致性分三档、社交标签按齐全比例给分。这篇把每一项的权重、扣分逻辑和那条核心评分公式全拆开,再给你一套从体检到修复的动线。
先问个扎心的问题:你上一次完整检查一个页面的meta标签,是什么时候?大多数人写完title和description就以为万事大吉,可页面SEO的地基远不止这两行。canonical指错了地方,全站内容被判重复;robots不小心带了noindex,辛苦做的页面悄悄从搜索结果里消失;Open Graph缺了图,链接转发到社媒变成一坨灰扑扑的纯文字。
这些问题有个共同特征:藏在HTML的head里,肉眼不扫一遍根本发现不了,可一旦出错就是系统性失血。Meta标签检测器要干的,就是把这片看不见的雷区一次性扫出来,并且给你一个能横向对比、能追踪进步的分数。
为什么meta标签值得单独做一次体检?
有人觉得,meta标签嘛,装个SEO插件不就自动生成了。问题恰恰出在这里:插件生成的是“默认值”,不是“对的值”。默认的canonical可能指向带参数的脏URL,默认的og:image可能根本没配,默认的robots在某个模板上被开发顺手加了noindex。插件让你以为标签齐了,检测器才告诉你标签对不对。
更现实的场景是改版和迁移。换个主题、上个headless架构、做一次域名搬迁,meta标签是最容易集体失分的重灾区。canonical还指着老域名、hreflang的对应关系断了、charset声明丢了——这些在功能测试里完全看不出来,页面照常打开,可搜索引擎那头已经乱套。一次体检胜过三个月后对着掉量的曲线干瞪眼。
还有AI搜索这层新变量。结构化数据、Open Graph这些原本“锦上添花”的标签,在AI引擎抓取、理解、引用你内容的链路里权重越来越高。把meta标签做扎实,不只是讨好Google,也是给豆包、Perplexity这些AI引擎递一张读得懂的名片。SERP模拟器管的是标签在搜索结果里“好不好看”,检测器管的是标签本身“对不对、全不全”,一前台一后台,发布前都该跑。
检测器的算法核心:10项加权,不是简单打勾
很多免费的meta检查工具,逻辑粗暴:有这个标签给绿勾、没有给红叉,最后数一数几个勾。这种打分有个致命问题——它把“缺一个title”和“缺一个twitter:image”当成同等严重,可这俩的SEO分量差着十万八千里。
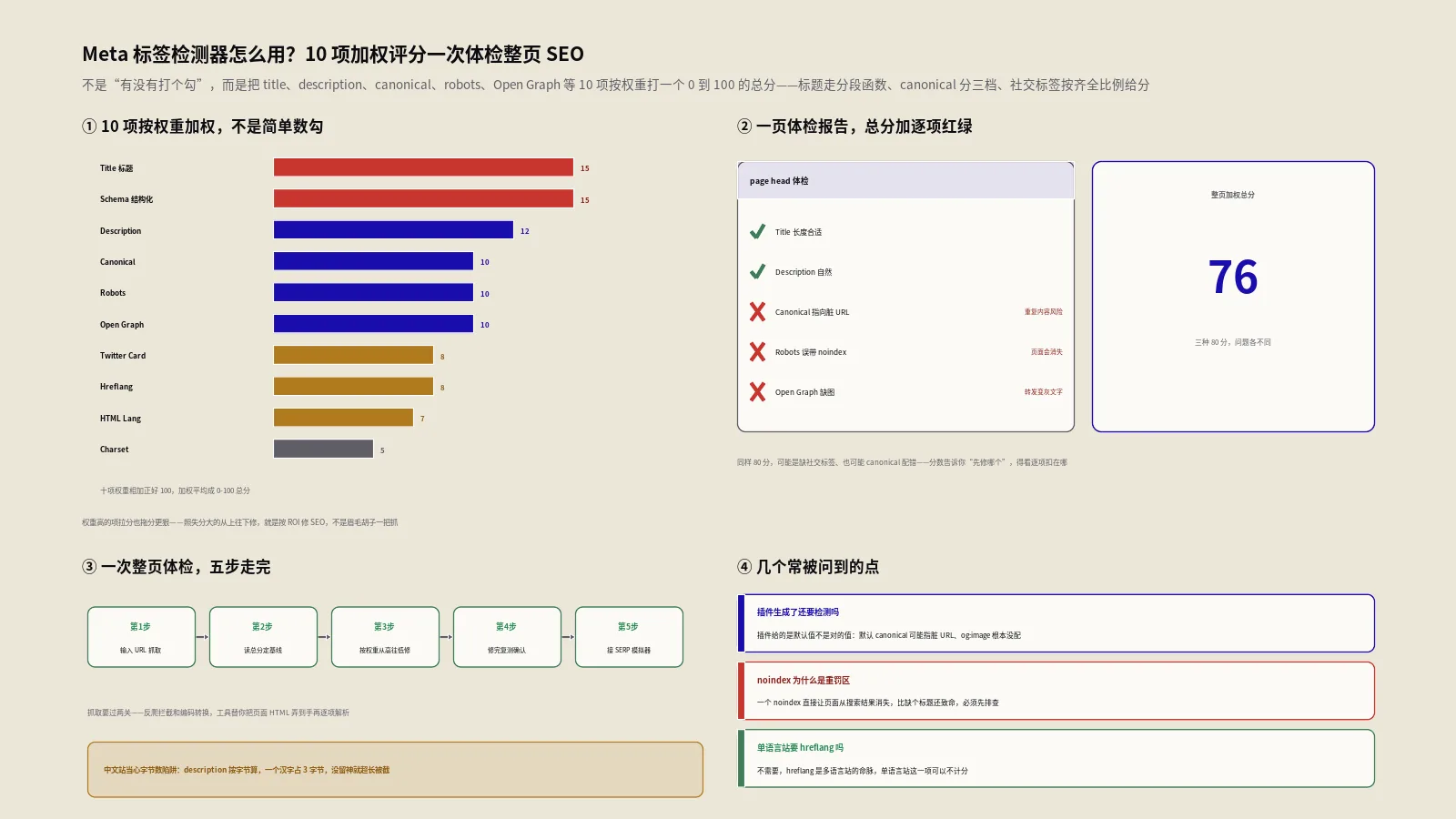
这款检测器不这么干。它给每一项分配了一个权重,权重越高、对总分的影响越大。权重分配直接反映了各标签的真实SEO重要性:
| 检测项 | 权重 | 为什么是这个分量 |
|---|---|---|
| Title标题 | 15 | 最直接影响排名与点击的标签,最高权重 |
| Schema结构化数据 | 15 | 富媒体与AI引用的入场券,并列最高 |
| Meta Description | 12 | 不直接影响排名但强烈影响点击率 |
| Canonical URL | 10 | 重复内容治理的关键,配错代价大 |
| Robots标签 | 10 | 误带noindex直接让页面消失 |
| Open Graph | 10 | 社媒分享展现,影响站外点击 |
| Twitter Card | 8 | X平台分享展现 |
| Hreflang多语言 | 8 | 多语言站的命脉,单语言站可不需要 |
