第三方SEO工具的数据到底准不准?6步校准不被噪声带偏
本文目录
- 第三方工具的数据,到底是测出来的还是猜出来的?
- 没有一个是真值
- 四类被当真值用的估算数据
- 这篇和站内另外两篇怎么分工
- 自然流量为什么各家差几倍?
- 估算管线:三层假设连乘
- 为什么差的是“倍”不是“百分之几”
- 长尾、品牌和登录内容是结构性盲区
- 点击流面板的采样偏差,是另一个没人讲的误差源
- 词库盲区怎么自己测出来
- 外链总数为什么三家差一个量级?
- 爬虫库规模决定你能看见的上限
- 去重和计法口径,把差距再放大一截
- 外链涨跌波动,大多是重爬抖动不是真变化
- 外链库的新鲜度,怎么一眼看出来
- DR、DA、AS这些权威分,能当KPI考核吗?
- 它们是相对排序,不是绝对真值
- 跨工具比这些分数毫无意义
- 把权威分当KPI的反模式
- 可见度份额、流量价值这些复合指标,陷阱在哪?
- 估算的估算,误差叠得更狠
- 它们只配看趋势,不配看绝对
- 老板和销售最爱要这种数字,怎么给才不误导
- 那这些工具到底什么时候能信?
- 同源相对原则
- 粗筛不是裁判
- 不同体量的站,信任折扣完全不一样
- 怎么用第一方数据把第三方校准着用?
- Search Console是你自己站的真值锚
- 日志是抓取行为的真值
- 一套可操作的校准流程
- 一个真实的校准例子,看系数怎么算出来又怎么用
- AI搜索时代,第三方数据为什么更不准了?
- 点击曲线被零点击打乱
- 关键词宇宙在碎片化
- 越是AI时代越要回第一方
- 常见问题解答
- 第三方工具的自然流量数据准吗?
- 为什么同一个站Ahrefs和Semrush的流量差好几倍?
- DR和DA能直接比较吗?
- 外链工具说我掉了几百条外链,是真的吗?
- 第三方工具数据什么时候可以信?
- 怎么用GSC校准第三方流量估算?
- 能用第三方工具的流量估值给网站定价吗?
