API测试工具怎么用?快速看清一个URL的状态码与响应头
本文目录
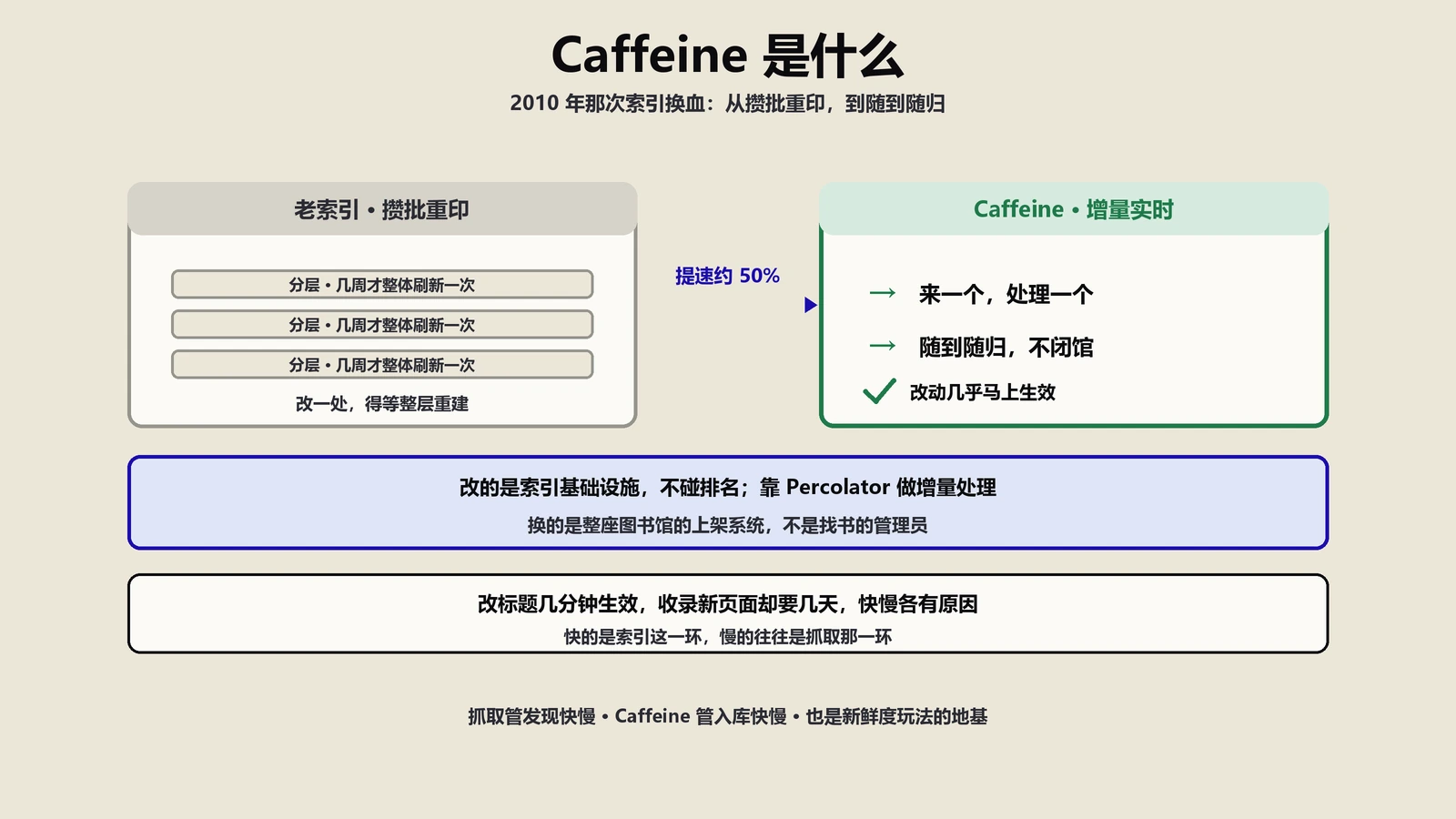
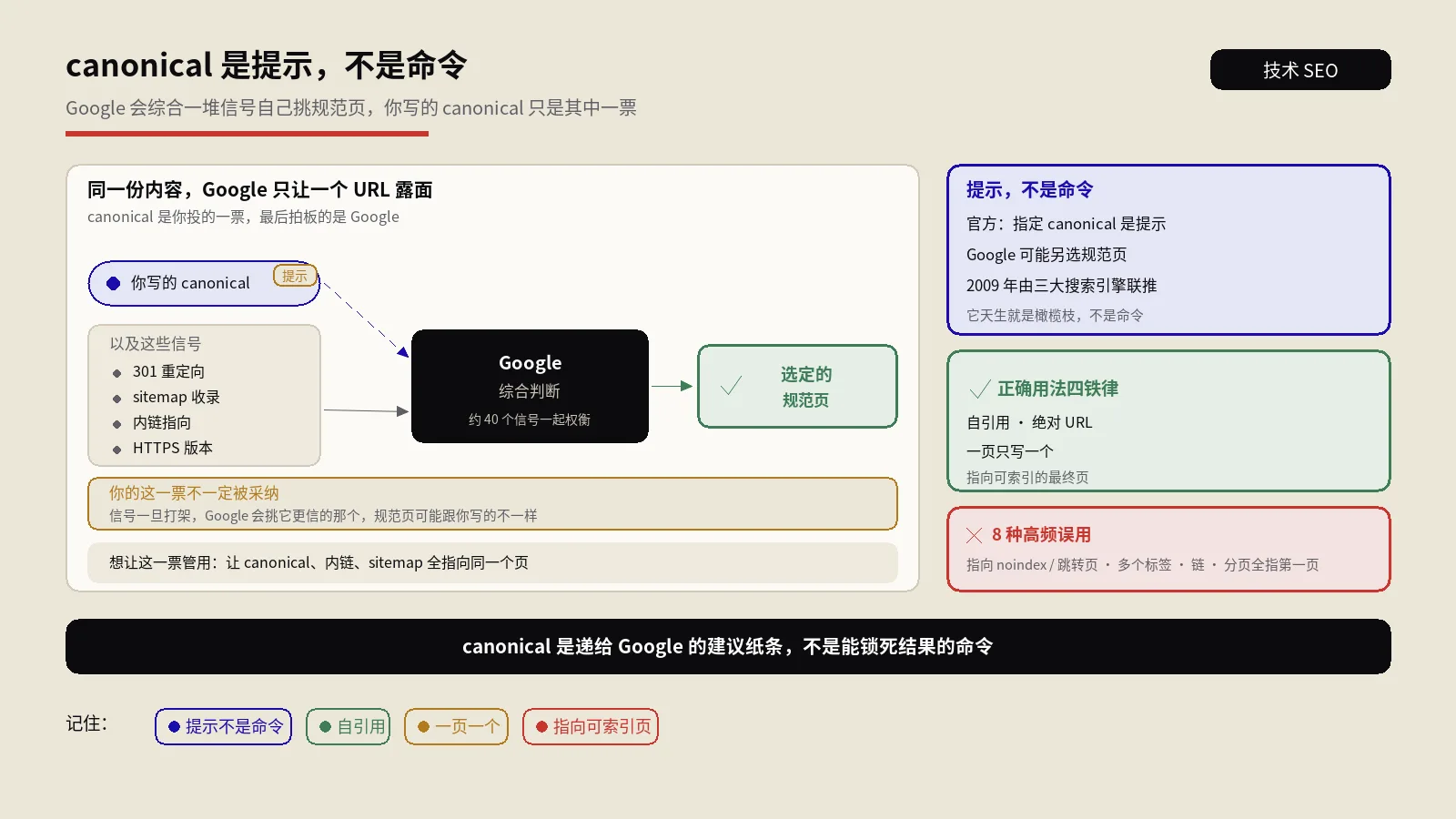
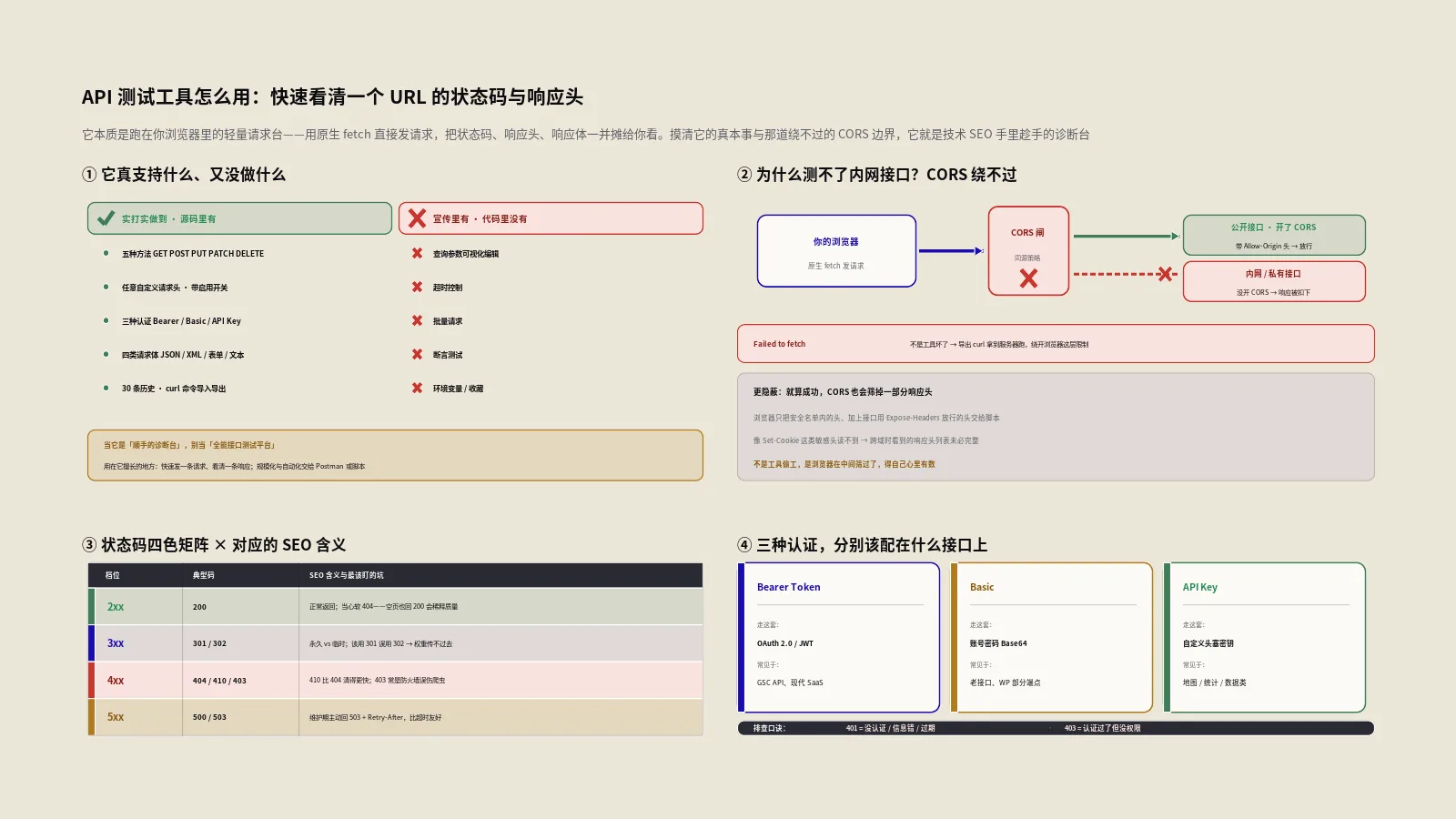
摘要:这个API测试工具,本质是一个跑在你浏览器里的轻量请求台:你填好网址、选好GET或POST这类方法、加上请求头和认证,它就用浏览器原生的fetch把请求直接发出去,再把回来的状态码、响应头、响应体、耗时和大小一并摊给你看。它最大的好处是请求不经过保哥笔记的服务器,你的Token和密码不会落到别人手里;它最大的死穴也在这——既然是浏览器发的请求,就被同源策略死死管着,目标接口只要没开CORS,浏览器就把响应拦下来,你那台公司内网的私有接口基本测不动。它真支持的是五种方法、任意自定义请求头、Bearer与Basic与API Key三种认证、四类请求体,外加三十条历史和一个curl命令的导入导出;它没做的是查询参数的可视化编辑、超时控制、批量请求、断言测试和环境变量,这些写在宣传里却没落到代码里。对做技术SEO的人来说,它真正值钱的地方不是当Postman使,而是拿来快速看一个URL的真实状态码与响应头——301到底跳没跳对、X-Robots-Tag有没有把页面悄悄设成noindex、Cache-Control和Last-Modified是怎么写的、headless接口吐回来的JSON-LD长什么样。把它的能耐和边界都摸清,它是个顺手的诊断台;把它当全能接口测试平台,迟早被CORS和那几个没实现的功能绊一跤。
做技术SEO,迟早要跟HTTP打交道。一个URL到底返回200还是404、一条301有没有跳到该去的地方、页面的响应头里藏没藏着一个把它设成noindex的指令、headless架构下那个内容接口吐回来的数据结构对不对——这些事,光在浏览器地址栏里敲一遍看不全,得有个能把请求和响应都摊开看的工具。
我们团队内部一直在用这款API测试工具做这类快速排查。它不复杂,就是个在线的HTTP请求台,但用顺了,很多过去要开命令行、装Postman才能干的活,点几下就出结果。这篇我们团队把它到底怎么实现的、真能干什么、哪几处宣传跟代码对不上、以及怎么把它接进日常的技术SEO排查流程,一次讲透——尤其是那条最容易让人栽跟头的CORS边界。
这个API测试工具,到底在怎么发请求?
