CDN边缘缓存到底怎么配才不踩坑?回源、TTL分层与缓存键实战
本文目录
- CDN的边缘缓存到底是怎么工作的?请求是怎么被边缘节点接住的?
- CDN凭什么决定缓存什么、缓存多久?Cache-Control是怎么指挥它的?
- 边缘缓存TTL和浏览器缓存TTL是一回事吗?
- 缓存键是什么?为什么URL参数会悄悄拖垮你的命中率?
- TTL该怎么分层设?静态资源、HTML、接口各给多久?
- 源站挂了或内容过期,边缘缓存怎么兜底?
- 内容更新后怎么精准失效缓存?purge有哪几种方式?
- 缓存命中率怎么看、怎么提?
- 回源风暴和缓存穿透怎么防?分层缓存有什么用?
- 保哥给一个独立站套CDN把命中率从五成提到九成,做了哪几步?
- CDN边缘缓存最容易翻车的几个地方有哪些?
- 常见问题解答
- 套了CDN网站还是不快、源站压力也没降,问题通常出在哪?
- 边缘缓存TTL和浏览器缓存TTL该怎么分别设?
- 查询参数(比如utm)真的会影响CDN命中率吗?怎么处理?
- 内容更新后,怎么让CDN缓存及时失效又不伤命中率?
- 边缘缓存能在源站宕机时让网站还能访问吗?
- 权威参考资料
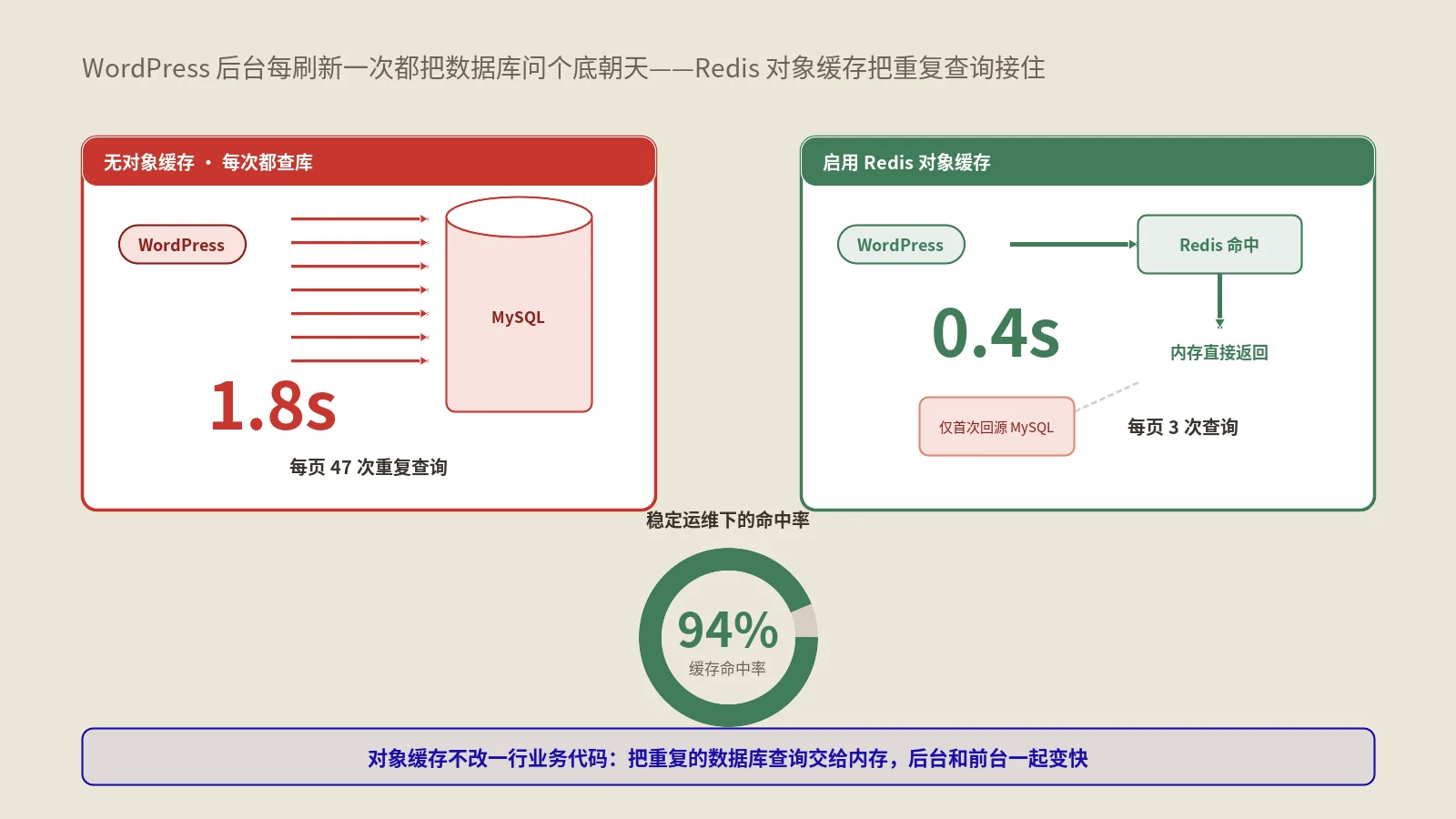
摘要:很多人给独立站套了CDN,以为流量一接过去网站就会自动变快、源站压力就会自动降下来,结果一看后台,缓存命中率才五成出头,源站照样被打得喘不过气,更新了内容用户半天还看到旧版。问题几乎都出在同一个地方:CDN接进来了,但边缘缓存的策略没配对,CDN沦为一个只会转发请求的中转站,根本没把“缓存”这件最值钱的事做好。
