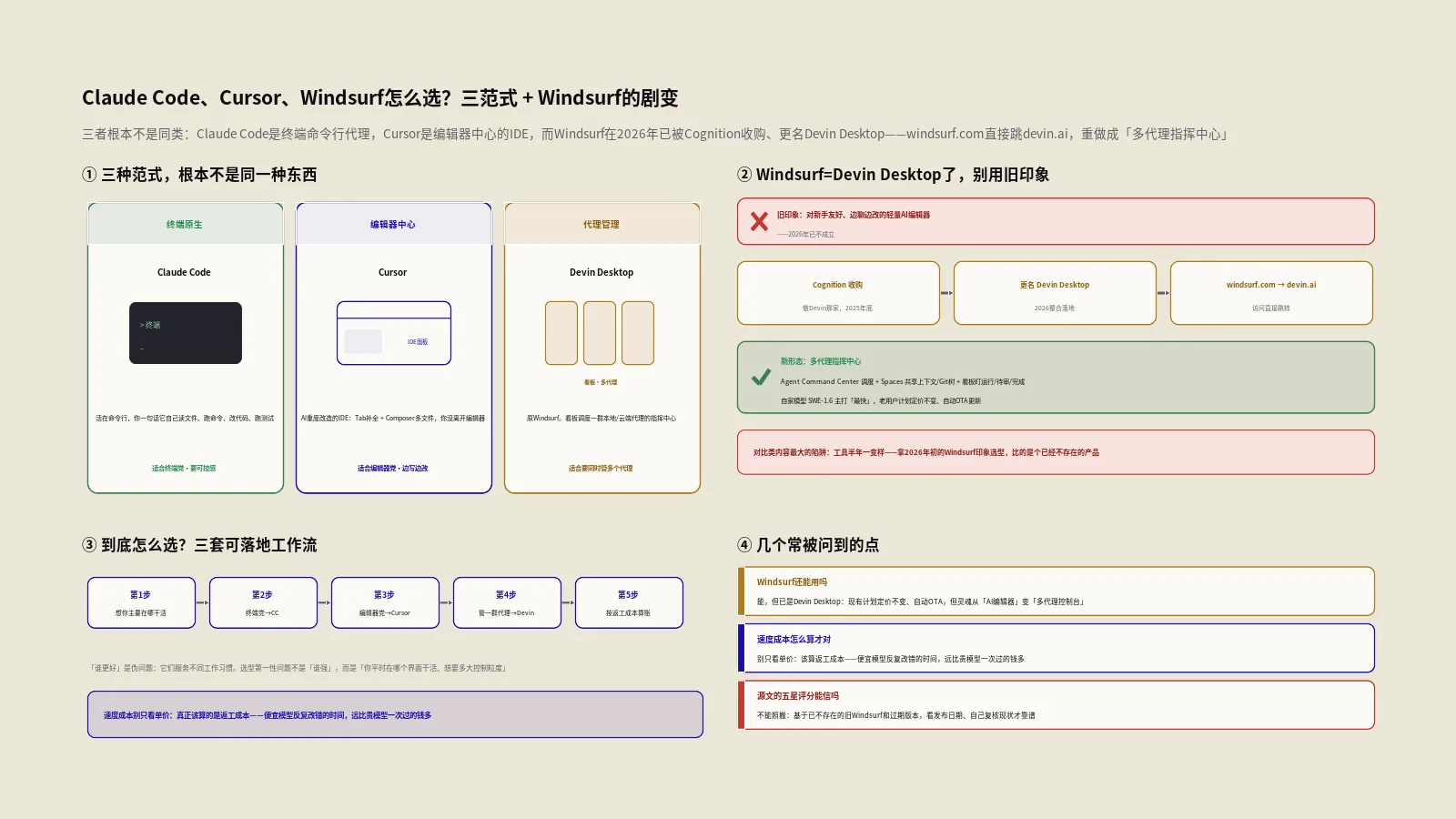
Claude Managed Agents是什么?官方托管智能体的真实用法与避坑
本文目录
- Managed Agents到底解决了什么问题?
- Agent、Environment、Session、Events,这四个概念怎么串?
