AI经常编造不存在的链接:幻觉引用怎么查、怎么把404变成机会

本文目录
- 先搞清楚:AI幻觉链接到底指什么
- 实测数据:AI给的链接有多少是坏的
- 更狠的一组:引用准确率低于四成
- 先盯哪个引擎:四家AI谁的幻觉最离谱
- 为什么大模型会一本正经地编链接
- 这件事怎么就成了SEO和GEO的问题
- 算笔账:1%的坏链到底漏掉多少人
- 动手前先分清:是幻觉,还是你自己删的页
- 第一步:在日志和GSC里把幻觉URL揪出来
- 第二步:把高频幻觉URL用301变成真实入口
- 该建真页还是301?一张判断表
- 301收编的实操:从一堆404到几条规则
- 第三步:让AI从一开始就把你认对
- 换个角度:幻觉URL其实在替你标注内容缺口
- 错误归属怎么办:主动纠偏
- 出海独立站还要多担一层坑
- 监测节奏:多久查一次、查什么
- 几个常见误解
- 常见问题解答
- AI给的链接点进去404,是我网站的问题吗?
- 怎么发现AI在编造指向我网站的链接?
- 幻觉URL到底该建成真页,还是301重定向?
- AI把我的内容说成是别人的,怎么纠正?
- 为什么大模型会编出格式完全正确、却不存在的链接?
- 幻觉链接这事会随着模型升级自己消失吗?
- 权威参考资料
摘要:AI搜索现在会大大方方给你一条编造出来的链接——点进去要么404,要么把别人的内容挂在你名下。这不是偶发抽风,而是大模型按“最像的下一个词”生成时的结构性副产品。哥伦比亚新闻学院的横评显示,八家AI搜索引擎超过六成的回答引用有误;SE Ranking抓了十万条ChatGPT提问,发现被引URL里1.34%直接是坏链,其中九成是404,坏链率是Google AI概览的两倍多。对做SEO和GEO的人来说,这既是麻烦也是机会:麻烦在于真实意向流量撞上404白白流失、品牌被张冠李戴;机会在于那些被反复编造的URL,其实在替你标注内容缺口。这篇把幻觉链接的三种形态、为什么会发生、怎么在日志里揪出来,再到用301把幻觉URL收编成真实入口的完整打法,一次讲透。
先说个保哥这两年越来越常遇到的场景:客户拿着ChatGPT的回答截图来问,“你看AI都推荐我们了,还给了链接”,结果那条链接点进去是一个干干净净的404页面——域名是他家的,路径却是他家从来没建过的。AI不是引用了他,而是凭空替他造了一个页面地址。这类现象有个不太严谨但很传神的叫法:幻觉链接(hallucinated link)。它正在从技术圈的谈资,变成实实在在影响流量和品牌的SEO问题。
先搞清楚:AI幻觉链接到底指什么
幻觉链接不是一个精确的技术术语,而是对一类现象的统称。按维基百科对AI幻觉的定义词条的说法,AI幻觉指模型生成了看起来合理、实则错误或凭空捏造的内容,而链接、引用、出处是重灾区。落到SEO语境,它至少有三副面孔,很多人把它们混为一谈:
- 编造URL:模型给出一条格式完全正确、域名也是真的、但目标页根本不存在的地址,点进去就是404或410。这是最典型的“幻觉链接”。
- 错误归属:链接本身能打开,但AI把内容的出处认错了——把竞品的观点安在你头上,或者把你写的东西说成是别人家的。地址是真的,归属是假的。
- 虚构出处:AI在正文里煞有介事地说“根据某某机构某年的报告”,那份报告、那个数据、那位专家可能压根不存在。法律圈那起著名的Mata诉Avianca案,律师引用了ChatGPT编造的判例,就是这一类。
这三种形态的危害和应对完全不同,后面会分开讲。但它们共享同一个病根:模型在“猜”,而且猜得特别像真的。