边缘缓存的逻辑其实不复杂:CDN在全球各地放了一堆边缘节点,用户的请求就近被最近的节点接住,如果这个节点缓存里有现成的内容就直接吐回去、根本不碰你的源站,这才是CDN让网站变快、给源站减压的核心。配好它的关键,是想清楚什么该缓存、缓存多久、缓存键怎么定、内容更新了怎么精准失效。
保哥这篇不绑定某一家CDN,讲的是适用于Cloudflare、CloudFront、Fastly等任何CDN的通用边缘缓存策略:边缘节点怎么接住请求、Cache-Control怎么指挥CDN、边缘TTL和浏览器TTL的区别、缓存键怎么悄悄拖垮命中率、TTL怎么分层、源站挂了怎么用陈旧内容兜底、内容更新后怎么精准purge、命中率怎么提、回源风暴怎么防,最后给一个把命中率从五成提到九成的真实案例和几个翻车现场。
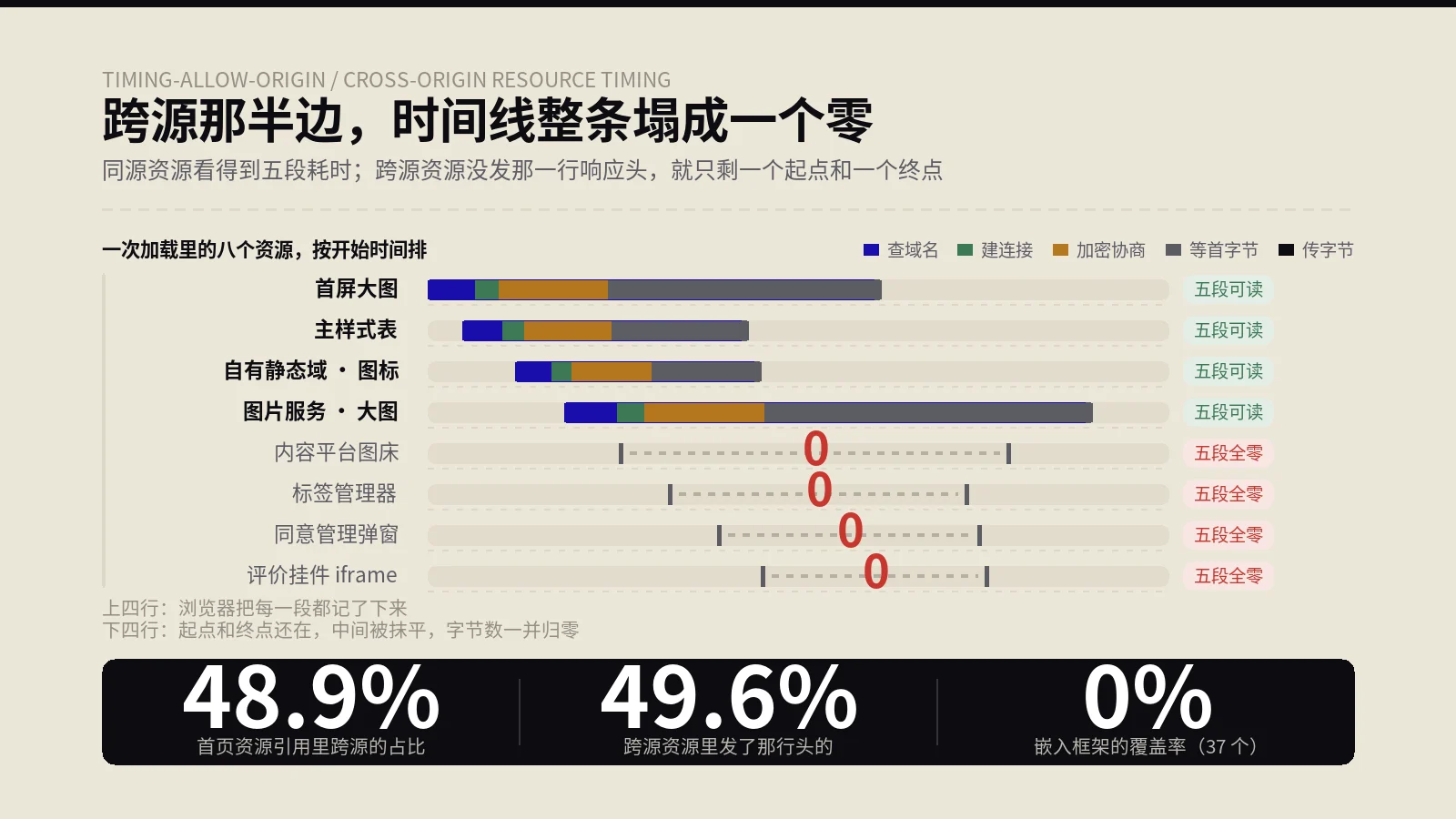
保哥先讲个真见过的事。一个做外贸的独立站,老板花钱上了CDN,满心以为网站从此飞快。跑了一阵发现源站负载没怎么降,打开后台一看缓存命中率只有48%——意思是超过一半的请求CDN都没缓存,老老实实回源去问了一遍。再细查,原因哭笑不得:源站给几乎所有响应都带了Set-Cookie,CDN一看带cookie的响应,按默认规则当成“因人而异的私人内容”就不缓存了,于是CDN形同虚设。
这事的根子不在CDN本身,而在没人去理解和配置边缘缓存的规则。所以这一篇,保哥按“边缘缓存怎么工作、CDN怎么判断缓存什么、TTL怎么设、缓存键怎么定、更新了怎么失效、出问题怎么查”这条真实链路,把CDN边缘缓存策略讲清楚,让你套了CDN之后是真的快、真的给源站减压,而不是花钱买了个摆设。
CDN的边缘缓存到底是怎么工作的?请求是怎么被边缘节点接住的?
