对手的外链你能抄哪些?反链差距分析就这么挖
本文目录
- 为什么照着对手的反链列表逐条抄,几乎一定白干?
- 竞争对手反链分析到底在分析什么?
- 先选对竞争对手——排名对手不等于链接对手
- 分析的三个产出物,不是一个链接清单
- link intersect为什么是命中率最高的那一刀?
- 为什么“链了多个对手却没链你”是强信号?
- 交集阈值怎么定,是2个对手还是3个?
- 实际跑一次link intersect是什么操作?
- 一条反链机会值不值得追,到底怎么打分?
- 把上千条砍到几十条的资格漏斗
- 资格打分该看哪几个维度?
- 这些机会该怎么分类,分别用什么打法去拿?
- 一个真实的反链差距分析是怎么跑下来的?
- 工具给的反链数据,能直接拿来就信吗?
- 反链差距分析里最常见的几个误判是什么?
- 找到机会,和持续盯着别让它漏,是两件事吗?
- 怎么把反链差距分析做成季度动作,而不是一次性项目?
- 常见问题解答
- 权威参考资料
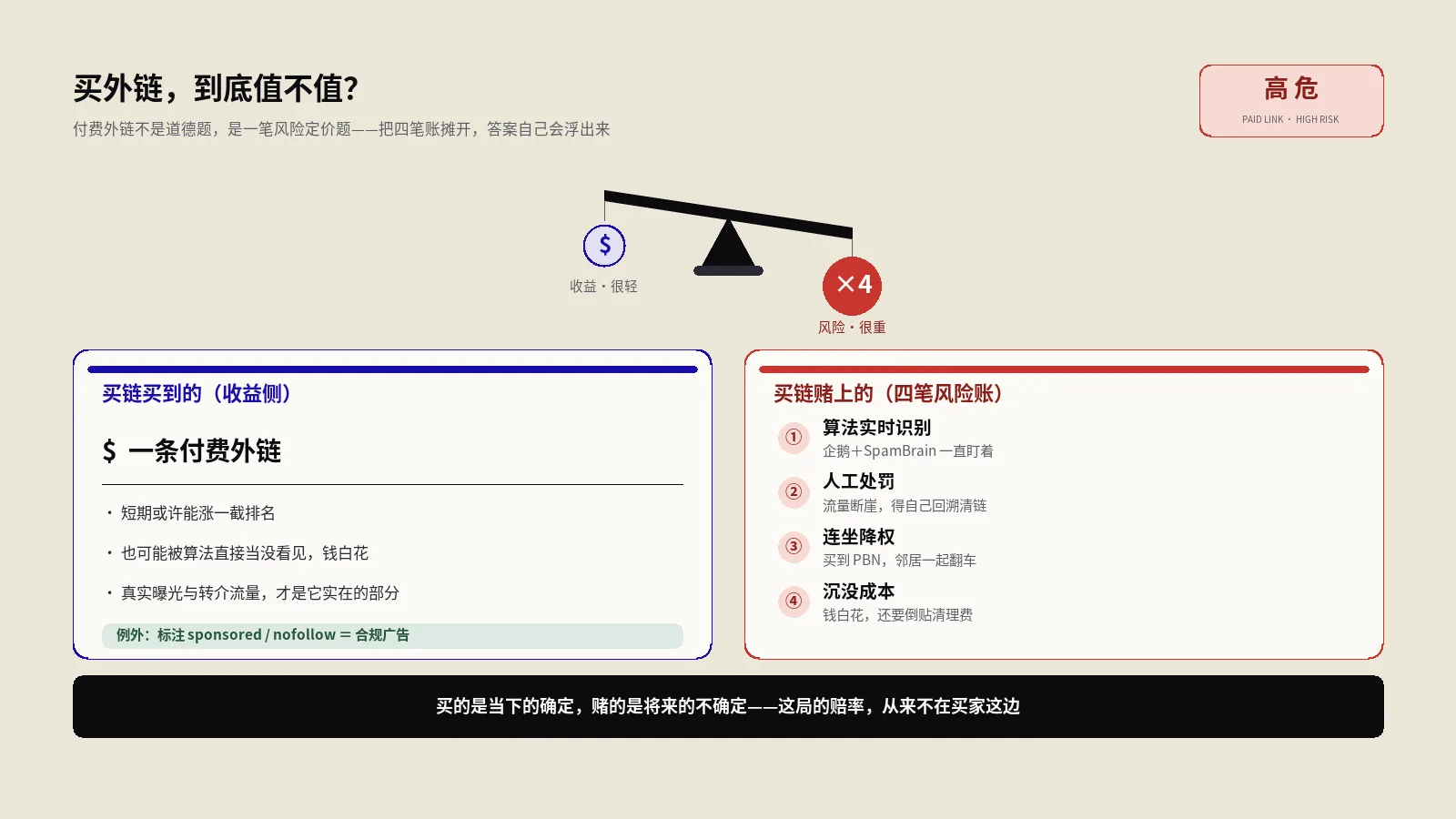
摘要:竞争对手反链分析的价值,从来不是把对手的链接列表逐条抄一遍——那张表看着几千条,真正你能复制的往往不到百分之五。它真正该产出的是三样东西:结构上你也够得着的获链来源、能持续吸链的内容资产缺口、值得进入的公关与关系territory。而命中率最高的一刀,是link intersect——那些同时链了你两三个对手、却偏偏没链你的站,它们已经被对手验证过愿意在这个领域给链接,只差一个理由。没有资格打分这道漏斗,你会把上千条线索全发一遍邮件,回报却集中在最初没筛出来的那十几条上。
几乎每个做外链的人都干过这件事:拿工具导出竞争对手的反链,几千上万条,越看越兴奋——“原来链接是从这些地方来的,照着做就行了”。然后真的开始照着做,发了几百封邮件,换来个位数的回复,最后拿到的链接寥寥无几。回头一看,真正成的那几条,根本不是当初列表里最显眼的,而是某种特定类型,当时还差点被划掉。
问题不在“分析竞争对手反链”这件事本身,它依然是外链里性价比最高的方向之一。问题在于绝大多数人做的根本不是分析,是抄作业;而且抄的还是一份大部分题目你根本没资格做的作业。把别人的反链当成一张待办清单,是这件事最贵的误解。
这篇保哥想把竞争对手反链差距分析这件事,从“导出一张表”升级成一套真正能落地的方法:怎么先选对要分析的对手,分析到底该产出什么(不是一个链接清单),为什么link intersect是命中率最高的切入点,怎么用一道资格漏斗把上千条砍到几十条还不误伤,不同类型的机会分别该用什么打法去拿,分析里有哪几个最常见的误判,以及怎么把它做成季度常态而不是一次性的体力活。看完你对“竞品外链”的认知会换一个层级。