- AI搜索时代第三方SEO数据是不是更不准了?
- 权威参考资料
摘要:第三方工具给你的自然流量、外链总数、关键词数、DR或DA这些权威分,没有一个是真测出来的,全是各家拿自己的爬虫库、点击流面板和外推模型估出来的。估算口径不一样,同一个站各家差两三倍甚至一个量级是常态,不是哪家有bug。所以正确的问题不是“哪家最准”,是搞懂每个数字怎么估出来、误差从哪进来,然后只把它当相对信号横向比趋势,绝对值必须用Search Console和日志这类第一方数据校准。把估算值当真值去做决策,等于把楼盖在沙子上。
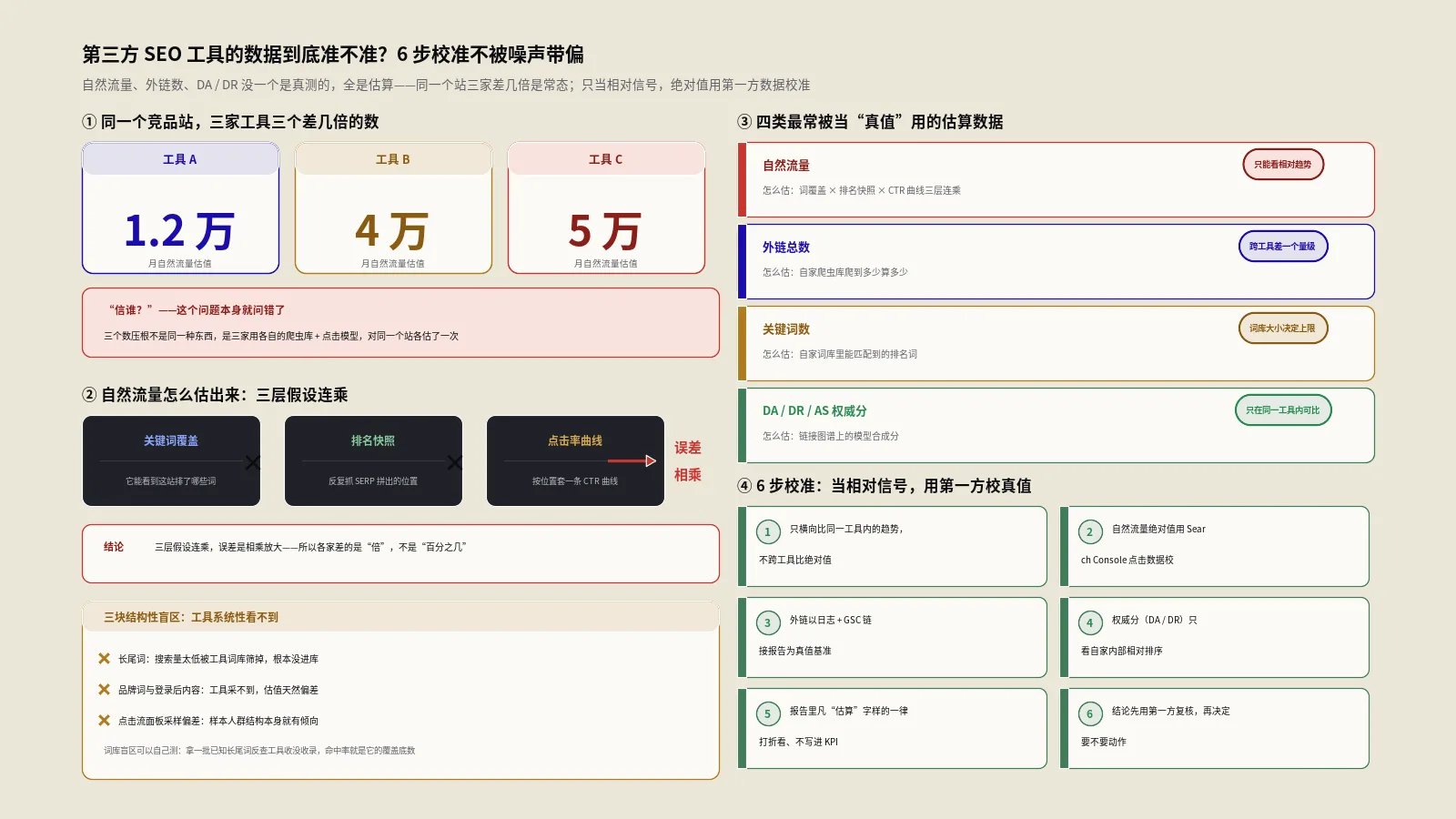
讲个常见的场景。一个做DTC出海的客户,拿着一份导出的工具报告冲进会议室:竞品月自然流量五万,我们才八千,差太远了,得追。保哥没接这个数,让他当场打开同一个竞品域名,分别在另外两家主流工具里看“自然流量”——一家给的是一万二,一家给的是四万出头,加上他手里那份,三家从一万出头到五万,跨度好几倍。会议室一下安静了。这位客户的困惑很典型:到底信谁?而真正的答案是——“信谁”这个问题本身就问错了,这三个数字压根不是同一种东西,它们是三家公司用三套不同的爬虫库、三套不同的点击模型,对同一个站各自做的一次估算,它们之间没有谁对谁错,只有口径不同。
这种事保哥在尽调里见得更狠:卖方挑三家工具里数字最大的那家截图进商业计划书,买方拿数字最小的那家压价,谈判桌上两边对着两个估算值争得面红耳赤,没有一个人停下来问这数字是怎么来的。这篇不重复站内已经讲过的单一关键词难度指标怎么标定,也不重复Search Console第一方报告怎么读,专讲一件更底层的事:第三方工具那些被当真值用的数据,到底是怎么估出来的、为什么各家差这么多、什么时候能信什么时候只能当噪声、以及怎么用第一方数据把它们校准着用。把这套搞懂,你就再也不会在“信谁”这种伪问题上浪费时间。
第三方工具的数据,到底是测出来的还是猜出来的?