实测数据:AI给的链接有多少是坏的
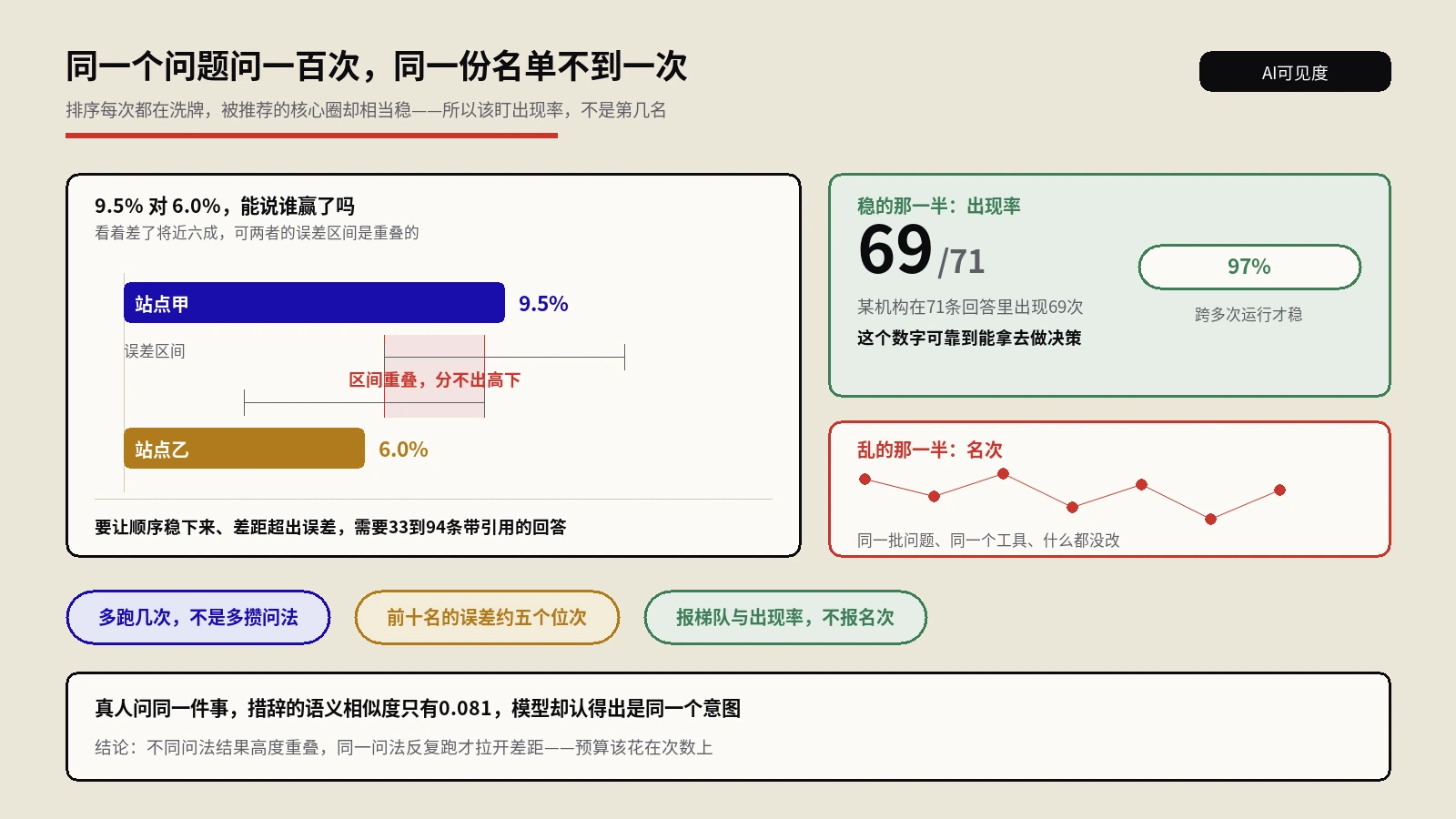
光说现象没有说服力,来看数字。SE Ranking对十万条ChatGPT提问做的抓取分析是目前样本最大的一份:他们从10万个提问里提取出约14.5万条被ChatGPT引用的URL,逐一去查HTTP状态码,结果是——
- 1.34%的URL返回4xx客户端错误,其中91%是404 Not Found(1770条),另有8.33%是410 Gone,剩下极少数是451法律原因下架;
- 单看404,ChatGPT的比例是1.22%,而Google AI概览只有0.56%,AI模式0.87%,普通自然搜索结果0.65%。换句话说,ChatGPT给你坏链的概率,是Google AI概览的两倍多。
1.34%听起来不高,但换算成绝对量就吓人了:如果一个品类每天有上万次AI提问触及你的行业,几百次落到404上,日积月累就是一笔不小的意向流量在门口被拒之门外。而且这只是“技术性坏链”,还没算上那些能打开、但归属错了的情况。
更狠的一组:引用准确率低于四成
如果说SE Ranking量的是“链接通不通”,那哥伦比亚新闻学院Tow Center的八引擎引用测试量的就是“引用对不对”,结论更让人坐不住。他们拿20家出版商的真实文章,每家挑10篇,让8个聊天机器人识别出处,一共1600次测试:
- 整体超过六成的回答引用有误;
- Grok 3是灾难现场——200次里有154次把用户导向了错误或404页面,失败率77%;
- ChatGPT有134次(约67%)给出了错误答案;Gemini在能抓到10家出版商内容的情况下,只有1次完全答对;
- 最反直觉的是,付费版反而更糟:Perplexity Pro和Grok 3这类付费模型“给出斩钉截铁但错误的答案,而不是老老实实说不知道”,错误率比免费版还高。
这份研究里有个细节值得SEO记住:Grok 2经常直接链到网站首页而不是具体文章。这说明AI在“找不到精确出处”时,会退而求其次编一个看似合理的地址,而首页、常见路径正是它最容易编对格式、编错内容的地方。
先盯哪个引擎:四家AI谁的幻觉最离谱
幻觉链接的严重程度,不同AI差得很远。监测资源有限时得分清主次,把前面两份研究的分引擎数据摆到一起,画像就清楚了:
- Grok系最离谱。Grok 3在Tow Center测试里200次有154次导向错误或404页面,失败率77%,是重灾区里的重灾区。你的用户要是在用Grok,几乎得逐条核对。
- ChatGPT量大、错得也不少。约67%的引用出错,加上它用户基数最大,绝对影响面最广,是多数出海站要优先盯的对象。
- Perplexity相对好一些。错误率约37%,是几家里表现较好的,但它偏爱机构和学术来源,中小站想被它引对,门槛反而更高。
- Gemini反差最大。在能抓到出版商内容的前提下几乎全错,只有1次完全答对,说明能抓到和引得对,完全是两码事。
一个反直觉的点前面提过、这里再钉一遍:付费版不一定更准。付费模型更倾向给斩钉截铁的答案,而不是老实说不知道,错起来反而更理直气壮。所以别因为自己用的是Pro版就放松核对——花了钱的幻觉,还是幻觉。
为什么大模型会一本正经地编链接
要治病得先懂病理。大模型编链接不是bug,是它工作方式的直接结果。一篇拆解大模型为什么产生幻觉的论文把机制讲得很清楚,用大白话转译一下:
- 它的目标是“像”,不是“真”。大模型的训练本质是预测下一个词——给一段文字,猜接下来最可能出现什么。训练信号是流畅度,数据里并没有标签告诉它哪句是真、哪句是假。所以它天生就是个“很会顺着说”的机器。
- URL格式太有规律,最好编。域名加斜杠加英文单词加连字符,这种结构在训练数据里出现过千万遍。当被问到训练里没见过、或者把几个概念拼在一起的新问题时,模型会照着这个格式“外推”出一个语法上无懈可击、实则从未存在的地址。
- 错误会自我强化。自回归生成里,一旦早期吐出一个错误的域名或路径,它就成了后文的上下文,模型为了“自圆其说”会顺着这个错继续编下去。一个幻觉的开头,往往拖出一整段幻觉。
理解这一层很重要:它意味着幻觉链接不会因为模型变大就彻底消失,只会被压低概率。指望等下一代模型自动修好,是靠不住的。你能做的是让自己这一侧的“地基”更硬,让AI更容易抓到真实的你。
这件事怎么就成了SEO和GEO的问题
可能有人觉得,AI乱编链接是AI厂商的锅,跟我一个做站的有什么关系?关系大了。Nieman Lab对这项研究的综述点得很直白:引用错误已经是全行业的慢性病,不是某一家的偶发故障。既然是慢性病,你就得把它当成日常运营的一部分来管,具体到四笔账:
- 真实意向流量在门口流失。会用AI搜索、还愿意点链接的用户,往往是意向最强的那批人。他们冲着你来,却撞上404,这一单基本就黄了,而且体验极差。
- 品牌被张冠李戴。AI把你的原创观点说成是竞品的,或者把一段你根本没说过的话安在你品牌头上——前者是白干,后者可能是背锅。
- 竞品截胡。当AI找不到你的准确页面,可能顺手把流量导给了排得更靠前、实体更清晰的竞品。
- AI概览时代被放大。零点击的AI概览把答案直接铺在搜索结果顶部,一旦它引错、链错,错误的曝光量是过去的量级。关于AI搜索带来生意但后台一片空白的零点击时代归因怎么补,站内之前专门拆过,幻觉404正是那套归因盲区里最容易被忽略的一块。
算笔账:1%的坏链到底漏掉多少人
很多人对1.34%这个数字无感,觉得小到可以忽略。用一个简化的算例把它掰开——数字是假设的,但量级贴近真实出海站:
假设你的品类在AI搜索里每天被提及并附上你站链接1万次,按ChatGPT约1.2%的404率算,就是每天120次点击撞墙。一个月3600次,一年约4.3万次。这4.3万次不是随便逛逛的流量,而是已经被AI筛过、带着明确意向、主动点链接来找你的人,转化价值远高于泛泛的自然流量。哪怕其中只有2%本可以成单、客单价1000元,一年就是86万的生意在一个404页面上无声蒸发。
这还只算了编造URL这一种。把错误归属造成的品牌损耗、被竞品截胡的部分叠上去,账面只会更难看。所以别拿百分比麻痹自己,换算成活生生的人数和金额,你就知道这件事值不值得每周花半小时去治了。
动手前先分清:是幻觉,还是你自己删的页
治理幻觉链接有个前置动作千万别跳过——确认这条404到底是AI编的,还是你自己造成的。两者混在同一张清单里,处理逻辑完全相反。
判断方法是查这个URL的前世:翻CMS的历史记录、数据库的文章表、或者旧的sitemap存档,看这个路径曾经有没有真实存在过。查得到,说明是你删了页或改了结构没做重定向,属于常规死链治理,该301的301、该恢复的恢复;如果整个站史上从没有过这个路径,那基本就是AI凭空编的幻觉链接,按后面的判断表决定收编还是放任。
这一步之所以关键,是因为它决定了你要处理的是自己的技术债,还是顺着AI的水推舟。分不清就动手,容易把本该恢复的重要页草率重定向掉,或者反过来花力气去修复一个根本不该存在的地址。先分清,再动手。
