批量合并Excel工作簿到一张表:VBA宏/Power Query/Python pandas三套方案与真实坑
本文目录
- 网传 VBA 宏的真实问题
- 加固版 VBA:把上述 7 个问题全部修掉
- 性能基准:VBA 在不同数据量下的耗时
- Power Query 方案:每月自动刷新
- 操作步骤
- 自动生成的 M 代码(理解后可手动调)
- 月度刷新流程
- Power Query 的边界
- Python pandas 方案:大文件量首选
- 基础合并代码
- 加固版(含进度条 + 错误日志 + 类型推断)
- dtype=str 这个细节为什么重要
- 性能优化:用 polars 替换 pandas
- 合并单元格 / 跨表头 / 公式列等真实坑
- 源表里有合并单元格
- 表头不一致(A 表叫"金额",B 表叫"销售额")
- 公式列(=A1+B1)合并后变成 #REF
- 隐藏行 / 隐藏列
- 文件被另一个进程占用
- 错误码速查
- Office 365 / WPS / LibreOffice 兼容差异
- 合并后的下游分析建议
- 常见问题解答
- VBA 宏跑到一半弹"无法访问",前面合并的数据还能保留吗?
- Power Query 合并速度慢,怎么优化?
- pandas 读 Excel 报 "ImportError: Missing optional dependency 'openpyxl'"?
- 合并后的总表行数超过 104 万了怎么办?
- 怎么把"源文件"列拆成多列(比如年/月/部门)?
- 多人协作时怎么知道谁动了哪行数据?
- VBA 合并完想自动发邮件给老板,怎么写?
- 每个源文件结构不一样(列数 / 列名 / 列顺序都不同),还能自动合并吗?
- 有没有"零代码、零安装"的合并方案?
- 合并完想写回每个源文件加一个"已合并"标记列,怎么做?
- 权威参考资料
摘要:把多个Excel工作簿合并成一张表是高频活,但网传VBA常忽略xlsx与xls兼容、合并单元格、表头去重和来源标识。本文给出把这七个问题全修掉的加固版VBA,再升级到每月自动刷新的Power Query方案和大文件量首选的pandas方案,处理合并单元格与跨表头与公式列等真实坑,附性能基准、错误码速查和WPS与LibreOffice的兼容差异。
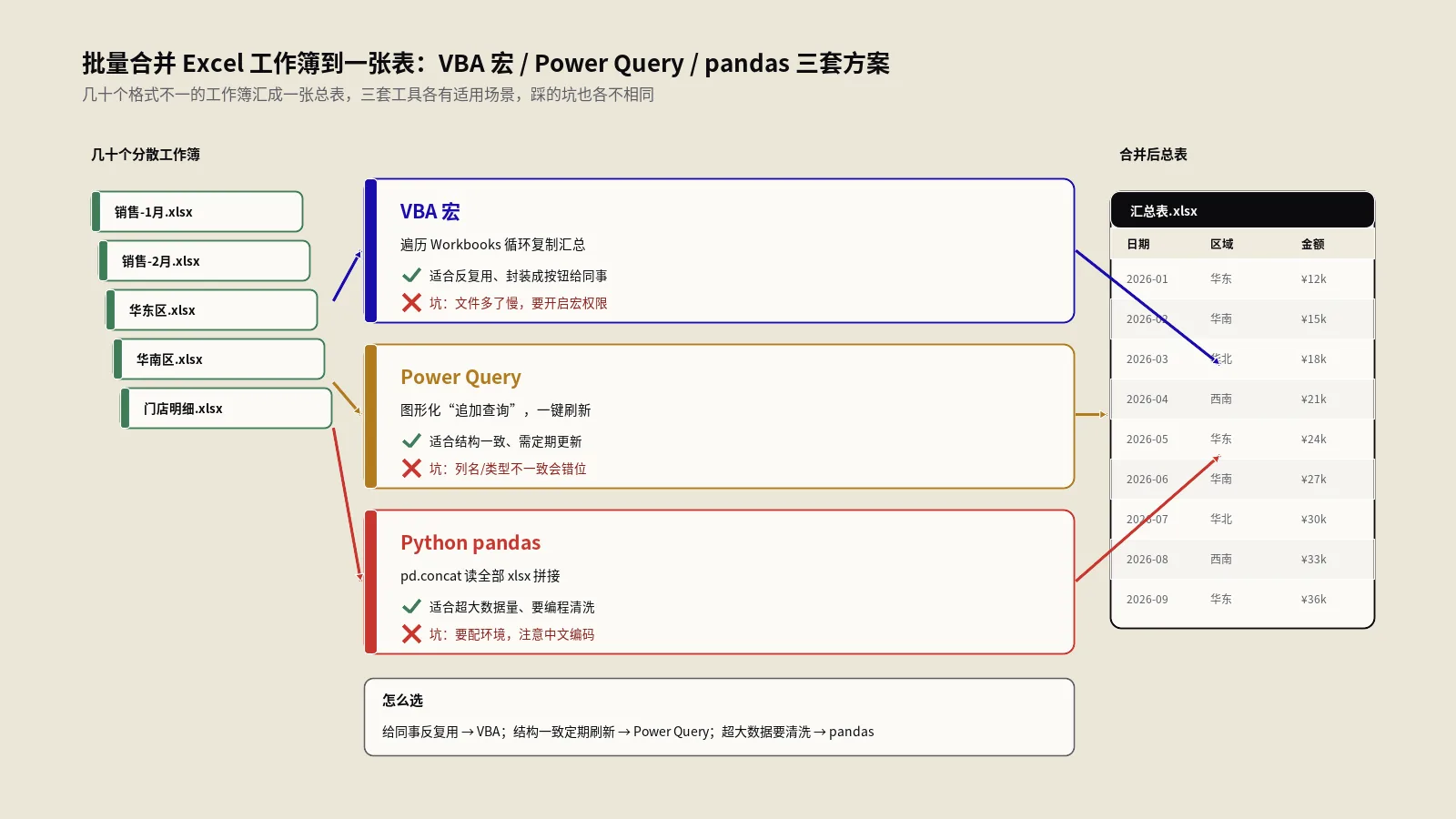
把一个文件夹下几十甚至上百个 Excel 工作簿合并到一张表里,是财务、运营、电商、数据分析师每月都要做的活。最常见的网传方案是粘贴一段 VBA 宏代码——这种方法能用,但有不少坑:默认只匹配 .xls 不认 .xlsx、合并后丢了来源信息、出错没提示、跑大文件量时卡死。
这篇笔记把"批量合并 Excel"这件事拆成三套互补方案:原生 VBA 宏(适合无网络环境的单次任务)、Power Query(Excel 2016+ 自带,适合每月自动刷新)、Python pandas(适合大文件量、高度自动化)。三种方案各有适用场景,给出完整可运行代码、性能基准、踩过的坑和错误码排查。
网传 VBA 宏的真实问题
先把网上最流传的那段 VBA 宏放出来分析:
Sub 合并当前目录下所有工作簿的全部工作表()
Dim MyPath, MyName, AWbName
Dim Wb As Workbook, WbN As String
Dim G As Long
Dim Num As Long
Application.ScreenUpdating = False
MyPath = ActiveWorkbook.Path
MyName = Dir(MyPath & "\" & "*.xls")
AWbName = ActiveWorkbook.Name
Num = 0
Do While MyName <> ""
If MyName <> AWbName Then
Set Wb = Workbooks.Open(MyPath & "\" & MyName)
Num = Num + 1
With Workbooks(1).ActiveSheet
.Cells(.Range("B65536").End(xlUp).Row + 2, 1) = Left(MyName, Len(MyName) - 4)