先把它的底层机制说清楚,因为这一条直接决定了它能干什么、不能干什么。它是纯前端工具:你点发送,是你自己的浏览器用原生的fetch把请求直接发到目标接口,不经过保哥笔记这边的服务器中转。源码里那段PHP后端其实是个摆设,收到带action的POST只回一句client_side:true,并不真的替你转发任何请求。
这件事有两面。好的一面是隐私——你填进去的Bearer Token、API Key、Basic认证的账号密码,全程只在你浏览器和目标接口之间走,不会落到第三方服务器上。处理带密钥的接口时,这一点比那些后端代理式的在线工具让人安心得多,因为代理式的工具理论上能在服务器日志里看到你的凭据。
坏的一面,也是它最硬的天花板:既然请求是浏览器发的,就得守浏览器的规矩,而浏览器对跨域请求的规矩就是同源策略和CORS。MDN的Fetch API使用指南里讲得很清楚,fetch拿到响应后能读response.status、能遍历response.headers、能用response.text()取响应体——这套正是工具展示状态码、响应头、响应体的全部来源。但前提是浏览器愿意把响应交给脚本,而这个前提,跨域时不总是成立。
所以记住一句话:它是把浏览器的fetch能力包了个好用的界面,浏览器能做的它能做,浏览器做不了的它一样做不了。后面讲CORS那节,会把这条边界彻底掰开。
它真正支持哪些功能?一条条盘清楚
先看它实打实做到的部分,这些是源码里有完整实现、能稳定用的。把家底盘清,才知道哪些是真本事、哪些是吹的。
HTTP方法上,它给了五种:GET、POST、PUT、PATCH、DELETE。这五种覆盖了REST接口的绝大多数日常操作,增删改查都齐了。没给的是HEAD和OPTIONS——前者本来很适合只取响应头不取body的轻量探测,后者是CORS预检用的,这俩界面里压根没有,算是个小遗憾。
请求头是它做得最扎实的地方之一。你能加任意多个自定义头,每个头还配了个独立的启用开关——想临时关掉某个头试试效果,不用删,点一下开关就行,发请求时关掉的头会被自动跳过。默认它会带一个Content-Type: application/json,符合大多数接口的口味。
认证给了三种,覆盖面相当实用。一是Bearer Token,填进去它自动拼成Authorization: Bearer 你的token,OAuth 2.0和JWT都走这条;二是Basic认证,填账号密码,它用浏览器的btoa把账号:密码做Base64编码,拼成Authorization: Basic ...;三是API Key,头名和值都能自定义,默认给的是X-API-Key,你也能改成接口要求的任意头名。