第一步:在日志和GSC里把幻觉URL揪出来
治理从看见开始。幻觉URL不会自己报到你后台,得主动去捞。三个抓手:
- 翻服务器日志。找状态码404、且来源(referrer)或User-Agent带有AI平台特征的请求——比如referrer是chatgpt.com、perplexity.ai,或UA里出现相关标识。把这些404的路径单拉一张表,就是你的“幻觉URL清单”。
- 盯GSC覆盖率报告。Google Search Console的“页面”报告里,“未找到(404)”分组会积累外部指向你站的死链,其中一部分就是AI和抄了AI答案的页面制造的。按出现频次排序,高频的优先处理。
- 手动抽查。拿你品类里最核心的十几个问题,去ChatGPT、Perplexity、Google AI模式里各问一遍,看它给你家的链接对不对。这一步最笨也最真实,能发现日志里还没积累出量的新幻觉。
把清单建起来后,你会发现幻觉URL不是随机乱撒的,它们有明显的模式——某个不存在的分类目录、某种它“觉得你应该有”的页型。这恰恰是下一步的抓手。
第二步:把高频幻觉URL用301变成真实入口
这是整套打法里最实用的一招。既然AI反复把用户导到某个不存在的地址,而这个地址又符合合理的命名逻辑,那你与其让它404,不如把它301重定向到最相关的真实页面,等于白捡一批意向流量。Google官方的重定向与搜索指南把301(永久重定向)和302(临时)的语义讲得很清楚:用301告诉搜索引擎“这个地址永久搬到那边了”,权重和用户都会顺着过去。
操作上分两种情况:如果幻觉URL指向的内容你本来就有,只是路径不对,直接301到对应真实页;如果它指向的是一个你还没做、但用户和AI都期待你有的主题,那更好——这说明有真实需求,你可以先301到最接近的页兜底,再排期把这个页真正建出来。这一步和让AI主动引用你的逻辑一脉相承,站内在被检索和被引用的两套打法里讲过,被引用的前提是内容真实、可达、可读,301收编幻觉URL就是把“可达”这一环补齐。
该建真页还是301?一张判断表
不是所有幻觉URL都值得处理,也不是都用同一招。保哥用这张表来决定:
| 幻觉URL的情况 | 出现频次 | 推荐动作 |
|---|---|---|
| 指向已有内容,只是路径写错 | 不限 | 301到对应真实页,立刻做 |
| 指向合理主题,你还没这个页 | 高频 | 先301兜底到最近页,再排期建真页 |
| 指向合理主题,你还没这个页 | 低频 | 301兜底即可,暂不单独建页 |
| 路径怪异、无合理语义、一次性 | 极低频 | 不管它,返回标准404即可 |
| 指向已下架且不该复活的内容 | 不限 | 保持410 Gone,明确告诉爬虫“没了” |
核心原则就一句:有真实意向的幻觉URL才值得收编,纯噪声不必理会。别看到404就全站狂做重定向,把站搞成一团重定向意面,那是另一种病。
301收编的实操:从一堆404到几条规则
清单拉出来往往是几十上百条杂乱路径,一条条手动重定向不现实。实操上按这个顺序收敛:
- 按模式归组。把幻觉URL按路径特征聚类——大量落在某个不存在的目录前缀下(比如/guides/、/compare/),还是集中在某几个具体slug上。归完组你常会发现,几十条路径能被三五条规则覆盖。