先把一个认知钉死:反链差距分析的本质是“机会发现”,不是“链接复制”。你要从对手的反链结构里读出的,是这个赛道里链接被给出去的规律,以及这些规律里有哪些对你这个体量的站也成立。理解了这一点,下面所有的方法才接得住;理解不了,再多技巧也只是把抄作业抄得更熟练而已。
为什么照着对手的反链列表逐条抄,几乎一定白干?
要理解这件事,先得看清一个对手的反链档案里,到底混着哪几种性质完全不同的链接。把它们摊开,你会发现绝大多数对你毫无可操作性。
有一类是花钱买的或者付费投放带出来的,你抄不了,除非你也愿意付同样的钱、承担同样的风险。有一类是关系链接——创始人是某编辑的老朋友、投资方带来的资源、合作伙伴互链,这些挂在网页上看着和普通链接没区别,背后是你复制不了的人际资本。有一类是品牌报道,媒体写它是因为它本身是新闻——融资、爆款、行业第一,你没有那个由头,硬模仿只会显得拙劣。有一类是历史遗留,十年前互联网的给链门槛和今天完全不同,那批链接是在一个已经不存在的环境里攒下的。还有一类是它被收购、合并、迁移带过来的存量,根源压根不在它自己的运营动作里。
把这些刨掉,一个看似几千条的反链档案,结构上你真正“也够得着”的,常常只剩很薄的一层。如果你不先做这个分层,直接对着整张表发外联,结果是必然的:你把大量时间花在了结构上就赢不了的线索上,真正该重仓的那薄薄一层反而被淹没在噪声里没被认真对待。逐条抄的失败,不是执行不到位,是方向从一开始就错了——你在复制结果,而不是理解获取结果的机制。
这里有个特别值得记住的概念,保哥把它叫“可操作率”:一个反链档案里,结构上你真正复制得了的链接,占总量的比例。这个比例在不同对手身上差别巨大。一个靠资本和媒体关系堆出来的大牌,可操作率可能低到个位数百分比——它的反链档案对你基本是观赏性的;一个和你同段位、主要靠内容和正经外联攒链接的站,可操作率能高得多。先估这个比例,再决定要不要深挖某个对手,比一上来就导数据理性得多。一个低可操作率的对手,导出再多数据也只是在确认“你和它资源不对等”这件你早就知道的事。
另一个反直觉的点:链接的绝对数量几乎没有参考意义,结构才有。两个站可能反链域名数差不多,但一个是几百个相关行业站自然给的,一个是几千个泛目录和低质站刷出来的,后者数字更好看,可操作的、值得复制的机会反而更少。盯着对手反链域名总数焦虑,是这件事上最没必要的情绪——你要看的从来不是它有多少,是那些链接是从什么机制里来的。
竞争对手反链分析到底在分析什么?
