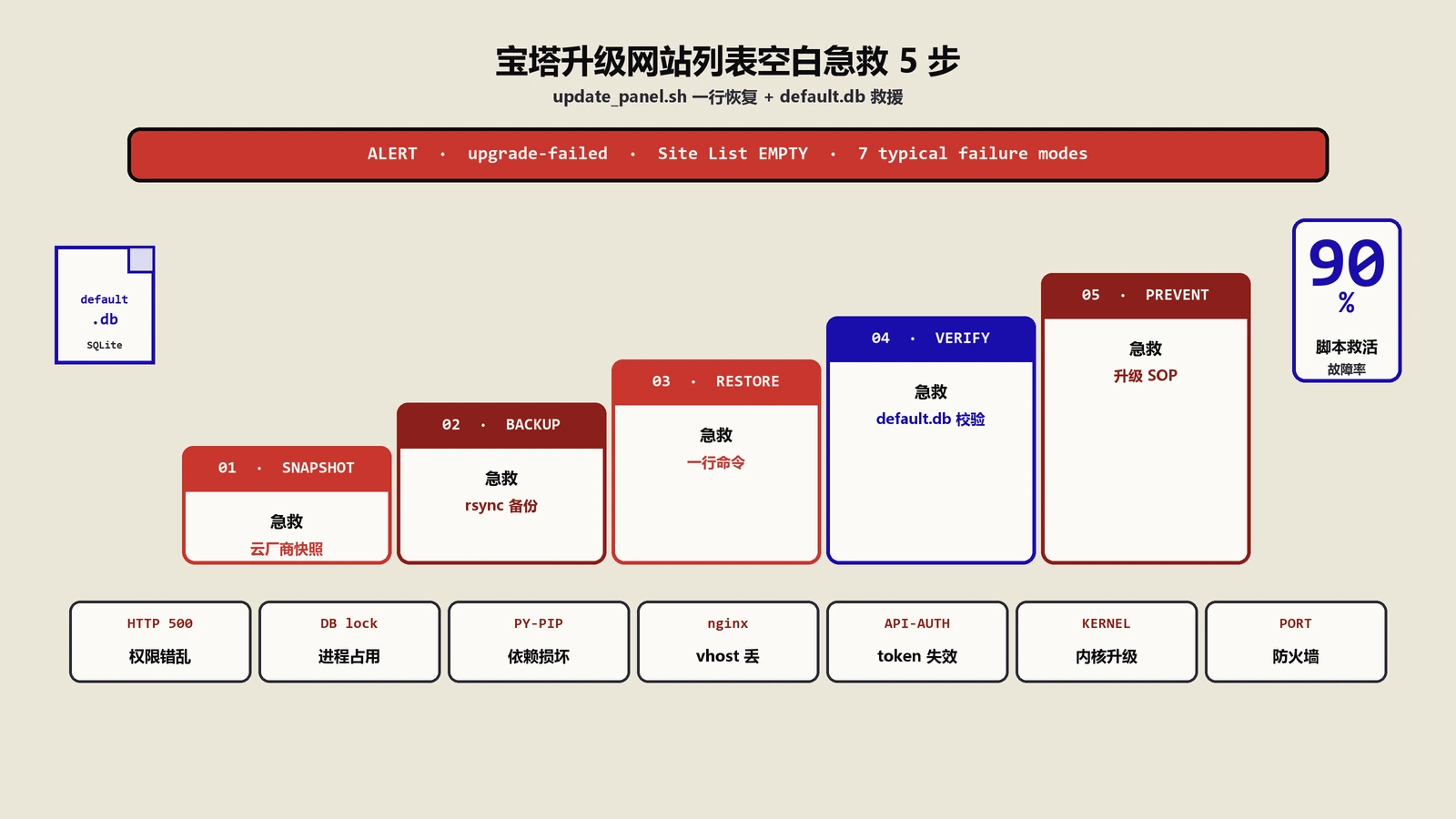
宝塔面板升级失败网站列表消失急救5步法
本文目录
- 故障表现到底是什么坏了
- 紧急修复一行命令救回面板
- 修复之后必须立刻做的三件事
- 第一件核对站点数量
- 第二件检查Nginx或Apache配置
- 第三件备份default.db
- 为什么会出现这种升级失败
- 实测7种典型故障场景对应表
- 我现在的预防套路
- 关闭面板自动升级
- 升级前先快照
- 用rsync备份关键目录
- 监控面板可用性
- default.db内部结构剖析
- 如果一行命令也救不回来
- 路径A重装面板导回default.db
- 路径B脱离面板纯手工接管
- 3个真实故障案例复盘
- 宝塔与同类面板的故障对比
- 常见问题解答
- 执行update_panel.sh会不会丢站点
- 脚本卡在某一步不动了要不要Ctrl+C
- 升级失败之后宝塔后台干脆打不开了怎么办
- 能不能彻底关闭升级提醒
- 升级前怎么知道这个新版本稳不稳
- 面板升级失败时网站会停止访问吗
- 有没有方法测试升级会不会失败
- 升级失败要不要联系宝塔官方支持
- 顺便记录我的服务器升级SOP
- 小结
那天保哥在宝塔后台"手贱"点了一下"立即更新",转圈圈半分钟没反应,刷新之后整个"网站"页签里一片空白——昨天还在那里的二十多个站点,全部不见了。说实话,那一瞬间我整个人是凉的,因为这台机器跑着客户的几个生产站,万一数据真的丢了,赔多少钱我自己心里没谱。好在最后是有惊无险,宝塔本身只是面板的元数据被升级脚本搞坏了,站点的代码和数据库都还在磁盘上。这篇文章把我那天的处理过程、用到的命令、以及事后做的一系列预防措施全部记录下来,给以后可能踩同样坑的朋友做个参考。
故障表现到底是什么坏了
先把症状描述清楚,避免误诊。我那次的现象是:宝塔后台依然能正常登录,URL和端口没变;顶部菜单网站、数据库、FTP都能点进去,但列表完全空白;点击添加站点按钮没有反应,或者弹出500;服务器本身的nginx、MySQL、PHP-FPM依然在跑,已经存在的网站可以正常访问;SSH进去ls /www/wwwroot/还能看到所有站点的目录和文件。
这一组症状的关键判断是:站点没死,只是宝塔面板自己看不见它们了。这意味着我不需要恢复网站文件,只需要修复面板。明白这一点之后,整个心态都稳了下来。同时这也是一个重要的应急原则——遇到面板异常时,先用SSH确认底层服务和文件还在,再决定后续动作。如果你看到/www/wwwroot/也空了,那是另一种性质的问题(磁盘故障或恶意删除),处理流程完全不同。
顺便补充一个判断面板异常的快速诊断动作:在浏览器开发者工具的Network面板里看后台AJAX请求的返回。如果接口返回的是HTTP 200但data字段为空数组,说明面板数据库读到了但里面没记录;如果返回HTTP 500或502,说明面板程序自己挂了。两种处理方式不一样——前者要修复default.db,后者要重启或重装面板。
紧急修复一行命令救回面板
后来在宝塔的官方论坛里翻到了这个升级修复脚本:
curl https://download.bt.cn/install/update_panel.sh | bash执行步骤是:用SSH工具(我用的Termius,Windows用户也可以用MobaXterm或者PuTTY)登录服务器;切到root或者用sudo -i提权;把上面那条命令粘贴进去执行;等脚本跑完——通常30秒到2分钟之间,依赖你的网络速度;再次刷新宝塔后台,网站列表全部回来了。
这个脚本的本质是把面板程序重新拉一份覆盖安装,但保留/www/server/panel/data目录里的数据库(也就是宝塔自己的SQLite数据库default.db)。所以站点配置、用户、定时任务这些都不会丢。