- 给每组选目标页。目录型的,重定向到对应真实栏目或最相关的枢纽页;具体slug型的,逐一映射到语义最近的现有页。目标页要真的相关,别为了消灭404把用户一股脑扔到首页,那等于二次伤害。
- 用服务器级301落地。在Nginx、Apache或CDN边缘配规则,能用前缀匹配就别写死每一条。规则上线后,拿几条代表性幻觉URL实际点一遍,确认跳转到位、返回的是301而不是302。
- 回填监测。上线后继续盯这些路径的访问,看跳转后用户是留下了还是立刻跳出——跳出率高,说明目标页选得不够相关,得再调。
整套做下来,那批本来白白404的流量就被顺进了真实页面,断掉的转化链路重新接上。这活儿不复杂,难在坚持每周捞一次、稳定地做下去。
第三步:让AI从一开始就把你认对
前两步是被动补救,这一步才是釜底抽薪——减少幻觉的发生概率。核心是让AI在生成答案时,能更容易地“接地”(grounding)到关于你的真实信息,而不是靠猜。几个动作:
- 把实体讲清楚。用结构化数据、清晰的About页、一致的品牌名和描述,让机器明确知道“你是谁、做什么、官方地址是哪个”。Google那份讲怎么教AI认识你的实体专利解读,本质就是在降低AI把你认错、编错的概率。
- URL和canonical保持稳定一致。一个页面只留一个规范地址,别让同一内容散落在带参数、带斜杠、带大小写差异的多个URL上,减少AI“选错门”的机会。
- 去真实的高权威平台留足迹。AI更倾向引用它信得过的来源,站内拆过哪些网站最常被AI引用,Reddit、Wikipedia、YouTube这类高被引平台上你的真实内容越多,AI越不需要靠编来回答关于你的问题。
说白了,幻觉链接是AI在信息不足时的“填空”。你把关于自己的真实信息铺得足够密、足够清晰,它就没那么多空要填。
换个角度:幻觉URL其实在替你标注内容缺口
前面都在讲怎么防、怎么补,但幻觉链接还有个反直觉的用法——它是免费的市场调研。想想看:AI为什么会编出某个特定路径的URL?因为在它的统计里,“像你这样的站,就应该有这么一个页”。这背后是大量用户提问和内容模式的沉淀。
所以那张幻觉URL清单,换个眼光看就是一份需求线索表:AI替一堆用户喊出了“你应该有但没有”的内容。某个反复被编造的“对比页”“价格页”“某功能教程页”,恰恰是你内容矩阵里的洞。把高频幻觉URL的slug拆开读,你能读出用户和AI共同期待你覆盖的话题。这时候“建真页”就不只是补404,而是顺着真实需求扩内容资产——一箭双雕。有点像AI不小心把你竞争对手的作业本翻开给你看了。
举个具体的:如果日志里反复冒出/best-你的品类-for-beginners这类被编出来的路径,别只当它是噪声——它在提示你,大量新手用户正指望有一个面向入门者的选购或对比页,而你恰好还没做。顺着这条线索把页真正建出来,既接住了原本撞墙的流量,又填了一个有真实搜索需求的内容洞。AI的幻觉在这里反倒成了免费的选题雷达,前提是你愿意蹲下来读它。
错误归属怎么办:主动纠偏
编造URL好治,301一下就行;难的是错误归属——链接是真的,但AI把出处认错了。这类问题没法靠重定向解决,得从信号源头纠偏:
- 监测品牌被怎么引用。定期在各AI平台抽查关于你品牌、你核心观点的问题,看它归属对不对。发现系统性错误,记录下来。
- 强化正确的实体信号。如果AI总把你的原创数据说成别人的,往往是因为别人转载时链接、署名更规范。回到自己站把原创声明、作者信息、发布时间、结构化数据补齐,让“你是原始出处”这件事机器可读。