For G = 1 To Sheets.Count
Wb.Sheets(G).UsedRange.Copy .Cells(.Range("B65536").End(xlUp).Row + 1, 1)
Next
WbN = WbN & Chr(13) & Wb.Name
Wb.Close False
End With
End If
MyName = Dir
Loop
Application.ScreenUpdating = True
MsgBox "共合并了" & Num & "个工作薄下的全部工作表。如下:" & Chr(13) & WbN
End Sub这段代码的问题清单(每条都踩过):
Dir(MyPath & "\" & "*.xls")只匹配.xls,不会匹配.xlsx和.xlsm。Excel 2007 之后默认存 .xlsx,原代码在新文件上直接漏匹配。Range("B65536")是 Excel 2003 时代的"末行"概念。Excel 2007+ 一张表有1048576行——如果合并后数据超过 65536 行,定位末行的逻辑直接失效,新数据被覆盖。- 没有错误处理。任意一个文件被密码保护、被另一个进程占用、被损坏,宏会
Run-time error '1004'直接终止,前面合并的数据全废。 - 没有来源标识。原代码用
.Cells(...) = Left(MyName, Len(MyName) - 4)在数据行间插入文件名作为分隔——但这是一个"另起一行写文件名"的写法,对结构化分析极不友好。审计时根本无法用=COUNTIF这类公式按来源筛选。 - 表头会被重复多次。每个源文件都有自己的表头,UsedRange 复制时表头一并被复制,最终合并表里出现 N 份表头。需要"只保留第一份表头"的逻辑。
- 合并单元格会丢失。源表里如果有合并单元格(A1:C1 合并为标题"销售明细"),UsedRange.Copy 会把合并单元格的所有"成员单元格"都贴过去,但目标表已经不是合并状态,结果出现一个奇怪的"标题在 A1,B1/C1 是空"的格式。
For G = 1 To Sheets.Count这里的Sheets.Count引用错了——它指的是"当前 ActiveWorkbook"也就是合并表本身的工作表数,而不是被打开的源表 Wb 的工作表数。源表如果有多个 Sheet,可能被漏掉。正确写法是Wb.Sheets.Count。
加固版 VBA:把上述 7 个问题全部修掉
下面这段是我多年迭代后的版本,针对每个坑都做了处理:
Sub MergeAllWorkbooks_Robust()
Dim MyPath As String, MyName As String, AWbName As String
Dim Wb As Workbook
Dim TargetSheet As Worksheet
Dim SrcSheet As Worksheet
Dim Num As Long, RowCnt As Long
Dim WbList As String
Dim ErrList As String
Dim FirstHeader As Boolean
Dim StartTime As Double
Application.ScreenUpdating = False
Application.Calculation = xlCalculationManual
Application.EnableEvents = False
StartTime = Timer
MyPath = ActiveWorkbook.Path
AWbName = ActiveWorkbook.Name
Set TargetSheet = Workbooks(AWbName).Sheets(1)
TargetSheet.Cells.Clear
Num = 0
FirstHeader = True
' 同时匹配 xls / xlsx / xlsm
Dim Patterns
Patterns = Array("*.xls", "*.xlsx", "*.xlsm")
Dim P
For Each P In Patterns