一切误用的起点,是默认这些数字是“测量结果”。它们不是。Google不对外公开任何一个站的真实自然流量、完整外链、真实关键词排名全集,第三方工具站在墙外,只能想办法估。理解这一点,后面所有差异都顺理成章。
没有一个是真值
把工具面板上那几个被反复引用的数字过一遍,没有一个是直接测出来的:自然流量是估的,外链总数是它自己爬到多少算多少,关键词数是它的词库里能匹配到多少算多少,DR/DA/AS这类权威分更是纯模型算出来的合成指标。它们的共同点是——都建立在“工具能看到多少”和“工具的模型怎么外推”这两个前提上,而这两个前提各家差异巨大。想理解工具为什么只能在外面估、估的到底是哪一步,得先明白搜索引擎抓取、索引、排名是怎么运转的:真实的排名和点击发生在Google内部那套黑箱里,工具能拿到的只是从外部反复抓取SERP拼出来的一张张快照,再用模型把快照外推成“流量”。从快照到流量,中间隔着好几层假设。
四类被当真值用的估算数据
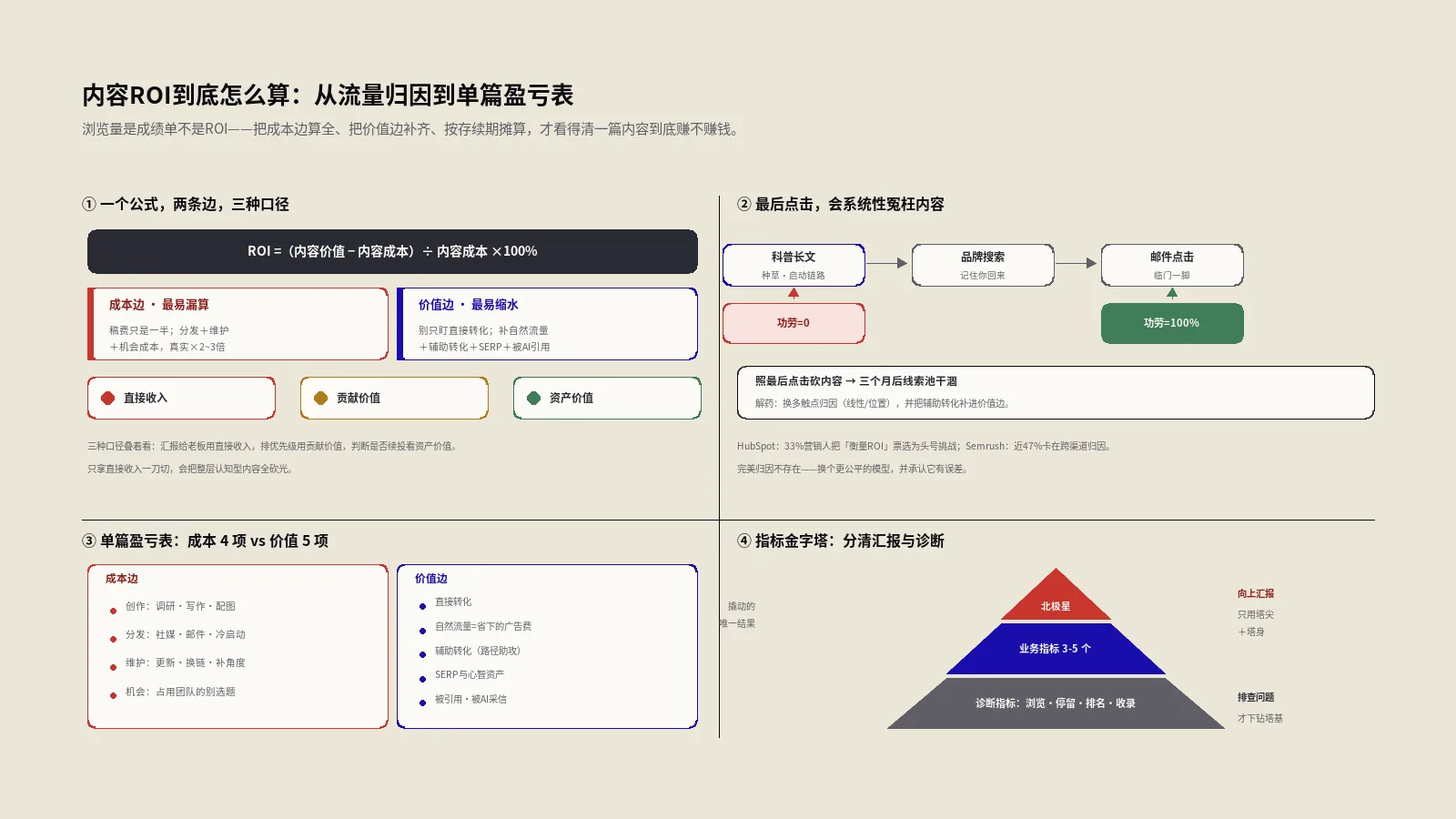
实际工作中最容易被当真值的,是这四类。先用一张表把它们怎么估的、误差从哪来、能不能当绝对值摆清楚,后面每一类单独拆:
| 数据 | 怎么估出来的 | 主要误差源 | 能当绝对值用吗 |
|---|---|---|---|
| 自然流量 | 关键词覆盖×排名快照×点击率曲线外推 | 三层假设连乘,误差相乘放大 | 不能,只能看相对趋势 |
| 外链总数 | 自家爬虫库爬到多少算多少 | 爬虫库规模、去重与计法口径 | 不能,跨工具差一个量级 |
| 关键词数 | 自家词库里能匹配到的排名词 | 词库大小、SERP抓取覆盖 | 不能,词库决定上限 |
| DR/DA/AS权威分 | 链接图谱上的模型合成分 | 对数尺度、公式黑箱、标定样本 | 不能,只在同一工具内可比 |
这篇和站内另外两篇怎么分工
需要先划清范围,避免重复。站内已经有一篇专讲单一关键词难度这一个指标为什么各家算法打架、对数尺度怎么标定的内容;也有一篇专讲Search Console这个第一方工具的报告怎么读、索引问题怎么诊断。本篇既不是讲某一个指标,也不是讲第一方工具用法,而是讲所有第三方外部估算数据共同的管线机制,以及怎么用第一方把它们校准着用——三者是互补关系,一个讲单指标标定,一个讲第一方真值读法,这篇讲外部估算的系统性偏差与校准方法论。后文会在对应处把另外两篇接上。
自然流量为什么各家差几倍?