- 真实的代码长什么样?别信那些虚构的API
- 内置工具到底有哪些?这块二手资料错得最多
- 为什么是事件流加SSE,而不是一问一答?
- 什么时候该用Managed Agents,什么时候自己搭循环?
- 多智能体、结果评估这些进阶能力跟得上吗?
- 限制和计费,有哪些要提前知道的?
- 常见问题解答
- Managed Agents和直接用Messages API有什么区别?
- 用Managed Agents需要装单独的SDK包吗?
- 内置工具到底有哪几个?
- 能跑在我自己的基础设施上吗?
- Managed Agents怎么收费,比直接调模型贵吗?
- 它支持多智能体协作吗?
- 权威参考资料
摘要:Claude Managed Agents是Anthropic官方推出的“托管智能体”——你不用再自己写agent循环、自己搭沙箱、自己实现工具调用,它把这一整套运行容器(harness)打包成几个REST接口,Claude在云端安全沙箱里自主读文件、跑命令、搜网页、调MCP,结果通过SSE流式回传。它围绕Agent、Environment、Session、Events四个概念组织,所有请求带managed-agents-2026-04-01这个beta头,SDK会自动加。这篇讲清它是什么、四个概念怎么串、真实的SDK代码怎么写、内置工具到底有哪些(很多二手教程这块是错的)、什么时候该用它而不是自己拿Agent SDK搭循环,以及它的限制和计费维度。Managed Agents到底解决了什么问题?
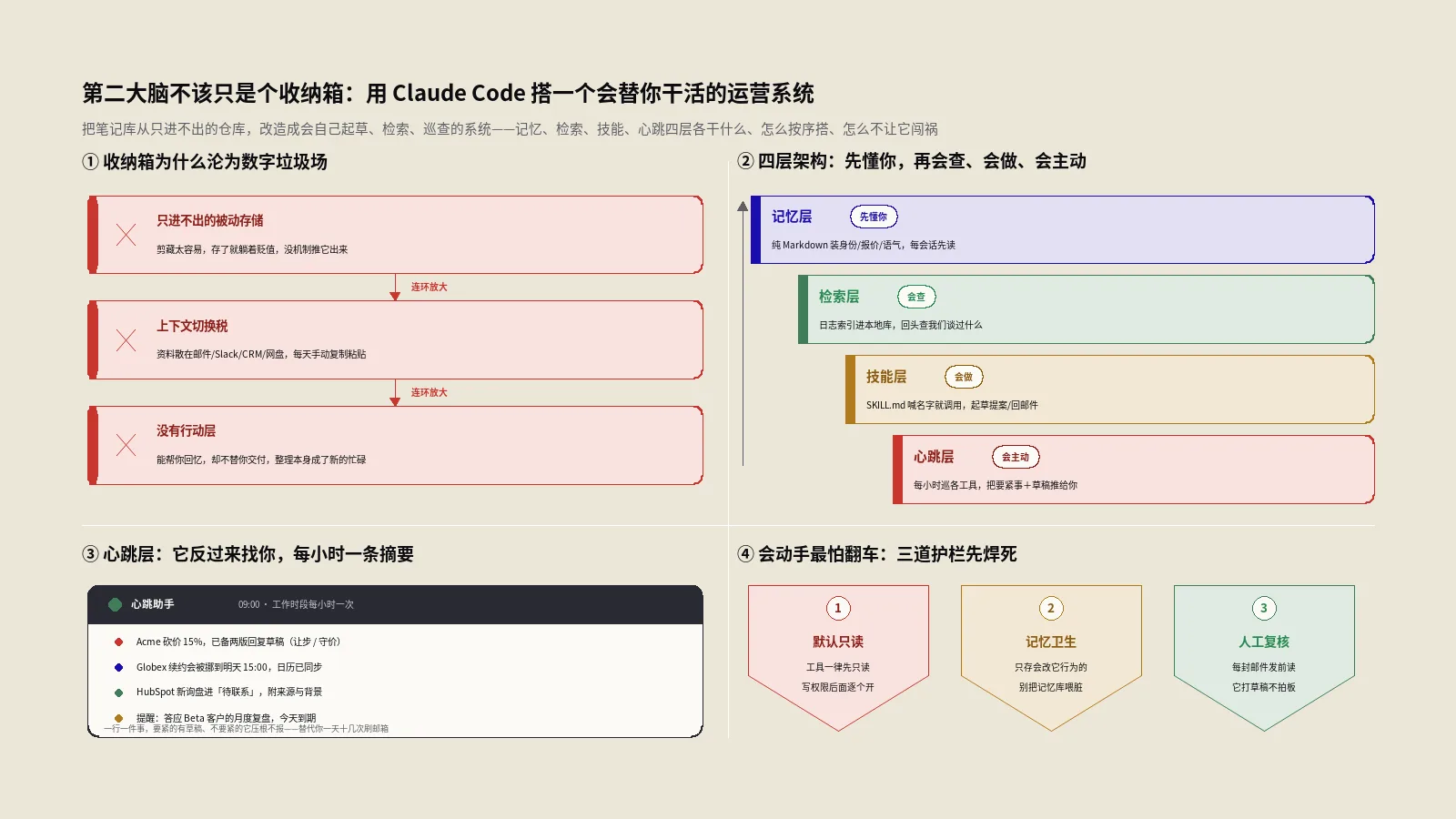
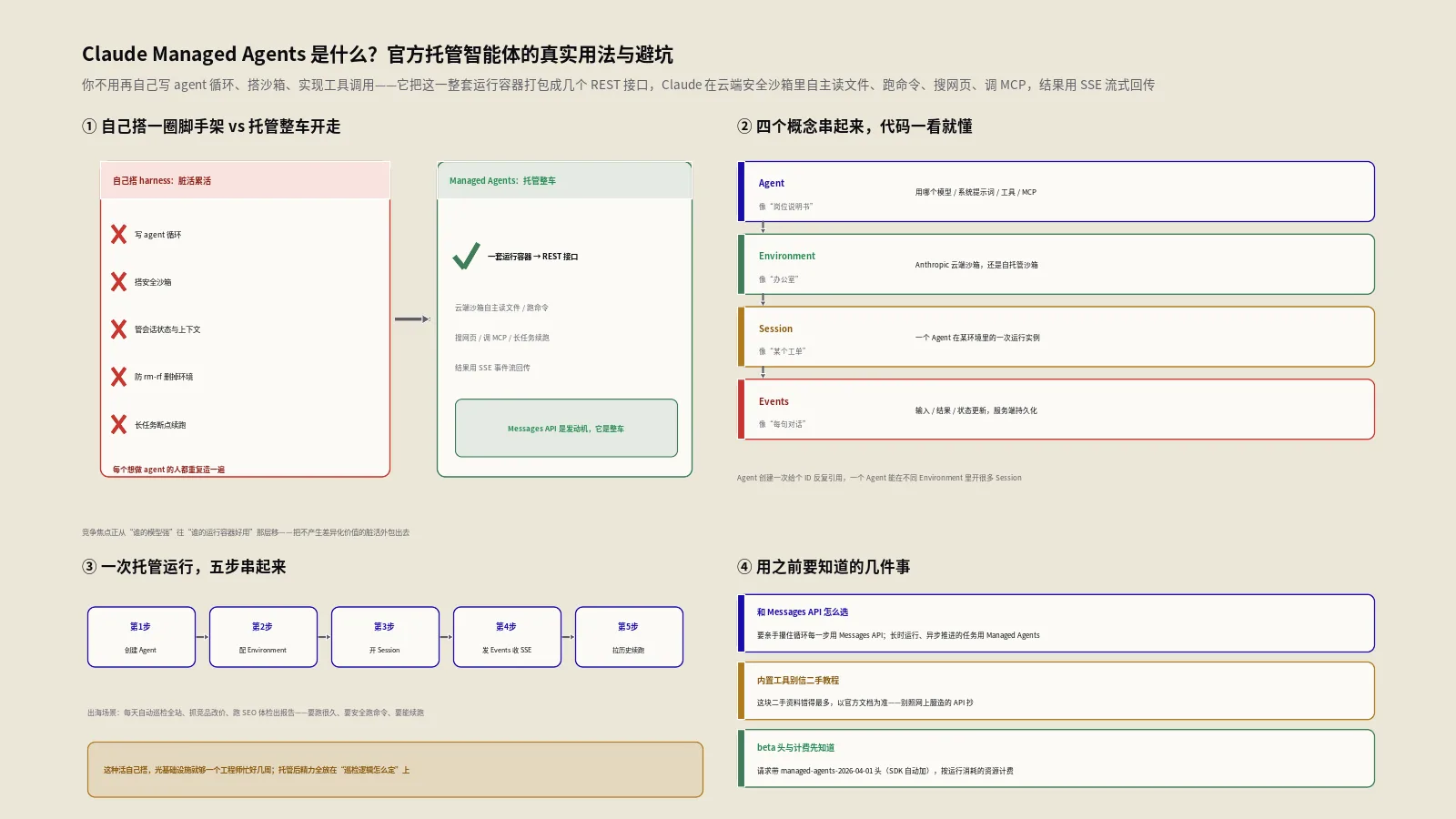
要搞懂Managed Agents,得先承认一个现实:把大模型变成一个能自主干活的agent,难的从来不是调模型,而是调模型外面那一圈“脚手架”。你得写一个循环,让模型说“我要调这个工具”、你执行、把结果塞回去、再让它接着想;你得给它一个能安全跑命令的沙箱,不然它rm -rf一下把你环境删了;你得管会话状态、管上下文压缩、管长任务跑几个小时中间断了怎么续。这些活儿,统称harness(运行容器),每个想做agent的人都得重复造一遍,又琐碎又容易出错。
Managed Agents干的事,就是把这一整圈脚手架托管起来。官方文档Managed Agents概览把它和传统的Messages API摆在一起对比得很清楚:Messages API给你的是“直接对模型提示词”的细粒度控制,适合你想亲手攥住agent循环每一步的场景;而Managed Agents给你的是“一个预先搭好、可配置的agent运行环境”,适合长时间运行、异步推进的任务。一句话——Messages API是发动机,Managed Agents是连发动机带底盘带驾驶舱的整车。
这背后是一个挺重要的行业判断:随着agent变成主流,竞争的焦点正从“谁的模型强”往“谁的运行容器好用”那一层移。自己手搓一个生产级harness的成本越来越高,把它交给平台、自己专注业务逻辑,对大多数团队是更划算的选择。Managed Agents就是Anthropic在这一层给出的官方答案。
举个出海团队会遇到的场景你就有体感了。假设你做跨境独立站,想搭一个“每天自动巡检全站、抓竞品改价、跑一轮SEO体检再出报告”的agent。这活儿的特点是:要跑很久(几十个页面挨个抓、分析)、要安全地跑命令和访问网络(不能在你的生产服务器上裸跑)、还得能中断续跑(半夜跑崩了不能从头来)。如果自己搭,你得搞一台沙箱机器、写一套任务队列、处理断点续传、防着agent把环境搞坏——光这套基础设施就够一个工程师忙好几周。用Managed Agents,这些全是平台现成的,你把精力放在“巡检逻辑怎么定、报告怎么出”这些真正产生价值的业务上就行。这就是“托管”二字对一个小团队的实际意义:把不产生差异化价值的脏活累活外包出去。
Agent、Environment、Session、Events,这四个概念怎么串?
