关键词排名监测为什么对不上?换台设备就全变的6大原因
本文目录
- “这个词我排第几”这个问题,为什么本身就问错了?
- 同一个词,排名为什么每次查都不一样?
- “平均排名”这个指标,到底藏了什么?
- 比“排第几”更该看的,是可见度份额
- 结果页一大半已经不是自然结果,排名还能代表流量吗?
- 排名监测该怎么设计才可信?词、地点、设备、频率怎么定?
- 选词:不是越多越好,是分层后挑决策相关的
- 地点和设备:绑死你真实的人在哪、用什么
- 频率:对齐决策节奏,别和噪音赛跑
- 搜索后台的位置和第三方工具的排名为什么对不上,该信谁?
- 排名掉了,第一步该排查的是真掉了还是测量在骗你?
- 排名数据该驱动哪些决策,不该碰哪些?
- 这套测量和工具数据校准、排名波动归因是什么关系?
- 点击衰减曲线怎么用,为什么不能套一条通用曲线?
- 只盯自己的可见度份额够吗?竞争视角怎么加进来?
- AI摘要出现之后,“排名”这件事又被改写了一次
- 每个词的结果页该怎么记录,监测才有据可查?
- 多地点多设备的监测矩阵,怎么设计才不会爆炸?
- 一个真实感很强的例子:被“平均排名上升”骗掉一个季度
- 常见问题解答
- 权威参考资料
摘要:“这个词我排第几”在今天已经没有唯一正确答案。换个地点、换台设备、换个人去搜,同一个词的名次就不一样;再加上结果页里一大半已经不是自然结果,单一一个“排名数字”早就代表不了你真实的可见度。拿它当核心指标做决策、做汇报、发奖金,等于用一把刻度会自己变的尺子量身高,量出来的“进步”很可能是尺子在动。可信的排名测量,测的从来不是“第几名”,是“在我真正在乎的人群和场景里,我占住了多少能被看见的份额”。
几乎每个团队都有一张排名监测表,红红绿绿,每天有人盯。可真要追问一句“你这个排名是哪台设备、在哪个城市、有没有登录、什么时候、结果页长什么样的情况下的第几名”,多数人答不上来。答不上来,这个数字就没法支撑任何严肃决策——它不是错,是没定义。
这篇想把排名测量这件事掰开讲清楚:为什么“排第几”这个问题本身就问得不严谨、同一个词的排名为什么每次查都不一样、“平均排名”这个看似中立的指标藏了什么、比名次更该看的可见度份额是什么、结果页非自然化之后排名和流量怎么脱钩、排名监测该怎么设计才可信、自家搜索后台的位置和第三方工具的排名为什么对不上该信谁,以及排名数据到底该驱动哪些决策、不该碰哪些。
“这个词我排第几”这个问题,为什么本身就问错了?
排名在很多人脑子里还是个标量:一个词,一个数字,今天第八明天第五。这个心智模型停在十几年前。今天的搜索结果是按人、按地、按设备、按时刻实时拼装出来的,同一个词在不同条件下根本不是同一张结果页,自然也就没有一个跨条件通用的“第几名”。
把它类比成体重就好理解了。你问“我多重”,得说清是早上空腹还是晚饭后、穿没穿衣服、哪台秤。不交代这些,“我多重”这个问题没法回答。排名一样:不交代地点、设备、登录态、时间、结果页形态,“我排第几”同样没法回答。问题不在于答案难找,在于这个问题在没有限定条件时根本不成立。承认这一点,是把排名测量做对的起点——你要测的不是一个虚构的通用名次,而是一组明确限定条件下的可见度。
同一个词,排名为什么每次查都不一样?