这是被误用最多、也最值得拆透的一个。开篇那个三家差五倍的场景,根源就在这套估算管线的结构里。
估算管线:三层假设连乘
第三方工具估一个站的自然流量,大致是三步连乘:第一步,确定这个站排了哪些关键词——这取决于工具自己的关键词库有多大,库里没有的词,这个站就算排第一它也看不见;第二步,确定每个词排在第几位——这取决于工具最近一次抓这个词的SERP是什么时候、抓没抓到这个站,SERP是高度个性化和波动的,一次快照只是一个截面;第三步,把“排第几”换算成“多少点击”——这要套一条点击率曲线,假设第一位多少点击率、第二位多少,再乘以这个词的搜索量(搜索量本身又是另一个估算值)。三步里每一步都是估算,而且是相乘关系:关键词覆盖估出来、排名快照估出来、点击率曲线套上去,三个估算值一乘,最终那个“月自然流量”就是估算的三次方。
为什么差的是“倍”不是“百分之几”
很多人不理解:都是大公司做的工具,差也该差个一两成,怎么会差好几倍?答案就在“连乘”两个字。假设A工具关键词库覆盖比B工具大30%,A的SERP快照比B新、多抓到20%的排名词,两家点击率曲线对热门位置的假设又差25%——单看每一层差距都不算离谱,但1.3×1.2×1.25已经接近两倍,再叠加搜索量估算本身的差异,三五倍就出来了。这不是误差失控,是估算管线的数学结构决定的——多个独立估算值相乘,偏差不是相加是相乘,所以第三方流量数字天然就是“量级正确、绝对值不可信”。能从中读出来的有效信息,是“这个站大概是几千还是几十万这个量级”和“它的趋势在涨还是在跌”,绝不是“它精确是47,300”。
长尾、品牌和登录内容是结构性盲区
还有三块是估算管线天然看不见的。一是无搜索量长尾词:工具词库主要覆盖有一定搜索量的词,一个靠海量长尾撑流量的内容站,真实流量可能是工具估值的好几倍,因为大半流量来自工具词库里根本没有的词。二是品牌词和直接流量:用户直接搜品牌名、直接输网址进来的这部分,工具要么看不见要么严重低估,品牌越强这块被漏得越多。三是登录后内容、App内流量:工具只能抓公开SERP,墙后的一概看不到。所以工具流量估值对不同类型的站系统性偏差方向不同——长尾内容站普遍被低估,强品牌站的非品牌估值容易被品牌噪声污染,这意味着你不能用同一个“信任折扣”套所有站。
点击流面板的采样偏差,是另一个没人讲的误差源
前面讲的三层连乘还只是基于SERP抓取那条线。有一类数据——尤其是带“真实访问”色彩的流量估算和某些用户行为指标——还掺了第二个数据源:点击流面板(clickstream panel)。它的原理是工具方通过浏览器插件、某些免费软件捆绑、合作的网络服务商,采集一批真实用户的匿名浏览行为,再把这个样本放大到全网。问题出在“这批样本是谁”:装这类插件的用户、用这些免费软件的用户,在地域、设备、人群、行业上是高度有偏的——通常偏特定地区、偏个人消费类浏览、偏桌面端。这意味着面板对偏冷门的B2B站、强地域的本地站、移动端为主的站系统性采样不足,把一个偏斜的小样本放大成全网估值,偏差方向是固定的:越是小众、越是非英语区、越是移动端,被面板低估得越狠。这也是为什么同一个工具对一个大众消费类英文站估得还像样,对一个垂直B2B或非英语区的站能离谱到不能看——不是它对你有偏见,是它的面板里几乎没有你这类用户的样本。
词库盲区怎么自己测出来
三层连乘里的第一层“关键词覆盖”,背后是工具的关键词库。这个库怎么来的?大体是搜索建议抓取、点击流里捞到的真实查询、历史SERP沉淀、再加种子词扩展几路拼起来,规模各家差很多,且都对“有一定搜索量、相对常见”的词覆盖好,对零散长尾覆盖差。这给了你一个能自查的指纹:把工具显示的“你的站排名关键词总数”和Search Console里你这个站真实有曝光的查询总数对一下——如果Search Console的查询数是工具显示的好几倍,说明你的流量主体落在工具词库的盲区里,它对你的流量估值会系统性严重偏低,这种站尤其不能信工具的绝对流量。反过来,如果两者量级接近,说明你的流量集中在常见词上,工具的估值至少在“能看见的部分”相对靠谱一些。这个简单对比,比纠结“哪家工具准”有用得多,因为它直接告诉你工具对你这个具体的站偏在哪个方向、偏多大。
记住自然流量估值的本质:它是“关键词覆盖”乘“排名快照”乘“点击率曲线”三个估算值连乘的结果,关键词覆盖背后是有偏的词库、流量数据里还掺了有偏的点击流面板,量级可参考,绝对值不可信,趋势比数值有意义得多。
外链总数为什么三家差一个量级?
