Vibe Coding重塑SEO工作流:自养工具的杠杆与10步实操
本文目录
- vibe coding给SEO的,到底是什么优势?
- 哪些SEO活适合用vibe coding,哪些碰都别碰?
- 一个SEO能在几天里vibe出哪些真有用的工具?
- 为什么"几天造个工具"反而常常埋雷?
- vibe-coded工具三个月后为什么没人敢动?
- 信息怎么被"看见",为什么是被低估的SEO优势?
- SEO团队该怎么把vibe coding用成可持续优势,而不是技术债工厂?
- 常见问题解答
- 不懂编程的SEO能靠vibe coding做出可用工具吗?
- vibe coding做的SEO工具能直接上生产吗?
- 哪些SEO任务最适合用vibe coding快速做?
- vibe coding生成的代码最常见的隐患有哪些?
- 为什么vibe出来的工具几个月后就没人敢改?
- vibe coding会取代SEO团队里的开发吗?
- 权威参考资料
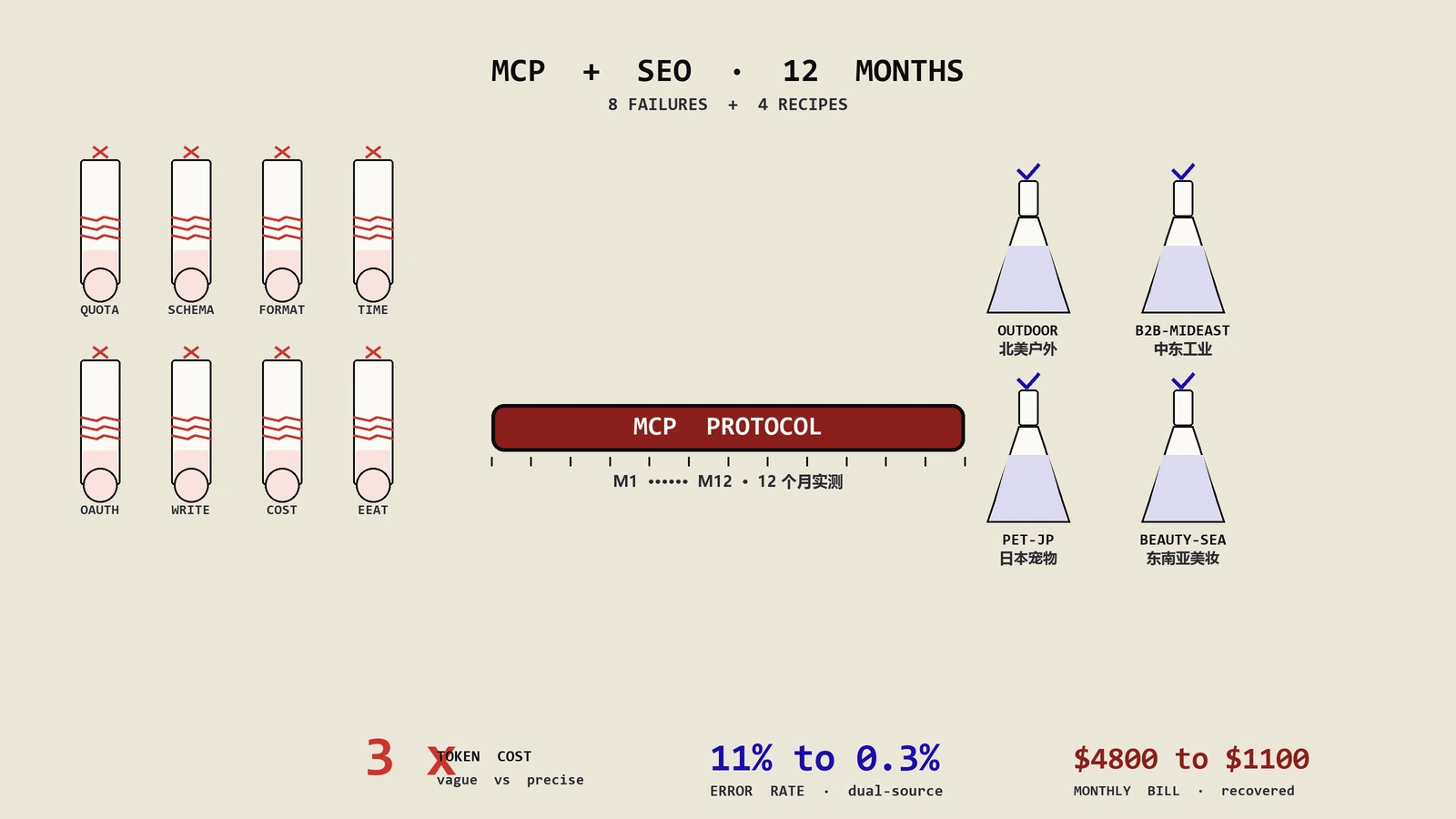
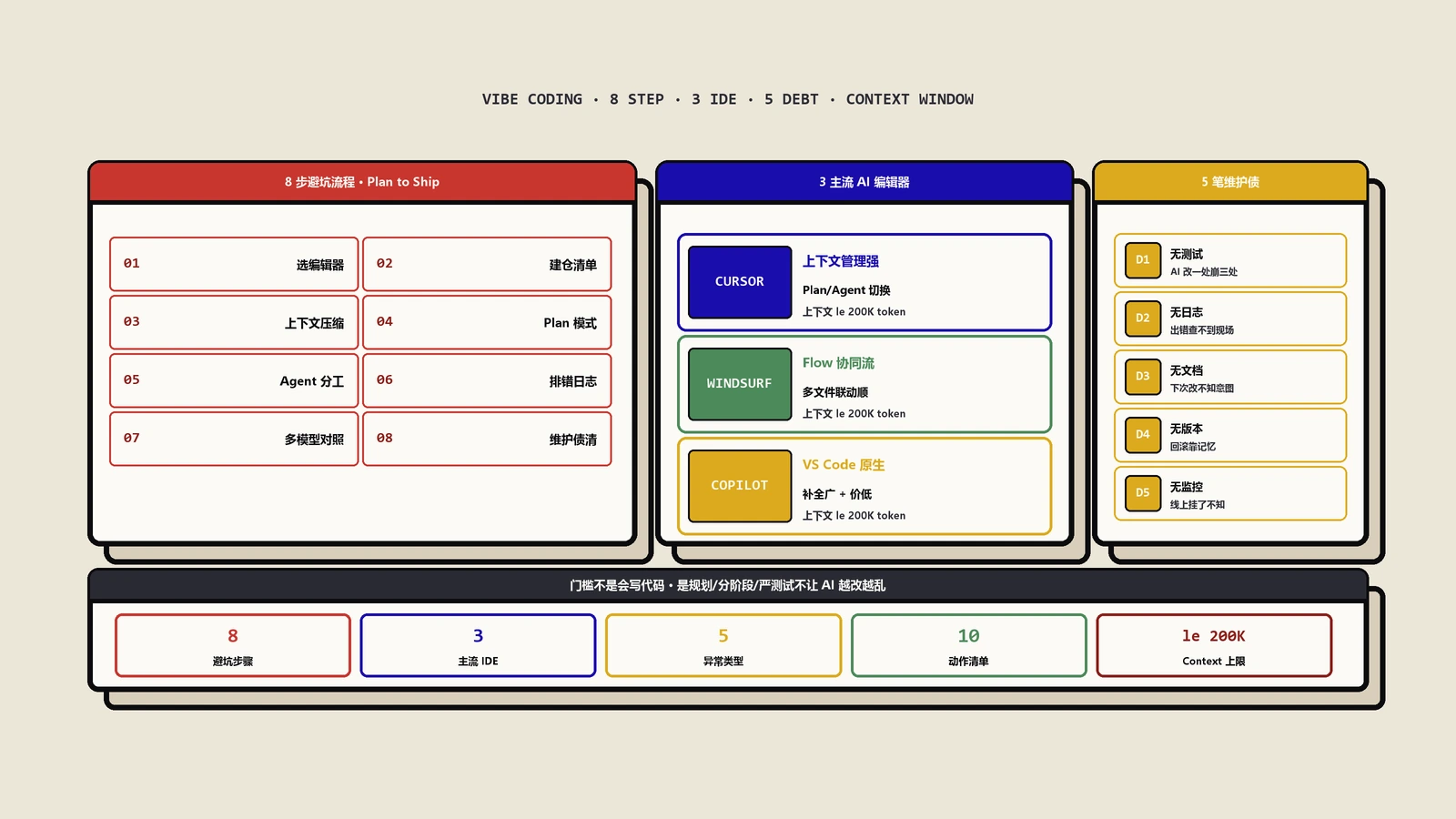
摘要:vibe coding给SEO团队的真正优势不是省了程序员,是把一个想法变成能跑的工具的延迟,从几周排期压到几小时——SEO的瓶颈从来不是没点子,是点子排不进开发队列。会用它的SEO能自己做掉GSC大文件处理、关键词聚类、日志爬虫分析、批量schema、内链图诊断这类一次性和内部活,把真工程师留给模板和基础设施。但它有明确的雷区:生成的爬虫默认不限速会打挂站、schema常漏实体连接、API密钥可能被写进前端,而且三个月后没人敢动那段代码。把它用在原型和一次性分析上是杠杆,拿它建会改信息架构的生产系统就是技术债工厂。