| HTML Lang属性 | 7 | 帮搜索引擎和读屏软件识别语言 |
| Charset字符编码 | 5 | 基础但出错少,权重最低 |
十项权重加起来正好100。最终总分的算法是:每一项先得一个0到100的子分数,乘以自己的权重累加成总得分,再除以满分(每项100分乘权重的总和)乘100,归一化成一个0到100的总分。说白了就是加权平均,权重高的项目拉分也拖分更狠。
这种设计的好处是,分数会诚实地告诉你“先修哪个”。一个title出问题扣的分,顶得上两三个twitter标签缺失。你照着失分大的项目从上往下修,就是按ROI在修SEO,而不是眉毛胡子一把抓。
逐项拆解:每一项怎么打分、扣在哪
权重决定“这项多重要”,子分数决定“这项做得多好”。十项的子分数逻辑各不相同,挨个拆给你看。
Title与Description:走长度分段函数
这两项不是有没有的问题,而是长度合不合适。检测器对标题的理想区间设成30到60字符、描述设成100到160字符。落在区间内满分,太短或太长都按一条分段公式扣分(这条公式下一节专门讲)。逻辑很务实:标题太短浪费了搜索结果的展示空间,太长在Google里被截断;描述太短信息不足,太长被砍尾巴。Google在《Control your snippets in search results》里也强调,描述要能概括整页、别堆关键词,检测器的长度评分正是这条原则的量化执行。
Canonical:一致性分三档
canonical的打分最能体现“分档”思想。完全没设canonical,给30分——不是零分,因为没有canonical不等于致命,但确实有重复内容风险。设了、但指向的地址和当前页URL不一致,给70分——可能是有意为之(比如带不带www的归一),也可能是配错,给个中间分提醒你确认。设了且和当前URL一致,满分100。
Google在《What is canonicalization》里点明,rel=canonical只是给Google的提示而非命令,它最终可能选别的页做规范版。所以检测器对一致性给三档分而非一刀切,正是这种弹性的体现——指向不一致未必是错,但值得你确认一眼。
Robots:noindex是重罚区
robots标签的判定围绕一个核心风险:页面是不是被悄悄设成不收录。没有noindex的页面给满分;一旦检测到noindex,直接掉到20分的重罚区——因为这往往是个事故,辛苦做的页面被挡在索引门外。检测到nofollow会单独提示,但不像noindex那样重罚。
Open Graph与Twitter Card:按齐全比例给分
这两项社交标签的打分是“按比例”的。Open Graph看你配齐了多少个必需属性,按《The Open Graph protocol》官方规范,og:title、og:type、og:image、og:url是四个必需属性,配齐的比例乘100就是子分数——配了一半给50,全配齐给100。Twitter Card同理,按必需加可选标签的齐全度折算。这种比例给分比“有没有”精细,能反映出你做到了哪一步。
Lang、Charset、Hreflang、Schema:各有各的脾气
HTML lang属性简单粗暴:没设给20分、设了给100。Charset分三档:没声明给30、用了非UTF-8编码给60、用UTF-8给满分。Hreflang比较宽容,单语言站本就不需要它,所以没有hreflang不重扣、给80分,避免误伤;多语言站则看有没有配x-default。Schema结构化数据是权重15的大项,没检测到给20分、检测到给100,并把每段Schema的 @type和体积列出来给你看。