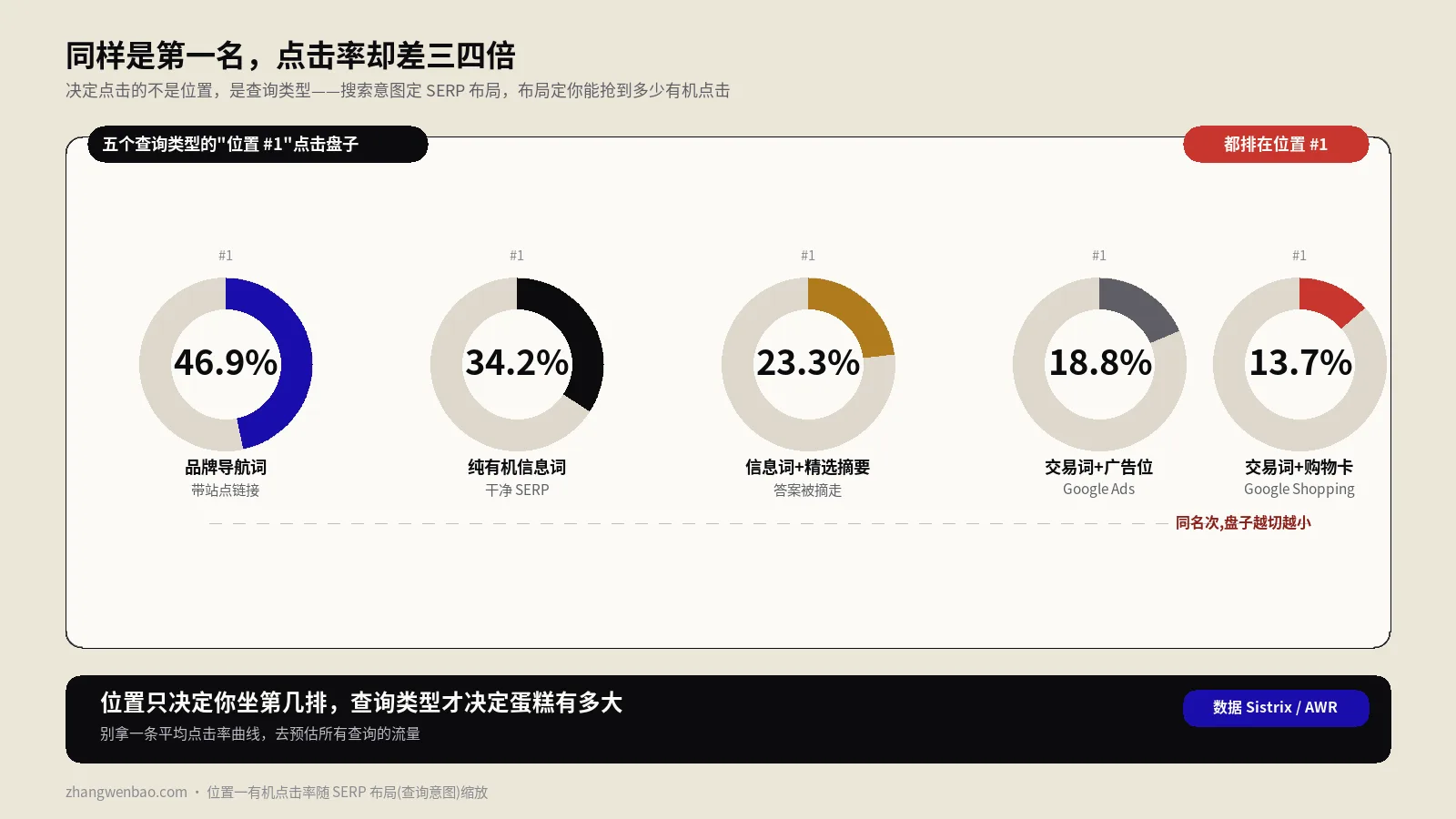
很多人第一次认真比对会被吓到:同一个词,自己电脑搜是第六,手机搜是第十一,让外地同事搜又变成第四。这不是工具坏了,是排名本来就因人因场景而变。变量大致有这么几类。
| 变量 | 怎么影响名次 | 常被忽略的程度 |
|---|---|---|
| 地理位置 | 城市甚至街区级别都会改结果,本地意图词尤其剧烈 | 最常被忽略,却往往是最大变量 |
| 个性化历史 | 登录态、过往点击与访问会重排你看到的结果 | 自己搜自己网站常年偏高,最容易自我欺骗 |
| 设备 | 手机和桌面是两套结果与两套点击分布 | 只看桌面排名,丢掉了大半真实流量场景 |
| 查询时间 | 结果页随新鲜内容、活动、新闻实时变动 | 不同时点抓的快照当成同口径对比 |
| 结果页构成 | 有没有精选摘要、商品组、AI摘要会改自然区起点 | 名次没变,自然结果的实际位置却被推下去了 |
| 数据中心与实验 | 同一时刻不同机房、不同实验分桶结果可能不同 | 把正常抖动误读成排名异动 |
这里面最坑人的是个性化历史。你天天在自己电脑上搜自家词、点自家站,搜索引擎学会了“这个人爱看这个站”,于是常年把你抬得很高。你看着自己排第二,心里踏实,真实用户那边可能在第九。用没登录、没历史、干净环境去看,是排名测量的基本卫生,可惜大量团队的“我们排得挺好”,是在被个性化喂了糖的环境里得出的幻觉。
明白了变量这么多,就能推出一个关键结论:排名天然是个分布,不是一个点。正确的问法不是“我排第几”,而是“在我目标人群所在的地区、他们用的设备、干净环境下,我这个词的名次分布大概落在哪个区间”。把分布硬压成一个数字汇报,信息已经在那一步丢光了。
“平均排名”这个指标,到底藏了什么?