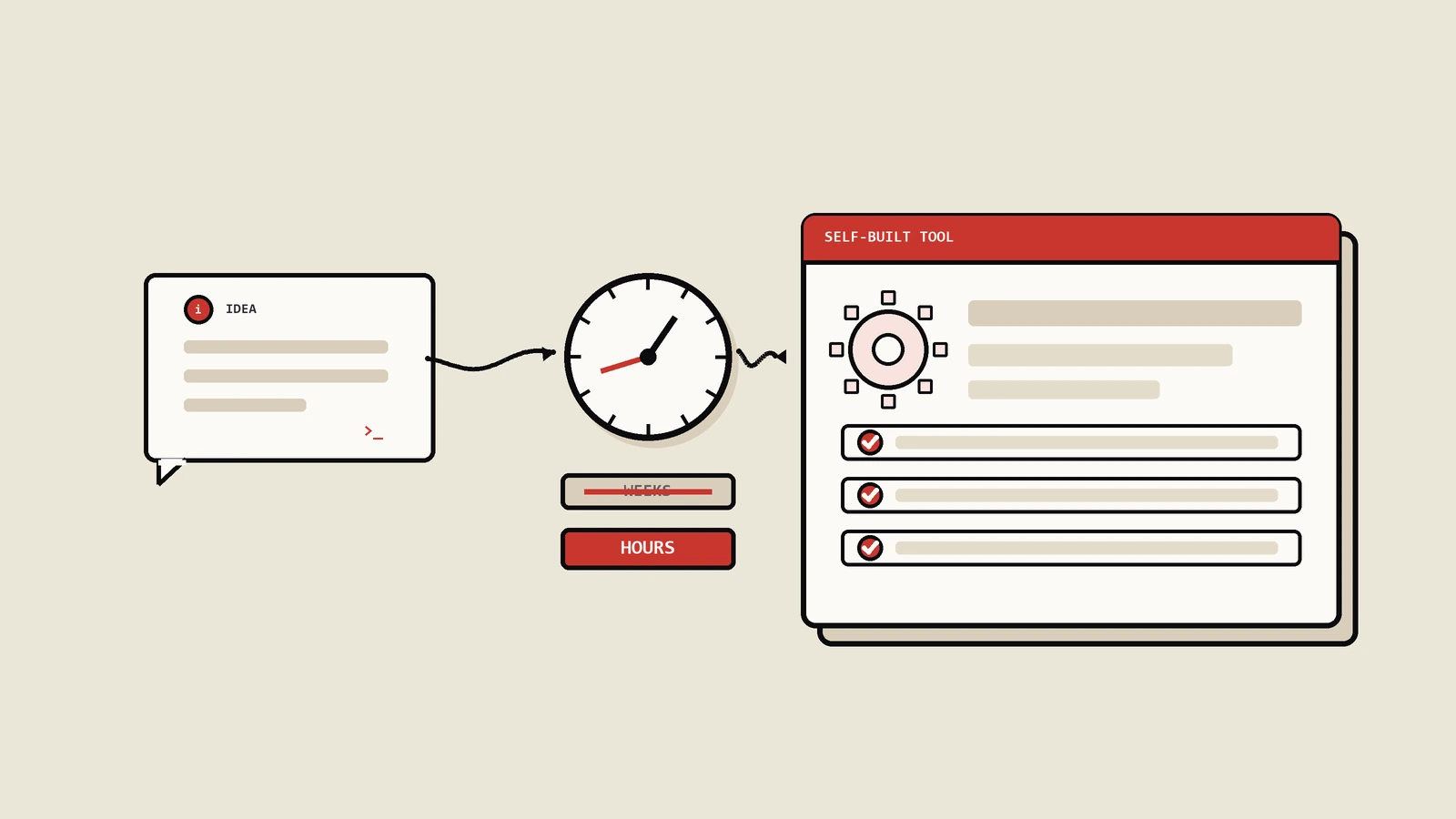
上个月保哥帮一个北美家居DTC客户排查内链结构,需要把GSC里近半年三十多万行的查询数据,和Screaming Frog导出的两万个URL做关联,捞出那些"高展现、低点击、却没有任何内链指向"的页面——这种页面是流量潜力被自己埋掉的重灾区。这活搁以前只有两条路:要么求客户那边的工程师排期,回复通常是"下个迭代看看",约等于两周后;要么自己在Excel里手动炼狱,三十万行还没打开表格就卡死了。那天用Cursor把关联逻辑、阈值、输出格式描述了一遍,四十分钟出了个能跑的脚本,当天就拿到了那批被内链遗忘的高潜力页清单,客户当周就开始改。这就是vibe coding对SEO最直接、也最容易被讲浅的改变——它动的根本不是"SEO会不会写代码",是"想法到结果之间那段要命的排期"。
vibe coding给SEO的,到底是什么优势?
