多语言大站hreflang手写维护不动?用AI写脚本从爬虫结果自动生成sitemap

本文目录
- 为什么多语言站一上规模,hreflang就成了维护噩梦?
- hreflang到底能放哪几个地方,大站为什么偏偏要选sitemap?
- sitemap里的hreflang,到底长什么样?
- 手写既然不现实,为什么不干脆写个脚本来生成?
- 关键心法:把AI当成一个聪明但需要明确指令的初级程序员
- 开工前,先把这几类边界情况跟AI谈清楚
- 喂给脚本的数据,得先洗干净
- 用Google Colab跑,省掉“装环境”这件最劝退的事
- 怎么一步步把AI逼出一个真能用的脚本?
- 脚本生成完别急着上线,先用爬虫反向验收一遍
- 这套“让AI写脚本”的思路,能迁移到哪些活上?
- 一个出海多语言站,是怎么把这件事跑顺的?
- 落地这套流程,最容易踩的几个坑是什么?
- 常见问题解答
- 我们站就两三种语言,也值得这么折腾去写脚本吗?
- 我完全不会写代码,真能靠AI把这个脚本搞出来吗?
- 为什么一定要把404和301这些先从清单里删掉?
- 为什么推荐Google Colab,本地装个Python不行吗?
- 用插件自动生成hreflang,和用脚本生成sitemap,到底差在哪?
- 脚本生成的sitemap,多久要重新跑一次?
- 权威参考资料
摘要:多语言站做到几千上万个页面,hreflang靠手写、靠插件硬撑,迟早会维护不动——漏一个回指标签、写错一个地区码,整组语言关系就失效。这篇讲一条更省力的路:把hreflang收进XML sitemap集中管理,再让AI当一个初级程序员,帮你写一个Python脚本,从爬虫导出的清单里自动生成这份sitemap。重点不在代码本身,而在怎么指挥AI——先聊架构和边界情况、先把数据洗干净、用Colab免去装环境、拿具体例子逼它一轮轮改对,最后用爬虫的hreflang报告反向验收。一套学会,能迁移到一大批重复的技术SEO活上。