scoreTag公式:长度怎么换算成分数
前面欠了一笔账:标题和描述太短太长到底怎么扣分?这就要请出检测器里那条核心的长度评分函数。它把“一个长度”映射成“一个分数”,逻辑是一条分段折线。
规则拆成四段。其一,标签压根不存在,0分,没得商量。其二,长度落在理想区间内(标题30到60、描述100到160),满分100。其三,长度不足下限,按“当前长度除以下限再乘100”算,但有个40分的保底——再短也不会低于40。其四,长度超过上限,从100开始、每超一个字符扣2分,但有个50分的地板——再长也不会低于50。
拿几个真实数字走一遍就透了,以标题为例(下限30、上限60):
| 标题长度 | 落在哪段 | 算式 | 得分 |
|---|---|---|---|
| 0(没写) | 不存在 | — | 0 |
| 20字符 | 不足下限 | max(40, 20÷30×100) | 67 |
| 45字符 | 理想区间 | — | 100 |
| 80字符 | 超过上限 | max(50, 100−(80−60)×2) | 60 |
| 100字符 | 严重超长 | max(50, 100−(100−60)×2) | 50(触地板) |
这条公式的妙处在于两个保底。短的保底40、长的保底50,意味着“写了但长度不理想”永远比“没写”得分高——这符合直觉,残缺的标签也比没有强。同时超长的惩罚比偏短更狠(每字扣2),因为超长会触发截断,是实打实的展现损失。SEO Title优化的5个维度这篇能帮你把标题写进满分区间,再用检测器复核一遍长度,双保险。
抓取那一关:检测器怎么把页面HTML弄到手
评分再精巧,前提是先拿到页面的HTML。这一步看着简单,其实藏着两道坎,理解了它你才知道为什么有时候抓取会失败、抓回来的中文为什么有时是乱码。
第一道坎:反爬拦截
不少站会对来路不明的请求摆脸色,直接返回403禁止或429限流。检测器的对策是带一个真实浏览器的身份去敲门——它把请求伪装成Chrome浏览器,带上完整的User-Agent标识,而不是裸着一个脚本特征去抓。更进一步,它准备了多套不同的浏览器身份和请求头组合,第一套被拒就换第二套试,模拟不同浏览器轮番敲门。
即便这样,碰到Cloudflare这类硬核防护、或者明确返回403、429的站,还是可能抓不动。这不是工具不行,是对方铁了心不让自动化访问。遇到这种情况,老老实实在浏览器里打开页面、复制源码来分析,是最稳的退路。
第二道坎:编码转换
抓回来的HTML不一定是UTF-8。国内很多有年头的老站,还在用GBK、GB2312这些编码,直接当UTF-8解析,中文全是乱码,meta标签的内容也就读废了。检测器为此做了一套三级编码兜底。
第一级,读HTML里声明的charset,如果不是UTF-8,就按声明的编码转成UTF-8。第二级,万一没声明或声明不可信,就自动探测——在UTF-8、GBK、GB2312、BIG5、ISO-8859-1这几种常见编码里猜出最可能的那个,再转码。第三级,实在转不动就原样返回,至少不把数据弄坏。这套兜底让它面对繁体BIG5的港台站、GBK的内地老站,都能把中文meta正确读出来。
怎么用检测器跑一次完整体检?