要把边缘缓存配对,先得看清一个请求在CDN体系里走的完整路径。保哥用一次普通的访问来拆解。
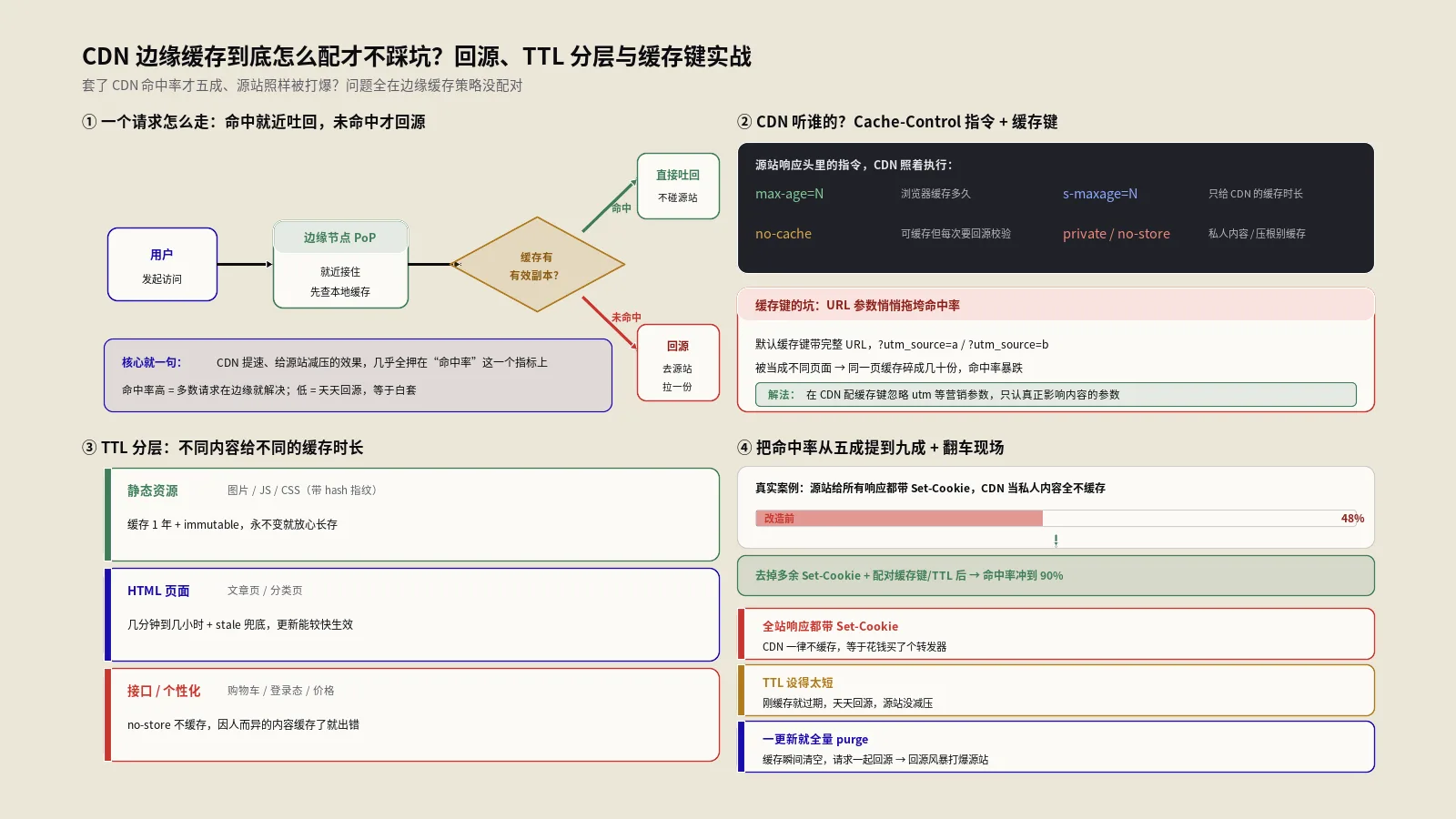
当一个用户访问你的网站,请求并不会直接打到你那台源服务器上,而是先被CDN的DNS解析引导到离用户地理位置最近的边缘节点(业内也叫PoP,接入点)。CDN在全球部署了成百上千个这样的节点,靠Anycast技术让同一个IP在不同地区指向不同的就近节点,所以一个中国用户和一个德国用户访问你的站,接住他们的是各自附近的不同节点。光是这个“就近接入”,就已经把网络延迟砍掉一大截。
接住请求后,边缘节点做的第一件事是查自己的本地缓存:如果缓存里有这个资源的有效副本(缓存命中,cache hit),节点直接把它吐回给用户,整个过程根本不碰你的源站,速度极快、源站零压力。这是CDN价值的核心。如果缓存里没有、或者副本已经过期(缓存未命中,cache miss),节点才会回源——也就是去你的源服务器把内容拉一份回来,一边返回给用户,一边按规则缓存下来,下一个访问同一资源的用户就能命中了。
所以整个CDN提速和减压的效果,几乎全部押在“命中率”这一个指标上。命中率高,意味着绝大多数请求在边缘就被解决了,源站清闲、用户飞快;命中率低,意味着CDN天天回源,既没给源站减压,还多绕了一道,甚至可能更慢。理解了这条路径,你就明白后面所有策略——TTL、缓存键、purge——本质上都是在为“提高命中率、且不缓存错东西”这一个目标服务。
CDN凭什么决定缓存什么、缓存多久?Cache-Control是怎么指挥它的?
