算独立站LTV老是算错?Cohort留存还原ROAS的5步财务模型
本文目录
摘要:广告投了一年ROAS(广告花费回报率)3.5、年底盘账净利是负的——几乎每家做了三年以上的出海独立站都栽过这一跤。原因只有一个:LTV(用户终身价值)算法用的是"首月订单 × 一个拍脑袋的倍数",根本没还原成Cohort(按入站月份分组)的真实复购曲线,结果广告渠道之间的真假ROAS一锅炖。这篇拆5步财务模型,附一家宠物用品独立站18个月的真实推演。
先把术语挡门口讲清楚、入门的朋友不被砸晕。LTV是Customer Lifetime Value的缩写、中文常译"用户终身价值"——一个客户从第一次下单到最后一次下单为止、累计给店里贡献了多少钱。ROAS是Return on Ad Spend、广告花费回报率、说白了就是"我花1块广告费换回了几块销售额"。Cohort是"同期群"、就是把同一个月(或同一周)第一次下单的客户分成一组、跟踪这一组人后面12个月、24个月的复购情况。三个词背后的事其实是一件——把独立站的客户从"一次性下单数据"还原成"长期价值曲线"。
这篇文章想帮你想清楚三件事:为什么ROAS看着好看但年底净利还是负?LTV算法在哪一步最容易跑偏?怎么把"真实LTV ROAS"反推回每个广告渠道的目标CPA(单次获客成本)?读到第三节算法时如果数学符号有点吓人、可以跳到第六节复盘段,那一段最像故事。
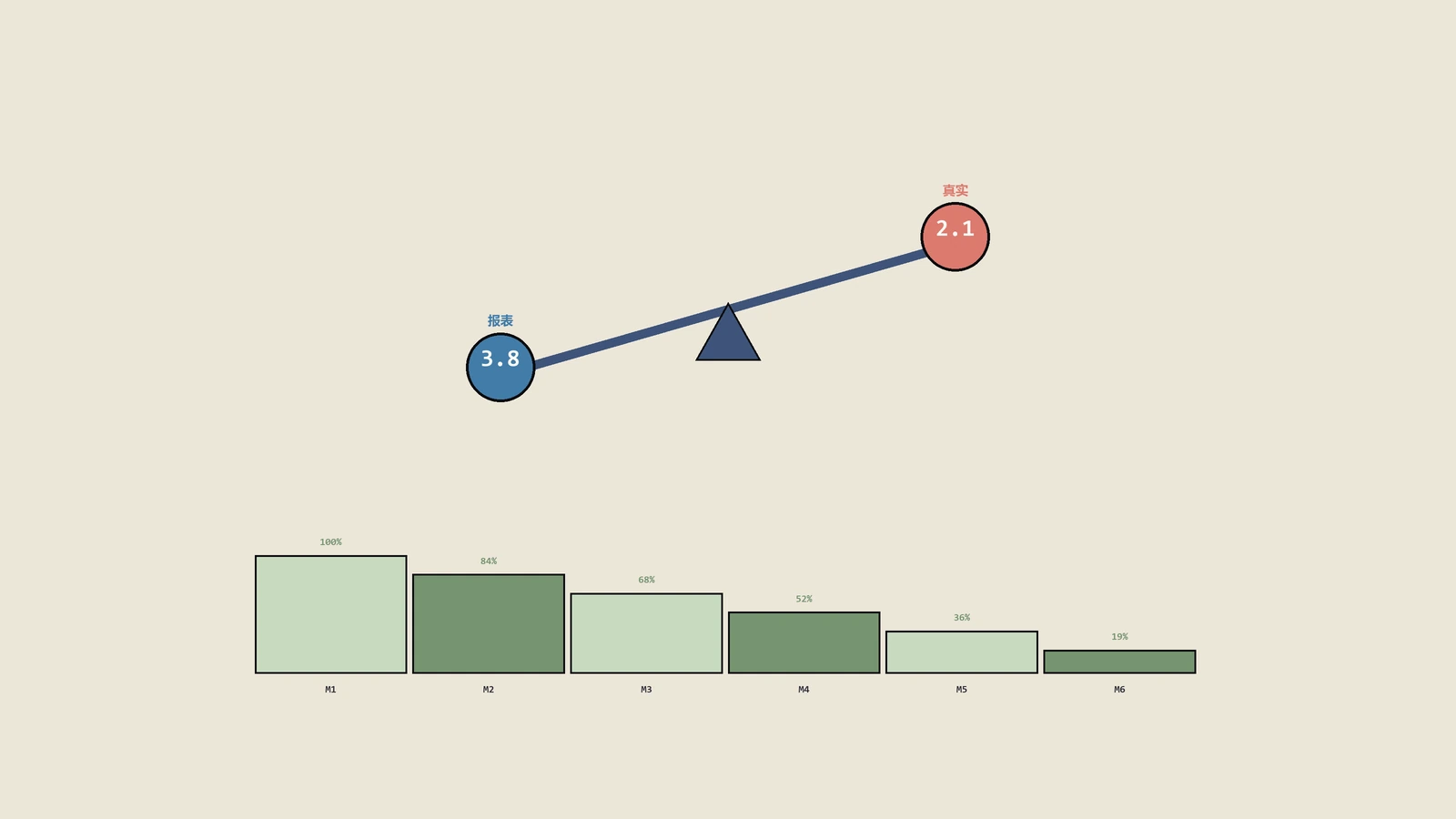
2024年春天保哥碰到一家做宠物用品的出海独立站、月GMV已经跑到60万美元、Meta广告月花费12万美元、报表上的ROAS 3.8看起来很漂亮。创始人开会时反复说一句话——"我们Meta ROAS 3.8已经超过行业基准、为什么银行账户余额年底反而少了8万美元?" 那一刻整个会议室没人接话、因为大家都知道ROAS报表只是冰山一角、问题埋得更深。这家店后来花了三个月把LTV算法从头建起来、发现Meta那批客户的12个月真实LTV ROAS其实只有2.1、跟报表上的3.8差了将近一半。
这不是这家店一个人的问题、是所有靠首单ROAS看广告效果的独立站都会撞的墙。底层原因就一个——ROAS用的是"广告期内发生的订单"、LTV算的是"广告带来的客户未来一辈子"。两个数字对应的是完全不同的时间窗口、混在一起看就是在拿苹果和橘子比重。
更扎心的是、这种错误在广告投得越凶的店里反而越隐蔽。月广告花1万美元的小店亏5000一眼就看到、马上停手;月花12万美元的中型店亏8万会被92万营收的体量盖住——账面GMV还在涨、净利在阴跌、等到年终算P&L表才发现"原来一直在烧钱跑步"。规模越大、首单ROAS偏差导致的真实净利错觉越严重。这是过去三年保哥手上四五家不同独立站撞过的同一堵墙、几乎没有例外。