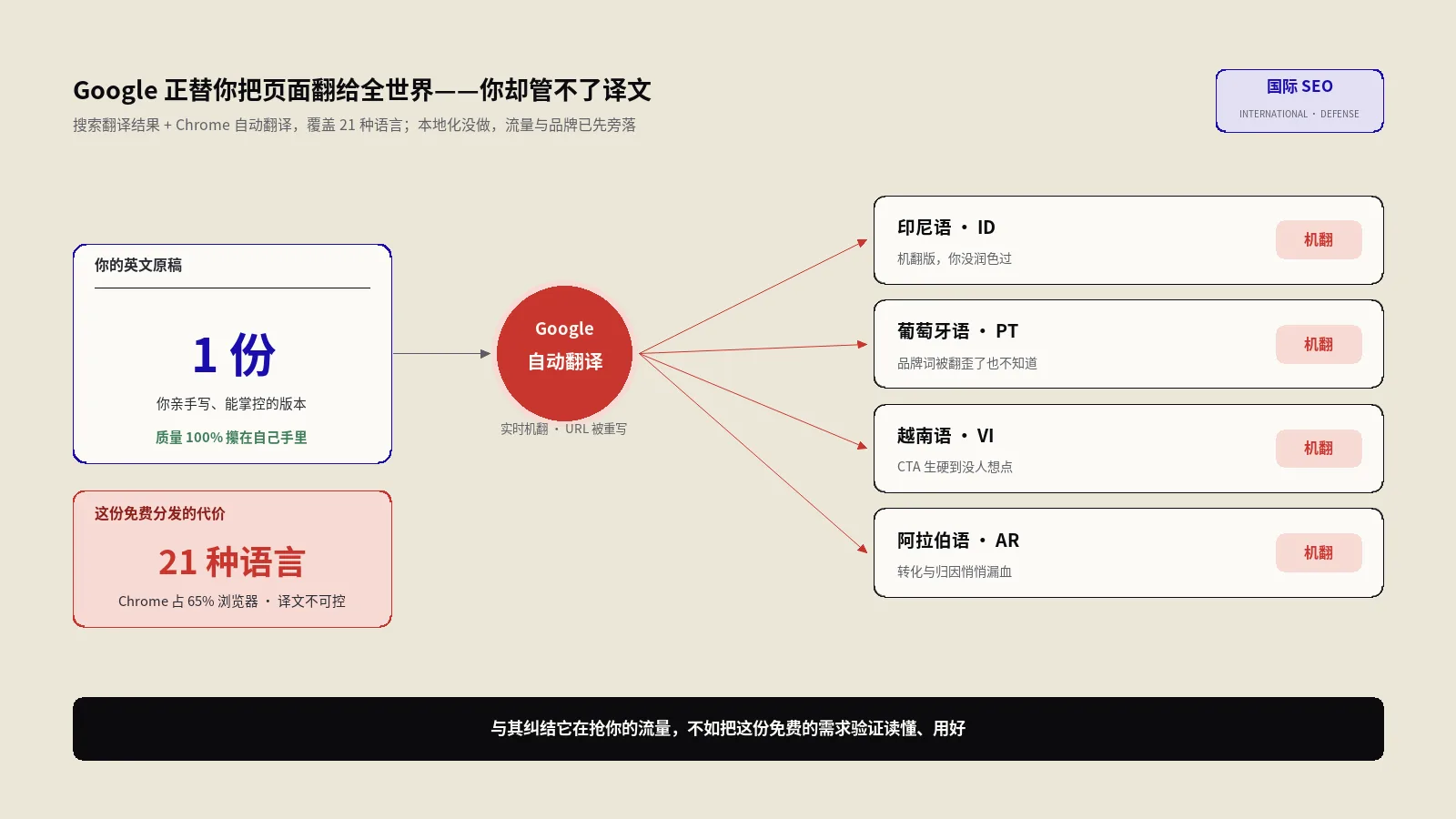
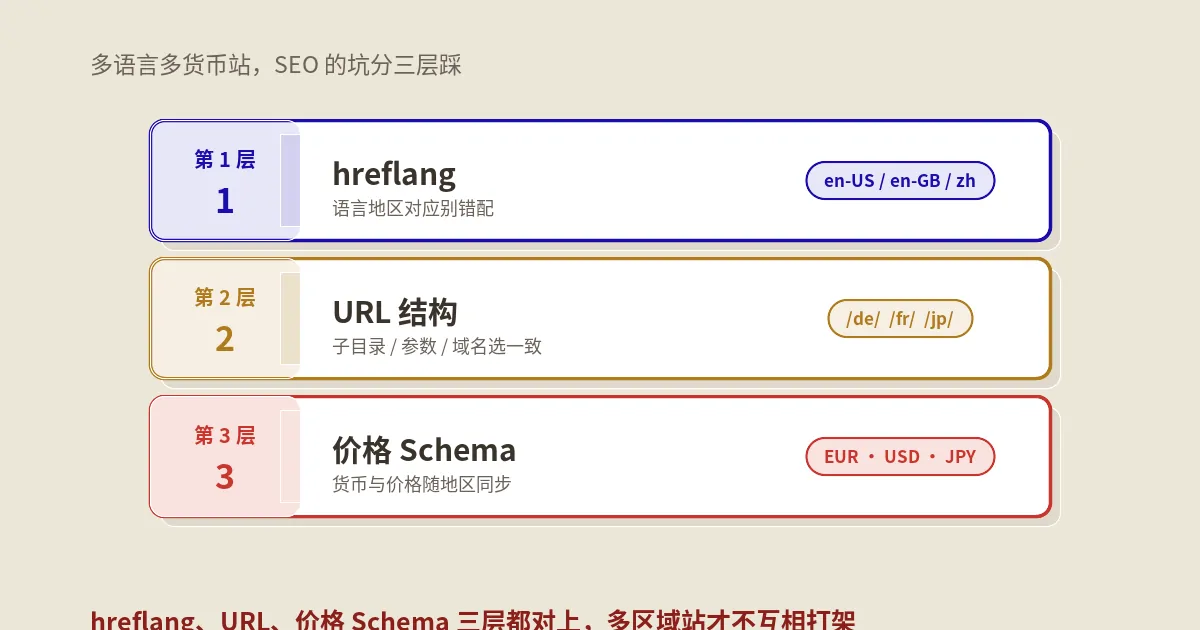
做外贸独立站、做出海多语言站的人,多半都和hreflang打过架。一两个语言版本的时候它岁月静好,可一旦站点铺到五六种语言、再叠上美英澳几个地区,页面数量乘起来,hreflang这件事就从“配置一下”变成了“维护噩梦”。
更糟的是它脆。hreflang是一组必须两两对上的关系,漏一个回指、写错一个代码、指向一个已经404的旧页,那一整组语言关系就可能被搜索引擎默默忽略。页面越多,手一抖出错的概率越高,而出了错你往往还看不见。这篇就讲一条能实实在在省力气的路:把hreflang收进sitemap,再让AI替你写脚本自动生成它。
为什么多语言站一上规模,hreflang就成了维护噩梦?
先说清楚痛在哪。hreflang最常见的实现方式,是在每个页面的head里,用一串link标签把这个页面的所有语言地区版本都列一遍,而且每一版都得列上自己(自指),还得把其它所有版本也列全。
问题就出在“列全”这两个字。假设你有6种语言地区版本,那么每一个页面的head里都得塞6行hreflang标签;而同一篇内容跨6个版本,就是6个页面、每页6行,光这一篇文章背后就是36行需要彼此对齐的标注。页面数量再一乘,整站要维护的hreflang标签轻松上万行。
这套东西最要命的地方是牵一发动全身。你新增一个语言版本、或者改了某个页面的URL,那么所有指向它的兄弟页面的hreflang都得跟着改一遍。靠人去维护,几乎不可能不漏;靠多语言插件自动生成,又经常在边界情况上翻车——分页、参数页、被canonical合并的页面,插件未必处理得对。关于这套关系到底为什么这么难对齐、有哪些典型根因,保哥在国际化SEO和hreflang完整指南里系统拆过,这里只强调一个结论:规模一大,靠手和插件都不够,得有一套能批量、能复算的生成方式。