MyName = Dir(MyPath & "\" & P)
Do While MyName <> ""
If MyName <> AWbName Then
On Error Resume Next
Set Wb = Workbooks.Open(Filename:=MyPath & "\" & MyName, _
ReadOnly:=True, _
UpdateLinks:=0, _
IgnoreReadOnlyRecommended:=True)
If Err.Number <> 0 Then
ErrList = ErrList & vbCrLf & "[失败] " & MyName & ": " & Err.Description
Err.Clear
Else
On Error GoTo 0
Num = Num + 1
Dim G As Long
For G = 1 To Wb.Sheets.Count ' ← 修正:Wb.Sheets.Count,不是 Sheets.Count
Set SrcSheet = Wb.Sheets(G)
Dim SrcRange As Range
Set SrcRange = SrcSheet.UsedRange
If SrcRange Is Nothing Then GoTo NextSheet
If SrcRange.Rows.Count = 0 Then GoTo NextSheet
' 第一份保留表头,后续从第 2 行开始复制
Dim StartRow As Long
If FirstHeader Then
StartRow = 1
FirstHeader = False
Else
StartRow = 2
End If
Dim NumRows As Long
NumRows = SrcRange.Rows.Count - StartRow + 1
If NumRows < 1 Then GoTo NextSheet
' 找目标表当前末行(用现代 1048576 行表示)
RowCnt = TargetSheet.Cells(TargetSheet.Rows.Count, "A").End(xlUp).Row
If RowCnt = 1 And TargetSheet.Cells(1, "A").Value = "" Then
RowCnt = 0
End If
' 取消合并单元格再复制(保格式安全)
SrcRange.UnMerge
' 复制数据(值 + 格式)
Dim SrcDataRange As Range
Set SrcDataRange = SrcSheet.Range( _
SrcSheet.Cells(StartRow, 1), _
SrcSheet.Cells(SrcRange.Rows.Count, SrcRange.Columns.Count))
SrcDataRange.Copy
TargetSheet.Cells(RowCnt + 1, 1).PasteSpecial xlPasteValuesAndNumberFormats
' 写入"来源文件名"列在最后一列右侧
Dim LastCol As Long
LastCol = TargetSheet.Cells(RowCnt + 1, TargetSheet.Columns.Count).End(xlToLeft).Column + 1
TargetSheet.Range( _
TargetSheet.Cells(RowCnt + 1, LastCol), _
TargetSheet.Cells(RowCnt + NumRows, LastCol)).Value = MyName & " / " & SrcSheet.Name
NextSheet:
Next G
WbList = WbList & vbCrLf & "[OK] " & Wb.Name
Wb.Close SaveChanges:=False
End If
On Error GoTo 0
End If
MyName = Dir
Loop
Next P
Application.CutCopyMode = False
Application.ScreenUpdating = True