LTV算错的几个典型姿势是哪些?
看过不下二十家独立站的LTV算法、能犯的错基本逃不出五种。挑出来说一下、看看自己有没有中招。
第一种是"首月订单 × 固定倍数"。比如有的店看了别人公众号文章说"LTV是首月的3倍"、就直接拿首月订单价值乘3当作LTV——这种算法相当于"看了别人的体重再来估自己的体重、连身高都不参考"。日耗品和耐用品的复购周期天差地别、用同一个倍数八成偏。某家做家居用品的客户曾经把LTV算成首单的3倍、按这个数算ROAS投了半年广告、年底发现真实LTV其实只有首单的1.2倍——亏的钱够请整个团队吃一年米其林了。
第二种是"按整体客户平均算、不分Cohort"。把所有时期入站的客户混在一起算平均LTV——结果新客户(刚来1-3个月)和老客户(已经来了18个月)的数据混在一个盆里,新店看着LTV很高(其实只是老客户拉高均值)、老店看着LTV很低(其实只是新客户拖低均值)。混算LTV等于把一桶水的温度和一桶冰水的温度加在一起取均值、得出来"两桶都是温水"——荒谬但常见。
第三种是"算GMV不算毛利"。LTV用销售额算出来一个漂亮的大数字、但商品成本、物流费、退货损失、客服分摊全没扣——所谓的LTV 350美元里、毛利可能只剩90美元。算ROAS时如果用毛利对应的LTV才有真正的财务意义、用GMV对应的LTV等于在自我安慰。
第四种是"归因到末次接触"。客户的首单订单可能是从Google自然搜索来、第二单是Meta再营销带来——很多团队把第二单的销售额归到Meta头上、把Google自然搜索的"前期种草贡献"完全抹掉。归因模型用末次接触会系统性低估前端流量(自然搜索、品牌广告、KOL种草)的真实LTV贡献、高估末端再营销渠道。这种偏差长期累积、广告预算分配就跑偏了。
第五种最隐蔽——"样本量不够强行预测"。新店开张4个月就开始建LTV模型、用4个月数据预测24个月LTV——这种预测的置信区间能宽到上下浮动40%、决策时跟掷骰子差不多。LTV模型需要至少9-12个月数据才能稳定、6个月以下做出来的预测自己心里要打折扣。这一点在创业团队特别难做到、CEO总觉得"早点算出LTV早点优化广告"、但样本量不够时算出来的数字反而误导决策、还不如不算。一家做户外装备的独立站2023年开张5个月就拍板"按LTV模型放大Meta预算"、用错误高估的LTV撑了6个月广告、烧掉40多万美元才回头校正——血泪教训。