hreflang到底能放哪几个地方,大站为什么偏偏要选sitemap?
很多人不知道,hreflang其实有三个合法的放置位置,Google在官方的多语言多地区版本文档里写得很清楚:可以放在HTML的head标签里,可以放在HTTP响应头的Link字段里,也可以放在XML sitemap里。三种方式对搜索引擎是等效的,选哪种是工程问题,不是效果问题。
对小站来说,head标签最直观,写死在模板里就行。但前面算过那笔账——大站用head,等于把上万行彼此关联的标签摊进每一个页面,又乱又难改,还白白增加每个页面的体积。HTTP头的方式适合PDF这类非HTML文件,配置起来对服务器要求也高。
剩下sitemap这条路,恰恰是为大站准备的。它把全站的hreflang关系从一个个页面里抽出来,集中到一份(或几份)XML文件里统一声明。好处有三个:一是集中,所有语言关系在一处维护,改起来有的放矢;二是干净,页面本身不被一堆标签撑大;三是可生成,既然是结构规整的文件,那就天然适合用脚本批量产出,而不是手写。
这里顺带提一句sitemap本身的硬限制:按Google的构建和提交sitemap官方说明,单个sitemap文件最多5万条URL、未压缩不超过50MB,超了就得拆成多个文件、再用一个sitemap索引文件统管。大站基本都会触到这条线,所以脚本除了生成内容,最好顺手把分片和索引也一起处理掉。sitemap这套文件本身怎么写才不出错,可以对照Sitemap完整指南那一篇,把格式细节先吃透。
sitemap里的hreflang,到底长什么样?