- 用一手证据占住话语权。原创数据、独家案例、第三方可验证的提及,是最难被张冠李戴的资产。当全网只有你有这份数据,AI想引错都难。
- 向平台反馈。多数AI产品都有反馈入口,遇到明显的错误归属,实事求是地报一条。单条未必立刻改,但这是官方修正的一环。
这类错误有多普遍?Tow Center那份研究里有个扎心的细节:ChatGPT甚至把链接编错到了OpenAI自己的新闻合作伙伴文章上——连“自己人”都认不准。所以别指望AI会自动帮你把出处摆对,主动把正确信号铺满,才是唯一靠得住的办法。
出海独立站还要多担一层坑
做出海的朋友注意,幻觉链接在多语言、多市场场景下会更严重。原因不难理解:AI对非英语市场、小众品类的训练数据更稀疏,“填空”的动作就更多。多语言站常见的带地区路径、带语言子目录的URL结构,本身命名空间就大,AI编错的排列组合也更多。
保哥手头一个做户外储能的出海独立站客户就踩过:AI在回答某个欧洲小语种市场的产品问题时,反复编造一个不存在的德语分类路径,把询盘意向最强的用户导到404。后来的处理很直接——把那条高频幻觉路径301到最相关的产品集合页,当月就从这条“凭空冒出来”的路径捞回了一批自然会话,随后再补上真正的本地化落地页。这类活儿的抓手,和技术端怎么让AI爬虫抓得到、读得懂是同一套逻辑,只是多盯了一层多语言的命名混乱。
监测节奏:多久查一次、查什么
幻觉链接治理不是一锤子买卖,得有节奏地循环。保哥给客户定的基线是这样:
| 动作 | 频次 | 看什么 |
|---|---|---|
| 翻AI来源的404日志 | 每周 | referrer/UA带AI特征的404路径,按频次排序 |
| GSC覆盖率“未找到”复查 | 每月 | 新增高频死链,判断建页还是301 |
| 核心问题人工抽查 | 每月 | 十几个品类核心问题在各引擎的链接与归属对不对 |
| 品牌归属专项体检 | 每季度 | 原创观点、独家数据有没有被认错出处 |
| 大促/大更新后专项 | 触发式 | URL结构变动后,AI是否还在链旧的、编新的 |
不用一上来就全套铺开,先把每周翻404这一件事做起来,建立基线,其余按站的体量逐步加。
几个常见误解
- “链接404是我站的锅”——不一定。要先分清是你真删了页,还是AI凭空编的。前者是自己的技术债,后者是AI的幻觉,处理方式不同。
- “AI乱编,我干预不了”——能。你干预不了模型怎么生成,但你能决定那条被编出来的URL是返回404还是301到真实页,能决定关于你的真实信息铺得多密。主动权比你以为的大。
- “这只影响流量,不影响品牌”——错。错误归属直接动的是品牌资产和信任,用户看到AI把你的话说成别人的,或把别人的锅甩给你,伤的是长期认知。
- “等模型升级就好了”——别等。幻觉是大模型的结构性特征,只会被压低不会归零。把它当成会长期存在的运营变量来管,才是稳的。
- “用301收编是钻空子,会挨罚”——不会。把不存在的URL重定向到真实相关页,是标准的死链治理动作,Google的重定向指南本来就鼓励用301处理地址变更。你没有操纵排名,只是把撞墙的用户接住,合规又正当。
说到底,幻觉链接是AI搜索时代绕不开的新常态。你左右不了模型怎么生成,但完全可以决定:撞到你门上的那条幻觉URL,是让它404、还是接住它变成一单生意。把监测和301收编做成每周的例行公事,这道原本失分的题,反而能被你答成加分项——比对手早一步蹲下来读日志,就是AI搜索时代不起眼却实在的护城河。
常见问题解答
AI给的链接点进去404,是我网站的问题吗?