把这五种典型错误对照检查一遍、能筛掉80% 的常见偏差。剩下20% 是更复杂的进阶问题(多触点归因、跨设备ID拼接、跨平台数据冲突等),那一层留给数据团队慢慢搭。先把基础的五个坑避开、LTV模型已经能服役了。
Cohort留存曲线为什么是LTV的地基?
Cohort这套方法SaaS行业用了十多年、DTC圈反而是2018年之后才慢慢普及。核心逻辑特别简单——把"2023年1月第一次下单的客户"归成一组叫"2023-01 Cohort",跟踪这一组人后面每一个月还回来下单的有多少。月份维度一拉、就能看到这群人"复购衰减曲线"——第二个月还有X% 回来、第六个月还有Y%、第十二个月还有Z%。这条曲线是LTV计算的地基、没它一切都是猜。Klaviyo官方博客那篇Cohort分析完整指南里给了从邮件营销视角看Cohort留存的具体步骤、入门读这一篇比读学术论文友好。
为什么不直接拿历史平均订单数 × 客单价?因为客户的复购行为是"前密后疏"的指数衰减形状——刚下单完那1-3个月是复购高峰、之后慢慢衰减、到第12-18个月稳定在一个低水位。算平均会把"前密"那一段拉高均值、得出过于乐观的LTV;算Cohort留存曲线 + 积分(其实就是把曲线下面积加起来)才能拿到真实的12个月或24个月累计价值。
| 品类 | 典型复购周期 | 12月LTV / 首单倍数 | 留存曲线形状特征 |
|---|---|---|---|
| 咖啡 / 宠物粮 / 护肤品(日耗品) | 30-45天 | 2.5-4倍 | 第2-3月有明显复购峰、之后温和衰减 |
| 家居 / 家电 / 3C(耐用品) | 180-365天 | 1.1-1.5倍 | 前6月几乎平、6-12月有零星补购 |
| 服装 / 配饰(季节性) | 90-120天 | 1.8-2.6倍 | 季节切换月有峰、其他月谷 |
| 订阅模式(Box / SaaS / 剃须刀) | 固定周期 | 5-8倍 | 前3月陡降、之后稳定(churn后稳) |
| 母婴 / 营养补剂 | 30-90天 | 3-5倍 | 类似日耗、第4-6月有第二波峰 |
这张表只是一个起点、不是每一家独立站都能套——同样是宠物粮、卖给"刚养狗的新手"和卖给"养了8年金毛的老司机"的复购曲线差别能有30%。所以拿到自己店的真实数据画自己的曲线、永远比抄表强。把Shopify后台导出过去24个月所有订单CSV、用Excel透视表按"客户首单月份"行 + "订单月份差"列就能画出一张Cohort矩阵——一上午能搞定的活、能省一年学费。
5步财务模型具体怎么算?