动手写脚本之前,得先知道目标产物长什么样,不然没法跟AI说清楚要什么。在sitemap里,每一个URL用一个url块表示,块里除了常规的loc,还要为它的每一个语言地区版本各加一行xhtml:link标注,而且必须把自己也算进去。一个最小例子是这样:
<url>
<loc>https://example.com/en-us/product/</loc>
<xhtml:link rel="alternate" hreflang="en-us" href="https://example.com/en-us/product/"/>
<xhtml:link rel="alternate" hreflang="en-gb" href="https://example.com/en-gb/product/"/>
<xhtml:link rel="alternate" hreflang="de-de" href="https://example.de/produkt/"/>
<xhtml:link rel="alternate" hreflang="x-default" href="https://example.com/product/"/>
</url>这里有几条铁规则,错一条整组就废。第一,自指不能少:每个URL的hreflang清单里,必须有一行指向它自己。第二,必须双向回指——官方的说法是,如果A页指向B页,那B页也必须指回A页,单向的会被忽略。第三,语言地区代码要合规:语言用ISO 639-1(比如en、de),地区用ISO 3166-1的两位字母(比如US、GB),写成en-us这种形式,常见的低级错误是把英国写成en-uk,可这个uk不是合法地区码,正确的是en-gb。
第四,x-default用来兜底:当用户的语言地区跟你所有版本都对不上时,给他看哪个页面,就用x-default标出来,通常指向语言选择页或默认的国际版。把这几条规则记牢,它们后面会变成你验收脚本输出的检查清单——脚本生成得对不对,就看这几条有没有逐条满足。
手写既然不现实,为什么不干脆写个脚本来生成?
看到上面那套结构你大概也明白了:它规整、重复、规则明确——这正是最适合交给程序去做的活。人去手敲上万行还要保证两两对齐,是在跟自己的注意力极限较劲;而一段脚本只要逻辑写对了,跑一万条和跑十条一样稳。
那为什么过去很多SEO没走这条路?因为“写脚本”这四个字,对不少做内容、做运营出身的人是道门槛——不会Python、不懂怎么搭环境、报个错就卡住。但这两年这道门槛被AI抹平了一大半。你不必自己从零写代码,而是把需求讲清楚,让AI替你写,你来当那个提需求、验结果、指出问题的人。
说白了,这是把自己的角色从“码农”换成了“带初级程序员的技术负责人”。你不需要懂每一行语法,但你得懂这件事该怎么拆、边界在哪、什么样的输出算对——这些恰恰是SEO比AI更懂的部分。用AI写SEO小工具这条路本身怎么走、有哪些通用避坑,用Vibe Coding做SEO工具实战指南里有一套现成的方法,这篇算是把它落到hreflang sitemap这个具体场景上。
关键心法:把AI当成一个聪明但需要明确指令的初级程序员
这是整件事最值钱的一句话,也是新手和老手用AI写脚本差距最大的地方。初级程序员的特点是什么?聪明、手快、语法熟,但缺乏对你业务上下文的理解,你给的指令越含糊,他自由发挥得越离谱。
所以别一上来就甩一句“帮我写个生成hreflang sitemap的脚本”然后等着收成品。正确的开场,是先跟它讨论架构和边界情况:输入数据长什么样、字段有哪些、语言地区怎么从URL或某个字段里识别、遇到没有对应翻译版本的页面怎么办、x-default该指向哪里、输出要不要分片。把这些边界先聊明白,再让它动手,出来的第一版才不会南辕北辙。
这里的反直觉之处在于:花在“聊清楚需求”上的时间,远比花在“让它改bug”上的时间值钱。一个被含糊需求带偏的脚本,你可能要来回纠十几轮还在原地打转;而一个开局就把边界谈清楚的脚本,往往两三轮就能用。带过人的都懂——返工的根源,九成在交代任务的那一刻就埋下了。