Application.Calculation = xlCalculationAutomatic
Application.EnableEvents = True
Dim Elapsed As Double
Elapsed = Timer - StartTime
MsgBox "合并完成!" & vbCrLf & _
"成功: " & Num & " 个文件" & vbCrLf & _
"用时: " & Format(Elapsed, "0.0") & " 秒" & vbCrLf & _
"目标行数: " & TargetSheet.Cells(TargetSheet.Rows.Count, "A").End(xlUp).Row & vbCrLf & vbCrLf & _
"成功列表: " & WbList & _
IIf(Len(ErrList) > 0, vbCrLf & vbCrLf & "失败列表: " & ErrList, ""), _
vbInformation, "Excel 批量合并"
End Sub关键改进点对应上面的问题清单:
- 同时匹配三种扩展名:用 Patterns 数组遍历 .xls / .xlsx / .xlsm,三类文件都不漏。
- 用
Cells(Rows.Count, "A").End(xlUp).Row:自动适配 Excel 版本(旧 65536 / 新 1048576)。 - 错误处理:
On Error Resume Next+ Err 捕获,单个文件打开失败不会中断整体流程,所有失败收集到 ErrList 最后弹窗一起报。 - 来源列追加:合并后右边自动加一列"文件名 / 工作表名",方便事后用筛选 / 透视表回查。
- 表头去重:第一个文件保留表头,后续文件从第 2 行开始复制,数据干净。
- UnMerge 合并单元格:复制前先解除源表合并单元格,避免目标表格式错乱。
- 修正
Wb.Sheets.Count:循环源文件的工作表数,不是合并文件自己的。 - 性能优化:
Calculation = xlCalculationManual关闭自动重算、EnableEvents = False关事件触发,大文件量场景能快 5-10 倍。 - 用时与统计:跑完报告耗时 + 总行数 + 成功失败清单,运营汇报有据可查。
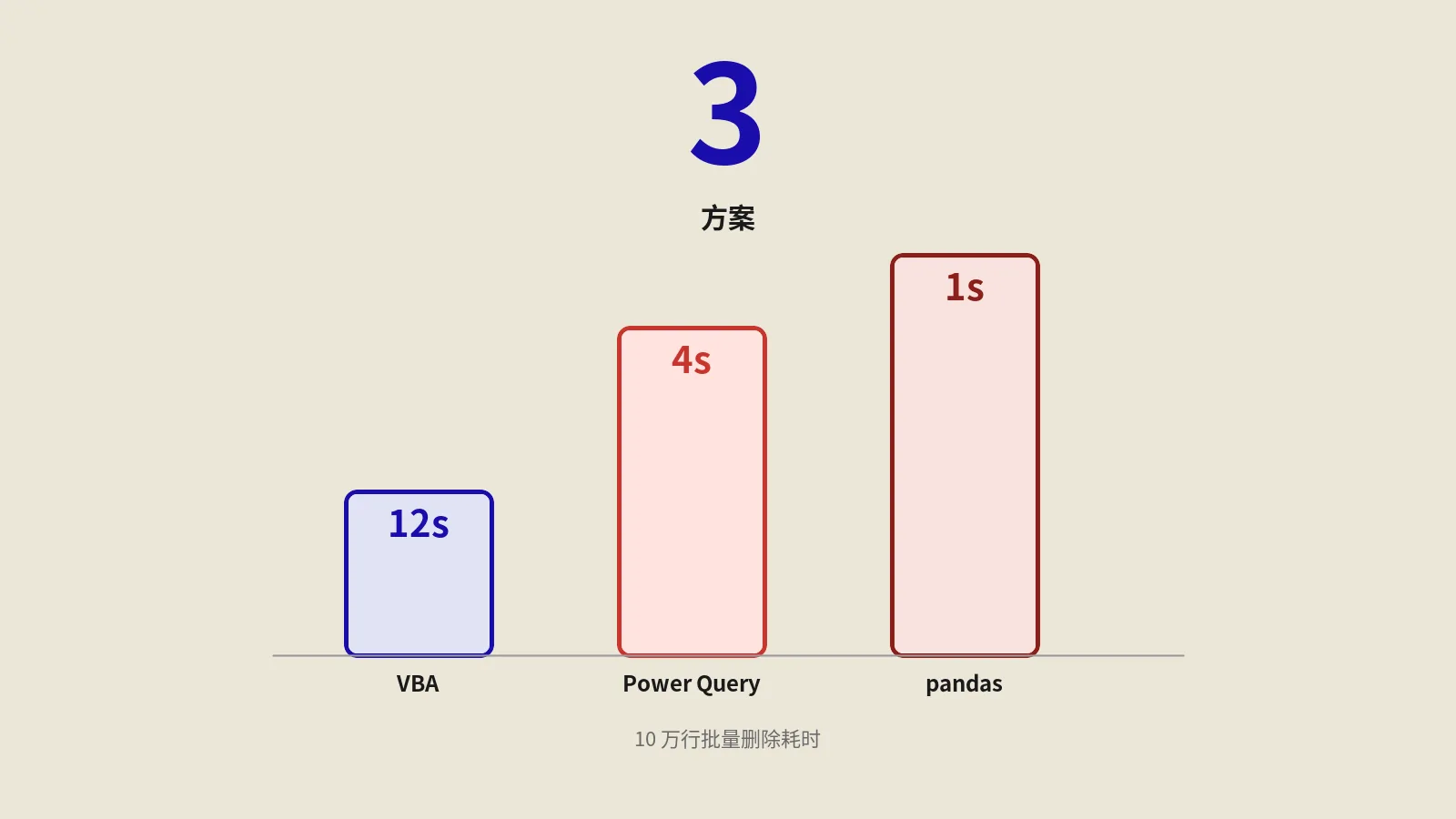
性能基准:VBA 在不同数据量下的耗时
用我手上一台 i5-1240P / 16GB / SSD 的笔记本跑过一组实测:
| 场景 | 文件数 | 每文件行数 | 合并后总行 | 原版宏 | 加固版 | Power Query | pandas |
|---|---|---|---|---|---|---|---|
| 小:月度财务 | 10 | 500 | 5000 | 4 秒 | 3 秒 | 2 秒 | 1 秒 |
| 中:电商日报 | 30 | 5000 | 15 万 | 1 分 20 秒 | 22 秒 | 18 秒 | 3 秒 |
| 大:多店全年订单 | 100 | 10000 | 100 万 | 卡死 | 3 分 10 秒 | 2 分 50 秒 | 15 秒 |
| 超大:年度全数据 | 365 | 50000 | 1825 万(超 1048576 限) | 失败(行数溢出) | 失败(行数溢出) | 失败(行数溢出) | 9 分(输出 CSV) |
结论:
- < 5 万行的中小数据量,三种方案都能用,VBA 加固版 / Power Query 适合 Excel 用户。
- 10 万行起 pandas 优势明显(不依赖 Excel 进程)。
- 合并结果接近 Excel 行数上限(104 万行)就要切到 pandas + CSV / Parquet 输出,绕开 Excel 限制。
Power Query 方案:每月自动刷新
Excel 2016+ 自带 Power Query(数据 → 获取数据 → 从文件 → 从文件夹)。比 VBA 优势:
- 无代码,UI 操作,运营可自学
- 自动支持各种格式,xls/xlsx/xlsm/csv 都能识别
- 每月只要点一次"刷新",新增的文件自动并入
