JSON-LD怎么校验调试?一个尾逗号就能让整页结构化数据失效

本文目录
- 为什么改一个标点,整页结构化数据就当场失效?
- JSON-LD到底是写给谁看的?
- 一个绕不开的事实:JSON-LD本质就是JSON
- 把代码丢进格式化:第一眼就能看出缩进塌没塌
- 校验按钮到底在帮你查什么?
- 实测最容易翻车的几类JSON-LD语法错误
- 尾随逗号——最高频的翻车点
- 引号用错——中文引号和未转义的双引号
- 括号不配对——少一个花括号全盘皆崩
- @context与 @type拼写
- 校验提示的出错位置对不上,怎么二分法揪出真凶?
- 中文站的隐藏坑:编码、转义与那三个看不见的字节
- 为什么URL会变成https:\/\/,要不要紧?
- 五步用工具把一段JSON-LD调到干净
- 树形视图:在几百行嵌套里一眼找到出问题的那一层
- @graph把好几种Schema打包在一起,校验时要盯什么?
- 压缩成一行:上线前最后一步顺手做的事
- 语法对了,不代表结构化数据就对
- 它和Google富结果测试工具怎么分工?
- 把它接进“生成→校验→审计”这条流水线
- 一个跨境办公用品站的JSON-LD排错实录
- 插件和主题自动生成的JSON-LD,为什么也会崩?