搜索后台给的“平均排名”看起来客观又省事,于是成了汇报里最常被引用的数字。但它是个被高度压缩、极易误读的指标,藏了至少两层东西。
第一层,它是跨大量查询、地区、设备、按展现加权平均出来的。一个页面可能为成百上千个查询出现过,平均排名把这些全摊平成一个数。第二层,也是最致命的——它会被查询组合的变化污染。这就是混合效应:当一批新的长尾词开始有少量展现、且名次还不错,它们会把整体平均排名拉高,看着像“整体进步”,可你真正赚钱的那几个头部词可能纹丝没动甚至在退。反过来,平均排名变差,也可能只是因为你新覆盖了一批排名靠后的长尾词,核心词其实更好了。
结论很反直觉但必须记住:平均排名上升不代表你重要的词变好了,平均排名下降也不代表变差了。它是一个被混合效应严重干扰的聚合数,适合当一个粗略的体温计扫一眼趋势,绝不适合单拎出来当成败结论,更不能用它发奖金、定KPI。任何严肃判断都要下钻到按词、按词的商业价值分层之后再看。
比“排第几”更该看的,是可见度份额
既然单一名次不可靠、平均排名会骗人,该用什么?答案是把视角从“某个词的名次”换成“在一组我在乎的词上,我占了多少能被看见的份额”,也就是可见度份额。
它的算法思路不复杂:先选定一组对业务真正重要的词,给每个名次按它的真实被看见概率配一个权重(第一名权重远高于第十名,这条点击衰减曲线很陡),再用你的实际名次去对照,加权汇总,得到你在这组词上整体占了多大的“可被看见”的盘子。它比单一名次好在三点:一是天然是组合视角,不会被单个词的抖动带偏;二是用位置权重而不是名次本身,把“第三名和第一名差距远比第三名和第五名大”这个非线性如实反映出来;三是可以按词的商业价值再加权,让赚钱的词在指标里说话更重,而不是和无关长尾一人一票。
用可见度份额,你汇报的就不再是“某词从第八到第五”这种孤立、易被质疑的点,而是“在核心交易词这组上,我们能被看见的份额从四成涨到了五成五”——这是一个能直接和流量、生意挂上钩、也经得起追问的量。当然它也有前提:选词必须诚实,把一堆自己本来就排第一的品牌词塞进去凑高份额,是自己骗自己,这点后面讲测量设计时还要再强调。这里多提醒一个容易被忽略的算法陷阱:算份额时,分母用的“可被看见的总盘”必须把非自然区块占掉的那部分也算进去,不能假装结果页只有十个蓝链。如果结果页顶上有AI摘要和商品组,真实能被自然结果分到的注意力本就只剩一小块,分母还按“满分十个自然位”算,会系统性高估自己的份额,得出一个比真实可见度乐观得多的数字,反而比不算更误导。份额这个指标,分子分母都得诚实,它才比单一名次可信。
结果页一大半已经不是自然结果,排名还能代表流量吗?