开工前,先把这几类边界情况跟AI谈清楚
“先聊边界”说起来抽象,落到hreflang sitemap这个活上,其实就是几类绕不开的具体问题。把它们当成一份开工前的清单,逐条跟AI交代明白,第一版脚本就能少走很多弯路。
第一类是语言地区怎么识别。你的多语言版本是放在子目录里(example.com/en-us/)、子域名里(en.example.com),还是独立的国家域名(example.de)?脚本得知道从URL的哪一段、还是从导出表里的哪个字段,把每个页面的语言地区码摘出来。这一步规则不讲清楚,它后面全是瞎猜。
第二类是没有对应翻译的孤页怎么办。现实里很少有内容能做到每种语言都齐整,总有些页面只有英语版、没有德语版。脚本遇到这种页面,是只给它列出存在的那几个版本,还是硬塞一个不存在的链接?答案当然是前者——只标真实存在、能访问的版本,宁缺毋滥,但这条得明确告诉它。
第三类是x-default到底指向哪。是指向语言选择页,还是默认的国际版首页,还是英语版?这没有标准答案,取决于你站点的结构,但你必须替它拍板,否则它要么漏掉x-default,要么乱指一个。第四类是同一篇内容被抓到多个带参数或带斜杠差异的变体时怎么去重,得让脚本认准canonical那一个,别把重复变体也当成独立版本塞进去。
最后一类是分片。前面说过单个sitemap有5万条上限,所以还得交代清楚:超过阈值时怎么自动拆成多个文件、再生成一个sitemap索引文件统管。把这五类边界一次性跟AI摆明白,它写出来的第一版才算站在了正确的起点上,剩下的就是拿真实数据去迭代细节了。
喂给脚本的数据,得先洗干净
脚本再聪明,喂进去的是垃圾,吐出来的也是垃圾。生成hreflang sitemap,第一步不是写代码,是准备一份干净的URL清单,而这份清单的质量直接决定成败。
常规做法是用爬虫把全站爬一遍,导出一份URL列表。一般用桌面爬虫工具把站点完整抓一轮,导出成CSV,具体怎么配置爬取范围、怎么处理大站,可以参考Screaming Frog全站审计实战那套流程。但导出来的原始清单不能直接用,得先过一道筛。
筛的核心原则是:只有能被索引、状态正常的页面才配进hreflang。所以要把这几类剔掉——返回404的死链、做了301跳转的旧地址、带noindex的页面、非canonical的重复变体。理由很硬:hreflang指向一个不该被索引的URL,本身就是个错误信号,会拖累整组关系的可信度。
这一步偷不得懒。保哥见过最典型的翻车,是有人把爬虫导出的几万行原封不动喂给脚本,结果生成的sitemap里混进一大堆301和404,hreflang报告一片飘红。先花十分钟在表格里按状态码和可索引性过滤一遍,比后面回头排查一整天划算得多。清洗这一步做扎实了,后面脚本的逻辑反而简单——因为它要处理的,已经是一份“每一行都该进sitemap”的干净数据。
用Google Colab跑,省掉“装环境”这件最劝退的事
很多人卡在第一关不是写不出代码,而是装不好环境——Python装哪个版本、依赖怎么管、报个找不到模块的错就不知道怎么办。这一关足以劝退一大半想动手的SEO。
绕过它的办法,是用Google Colab这类云端笔记本。它本质是一个跑在浏览器里的Python环境,免费、零安装,打开网页就能写代码、跑代码,常用的库大多已经预装好。你把AI写的脚本贴进去,上传那份洗干净的CSV,点运行,sitemap文件就生成在云端,下载下来即可。
这么选有两个额外好处。一是环境统一,你和AI沟通时不用再纠结“我本地装的是什么版本”,大家都在同一个标准环境里,报错也更好复现。二是门槛真的低到了非技术同事也能跟着跑——把笔记本分享出去,别人改几个参数就能复用,等于顺手把这件事沉淀成了团队能反复用的工具,而不是锁在你一个人电脑里的一次性脚本。
怎么一步步把AI逼出一个真能用的脚本?