- 几十个商品页要逐个校验,有没有更省力的办法?
- 把校验固化进发布流程,别等掉了收录才回头查
- 校验通过的代码,过段时间怎么又悄悄失效了?
- 常见问题解答
- JSON校验工具能直接告诉我Schema类型选得对不对吗?
- 我的JSON-LD里中文都变成了 \u开头的乱码,是出错了吗?
- 把JSON-LD压缩成一行,会不会影响SEO效果?
- 校验显示绿灯了,为什么Google还说我的结构化数据无效?
- 手写JSON-LD和用插件自动生成,哪种更容易出语法错误?
- 权威参考资料
摘要:结构化数据失效,十有八九不是你写错了类型,而是一个尾逗号、一对中文引号、少一个花括号——JSON-LD本质就是JSON,JSON的语法红线一条都碰不得。这篇把一台JSON格式化/校验工具讲透:怎么用它一眼揪出缩进塌陷、怎么靠错误提示定位到具体出错的位置、中文站特有的编码与转义坑怎么绕、为什么上线前还要顺手压一遍,以及它和Google富结果测试工具、结构化数据生成器各自该站在流水线的哪一环。
做技术SEO这些年,保哥见过太多人对着Google Search Console里“结构化数据无效”的红字发呆,翻来覆去检查Schema类型选得对不对、字段全不全,最后发现罪魁祸首只是某一行末尾多敲了一个逗号。这种bug最折磨人——它和你的SEO水平毫无关系,纯粹是机器对语法零容忍。
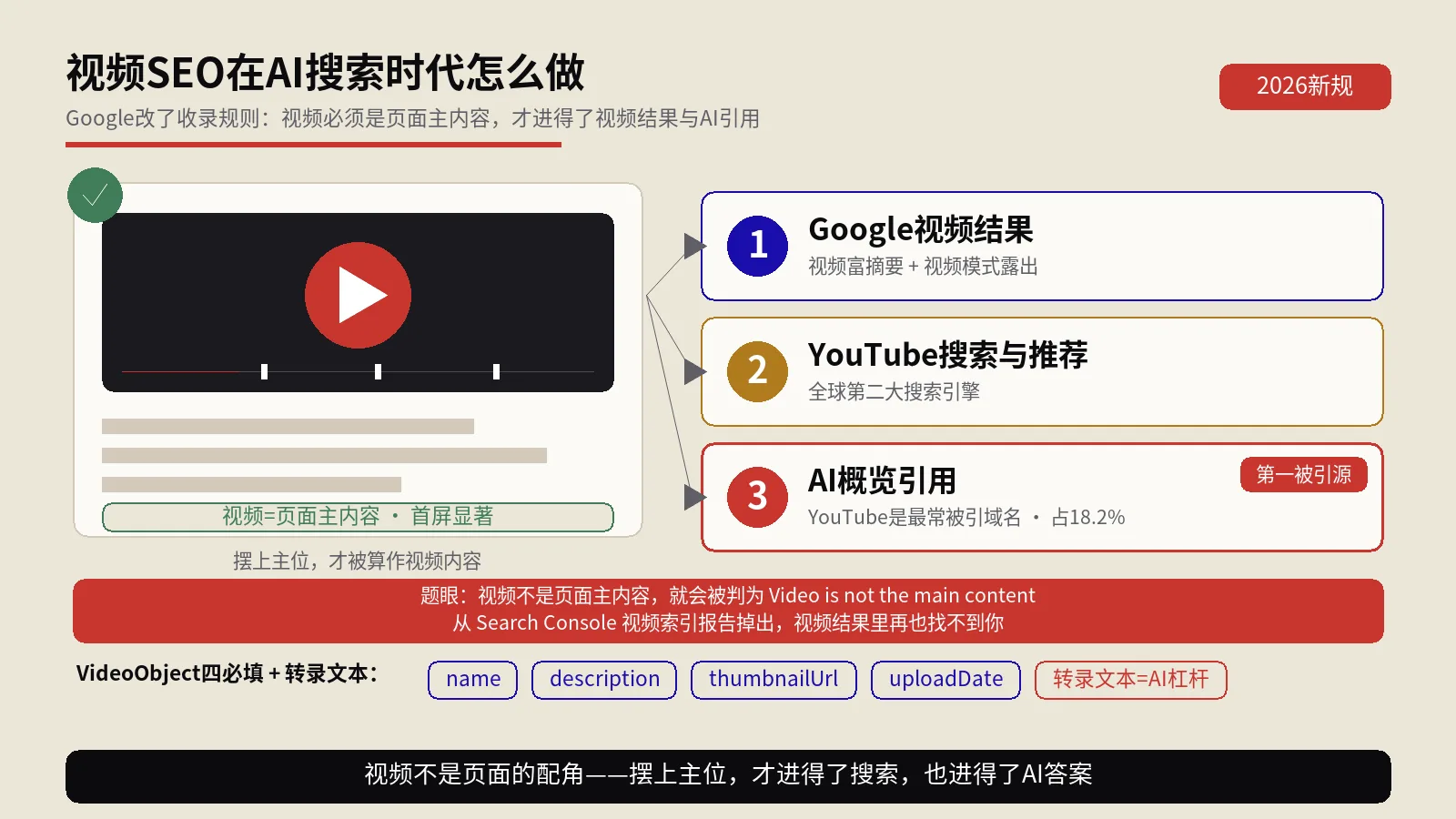
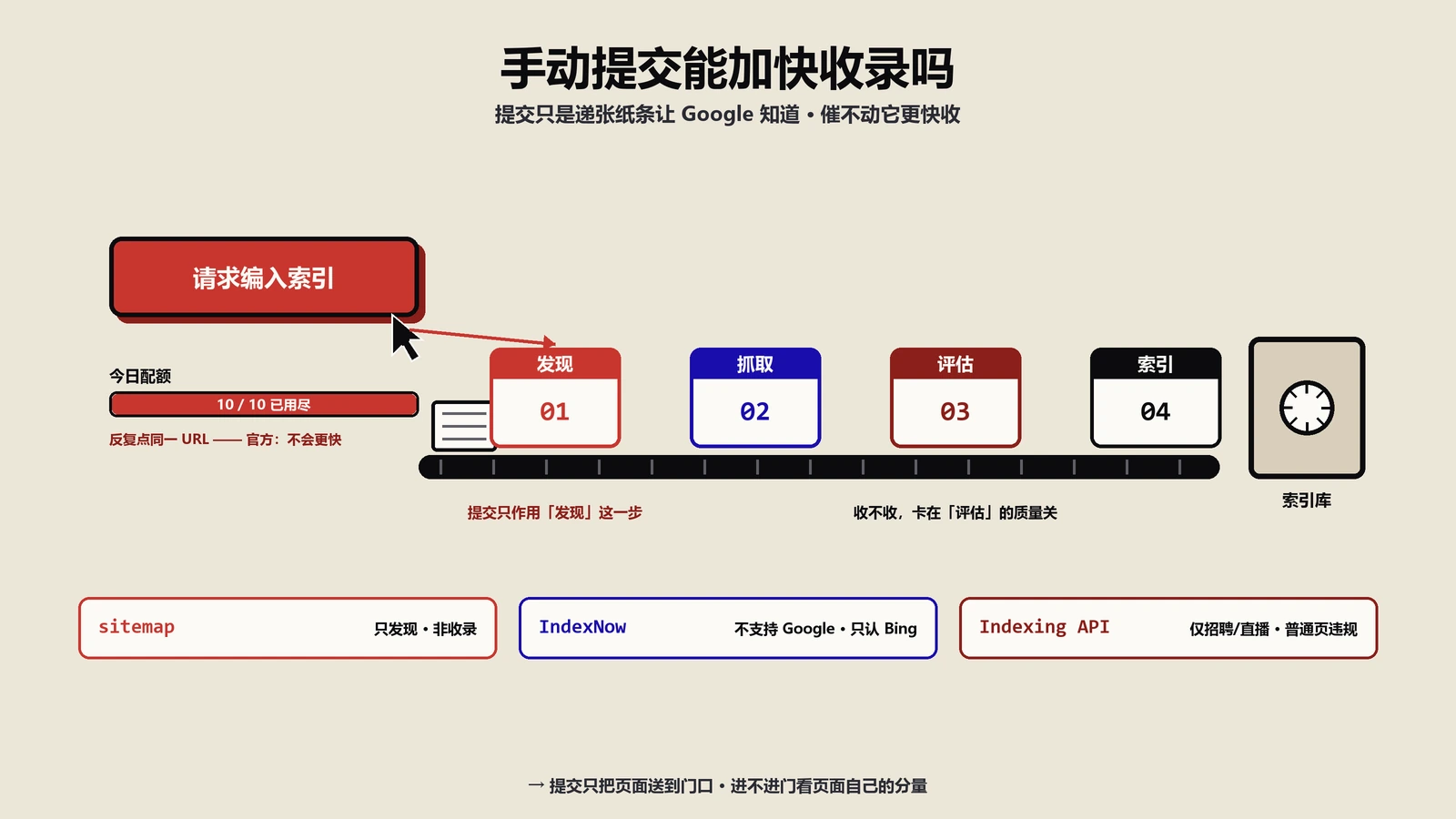
为什么改一个标点,整页结构化数据就当场失效?
搜索引擎读JSON-LD的方式,和你写Word文档完全不同。它不会“连蒙带猜”,而是用一个严格的JSON解析器逐字符往下读,一旦遇到不符合语法的地方,立刻停下、报错、然后把整段数据丢掉。注意,是整段丢掉,不是丢掉出错的那一行。
这意味着你精心写的50行商品结构化数据,只要第12行有一个全角引号,剩下49行正确的内容也跟着一起作废。Google看到的不是“有点小毛病的结构化数据”,而是“这里压根没有结构化数据”。富媒体摘要、价格星级、面包屑,全部不会出现。
所以排查结构化数据问题,第一步永远不该是怀疑自己Schema知识不够,而该先问一句:这段代码,它在语法层面是合法的JSON吗?这正是一台JSON校验工具存在的意义——把“语法对不对”这件机器才较真的事,先替你确认掉。
JSON-LD到底是写给谁看的?