请求体支持四类:JSON、XML、表单编码也就是application/x-www-form-urlencoded、以及纯文本。你选哪类,它发请求时就自动把对应的Content-Type补上,省得你手动写。要注意它明确不支持multipart/form-data,也就是说带文件上传的接口它测不了,这点工具自己也老实标了。
响应这边展示得挺全:顶部一条状态栏,把状态码按2xx、3xx、4xx、5xx分了颜色,旁边还跟着这次请求的耗时(毫秒级,用performance.now掐的)和响应体大小。下面分两块,一块是完整的响应头列表,一块是响应体——如果响应体是合法JSON,它会自动格式化成带缩进的样子,看起来舒服很多。
另外还有两个顺手的小功能。一是历史记录,最近三十条请求自动留着,每条都能一键回放重发,调接口时来回试特别省事——但它只存在内存里,刷新页面就清空,别指望它帮你长期留底。二是curl命令的导入导出,你能把一条curl命令粘进去让它解析成表单,也能把当前请求导出成curl命令丢给后端同事去复现问题。
为什么它测不了你自己的内网接口?CORS这道坎绕不过
这是整篇最该钉死的一条,也是新手最容易栽的地方。很多人兴冲冲拿它去测自家服务器上的私有接口,结果一发就是红字Failed to fetch,以为是工具坏了,其实是撞上了CORS。
前面说过,请求是浏览器发的。浏览器有一条铁律:一个网页上的脚本,想读另一个域名接口的响应,必须那个接口在响应头里明确点头同意,也就是带上Access-Control-Allow-Origin这个头。MDN的跨源资源共享CORS文档把这套机制讲得很细:没有这个头,或者这个头不允许当前来源,浏览器就算请求成功了,也会把响应数据扣下不给脚本,于是工具就只能报一句失败。
问题在于,绝大多数为前端服务的公共接口确实开了CORS,但企业内部接口、自家服务器上没特意配过CORS的接口、还有很多付费SEO工具的API,默认都是不开的。这意味着工具能流畅测的,主要是那些公开的、为浏览器调用设计的接口;你公司内网那套,它多半碰都碰不动。
还有个更隐蔽的副作用:就算请求成功了,CORS也会过滤掉一部分响应头。浏览器只把CORS安全名单里的头,加上接口主动用Access-Control-Expose-Headers放行的头,交给脚本读取。像Set-Cookie这类敏感头,脚本根本读不到。所以工具显示的响应头列表,跨域时未必完整——它不是工具偷工,是浏览器在中间筛过了。这点UI里没提示,得你自己心里有数。
那内网接口就没救了吗?也有变通:你可以在目标接口上临时加CORS响应头放行,测完再撤;或者干脆别用这个浏览器工具,改用命令行curl或Postman这类不受同源策略约束的客户端。工具的curl导出功能这时就派上用场——把请求在工具里搭好,导出成curl命令,拿到服务器上跑,绕开CORS。