边缘节点不会瞎缓存,它主要听源站响应头里的指令行事,其中最关键的就是Cache-Control。理解这个头怎么指挥CDN,是配置边缘缓存的基本功。
根据MDN的权威定义,Cache-Control里有两个最该分清的指令:max-age和s-maxage。max-age管的是“私有缓存”也就是用户浏览器该把资源存多久;s-maxage专门管“共享缓存”,CDN这种被所有用户共用的缓存就属于共享缓存。当响应里同时有这两个,CDN会优先听s-maxage的,浏览器则听max-age的。这给了你分别控制“边缘缓存多久”和“浏览器缓存多久”的能力,后面专门讲。
还有几个指令决定了一个资源到底能不能被CDN缓存。public 明确表示这个响应可以被共享缓存存;private 则告诉CDN“这是因人而异的私人内容,你不许缓存”,只允许浏览器自己存——用户的账户页、购物车、带个人信息的页面就该标private。no-store 是最严的,谁都不许存,敏感数据用它。no-cache 名字有迷惑性,它不是“不缓存”,而是“可以存,但每次用之前必须回源问一下有没有更新”。
这里就能解释开头那个案例:当源站给响应带上Set-Cookie,很多CDN会默认认为这是个性化内容而不缓存它。所以如果你的整站响应都莫名带着cookie,CDN的缓存就基本废了。配置边缘缓存的第一步,往往是把源站对静态资源、对公共页面的响应头理顺:该public的标public、给够s-maxage、别乱带Set-Cookie。这套响应头的逻辑和保哥讲浏览器HTTP缓存头那篇是一脉相承的,只不过那篇聚焦浏览器这一层,这篇聚焦CDN这层共享缓存,两层叠起来才是完整的缓存链路。
边缘缓存TTL和浏览器缓存TTL是一回事吗?