JSON-LD的全称是JSON for Linking Data,直译过来是“用于关联数据的JSON”。它是 W3C的正式推荐标准,也是 Google明确表态最推荐的结构化数据格式。说人话:它是一段藏在网页 <head> 或 <body> 里、用户看不见、专门写给搜索引擎和AI看的“机读名片”。
这张名片告诉机器:这个页面是一篇文章,作者是谁,发布于哪天;或者这是一件商品,叫什么名字,卖多少钱,有没有现货。机器拿到这些结构化的事实,就能在搜索结果里给你拼出富媒体摘要,也更容易在AI回答里把你的内容当作可信来源引用。
正因为它是写给机器看的,所以人眼很难一眼看出毛病。一段被压成一行、几百个字符连在一起的JSON-LD,你盯着看半天也未必能发现哪里少了个括号。工具的第一个价值,就是先把它“摊开”给你看。
一个绕不开的事实:JSON-LD本质就是JSON
很多人把JSON-LD当成一种独立的“Schema语言”来学,结果忽略了最基础的一点:JSON-LD首先得是一段合法的JSON。@context、@type 这些带 @ 的关键字只是JSON对象里的普通键名而已,真正决定这段代码能不能被解析的,是JSON本身那套铁律。
JSON的语法规矩其实就那么几条,但条条是红线:字符串必须用英文双引号包裹,键和值之间用冒号,元素之间用逗号、且最后一个元素后面不能有逗号,花括号和方括号必须严格配对。这套规矩由 RFC 8259这份国际标准定死,全世界所有JSON解析器都照它执行,没有方言、没有例外。
认清这一点,排查思路一下就清晰了:JSON-LD出问题,要么是JSON语法层面崩了(工具能秒查),要么是语法没问题但Schema字段用得不对(要靠另一类审计工具和Google测试工具)。先把第一种排除掉,能省下大半的瞎猜时间。
把代码丢进格式化:第一眼就能看出缩进塌没塌
工具最常用的一个动作是“格式化”,也就是美化。把一段压缩的、挤成一团的JSON粘进去,点一下,它会按层级重新缩进、换行,让对象的嵌套结构清清楚楚摊在你面前。这个动作背后做的事很简单:先把字符串解析成数据结构,再按标准格式重新输出。
关键在于,能被成功格式化,本身就是一次隐性的校验。如果你的JSON有语法错误,解析这一步就会失败,工具根本格式化不出来,直接给你报错。所以哪怕你只是想让代码好看点,格式化也顺手帮你确认了语法合法性。
格式化之后还有个肉眼可见的好处:缩进。一段结构正常的JSON-LD,缩进会像阶梯一样层层递进;如果某个地方的缩进突然“塌”了一层、对不齐了,往往就是括号配对出了问题的信号。这是工具帮你把抽象的语法错误,翻译成了肉眼能察觉的视觉异常。
校验按钮到底在帮你查什么?
除了格式化,工具还有一个专门的“校验”动作。它不改动你的代码,只做一件事:尝试解析这段JSON,告诉你合法还是不合法。如果不合法,它会把解析器吐出的错误信息原样给你——比如“意外的字符”“期望一个属性名”之类。
这些错误信息有时候读起来像天书,但它们几乎都会附带一个关键线索:出错的大致位置。哪怕只是告诉你“第几个字符附近”,也足够把你的注意力从几百行里收窄到一小段。排错最耗时的从来不是改,而是找;工具把“找”这一步的范围帮你圈小了。
实际工作里,我的习惯是写完一段JSON-LD先不急着上线,直接丢进校验跑一遍。绿灯了再说别的,红灯就照着提示的位置回去看。这个动作只花两秒钟,却能拦住绝大多数会让结构化数据整段作废的低级语法错误。