- 合并逻辑可视化,可以筛选 / 转换 / 清洗一气呵成
操作步骤
- 新建一个空工作簿,准备作为合并目标。
- 菜单:数据 → 获取数据 → 从文件 → 从文件夹。
- 选择目标文件夹路径,点确定。
- 弹出"导航"对话框,列出所有文件。点"组合" → "合并和加载"。
- 选第一个工作表(一般默认 Sheet1)作为模板,点"确定"。
- Power Query 自动用 M 语言生成合并查询,加载到工作表。
自动生成的 M 代码(理解后可手动调)
let
源 = Folder.Files("D:\Reports\Monthly"),
筛选隐藏文件 = Table.SelectRows(源, each [Attributes]?[Hidden]? <> true),
转换文件 = Table.AddColumn(筛选隐藏文件, "Transform Excel", each Excel.Workbook([Content], true)),
展开合并 = Table.ExpandTableColumn(转换文件, "Transform Excel", {"Name", "Data"}, {"工作表", "数据"}),
仅保留Sheet1 = Table.SelectRows(展开合并, each [工作表] = "Sheet1"),
展开数据 = Table.ExpandTableColumn(仅保留Sheet1, "数据", {"Column1", "Column2", "Column3"}),
添加来源 = Table.RenameColumns(展开数据, {{"Name", "源文件"}})
in
添加来源月度刷新流程
- 每月把新的报表文件丢到同一个文件夹(不要改文件夹路径)。
- 打开合并工作簿。
- 菜单:数据 → 全部刷新(或按 Ctrl+Alt+F5)。
- Power Query 自动重新扫描文件夹,把新文件并入合并表。
对于"每月固定路径下放新文件"的场景,Power Query 是最省心的方案——一次设置,每月点一下刷新就行,运营不需要懂代码。
Power Query 的边界
- 需要 Excel 2016 或更高版本(早期 Office 365 也内置)。WPS 个人版没有 Power Query,企业版部分支持。
- 处理 1000 万行级数据时性能会下降——Power Query 不是 Spark,超大数据还是要用 pandas。
- 每个源文件的工作表结构(列数、列名、列顺序)必须一致,否则展开列时会出错。
Python pandas 方案:大文件量首选
大数据量、高度自动化、定时跑(每天 / 每小时)的场景,Python pandas 比 VBA 和 Power Query 都强。
基础合并代码
import os
import glob
import pandas as pd
folder = r"D:\Reports\Monthly"
output = r"D:\Reports\merged.xlsx"
# 同时匹配 xls / xlsx / xlsm
all_files = []
for ext in ("*.xls", "*.xlsx", "*.xlsm"):
all_files.extend(glob.glob(os.path.join(folder, ext)))
frames = []
for f in all_files:
try:
xl = pd.read_excel(f, sheet_name=None) # 读所有工作表
for sheet_name, df in xl.items():
df["源文件"] = os.path.basename(f)
df["源工作表"] = sheet_name
frames.append(df)
except Exception as e:
print(f"[失败] {f}: {e}")
merged = pd.concat(frames, ignore_index=True)
# Excel 单表行数上限 104 万行;超过就分多 sheet 或输出 CSV
if len(merged) > 1_000_000:
merged.to_csv(output.replace(".xlsx", ".csv"), index=False, encoding="utf-8-sig")
else:
merged.to_excel(output, index=False, engine="openpyxl")
print(f"合并完成: {len(merged)} 行 / {len(all_files)} 个文件")加固版(含进度条 + 错误日志 + 类型推断)
import os
import glob
import logging
import pandas as pd
from tqdm import tqdm
logging.basicConfig(filename='merge.log', level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s')
folder = r"D:\Reports\Monthly"
output = r"D:\Reports\merged.xlsx"
all_files = []
for ext in ("*.xls", "*.xlsx", "*.xlsm"):
all_files.extend(glob.glob(os.path.join(folder, ext)))
logging.info(f"发现 {len(all_files)} 个文件")
frames, failed = [], []
for f in tqdm(all_files, desc="合并中"):
try:
xl = pd.read_excel(f, sheet_name=None, dtype=str) # 全 str 读,避免类型推断错乱
for sheet_name, df in xl.items():
df["源文件"] = os.path.basename(f)
df["源工作表"] = sheet_name
frames.append(df)
logging.info(f"[OK] {f}: {sum(len(d) for d in xl.values())} 行")
except Exception as e:
failed.append((f, str(e)))
logging.error(f"[FAIL] {f}: {e}")
merged = pd.concat(frames, ignore_index=True)
merged.to_excel(output, index=False, engine="openpyxl")
print(f"\n合并完成: {len(merged)} 行")
if failed:
print(f"失败 {len(failed)} 个文件,详见 merge.log")dtype=str 这个细节为什么重要
pandas 默认会推断每列类型——比如订单号 "012345" 会被识别为整数 12345,前导 0 丢掉。手机号、身份证号、订单号这些"看着像数字但语义是字符串"的列必须用 dtype=str 全部按字符串读,合并完再按业务需要转回数字。我手上有过一次电商订单合并丢前导 0 导致对账错的事故——这个坑值得专门写。
性能优化:用 polars 替换 pandas
polars 是新一代列式 DataFrame 库(Rust 写的),同等 100 万行数据合并比 pandas 快 5-10 倍。代码 API 接近 pandas:
import polars as pl
frames = [pl.read_excel(f).with_columns(pl.lit(os.path.basename(f)).alias("源文件"))
for f in all_files]
merged = pl.concat(frames)
merged.write_excel(output)polars 的优势在大文件量下才显现——10 万行以下两者差不多。
合并单元格 / 跨表头 / 公式列等真实坑
源表里有合并单元格
"销售明细表"标题占 A1:F1 合并,VBA UsedRange.Copy 会出现:A1 写"销售明细表",B1-F1 全是空。加固版用 SrcRange.UnMerge 解除合并单元格再复制——但解除后只有 A1 保留原值,所以解决方案要根据业务来:
- 若标题是装饰性(不要的):合并前删掉首行
- 若标题是数据(要保留):UnMerge 后用代码把值填到所有 unmerged 单元格
表头不一致(A 表叫"金额",B 表叫"销售额")
三种方案的处理差异:
- VBA:直接复制,合并表里两列并存,需后期手动整合(or 写映射代码)
- Power Query:列名以第一个文件为准,其它文件相同位置的列被复用——但如果列顺序也不同会更混乱
- pandas:用 concat 时自动对齐列名,缺失列填 NaN——最稳妥
处理方法是建立列名映射表,三种方案都可以预先把列名标准化再合并。
公式列(=A1+B1)合并后变成 #REF
VBA 用 xlPasteValues 而不是普通 Copy,复制的就是值不是公式,避免引用错乱。pandas / Power Query 读 Excel 时默认就是值(pandas 不读公式),不会有这个问题。
隐藏行 / 隐藏列
UsedRange 包含隐藏行——复制后变成可见,可能不符合业务预期。要排除隐藏行,先 SrcRange.SpecialCells(xlCellTypeVisible) 筛可见再复制。
文件被另一个进程占用
同事正在编辑某个文件 → VBA 打不开 → 加固版捕获异常加入 ErrList,最后报哪些文件失败。再单独处理这几个。
错误码速查
| 错误码 | 含义 | VBA 报错时出现位置 | 解决 |
|---|---|---|---|
| 1004 | 对象不支持此操作 | Range / Cells 范围越界、用户没权限 | 检查 Range 参数;改用 .End(xlUp) 自动定位 |
| 9 | 下标越界 | Wb.Sheets(N) 当 N 超过实际工作表数 | 用 For 循环代替硬编码 N |
| 91 | 对象变量未设置 | Set Wb 失败但代码继续用 Wb | Set 后立即检查 Wb Is Nothing |
| 438 | 对象不支持该属性或方法 | 用了 Range.Sheets(...) 这种不存在的属性 | 查 MSDN 对象层级,明确属性归属 |
| 1004 + "无法访问该文件" | 文件被锁 | 另一个 Excel 进程在用此文件 | 关闭其它 Excel 进程,或用 Open ReadOnly:=True |
Office 365 / WPS / LibreOffice 兼容差异
- Office 365:VBA 和 Power Query 全部可用,是首选环境。Microsoft Excel for the Web(在线版)不支持 VBA,需要桌面版。
- WPS Office 个人版:VBA 需要单独装"VBA 宏插件"(免费,从 WPS 官方下载),不装就提示"该工作簿包含宏"但不能运行。Power Query 个人版没有,企业版部分支持。
- LibreOffice Calc:VBA 部分兼容(用 BASIC 重写),但许多 Excel-only API(如
Application.ScreenUpdating)不工作。pandas + python 路线在 LibreOffice 用户中更受欢迎。 - Mac 版 Excel:VBA 工作但路径分隔符要用
:不是\,需要改MyPath & Application.PathSeparator自动适配。Power Query Mac 版功能受限较多。
合并后的下游分析建议
合并完了通常下一步是分析。几个我反复用的模式:
- 按"源文件"做透视表:合并表里的"源文件"列正好是天然分组维度。透视表行:源文件,值:金额求和——一眼看哪个店铺/部门数据高。
- 用 Power Query 的"分组依据"做汇总:合并完直接在同一个查询里加 GroupBy 步骤,得到月度/年度汇总。
- 跑相关性:pandas 合并完直接
df.corr(),看各列之间的关联度。 - 导出给 BI 工具:pandas 输出为 Parquet 给 PowerBI / Tableau / Metabase 直读,比 Excel 链接快得多。
常见问题解答
VBA 宏跑到一半弹"无法访问",前面合并的数据还能保留吗?