这是新手最容易混的一组概念,保哥必须掰开讲。边缘缓存TTL和浏览器缓存TTL是两个独立的东西,分别控制资源在两个不同地方待多久,可以、而且常常应该设成不一样的值。
边缘缓存TTL(Edge Cache TTL)指的是一个资源在CDN的边缘节点上被当作“新鲜的、可直接拿来用”能待多久。根据Cloudflare官方文档,它就是资源在CDN全球网络里缓存的最大时长,由s-maxage控制。浏览器缓存TTL(Browser Cache TTL)则是这个资源被缓存在用户浏览器里能待多久,由max-age控制。
为什么要分开设?因为这两层的更新成本完全不同。边缘缓存你能主动purge(清掉),浏览器缓存你清不到——内容一旦进了用户浏览器,在TTL到期前你基本没法强制它更新。所以常见的稳妥策略是:边缘TTL可以设得长一点(反正能随时purge),浏览器TTL对那些可能要改的内容设得短一点或适中,免得用户长时间抱着旧版还没法刷新。
举个实战例子:一张带指纹文件名的图片(比如logo.a1b2c3.png,内容变了文件名就变),它既可以给很长的边缘TTL,也可以给很长的浏览器TTL,因为它根本不会原地更新。而一个HTML页面,边缘TTL可以给几分钟到几小时(更新时一purge就生效),但浏览器TTL最好给很短甚至不缓存,否则你purge了边缘,用户浏览器里那份还在。分清这两层、按“能不能purge、会不会改”来分别给值,是TTL策略的核心判断。
缓存键是什么?为什么URL参数会悄悄拖垮你的命中率?
这是个隐蔽但杀伤力极大的点,很多站命中率上不去的元凶就在这儿。先说什么是缓存键。
缓存键(cache key)是CDN用来判断“两个请求要不要算同一个资源”的依据。默认情况下,缓存键主要由请求的完整URL(包括路径和查询参数)构成。CDN拿到一个请求,按缓存键去缓存里找:键一样就算命中,键不一样就当成不同资源、各缓存一份。
问题就出在查询参数上。如果缓存键把所有query参数都算进去,那么同一个页面带上不同的营销参数,就会被CDN当成无数个不同的资源,各回各的源、各缓存一份,命中率被稀释得惨不忍睹。想象一下,你的首页链接被投放到各个渠道,带着utm_source、utm_medium、fbclid、gclid等一堆追踪参数,结果同一个首页因为参数不同,在CDN眼里成了几千个不同URL,几乎每个都得回源一次——命中率怎么可能高?
解法是规范化缓存键:把那些不影响页面内容的参数从缓存键里剔除掉。各家CDN都提供这个能力,你可以配置“忽略所有查询参数”或者“只保留某几个真正影响内容的参数”(比如分页的page、语言的lang),把utm这类纯追踪参数统统排除在缓存键之外。这样无论链接带多少营销尾巴,CDN都认成同一个资源,命中率立刻上来。
反过来也要小心:有些参数是真的会改变页面内容的(比如 ?product_id=123),这种绝不能从缓存键里剔除,否则不同商品会串成同一个缓存、给用户返回错内容。规范化缓存键的精髓是“剔除噪声参数、保留内容参数”,剔多了串内容,剔少了命中率低,得逐站梳理你的参数清单。这一步保哥几乎在每个接CDN的项目里都要专门做一遍,收益往往立竿见影。
TTL该怎么分层设?静态资源、HTML、接口各给多久?
不同类型的内容更新频率天差地别,TTL当然不能一刀切。保哥按内容类型给一套分层的实战思路。
第一类,带指纹的静态资源(JS、CSS、图片、字体):给最长的TTL,越长越好,边缘和浏览器都可以缓存一年。前提是这些文件用了内容指纹命名——文件内容一变,构建工具就给它生成一个新文件名。这样旧文件名对应的内容永远不变,可以放心永久缓存;要更新就是引用一个新文件名,天然避开了“缓存了旧版”的问题。这类资源是CDN命中率的主力贡献者。
第二类,HTML页面:边缘TTL给适中(几分钟到几小时),浏览器TTL给很短或不缓存。HTML是内容会变的,但变的频率没那么高。给边缘几分钟到几小时的缓存,能挡掉绝大多数重复访问的回源;真要更新(改了文章、改了价格),主动purge一下立刻生效。浏览器这层别缓存太久,否则purge了边缘用户还看旧的。
第三类,API接口和真正动态的内容(购物车、用户中心、下单):原则上不缓存,标private或no-store。这些内容因人而异、实时性强,缓存了就会串号、就会给A用户看到B的数据,是事故的高发区。宁可让它们老老实实回源,也别为了命中率去缓存它们。如果某些接口数据是公共的、能容忍几秒延迟(比如商品列表),可以给一个很短的边缘TTL配合后台刷新,但要非常谨慎。
把这三层定下来,你的TTL策略就有骨架了:静态指纹资源往死里缓存,HTML短边缘缓存加随时purge,私人动态内容坚决不缓存。剩下的就是针对具体业务微调。这套分层思路和保哥讲TTFB与多层缓存那篇里强调的“按内容特性分层缓存”是同一套方法论,CDN只是这个多层体系里离用户最近的那一层。
源站挂了或内容过期,边缘缓存怎么兜底?