Managed Agents整个体系就建立在四个核心概念上,把它们的关系理顺,后面的代码你看一眼就懂:
- Agent(智能体):定义“这是个什么样的助手”——用哪个模型、系统提示词是什么、能用哪些工具、挂哪些MCP服务和技能。它创建一次、给个ID,之后被反复引用。
- Environment(环境):定义“它在哪儿跑”——是用Anthropic托管的云端沙箱,还是跑在你自己基础设施上的自托管沙箱。这一层管网络策略、沙箱配置。
- Session(会话):一个Agent在某个Environment里的具体一次运行实例,干一件具体的活、产出具体的结果。同一个Agent可以开很多Session。
- Events(事件):你的应用和agent之间来回传的消息——你发的用户输入、工具结果、它回的文本、状态更新,全是事件。事件历史在服务端持久化,随时能拉全。
用一个比方:Agent是“岗位说明书”,Environment是“办公室”,Session是“这位员工今天上班处理的某个具体工单”,Events是“你和他之间的每一句对话和每一次交接”。说明书写一次,办公室配一次,工单可以开无数个,每个工单里的往来都被完整记录。理清这四层,你会发现它跟自己拿Agent SDK从零搭循环的心智模型很不一样——那条路是你亲手写循环,可以参考Claude Agent SDK实战那篇;而Managed Agents是把循环也托管了,你只管发事件、收事件。
真实的代码长什么样?别信那些虚构的API
这一节要格外认真讲,因为网上不少介绍Managed Agents的二手文章,API是凭空编的——什么client.managed_agents.create(tools=["file_system","shell"])之类,看着挺顺,实际跑不通。这里按官方快速上手文档把真实流程过一遍,全部可复现。
先装SDK。注意,不需要装什么单独的agents包,就是标准的Anthropic SDK:
pip install anthropic第一步,创建一个Agent。模型用当前的claude-opus-4-8,工具用内置工具集agent_toolset_20260401:
from anthropic import Anthropic
client = Anthropic()
agent = client.beta.agents.create(
name="Coding Assistant",
model="claude-opus-4-8",
system="You are a helpful coding assistant.",
tools=[
{"type": "agent_toolset_20260401"},
],
)
print(agent.id, agent.version)第二步,创建一个Environment,告诉它在云沙箱里跑、网络放开:
environment = client.beta.environments.create(
name="quickstart-env",
config={
"type": "cloud",
"networking": {"type": "unrestricted"},
},
)
print(environment.id)第三步,引用前两步的ID开一个Session:
session = client.beta.sessions.create(
agent=agent.id,
environment_id=environment.id,
title="Quickstart session",
)
print(session.id)第四步,打开事件流,发一条用户消息,然后边收边处理事件:
with client.beta.sessions.events.stream(session.id) as stream:
client.beta.sessions.events.send(
session.id,
events=[{
"type": "user.message",
"content": [{"type": "text", "text": "写个脚本算斐波那契前20项并存进文件"}],
}],
)
for event in stream:
match event.type:
case "agent.message":
for block in event.content:
print(block.text, end="")
case "agent.tool_use":
print(f"\n[调用工具: {event.name}]")
case "session.status_idle":
print("\n完成。")
break看清楚这套真实结构:方法挂在client.beta.agents、client.beta.environments、client.beta.sessions下面,是分层的;交互是事件驱动加SSE流式的,不是一次请求一次响应。而那些虚构的managed_agents.create把所有东西揉成一个扁平调用,恰恰错在没有体现Agent、Environment、Session的分层。判断一篇Managed Agents教程靠不靠谱,看它有没有把这三层分开就行。所有请求都要带managed-agents-2026-04-01这个beta头,好在SDK会自动加,你不用手写。
内置工具到底有哪些?这块二手资料错得最多
源头一错,下游全错,内置工具就是重灾区。很多文章把Managed Agents的内置工具写成“文件系统、Shell、Playwright浏览器、代码执行、KV记忆存储”这么一长串,听着很全,但跟官方对不上。
官方文档明确的内置工具集(也就是agent_toolset_20260401这个类型一次性启用的那套)其实是这几样:
- Bash:在沙箱里跑shell命令。
- 文件操作:在沙箱里读、写、编辑、glob、grep文件。
- 网页搜索与抓取:搜索网络、抓URL内容。
- MCP服务:连接外部工具提供方。
看出区别没有?官方是Bash加文件操作加网页搜索抓取加MCP这四类,而不是二手资料里那种“浏览器自动化加独立代码执行器加KV存储”的拼盘。代码执行本身是通过Bash在沙箱里跑的,不是一个单列的“code execution工具”;所谓“记忆存储”也不是一个内置KV工具——Managed Agents的状态性是靠Session级别的持久化沙箱文件系统加服务端事件历史实现的,这是架构层面的能力,不是某个工具。把这两件事分清楚很重要,否则你会去找一个根本不存在的“memory工具”而抓狂。
至于连外部能力,Managed Agents走的是标准的远程MCP服务(支持MCP的streamable HTTP传输),私有MCP可以通过MCP隧道接进来。这跟你在Claude Code里挂MCP是同一套思路,怎么挑靠谱的MCP服务、避开虚构包名,保哥在MCP服务器怎么选那篇里专门梳理过,那套辨别真假的方法在这儿照样管用。
为什么是事件流加SSE,而不是一问一答?