把目标重新定义清楚:你不是在找“对手有哪些链接”,你是在从对手的反链结构里,反推出“在这个领域,链接是怎么被给出去的,哪些给链机制对你这个体量、这个资源结构的站也成立”。同样一份数据,前一种问法导出一张抄不动的清单,后一种问法导出一套可执行的策略。
先选对竞争对手——排名对手不等于链接对手
大多数人分析的对手选错了。你习惯性地盯着关键词排名上压着你的那几个,但排名对手和链接对手经常不是同一批。一个靠巨额品牌预算和媒体关系霸榜的大牌,它的反链档案对一个中小站几乎没有参考价值——你照着它做只会一次次确认自己资源不够。真正该重点拆的,是那些和你体量相近、起点相近、但反链结构明显比你健康的站:它们用得起的打法,大概率你也用得起。
所以选对手要分两类看。一类是“天花板对手”,看它是为了理解这个领域链接的上限长什么样、有哪些你现在够不着但值得记下的territory;另一类是“同段位对手”,这才是反链差距分析真正要榨干的对象——它们怎么从你也能进的那些地方拿到链接的。把这两类混在一起分析,是分析失真的头号原因。
同段位对手具体怎么选?给几个可操作的判据。其一,业务模式相近:同样是DTC品牌还是同样是内容站,获链机制差很远,别拿一个媒体站的反链去指导一个电商站。其二,起步时间和站点体量在一个量级:一个跑了十五年的站积累的历史链接,对一个三年的站没有可复制性。其三,反链结构看起来“干净且在生长”:相关行业来源占比高、近期还在持续有新链接进来,而不是几年前攒了一批之后停滞。其四,最好不是同一母公司或同一联盟下的兄弟站——它们之间的互链和共享资源会严重污染你的判断。按这四条筛出三到五个,比凭印象拍脑袋选准得多。
选三到五个而不是一个,也有讲究。单看一个对手,你分不清它某条链接是这个赛道的普遍机制,还是它一家的特殊操作。三五个放一起看,反复出现的来源类型才是这个领域真正的获链规律,只在某一家身上出现的,大概率是它的个性化资源、复制不来。这个“多对手交叉验证”的思路,正是下面link intersect的底层逻辑,这里先埋下。
分析的三个产出物,不是一个链接清单
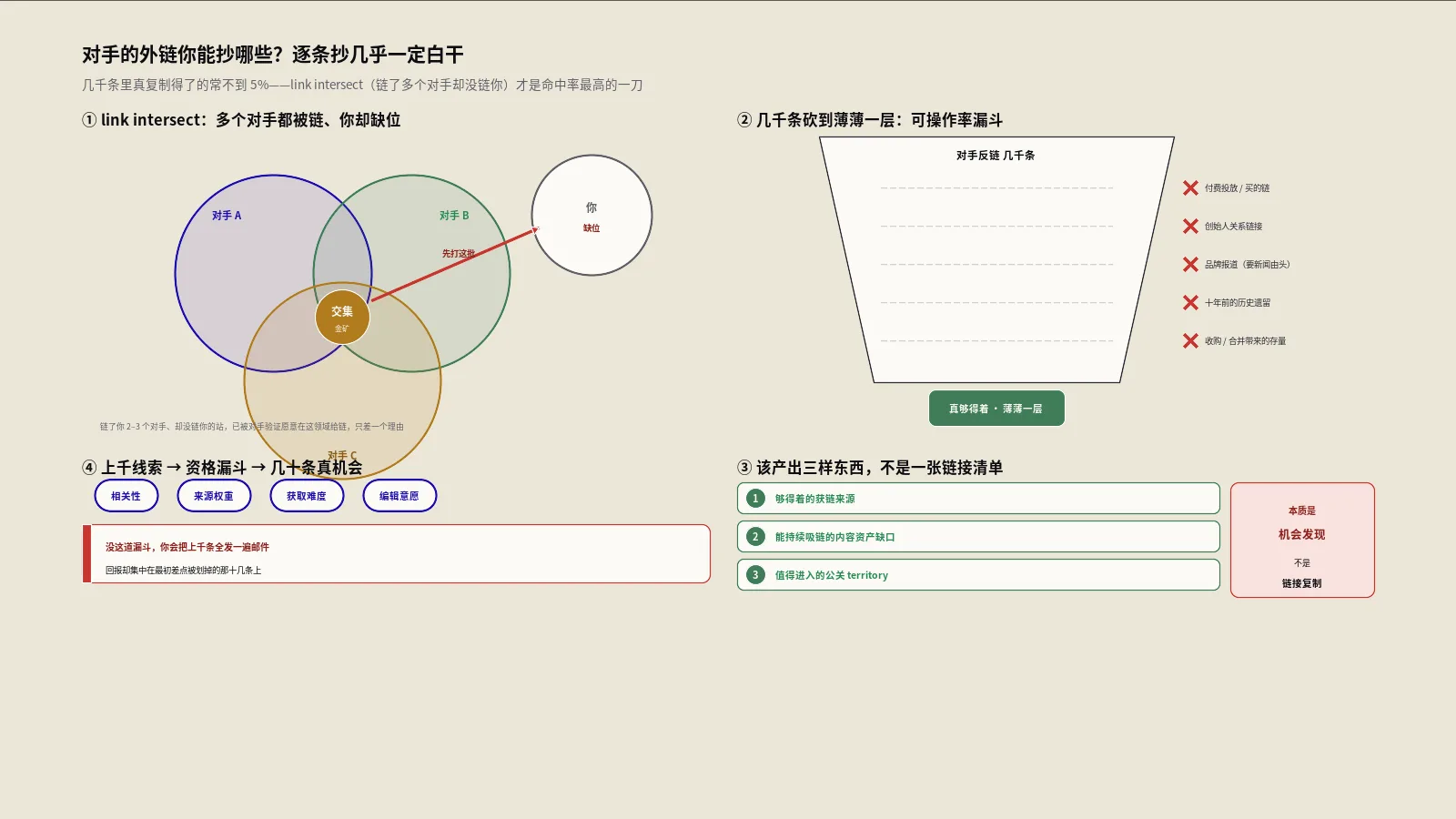