这是边缘缓存里非常实用、却常被忽略的一组能力:用“陈旧内容”兜底。它能同时改善速度和可用性。
第一个机制是stale-while-revalidate(过期后台刷新)。它的逻辑是:当缓存内容刚过期,CDN不让用户干等着回源,而是先把手头这份过期的(stale)内容立刻吐给用户,同时在后台悄悄回源拉一份新的更新缓存。这样用户永远是秒开的,代价只是可能看到几秒钟前的旧版,对绝大多数内容完全可以接受。根据MDN的说明,这个指令允许缓存在后台重新验证的同时复用过期响应。
第二个机制是stale-if-error(出错时用陈旧内容)。它管的是更要命的场景:当CDN回源时发现你的源站挂了、超时了、返回5xx错误,它不直接把错误页甩给用户,而是把缓存里那份过期的内容拿出来顶上。这等于给你的网站加了一层抗源站故障的保险——源站宕机的那几分钟,用户访问主要页面还能看到缓存的旧版,业务不至于整个白屏。
保哥的经验是,这两个机制对独立站特别值。源站偶尔抽风、重启、被突发流量打挂,是运维里躲不开的事;配好stale-if-error,这些瞬间用户基本无感,比裸奔着等源站恢复体面太多。配置上各家CDN略有不同,有的认Cache-Control里的stale-while-revalidate和stale-if-error指令,有的在面板里叫“总是在线”或类似的开关,但内核都是这套“用旧内容兜底”的思路。把它打开,等于花零成本给可用性买了份保险。
内容更新后怎么精准失效缓存?purge有哪几种方式?
缓存的另一面是失效。内容更新了,你得让边缘缓存里的旧版及时下岗,否则用户一直看旧的。这就是purge(缓存清除/失效),它有几种粒度,用对了能既快又准。
第一种,按URL精准purge。你改了某一篇文章、某一个商品页,就只purge那几个具体的URL。这是最精准、对命中率伤害最小的方式——只清掉真正变了的那几个,其他缓存原封不动。日常内容更新首选这种。
第二种,按缓存标签(cache tag)purge。这是更高级也更实用的玩法:你在源站给响应打上标签(比如给所有属于“某个商品分类”的页面都打上tag:category-shoes),更新时一条purge命令把带这个标签的所有页面一次清掉。改了一个分类下的批量内容、或者一个被很多页面引用的模块变了,用标签purge比一个个列URL高效得多。
第三种,按路径前缀purge。清掉某个目录下的所有缓存,比如 /blog/ 下全部。适合一整块内容批量更新的场景。
第四种,清空全部(purge everything)。把整站缓存一键全清。这是核武器,非必要别用——一清全部,所有边缘缓存瞬间归零,紧接着海量请求一起回源,源站可能被这波“回源风暴”直接打垮。只有在大改版、缓存策略整体调整这种场景才动用它,且最好避开流量高峰。
保哥的原则是:能按URL就别按前缀,能按标签就别清全部,purge的粒度越精准,对命中率和源站越友好。这套精准失效的纪律,和保哥在Nginx反向代理缓存那篇里讲的自建缓存purge思路是相通的,无论缓存在CDN还是在自己的反代上,“精准失效”都是同一条铁律。
缓存命中率怎么看、怎么提?
前面反复强调命中率是CDN的命根子,这一节说怎么量它、怎么提它。
命中率(cache hit ratio)的看法很直接:命中请求数 ÷ 总请求数。各家CDN的分析面板都有这个指标,还会按状态标出每个响应是HIT(命中)、MISS(未命中回源)、还是EXPIRED、DYNAMIC等。保哥的习惯是先看整体命中率,再下钻看哪些URL、哪类资源MISS最多,那里就是优化的突破口。一个健康的、以静态资源为主的站,命中率做到90% 以上是常态;如果你只有五六成,基本就是有东西配错了。
提命中率主要有几条路。一是规范化缓存键,把utm这类噪声参数从键里剔除,这往往是单项收益最大的一步,前面专门讲过。二是延长能延长的TTL,尤其是静态指纹资源,TTL太短会让缓存频繁过期、频繁回源。三是理顺响应头,别让该缓存的内容因为带了Set-Cookie、标了private或no-store而被CDN拒之门外。
四是对合适的站点开启更激进的缓存。如果你的站以静态内容为主(比如内容站、展示型独立站),可以配置规则让CDN把HTML也缓存起来(有的叫cache everything),别只缓存图片JS。当然这要配合好purge和对私人页面的排除,但对内容型站点,把HTML纳入边缘缓存往往能让命中率和速度再上一个台阶。
如果你用的恰好是Cloudflare,保哥在Cloudflare缓存与回源率优化决策树那篇里把具体到这一家的Cache Rules怎么写、回源率怎么压细讲过,可以拿这篇的通用原理对照那篇的具体操作落地。命中率不是玄学,它几乎总能被“缓存键 + TTL + 响应头 + 缓存范围”这四个旋钮调上去,逐个排查就能找到拖后腿的那个。
回源风暴和缓存穿透怎么防?分层缓存有什么用?