如果说流量估算差几倍,外链总数差的常常是一个量级——A说你有两万条,B说八千,C说五万。原因和流量不同,主要不在外推模型,在“能看见多少”。
爬虫库规模决定你能看见的上限
一条外链要被工具统计到,前提是这家工具的爬虫真的爬到了那个挂着链接的页面。各家爬虫库的规模、刷新频率、覆盖深度差异极大,这直接决定了它能“看见”多少外链。爬虫库大的工具天然报出来的外链数更多,不是因为它更准,是因为它看得更全或者它把更多低质页也算了进来。外链总数本质上是“这家工具的爬虫库覆盖度”的代理指标,不同工具的外链总数之间没有可比性,差一个量级太正常了。
去重和计法口径,把差距再放大一截
在“看见多少”之上,还有“怎么算”的口径差异:同一个域名给你一千个页脚链接,算一千条还是按域名算一条?nofollow、UGC、sponsored这些带标记的链接计不计进总数?已经404了的历史外链(链接墓地)还留在库里吗?子域和主域怎么合并?每一项口径选择都能让总数差好几倍,而各家口径既不统一也不完全公开。这就是为什么看外链不能看“总数”,要看引用域数量、要看去重后的真实独立来源、要按相关性和质量分桶——总数是最没信息量、最容易被口径操纵的那个数字。
外链涨跌波动,大多是重爬抖动不是真变化
很多人盯着工具的“新增外链/流失外链”当预警,今天掉了三百条就紧张。实际上这类短期波动绝大多数是工具重爬数据库时的抖动——某批页面这轮没爬到就显示“流失”,下轮爬到又“新增”,和你的链接真实状态没关系。外链的真实健康度要看趋势线和高质量引用域的稳定性,不是看每天那几百条的进出,那基本是噪声。真要排查链接风险,得回到具体的链接清单人工核,靠工具的总数波动追,追的全是幻觉。
外链库的新鲜度,怎么一眼看出来
各家外链库不只是大小不同,新鲜度也差很多——有的库刷新快,死链和过期页清理及时;有的库沉淀了大量早就404、域名都没了的“墓地链接”不清,靠这个把总数撑得很大。这给你一个判断库质量的指纹:抽查它给你的外链清单里,随机点开几十个来源页,看有多大比例已经打不开、跳别处或者明显是早死的站。如果一个工具报的外链总数很大,但抽样发现里面很高比例是墓地链接,那它这个大数字是注水的,它真正有参考价值的是“当前还活着的引用域数”这一项,不是总数。不同工具对“活链接”的重新核验频率差异,本身就解释了为什么有的工具外链数虚高、有的偏保守。看外链永远盯活跃引用域和它的趋势,把总数当库新鲜度的反向指标看,而不是当资产规模看。
DR、DA、AS这些权威分,能当KPI考核吗?
这几个分数被滥用得最厉害——写进KPI、写进外链报价单、写进甲方考核。它们能不能这么用,得先看清它们是什么。
它们是相对排序,不是绝对真值
DR、DA、AS本质上是各家在自己的链接图谱上跑一个模型,给全网站点排个相对座次,再压缩到一个零到一百的分数。关键性质有两个:一是它是相对的,分数高只代表在这家的链接图谱里排得靠前,不代表任何绝对的“权威量”;二是它是对数尺度的,从20涨到30和从60涨到70完全不是一回事,后者难得多、含金量差着数量级。这套尺度的标定逻辑,和站内那篇讲关键词难度指标为什么各家工具打架的机制是同一个家族——那篇专门拆了单个指标的对数尺度和标定样本怎么导致各家数字打架,这里要补的是:所有这类合成权威分都有同样的通病,不只是关键词难度。
跨工具比这些分数毫无意义
最常见的错误用法,是拿A工具的DR和B工具的DA放一起比,或者要求“外链来源DA必须大于40”却不指定是哪家的DA。不同工具的权威分是不同模型在不同链接图谱上、用不同标定样本算出来的,量纲都不一样,跨工具比就像拿摄氏度和华氏度直接比大小。同理,把这个分写进外链采购标准而不锁定工具和时间,等于给了对方一个可以挑工具、挑时点截图的操纵空间。
把权威分当KPI的反模式
更深一层的反模式,是把权威分本身当成要优化的目标去考核。一旦DR成了KPI,团队就会去做“能涨DR但对业务无意义”的动作——堆某类容易拉分的链接、被对数尺度骗着以为“从25到35进步很大”(其实在绝对意义上微不足道)。权威分是个粗糙的体检参考值,不是健康本身;拿它考核,考出来的是刷分行为,不是真实的链接资产质量。正确做法是把它当一个降噪用的粗筛指标,真实判断回到引用域质量、相关性和真实流量。
可见度份额、流量价值这些复合指标,陷阱在哪?