用它做技术SEO,能查出哪些真问题?
抛开它当通用接口测试平台的短板,对做技术SEO的人来说,它真正的价值是当一个轻便的HTTP诊断台。下面这些,都是它的真本事撑得起的活。
头一件是看真实状态码。你把任意一个URL填进去发个GET,状态栏立刻告诉你它到底返回200、301、302、404、410还是503,还按颜色分了类。这比在浏览器里点开看靠谱——浏览器会把301悄悄跟到底,你看到的是终点页,根本不知道中间跳过几道;工具能让你看到这一跳本身的状态码和Location。
第二件是查响应头里的SEO指令,这是它最被低估的用法。最该盯的是X-Robots-Tag。谷歌官方的robots meta标签与X-Robots-Tag规范里说明,noindex这类抓取指令既能写在页面的meta标签里,也能写在HTTP响应头的X-Robots-Tag里——后者藏在响应头中,光看页面源码看不见,特别容易被漏掉。一个本该收录的页面突然掉出索引,十有八九要查这个头。
顺着这条线,响应头里还有一串值得看的:Cache-Control告诉你缓存策略,Last-Modified是页面最后修改时间影响重新抓取的判断,Content-Type里的charset能帮你定位乱码问题,Vary关系到移动端和桌面端是否被区别缓存。还有些站把规范链接写在响应头的Link里用rel=canonical表示,这种PDF、图片之类没法写meta的资源常这么干,也只有看响应头才查得到。
第三件是验headless接口的返回。现在不少站走前后端分离,内容从一个API接口取,页面再渲染。你可以拿工具直接GET那个接口,看它吐回来的JSON结构对不对、有没有把该有的字段都给齐、里头嵌的JSON-LD结构化数据长什么样——它会自动把JSON格式化,读起来比一坨压缩的字符串清楚得多。要是返回的JSON特别长、还想顺手做语法校验和深层折叠,可以把它拷进专门的JSON格式化工具里细看,那个工具在结构化数据调试上比这里的简易格式化更趁手。
第四件是测各家平台的开放API。谷歌搜索资源平台的API、PageSpeed Insights的API,这些都支持Bearer或API Key认证,工具三种认证都能配,在你正式写数据导出脚本之前,先用它发一发、看看返回结构,能省下不少调试时间。当然,前提还是这些接口对浏览器开了CORS。顺带一提,如果你测的是判断来访身份的接口、想伪造各种爬虫的User-Agent来看接口怎么响应,可以配合爬虫识别工具先搞清各家爬虫的UA特征,再到这里的请求头里填进去测。
怎么用它一步步排查一条重定向链?