最后讲一个偏进阶、但对中大型站很关键的话题:怎么保护源站不被回源打垮。
先理解风险。当某个热门资源的边缘缓存同时过期、或者你刚purge了全部缓存,海量本来在边缘被消化的请求会在同一瞬间一起涌向源站,这就是回源风暴。源站平时只接边缘漏过来的零星请求,突然要扛全量回源,很可能直接被打挂。缓存穿透则是另一种:大量请求访问一个根本不存在、或不可缓存的资源,每一个都穿过CDN直达源站,CDN没起到任何屏障作用。
防回源风暴最主流的手段是分层缓存(tiered cache)或源站盾(origin shield)。它的思路是在“众多边缘节点”和“你的源站”之间,再加一层中间缓存层:所有边缘节点的回源请求不直接打源站,而是先汇聚到这个中间层,由它统一向源站要一次、再分发给各边缘节点。这样源站面对的不再是成百上千个边缘节点的并发回源,而只是中间层这一个收口,回源压力被收敛了一个数量级。
分层缓存还能提整体命中率:一个冷门资源在某个边缘节点MISS了,但它可能在中间层是热的(因为别的节点请求过),就不用一路回到源站。对全球分布、节点众多的站,这个收益相当可观。各家CDN对这个功能叫法不同(Argo Tiered Cache、Origin Shield等),但解决的都是同一个问题。保哥的判断是:小站靠规范缓存键和合理TTL把命中率做高就够了;一旦你的源站经不起回源高峰、或者业务全球分布,分层缓存就该提上日程,它是给源站上的一道关键护栏。
保哥给一个独立站套CDN把命中率从五成提到九成,做了哪几步?
回到开头那个命中率只有48% 的外贸独立站,保哥分享一下后来是怎么把它救上来的。
第一步是揪出Set-Cookie的元凶。保哥抓了一批响应头,发现源站给静态资源和公共页面也无差别地带了会话cookie,导致CDN把它们全当私人内容拒绝缓存。改源站配置,让静态资源和不需要会话的公共页面不再带Set-Cookie,这一步就让大批资源重新变得可缓存。
第二步是规范化缓存键。这个站的链接在各渠道投放,带着大量utm和广告点击参数。保哥配了规则,把所有纯追踪参数从缓存键里剔除,只保留分页和语言这种真正影响内容的参数。同一个落地页不再因为营销尾巴被拆成无数份,命中率立刻往上跳了一大截。
第三步是分层设TTL。给带指纹的JS、CSS、图片设了一年的长缓存;给HTML设了边缘缓存十分钟、浏览器不缓存;给购物车、账户这类页面明确标private,坚决不进边缘缓存。该缓存的往死里缓存,该实时的坚决回源,泾渭分明。
第四步是配好purge和兜底。接入了按URL和按缓存标签的精准purge,内容一更新就只清相关页面,不再动不动清全部;同时打开了stale-if-error,给源站抽风的时刻加了层保险。
四步做完,这个站的缓存命中率从48% 升到了91%,源站负载降了一多半,海外用户打开首页的速度也明显快了。老板原话是,原来CDN不是接上就完事,里头还有这么多门道。保哥跟他说,CDN给的是一套缓存的能力,但能力要靠策略激活——缓存键、TTL、响应头、purge这几样配对了,它才真的值你付的那笔钱。
CDN边缘缓存最容易翻车的几个地方有哪些?
保哥按踩坑频率,把CDN边缘缓存里最容易出事的几个点列出来,配置前对照检查能少掉很多坑。
第一,给所有响应乱带Set-Cookie,导致CDN不缓存。CDN默认把带cookie的响应当私人内容。静态资源和公共页面别带会话cookie,否则命中率从根上就废了。
第二,缓存键没剔除营销参数,命中率被稀释。utm、fbclid、gclid这类纯追踪参数会把同一个页面拆成无数份。规范化缓存键、剔除噪声参数,是提命中率收益最大的一步。
第三,把私人动态内容缓存了,给用户串号。购物车、账户页、带个人信息的页面标private或no-store,坚决别进共享缓存,否则A用户会看到B的数据,这是严重事故。
第四,内容更新了不purge,用户一直看旧版。边缘缓存不会因为源站变了就自动失效,你得主动purge。直写数据库、改了页面后,记得按URL或标签精准清掉对应缓存。
第五,动不动purge everything,引发回源风暴。清空全部会让所有请求瞬间一起回源,可能把源站打垮。能按URL就别按前缀,能按标签就别清全部,粒度越精准越安全。
第六,浏览器TTL设太长,purge了边缘也没用。内容进了用户浏览器,TTL到期前你purge不到。可能要改的内容,浏览器TTL给短一点,把更新的主动权留在自己手里。
这几个坑的共同点是:边缘缓存的威力来自“替源站挡住请求”,但挡得对不对、清得准不准,全靠你的策略。把缓存什么、缓存多久、缓存键怎么定、怎么精准失效这四件事想清楚,CDN才能从一个摆设变成真正的提速和减压利器。
常见问题解答
套了CDN网站还是不快、源站压力也没降,问题通常出在哪?