先把优势的本质讲准,否则很容易把它理解成"SEO现在也能写代码了"这种浅层结论,然后用错地方。vibe coding就是用自然语言向AI编码工具(Cursor、Claude Code、Replit、v0这一类)描述你要什么,它把代码写出来,你跑、看、再用自然语言迭代。它对SEO真正的杠杆,在于一句话:把"想法→可用原型"之间的延迟,从周和月的量级,压到小时的量级。
这件事为什么是分水岭,得回到这个行当一个憋了十几年的老痛点:SEO的瓶颈从来不是没想法。随便一个干了几年的SEO,脑子里常年存着十几个"要是有个小工具能批量看XX、能自动比对YY就好了"的念头。这些念头九成九都死在同一个地方——它需要写代码,而在任何一个有产品线的公司里,一个内部SEO小工具的开发优先级,大概排在第八百位,永远被排在收入功能后面。结果就是想法烂在脑子里,或者用人肉硬扛,扛到没人愿意再提需求。
这里值得把"延迟压缩"这件事再算笔账,因为它的复利效应被严重低估了。一个想法从产生到验证,传统路径的延迟主要不在写代码本身,在三个环节:说服别人这值得做、排进队列等资源、来回沟通需求。这三段加起来,一个内部工具想法的平均"想到到验证"延迟,据实际观察通常是四到八周,而且大部分想法根本走不到验证就死在第一段。vibe coding几乎把这三段全砍掉了——你不需要说服任何人,不需要排队,需求就在你自己脑子里不用传递。延迟从周级压到小时级,表面是快了几十倍,实际影响是质变:当验证成本低到几小时,你会愿意去试那些"大概率不成、但万一成了很值"的想法,而这类高风险高回报的想法,恰恰是真正拉开差距的来源。延迟高的时候,你只敢把宝贵的开发资源压在"看起来很稳"的想法上,而看起来很稳的想法,通常回报也平庸。
vibe coding把这条死亡链路从中间斩断了:验证一个想法,不再需要先说服工程团队相信它值得做、不再需要排进迭代、不再需要等。SEO自己几个小时就能做出一个能验证假设的原型,验证成立再谈下一步。整个"想到、验证、落地"的循环,从以季度计,直接压缩到以天计。所以会用和不会用这件事拉开的差距,根本不在技术高低,在迭代速度——会用的人一周能真刀真枪试五个想法、砍掉四个、留一个继续打磨;不会用的人一个季度才推动得了一个想法进开发,还不一定排得上。一年下来,前者试过两百个想法,后者试过四个,复利差距大到没法追。
这里要提醒一个反向的认知误区,免得读者从一个极端滑到另一个极端:迭代速度快,不等于做的东西就一定对。vibe coding降低的是"试错的成本",不是"判断的门槛"——它让你能快速做出一个东西,但那个东西是不是解决了真问题、那个分析结论可不可信,依然完全取决于你的SEO判断力和验证习惯。一个判断力差的人用了vibe coding,只是从"慢慢地做错事"变成"飞快地做错一堆事",还误以为自己很高产。所以这件事真正放大的,是判断力本身:判断力强的人,迭代速度的杠杆让他的优势指数级放大;判断力弱的人,同一个杠杆让他的错误也指数级放大。工具是中性的,它只负责放大,不负责纠偏。
哪些SEO活适合用vibe coding,哪些碰都别碰?
这是用好它的第一道、也是最重要的一道分界线,绝大多数翻车都源于这条线没划清:没分清哪些活能vibe、哪些活一旦vibe了就是给自己埋雷。判断标准其实可以精确到一句话——看这段代码万一出错,后果是"可回滚的一次性损失",还是"会沿着信息架构扩散开的系统性损失"。
| 适合vibe coding | 为什么安全 | 绝对别用vibe coding | 为什么危险 |
|---|---|---|---|
| 一次性数据处理(GSC大文件、日志解析) | 跑完即弃,错了重跑一遍,产出不进生产 | 站点生产模板(URL结构、渲染策略) | canonical、hreflang、内链、sitemap、语义HTML、渲染方式是涟漪型决策,事后改要重构路由甚至重做整个信息架构 |
| 内部分析工具(内链图、关键词聚类) | 产出是给人看的中间结果,人会复核再决定 | 会批量改信息架构的脚本 | 一次写错全站受影响,回滚成本极高,有时根本回滚不了 |
| 想法验证原型 | 目的是尽快证伪,本来就不追求工程质量 | 面向用户的高并发功能 | 性能、安全、边界没人兜底,出事直接在用户侧爆 |
| 取数脚本(SERP、搜索量、API拉取) | 输出是一份数据,不是线上行为 | 直接写生产库的自动化批改 | 静默失败时无声破坏数据,等发现时已经晚了好几周 |
为什么生产模板这一类绝对不能vibe,值得把机制讲透,否则总有人觉得"我小心点不就行了"。问题不在于你够不够小心,在于这类决策是涟漪型的:canonical指向哪、hreflang怎么配对、内链怎么分布、sitemap怎么分组、用什么渲染策略、HTML语义结构怎么搭——这六样里任意一样,一旦定下来就会沿着所有页面模板扩散,后面每加一个页面都在复用这个决策。等你三个月后发现当初vibe出来的渲染策略让关键内容进不了首屏,改它就不是改一个文件,是回头重构路由、重写组件、有时甚至要把整个信息架构推倒重来,代价是当初"省下"那点时间的几十倍。vibe coding的代码有个隐蔽特性:它解决你描述的那个点解决得很快,但它不会主动替你考虑这个点和整个架构其余部分的耦合,而生产模板恰恰是耦合最深的地方。所以这条线不是"小心就能跨",是"结构上就不该跨"。
一句话把这条线钉死:vibe coding适合"精度不致命、可回滚、不进生产"的活,绝不适合"一处错全站塌、且事后极难补救"的活。开头那个家居客户的内链关联分析,为什么敢放心vibe?因为它产出的就是一张清单,交给人看、人来决定改哪些,脚本本身从头到尾不碰线上一个字节。如果当时图省事,让脚本"分析完顺手把建议的内链直接写进生产库",那就是把一次性分析的便利,押在了系统性损失的风险敞口上——这两件事的风险根本不在一个量级,省下的那点时间不够赔的。
一个SEO能在几天里vibe出哪些真有用的工具?