把保哥这两年陪几家独立站建LTV算法的实操拆出来、5步走通能拿到一个可以代入广告投放出价的"真实LTV ROAS"。每一步都不是数学难关、关键是把数据流走顺。
第1步:按月份切Cohort、归并客户的"出生渠道"
从Shopify / WooCommerce / 自建站 后台导出过去18-24个月的所有订单CSV、字段至少要有:order_id、customer_id、order_date、order_value、cost_of_goods、shipping_cost、refund_flag、首单来源渠道(utm_source / 推荐来源)。Shopify官方那篇LTV入门指南里把后台导出步骤写得很清楚、新手照着做能省不少摸索时间。服务器端跟踪GA 4+BigQuery那套系统能帮你把首单来源渠道拉得比较干净、如果还没上服务器端跟踪、Shopify自带Sales by referrer凑合用也能跑起来、就是粒度粗一些。
归并的核心是——每个客户后续所有订单的销售额、都归到首单那个渠道。客户首单是Meta、第二单是Google再营销、第三单是Email、全部算Meta的LTV贡献。这一步反直觉、但符合财务现实——是Meta把这个客户"买回来"的、后面渠道只是在维护。
第2步:拉留存曲线、做Cohort矩阵
把每个月入站的客户分别画一条留存曲线——X轴是"距离首单的月数"、Y轴是"该月发生复购的客户占比"。Excel透视表能凑合做、想做得更细的话用 Python lifetimes库(专做LTV建模的开源包)、三五行代码画出来。
留存曲线一般有两种典型形状:陡降型(前3个月急速衰减、后面拖长尾)和缓降型(前6个月平稳、之后温和衰减)。陡降型适合用指数衰减拟合(y = a × e^(-bt) + c)、缓降型适合用Pareto/NBD模型(Pareto分布 + Negative Binomial Distribution、专门给非订阅业务的复购建模)。小店(月单 ≤500)用三参数指数衰减就够、中大店上Pareto/NBD。
第3步:积分得到累计LTV、扣掉成本拿到LTV毛利
把Cohort曲线积分(说人话就是把每个月的复购订单价值加起来)、拿到12个月或24个月累计GMV。然后逐项扣减:商品成本(一般30%-50%)、物流费(一般8%-15%、跨境更高)、退货退款(一般3%-10%)、客服 / 仓储 / 平台费分摊(一般5%-12%)——剩下来就是LTV毛利。这一步常被忽略,但它才是有财务意义的数字。
举个例子。某独立站咖啡品牌12个月累计GMV是320美元、商品成本40%(128美元)、物流12%(38美元)、退货4%(13美元)、其他分摊8%(26美元)——LTV毛利 = 320 - 128 - 38 - 13 - 26 = 115美元。这115美元才是广告费可以"花进去"换回来的钱、320是销售额、不是利润、混用就是给自己挖坑。
第4步:算"真实LTV ROAS"、不是"首单ROAS"
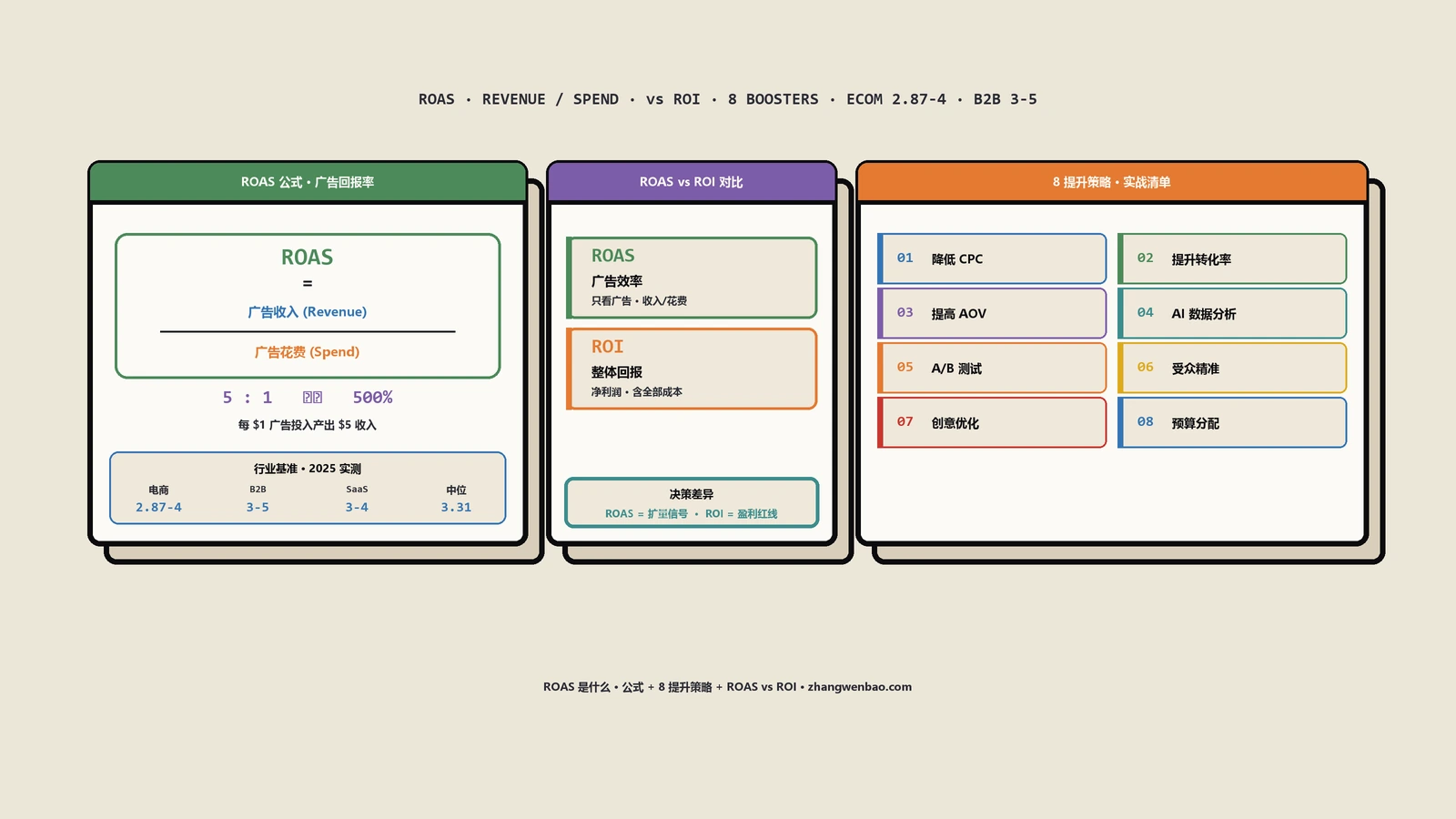