重定向链是技术SEO里的高频活,也是工具最能体现价值的场景之一。要提醒一句:fetch默认会自动跟随重定向,所以你不能指望发一次就把整条链看全,得手动一跳一跳地查。下面是我们团队常走的步骤。
- 把要查的起始URL填进网址栏,方法选
GET,先发一次,记下状态栏给出的状态码。如果是200,说明这一跳就是终点,没有重定向,到此为止。 - 如果状态码是
301或302,到响应头列表里找Location这个头,它的值就是这一跳要去的下一个地址。把这个地址抄下来。 - 把网址栏换成刚抄下来的
Location地址,再发一次GET,看这一跳的状态码和新的Location。重复这个动作,一跳一跳往下走。 - 一直走到某一跳返回
200为止,这就是整条链的终点。把每一跳的地址和状态码连起来,整条重定向链的样子就完整了。 - 对照检查:链里有没有出现
302临时跳本该用301永久跳的、有没有跳了三四道以上的长链白白浪费抓取预算、终点是不是你真正想要的页面而不是首页或错误页。
这套手动逐跳的法子虽然笨,但胜在能看清每一跳的细节,比那些一把梭直接给你终点的工具更适合诊断问题。配合历史记录功能,每一跳都留了底,回头复盘整条链特别方便。要是你想成批地查一站之内的死链和重定向健康度,这个单条逐跳的工具就不够用了,可以换用专做这事的死链检测工具,两者一个管深查单点、一个管批量巡检,正好互补。
它有哪些说了却没真正做到的地方?
诚实是用工具的前提。这款工具有几处宣传跟代码对不上,或者看着能用实则有限制,得提前知道,免得真出事了还以为是自己操作错了。
第一处是查询参数。介绍里提到支持查询参数,但代码里根本没有可视化的参数编辑器。实际用的时候,你只能自己在网址里把?page=1&limit=10这种参数手写全,工具不帮你拆开编辑,也不替你做URL编码。参数里要是带了特殊字符,得自己先编码好,否则可能发错。
第二处是超时控制。界面里没有超时设置,代码里也没有任何超时逻辑。这意味着碰上一个响应特别慢或者干脆不回的接口,fetch会一直挂着等,等到浏览器自己的默认超时为止,中间还没法取消,你只能干等或者关页面。调接口时这点偶尔挺烦。
第三处是curl导入的解析。它用的是几条比较粗的正则去抠curl命令里的网址、方法、请求头和数据。命令简单时没问题,但碰上跨多行的、单双引号混用的、数据里带特殊字符的复杂命令,常常解析不全。更坑的是,就算没解析对,它照样弹一句导入成功,你不仔细核对填进去的字段,根本不知道它漏了。
第四处是所谓的JSON语法高亮。它确实会把合法JSON自动格式化成带缩进的样子,但并没有真正的语法着色——没有引入任何高亮库,就是个纯文本的缩进展示。而且只有合法JSON才格式化,XML、HTML或者格式不对的内容,它原样吐出来,不动。
第五处是一批压根没有的功能。环境变量、请求收藏、批量请求、测试断言、响应对比——这些Postman那类专业工具的标配,这款轻量工具一个都没有。它就是个发单条请求、看单条响应的台子,别拿企业级接口测试平台的标准去要求它。
把这些边界摆出来,不是说它不好用,而是让你用在它擅长的地方。它擅长的是快速发一条请求、看清一条响应;不擅长的是规模化、自动化、复杂场景的接口测试。各归各位,它就是个趁手的小工具。
它和Postman、命令行curl比,什么时候该用哪个?