讲点具体的,空谈优势没意义。下面这些都是SEO日常真会反复用到、用vibe coding几小时到一两天就能出可用版本、而且都稳稳落在上面那张表安全区里的活。
处理大到Excel直接打不开的导出。GSC十六个月的完整数据、几十万行的Screaming Frog爬取、上百万行的服务器访问日志——这些用表格工具是灾难,但把逻辑描述清楚后,一个脚本几十秒跑完。最高频的用法是从原始日志里把Googlebot的真实抓取行为筛出来:哪些URL被高频抓取却没带来任何流量(抓取预算被浪费)、哪些重要页好几周没被抓过一次(收录风险)——这是任何第三方工具都给不全的一手数据,因为它来自你自己的日志。
把几千个关键词聚类并映射到页面。手工分词、分意图,几千个词能分到人崩溃。用向量化加聚类,几千个词自动分成主题簇,再算每个簇和现有页面的主题距离,直接给你两张清单:哪些簇没有任何对应页面(实打实的内容缺口)、哪两个页面在抢同一个簇(自我竞争,互相拉低排名)。
内链图诊断。把全站链接关系建成一张有向图,自动跑出孤岛页、内链权重的畸形分布、锚文本过度集中在哪几个词。再进一步,用页面向量算两两之间的主题相似度,给出"这两个页面高度相关却没有互链"的具体建议——这正是结构化内链该补的位置,而怎么用结构化数据把这类相关关系固化到页面里、让它对SEO真正生效,见用SignificantLink和RelatedLink结构化数据提升内链。
批量生成并注入schema、揪出近重复内容簇。按页面类型批量产出对应的结构化数据、通过接口灰度铺到多页;用产品描述的向量相似度做聚类,把"换了个名字其实是同一段"的近重复簇揪出来——电商站尤其需要这个,这种簇是稀释主题、内部互相抢排名的隐形杀手,人工一个一个看根本看不过来。再补两个实际用得最顺手、却很少被列进"vibe coding用例"的活。一个是"把多个数据源对账成一张可信底表":GSC的查询、爬虫的页面清单、CMS导出的内容元数据、第三方工具的关键词数据,这几份东西字段对不齐、口径不一致是常态,人工对账极其耗时且容易错。让脚本按URL或关键词做主键关联,顺手标出"GSC有但站点已删""爬到但GSC零展现"这类对不上的异常,一张干净底表出来,后面所有分析都站在可信地基上——这活产出是给人看的表,绝对安全,但价值极高,因为脏数据带来的错误判断,比没数据还危险。另一个是"一次性的批量诊断":比如全站标题和H1是否一致、是否有大批页面缺meta description、结构化数据是否成片缺失,这种"盘一次现状"的活,vibe一个脚本半小时跑完,比逐页人工抽查全面得多,而且因为只读不写,零风险。
这些之所以又快又安全,是因为它们的产出要么是给人复核的清单,要么是可灰度、可回滚的结构化数据,出了错不会沿着信息架构扩散。
为什么"几天造个工具"反而常常埋雷?