原理讲透了,落到操作。下面这套四步法,是保哥给客户站做技术SEO巡检时的标准动作。
第一步:输入URL抓取解析
把目标页面的完整URL填进去。检测器会去抓这个页面的HTML,解析出head里的所有meta标签。这里有个坑:如果页面对爬虫返回403或429,抓取会失败,这种站需要换别的方式拿到HTML再贴进来分析。
第二步:读总分,定基线
先别急着改,记下那个0到100的总分。这是你这个页面当前的SEO健康基线。优化是个对比游戏,没有起点分,你改完了也不知道到底提升了多少。把基线分截图存下来,改完再测,进步看得见。
第三步:按权重从高往低修
这是整套方法的灵魂。别从上往下逐条改,而是盯着“高权重 × 低子分数”的项目先下手。一个权重15的Title从60分提到100,比五个权重5的小标签全修好涨分还多。把精力花在拉分最狠的地方,这就是按ROI修SEO。
第四步:修完复测,确认进区
改完meta标签,重新跑一遍。看总分涨了多少,更要逐项确认每一项是不是真进了满分或安全区——别改了title却把description碰坏了。复测通过,这个页面的meta体检才算闭环。
🩺 动手试试:Meta标签检测器
输入任意URL,一次性体检title、description、canonical、robots、Open Graph、Twitter Card、hreflang、lang、charset、Schema十项,给出0到100的加权总分与逐项修复建议。
串进工具链:体检之后该修什么
检测器告诉你“哪项失分”,但具体怎么补,往往要接别的工具。保哥常用的串法是按失分项分流。
如果Title或Description失分,先用SERP模拟器把长度和截断调到位,再用检测器复核字符区间。一个管像素展现、一个管字符评分,两把尺子量同一行标题,互相印证。
如果Schema失分——这可是权重15的大项——用结构化数据生成器生成对应类型的JSON-LD贴进页面,再回检测器看Schema项是不是从20分跳到100。这是整套工具链里涨分最快的一环。
如果Robots项报了noindex或canonical配错,robots规则用robots.txt生成器重写一份干净的,canonical的跨页逻辑则该回到方法论层面理清。canonical标签的8种跨页场景与冲突诊断把这块讲得很透,配着检测器的一致性三档分一起看,最容易把canonical彻底捋顺。
如果Open Graph失分,社媒卡片长什么样用OG预览工具边补边看。检测器告诉你缺哪个og属性,预览工具让你看到补齐后的分享效果,闭环就完整了。
十项之外:权重0的那些“顺手一查”
除了参与评分的十项,检测器还顺手查了一组不计分、但值得一看的元素,归在“其他SEO元素”里,权重是0。权重0不代表不重要,而是它们要么过于基础、要么因站而异,不适合统一打分,但摆出来给你做个参考。
这组里最该留意的是viewport。少了它,页面在移动端不会做自适应缩放,体验直接崩,对移动优先索引是实打实的伤害——虽然不计分,但缺了它该补。其余几项偏信息性:favicon有没有在head里声明、有没有用http-equiv形式的X-Robots-Tag、author作者标注、generator生成器标识。
generator这项尤其有意思。很多CMS会自动往页面里塞一个generator标签,明晃晃写着“我是WordPress 6.x”或“我是某某建站系统”。这等于把你的技术栈底牌亮给所有人,包括想找漏洞的人。检测器把它列出来,是提醒你:要不要为了安全把这个标签去掉,自己掂量。这些权重0的项,看的是细节意识。
三种分数画像:同样80分,问题可能天差地别
加权总分最容易被误读成“分数高就没事”。其实同样一个80分,背后的问题可能完全不同,会读分数比记住分数更重要。保哥常拿三种典型画像给客户讲。
第一种,“高分虚胖型”:总分88,看着漂亮,可掉的那12分全压在canonical这个权重10的核心项上——它指错了地址。这种分数最危险,因为高分让你松懈,而失分点恰恰是会引发全站重复内容的致命项。读分要看失分落在哪,不是只看总分。
