中文简繁转换器怎么用?台湾香港用语本地化与那个会转错的“头发”
本文目录
- 简体转繁体,为什么不只是“换个字形”那么简单?
- 这个转换器到底支持哪几种转换模式?
- 它是靠一张多大的字表、怎么完成转换的?
- “头发”被转成“頭發”,这种错是怎么来的?
- 台湾“軟體”、香港“軟件”,它的地区词库够用吗?
- 繁转简的方向,会不会也踩一样的歧义坑?
- 台港市场和海外华人市场,繁体策略是一回事吗?
- 转换之外,繁体站还有哪些容易被忽略的本地化细节?
- 一句话判断:你到底该不该用这个工具?
- 关键词的简繁差异,到底怎么落到选词和页面布局上?
- 自动检测方向,它到底靠什么判断、什么时候会判错?
- 转换前后的差异对比和字符统计,能帮上什么忙?
- 一个汉方草本护肤出海站,是怎么用它做台湾繁体初稿的?
- 简繁双版本站,目录和URL结构该怎么搭才不打架?
- 它和机器翻译、专业本地化方案,分工到底在哪?
- 最容易转错的一简多繁字,给你一份重点核对清单
- 繁体内容的SEO收录,和简体站有什么不同要注意的?
- 三步用它生成一版繁体市场的内容初稿
- 简繁转换和国际SEO,到底有什么真实关联?
- 常见问题解答
摘要:这个中文简繁转换器,靠一张内置的约2700字简繁对照表加两套地区词库(台湾52个词、香港19个词)来工作,支持简转繁、繁转简和自动检测方向三种模式。它的转换分两层:先按词替换地区惯用语(软件转軟體、网络转網路这种),再逐字查表替换。但它有两个必须认清的天花板:一是它对“一简对多繁”的字是写死的一对一映射,不看上下文,所以“理发”会被错转成“理發”(正确应是“理髮”);二是它的地区词库小到只能覆盖最常见的几十个词,远不是OpenCC那种生产级方案。所以它是个很顺手的繁体内容初稿生成器,能帮你快速出一版台湾或香港版文案,但绝不能直接上线——一简多繁的歧义字和没收录的本地词,必须靠人工校对兜住。把它当初稿工具,配合人工审核用,它就好用。
出海如果要做繁体市场——台湾、香港,还有散布全球的海外华人——内容本地化里有一道绕不过去的关:简体转繁体。很多人以为这就是个“字形切换”,把简体字换成繁体字就完事了。真做起来才发现没这么简单:同一个简体字可能对应好几个繁体字,台湾人和香港人用的词还不一样,软件在台湾叫“軟體”、在香港叫“軟件”——这些都不是单纯换字能解决的。
这个中文简繁转换器,就是想帮你处理这道关。它内置了简繁对照表和地区词库,能一键把简体内容转成繁体,还能区分台湾用语和香港用语。这篇就把它的转换机制、它内置的字表和词库到底有多大、它在哪些地方会转错,连同简繁转换和国际SEO的真实关联,一次性讲清楚——重点是它那两个天花板,关系到你能不能放心用它的输出。