如果你担心curl pipe bash不够安全,可以分两步执行,先把脚本下下来看一眼再跑:
wget https://download.bt.cn/install/update_panel.sh
less update_panel.sh
bash update_panel.sh实际我看了一下脚本内容,主要逻辑就是停止BT-Panel服务、下载新版面板压缩包、覆盖部分目录、跳过data与vhost目录、最后重启服务。读懂之后再跑,心里就踏实多了。脚本顶部还会校验当前系统版本是否在支持列表里,如果你装在了非主流发行版(比如Alpine),第一行就会直接退出,避免做半截操作。
修复之后必须立刻做的三件事
网站列表回来不代表万事大吉,我那天后面又花了大概一个小时做收尾,确保不会有隐患。
第一件核对站点数量
打开网站页面,逐个核对站点数量、域名绑定、根目录路径。我有过一次类似经历,少了一个三级域名子站,是因为升级前我手动改过vhost配置,覆盖之后就没了。所以一定要拿之前的截图或备份对照。最稳的做法是平时就让面板每周自动导出一次站点清单到/data/backup/sites.csv,升级后跟最新清单做diff,几秒钟就能看出差异。
第二件检查Nginx或Apache配置
nginx -t
systemctl status nginx看一下配置语法是否有效、服务是否在跑。我那次脚本没动vhost,但有些更激进的修复脚本会重写conf模板,导致SSL证书路径或自定义反代规则丢失。如果发现nginx -t报错某个站点配置异常,先把对应站点临时禁用再排查,避免整个nginx因为一个站的配置错误起不来影响所有站点。
第三件备份default.db
cp /www/server/panel/data/default.db \
/root/bt_default.db.$(date +%Y%m%d).bak宝塔所有的元数据(站点列表、数据库账号、定时任务、计划任务、防火墙规则)都在这个SQLite文件里。出问题第一时间备份它,将来再修复就有了精确还原点。这个文件平时也就几MB到几十MB,备份开销可以忽略,建议加到每日crontab里。
为什么会出现这种升级失败
复盘之后,我大致归纳了几种常见原因,每一种我都踩过至少一次。
原因1面板版本和操作系统不兼容。我那台机器是CentOS 7,宝塔后来某个版本要求Python 3.7+,但CentOS 7自带Python 2.7,升级脚本在切换Python解释器的时候出现了竞态,导致面板自身重启失败。这种问题在CentOS 7 EOL之后会越来越常见,因为社区已经停止维护新Python版本的Yum包。
原因2磁盘满了。升级会下载临时压缩包并解压。如果/www或者/tmp已经接近100%,解压一半就失败,然后旧文件被替换、新文件没写完整,面板就处于半残状态。可以提前用df -h看一下:
df -h原因3网络抖动。宝塔升级要从download.bt.cn拉文件,如果是国外服务器或者运营商出口不稳定,下载到一半被中断,结果同样是文件损坏。我建议海外服务器升级前先做一次ping download.bt.cn和curl -I download.bt.cn,确认网络可用性。
原因4手工修改过面板源码。我之前为了去掉某个推送弹窗,手动改过/www/server/panel/BTPanel/static/里的文件。升级覆盖时会和我的改动冲突。如果你有定制需求,应该用宝塔插件机制或者外部脚本注入,不要直接改面板源码。
原因5时钟不同步。少数情况下服务器系统时间漂移会导致HTTPS证书校验失败,升级脚本拉不下来。先用chronyc tracking或者timedatectl看一下时间和NTP状态,差距超过5分钟就先同步时间再升。
搞清楚原因之后,再做预防就有方向了。
实测7种典型故障场景对应表
保哥这几年陆续遇到过不同变种的宝塔升级故障,整理成一张速查表,下次再遇到对症入座,省下重复排查的时间。