原版宏不能——一报错就 End 了,前面合并到内存里的数据如果没保存就丢了。加固版有两个保险:① 错误处理让宏不中断;② 默认 ScreenUpdating=False 但 Calculation=Manual,意外终止时数据还在内存,可手动 Ctrl+S 保存目标文件。生产建议在循环里每处理 N 个文件就 ActiveWorkbook.Save 一次。
Power Query 合并速度慢,怎么优化?
三个常见加速点:① 在加载到表前用 Table.Buffer 缓存中间表;② 关闭"在加载时启用查询折叠预览";③ 把多个查询合并成一个 M 代码,减少中间步骤。极限场景是把数据合并落到 SQL Server / PostgreSQL,用数据库的 BULK INSERT。
pandas 读 Excel 报 "ImportError: Missing optional dependency 'openpyxl'"?
pandas 读 Excel 默认用 openpyxl 引擎读 xlsx,xlrd 读 xls。安装:pip install openpyxl xlrd。读 xls 还可能要 pip install xlrd==1.2.0,新版 xlrd 不支持 .xls 了。
合并后的总表行数超过 104 万了怎么办?
三种方案:① 分多个工作表(每张 100 万行);② 输出 CSV(CSV 没有行数上限);③ 输出 Parquet / Feather(列式存储,给 pandas / polars / DuckDB 直读,比 CSV 快 10 倍)。生产环境推荐 Parquet。
怎么把"源文件"列拆成多列(比如年/月/部门)?
命名规范化:让源文件命名遵循 2026-01_销售部_华东区.xlsx 这种结构。合并后用 pandas 的 str.split("_") 或 Excel 的"分列"功能,一行拆三列。前期命名规范的成本远低于后期清洗。
多人协作时怎么知道谁动了哪行数据?
合并表本身做不了审计——审计要在源文件层面。两种思路:① 源文件放共享存储(Git LFS / OneDrive / SharePoint),用版本控制看修改历史;② 在源文件里强制加一列"录入人",每行入数据时填名字。
VBA 合并完想自动发邮件给老板,怎么写?
用 VBA 的 Outlook 自动化(CreateObject("Outlook.Application"))发邮件附 .xlsx。代码网上很多。但更优雅的做法:合并产物落到 OneDrive 共享文件夹,给老板一个永久链接——下次合并直接更新文件,链接不变,邮件内容也不用每次重发。
每个源文件结构不一样(列数 / 列名 / 列顺序都不同),还能自动合并吗?
VBA 几乎做不了——VBA 只能按位置合并。Power Query 可以用"添加自定义列 + 转换"做映射,但代码会很复杂。pandas 最强:pd.concat 自动按列名对齐,缺失列填 NaN,无关列保留——只要每个文件里"列名"是有意义的(不是 Column1 这种无意义占位),合并都能正确。
有没有"零代码、零安装"的合并方案?
有——直接用在线工具,比如微软自家的 Excel 在线版 + Power Query for Web、Google Sheets 的 IMPORTRANGE 函数(但 Google Sheets 单文件限 1000 万单元格),或者用低代码工具如 Power Automate / Zapier 做工作流。零代码方案的局限是数据量上限低 + 处理速度慢,对 < 10 万行可用。
合并完想写回每个源文件加一个"已合并"标记列,怎么做?
VBA 在循环里给 Wb.Sheets(1) 加列然后 Wb.Save 即可。但要小心——如果源文件后续还要用,加列会破坏其原始结构。更优雅的做法是建立一个独立的"合并日志表"(哪些文件已合并、合并时间、合并行数),不动源文件。
权威参考资料
本文标题:《批量合并Excel工作簿到一张表:VBA宏/Power Query/Python pandas三套方案与真实坑》
本文链接:https://zhangwenbao.com/batch-merge-excel-workbook.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0