很多人第一次看Managed Agents的代码,会卡在“为什么要先开流、再发消息”这个顺序上——直觉上不该是“发请求、等响应”吗?这个设计不是别扭,恰恰是它面向长任务的必然结果,值得专门说说。
传统的一问一答模式,前提是“请求很快就有完整响应”。但一个agent任务可能要跑几十分钟、调上百次工具,你不可能开一个HTTP请求干等几十分钟还指望它不超时。所以Managed Agents用的是服务端推送事件(SSE):你打开一条长连接的事件流,agent每完成一小步——说了句话、调了个工具、拿到工具结果、状态变了——就往流里推一个事件,你这边实时收、实时处理。它不是“一个大响应”,而是一连串小事件。
这套事件驱动还带来两个关键好处。其一,可中途干预:agent干到一半,你发现方向偏了,可以再发一个用户事件去纠偏、甚至打断它换个方向,不用等它把错的做完。其二,可断点续跑:因为事件历史和沙箱状态都在服务端持久化,会话能从暂停里干净恢复——网络断了、程序重启了,重新连上流就能接着来,长任务不会因为一次抖动从头再来。这两点是自己手搓harness时最难做对、最容易出bug的地方,也正是托管最值钱的部分。理解了“事件流是为长任务和可恢复性服务的”,你就不会再觉得那个先开流的顺序别扭了。
什么时候该用Managed Agents,什么时候自己搭循环?
这是最该想清楚的决策,本质是一道“买现成还是自己造”的题。两条路没有谁绝对更好,看你的场景。
官方给的“适合用Managed Agents”的信号很实在:
- 长时间运行:任务要跑几分钟到几小时、中间几十上百次工具调用。自己管这种长任务的状态和续跑非常痛苦,托管帮你扛了。
- 需要云端基础设施:要一个预装了包、带网络访问的安全沙箱,又不想自己运维。
- 要自托管执行:出于合规或数据驻留要求,沙箱得跑在你自己控制的基础设施上——注意,Managed Agents是支持自托管沙箱的,这点和某些二手资料说的“只能用它的云、不能上自己的环境”正好相反。
- 最小化基础设施投入:不想自己写agent循环、沙箱、工具执行层。
- 有状态会话:需要跨多次交互保持文件系统和对话历史。
反过来,如果你就是要对agent循环的每一步攥死控制——自定义每一轮怎么决策、工具怎么挑、上下文怎么裁,那自己拿Agent SDK或Messages API搭循环更合适,灵活度换来的是你得自己扛复杂度。想体会“亲手写一个agent循环”是什么感觉,保哥在手写你自己的Claude Code那篇里从零撸过一遍,跑通之后你对“托管到底替你省了多少活”会有非常具体的体感。
一个简单的判断法:把agent当“产品功能”要稳定上线、不想碰底层的,用Managed Agents;把agent当“研究对象”要折腾每个细节的,自己搭。多数业务团队属于前者,多数做agent框架研究的属于后者。
多智能体、结果评估这些进阶能力跟得上吗?