就算你把名次测准了,还有一道更狠的脱钩:你排自然第一,不等于你拿到第一位的点击。因为今天结果页的第一屏,自然结果常常被挤到很靠下的位置。
精选摘要、知识面板、商品组、本地地图包、视频区、“大家还问”、再到顶部的AI摘要,这些非自然区块一层层往下压,真正的自然第一名,像素上可能已经在用户要往下滚很久才看得到的地方。这就带来两个必须分开看的概念:名次位置是“你在自然结果里的第几个”,像素位置是“用户实际要滚到屏幕多深才看见你”。名次没变、像素位置却被新增的区块推下去,是排名表上看不出、流量却实打实在掉的典型情形。
更进一步,很多结果页用户压根不用点进任何网站,答案在AI摘要或精选摘要里就拿到了,这部分需求的点击根本不发生。这时候你那个词排第一的“价值”,和三年前排第一的价值完全不是一回事。所以看排名必须连着看:这个词的结果页是什么构成、自然区起点被压到多深、有多少点击在落地前就被截走。把这些和单纯的名次脱开看,你会系统性高估自己的可见度。点击在落地前被吃掉这件事该怎么单独算账,可以接着看零点击搜索的品牌影响怎么度量那一套,和这里是配套的。
排名监测该怎么设计才可信?词、地点、设备、频率怎么定?
讲清了各种坑,落到怎么搭一套可信的监测。核心心态转变是:监测配置不是“把词都塞进去看名次”,它是一次抽样设计,每一个选择都决定了你测出来的东西能不能代表真实。
选词:不是越多越好,是分层后挑决策相关的
把几千个词全扔进去每天看,是噪音工程,不是监测。该做的是先按商业价值分层:直接带成交的核心交易词、带认知和线索的中层词、量大但价值散的长尾,分开建组、分开看,绝不混进一个平均数。每一层只挑能驱动决策的代表性词去精细盯,长尾用聚合份额看趋势就够。把自家一搜就第一的品牌词单独隔开,别让它们混进非品牌组虚抬份额——这是测量诚实性的底线。
地点和设备:绑死你真实的人在哪、用什么
监测的地点要对齐你真实客户的地理分布,而不是图省事用一个默认大区。做本地或区域生意的,必须按目标城市分别测,用一个全国默认值会把本地词测得毫无意义。设备要按你真实流量的移动与桌面占比分别测、分别看,只测桌面等于对大半用户视而不见。这两项一旦设错,后面所有数字都是精确的错误。
频率:对齐决策节奏,别和噪音赛跑
很多团队每天甚至每小时刷排名,然后被正常抖动牵着情绪走。排名有大量日内、机房、实验级别的噪音,刷得越密,看到的噪音越多,真实信号反而被淹没。合理的频率应该对齐你的决策节奏:要做的是周、月级别的趋势判断,就按周看;只有在排查一次明确的疑似异动时,才临时加密采样去定位。把高频抖动当信号去反应,是排名监测最大的精力黑洞,也是团队最常见的自我消耗——这一点和理解排名为什么本来就在抖是连着的,可以对照排名波动到底是哪一层算法在动。
搜索后台的位置和第三方工具的排名为什么对不上,该信谁?
几乎所有人都遇到过:搜索后台显示某词平均位置6.2,第三方排名工具说你排第11,差一大截,到底信谁?答案是它们测的根本不是同一个东西,没有谁对谁错,只有各自适合回答什么问题。
| 搜索后台的位置 | 第三方工具的排名 | |
|---|---|---|
| 数据来源 | 你的页面真实被展现时的位置,按真实展现聚合 | 工具在设定的地点设备下,模拟抓取一次结果页测得 |
| 覆盖人群 | 你真实受众,跨他们所有地点设备和时间 | 工具设定的那一个固定条件,未必是你受众 |
| 个性化 | 含真实用户的个性化结果 | 通常是去个性化的干净环境 |
| 适合回答 | 我真实用户实际看到我排在哪、趋势怎样 | 在统一基准下我和对手相对位置怎样 |
所以用法是各取所长,不是二选一。要回答“我真实生意相关的可见度趋势如何”,以搜索后台为准,它是用真实展现加权出来的、最贴近你实际受众的口径;要回答“在同一把尺子下我和竞争对手谁高谁低、我这个词的竞争位次变化”,用第三方工具,因为它提供了一个跨站可比的统一基准。两者对不上是正常的、甚至是健康的——它们对上了反而可疑。真正错误的做法是拿第三方某次快照的名次,去质疑搜索后台的趋势,或者反过来。想把第三方工具那套估算数据的精度和校准吃透,可以接第三方SEO工具数据为什么各家差几倍;想把搜索后台每个报告用对,接搜索后台到底怎么用那篇。
排名掉了,第一步该排查的是真掉了还是测量在骗你?