实测最容易翻车的几类JSON-LD语法错误
语法错误的种类不多,但高频的就那么几种。把它们认全了,很多时候不用工具你自己都能反应过来哪里错了。
尾随逗号——最高频的翻车点
这是JSON-LD排错里的头号嫌疑犯。你写完一串属性,习惯性在最后一项后面也加了个逗号,或者删字段时删掉了内容却忘了删逗号。JavaScript对象能容忍这种尾逗号,但JSON标准不行,解析器读到“逗号后面紧跟着右括号”就会当场报错。
这个坑特别隐蔽,因为它在编辑器里看着毫无破绽。靠肉眼一行行数逗号很容易看走眼,但丢进校验工具,它会精准地把你带到那个多余逗号的位置。
引号用错——中文引号和未转义的双引号
JSON只认英文直双引号。可中文输入法一不留神就会打出全角的弯引号“”或者英文弯引号,这俩长得跟直引号几乎一样,肉眼极难分辨,但解析器一看就不认。另一种情况是字符串内容本身包含双引号却没转义,比如商品名叫“20寸"行李箱"”,里面的引号必须写成 \",否则解析器会以为字符串提前结束了。
这类错误是中文站的高发区。工具格式化时会把字符串重新规整,配合语法高亮的颜色,错位的引号会让整段颜色“串色”,很容易看出异常。
括号不配对——少一个花括号全盘皆崩
JSON-LD里对象套对象、数组套对象是常态,嵌套一深,花括号和方括号就容易多一个或少一个。这种错误在压缩成一行的代码里几乎不可能靠肉眼发现。格式化之后看缩进阶梯,或者用树形视图展开看层级,是定位它最快的办法。
@context与 @type拼写
这一类严格说不算JSON语法错误——@context 写成 @contxt,JSON解析照样通过,因为它只是个拼错的键名而已。但结构化数据会因此失效。这类问题校验工具查不出来,得靠后面会讲的Google富结果测试工具或专门的提取审计工具。把这两层分清楚,排错才不会找错方向。
校验提示的出错位置对不上,怎么二分法揪出真凶?
有时候校验工具提示的出错位置,和你肉眼看到的真正问题对不上——它说某个字符附近有问题,你过去看却一切正常。这不是工具在骗你。JSON解析器报的位置,是它“读不下去”的地方,而真正的错误(比如某个该闭合的括号没闭合)可能在更早的位置,解析器一路往后读,直到读到对不上了才停下报错。
遇到这种情况,二分法是最稳的笨办法:把JSON从中间砍成两半,分别丢进校验。哪一半报错,问题就在哪一半,再对那一半继续对半砍,几轮下来就能把出错范围收窄到很小一段。这招对那种“提示位置在结尾、真正的括号问题却在中间”的情况尤其管用,比从头到尾一行行死磕高效得多。
中文站的隐藏坑:编码、转义与那三个看不见的字节
出海做独立站的中文团队,常踩一个特别隐蔽的坑:文件保存成了带BOM的UTF-8。BOM是文件开头三个看不见的字节,普通编辑器不显示,但它会让JSON解析在第一个字符就失败,报一个让你完全摸不着头脑的错。把代码粘进工具校验时,这种藏在最前面的脏字符往往就暴露了。
另一个高频问题是中文被转成了 \u 转义。比如“行李箱”被某些工具自动转成 行李箱,虽然这在语法上完全合法、机器也能正确读出中文,但人眼完全没法核对内容对不对。好的格式化工具会带一个“不转义中文”的选项,把这些 \u 还原成可读的汉字,让你能直接核对商品名、描述这些关键字段写没写对。
为什么URL会变成https:\/\/,要不要紧?