说完糖,得说刀,而且这把刀比大多数人以为的钝刀要锋利。vibe coding最危险的地方,不是它写不出能跑的代码——它几乎总能写出"看起来能跑"的代码——而是坑恰好埋在你不会去看的地方。下面这几个,是保哥自己踩过和帮客户收过的,基本都是教程不会讲的:
- 生成的爬虫默认不带速率限制。你说"帮我抓这批URL的标题和H1",模型给的代码十有八九没有任何速率控制、没有并发上限、没有失败退避重试。拿去抓客户自己的站,瞬时并发能把一个没做好防护的中小站直接打到大面积5xx,你成了自己客户的DDoS源;拿去抓别人的站,IP当场被对方封掉,后面什么都干不了。这几行防护代码模型不会主动加,你不在提示里点名要,它就当你不需要。
- 生成的schema能过测试,但实体图是断的。模型给的结构化数据,字段填得齐,Rich Results Test也亮绿灯,但它经常漏掉@id以及实体之间的引用关系。结果是:单个页面的schema看起来"完全正确",整站的实体图却是一盘互不相连的散沙,你拿不到知识图谱本该累积的那部分实体权威——而且这个问题不会报错,测试工具也不报,它只是悄悄让你少拿分。
- API密钥被写死,甚至暴露在前端。让它做个调SERP接口的小工具,它会非常自然地把key明文硬编码进代码里,如果是个带页面的工具,还可能直接写在前端能看到的地方。你高高兴兴把这个好用的小工具分享给同事或者发到群里,key也就跟着一起泄出去了,等收到接口异常计费才发现。
- 相似度内链工具把模板样板文字也算进了相似度。用余弦相似度找"该互链的相关页",如果没有显式地先把导航、页脚、侧边栏、CTA这些全站重复的样板文字剔除掉,算出来的相似度会被这些样板严重拉高,最后给你的是一堆"全站页面互相都很相似、应该到处互链"的废建议。这个坑极其隐蔽,因为工具不报错,它只是一本正经地给了你错的答案,你不验证根本看不出来。
还有两个更阴的坑,踩过的人才知道有多疼。一个是时区和编码:让它处理GSC导出和日志,它默认按运行环境的本地时区和编码解析,你在不同机器上跑同一个脚本,得出的"某天抓取量"可能整体错位一天,或者中文URL被解析成乱码导致整批关联失败——而它不会报错,只会安静地给你一份错位的结果。另一个是分页和限额:调外部接口拿数据,模型给的代码常常只取了第一页就以为拿全了,GSC接口默认单次返回有上限,SERP接口也有每页条数限制,它不主动做翻页聚合,你以为分析的是全量,其实只分析了前一千行,结论方向都可能是反的。这两个坑和前面四个一样,共同特征是"不报错的错"——代码跑完了,绿的,有输出,但输出是错的,而且错得很有迷惑性。
这几个坑有一个共性:AI乐于帮你写功能,也同样乐于在你看不见的地方省掉防护、断掉连接、给出看似合理实则错误的结果,而且全程不报错、不提醒。所以vibe出来的任何东西,都必须当成"一个很快但不靠谱的实习生交上来的初稿"来逐项验,绝不能当成"它能跑就说明它对"。怎么从一开始就在提示和流程里把这些坑显式规避掉、把vibe这件事做规范,有一篇实操单独讲过,见用Cursor开发SEO工具的Vibe Coding实战。
vibe-coded工具三个月后为什么没人敢动?
比"当下写错"更深、更要命的问题是"维护债"。一个vibe出来的工具,上线那天跑得好好的,三个月后会变成全团队没人敢碰的黑箱——这几乎是必然结局,除非你从第一天就把它当工程项目对待。
原因有两层,第二层尤其致命。第一层是隐含假设没人记得。vibe coding的时候,你和模型之间存在一大堆没被写下来的默契:这个字段一定有值、那个接口返回结构永远固定、这批URL一定是某个格式、这个目录下文件一定按时间命名。三个月后,这些假设没有任何人记得了——包括你重新去问的那个AI自己也不记得,因为当初的对话上下文早没了。这时候改一行就崩,没人知道为什么崩,也没人敢动,工具就这么僵在那。这里有个特别值得记的反直觉点:vibe出来的代码,可读性往往比人写的还差,原因恰恰是它"太能写了"。人写代码受限于自己的理解,会本能地把逻辑拆到自己能看懂;模型不受这个限制,它能一口气生成一大段能跑但层层嵌套、隐含一堆未言明前提的代码,你当时只验证了"它跑通了"就放过,没人真正逐行读懂过。三个月后要改,你面对的不是一段你写过、只是忘了细节的代码,而是一段从来没有任何人真正理解过的代码——这比维护遗留代码还难,遗留代码至少当初有人懂过。务实的纪律是:任何打算留超过一次性使用的vibe产物,必须有人逐段读懂并写下它的关键假设,读不懂的部分要么让它重新解释到你懂、要么不许它留下来。