把每个渠道的广告花费分摊到对应Cohort、用LTV毛利对应广告花费,得出真实LTV ROAS。公式简单——真实LTV ROAS = Cohort LTV毛利 / Cohort对应广告花费。
这里有个反直觉点——首单ROAS高的渠道未必真LTV ROAS高。比如再营销渠道(Meta Custom Audience)首单ROAS经常能跑到6-8、但因为再营销抓的本来就是"高购买意向"的老访客、这群人无论投不投广告大概率也会来、加上他们后续复购率反而不如冷启广告抓来的新客、真LTV ROAS经常只有2.5-3.5。冷启广告(Meta Cold Audience)首单ROAS 1.5-2、看着难看、但真LTV ROAS能跑到3-4——因为它真正"创造"了新客户、不是在抢已经要来的人。
这个反差 iOS 14归因重塑那篇里讨论过、但放在LTV模型里看更刺眼。再营销看着ROAS漂亮、其实在"偷渡"自然流量本来就要发生的订单、把别的渠道的成果算到自己头上——好比一个学生数学考98分、其实有30分是抄同桌的、不能因为分数高就奖励他。
这一步对预算分配的指导意义巨大。算完真实LTV ROAS之后会发现一个常见现象——投入产出比最高的"明星渠道"和最低的"亏损渠道"经常和团队过去一年的直觉相反。Meta再营销以前被当作"金饭碗渠道"、其实只是个"虚胖渠道";TikTok冷启被当作"还在交学费"、其实是"在养未来的金主"。这种重新排序、对很多独立站团队是认知冲击、第一次看到数据时往往要花两三周才接受得了。
第5步:Bootstrap置信区间、识别假胜利
LTV算出来一个具体数字(比如115美元)看着挺确定的、其实背后是从有限样本里推断出来的。需要用Bootstrap(重采样统计方法、把样本随机抽N次、看每次抽出来的LTV分布)算个95% 置信区间——LTV 115美元 ± 25美元?还是 ± 5美元?区间越窄越可信。
区间宽的渠道往往是"伪LTV ROAS高"——样本量小、波动大、平均看上去4、其实可能是2.5也可能是5.5。区间窄的渠道(样本量大、复购模式稳定)才是真稳定。Python lifetimes库里BetaGeoFitter一行代码能出置信区间、是这一步的友好工具。
这一步在很多独立站团队被跳过、因为统计概念稍微进阶一点。但跳过它的代价就是——用样本量太小的ROAS数据做决策、追错渠道。一个广告渠道月花5000美元跑出"LTV ROAS 5"看着诱人、但样本量只有60个客户、95% 置信区间可能是2.8-7.2——意思是真ROAS可能其实只有2.8、而你按5在加预算、半年后才发现亏了。样本量 ≥200客户的渠道才适合做硬性出价决策、低于200的渠道结论自己心里要打七折。这一条规矩比LTV算法本身还重要。
5步走完拿到的"真实LTV ROAS"代回到广告平台的目标CPA(单次获客成本)设置就完成闭环。比如某渠道12个月LTV毛利180美元、目标真实LTV ROAS设3.0反推回目标CPA 60美元。Meta那边设进Cost Cap、Google那边设进Target CPA、TikTok那边设进Bid Cap、让算法自己跑、不要手动day-trading出价。一般14-28天能稳定收敛——这种"机器学习驱动"的玩法比人工调参靠谱得多、关键是给它正确的LTV输入信号、不是输错指挥它走偏。