你可能注意到,有些工具输出的JSON-LD里,网址会变成 https:\/\/example.com 这种带反斜杠的样子。这是因为JSON标准允许把斜杠转义成 \/,很多语言的默认输出会这么做。它在语法上完全合法,机器读起来毫无障碍,所以——不要紧。
但它确实碍眼,也不利于人工核对 @id、url 这些字段里的链接写对没有。这正是格式化工具里“不转义斜杠”选项的用处:输出干净的 https://,让你一眼就能确认每个URL都指向了正确的页面。对内容里全是绝对链接的JSON-LD来说,这个小开关能省不少核对的功夫。
五步用工具把一段JSON-LD调到干净
把上面这些拆开讲的点串成一套固定动作,下面这个流程我们团队几乎天天在用,照着走一遍,一段JSON-LD该有的问题基本都能在上线前拦下来。
- 原样粘贴先校验:把从模板或插件里复制出来的JSON-LD,连同可能存在的脏字符一起,原封不动粘进工具,先点校验。红灯就记下它提示的出错位置。
- 格式化看结构:点格式化,让代码按层级摊开。顺着缩进阶梯往下看,哪一层突然对不齐,问题大概率就在那附近,重点查括号配对和尾随逗号。
- 打开不转义中文与斜杠:让
\u还原成汉字、\/还原成正常斜杠,然后逐字段核对商品名、价格、URL这些关键内容,确认机器读到的和你想表达的一致。 - 用树形视图查嵌套:如果是
@graph多实体或深层嵌套的复杂结构,切到树形视图,一层层展开,确认每个对象的层级关系没有错位。 - 压缩后再上线:确认无误后点压缩,把代码压成一行,复制进页面模板。体积更小,加载更快,也避免多余空白在某些环境下引发意外。
树形视图:在几百行嵌套里一眼找到出问题的那一层
当JSON-LD简单的时候,格式化加缩进就够看了。但一旦你用 @graph 把文章、面包屑、组织信息打包在一起,或者商品下面挂了一堆评价和规格,代码动辄几百行,纯文本看起来就很吃力了。
树形视图把JSON渲染成可折叠的层级结构,每个对象、数组都能点开收起。你想确认“面包屑那一层的itemListElement是不是数组”,直接折叠掉无关的层,只展开那一支看,比在几百行文本里上下翻页找对应的括号快得多。它本质上是把JSON的嵌套关系,从一堆括号翻译成了你熟悉的文件夹式视图。
@graph把好几种Schema打包在一起,校验时要盯什么?
稍微复杂点的页面,往往会用 @graph 把好几种结构化数据打包在一起——一篇文章页可能同时挂着Article、面包屑、网站信息、组织信息四五个实体。这种打包写法本身是规范推荐的,但它把出错的概率也翻了几倍:任何一个实体内部少了一个括号,整个 @graph 都会跟着解析失败,一损俱损。
校验这种结构时有两个点要特别盯。一是 @graph 的值必须是一个数组,也就是用方括号括起来的列表,新手很容易误写成对象。二是数组里每个实体都得是独立完整的对象,实体之间用逗号隔开、最后一个后面别留逗号。格式化配合树形视图一起看,能让每个实体的边界清清楚楚,哪个实体“漏”进了别人内部、哪个少了收尾括号,一眼就能揪出来。
压缩成一行:上线前最后一步顺手做的事
格式化让代码好读,压缩则反过来——把所有缩进、换行、多余空格全部去掉,压成密不透风的一行。这是上线前的标准动作。原因有二:一是体积更小,几百行的结构化数据压缩后能省下可观的字节,对页面加载是实打实的优化;二是更稳妥,某些模板系统或缓存环境对多行内容的处理不够友好,压成一行能规避一些莫名其妙的渲染问题。
需要强调的是,压缩纯粹是去掉对机器无意义的空白字符,不会动任何数据内容,机器读到的信息和压缩前一模一样。所以放心压,它不影响结构化数据的有效性,只让它更精瘦。
语法对了,不代表结构化数据就对
这是最需要提醒的一点。JSON校验工具能保证的,仅仅是“这段代码是合法的JSON”。它管不了你的Schema用得对不对——类型选错了、必填字段漏了、@type 拼错了、日期格式不符合规范,这些在JSON语法层面统统合法,校验器照样给你亮绿灯。
换句话说,校验通过只是及格线,是“机器能读”,但不等于“Google认可并展示”。要确认Schema字段层面对不对,得靠Google官方的富结果测试工具,或者专门把页面里结构化数据提取出来、逐字段对照必填项的提取审计工具。语法层和语义层是两道不同的关,得分开过。
它和Google富结果测试工具怎么分工?