简体转繁体,为什么不只是“换个字形”那么简单?
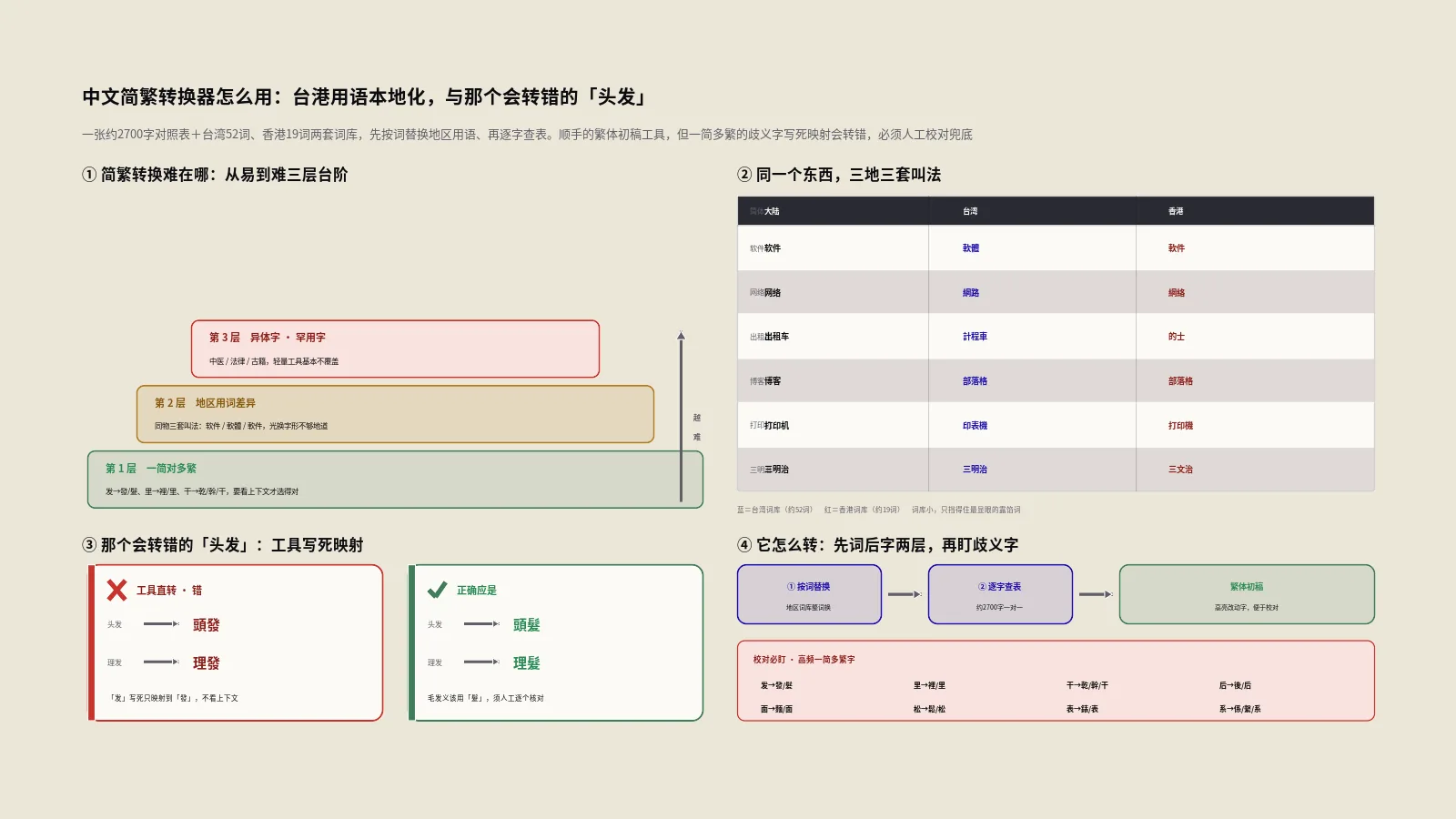
得先把这件事的难度讲透,你才明白这个工具在解决什么、又解决不了什么。简繁转换的复杂,藏在三个层次里。
第一层是“一简对多繁”。简化字方案里,好几个原本不同的繁体字,被合并成了同一个简体字。最经典的是“发”——它在繁体里对应两个字:表示“出发、发展”的“發”,和表示“头发、毛发”的“髮”。简体统一写成“发”,但转回繁体时,“发展”要转成“發展”,“头发”却要转成“頭髮”。再比如“里”对应“裡”(裡面)和“里”(公里)、“干”对应“乾”(乾燥)、“幹”(幹活)和“干”(干涉)。要转对,机器得看懂上下文——这正是难点所在。
第二层是“地区用词差异”。就算字形转对了,词也未必地道。同一个东西,大陆、台湾、香港的叫法常常三套:大陆的“软件”,台湾叫“軟體”,香港叫“軟件”;大陆的“打印机”,台湾叫“印表機”;大陆的“博客”,台湾叫“部落格”。光做字形转换,“软件”只会变成“軟件”——这在香港对,在台湾就不地道。真正的本地化,得连用词一起换。
第三层是“异体字和罕用字”。繁体里还有大量异体字、罕用字,专业内容(中医、法律、古籍)里尤其多。这一层,绝大多数轻量工具都覆盖不到。把这三层摆清楚,你就有了一把尺子,去衡量这个工具走到了哪一步。
这个转换器到底支持哪几种转换模式?
它给了三种工作模式。前两种是方向:简转繁(把大陆简体转成繁体)和繁转简(把港台繁体转回大陆简体)。第三种是自动检测——你把一段不确定的文本丢进去,它会统计文本里简体字和繁体字的数量,按比例判断这段大体是简体还是繁体,再自动决定该往哪个方向转。
在转换方向之外,它还有一个地区选项,决定要不要套地区词库:标准模式只做字形层面的转换、不替换用词;台湾模式会额外套上台湾用语词库;香港模式套香港用语词库。这就是说,你想要的不是“随便一种繁体”,而是“台湾人读着地道的繁体”时,得选台湾模式,让它在转字形的同时把“软件”也换成“軟體”。
这里要先点破一个宣传用语:界面把自动检测叫“智能检测”、把词库替换叫“智能替换”。但代码里并没有什么“智能”——所谓智能检测,就是数一数简繁字各有多少个、比个大小;所谓智能替换,就是拿词库做字符串查找替换。没有任何自然语言理解的成分。这不影响它好不好用,但你心里得清楚它的“智能”是营销话术,不是真有NLP。
它是靠一张多大的字表、怎么完成转换的?