LTV模型对独立站SEO投放优先级有什么启发?
这一节是私货——市场上谈LTV的文章95% 都聚焦在广告投放优化、几乎没人讨论LTV算法对SEO投入优先级的反向启发。但保哥做SEO二十多年看到的真实数据是——自然流量来源的客户、12-24个月LTV通常显著高于付费渠道。
具体差距是多少?同一个客户基数下、行业中位差大概是20%-40%——意思是自然流量客户的LTV比付费客户高20%-40%。原因不复杂:自然流量是"主动搜索来的"、需求明确、品牌认知已经建立;付费流量很多是"被广告打中的"、需求被人为激发、品牌忠诚度天然弱一些。
这个差距对SEO投入优先级意味着什么?传统财务模型只看"获客成本"——SEO一篇好内容花3000美元、能带来50个客户、获客成本60美元;Meta广告花3000美元能带80个客户、获客成本37.5美元。看起来Meta完胜。但代入LTV毛利反推:SEO客户LTV毛利150美元 × 50 = 7500美元、Meta客户LTV毛利105美元 × 80 = 8400美元——差距骤然缩小到12%、而SEO还有持续半年到一年的长尾流量增量没算进去。把长尾算进去SEO反超是常态。
一家做咖啡订阅的客户后来算明白这个账之后、把广告预算的25% 转去做 站内信任建设和长尾内容、18个月之后自然流量客户占比从18% 涨到41%、整体LTV毛利率从32% 涨到41%。这是LTV模型在背后撑腰才敢做的决策——不算LTV单看ROAS、SEO永远是"慢"和"贵"。
反过来说、如果一家独立站LTV数据显示"付费渠道客户LTV几乎等于自然流量"、那可能是它的内容/品牌建设根本没差异化——值得反思的不是SEO不行、是它的SEO没在做"差异化阵地"、只是在做"关键词搬运"。SEO数据怎么报给商业决策层那个话题里聊过、LTV是SEO投入争取预算的最硬筹码、比关键词排名说服力强10倍。
第5步完成后还有一个细节常被忽略——LTV模型的dashboard化与团队对齐。算好的真实LTV ROAS如果只躺在数据分析师的Jupyter Notebook里、没有变成CMO和CFO每周开会能看到的可视化报表、这套模型对实际决策的影响几乎为零。CRM厂商Optimove整理的CLV学习中心里把"LTV模型怎么和CRM自动化串联做客户分层"讲得比较系统、对做品牌私域的团队特别有用。最佳实践是把LTV模型输出做成Looker Studio或Power BI dashboard、每周自动刷新、按渠道展示首单ROAS vs真实LTV ROAS的对比柱状图、加上95% 置信区间的误差棒。让所有人一眼看到"哪个渠道在欺骗你、哪个渠道在真贡献"。这一步看似工程化、但它决定了LTV模型能不能渗透到团队日常决策里——技术只是底子、组织对齐才是上层建筑。
独立站LTV算法最常踩的5个坑是哪些?