第一版脚本几乎不可能一次到位,真正的功夫在迭代。而迭代的效率,取决于你怎么给反馈。
最常见也最低效的反馈,是甩一句“不对,有问题,再改改”。AI收到这种话只能瞎猜,越改越乱。高效的反馈是给具体例子:“这一行URL,它的地区版本应该是这三个,但脚本只识别出两个,漏了de-de这个”。你把出错的具体输入、期望的正确输出、实际的错误输出都摆出来,AI才能精准定位逻辑哪里错了。
这跟带人改方案是一个道理——你说“这版不行”,对方一脸茫然;你说“第三段这个数据引错了,应该是X”,对方立刻就懂。每一轮都用一个具体的失败案例去推它,三五轮下来,那些边界情况就被一个个堵上了:没有翻译版本的孤页怎么处理、同一页被抓到两个带参数的变体怎么去重、x-default该挂在哪。把这些都迭代干净,脚本才算真能上生产。
保哥的经验是,准备一小批“刁钻样本”专门喂给它——故意挑那些结构最乱、最容易出错的页面去测脚本,而不是拿一批规整的标准页验完就以为没事。脚本能把最难的几类啃下来,剩下的规整页自然不在话下。
脚本生成完别急着上线,先用爬虫反向验收一遍
脚本跑出一份sitemap,不代表它就是对的。上线前必须做一道反向验证,而最省事的验证工具,恰恰还是爬虫。
Screaming Frog在官方的hreflang审计教程里提供了一整组专门的hreflang报告,几乎就是照着前面那几条铁规则来挑错的:缺失回指链接、回指语言不一致、指向非canonical页面、指向noindex页面、指向非200状态页、语言地区代码写错、自指缺失、重复条目。把生成的sitemap交给它跑一遍,这几张报告全干净,才说明脚本的逻辑真的对了。
举个常见的隐形坑。脚本从URL里识别语言地区时,如果把某一批带地区子目录的页面漏识别了,那这批页面在sitemap里就会缺自指、或者缺对兄弟版本的回指——肉眼扫一遍XML根本看不出哪里不对,可爬虫的“缺失回指链接”“缺失自指”两张报告会立刻把它们标红。没有这道独立复核,这种错误很可能就带病上线,几个月后你在搜索后台看到一堆hreflang告警,还得回头猜是哪一步出的问题。
这一步千万别省。脚本是人(和AI)写的,逻辑里藏个边界没考虑到太正常,而hreflang的错误又是那种你肉眼几乎看不出、却实实在在让整组关系失效的隐形坑。用爬虫报告当验收闸,等于给自动化加了一道独立的复核——生成靠脚本,把关靠报告,两边对上了再提交给搜索引擎,心里才踏实。一句话,能自动生成不等于能盲目信任,脚本负责快,报告负责对。
这套“让AI写脚本”的思路,能迁移到哪些活上?
把hreflang sitemap这个具体例子放下,你会发现真正学到的不是一段代码,而是一套可复用的工作方式:凡是规整、重复、规则明确、数据量大的技术SEO活,都可以照这个套路交给AI写脚本来批量处理。
能往上套的场景不少——批量给上千个URL生成结构化数据、从爬取结果里批量提取和比对meta信息、把一堆旧链接按规则批量生成重定向映射、定期对比两次爬取找出新增的死链。这些活的共同点都是:人来做又烦又容易错,逻辑却清晰到能讲明白。
拿重定向映射举个例子就很直观。站点改版、换URL结构时,往往有几千条旧链接要一一映射到新地址,人工在表格里对,又慢又容易错配。但这件事的规则其实清楚得很——按某种路径模式、某个ID字段去匹配新旧。把新旧两份URL清单交给脚本,再把匹配规则跟AI讲明白,几分钟就能产出一份完整的301映射表,剩下的只是抽查几条确认逻辑没跑偏。和hreflang sitemap是同一个套路:规整、重复、规则可讲,就交给脚本。
关键的迁移能力有两条。一是判断哪些活适合自动化——前面那几个特征就是判据,越规整重复越值得。二是会指挥AI——先聊架构和边界、把数据洗干净、用具体例子迭代、拿独立工具反向验收,这套心法换个场景照样管用。换句话说,这一篇你真正该带走的,是把SEO里那些重复脏活,一件件变成“可以让AI帮我写个脚本搞定”的判断力,而hreflang sitemap不过是个练手的好起点。
一个出海多语言站,是怎么把这件事跑顺的?