一次像样的反链差距分析,产出的不该是“待发外联列表”,而是这三样:第一,可复制的获链来源——那些结构上对你开放、对手已经验证过会给链的站点和页面类型;第二,内容资产缺口——对手有某个能持续被引用的东西(一份数据、一个工具、一个权威指南),你没有,所以这一整类链接你天然拿不到,得先把资产补上;第三,关系与公关territory——你暂时够不着但值得长期布局的媒体、社区、行业节点。把竞争对手反链放进一个更完整的逆向框架里看会更清楚,链接只是对手可被逆向的几层结构之一,怎么系统拆解对手的内容、链接、实体结构,是一个更大的方法论:竞品逆向分析框架怎么系统拆对手,本文是把其中“链接”这一层挖到底。
这三个产出里,最容易被忽略、价值却最高的是“内容资产缺口”。它的发现方式很特别:当你在对手反链里反复看到一批站,链的都是对手的某一个特定页面——一份调研、一个计算器、一份成为行业默认引用的清单——而你没有任何东西对得上它,这就是一个被点名的资产缺口。它不是“你少做了几次外联”,是“你少了一个会自己生链接的东西”。普通分析者看到这批链接,会把这批站列进待联系名单然后徒劳地发邮件;真正读懂的人会意识到:这批链接的根因是那个资产,名单是果不是因,该补的是因。能不能从对手反链里读出资产缺口,几乎是区分“抄作业”和“做分析”的分水岭。
link intersect为什么是命中率最高的那一刀?
如果反链差距分析只让你掌握一个技术,那就是link intersect——链接交集。它的定义很简单:找出那些同时链接了你的两个或更多竞争对手、却唯独没有链接你的域名。这个集合,是整个分析里信噪比最高的一块。
为什么“链了多个对手却没链你”是强信号?
拆开看这个集合自带的几重资格。第一,它已经被验证愿意在你这个领域给出链接——不是猜测,是它已经链了你的对手,行为发生过。第二,它链的不是一个而是多个对手,说明它给链不是一次性的偶然,是这个站本来就在持续覆盖、推荐这个领域的东西。第三,它没链你,意味着这是一个明确的、尚未兑现的缺口,而不是一个你已经拿到、再去争没有增量的位置。一个普通的反链线索,这三件事你都得从零验证;link intersect的线索,三件事开局就成立了。这就是为什么同样发一百封外联邮件,从intersect名单里发,回报率经常是从原始大列表里发的好几倍。
它还顺带帮你过滤掉了前面说的那些抄不动的类型。买的链接通常不会精准地“同时投给多个竞品又独漏你”;纯关系链接也很少呈现这种多对手覆盖的形态。能同时链多个对手的,往往是那些本来就在做行业资源整理、横向评测、领域目录、持续报道这个赛道的站——而这些,恰恰是结构上对你也开放的那一层。
交集阈值怎么定,是2个对手还是3个?