陪几家独立站建LTV算法这两年、踩过和看着别人踩过的坑也不少、挑5个最高频的拿出来说说。
误区一,用Order Value算LTV不扣退货。Shopify后台导出的订单CSV里默认包含已退货订单(refund_flag = true的那些),算LTV时如果不过滤会系统性高估。退货率高的品类(服装类常见15%-25%)不扣退货算出来的LTV能虚高20%。第一步导数据时就把refund_flag那一列过滤掉——这一步漏了后面再补很麻烦。
误区二,把订阅模式和非订阅模式混在一个Cohort算。订阅模式(Box、SaaS)的留存曲线是"前3月急降后稳"、非订阅是"全程渐降"。如果一家独立站既有订阅产品也有零售产品、把两类客户混合算Cohort、得出来的曲线两头不像、模型基本废。建议至少分订阅 / 非订阅两组分别建模、有条件分得更细。
误区三,忽略季节性、用全年数据拟合通用曲线。圣诞季入站的客户和淡季入站的客户复购行为完全不同——圣诞冲动消费的转化客户后续复购率明显低于淡季有明确需求来的客户。建模时至少分"旺季Cohort"和"淡季Cohort"、有条件按月份分别拟合、不然旺季客户的低复购会拖低整体LTV预测的精度。
误区四,用历史LTV直接预测未来LTV、不考虑产品变化。如果一家独立站去年改了价格、加了新产品线、做了重大改版、过去的LTV模型对未来不再适用——产品变了消费者行为也变了、相当于"看着五年前的中国GDP预测今年的"。模型每6-12个月得回炉重做、不是建一次用三年。
误区五,把LTV模型算出来的数字当圣旨。LTV是预测、不是真值——置信区间宽 ±25%-40% 是常态。把LTV预测值 ×0.8作为"保守LTV"做预算决策、把 ×1.2作为"乐观LTV"做天花板规划。直接拿点估计值(最可能的那个数)做硬性出价上限、容易被波动打脸。这一点说穿了就是——别太相信自己的模型、它只比拍脑袋好一点、不是上帝视角。
宠物用品独立站18个月LTV实战复盘
把前面提到的那家宠物用品独立站完整复盘一遍、给一个具体的时间维度参照。背景——北美宠物用品DTC品牌、主品类宠物粮+宠物用品配件、月GMV起步阶段60万美元、客单价48美元、Meta+Google+TikTok三渠道月广告12万美元、Shopify自建站。2024年3月开始重建LTV模型。
第1-2个月——数据基础设施。这家店的核心障碍不是算法、是数据底层乱。Shopify订单与Klaviyo客户表与Meta广告报表三套数据各自为政、同一个客户在三个系统里customer_id都不一样、对不上。前两个月几乎全花在"数据中台搭建"——用Stape服务器端跟踪把首单来源渠道写回Shopify客户标签、用Klaviyo的customer_id作为主键统一打通、把Meta广告花费按UTM标签精确分摊到Shopify Cohort。光这一步就值回了后续16个月的所有LTV建模收益——数据干净比算法精细重要10倍。
第3-5个月——LTV模型v1。用过去12个月数据拉出来初版Cohort矩阵、跑Pareto/NBD模型(这家店月单4000+ 适合)。第一版结果就给团队当头一棒:Meta渠道客户的12个月LTV ROAS真实值只有2.1、而报表里的首单ROAS是3.8——意思是每花1块钱Meta广告、看似赚回3.8、其实只赚回2.1。Google Search Brand渠道首单ROAS 7.2看着夸张、真实LTV ROAS 4.6(因为品牌词流量本来就是高意向、首单转化高但复购未必持续)。TikTok渠道首单ROAS 2.4看似难看、但真实LTV ROAS跑到3.8——TikTok抓来的是真正的新客户、复购衰减反而比Meta慢。三个渠道的真假对比让团队第一次明白广告预算分配该往哪挪。