说个接触过的真实场景。一家做出海家居的独立站,铺了英语(分美、英、澳三个地区)加德语、法语,前后五六个版本,页面好几千。早先他们靠多语言插件自动生成hreflang,结果搜索后台长期挂着一堆“缺失回指”“指向非索引页”的告警,没人能彻底理清。
后来他们换了打法。先用爬虫把全站抓一轮导出CSV,在表格里按状态码和可索引性筛掉了一两千行死链、跳转和重复变体;再用Colab开个笔记本,跟AI把需求——怎么从URL路径里识别语言地区、孤页怎么处理、x-default指向国际版首页、超5万条要分片——一条条聊清楚,让它写脚本。第一版漏识别了几类带地区子目录的URL,他们拿具体例子来回纠了四五轮才对。
脚本定稿后,生成的sitemap先用爬虫的hreflang报告过了一遍,把残留的几个回指问题补干净,才提交上去。最大的变化不是当时那一次生成,而是之后——每次站点结构有变动,他们只要重新爬一轮、洗一遍、把脚本重跑一次,几分钟就产出一份全新的、两两对齐的sitemap,再不用一个个页面去抠标签。
一件原本要专人长期盯着、还总也理不干净的脏活,就这么被压成了一条“爬取、清洗、运行”的固定流程。半年之后回头看,搜索后台那些常年清不掉的hreflang告警基本归零,几个地区版本的收录也跟着稳了下来——省下来的人力和稳住的可见性,才是这套脚本真正的回报。
落地这套流程,最容易踩的几个坑是什么?
第一个坑,是数据没洗就喂脚本。把爬虫导出的原始清单直接拿去生成,里头混着404、301、noindex,产出的sitemap自带一身病。清洗那一步是地基,省不得。
第二个坑,是跟AI上来就要成品。不先聊架构和边界情况,第一版必然南辕北辙,然后陷进无尽的改bug循环。先谈清楚再动手,这条值得反复强调。第三个坑,是反馈太笼统——“不对再改改”推不动AI,得用具体的失败案例去喂。第四个坑,是脚本一跑通就上线,跳过了用爬虫报告反向验收这一关,结果隐形的hreflang错误带病上了生产。
还有一个容易被忽略的坑:把脚本当一次性的。真正的价值在于它能反复跑——站点一变就重新生成,所以脚本和那份Colab笔记本要留好、要写清楚参数,让它沉淀成团队能复用的工具。保哥的建议是,第一次跑通后顺手把整条流程记成一份简短的操作手册,把参数、清洗规则、运行步骤都写下来,下次换个人、隔几个月再用,照着走就行,别让这套本事只活在你一个人的记忆里。
常见问题解答
我们站就两三种语言,也值得这么折腾去写脚本吗?
多半不值得,这套打法是为规模准备的。两三种语言、页面也不多的时候,hreflang直接写在head标签里、或者用多语言插件生成,完全够用,专门去搭脚本反而是杀鸡用牛刀。真正的分水岭,是当你的语言地区版本一多、页面数量上了几千,手和插件开始频繁出错、搜索后台的hreflang告警清不干净的时候——那才是把它收进sitemap、用脚本批量生成的最佳时机。先用最简单的方式撑着,撑不住了再升级,是更划算的节奏。
我完全不会写代码,真能靠AI把这个脚本搞出来吗?