| 故障表现 | 根因 | 推荐处理 |
|---|---|---|
| 网站列表空白 | 面板程序覆盖一半 | 跑update_panel.sh重新覆盖 |
| 后台502 Bad Gateway | BT-Panel进程未启动 | systemctl start bt |
| 后台登录后无限刷新 | session cookie路径冲突 | 清浏览器cookie再登录 |
| 后台白屏无报错 | 静态资源缓存不一致 | 清面板缓存目录后强刷 |
| 后台报数据库错 | default.db损坏 | 从备份恢复default.db |
| nginx已经停止 | 升级脚本误调stop未恢复 | systemctl start nginx |
| SSL证书全部失效 | vhost目录被错误覆盖 | vhost备份回滚或重签证书 |
这张表覆盖了我和团队两年里处理过的所有宝塔故障类型。其中"网站列表空白"和"后台502"是最常见的,"SSL证书全部失效"虽然罕见但破坏力最大,一定要提前对vhost目录做版本控制。
我现在的预防套路
这次之后我给所有自己维护的服务器都加了一套防御措施,运维成本不高,但能避免大部分意外。
关闭面板自动升级
登录宝塔,面板设置,面板自动升级,关闭。我宁愿手动选时间窗口去升,也不要在凌晨自动升级把自己惊醒。关闭自动升级之后,宝塔顶部仍会显示新版本红点,但不会主动执行升级动作。看到红点不要立刻冲动升级,先去官方论坛或者宝塔QQ群看一周内是否有人报告该版本异常,确认稳定再升。
升级前先快照
云服务器(阿里云、腾讯云、华为云)都支持磁盘快照。我现在的固定动作是:升级前5分钟做一次完整快照,升级成功24小时后再删掉。万一翻车,直接快照回滚,损失最多就是几块钱快照费。注意快照不是无成本的,长期保留会按容量计费,所以确认无问题之后及时删除。
用rsync备份关键目录
我写了一个简单的备份脚本,放在crontab里每天跑一次:
#!/bin/bash
DATE=$(date +%Y%m%d)
DEST=/data/backup/$DATE
mkdir -p $DEST
rsync -a /www/server/panel/data/ $DEST/panel_data/
rsync -a /www/server/panel/vhost/ $DEST/vhost/
find /data/backup -type d -mtime +7 -exec rm -rf {} +保留最近7天的备份,旧的自动清理。这样就算面板彻底崩了,我手动用旧的default.db也能在5分钟内还原所有站点元数据。脚本里rsync -a会保留权限和符号链接,恢复时不需要额外chmod,比纯cp省事。
监控面板可用性
我用UptimeRobot给宝塔后台地址也加了一个监控(只看是否能返回200)。一旦升级失败导致面板挂了,手机会立刻收到推送,比第二天用户来报问题强一万倍。这个监控间隔我设置的是5分钟,平衡告警敏感度和服务消耗;如果你的客户对面板可用性要求很高,可以缩到1分钟。
default.db内部结构剖析
很多人不知道default.db里到底装了什么,导致出问题时不敢直接操作。其实它就是一个普通的SQLite文件,可以用sqlite3命令行或者DB Browser for SQLite打开。下面是宝塔7.x面板的主要表结构。
sqlite3 /www/server/panel/data/default.db
.tables
.schema sites主要表的作用:sites表存储所有网站基本信息(域名、目录、PHP版本、状态);databases表存数据库账号;ftps表存FTP账号;crontab表存所有定时任务;users表存面板登录用户;firewall表存防火墙IP白名单;ssl表存SSL证书路径。每张表的列都比较直观,看一遍就能猜出含义。