比单项估算更危险的,是工具面板上那些看起来很高级的复合指标:可见度份额、流量价值(traffic value)、市场份额。它们最唬人,也最不能当真。
估算的估算,误差叠得更狠
这些复合指标的算法,是把前面那些本来就是估算的值再组合运算一遍:可见度份额要先估你和所有对手在一批词上的排名再加权;流量价值要先估流量、再乘以每个词的估算CPC;市场份额要先圈定“这个市场”有哪些站再估每家流量。每一步输入都是估算值,复合指标就是估算的估算,前面三层连乘的误差到这里又被叠了一层,绝对值已经基本没有参考意义。
它们只配看趋势,不配看绝对
这不代表它们一无是处。在同一个工具、同一套口径下,看你自己的可见度份额曲线是往上还是往下、流量价值的趋势在改善还是恶化,这是有意义的——因为系统性偏差在时间序列里大体抵消了,方向是可信的。但拿你的“流量价值”绝对数去和别人比、或者拿它去做估值,就是在用估算的估算当真账。复合指标的唯一正确用法是同源看趋势,任何把它的绝对值拿去横向比较或对外报价的做法都是误导。
老板和销售最爱要这种数字,怎么给才不误导
现实是,复合指标恰恰最讨管理层和客户喜欢——一个数就能讲故事。负责任的给法是:给趋势不给孤立绝对值(“我们的可见度份额过去半年从某基线涨了百分之X”而不是“我们的流量价值是Y万美元”),给区间和口径(注明是哪家工具、什么时间、什么定义),并在旁边永远放一个第一方数据做锚。把估算值包装成精确账目对外讲,短期好看,等真实转化对不上的时候,信任反噬得更狠。
那这些工具到底什么时候能信?
讲了一堆不能信,不是要你卸载工具——它们仍是效率利器,只是得用在对的地方。能信和不能信的边界,可以画得很清楚。
| 场景 | 能信的用法 | 不能信的用法 |
|---|---|---|
| 看自己站 | 同工具看流量/排名的趋势方向 | 把绝对流量当真实访问量 |
| 看竞品 | 判断量级(几千还是几十万)和大致走势 | 拿绝对值算差距、定追赶KPI |
| 选词找机会 | 批量粗筛、降噪、找方向 | 拿难度分当唯一裁判 |
| 看外链 | 同工具看引用域趋势和质量分布 | 跨工具比总数、追每日进出 |
| 跨工具 | 几乎没有能直接比的绝对值 | 把不同工具的数字混在一起比 |
同源相对原则
把上面这张表压成一句可执行的原则:同一个工具、同一段时间、只看相对关系和趋势——这是第三方数据唯一可靠的用法。同源,是因为系统性偏差在同一工具内部是一致的,比相对关系时偏差抵消;看趋势,是因为时间序列里偏差也大体恒定,方向可信而数值不可信。只要跨出“同源”和“相对”这两个边界——换工具比、看绝对值——可靠性立刻崩塌。
粗筛不是裁判
另一个实操心法是分清“粗筛”和“裁判”。用工具在几千个词里快速圈出有潜力的几百个、在一堆竞品里快速定位谁值得深挖、在外链机会里快速过滤明显垃圾——这些“降噪、缩小范围”的活它干得又快又好。但最终“这个词到底做不做、这条链值不值得要、这个竞品到底强在哪”的判断,必须回到SERP人工看、回到第一方数据核。把工具当裁判,是把一个为了省时间的粗筛器,错当成了精确决策依据。
不同体量的站,信任折扣完全不一样
很多人想要一个统一的“工具数据打几折信”,但前面拆下来会发现,偏差方向和大小是跟站的类型强相关的,没有一个通用折扣。把典型站型和它对应的信任姿态列一下,按自己手上的站对号入座:
| 站点类型 | 最不可信的指标 | 偏差方向 | 建议姿态 |
|---|---|---|---|
| 大众消费英文站 | 绝对流量值 | 相对接近但仍偏高 | 趋势可用,绝对值打折 |
| 长尾内容站 | 自然流量、关键词数 | 系统性严重低估 | 真实流量按数倍上修,别信工具低值 |
| 强品牌站 | 非品牌流量拆分 | 品牌词污染、口径混乱 | 必须用第一方拆品牌与非品牌 |
| 垂直B2B站 | 流量、点击流类指标 | 面板采样不足、低估 | 几乎只能看趋势,绝对值放弃 |
| 非英语区/本地站 | 流量、可见度份额 | 词库与面板双重盲区 | 重度依赖第一方,工具仅做粗筛 |
这张表最该带走的不是某一行,是这个认知本身:“工具数据准不准”没有统一答案,只有“对我这类站、这个指标,它往哪个方向偏、偏多大”这个具体答案。同一个工具,对大众消费英文站的流量估值可以拿来做粗判断,对一个非英语区B2B站的同一个指标可能直接不能看。先认清自己的站落在哪一行,再决定哪些数字能进决策、哪些只能当背景噪声——这一步想清楚,比换十个工具都管用。
怎么用第一方数据把第三方校准着用?