第二层是静默失败,这一层能造成真实损失。设想一个每天自动跑的内链建议脚本:某一天,它依赖的SERP接口悄悄改了返回字段名,脚本拿到的是空数据。关键在于——它不报错。它老老实实地按照"空"继续往下算,然后一本正经地输出一份"建议大批量删除现有内链"的结果,如果这个脚本还被设成自动执行,它就真的把内链删了,而你要等到两三周后流量出现异常,才反推回来发现是它干的。没有告警的自动化,根本不是自动化,是一颗设了引信的定时炸弹。
插一个真实场景,说明它有多隐蔽。一个跑了两个多月、看起来岁月静好的关键词聚类脚本,产出一直被当成内容规划的依据。直到有人偶然交叉核对,才发现它依赖的向量化接口在某次升级后,对超过一定长度的输入会静默截断而不报错——长一点的关键词只拿前半段去算相似度,聚类结果早已系统性偏了快两个月,基于它做的好几轮内容规划全建在沙子上。要害不在"接口会变",接口当然会变;要害在于,如果当初脚本在"输入被截断"这种边界上有一行断言、出问题会主动喊一声,它第一天就暴露了,而不是错满两个月才被偶然撞见。
静默失败之所以是最危险的一类,是因为它违反了人对自动化的根本预期:人会默认"没报警就是没事"。一个会崩、会报错、会发红色告警的脚本,反而是安全的,因为它出问题时你立刻知道、立刻能停;真正吃人的是那种出了问题还一脸正常继续跑、还在持续产出"看起来合理"的错误结果的脚本,等你从下游某个反常指标反推回来,它可能已经安静地错了一个月,污染了一个月的决策。所以判断一个vibe产物能不能转长期跑,核心不是看它功能对不对,是看它"错的时候会不会喊"——会喊的,补补还能用;不会喊的,功能再全也是定时炸弹,而且这颗炸弹的引信长度等于"你多久才会偶然发现它错了"。这就是为什么对长期跑的东西,告警不是附加功能,是它的本体:一个不会在出错时主动喊停并通知你的自动化,本质上不具备"可被信任地无人值守"这个属性。
这就是为什么"几天能vibe出一个工具"是优势,而"把vibe出来的工具当生产系统裸跑"是灾难,两者只隔着一层工程纪律。一个要长期跑的SEO自动化,要的从来不是"能跑",是这么几样硬东西:幂等且可重放(同样的输入跑两次结果必须一致、且任何一步都能回滚)、关键步骤有断言(数据为空、行数比上次骤降、格式不符就主动报错停下,而不是带病继续算)、告警是它的核心功能而不是事后补丁、还要有成本闸防止某天接口异常把调用量和账单打爆。这套工程纪律,和"快速vibe一个原型"完全是两种模式,什么时候必须从前一种切到后一种、切的时候具体要补哪些东西,有一篇按软件工程视角系统拆过,见SEO自动化为什么总烂尾:按软件工程做才跑得久。
信息怎么被"看见",为什么是被低估的SEO优势?
前面都在讲工具,这一层讲的是更值钱、也更少人意识到的一块优势:信息被视觉化呈现的方式本身,就是一种SEO竞争力。一个能让用户一眼就拿到答案、还能自己动手筛的页面或组件——一个交互式的对比、一个可按条件筛选的表、一个把复杂决策拆成三步选择的小工具——它命中的是"格式精确契合用户意图"这一层信号,而这层信号在AI和现代搜索里被放大了,不是可有可无的装饰。
过去这种"用交互界面即刻回答意图"的东西很贵:要产品设计、要前端开发、要排进迭代,只有大站做得起,中小站只能用一大段文字硬扛同一个意图,体验天然差一截,行为信号也跟着差。vibe coding做的事,是把这种东西的实现成本直接砍掉了一个数量级——一个SEO自己花一两天,就能给一个高意图页面做出一个真能帮用户做决定的交互组件,而不是再写八百字去解释一件本该一目了然的事。这不是锦上添花,它直接影响这个页面在SERP里的格式契合度、用户停留与交互这些真实行为信号。举个具体到能照做的例子:一个高意图的"X怎么选"页面,传统做法是写三千字把各种维度讲清楚,用户读完还得自己在脑子里把信息组装成一个决定。换个做法,用一两天vibe一个轻量的交互组件——用户勾几个关键约束(预算、场景、硬性要求),组件即时给出一个收窄到两三个选项的建议加理由。同一个意图,后者的体验、停留、完成度全面碾压前者,而且它天然产出可被结构化的内容(每个选项及其适配条件本身就是高质量、可被AI抽取的单元)。注意这类组件之所以适合vibe coding,是因为它落在前面那张表的安全区:它是一个相对独立的前端交互件,不改信息架构、不写生产库、出错也只影响这一个页面可灰度回滚——它恰好是"高价值且低风险"的那种活,这正是vibe coding的最佳着力点。能识别出"哪些SEO价值点恰好落在vibe coding的安全区里",这个判断力本身就是优势的一部分。
把"信息怎么呈现"从"那是设计和前端的事"重新理解成"那是SEO的事",再用vibe coding把它的实现成本打下来——这是目前真正能拉开差距、但绝大多数团队还没反应过来的一块。先动起来的人,吃的是认知差加成本差的双重红利。
SEO团队该怎么把vibe coding用成可持续优势,而不是技术债工厂?