核心词排名掉了,最常见的错误反应是立刻去改内容、查外链、怀疑被惩罚。在动手之前,必须先过一道分诊:这个“掉”,到底是真的可见度损失,还是测量口径制造出来的幻觉。顺序反了,会把大量精力投到根本不存在的问题上。
分诊按这个次序走,能拦掉大半误报。第一步,先排除测量噪音:是不是只看了某一天某一次快照,换个时间、换台干净环境、按目标地点重测,分布是不是其实没动——很多“暴跌”重测就消失了。第二步,排除个性化幻觉:之前的“高排名”是不是在你常年自搜的环境里被个性化喂出来的,用无登录无历史环境一看,可能它从来没那么高,是基准错了不是现在掉了。第三步,排除混合效应:掉的是“平均排名”还是具体核心词?平均排名变差很可能只是新铺了一批靠后的长尾把均值拉低,核心词其实没事。第四步,排除结果页改版:核心词的名次到底动没动?如果名次没动、流量却掉,多半是结果页新长出了AI摘要或商品组把点击截走——这不是排名问题,是可见度被压缩,处方完全不同。只有这四步都排除掉,才进入“可能是真的内容或链接出了问题”的排查,去和波动归因那套接上。
这道分诊看似多此一举,实战里却是省时间最狠的一步。跳过它直接“掉了就优化”,是SEO团队最普遍的精力浪费——一半的“排名问题”根本不是排名问题,是测量没做对,或者结果页变了而你只盯着名次。
排名数据该驱动哪些决策,不该碰哪些?
测得再准,用错地方一样有害。排名数据有它该待的位置,也有它绝不该插手的地方。
它适合做诊断触发器:某组核心词可见度份额持续走低,触发一次排查;某词结果页新增了精选摘要或商品组、自然区被压下去,触发一次抢区块或调整内容形态的评估;自己和对手在一组词上的相对位置出现结构性变化,触发一次竞争分析。这些用法的共同点是——排名是用来“提示去看什么”的信号,不是结论本身。
它不适合、甚至有害的用法有这么几类:当成团队的核心KPI或发奖金的依据,因为它会诱导大家去刷那些容易但没价值的词;拿单日波动当事故每天开会复盘,把团队拖进和噪音的无意义搏斗;以及最根本的一种误用——把“排名上升”本身当成目标。排名只是通往生意的中间变量,一个词排第一却没人点、点了不转化,这个第一没有意义。把排名当目标,是用一个中间指标替换掉真正的目标,方向一旦这么定,团队会理性地做出一堆对排名数字好看、对生意没用甚至有害的动作。排名服务于判断,不该成为判断本身要追逐的东西。
这套测量和工具数据校准、排名波动归因是什么关系?
排名这个话题底下有几件相邻的事,容易混着说,这里划清边界,免得重复用功或张冠李戴。它们彼此正交,各回答不同的问题。
本文讲的是测量口径:排名这个东西到底该怎么定义、怎么测、用什么指标表达才不失真。第三方工具数据校准回答的是数据精度:工具给的搜索量、难度、排名这些估算数,各家为什么差几倍、怎么校准着用,是“数字本身准不准”。排名波动归因回答的是因果解释:名次确实动了,到底是哪一层算法、哪个动作、还是纯噪音造成的,是“为什么动”。零点击度量回答的是价值换算:在点击不发生的前提下,排名和曝光还值多少、怎么折算成影响。四件事是一条链:先用对的口径把可见度测出来(本文),知道手里数字的精度边界(校准),看到异动能归对因(波动归因),再把没有点击的那部分价值算进账(零点击度量)。哪一环缺位,排名数据都会从决策依据退化成误导来源。
点击衰减曲线怎么用,为什么不能套一条通用曲线?