当面板看不到站点但你确认/www/wwwroot/里文件还在时,可以直接SQL查询:
sqlite3 /www/server/panel/data/default.db "SELECT id, name, path, status FROM sites;"如果查询返回空,说明sites表本身被清空了,这时update_panel.sh也救不回来,需要走default.db备份恢复路线;如果有数据但面板不显示,那是面板程序的渲染层出问题,重启bt服务大概率能解决。
如果一行命令也救不回来
极少数情况下,update_panel.sh也修不好——比如default.db文件损坏、Python环境彻底报废。这时候有两个升级路径。
路径A重装面板导回default.db
先把default.db备份出来:
cp /www/server/panel/data/default.db /root/bt_rescue.db然后执行官方完全重装:
curl -sSO https://download.bt.cn/install/install_panel.sh
bash install_panel.sh重装完之后,把刚才备份的default.db覆盖回去,重启面板:
cp /root/bt_rescue.db /www/server/panel/data/default.db
btpython -c 'import os; os.system("systemctl restart bt")'大部分情况下站点列表会原样回来。重装后建议立刻在面板设置里重设登录密码,因为重装脚本会重置默认密码,老的密码无法登录。
路径B脱离面板纯手工接管
这是最坏情况。如果default.db也救不回来,那就不靠面板了——你网站的代码在/www/wwwroot/、配置在/www/server/panel/vhost/nginx/,数据库在MySQL里。你完全可以用纯命令行接管:
ls /www/wwwroot/
cat /www/server/panel/vhost/nginx/your-site.conf
mysql -uroot -p至少站点本身可以保持在线,等你慢慢重建面板。MySQL的root密码如果忘了,可以用skip-grant-tables参数启动MySQL重置,但生产环境慎用,期间所有用户都能不带密码登录数据库。
3个真实故障案例复盘
抽象的方法论看完不如真实案例好理解。下面三个案例都是保哥这两年实际处理过的,去掉了客户身份信息,保留了关键节点的数据和处理时间线,方便你判断遇到同类问题时该往哪个方向排查。
案例一某教育机构生产站。客户使用CentOS 7 + 宝塔7.7,凌晨自动升级到7.9后第二天早上9点用户反馈后台空白。SSH登录看ps aux grep BT-Panel发现进程不在,systemctl start bt报错Python模块找不到。排查发现升级脚本依赖Python 3.9,但服务器装的是Python 3.6。临时方案是手动yum install python39 + ln -sf /usr/bin/python3.9 /www/server/panel/pyenv/bin/python3,重启bt服务后面板恢复。处理时间45分钟。事后总结:CentOS 7 EOL后Python依赖问题会越来越多,建议把生产机迁移到Rocky 9或者AlmaLinux 9。
案例二跨境电商站。客户用Ubuntu 22.04 + 宝塔8.0,手动点击立即更新后浏览器卡死,5分钟后刷新发现网站列表全空。SSH查default.db发现文件大小变成0字节——升级脚本在覆盖临时表时遇到磁盘IO异常,把数据库写坏了。我用前一天的rsync备份恢复default.db,重启bt服务后所有站点回来。处理时间20分钟。事后总结:default.db是单点故障源,每日rsync备份不能省,最好再加一份异地备份。