第6-9个月——按LTV ROAS重新分配预算。把Meta预算砍掉25%、转给TikTok和Google Brand Search;同时调整每个渠道的目标CPA(按真LTV ROAS反推)、Meta Cost Cap设到35美元(之前是50)、TikTok Bid Cap设到42美元(之前是28)。前两个月广告总量略减、营收受到8% 短期影响——但毛利反而涨了3%、因为低LTV ROAS的预算被砍了。
第10-14个月——LTV模型迭代v2与SEO投入启动。v1模型跑了半年发现了一个隐藏价值——自然搜索流量的客户LTV比付费高出大约35%。团队拍板把广告预算的18% 转去做SEO内容与品牌建设、跟内容代理签了一个为期12个月的长尾内容项目(每月6篇深度内容)。这一阶段广告ROAS短期看略降、但自然流量月度增长率从原本的4% 跳到11%。
第15-18个月——收敛与回报。整体毛利率从重建前的28% 涨到36%、月GMV从60万美元涨到92万美元、广告总花费基本持平(12万→12.5万美元/月)、净利首次实现年化 +180万美元。创始人在第18个月的board meeting上说了一句话——"我们以前是按报表数字开车、现在是按真实数字开车、油耗下来了车反而更快"。这话有点像鸡汤、但财务数据是真的。
这家店的复盘有几个细节值得拿出来单独说。一个是团队心态从"追ROAS数字"转到"按Cohort看真实价值"花了大概4个月、比技术建模本身花的时间还长——人对漂亮数字的依恋是本能、要让CMO和CFO都接受"我们以前看的ROAS是假的"这个事实、需要反复用数据例子说服。第二个是模型上线后的第一次"打脸时刻"在第7个月——某次Meta优化师在不知情的情况下给一个低LTV ROAS渠道猛加预算、模型dashboard当周亮红灯、CFO直接叫停、避免了8万美元浪费。这种"系统能挡住人性偏差"的体验、是LTV模型对企业最有价值的部分。第三个是SEO投入启动到自然流量翻倍用了10个月——这个ROI周期比广告优化长得多、但因为有LTV数据撑腰、团队耐心是有的、没有中途放弃。
三条复盘心得:LTV建模80% 的工作量在数据底层不在算法、数据没打通Pareto/NBD跑得再花哨也是空中楼阁;Cohort真LTV ROAS与首单ROAS经常差1.5-2倍、不重建一次根本不知道自己在追假渠道;LTV模型最有价值的副产品是揭示出SEO与品牌长期投入的真实回报、付费渠道当下好看但LTV不一定撑得起、决策视角拉到18个月才看得清。这三条心得不只适用于宠物用品、对绝大多数月单 ≥1000的出海独立站都适用。
常见问题解答
下面几个问题是在独立站社群、客户咨询、行业聚会上被反复问到的、做了集中回答。详细字段也写进了本页的FAQPage结构化数据、方便Google直接抓取展示。
权威参考资料
本文标题:《算独立站LTV老是算错?Cohort留存还原ROAS的5步财务模型》
本文链接:https://zhangwenbao.com/dtc-ltv-calculation-cohort-roas-attribution.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0