很多人会问,既然Google有官方的富结果测试工具,为什么还要单独用一台JSON校验工具?答案是分工不同,而且JSON校验跑在更前面。
Google的工具强在语义层:它知道Article必须有headline、Product推荐有image,能告诉你哪个字段缺了、哪个值不符合要求。但它有两个短板——一是需要联网、有时还要求页面可公开访问,调试草稿不方便;二是当你的JSON有语法错误时,它往往只会笼统地说“解析不出结构化数据”,不会精确告诉你是第几行那个逗号的锅。
JSON校验工具正好补上这一段:在你还没把代码贴上线之前,先在本地把语法层的坑全填平,确保丢给Google工具的是一段语法干净的JSON。这样Google工具报的就全是真正的Schema字段问题,而不是被语法错误带偏。先JSON校验、再Google测试,这个顺序能让排错效率高一大截。
把它接进“生成→校验→审计”这条流水线
单独看,JSON校验只是个小工具;但把它放进结构化数据的完整工作流里,位置就清晰了。我们内部把这条线分成三段:先用结构化数据生成器按类型生成JSON-LD骨架,再用JSON校验工具把语法层的毛刺磨干净,最后用提取审计工具对照线上页面,确认Schema字段完整、被搜索引擎正确识别。
这三段各管一摊:生成管“写得快”,校验管“语法对”,审计管“字段全、能被认”。任何一段缺位,结构化数据都可能在某个环节悄悄失效却没人发现。把JSON校验固定在生成之后、上线之前这个位置,等于给结构化数据装了一道最便宜也最有效的语法保险。
一个跨境办公用品站的JSON-LD排错实录
去年帮一个做跨境办公用品的独立站看问题,他们的人体工学椅产品页明明配好了Product结构化数据,Search Console里却始终报无效,富媒体星级死活出不来。运营自己查了好几天,把Schema字段对着官方文档核了一遍又一遍,确认没毛病,百思不得其解。
保哥拿到那段代码,没急着看字段,先整段丢进JSON校验跑了一下,红灯。提示出错位置在中段,顺着过去一看——产品描述里写了句“适合30寸"宽桌面"使用”,那对英文双引号没转义,解析器读到第一个引号就以为字符串结束了,后面全乱套。改成 \",再校验,绿灯,重新提交,第二天富媒体星级就出来了。
这事的教训很典型:折腾了好几天的“Schema配置问题”,根子其实是一个两秒钟就能查出来的语法错误。运营之所以绕远路,就是因为一上来方向就错了——盯着语义层猛查,却跳过了更底层、更该先排除的语法层。从那以后,那个站把JSON校验列成了结构化数据上线前的强制一步。
插件和主题自动生成的JSON-LD,为什么也会崩?
不少人觉得,装了SEO插件、用了带结构化数据的主题,JSON-LD这事就交给程序了,自己不用操心。这个想法对了一半。插件确实能保证它生成的“框架”语法正确,但框架里填的内容,是你在后台一个个字段敲进去的——一旦你填的标题里带了没转义的英文引号,描述里粘了一段带富文本格式的内容,或者价格字段混进了货币符号和千分位逗号,插件照样会吐出一段崩掉的JSON-LD。
还有一种更隐蔽的崩法:主题自带一套结构化数据,又装了个SEO插件也输出一套,两套抢着往页面里塞,结果同一个页面冒出两个Article、两套互相打架的字段。这种问题语法层未必报错,却会让搜索引擎犯迷糊。所以哪怕全靠程序生成,上线前抓几个代表性页型,把它们的JSON-LD提出来过一遍校验,仍然是省心的做法。
几十个商品页要逐个校验,有没有更省力的办法?
独立站SKU一多,让人对着几百个商品页一个个复制粘贴校验,显然不现实。规模化的思路是抓重点,而不是拼体力。结构化数据绝大多数是模板渲染出来的,同一种页型共用一套模板,所以模板对了,这一类页就基本都对——校验的重点应该放在“每种页型抽一两个代表页”上,而不是全量页。
具体做法上,先把站点的页型理清楚:首页、分类页、商品页、文章页、活动页各算一类,每类挑字段最全、嵌套最复杂的那一个做深度校验,确认模板层没问题。剩下的交给能批量扫描线上页面的提取审计工具去抽查,重点看有没有哪一批页因为数据缺失或特殊字符而集体失效。手动精校代表页、工具批量兜底,是兼顾质量和效率的组合。
把校验固化进发布流程,别等掉了收录才回头查
工具再好用,临时想起来才用一次,价值也有限。真正能省心的做法,是把“上线前JSON校验”变成一条雷打不动的发布纪律,就像代码合并前要过一遍测试一样。每次改动了页面的结构化数据——不管是手写的、模板生成的还是插件输出的——上线前都先丢进工具校验、格式化、核对、压缩,一套走完再发。
这个习惯的回报是隐性的:它防住的是那些“不报错、但悄悄失效”的问题。结构化数据失效不会让页面崩溃,用户照样能正常浏览,所以很容易拖很久都没人发现,等你察觉富媒体摘要不见了、AI也不再引用你的内容,可能已经损失了好几个月的流量。一个两秒钟的校验动作,挡在前面,比事后追查划算太多。
校验通过的代码,过段时间怎么又悄悄失效了?