工具没有最好的,只有最合适的。这三样各有各的地盘,搞清楚分工,才不会拿错家伙。
这款浏览器API测试工具,胜在轻和快——打开网页就能用,不装东西,认证和请求头点几下就配好,还自带历史回放。它最适合的场景是:临时测一个公开接口、快速看某个URL的状态码和响应头、在写脚本前先摸一摸某个开放API的返回结构。代价是受CORS约束,内网接口和不开CORS的接口它够不着。
Postman是专业选手,能测任何接口包括内网的,有环境变量、有测试集合、有断言、有团队协作。代价是重——要装客户端、有学习成本。当你的接口测试已经成了规模化、需要管理一堆用例和环境的活,Postman才值得搬出来。
命令行curl是终极底牌,不受任何同源策略约束,能在服务器上直接跑,脚本化能力最强。代价是没界面,全靠记参数,响应也是一坨纯文本得自己看。当你要在服务器上批量探测、或者要把请求写进自动化脚本时,curl是正解——而这款工具的curl导出功能,正好能帮你把界面里搭好的请求一键翻译成curl命令,接力交给服务器。
所以实战里它们常是接力关系:用这款工具在浏览器里把请求快速调通,导出成curl,拿到服务器上绕开CORS跑,需要规模化了再迁到Postman或脚本里。把这条链走顺,比纠结哪个工具最强有用得多。
把它接进日常技术SEO工作流,几个实战场景
讲点具体的。我们团队带过一个做出海智能健身器材的独立站客户,主营家用健身镜和智能划船机,站点走的是headless架构,内容从一个内容接口取了之后再渲染成页面。这套架构SEO上的坑特别多,工具在里头帮了不少忙。
第一个场景是排查页面莫名掉出索引。客户反馈几个产品页谷歌不收录了,页面源码里的robots meta看着是正常的index。我们团队拿工具GET了一下这几个页面,在响应头里逮到了一个X-Robots-Tag: noindex——原来是CDN层的一条规则误伤,把这批URL的响应头悄悄设了noindex,页面meta里看不出来。要不是工具能把响应头摊开看,这问题能查上半天。
第二个场景是验内容接口的返回。这个站的产品数据从一个JSON接口取,有阵子部分产品页的结构化数据出不来。我们团队直接拿工具GET那个内容接口,把返回的JSON格式化开一看,发现某些产品的JSON-LD字段是空的——是接口那头数据没补齐,不是渲染的问题。定位到根上,改起来就快了。
第三个场景是上线前的批量自查。每次大改版前,我们团队会用工具把站点的robots.txt、sitemap.xml这些关键资源URL逐个发一遍,确认都返回200、Content-Type对、内容没被CDN缓存成旧版。虽然它没有批量功能得一个个来,但配上历史记录,几个关键URL过一遍也就几分钟。
第四个场景是接平台API前的预演。这个客户要把谷歌搜索资源平台的数据导进自家看板,正式写导出脚本前,我们团队先用工具配好OAuth的Bearer Token,发了几个查询请求,把返回的数据结构、字段含义、分页方式都摸清了,脚本一次就写对,省去了在代码里反复试错的工夫。
这几个场景的共性是:它不替你做大规模的事,但在定位单点问题、验证单个返回、上线前点检这些活上,快且准。把它当成技术SEO工具箱里那把随手就能掏出来的小螺丝刀,而不是大型电动工具,定位就对了。接口这头摸清了,数据落库那头同样有讲究——批量改SEO字段、清理重复数据这类活,可以接着看配套的SQL语句生成工具那篇,一个管接口调试、一个管数据库批量操作,凑成开发者手里这套接口与数据的趁手二件套。
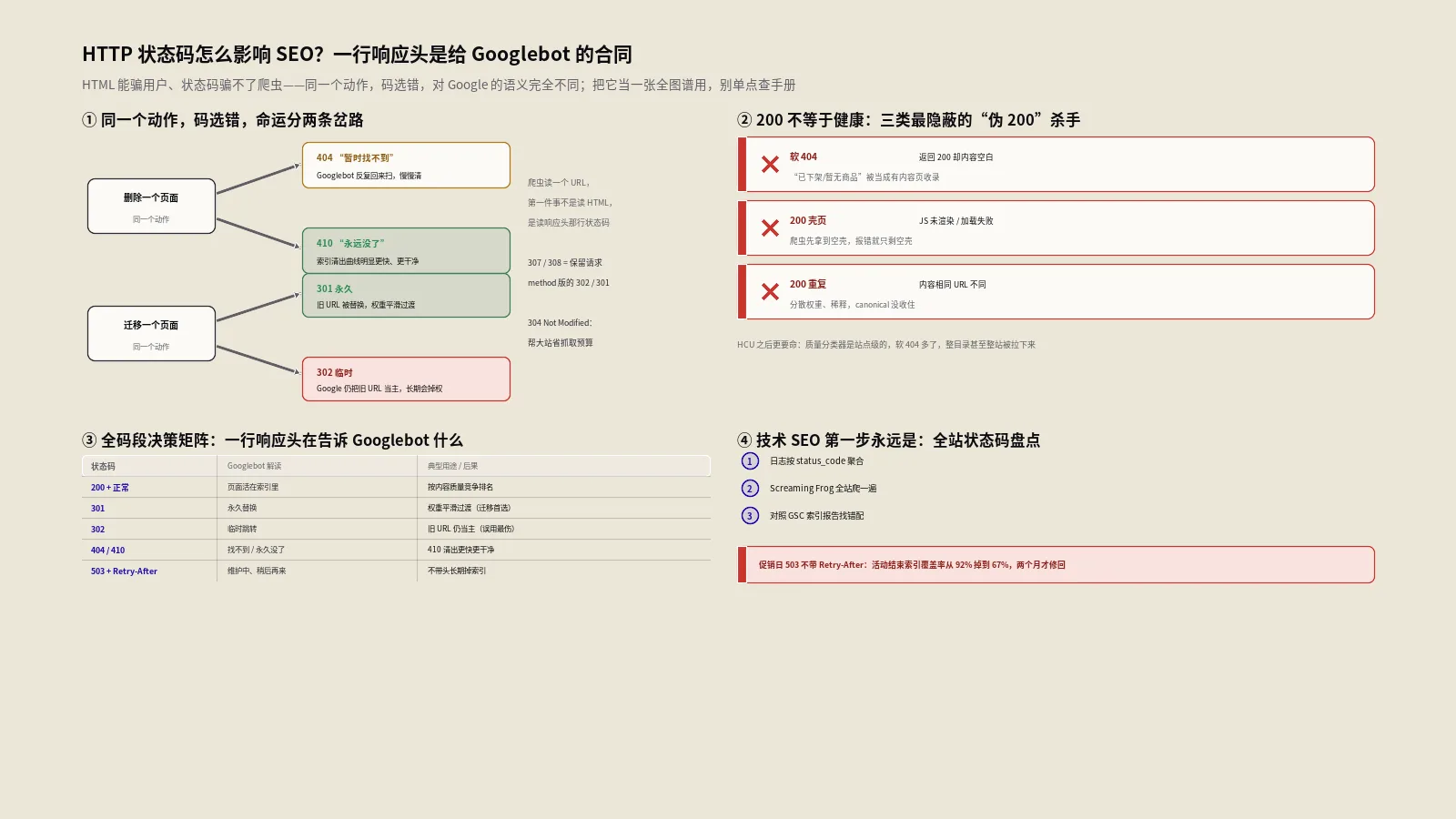
状态码分了颜色,每一类对应什么SEO含义?