可见度份额的核心是给每个名次配一个“被看见的概率”权重,这条权重就是点击衰减曲线。很多人随手网上抄一条“第一名约占三成、第二名约一成五”的通用曲线套上去,算出来的份额其实是错的,因为这条曲线在不同情况下形状差得很远。
曲线的陡峭程度,主要被结果页构成和意图类型决定。一个挂着精选摘要和AI摘要的信息类结果页,第一名以下的点击会被顶部那几块吃得很狠,曲线极陡,第三名和第一名可能差一个数量级;一个纯商品列表的交易类结果页,用户更愿意往下比价比货,曲线相对平缓,第五名也还能分到不少。意图也在变形:导航类查询几乎所有点击都砸在第一个结果上,曲线陡到接近垂直;而宽泛探索类查询,用户会点开好几个对比,曲线明显更平。再叠一层品牌效应——同样排第三,一个用户认识的品牌拿到的点击远高于一个陌生站,因为人是先扫品牌再点的。
所以正确做法不是套通用曲线,而是用自己搜索后台里“展现到点击”的真实数据,按结果页类型、意图类型分桶,反推出几条属于你自己业务的点击衰减曲线,再拿去给可见度份额加权。这一步不做,份额这个指标的精度上限就被一条来路不明的曲线锁死了。这背后其实也是个数据精度问题,和怎么校准外部估算数据是同一种思路:任何不知道误差来源的数字,都不该直接拿去做决策。
只盯自己的可见度份额够吗?竞争视角怎么加进来?
只看自己在一组词上占了多少份额,还是只看到半张图。份额是相对的:你的份额没变,可能是大家都没动,也可能是整个盘子在变大或缩小、对手在猛涨而你只是没掉。不引入竞争视角,份额会给你一种虚假的安稳。
把竞争视角加进来,就是把这组词当成一块固定的“可被看见的总盘”,看这块盘被你和主要对手怎么瓜分、占比随时间怎么挪。这样你能看出几件单看自己绝对看不出的事:某个对手在你核心词组上的份额是不是在结构性地往上走、是从谁手里抢的;整块盘是不是因为非自然区块变多而在缩小,所有自然玩家其实都在分一块越来越小的饼;以及你以为的“稳住了”,是不是只是大盘没动、而你相对对手已经在掉。份额必须连着竞争一起看,否则它和单一名次一样会给错误的安全感。当然这要求你诚实地选同一组对业务真实重要的词来比,而不是挑自己强的词。落地时还有个常被问的问题:竞争对手到底取谁。不要取所有在结果页出现过的域名,那会把一堆和你不抢生意的百科、聚合站也算进对手,稀释掉真正的信号;该取的是那几个真正在和你抢同一拨人、同一笔钱的直接竞争者,把盘子定义成“你和这几个真对手之间的可见度分配”,这个份额才对决策有意义。对手选错,竞争视角一样会算出一个好看但没用的数。
AI摘要出现之后,“排名”这件事又被改写了一次
过去几年排名测量的所有坑还没填平,AI摘要又在结果页最顶上加了一个全新的、会吃掉大量点击的东西,而且它的逻辑和蓝色链接排名不是一回事。这让“我排第几”这个问题进一步失效。
关键的变化有两点。第一,结果页最顶端那一块AI摘要,可能直接把答案给了,用户连往下滚的动作都没有,你那个词的自然第一名拿到的点击被再砍一刀,而这件事在传统排名表上完全看不出来——名次没动,曲线却又陡了一截。第二,能不能被AI摘要引用、引用时有没有带出你的品牌或链接,是一套和蓝链排名部分脱钩的新游戏:你蓝链排第七,却可能被摘要引用;你蓝链排第二,却可能完全没被提到。只测蓝链名次,对“你在AI答案里到底有没有存在感”这个越来越重要的问题,是完全瞎的。
测量上要做两件事。一是把“这个词的结果页有没有AI摘要、自然区被它压到多深”作为每个词的常规记录项,纳入可见度的计算,而不是假装它不存在。二是对核心词,单独建一类“有没有被AI答案带到、怎么带的”的观测,把它和蓝链名次分开看、分开汇报。这部分价值因为点击常常不发生,传统口径会系统性地把它记成零,怎么给这种没有点击却有影响的可见度算账,和前面说的零点击问题是同一个账本上的两页,要连起来记,否则你在AI答案里的存在感会被整张报表当成不存在。
每个词的结果页该怎么记录,监测才有据可查?