有个常被忽略的事实:JSON-LD不是写一次就一劳永逸的。它失效往往发生在“上线时明明是好的”之后。最常见的诱因有三类。第一类是动态数据变动:商品价格、库存状态这些字段是从数据库实时取的,某天运营在后台把价格改成了带特殊符号的写法,模板拼出来的JSON-LD就崩了。
第二类是模板或插件升级。一次主题更新、一个插件版本变化,都可能悄悄改动结构化数据的输出格式,把原本正确的字段名改了,或者多塞了一层嵌套。第三类是内容编辑:有人在商品描述里粘了一段带引号、带换行的文案,这些字符进了JSON-LD字段又没被正确转义,整段就废了。这三种情况的共同点是,它们都发生在你“以为已经搞定”之后。
应对办法不是更勤快地手动检查,而是建立监控。定期用提取审计工具抽扫线上页面,或者在Search Console里盯着结构化数据报告的趋势——一旦某类页型的有效数突然下跌,多半就是某次改动引入了语法问题。把校验从“上线前一次性动作”升级成“持续性监控”,才能真正守住结构化数据长期不掉链子。
常见问题解答
JSON校验工具能直接告诉我Schema类型选得对不对吗?
不能。它只负责语法层,确认这段代码是不是合法的JSON。类型选得对不对、必填字段全不全这些语义层的问题,它管不了,得用Google富结果测试工具或专门的结构化数据提取审计工具来查。两类工具分工不同,建议先过JSON校验、再过语义校验。
我的JSON-LD里中文都变成了 \u开头的乱码,是出错了吗?
没出错。\u 是JSON对非ASCII字符的合法转义写法,机器能正确还原成中文,不影响结构化数据有效性。只是人眼没法核对内容。用格式化工具里的“不转义中文”选项,就能把它还原成可读的汉字,方便你确认字段写对没有。
把JSON-LD压缩成一行,会不会影响SEO效果?
不会有负面影响,反而略有好处。压缩只是去掉对机器无意义的空白字符,结构化数据携带的信息一字不少,搜索引擎读到的完全一样。而且体积更小、加载更快,对页面性能是正向的。所以上线版本用压缩后的代码是更推荐的做法。
校验显示绿灯了,为什么Google还说我的结构化数据无效?
因为校验绿灯只代表JSON语法合法,不代表Schema用得对。很可能是类型选错、必填字段缺失、@type 拼写错误,或者日期、URL等字段格式不符合Google要求。这些都属于语义层问题,JSON校验查不出来。下一步该把代码放进Google富结果测试工具,它会逐字段告诉你缺什么、错什么。
手写JSON-LD和用插件自动生成,哪种更容易出语法错误?
手写更容易出语法错误,尾逗号、引号、括号都是高发区,所以手写后过一遍JSON校验几乎是必须的。插件自动生成的语法通常更可靠,但也不是绝对——当你往插件里填的内容本身带了未转义的引号或特殊字符时,它输出的JSON-LD一样会崩。所以无论哪种来源,上线前都建议统一过一道校验。
权威参考资料
本文标题:《JSON-LD怎么校验调试?一个尾逗号就能让整页结构化数据失效》
本文链接:https://zhangwenbao.com/json-ld-validator-syntax-debug-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0