能,而且这正是这套方法的前提——它假设你不会写代码。你要做的不是写代码,而是当那个提需求、验结果的人:把输入数据长什么样、语言地区怎么识别、边界情况怎么处理讲清楚,让AI去写;它写出来你跑一遍,哪里不对就拿具体例子告诉它,让它改。整个过程你需要懂的是hreflang的规则和你站点的结构,这些恰恰是你作为SEO本来就懂的。配上Colab这种零安装的环境,连搭环境这道最劝退的坎也绕过去了。
为什么一定要把404和301这些先从清单里删掉?
因为hreflang的本意,是告诉搜索引擎“这几个能正常访问、能被索引的页面,是同一内容的不同语言地区版本”。如果你让hreflang指向一个404死链或者一个会301跳走的旧地址,等于在告诉它一个自相矛盾的信号:这是个有效的语言版本,但它其实不该被索引。这种矛盾会拖累整组语言关系的可信度,甚至让搜索引擎干脆忽略掉这组标注。所以只有状态200、能被索引、是canonical的页面才配进hreflang,清洗这一步删的就是这些“不配进来”的行。
为什么推荐Google Colab,本地装个Python不行吗?
本地装当然也行,Colab解决的是“门槛”和“劝退率”的问题。对会折腾环境的人,本地跑没任何障碍;但对大多数做内容、做运营出身的SEO,装Python、管依赖、处理报错,这一串足以让人在动手之前就放弃。Colab是个跑在浏览器里、免费、零安装的Python环境,常用库大多预装好,打开网页就能跑,等于把那道劝退的门槛直接抹平了。它还有个附带好处:环境统一,你和别人复现同一个脚本时不会因为版本不同各跑各的,分享给非技术同事也能直接用。
用插件自动生成hreflang,和用脚本生成sitemap,到底差在哪?
差在“可控”和“可验”。多语言插件是个黑盒,它怎么判断语言关系、遇到分页和参数页怎么处理,你很难干预,碰到它处理不好的边界情况,你往往只能干瞪眼。而自己用脚本生成,逻辑是你和AI一条条谈定的,孤页怎么办、怎么去重、x-default指哪,全都明明白白写在脚本里,出问题能精准定位、能改。再加上生成完用爬虫报告独立验收一遍,整个过程从黑盒变成了透明可控的流程。规模小的时候插件够用,规模一大、插件频繁翻车时,脚本这条路的可控性优势就体现出来了。
脚本生成的sitemap,多久要重新跑一次?
没有固定周期,触发点是“站点结构有没有变”。只要发生了会影响URL或语言关系的变动——上新页、删旧页、改URL结构、加一个新的语言地区版本——就该重新爬一轮、洗一遍数据、把脚本重跑一次,产出一份新的sitemap。这正是脚本化最大的好处:重新生成的成本被压到了几分钟,不再是过去那种要逐页抠标签的苦差。对页面更新频繁的站,可以干脆把这条“爬取、清洗、生成”的流程接进定时任务里,让它定期自动跑,省得靠人记着。
权威参考资料
- Google:向Google说明页面的本地化版本 —— 官方对hreflang三种放置方式、双向回指、x-default与语言地区代码规则的权威说明,是写脚本前定义产物结构的依据。
- Google:构建和提交sitemap —— 单文件5万条URL、50MB上限与sitemap索引文件的官方规则,决定大站脚本要不要做分片。
- Screaming Frog:如何审计与测试hreflang —— 缺失回指、非canonical、代码错误等一整组hreflang报告,是给脚本输出做反向验收的工具清单。
本文标题:《多语言大站hreflang手写维护不动?用AI写脚本从爬虫结果自动生成sitemap》
本文链接:https://zhangwenbao.com/ai-script-hreflang-xml-sitemap-multilingual.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0