可见度份额、像素位置、AI摘要占比这些指标要算得出来,前提是你对每个被监测的词,记录的不只是一个名次数字,而是一份结果页的结构快照。只存名次,等于把算这些指标的原材料一开始就丢了。
对核心词,每次采样该记录的至少有这么几项:自己的自然名次;结果页上出现了哪些非自然区块(精选摘要、AI摘要、商品组、本地包、视频区、问答区)及它们的位置;自然结果第一名大致被压到了第几屏;这些区块分别是谁占着的;以及采样时的地点、设备、是否登录、时间。这份记录看起来繁琐,但它是把“排名”从一个会骗人的标量,还原成“可见度”这个可解释量的唯一办法。长尾词不必这么细,用聚合趋势即可;这套精细记录只压在那批真正驱动决策和生意的核心词上,成本可控。
这份结构快照还有个额外用处:当某个核心词流量掉了,你能立刻拿历史快照对比,看到底是自己名次退了、还是名次没动但结果页新长出一个区块把点击吃了。没有这份留痕,掉量排查只能靠猜,常常把“结果页变了”误判成“我们内容不行了”,然后往错的方向投入。把判断依据连同结果页快照一起留档,复盘时才对得上账。
多地点多设备的监测矩阵,怎么设计才不会爆炸?
一旦认真对待地点和设备,就会撞上一个组合爆炸:几百个核心词,乘以十几个目标城市,再乘以移动和桌面两种设备,再乘以采样频率,监测量和成本瞬间失控。很多团队就是被这个爆炸吓回去,干脆退回“一个默认地点、只看桌面”,又掉进前面说的精确的错误。出路不是全测,是把它当抽样设计来做。
设计的思路是按“决策价值”而不是“可能性”来铺采样点。先问每个维度真正的决策意义有多大:地点维度,只有当你的业务对地理强敏感(本地服务、区域配送、分城运营)时才需要按城市细铺,否则选两三个能代表主要市场的点就够;设备维度,按你真实流量的移动桌面占比定权重,占比悬殊时甚至可以只精测占大头那个、另一个低频抽查;词维度,只有核心交易词值得在多个地点设备下都测,长尾用单一基准看趋势即可;频率维度,越往核心越密、越往长尾越疏。把这些维度按价值排序后,你会发现真正需要密集采样的,是“核心词 × 主力市场 × 主力设备”这一小块高价值交集,其余维度低频抽查兜底即可。
这套设计的本质,是承认监测资源有限,于是把它优先投到“测错了会让你做错决策”的地方,而不是均匀地撒在所有组合上。监测矩阵不是越全越好,全而不准、全而无人看,比小而精准更糟。判断标准始终是:这个采样点测出来的差异,会不会改变某个具体决策;不会,就别为它付采样成本。
一个真实感很强的例子:被“平均排名上升”骗掉一个季度
保哥接触过一个做专业咖啡器具的跨境独立站,增长团队的季度复盘一直用一张大表,最显眼的指标是“核心词平均排名”。那个季度这个数字很好看,从十二点几升到了八点几,汇报里写着“排名持续优化,成效显著”,老板也认可,资源继续按这个方向投。问题是,同一个季度,自然流量基本没动,靠搜索进来的成交甚至略降。指标在涨,生意在原地,没人解释得了这个矛盾,于是先归因成“有滞后,再等等”。
又等了大半个季度还是不动,才下决心把那个平均排名拆开看。一拆全明白了。平均排名变好,几乎全部来自一批新铺的长尾科普词——它们刚开始有少量展现、名次也还行,把整张表的平均值往上抬。而真正带成交的那几个头部交易词,名次表上看着没怎么变,问题恰恰在“看着没变”上:那个季度这些词的结果页陆续加上了商品组和顶部AI摘要,自然第一名的像素位置被结结实实压下去一大截,名次数字没动,能拿到的点击却被前面那些区块分走了一大块。团队用一个被混合效应污染、又完全无视结果页构成变化的单一指标,给自己讲了一个“在进步”的故事,整整一个季度。
后来的修法没有什么玄学:把那张表废掉,按词的商业价值分三层,核心交易层只看可见度份额、像素位置和结果页非自然区块占比这三项,再拿搜索后台的真实展现点击交叉验证,长尾层只看聚合趋势不进核心汇报。换了口径之后,团队第一次看清楚真正赚钱的那几个词其实在退,资源调过去重抢被区块压掉的可见度,生意才慢慢回来。值得多说一句的是修法里最关键的那一步:不是换了多漂亮的新指标,而是先建了每个核心词的结果页快照留痕。正是靠把当季和上季的结果页快照摆在一起对比,团队才一眼看出那几个交易词是“名次没动、但顶上多了商品组和AI摘要”,而不是内容质量出了问题——没有这份留痕,复盘多半又会归错因,把钱投到再优化一遍内容上,问题原地不动。这件事真正的教训和技术细节关系不大:用错的指标做对的努力,比不努力更危险,因为它让你坚信自己在赢。排名测量这件事,测得对不对,往往比测得勤不勤重要得多。
常见问题解答
问:同一个关键词,为什么我查和同事查排名不一样?