工具把状态码按首位数字分成了四色,这套颜色背后,对应的正是技术SEO里几类截然不同的处境。把每一档的含义吃透,看到颜色就能条件反射出问题在哪。
2xx这一档是绿灯,最常见的是200,意思是页面正常返回、内容拿到了,搜索引擎可以正常抓取和考虑收录。但绿灯不等于万事大吉——有些站把不存在的页面也返回200配一个看着像样的错误页,这就是臭名昭著的软404,谷歌会把它当正常页收录,白白稀释站点质量。工具帮你确认的是状态码这一层,软404还得结合页面内容一起判断。
3xx这一档是重定向,核心是301和302。301是永久重定向,告诉搜索引擎这个地址永久搬家了,权重应当传递到新地址,做URL迁移、合并旧页时就该用它。302是临时重定向,意思是原地址还在、只是暂时跳走,搜索引擎倾向于保留原地址。最常见的事故就是该用301的地方误用了302,导致权重传不过去,工具能让你一眼看清这一跳到底是哪个码。
4xx这一档是客户端错误,主力是404和410。404表示页面找不到,可能是临时挂了也可能是真没了,搜索引擎会反复回来探几次再决定。410表示页面已永久删除、别再来了,态度比404决绝,搜索引擎清得更快。想让一批废弃页面尽快从索引里消失,返回410比404更利落,工具能帮你确认服务器到底回的是哪个。
还有个容易忽略的403,表示禁止访问。有时候你会发现谷歌抓不到某些页面,拿工具一测发现是403——可能是防火墙或者权限规则误伤了爬虫。这种问题在浏览器里你自己访问可能正常,因为你带着登录态,得用工具模拟干净的请求才暴露得出来。
5xx这一档是服务器错误,500是程序崩了,503是服务暂时不可用。503对SEO其实有正面用法:站点维护时主动返回503配上Retry-After头,等于礼貌地告诉搜索引擎我在维护、过会儿再来,比直接返回错误页或者超时要友好得多,能减少维护期被误判的损失。工具能帮你确认维护页返回的到底是不是503。
把这五档对应的SEO含义记牢,工具的那条彩色状态栏就从一个数字变成了一张诊断地图。看到红的知道是错误要查、看到黄的知道是重定向要看跳向哪、看到绿的还要多留个心眼防软404。这就是把工具用出门道和只会发请求看个数字的区别。
认证那三种方式,分别该用在什么接口上?
工具给的Bearer、Basic、API Key三种认证,不是随便选哪个都行,得跟接口要求的方式对上。搞清各自的适用场景,配认证时就不会瞎试。
Bearer Token是现在最主流的,OAuth 2.0和JWT都走这条。它的特征是接口要求你在Authorization头里带一个Bearer开头的令牌。谷歌搜索资源平台的API、各类现代SaaS的开放API,基本都是这一套。工具帮你把令牌自动拼成规范的格式,你只管把拿到的Token粘进去。要注意Token通常有有效期,过期了得重新获取,测的时候发现突然返回401,先想想是不是令牌过期了。
Basic认证是最老牌的,账号密码用Base64编码后放进Authorization头。它简单但安全性弱——Base64不是加密,是任何人都能解开的编码,所以Basic认证必须配HTTPS才算安全,裸HTTP下传等于明文。一些老接口、内部管理接口、WordPress的部分REST端点还在用它。工具帮你做编码,你填明文账号密码即可,但别在不安全的网络环境下测带真实凭据的Basic接口。
API Key方式最灵活,本质是往某个自定义头里塞一个密钥。不同接口要求的头名千差万别,有的叫X-API-Key,有的叫别的,工具允许你自定义头名和值,正好应对这种多样性。很多数据类、地图类、统计类的接口用这种方式。配的时候关键是把接口文档要求的头名抄对,头名错一个字符认证就过不了。
实战里有个排查技巧:认证失败时,返回的状态码能帮你定位。401通常是没认证或者认证信息错了,403通常是认证过了但没权限。看到401就去检查Token或账号密码对不对、有没有过期;看到403就去想是不是这个账号确实没有访问这个资源的权限,两者的排查方向完全不同。把状态码和认证方式结合着看,调接口的效率能高不少。
除了状态码和响应头,它还能帮你看清什么?