第二种,“低分实壮型”:总分76,看着一般,可失分全在Twitter Card、hreflang这些对你这个单语言、不做社媒的站根本用不上的项;权重10以上的核心项个个满分。这种站的SEO地基其实很扎实,76分只是被无关项拖低,不必慌。
第三种,“真的该急型”:总分70,且Title、Description、Schema三个高权重项同时失分。这才是真正要立刻动手的——地基项集体亮黄灯,每一项都直接关系排名和点击,拖一天就多漏一天的流量。
这三种画像分数接近,处置优先级却天差地别,这正是加权评分配上“看失分项”才能发挥的价值。记住一句话:总分是给你看趋势的,失分清单才是给你派活的,两者一起读才算读懂,否则一个漂亮的数字反而会让你对真正的隐患视而不见。robots.txt和meta robots什么时候用哪个这篇能帮你把Robots项里最容易搞反的那部分彻底厘清,避免一个不该出现的noindex把整页悄悄误杀。
中文站要注意的字节数陷阱
得诚实提醒一个容易踩的坑。检测器判断标题、描述长度时,底层用的是字符串的字节长度。对英文内容,一个字母就是一个字节,长度判断和你数的字符数完全吻合。可中文是另一回事。
一个中文字符在UTF-8编码下占3个字节。这意味着,一个只有20个汉字的中文标题,字节长度是60,在检测器眼里正好压在“理想上限”那条线上;写到25个汉字,字节数75,就被判成超长扣分了。可你肉眼看着才二十几个字,怎么就超了?
所以中文站读这个长度分数时,心里要做个换算:理想区间的字节上限除以3,才是大致的汉字数。标题60字节约等于20个汉字、描述160字节约等于53个汉字。当然,这个字节口径其实和搜索结果的真实截断(按像素)又是两套逻辑——这也是为什么保哥主张中文标题别只信一个工具,长度评分看检测器、真实截断看SERP模拟器,两头一起校。知道工具量的是字节还是像素,才不会被分数带偏。
从单页到全站:怎么把体检规模化
检测器是个单页工具,一次看一个URL。可一个站动辄几百上千个页面,难道一个个手敲?规模化的思路,是把单页检测当成“标准”,而不是“全部工作量”。
保哥的实操是分三层做。第一层抓模板。一个站的页面通常就那么几类模板:首页、分类页、产品页或文章页、专题页。每类模板挑一两个代表页用检测器跑透,把这类模板的meta配置规律摸清。模板级的问题——比如所有产品页的canonical都用错了变量——修一个模板就修了一整类,这是杠杆最大的活。
第二层定基线分。给每类模板的代表页记一个加权总分作为基线,写进你的SEO巡检表。以后每次改版、上新功能,回头重测这几个代表页,分数掉了就知道这次改动碰坏了meta。检测器的总分在这里是个特别好用的回归测试指标——它把抽象的“meta健康度”压成了一个能逐月对比的数。
第三层管异常页。模板没问题,不代表每个页面都没问题。手工发布的专题页、营销活动页、被插件特殊处理过的页面,最容易脱离模板规律单独出错。这些“非标页”值得逐个过检。把模板级和非标页两头管住,几百个页面的meta体检就被压缩成了十几次有针对性的检测,规模化也就成立了。
有条件的团队还能更进一步,把这套加权评分逻辑接进自己的脚本,对sitemap里的URL批量跑、把分数写进数据库做趋势监控。工具给的是方法论和那套可复用的权重模型,规模化的上限取决于你愿意把它工程化到哪一步。
保哥还想强调一个容易被忽略的用法:把检测器当成跨团队的沟通语言。技术SEO最头疼的就是和开发、运营扯不清“到底哪里没做好”。有了一个0到100的加权总分和逐项失分清单,你跟开发说的不再是模糊的“meta标签优化一下”,而是“产品页模板的canonical项只有70分、Schema项才20分,这两块按这个清单改”。一个可量化、可复测的分数,把扯皮变成了可验收的工单,这在多团队协作里省下的沟通成本,比工具本身省的时间值钱得多。
常见问题解答
Meta标签检测器和普通的SEO检查工具有什么区别?