答:因为排名本来就因人因场景而变。地理位置、登录态与个性化历史、设备、查询时间、结果页实时构成、数据中心实验分桶都会改名次。尤其自己常搜自家站会被个性化抬高,要用没登录、无历史的干净环境,并按目标受众的地点设备去测,才接近真实。
问:搜索后台的平均排名能直接当核心指标用吗?
答:不能单拎出来用。它是跨大量查询地区设备按展现加权的聚合数,会被查询组合变化污染——新铺一批长尾就能把均值拉高,核心词其实没变甚至在退。它只适合粗扫趋势,任何严肃判断都要按词、按商业价值分层下钻,绝不能用它发奖金定KPI。
问:可见度份额比单看排名好在哪?
答:它是组合视角,不被单词抖动带偏;用位置点击权重而非名次本身,如实反映第一名和第三名差距远大于第三和第五;还能按词的商业价值加权,让赚钱的词说话更重。它能直接和流量生意挂钩、经得起追问,但前提是选词诚实,别塞品牌词虚抬。
问:我排自然第一,为什么流量还在掉?
答:名次位置和像素位置是两回事。精选摘要、商品组、AI摘要等非自然区块会把自然第一压到屏幕很深处,名次没变能拿到的点击却被截走;还有大量需求在AI或精选摘要里就被满足,点击根本不发生。看排名必须连着看结果页构成和自然区被压深度。
问:搜索后台位置和第三方工具排名对不上,该信哪个?
答:它们测的不是同一个东西,没有谁对谁错。看真实受众的可见度趋势以搜索后台为准,它按真实展现加权最贴近你用户;看和对手在统一基准下的相对位次用第三方工具。两者对不上是正常的,错误用法是拿第三方某次快照去否定搜索后台的趋势或反之。
问:排名监测多久看一次合适?
答:对齐决策节奏,不要和噪音赛跑。做周月级趋势判断就按周看;排名有大量日内、机房、实验噪音,刷得越密看到的噪音越多。只有在排查一次明确疑似异动时才临时加密采样定位,平时高频盯盘是最大的精力黑洞。
问:排名能不能当团队KPI?
答:不建议。把排名当KPI或发奖金依据,会诱导团队去刷容易但没价值的词,并把“排名上升”本身错当成目标。排名只是通往生意的中间变量,排第一却没人点、点了不转化毫无意义。它该做诊断触发器提示去看什么,不该成为被追逐的目标本身。
问:可见度份额的位置权重,能直接套网上的通用点击曲线吗?
答:不能。点击衰减曲线随结果页构成、意图类型、品牌认知差很多——挂AI摘要的信息页极陡,纯商品比价页较平,导航词几乎全砸第一名。要用自己搜索后台真实的展现到点击数据,按结果页和意图类型分桶反推出自己的曲线,套通用曲线会让份额失真。
问:AI摘要出现后,传统排名监测还够用吗?
答:不够。AI摘要在最顶上又吃一刀点击,名次表完全看不出;且能否被AI答案引用和蓝链名次部分脱钩,蓝链第七可能被引、第二可能没被提。要把有无AI摘要、自然区被压多深纳入常规记录,并对核心词单独观测有没有被AI答案带到,和蓝链名次分开看。
问:多地点多设备测,组合太多成本爆炸怎么办?
答:别全测,按决策价值做抽样设计。密集采样只投在核心交易词乘主力市场乘主力设备这块高价值交集,地点对地理不敏感的业务选两三个代表点即可,设备按真实流量占比定权重,长尾用单一基准看趋势。判据是这个采样点的差异会不会改变某个决策,不会就别付成本。
权威参考资料
本文标题:《关键词排名监测为什么对不上?换台设备就全变的6大原因》
本文链接:https://zhangwenbao.com/rank-tracking-methodology-traps-share-of-voice.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0