九成出在缓存命中率太低,也就是CDN接进来了,但大量请求并没有在边缘被缓存命中,而是老老实实回源了,CDN只起了个转发的作用,没起到缓存的作用。命中率低最常见的三个原因:一是源站给响应乱带Set-Cookie,CDN默认把带cookie的响应当个性化私人内容而拒绝缓存;二是缓存键没剔除营销参数,同一个页面带不同的utm、广告点击参数被CDN当成无数个不同资源,缓存被稀释得几乎没用;三是响应头没配好,该缓存的内容被标了private、no-store或根本没给缓存指令。排查时先去CDN面板看整体命中率和哪些URL的MISS最多,然后顺着Set-Cookie、缓存键、响应头这三个方向逐个查。一个以静态资源为主的健康站点,命中率应该在90% 以上,如果你只有五六成,一定有东西配错了,逐项排基本都能救回来。
边缘缓存TTL和浏览器缓存TTL该怎么分别设?
核心判断是看“能不能purge”和“内容会不会改”。边缘缓存你能主动purge,浏览器缓存你purge不到,所以两层的策略不同。对带内容指纹的静态资源(文件名随内容变的JS、CSS、图片),边缘和浏览器都给最长的TTL,因为它们永远不会原地更新,要改就是换个新文件名。对HTML这类会变的内容,边缘TTL给适中(几分钟到几小时),因为真要更新时purge一下就立刻生效;但浏览器TTL要给很短甚至不缓存,否则你purge了边缘,用户浏览器里那份在TTL到期前还是旧的,你够不着。对购物车、账户这类私人动态内容,两层都别缓存,标private或no-store。一句话总结:能purge又不变的往长了设,会改的边缘短缓存加随时purge、浏览器尽量短,私人内容坚决不缓存。
查询参数(比如utm)真的会影响CDN命中率吗?怎么处理?
影响极大,而且是很多站命中率上不去的隐形元凶。默认情况下,CDN的缓存键包含完整URL,连查询参数一起算。这意味着同一个页面,只要后面跟的参数不同,CDN就当成不同的资源各缓存一份、各回各的源。你的链接被投放到各渠道,带着utm_source、utm_medium、fbclid、gclid一堆追踪尾巴,结果同一个落地页在CDN眼里裂变成成千上万个不同URL,命中率被稀释到惨不忍睹。解法是规范化缓存键:在CDN配置里把那些不影响页面内容的参数从缓存键中剔除,只保留真正改变内容的参数(比如分页page、语言lang)。这样无论链接带多少营销参数,CDN都认成同一个资源。要注意别把会改变内容的参数也剔了(比如product_id),否则不同商品会串成同一个缓存返回错内容。剔除噪声、保留内容参数,逐站梳理一遍参数清单,命中率往往立竿见影地往上走。
内容更新后,怎么让CDN缓存及时失效又不伤命中率?
用尽量精准的purge粒度。CDN的purge通常有几种粒度:按具体URL清、按缓存标签(cache tag)清、按路径前缀清、以及清空全部。日常内容更新优先用按URL精准清,只清你真正改了的那几个页面,对其他缓存零伤害。如果是一批相关页面一起变了(比如某个分类下的批量内容、或一个被很多页面引用的模块),用缓存标签清最高效——提前给这批页面打上同一个标签,更新时一条命令全清掉。一整块目录更新可以用前缀清。最该慎用的是清空全部,它会让所有边缘缓存瞬间归零,紧接着海量请求一起回源,可能引发回源风暴把源站打垮,只在大改版时才用且要避开高峰。原则是:能按URL就别按前缀,能按标签就别清全部,粒度越细,更新生效又快、对命中率和源站的冲击又小。另外别忘了,直写数据库改内容不会自动触发CDN失效,得手动purge。
边缘缓存能在源站宕机时让网站还能访问吗?
能,靠的是stale-if-error这套用陈旧内容兜底的机制。正常情况下,当CDN回源发现源站挂了、超时或返回5xx错误,它默认会把错误甩给用户。但如果你配了stale-if-error,CDN在这种时刻不返回错误,而是把缓存里那份已经过期的旧内容拿出来顶上,让用户至少还能看到主要页面的旧版,业务不至于整个白屏。这等于给网站加了一层抗源站故障的保险,源站重启、被突发流量打挂的那几分钟,用户基本无感。和它配套的还有stale-while-revalidate,管的是内容刚过期时不让用户干等回源,先返回旧的、后台再悄悄更新,兼顾了速度。这两个机制对独立站特别值,因为源站偶尔抽风是运维躲不开的事,配好它们几乎零成本就换来了可用性的明显提升。配置上有的CDN认Cache-Control里的对应指令,有的在面板里是“总是在线”之类的开关,内核都是用旧内容兜底,建议都打开。
权威参考资料
本文标题:《CDN边缘缓存到底怎么配才不踩坑?回源、TTL分层与缓存键实战》
本文链接:https://zhangwenbao.com/cdn-edge-caching-strategy-ttl-cache-control-purge-origin-shield.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0