阈值不是越高越好。设“同时链3个以上对手”,名单会很短、质量极高,适合资源紧、只想打必中之仗的阶段;设“同时链2个对手”,名单变长、命中率略降但机会量上来,适合要规模化铺的阶段。更聪明的做法是分层:3个以上的进“高优必追”池,单独定制化外联;恰好2个的进“批量验证”池,先轻量触达测水温。一个常见误区是把阈值一刀切死,要么名单太窄错过大量可拿的,要么不分层把高价值线索和一般线索用同一种粗放方式群发,把本该精打的机会浪费掉了。
实际跑一次link intersect是什么操作?
把它落到动作上,并不复杂。准备好两组域名:一组是你筛定的三到五个同段位对手,一组是你自己。用反链工具的链接交集功能(多数主流工具都有这个能力),让它列出“链接了对手组里至少两个、但没有链接你”的域名。导出来这份原始名单,就是你后面所有工作的起点。它通常有几百到上千条,看似很多,但记住——这已经是过滤掉了海量噪声之后、信噪比最高的那一块原料了,真正的功夫在后面的资格漏斗。
有几个边界情况会让intersect名单失真,必须人工识别。一是“伪交集”:链向多个对手的,其实是同一张联盟网络、同一个内容联合分发源、或者同一家公关公司批量投放的稿子被多站转载——它看着像优质交集,本质是一个你复制不了的单一来源被算成了多个。二是导航和全站性链接:某些站在页脚或侧栏全站挂着指向对手的链接,这种交集对你参考价值很低。三是时间错配:对手的这些链接是好几年前在不同环境下拿的,今天同样的来源未必还给链。把这三类先标出来排掉,剩下的intersect名单才是真正干净的进攻原料。
一条反链机会值不值得追,到底怎么打分?
就算是intersect筛出来的名单,也不能闭眼全追。你需要一道资格漏斗,把名单按“值不值得花外联成本”再砍一刀。这一步决定了你的外联投入是集中在高回报线索上,还是平摊在大量根本成不了的线索上。
把上千条砍到几十条的资格漏斗
漏斗从粗到细分几道闸。第一道是真实性:这个链接现在还活着吗、是不是软删除、是不是放在一个早就没人看的死页面上——很多工具数据里的链接,导出来时早已不复存在或失去价值。第二道是相关性:链接所在的站和页面,主题和你沾不沾边,一个完全不相关的站给你链,价值低还可能有反效果。第三道是可获取性:你有没有一个让对方愿意链你的合理由头——如果对手是靠一份独家数据被链的,而你什么都没有,这条线索现在对你就是不可获取的,得先补资产。第四道是风险:这个链接来源本身干不干净,会不会把你拖进有毒链接的池子。这四道闸过下来,上千条砍到几十条是常态,而剩下的这几十条,质量远胜原始名单的前几百。
资格打分该看哪几个维度?
| 维度 | 要问的问题 | 该降级或淘汰的情况 |
|---|---|---|
| 真实在线 | 这个链接现在还活着、还在被收录吗? | 已失效、软404、所在页面早已死掉 |
| 主题相关 | 来源站和页面跟你的领域沾边吗? | 完全无关领域、内容农场、链接交易站 |
| 可获取性 | 你有没有让它愿意链你的现成由头? | 需要一个你还没有的资产或新闻由头 |
| 链接类型 | 是编辑自然给的,还是某种你复制不了的型? | 纯付费、纯关系、收购存量、历史遗留 |
| 权重质量 | 这个来源传递的权重值不值得花外联成本? | 权重极低、出链泛滥、明显被压制 |
| 风险 | 追这条会不会反而引入有毒链接风险? | 来源处在已知的垃圾链接网络里 |
这套打分不必做成精密的数值模型,反而会被假精确误导。更实用的是三档分诊:六个维度里只要“可获取性”或“风险”任一项触雷,直接淘汰,不进名单,不浪费一秒;其余的,按相关性和权重质量粗分成“高优必追”“批量验证”“长期观察”三档。高优档值得为每一条写定制化的接触理由;批量验证档用轻量、可规模化的方式先试水温;长期观察档只记录、定期回看,现在不动。分诊的意义不是把每条线索算出一个小数点后两位的分,是让你的精力按回报梯度分配——把最贵的人工花在最可能成的那一小撮上,这比任何评分公式都重要。
“权重质量”和“风险”这两栏,本质是一次小型的链接估值,不能凭来源域名看着大就追、看着小就丢。怎么给一个潜在链接来源估值、怎么识别该躲开的有毒来源,是一套独立的判断标准,前移到这里复用正好:怎么先估值后处理别自伤的有毒外链审计,把它的估值标准当作资格漏斗最后两道闸来用,能避免你辛苦追来一批反而拖累自己的链接。
这些机会该怎么分类,分别用什么打法去拿?