先别急着认领。要分两种情况:一种是你确实建过这个页、后来删了或改了路径没做重定向,这是你的技术债;另一种是这个路径你压根没建过,是AI按合理格式凭空编的,这是幻觉链接。判断很简单——去你的CMS或数据库里查这个URL历史上有没有存在过。是自己的债就补重定向、清死链;是AI编的,就按频次决定要不要用301把它收编成真实入口。
怎么发现AI在编造指向我网站的链接?
三条路组合用。一是翻服务器日志,筛出状态码404、且来源或User-Agent带ChatGPT、Perplexity等AI平台特征的请求,把路径拉成清单;二是看Google Search Console的页面报告里“未找到(404)”分组,按频次排序找高频死链;三是拿品类核心问题去各AI引擎手动抽查,看它给你家的链接对不对。日志和GSC适合发现已成规模的幻觉,人工抽查适合逮住刚冒头的新幻觉。
幻觉URL到底该建成真页,还是301重定向?
看两件事:这个URL指向的主题你有没有,以及它被编的频次高不高。指向已有内容只是路径错了,直接301到真实页;指向合理主题但你没这个页且高频,先301兜底再排期建真页;同样情况但低频,301兜底即可不必单独建;路径怪异、无合理语义、只出现一两次的,返回标准404就行,不用管。核心是有真实意向的才值得收编,纯噪声不必理会。
AI把我的内容说成是别人的,怎么纠正?
错误归属没法靠重定向解决,得从信号源头补。第一,把自己是原始出处这件事做得机器可读——原创声明、作者信息、发布时间、结构化数据补齐;第二,用原创数据、独家案例这类难以被张冠李戴的一手资产占住话语权,全网只有你有的数据,AI想引错都难;第三,定期监测品牌被怎么引用,发现系统性错误就向平台反馈。这是个慢功夫,靠的是长期把正确信号铺密。
为什么大模型会编出格式完全正确、却不存在的链接?
因为大模型的本质是预测下一个最可能的词,追求的是“像”不是“真”。URL的格式(域名加路径加连字符英文)在训练数据里出现过无数遍,规律性极强,所以当模型遇到训练里没覆盖、或概念组合很新的问题时,会照着这个格式外推出一个语法完美、实则从未存在的地址。再加上自回归生成会让早期的一个错误token顺着上下文自我强化,一个幻觉开头常常拖出一整段。这是它工作方式的结构性结果,不是偶发故障。
幻觉链接这事会随着模型升级自己消失吗?
不会消失,只会被压低概率。幻觉是大模型按概率生成的结构性特征,模型越大、检索增强越强,出错率能降,但只要它还是在“猜下一个词”,就不可能归零。所以正确的心态是把幻觉链接当成一个会长期存在的运营变量:与其等模型自己修好,不如把自己这侧的地基做硬——实体清晰、URL稳定、真实信息铺密,同时把监测404和301收编做成日常动作。
权威参考资料
- AI Search Has a Citation Problem(哥伦比亚新闻学院Tow Center) —— 用200个问题横评八家AI搜索引擎,实测超六成回答的引用有误,Grok 3有154次把用户导向404,付费版反而错得更自信。
- ChatGPT Is 2x More Likely to Cite 404s than AI Overviews(SE Ranking) —— 抓取十万条ChatGPT提问共约14.5万条URL,统计出1.34%为坏链、其中91%是404,并与Google AI概览、AI模式、自然结果逐一对比。
- AI search engines fail to produce accurate citations in over 60% of tests(Nieman Lab) —— 尼曼新闻实验室对Tow Center研究的综述,点明引用错误是全行业慢性病而非某家偶发。
- Redirects and Google Search(Google Search Central) —— Google官方讲各类重定向的实现与301/302语义,是把高频幻觉URL用301收编到真实页的官方依据。
- Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations(arXiv) —— 从子序列关联角度解释大模型为什么会一本正经地编内容,含URL这类高规律格式为何尤其容易被编造。
- Hallucination (artificial intelligence)(Wikipedia) —— AI幻觉的定义词条,收录了编造引用、虚构法律判例(如Mata诉Avianca案)等典型案例。
本文标题:《AI经常编造不存在的链接:幻觉引用怎么查、怎么把404变成机会》
本文链接:https://zhangwenbao.com/ai-hallucinated-links-fake-citations-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0