把前面所有东西收成一套能直接执行的纪律。核心就一句话,记住它比记住任何工具名都重要:原型和生产是两种东西,绝不能让原型偷偷长成生产。几乎所有vibe coding酿成的技术债,根子都是这一句没守住。
- 物理隔离原型与生产。vibe出来的东西默认身份就是"一次性、给人复核",不允许它直接写线上库、不允许它无人值守裸跑、不允许它接生产流量。它要想转正常驻,必须先走完下面的规范化流程,没有例外。
- 每个vibe产物过一张固定的验证清单。不管多急,固定问这四件事:有没有速率控制和失败退避?有没有把密钥写死或暴露在能被看到的地方?关键数据为空或异常时,它是报错停下还是带病继续?输出是否已经把模板样板这类已知噪声显式剔除?这四项里任意一项不过,这个产物的结果就不准用于任何会影响线上的决策。
- 明确设一条"该交给真工程师"的红线。当一个原型满足以下任意一条——需要无人值守长期跑、需要写生产数据、会影响信息架构、要面向用户——它就已经长过了"good enough"这个尺寸,必须由工程按幂等、断言、告警、成本闸正经重写一遍,而不是继续在那段没人看得懂的原型代码上打补丁续命。
- 成功的原型要被规范化,不是直接上线。原型证明了"这个想法确实有价值"之后,正确动作是把它当成一份需求文档交付出去重写,而不是把那段验证用的vibe代码塞进crontab就不管了。要时刻分清:原型的价值是"它验证了这个想法值得做",从来不是"这段代码可以这样用一辈子"。
- 守住任务边界。哪些SEO任务值得自动化、自动化到什么程度有明确的投入产出边界,不是所有"能自动化"的都"该自动化",有些活人工反而更快更稳,这条边界单独梳过,见2026年SEO自动化的10个任务边界与工具栈。
这套纪律里还有一个最容易被跳过、却最该坚持的动作:给每个值得留下来的vibe产物,写一个"它能做什么、不能做什么、依赖哪些假设、什么情况下结果不可信"的一页纸说明。听起来像走形式,但它解决的正是前面所有问题的总根源——隐含假设没人记得。这一页纸花不了十分钟,却是三个月后那个工具能不能被信任、能不能被接手的唯一凭据。判断一个团队是不是真把vibe coding用成了优势,有个很准的外部信号:看他们留下来的工具,有没有这一页纸。没有的,工具再多也只是一堆迟早集中爆雷的债;有的,才是真的把试错速度沉淀成了组织能力。
保哥自己这两年的用法其实很简单,一句话:把vibe coding当成一台"超级快的草稿机"。一切探索性的、一次性的、给自己看的活,全用它,迭代飞快,错了就重来,不心疼;但凡某个原型被验证"这个值得长期跑下去",立刻停手,把它当一个正式的工程项目从头重做,该上的幂等、断言、告警、成本闸一个不能少。靠这套节奏,这两年给客户做掉了一大堆原本要排期好几个月的分析和内部工具,没有一个变成后来没人敢碰的黑箱。说到底,vibe coding是不是你的优势,根本不取决于你会不会让AI写代码——这个门槛已经低到人人都会——只取决于你分不分得清哪些该快、哪些必须慢。分得清的人,它是杠杆;分不清的人,它就是一座以肉眼可见速度堆高的技术债工厂。
常见问题解答
不懂编程的SEO能靠vibe coding做出可用工具吗?
能做出一次性分析和内部工具,这正是它的价值所在。但你需要会判断输出对不对、会问关键问题(有没有限速、密钥是否暴露、空数据是否报错)。不懂编程不影响用它做草稿,但不会验证就直接信结果,迟早出事。
vibe coding做的SEO工具能直接上生产吗?
不能直接上。原型证明想法有价值后,要当需求交给工程按幂等可重放、关键步骤断言、告警、成本闸重写。把没人看得懂的vibe代码塞进定时任务裸跑,是最典型的技术债来源,迟早静默失败无声破坏数据。
哪些SEO任务最适合用vibe coding快速做?
精度不致命、可回滚、不进生产的活:GSC大文件和日志解析、关键词聚类映射、内链图与孤岛页诊断、近重复内容簇检测、取数脚本。共性是产出给人复核或可灰度回滚,出错只是一次性损失不会沿信息架构扩散。
vibe coding生成的代码最常见的隐患有哪些?
四个高频坑:爬虫默认不限速会打挂站或被封、schema过测试但漏@id导致实体图断裂、API密钥被硬编码甚至暴露前端、相似度内链工具没剔除模板样板算出全站互链废建议。模型不主动加防护,你不问就没有。
为什么vibe出来的工具几个月后就没人敢改?
两层原因:一是vibe时大量隐含假设没写下来,几个月后没人(包括AI)记得,改一行就崩;二是静默失败,依赖的API改字段返回空,脚本不报错继续算出错误结果,很久才被发现。没有告警的自动化是定时炸弹。
vibe coding会取代SEO团队里的开发吗?
不会,它改变分工而非取代。SEO用它做探索、一次性和内部工具,把开发资源从这些琐碎需求里解放出来,专注模板、基础设施、可扩展性这些真工程。会改信息架构、面客高并发、需长期无人值守的部分,仍必须工程师按工程纪律来。
权威参考资料
本文标题:《Vibe Coding重塑SEO工作流:自养工具的杠杆与10步实操》
本文链接:https://zhangwenbao.com/vibe-coding-seo-competitive-advantage.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0