工具的价值不止在状态码和响应头,响应这一侧它还摊开了几样信息,用好了对诊断很有帮助。
头一样是响应耗时。状态栏里那个毫秒数,是这次请求从发出到收到完整响应的总时间。虽然它不是专业的性能测试,但拿来粗略感知一个接口或页面的响应快慢够用了。同一个接口连发几次,耗时忽高忽低,可能后端有性能抖动;某个接口稳定地慢,那它就是优化的候选。对在意爬虫抓取效率的站,接口响应慢会拖累抓取预算,这个数值能给你个直观的感受。
第二样是响应体大小。状态栏里的字节数告诉你这次拿回来多少数据。一个本该精简的API返回了远超预期的体积,可能是返回了冗余字段、或者没做分页一次吐了太多。对走headless的站,接口返回越臃肿,前端渲染和传输的负担越重,间接影响页面速度。这个数值能帮你揪出那些悄悄变胖的接口。
第三样是响应体本身的结构。它对合法JSON会自动格式化成带缩进的样子,你能清楚看到字段层级、有没有缺字段、值对不对。验接口契约、看返回数据结构、确认某个字段到底叫什么名字,这都比对着一坨压缩字符串瞎找强。配合前面说的JSON格式化工具做更深的校验,一套流程就顺了。
第四样是编码问题的定位。响应头里的Content-Type会标出charset,要是这个声明跟实际内容的编码对不上,页面就会乱码。碰上乱码问题,先用工具看响应头里声明的charset是什么、再看响应体实际显示成什么样,两边一对照,乱码的根源往往就浮出来了。这种问题在迁移老站、处理多语言内容时特别常见。
把这几样信息串起来看,工具就不只是个状态码查询器,而是个能从多个维度给接口和页面做体检的小诊断台。耗时看性能、大小看臃肿、结构看契约、编码看乱码,一次请求拿到的信息,比你想象的要多。
把它和浏览器开发者工具搭着用,效率更高吗?
很多人会问,浏览器自带的开发者工具网络面板也能看请求和响应,为什么还要单独用这个工具?答案是两者各有所长,搭着用比单用任一个都顺。
开发者工具的网络面板,强在被动记录——它把页面加载时自动发出的所有请求都抓下来,让你看清这个页面到底向哪些接口要了数据、每个请求的状态码和耗时如何、资源加载的瀑布流是什么样。诊断页面为什么慢、为什么某个资源没加载出来,看网络面板最直接。但它是被动的,记录的是页面自己发的请求,你没法在里头轻松地主动构造一个全新的请求去测。
这款API测试工具,强在主动构造——你想测什么接口、用什么方法、带什么头、填什么认证,全由你说了算,发出去看结果。它适合的是有目的地去探一个接口、验一个URL的状态码、试不同参数下接口的反应。这种主动发起的活,在网络面板里做起来很别扭,在这个工具里却是本职。
所以实战里常这么配合:先用开发者工具的网络面板看清页面都调了哪些接口、哪个接口出了问题,把那个可疑接口的地址、方法、请求头从网络面板里抄出来——开发者工具支持把某条请求直接复制成curl命令,正好能粘进这个工具的curl导入里,一键还原成可编辑的请求。然后在工具里反复改参数、试认证、看不同情况下的返回,把问题摸透。
这套组合的精髓是:网络面板负责发现问题在哪个接口,工具负责把那个接口翻来覆去地测明白。一个被动观察、一个主动探查,职责互补。光会看网络面板,遇到要主动构造请求的场景就卡壳;光会用这个工具,又容易漏掉页面实际发了哪些请求。两手都会,技术SEO里的接口排查才算趁手。
再补一句,开发者工具是跟着浏览器走的、不受额外限制,而这个工具同样受CORS约束。所以从网络面板复制出来的某些跨域接口,搬到工具里直接发可能会被CORS拦——这时候还是回到那条老路,导出curl拿到命令行去跑。把这几样工具的边界都摸清,它们之间怎么接力就清楚了。
常见问题解答
把大家最常问的几个问题集中答一下,都是用它做技术SEO时真会撞上的。
问:为什么我测自己服务器上的接口总是报Failed to fetch?因为它是浏览器用fetch发的请求,受同源策略和CORS约束。你的接口如果没在响应头里带Access-Control-Allow-Origin放行当前来源,浏览器就会把响应拦下,工具只能报失败。解法是给接口临时配上CORS放行头,或者把请求导出成curl命令拿到服务器上跑,绕开浏览器这层限制。
问:我填进去的API Key和Token安全吗,会被保哥笔记记录吗?请求是你浏览器直接发到目标接口的,不经过保哥笔记的服务器,所以凭据不会落到这边。但要清醒一点:凭据仍然在你浏览器内存里,浏览器开发者工具的网络面板里也看得到Authorization头,别在不可信的公共电脑上操作敏感凭据,也别截图时把头露出去。
问:它能一次批量测一百个URL的状态码吗?不能。它一次只发一条请求,没有批量导入功能,历史记录最多也就留三十条还刷新即清。要批量查状态码,得用专门的批量检测工具或者写脚本。它适合的是单个URL的深度排查,不是规模化巡检。
问:用它跟踪重定向,为什么只看到终点页看不到中间跳转?因为fetch默认会自动跟随重定向,一口气跟到终点才把结果给你。想看清每一跳,得手动来:发一次看状态码,301就去响应头找Location,把地址换成Location再发,一跳一跳手动走完整条链。本文前面专门写了这套步骤。
问:响应头列表里好像少了几个头,是工具的问题吗?多半不是工具的问题,是CORS在中间筛过了。跨域时,浏览器只把CORS安全名单里的头、以及接口用Access-Control-Expose-Headers主动放行的头交给脚本读,像Set-Cookie这种敏感头脚本根本读不到。所以工具显示的响应头,跨域场景下未必是服务器发的全部。
权威参考资料
本文标题:《API测试工具怎么用?快速看清一个URL的状态码与响应头》
本文链接:https://zhangwenbao.com/api-tester-http-status-header-rest-debug-seo-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0