过完资格漏斗,剩下的几十条不是同一种东西,硬用同一套外联模板群发,转化率会很难看。按“它为什么会给链”分类,再对应不同打法,是把命中率再抬一截的关键。
第一类是资源页与失效链接型:对方页面本来就在收集这个领域的资源,或者它引用的某个链接已经失效。这类的打法是“帮它把页面变得更好”——补一个它缺的优质资源,或者指出它的死链并提供替换。这是结构上最干净、成功率最稳的一类,值得优先打。
第二类是数据与工具引用型:对手被链,是因为它有一份被反复引用的数据、一个好用的免费工具、一份成为行业默认参照的指南。这类你没有对应资产就根本无从下手——它不是外联能解决的,是内容资产缺口。你得先把那个值得被引用的东西做出来,链接才会自己发生。什么样的内容能持续被动吸链、数字公关怎么把它放大,是这类机会的前置工程:为什么有的内容能自动被链,先把资产补齐,这一整类机会才对你打开。
第三类是行业目录、榜单、横向评测型:对方在做赛道盘点,把对手收了没收你。这类打法是“证明你够资格被收进去”——不是去求收录,而是先确保你在它收录的那个评判维度上确实达标(有真实用户、有可验证的数据、有它栏目要的那类信息),再用一封“我们符合贵榜单的XX标准,资料如下”的邮件把举证成本降到最低。它要的不是说服,是省事,你把它该核的信息打包好,收录概率会高很多。
第四类是内容共创、客座、专家引述型:靠的不是页面,是你这个人或这个团队的专业可信度。打法是先建立可被识别的专家身份(公开的观点输出、可查的过往、明确的细分领域),再去对接,对接时给的是“我能为你的读者补上你现在缺的那块专业视角”,而不是“能不能给我个链接”。这类慢,但一旦建立,壁垒极高,对手很难抢走。第五类是关系与公关territory型:短期拿不到,别硬耗,归入长期布局清单,定期重访,等你攒够由头再启动。把每一条线索贴上类型标签,再按类型排打法和优先级,比一份不分型的群发名单有用十倍——同样的人力,结构化分型之后的产出经常是无差别群发的数倍。
这里还有一条贯穿所有类型的原则:每一类打法的核心,都是“先让自己值得被链,再去要”。资源页要你真有值得被收的资源,目录要你真达标,专家引述要你真有专业沉淀。反链差距分析能告诉你机会在哪、缺口是什么,但它替代不了你得先有让人愿意链的东西。这也是为什么分析的产出里,“内容资产缺口”那一项往往比“可打来源清单”那一项更值钱——前者指向的是结构性能力,后者只是一批待执行的活。
一个真实的反链差距分析是怎么跑下来的?
讲一个保哥手里跑过的例子,一个出海做园艺与户外种植工具的DTC品牌。它的处境很典型:内容发了不少,自然链接却长期攒不起来,团队一度想直接买一批了事。
第一步没有急着导数据,而是先分对手。把“天花板对手”(一个有大量园艺媒体关系的老牌)单独拎出来只做参考,重点锁定三个和它体量相近、但反链结构明显更健康的同段位站。第二步对这三个站跑link intersect,找同时链了其中两个以上、却没链这个品牌的域名。原始intersect名单有几百条。第三步过资格漏斗,刷掉失效的、无关的、纯付费纯关系的、有毒的,名单瘦到几十条。第四步给这几十条贴类型标签,结果分布很说明问题:相当一部分是园艺类资源页和失效链接机会,这类直接可打;另一部分集中在“它们引用了对手的一份种植季节数据/一个工具”,意味着这个品牌缺的不是外联力度,是一个值得被引用的资产。
团队最后做的事很克制:资源页与失效链接那批立刻按定制化打法推进,稳扎稳打地拿;数据引用那一类不强追外联,而是反过来立项做一个对方都没有、面向他们目标市场的种植决策小工具,把吸链交给资产本身。这里没有任何“群发上千封邮件”的悲壮,整个动作的杠杆点,是分析阶段就把“能直接拿的”和“得先补资产才能拿的”分开了——这正是逐条抄列表那套永远得不到的判断。
为什么是做工具,而不是把那几十个引用对手数据的站逐个去邮件公关?这是分析里最关键的一次判断。那些站之所以链对手,是因为对手提供了一个它们写文章时需要顺手引用的东西;它们要的不是“认识谁”,是“手边有没有可引的东西”。在这种结构下,外联本质上是在请求别人为一个还不存在的理由给你链接,转化率注定极低。而一旦那个值得引用的工具上线,同样这批站、加上更多本来没在名单上的站,会在它们自己写内容时主动引用——获取动作从“你追着几十个人要”变成了“资产在持续替你要”。同样投入下,后者的杠杆完全不在一个量级。这就是为什么前面反复强调,分析的产出里“资产缺口”比“待打清单”更值钱:它指向的是把外联从体力活变成复利的那个开关。
还有一个容易被跳过的细节:这个案例里,团队没有去碰那个“天花板对手”的反链。它的链接大量来自园艺媒体的长期关系和品牌报道,可操作率极低,深挖只会得出“我们没有它那些关系”这种早就知道的结论。把分析火力集中在三个同段位对手身上,是这次没有把时间浪费掉的另一半原因——选错分析对象,再好的方法也只是在精确地做无用功。
工具给的反链数据,能直接拿来就信吗?