核心区别是加权评分。普通工具多半是“有标签给勾、没标签给叉”,把所有标签当同等重要。这款检测器给十项标签各分配了权重——Title和Schema权重15,Charset只有5,最终算加权总分。好处是分数会告诉你先修哪个:失分大的高权重项才是真正该优先解决的,避免你在无关紧要的小标签上浪费时间。
总分多少算及格?要追求100分吗?
不必死磕100。很多满分项对特定站点根本不适用,比如单语言站的hreflang、没有社媒运营需求的Twitter Card。保哥的判断标准是:权重10以上的核心项(Title、Schema、Description、Canonical、Robots)务必拉到满分或安全区,这几项决定了页面的SEO地基;权重低的项按业务需要补,不强求。总分能稳定在85以上,地基就算扎实了。
canonical显示70分、提示和当前URL不一致,要紧吗?
看是不是有意为之。70分是检测器留的中间档,专门对应“你设了canonical,但它指向别的地址”这种暧昧情况。如果是你刻意做的归一(比如带参数页指向干净主版本、带www指向不带www),那没问题。如果你压根不知道为什么不一致,那多半是配错了,得回去查。它给中间分而不是直接扣到底,就是提醒你确认而非报警。
页面抓取失败、返回403怎么办?
说明目标站对爬虫做了拦截。这种情况下检测器抓不到HTML,自然没法分析。解决办法是绕过抓取:在浏览器里打开页面、查看源代码、把head部分的HTML复制出来,用支持直接粘贴HTML的方式分析。很多反爬严格的站都得这么处理,这不是工具的问题,是对方不让抓。
Schema检测到了就一定能拿富媒体吗?
不能划等号。检测器的Schema项只判断“页面上有没有结构化数据、是什么类型”,它给100分代表你贴了Schema,不代表这段Schema一定合规、一定能触发富媒体。能不能拿富媒体还要看必填属性齐不齐、有没有通过Google的富媒体测试、以及Google愿不愿意展示。检测器管“有没有”,富媒体资格得用专门的富媒体测试工具再验一道。
Open Graph和Twitter Card缺失,会影响Google排名吗?
基本不直接影响Google自然排名,它俩管的是站外社媒分享时的展现。但别因此忽视——链接被转发到社交平台、聊天工具时,有没有一张漂亮的卡片,直接影响站外引流的点击率。而且og:title还会被Google当作生成标题链接的候选来源之一,间接沾点边。权重10和8的设定,正反映了它们这种“站外重要、站内间接”的定位。
权重0的“其他SEO元素”能直接忽略吗?
不建议无脑忽略。权重0只是说它们不进总分,不代表无关紧要。viewport缺失会直接拖垮移动端体验,这在移动优先索引时代是硬伤,该补就得补。generator标签把你的CMS版本暴露给所有人,从安全角度也许该删。这组项检测器单独列出来,考的是你的细节意识——总分满足了,再扫一眼这一栏,往往能捡到几个低成本但有意义的优化点。
检测器给了满分,是不是就完全不用管这个页面了?
满分代表meta标签层面没硬伤,但SEO远不止meta。内容质量、内链结构、页面速度、外链、用户体验这些,检测器一概不管。把它定位成“技术地基的体检仪”最准确——它确保你的标签没拖后腿,但拿不拿得到好排名,还得靠地基之上的内容和体验。地基过关只是入场,不是终点。
抓回来的中文是乱码,是工具的问题吗?
多半不是。检测器内置了三级编码兜底:先读页面声明的charset转码,再自动在UTF-8、GBK、GB2312、BIG5等常见编码里探测转换,实在不行才原样返回。它对付内地GBK老站、港台BIG5站都能正确读出中文。如果还是乱码,通常是源页面本身的编码声明和实际内容打架,那是页面自己的charset配错了,正好也是检测器该给你扣分提醒的问题。
本文标题:《Meta标签检测器怎么用?10项加权评分一次体检整页SEO》
本文链接:https://zhangwenbao.com/meta-checker-weighted-seo-audit-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0