Managed Agents不只是单个agent干活,它的进阶能力也在快速补齐,目前都在公测范围内:
多智能体(Multiagent)会话:一个协调者agent可以把任务分派给其他agent、再收集它们的结果,事件流里有专门的线程事件来反映这种协作。这跟Claude Code里的Agent团队是相通的思路——多个agent并行、互相交接,保哥在Claude Code多Agent协作那篇里讲过并行协作的价值和坑,理念在Managed Agents这边一样成立。
结果(Outcomes)评估:你可以给agent定义一个要达成的“结果”,让它朝着这个目标干,事件流里有对应的评估事件来反映进度。这对“我要它把事办成、而不只是把话说完”的场景很关键。
记忆(Memory):跨会话的记忆能力也在公测。配合前面说的持久化沙箱,agent能在更长的时间跨度上保持连续性。
这三样——多智能体、结果评估、记忆——都用同一个managed-agents-2026-04-01beta头,不用额外申请。另外还有MCP隧道和“做梦”(dreaming,一种后台自主探索机制)属于更受限的研究预览,要单独申请才能开。
限制和计费,有哪些要提前知道的?
上生产之前,这几条边界得心里有数,保哥按官方参考文档给你交个底,不编数字。
速率限制:按组织计,创建类接口(建agent、session、environment等)每分钟300次请求,读取类接口(获取、列举、流式)每分钟600次请求。此外还叠加组织级的消费上限和按等级的速率限制。注意,官方给的就是这两个每分钟请求数,那些“单次运行最多4小时、并发只能10个”之类的具体数字,在官方文档里我没找到出处,多半是二手资料脑补的,别当真。
计费维度:这是和直接调Messages API最大的不同。Managed Agents除了模型token本身的费用,还多了一层托管基础设施的成本——沙箱在云端跑起来、长时间持有状态,这部分运行时是要算钱的。具体价目以官方定价页为准,但你心里要有个数:它不是免费的便利,省下的运维人力换成了平台账单,规划预算时把这层算进去。
数据保留:Managed Agents天生是有状态的——会话长时间运行、能从暂停干净恢复、对话历史和沙箱状态都存在服务端。正因如此,它目前不在零数据保留(ZDR)和HIPAA业务伙伴协议(BAA)的覆盖范围内。好在控制权在你手上:会话可以删、上传的文件可以单独删。对数据合规敏感的业务,这条要重点评估。
还在beta:整套东西挂着beta标签,行为可能在版本间微调。所有API账户默认就有访问权限,但别把还会变的接口当成一成不变的地基,留好适配的余地。
常见问题解答
Managed Agents和直接用Messages API有什么区别?
Messages API给你对agent循环的细粒度控制,适合想亲手攥住每一步的场景,但循环、沙箱、工具执行都得自己写。Managed Agents把这整套运行容器托管了,你只管发事件收事件,适合长时间运行、异步推进的生产任务。一个是发动机,一个是整车。
用Managed Agents需要装单独的SDK包吗?
不用。就是标准的Anthropic SDK,Python直接pip install anthropic。方法挂在client.beta.agents、client.beta.environments、client.beta.sessions下面。所有请求要带managed-agents-2026-04-01这个beta头,SDK会自动加,不用手写。
内置工具到底有哪几个?
官方的内置工具集(agent_toolset_20260401一次启用的那套)是四类:Bash、文件操作(读写编辑glob grep)、网页搜索与抓取、MCP服务。所谓独立的“代码执行器”其实是通过Bash在沙箱里跑,所谓“KV记忆工具”并不存在,状态性靠持久化沙箱和服务端事件历史实现。
能跑在我自己的基础设施上吗?
能。Managed Agents支持自托管沙箱,可以出于合规或数据驻留要求把沙箱跑在你自己控制的环境里。某些二手资料说的“只能用它的云、不能上自己的环境”是错的,自托管是官方明确支持的一种Environment配置。
Managed Agents怎么收费,比直接调模型贵吗?
除了模型token费用,它多一层托管基础设施成本——沙箱在云端运行、长时间持有状态这部分运行时要算钱。具体价目看官方定价页。本质是用平台账单换掉你自己的运维人力,做长任务时省心,但规划预算要把这层算进去。
它支持多智能体协作吗?
支持,多智能体会话在公测中。一个协调者agent能把任务分派给其他agent再收集结果,事件流里有专门的线程事件反映协作。和它一起公测的还有结果评估和跨会话记忆,都用同一个beta头,不用额外申请。
本文标题:《Claude Managed Agents是什么?官方托管智能体的真实用法与避坑》
本文链接:https://zhangwenbao.com/claude-managed-agents.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0