整套方法建立在工具导出的反链数据上,所以必须清醒:这些数据没有一家是全的,也没有一家是绝对准的。不同工具的链接索引覆盖差异很大,A工具看到的反链B工具可能根本没收;导出的链接里有相当比例是历史快照,导的时候早已失效;dofollow和nofollow、链接在页面里的位置和权重差异,列表里那个数字一概体现不出来。
举个具体后果:你只用一家工具跑intersect,它的索引恰好没收某个其实链了你的站,于是这个站被误算进“没链你”的缺口,你兴冲冲去外联,对方回一句“我们早就链过你了”,一次本可避免的尴尬,根源就是单源数据的覆盖盲区。反过来,另一家工具漏收了某批确实链了多个对手的优质站,你的高价值机会就这么被静默漏掉,你甚至不知道自己错过了什么。所以两条纪律不能省。一是交叉:关键判断别只信一家工具,多源比对,尤其是intersect这种依赖“有没有这条链接”的判断,单一数据源很容易漏或者误报。二是抽验:进入高优池、要投入定制化外联的线索,挨个人工打开实际页面确认链接真实存在、位置合理、来源没问题,再花外联成本。把工具数据当成“线索来源”而不是“事实结论”,是这套方法不翻车的底线。在这个判断上吃过亏的人都知道,省掉抽验这一步省下的时间,最后都加倍还回去了。
反链差距分析里最常见的几个误判是什么?
方法对了,判断错了,照样白做。保哥见过最多的几类误判,单独拎出来提醒一下,因为它们都披着“在认真分析”的外衣。
第一个是把品牌报道当成可复制机会。对手因为融资、获奖、出了爆款被一批媒体写了,你看到一长串高权重新闻链接很眼红,于是把它们全列进待办。问题是这些链接的根因是“它发生了一件新闻”,不是“它做了一个外联动作”。你没有那个由头,把它们列进名单只会让你的可操作名单虚胖、注意力被稀释。第二个是忽略链接的时间语境。对手三年前增长曲线陡峭那段时间集中拿到的链接,往往伴随着当时的话题红利、当时的关系、当时还宽松的给链门槛,脱离那个时点单看链接本身,会高估今天复制它的可能性。
第三个是只数域名不看获链机制。前面说过,反链域名总数是最没用的虚荣指标,但它特别容易变成汇报里的主角,导致整个分析的目标被悄悄替换成“把数字追上对手”,而不是“补上结构性的获链能力”。第四个是用单一工具的数据下死结论。尤其是intersect这种强依赖“某条链接到底存不存在”的判断,单一数据源的覆盖盲区会直接让你的名单要么漏掉真机会、要么塞满早已不存在的幽灵链接。第五个,也是最隐蔽的:分析做得很漂亮,但从不回头看“缺口有没有真的在收窄”,于是每个季度都在重新发现同样一批机会,动作却从没真正落地。把这五个误判贴在分析流程旁边,能挡掉这件事八成的无用功。
找到机会,和持续盯着别让它漏,是两件事吗?