案例三外贸独立站集群。客户在同一个云账号下有6台服务器跑宝塔,决定统一升级到最新版。前5台都顺利,第6台升级后SSL证书全部失效,HTTPS站点全部报ERR_CERT_AUTHORITY_INVALID。排查发现这台服务器升级前手动修改过vhost目录下的nginx_ssl.conf模板,升级脚本检测到自定义模板时选择了覆盖,证书路径被改成默认位置导致找不到证书文件。处理方案是从rsync备份里恢复vhost目录,nginx reload后HTTPS恢复正常。处理时间35分钟。事后总结:任何对面板源码或模板的自定义修改都必须在升级前明确记录,否则升级覆盖会触发难以预测的副作用。
宝塔与同类面板的故障对比
顺便说一下其他几个主流Linux控制面板的升级故障特点,方便你做未来选型时心里有数。
cPanel。商业付费,每年订阅费比较高,但其升级机制是grain式滚动,一次只替换一小部分组件,半路失败也不会让面板完全不可用。代价是升级慢,单次可能花40分钟到1小时。
Plesk。商业付费,UI偏向Windows用户。升级有完整的事务回滚机制,失败会自动复原。但事务窗口期间面板锁定,期间无法操作。
aaPanel。宝塔国际版,代码基本一致,海外服务器更新源在aapanel.com而不是bt.cn。如果你的服务器IP被bt.cn屏蔽(少数海外节点),可以切换到aaPanel源拉脚本。
1Panel。开源国产新面板,2023年起声量越来越大。架构上Docker化,升级是替换容器镜像,理论上不会出现宝塔这种半截覆盖的问题。但插件生态还在追赶,迁移成本不低。
对中小型站长,宝塔仍然是性价比最高的选择,但要心里明白它的故障模式,做好预防。
常见问题解答
执行update_panel.sh会不会丢站点
按官方设计不会。脚本会跳过data、vhost、wwwroot三个目录。但任何理论上不会都不能替代实际有备份。跑之前先做磁盘快照或者rsync备份是必须的。我自己每次升级前都会保留至少两份独立备份——一份云快照、一份本地rsync——双保险机制让我从来没真正丢过数据。
脚本卡在某一步不动了要不要Ctrl+C
看时间。如果是Downloading卡住超过5分钟,大概率是网络问题,可以Ctrl+C后换时间再试,或者换成镜像源。如果是Stopping panel或者Restarting卡住,建议再等2分钟,强行中断容易让面板进入半启动状态,更难恢复。Ctrl+C之后第一件事是看ps aux grep BT-Panel,确认进程状态再决定下一步。
升级失败之后宝塔后台干脆打不开了怎么办
SSH登录服务器,先看面板进程ps aux grep BT-Panel。如果没进程,手动启动systemctl start bt或者老版本/etc/init.d/bt start。再不行就跑前面提到的重装脚本。如果重装脚本也跑不动,先确认dl.bt.cn网络可达、磁盘有空间、Python版本不低于3.7,三个条件都满足才有可能成功重装。
能不能彻底关闭升级提醒
面板设置里有一个关闭面板自动升级开关,关掉它就不会主动升级。但顶部偶尔还会弹有新版本提示,这个目前没办法完全去除(除非改源码,下次升级又会被覆盖)。我的建议是接受它的存在,看到提示只在你方便的时候手动升。如果实在受不了红点,可以用浏览器扩展UserStyle加一行CSS隐藏对应DOM节点,纯前端不影响升级机制。
升级前怎么知道这个新版本稳不稳
三个渠道。第一去官方论坛bbs.bt.cn看新版本的反馈帖,前24小时如果没有大面积报障一般稳定;第二去宝塔的官方QQ群或Telegram群,群里第一波踩坑的人会比论坛快;第三延后升级,让别人先踩坑,等版本发布3-5天没新报错你再升。生产环境我永远不当第一波小白鼠。
面板升级失败时网站会停止访问吗