真正专业的用法,不是抛弃第三方,是用第一方数据给它建一个校准锚,让估算值变得“可控地不准”而不是“不知道有多不准”。
Search Console是你自己站的真值锚
对你自己运营的站,Search Console是离真值最近的东西——它是Google第一方给的真实曝光和点击。校准方法是:把第三方工具对你自己站的流量估值,和Search Console同口径时间段的真实点击放一起,算出这家工具对“你这类站”的系统性偏差系数(比如它系统性高估1.8倍)。有了这个系数,你再看它对竞品的估值时,就能在心里做量级修正,而不是照单全收。怎么从Search Console里取到可用作锚的真实数据、哪些指标会骗人,站内那篇GSC报告怎么读、索引问题怎么诊断讲得很细,校准前先把第一方数据本身读对,否则拿一个错的锚去校准,错上加错。
日志是抓取行为的真值
第三方工具完全看不到爬虫真实怎么抓你的站——它只能看SERP,看不到Googlebot的真实行为。这部分的真值在服务器日志里。校准价值在于:当第三方工具的收录或可见度数据和你的实际表现对不上时,日志能告诉你到底是抓取出了问题还是工具估错了。站内有一篇专讲日志文件分析能看到第三方工具看不到的爬虫真相,那篇讲的是日志分析方法本身,这里要强调的是它的另一重用途——它是判断“第三方数据异常到底是真问题还是工具噪声”的第一方裁判。
一套可操作的校准流程
把上面这些串成可以照做的步骤:第一步,用Search Console和后台分析建立“我自己站在每个常用工具里的偏差系数”,分清它对我这类站是高估还是低估、大概几倍。第二步,看竞品数据时,用这个系数做量级修正,并永远只用它判断量级和趋势,不用它的绝对值。第三步,任何要对外或对上汇报的数字,旁边必须配一个第一方锚和口径说明。第四步,定期重标——工具会改模型、Google会改搜索(尤其AI搜索改变点击结构后),旧的偏差系数会失效,至少每季度用第一方数据重校一次。这套流程的内核就一句:第三方负责快速给方向,第一方负责定准星,永远不让估算值脱离第一方锚单独做决策。
一个真实的校准例子,看系数怎么算出来又怎么用
抽象流程不如看一遍真做是怎么做的。2019年保哥带一个北美家居DTC独立站做竞品摸底,团队一开始的诉求和开篇那位一模一样:某第三方工具显示头部竞品月自然流量约二十万,自己站只有三万出头,差六七倍,压力很大。第一步不是去看竞品,是先校准工具对自己站偏多少。把这个工具对自己站当月的自然流量估值,和Search Console同一个月、同口径(自然搜索、同地区)的真实点击放一起:工具估值约三万二,Search Console真实点击约四万八。也就是说,这家工具对“我们这类站”不是高估,是系统性低估,真实约是它估值的一点五倍——这个一点五就是偏差系数。原因也想得通:这个站很大一块流量来自长尾产品词和品牌词,正落在工具词库和品牌盲区里。
有了这个系数,再回头看竞品那二十万就完全不是原来的意思了。竞品和自己站品类、结构、流量构成接近,可以合理假设工具对它也存在同方向的低估,那它真实流量的量级更可能在三十万上下,而不是二十万——差距不是缩小了,是确认了对方确实强、且强得比报告显示的还多,追赶策略得按更大的体量重新规划,而不是按那个被低估的二十万去做计划。这里的关键不是那个具体数字,是方法把“一个不知道多不准的数字”变成了“一个知道往哪个方向偏、偏多少的数字”——前者只能信或不信,后者可以拿来做判断。这个站后来每个季度用Search Console重标一次系数,因为工具中途改过一次模型、系数从一点五漂到了一点三左右,没重标的话后面所有竞品判断会跟着系统性偏掉。这就是“第三方给方向、第一方定准星、定期重标”落到一个真实项目里的样子。
AI搜索时代,第三方数据为什么更不准了?