很多人把反链工作笼统当成一件事,其实它至少是两件性质不同的事,需要分开管。反链差距分析解决的是“获取”——从无到有地发现并拿下新链接机会,它是进攻性的、项目式的、节奏偏快的。而你已经拥有的那些反链会老化、会失效、会被对方删,盯着它别一直往下漏,解决的是“留存”——它是防守性的、常态化的、节奏偏慢的。这两件事用的数据视角、节奏、甚至负责的人都可能不一样。
把它们混为一谈的代价是:要么你只顾扩张,老链接漏了一地没人管,等于一边进水一边漏水;要么你只盯着存量维护,从不主动开拓,反链结构慢慢被持续进攻的对手拉开。反链是会折旧的资产,存量怎么盯、怎么及时发现流失和回收,是和本文互补的另一半:反链是会折旧的资产没人盯就一直在漏。本文负责帮你把新机会找出来,那一篇负责帮你别把已有的弄丢,两件事都做,反链结构才是真的在变好。
怎么把反链差距分析做成季度动作,而不是一次性项目?
最后一个常被忽略的点:反链差距分析不是做一次就一劳永逸的。竞争格局在动——对手在持续拿新链接,新的intersect机会在不断生成,你已经拿下的会从缺口里消失,你的对手名单本身也会变。一次性项目的产出,三五个月后就开始过期。
可持续的做法是把它压缩成一个固定节奏的轻量动作:每季度重跑一次intersect,对比上一季,重点看新增了哪些“多对手覆盖却仍没链你”的机会、以及你这一季实际拿下了多少、缺口在不在收窄。这个季度看板只需要放四个数:仍存在的缺口规模(多对手覆盖未链你)、本季新生成的机会数、本季实际拿下并验证在线的数、以及对手反链结构相对你的领先幅度变化。不需要放反链域名总数这种虚荣指标,它只会把注意力带偏。看板的唯一目的是回答一个问题——“那道缺口在变小还是变大”,其余的数字都是噪声。
把这个产出直接接进内容和公关路线图——发现的资产缺口变成内容选题,发现的可打来源变成外联排期,而不是让它躺在一个没人再打开的表格里。谁负责重跑、谁负责把机会转成行动、用什么口径衡量缺口收窄,这几件事定下来,反链差距分析才从“某次心血来潮的大扫描”变成一台持续产出链接机会的发动机。判断它有没有真的起作用,看的不是你扫出了多少条线索,而是季度对比里那个“对手有你没有”的缺口,是不是在稳定变小。
常见问题解答
问:竞争对手反链分析就是把对手链接导出来照着做吗?
答:不是,那恰恰是最常见的失败做法。对手反链里大部分是付费、关系、品牌报道、历史遗留、收购存量这些你复制不了的类型。分析的真正产出是可复制的获链来源、内容资产缺口和公关territory,不是一张待办列表。
问:link intersect到底指什么,为什么命中率高?
答:指同时链了你两个或更多竞争对手、却没链你的域名。它开局就自带三重资格:已验证愿意在你领域给链、不是偶然一次、且是明确未兑现的缺口。普通线索这三点要从零验证,所以同样外联,intersect名单回报常高数倍。
问:分析竞争对手时,对手该怎么选?
答:分两类。天花板对手只做参考,理解链接上限和territory;同段位对手(体量相近但反链更健康)才是榨取重点,它们用得起的打法你大概率也用得起。把两类混在一起分析,是结论失真的头号原因。
问:intersect名单很长,全部发外联可以吗?
答:不行。要先过资格漏斗:真实在线、主题相关、可获取性、链接类型、权重质量、风险六道闸。上千条砍到几十条是常态,剩下的质量远胜原始名单,外联成本要集中在这几十条上。
问:发现对手靠一份数据或工具被大量引用,我该怎么追?
答:这类追外联没用,它是内容资产缺口。对方被链是因为有个值得被引用的东西,你没有就拿不到这一整类链接。正确动作是先把对应的可被引用资产做出来,让吸链由资产本身发生。
问:工具导出的反链数据可以直接信吗?
答:不能。各家索引覆盖不同、含大量已失效的历史快照、权重和位置差异列表里看不出。纪律是交叉比对多源、对高优线索人工抽验实际页面,把工具数据当线索来源而非事实结论。
问:反链差距分析和反链监控是一回事吗?
答:不是。差距分析负责“获取”——从无到有发现并拿下新机会,进攻性、项目式;监控负责“留存”——盯着已有反链别老化流失,防守性、常态化。两件事节奏和视角都不同,只做一件反链结构都会出问题。
问:这套分析多久做一次合适?
答:按季度做成固定轻量动作,不是一次性项目。每季重跑intersect、对比上一季新增机会和缺口收窄情况,并把资产缺口接进内容选题、可打来源接进外联排期。判断有没有用,看缺口是否在稳定变小。
权威参考资料
本文标题:《对手的外链你能抄哪些?反链差距分析就这么挖》
本文链接:https://zhangwenbao.com/competitor-backlink-gap-link-intersect-prospecting.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0