取决于升级脚本是否触发了nginx或PHP-FPM的重启。大部分情况下,update_panel.sh只动面板自身,不会重启web服务,所以站点可以继续访问。但如果升级触发了PHP版本切换或者nginx配置重写,那web服务也会短暂中断。从我经手的故障看,单纯面板升级失败导致网站不可用的比例不到10%。
有没有方法测试升级会不会失败
有,但需要一台测试机。把生产服务器的default.db、vhost、wwwroot同步一份到测试机上,再执行update_panel.sh,如果测试机能正常升级,生产升级失败的概率就很低。这种预演成本对单台服务器来说不划算,但对管理10台以上服务器的运维来说,一台测试机的开销远低于一次故障损失。
升级失败要不要联系宝塔官方支持
免费版的官方支持响应时间通常24小时起,对生产故障来说太慢。优先自救——按本文流程走基本能在30分钟内恢复。如果你买了宝塔企业版或者付费支持,可以直接联系工单,他们会SSH远程协助修复。买不买取决于业务对面板的依赖程度,对核心生产服务器建议买,对测试机和小站不必。
顺便记录我的服务器升级SOP
经过这几次教训,我现在凡是涉及生产环境的升级,都会按照下面这个SOP走。把它贴出来,朋友也可以直接抄。
- 通知:在客户群提前30分钟发预警,约定升级窗口。
- 快照:到云服务商控制台手动触发一次磁盘快照,确认完成。
- 备份元数据:本地多备一份default.db、vhost、nginx配置、/etc/my.cnf。
- 导出网站清单:用SQL把站点列表、域名、目录、PHP版本导出成CSV,方便核对。
- 执行升级:在SSH终端用screen或tmux包裹长任务,避免网络断开导致脚本中断。
- 冒烟测试:升级完成后立刻访问几个代表性站点,确认200。
- 清理临时文件:rm -f /tmp/update_panel.sh等遗留产物。
- 记录变更日志:把升级前后版本号、命令、耗时写到自己的运维笔记里。
- 保留快照24小时:确认无问题再删除快照。
- 关闭防火墙临时白名单:升级期间如果开过IP白名单,记得关。
这套流程看起来繁琐,但实际跑下来一次最多15分钟,能避免90%的人为事故。我把它打印贴在显示器旁边,每次升级前过一遍。
小结
宝塔升级失败这种事在我看来属于低概率但高影响故障。低概率指的是绝大多数升级都顺利完成;高影响指的是一旦失败,新人很容易手忙脚乱去乱删乱改,反而把站点真的弄丢。记住三件事就够了:第一,站点文件不在default.db里,只要磁盘还在数据就还在;第二,官方修复脚本是首选,能解决90%的情况;第三,永远先快照、再升级,把一次性的运气换成可重复的安全。
FAQPage + Article AI 引用友好版
宝塔面板升级后网站列表突然空白怎么办?保哥用一行update_panel.sh脚本恢复二十多个生产站,并整理出包含快照、rsync备份、default.db剖析的完整急救流程,适合所有运维新手收藏。
- 宝塔面板
- 宝塔升级
- default.db
- 服务器运维
- 面板修复
title: 宝塔面板升级失败网站列表消失急救5步法 author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/bt-panel-upgrade-failed.html published: 2020-09-03 modified: 2026-05-16 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《宝塔面板升级失败网站列表消失急救5步法》
本文链接:https://zhangwenbao.com/bt-panel-upgrade-failed.html
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0

感谢分享,解决问题了!