最后这部分是个正在恶化的趋势。AI搜索不是让第三方数据稍微差一点,是动摇了它估算管线的根基。
点击曲线被零点击打乱
第三方流量估算最依赖的那条“排第几位对应多少点击率”的曲线,建立在传统蓝链SERP的点击行为上。AI Overview、AI概览这类生成式结果出现后,大量查询在结果页内就被回答了,用户根本不点进任何网站(零点击),或者点击高度集中到被AI引用的少数源。工具的点击率模型还停留在老假设上,于是它对“排在前面”的站系统性高估流量——因为它假设的那些点击,被AI答案吃掉了,没真实发生。这个偏差还会随AI结果覆盖率上升持续扩大。
关键词宇宙在碎片化
用户越来越多地用长对话式、口语化的方式提问,这类查询高度长尾且千人千面,工具的关键词库本来就覆盖不到这一块,碎片化只会让“词库盲区”这个本就存在的结构性问题更严重。也就是说,AI时代工具不仅高估了能看见的词的流量,还更大面积地漏掉了看不见的那部分需求。
越是AI时代越要回第一方
结论很明确:第三方估算管线赖以成立的两个根基——稳定的点击率曲线和可枚举的关键词宇宙——都被AI搜索动摇了,它会越来越多地告诉你一个“量级大致对、方向可能对、绝对值越来越离谱”的数字。这不是不用工具的理由,是更要把第一方校准这件事做扎实的理由:工具给方向的价值还在,但当真账的空间被AI进一步压缩,第一方数据作为准星的重要性只会越来越高。谁更早把“第三方给方向、第一方定准星”这套校准纪律建起来,谁在AI搜索时代的判断就更不容易被估算值带偏。
常见问题解答
第三方工具的自然流量数据准吗?
不准,它是关键词覆盖、排名快照、点击率曲线三个估算值连乘出来的,量级可参考、绝对值不可信。同一个站各家差几倍是常态,只能用来看趋势和量级,不能当真实访问量。
为什么同一个站Ahrefs和Semrush的流量差好几倍?
因为两家用不同大小的关键词库、不同时点的SERP快照、不同的点击率曲线各自估算,而这些是相乘关系。每层差两三成,连乘起来就是几倍,不是谁家有bug,是估算管线的数学结构决定的。
DR和DA能直接比较吗?
不能。它们是不同工具在不同链接图谱上用不同模型和标定样本算的相对分,量纲都不一样,跨工具比就像拿摄氏度和华氏度比大小。它们还是对数尺度,只在同一工具内部看相对位置才有意义。
外链工具说我掉了几百条外链,是真的吗?
多半不是真变化,是工具重爬数据库的抖动,某批页面这轮没爬到就显示流失,下轮又新增。看外链健康度要看引用域趋势和高质量来源稳定性,不是盯每日进出,那基本是噪声。
第三方工具数据什么时候可以信?
同一个工具、同一段时间、只看相对关系和趋势时最可信,因为系统性偏差在同源同期内大体抵消。一旦跨工具比、看绝对值、用于小站长尾或当KPI估值依据,可靠性立刻崩塌。
怎么用GSC校准第三方流量估算?
把第三方对你自己站的流量估值和GSC同口径时段的真实点击对比,算出这家工具对你这类站系统性高估或低估几倍,得到偏差系数;再用这个系数去对竞品估值做量级修正,不照单全收。
能用第三方工具的流量估值给网站定价吗?
非常危险。流量估值本身是估算的三次方,定价还要再叠流量价值这种估算的估算,绝对值几乎没参考性。尽调要回到GSC、GA4、服务端这些第一方数据核真实流量和转化,工具数字只能做交叉印证。
AI搜索时代第三方SEO数据是不是更不准了?
是,而且根基性变差。它的点击率曲线建立在传统蓝链点击上,AI概览带来的零点击让它对靠前的站系统性高估流量,长对话查询又扩大词库盲区。越是AI时代越要靠第一方数据定准星。
权威参考资料
本文标题:《第三方SEO工具的数据到底准不准?6步校准不被噪声带偏》
本文链接:https://zhangwenbao.com/third-party-seo-tool-data-accuracy-estimation-methodology.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0