把转换机制拆开看,它的能力边界就清楚了。它的核心,是一张内置的简繁对照表,大约2700个简繁字对,从“万→萬”一直到“龟→龜”,覆盖了GB2312和Big5里的绝大多数常用字。繁转简方向的表,是把这张简转繁表反转生成的,所以它实际维护的是一张双向表。
转换过程分两层,顺序很关键。第一层是按词替换:工具先拿地区词库里的词,在文本里做整词替换,而且是按词的长度从长到短排序后再替换——这样能避免“短词先被换掉、导致长词匹配不上”的问题。第二层是逐字替换:词替换完,剩下的文本再一个字一个字查那张2700字的对照表,逐字转换。
这个“先词后字”的两层设计,是它做对的地方——有了词层,“软件”能被整个换成“軟體”,而不是逐字变成没人用的“軟件”(在台湾语境下)。但请注意,这两层都只是机械的查表和字符串替换,没有分词、没有语义分析。词库里收了的词能换对,没收的词就只能退回逐字层,按那张一对一的字表硬转——而这,正是它出错的根源。
说到字表规模,得诚实对比一下。它的约2700字,应付日常常用字够用,但跟生产级的开源方案比,差着量级。专门做简繁转换的 OpenCC开源项目,内置的词条以万计,支持字级、词级转换和地区惯用语,还区分大陆、台湾、香港多套标准。这个工具更像是OpenCC思路的一个轻量缩小版——能转,但覆盖面和精度都是另一个段位。
“头发”被转成“頭發”,这种错是怎么来的?
这是全篇最该记牢的一节,直接决定你能不能信它的输出。前面说过简繁转换最难的是“一简对多繁”,需要看上下文才能选对繁体字。而这个工具,恰恰在这一层是缴械的。
它那张对照表,是写死的一对一映射。“发”在表里只映射到一个繁体字(“發”),不管上下文。于是“发展”转成“發展”是对的,但“头发”会被转成“頭發”——大错,正确应该是“頭髮”。同样,“理发”会错成“理發”(应为“理髮”)、“干燥”会错成“幹燥”或“干燥”(应为“乾燥”,看它表里映射的是哪个)。凡是落在“一简对多繁”上的字,只要文本里用的不是它映射的那个义项,就会转错。
为什么会这样?因为它的逐字层就一行逻辑:查表,命中就替换成表里那个唯一的繁体字,查不到就原样保留。没有任何上下文判断的余地。词库层能挡掉一部分——如果“头发”恰好作为一个词被收进了词库,就能被整体换对,但它的词库只有几十个词,绝大多数含歧义字的词都没收,只能退到逐字层去碰运气。
工具自己其实也承认了这一点——它的常见问题里写着“少数一简对多繁的情况,本工具使用最常见的对应关系,特殊语境可能需要人工校对”。这是它难得的诚实。但作为使用者,你要把这句话的分量放大:凡是繁体输出,含“发、里、干、后、表、面、松、回、范”这类高频歧义字的地方,都得逐一人工核对,不能闭眼信。
台湾“軟體”、香港“軟件”,它的地区词库够用吗?
地区用词,是繁体本地化里仅次于歧义字的第二个坑。这个工具有两套地区词库,我们得诚实看看它们的规模。
台湾词库大约52个词,收的是最典型的科技和生活用语:軟體、硬體、網路、資訊、程式、伺服器、印表機、滑鼠、部落格、預設、記憶體、智慧(智能)、行動電話、計程車(出租车)、捷運(地铁)、馬鈴薯/番薯(土豆)等等。香港词库更小,大约19个词:軟件、網絡、的士(出租车)、巴士(公交车)、三文治(三明治)、朱古力(巧克力)、芝士(奶酪)这类。
这两套词库,方向是对的——它确实抓住了“软件”在台港的不同叫法、抓住了一批高辨识度的本地词。但规模诚实讲,是远远不够的。台湾和香港的本地用词差异,真实数量是成百上千的,涉及科技、生活、教育、医疗、法律方方面面。52个和19个,只能覆盖最表层、最常被提起的那一小撮。大量日常词——很多专业术语、机构名、习惯表达——它都没收,只会按字形原样转过去,读起来就是“字是繁体,但味道是大陆的”。
所以对地区词库,正确的期待是:它能帮你把最显眼的那几十个“一眼就露馅”的大陆词换掉,让初稿的本地化程度上一个台阶;但要做到母语者读着完全地道,靠这点词库远远不够,后面必须有本地化人工或更专业的词库补上。它解决的是“别太露怯”,不是“完全地道”。
繁转简的方向,会不会也踩一样的歧义坑?
前面讲的歧义,都是简转繁方向的。反过来——繁转简——是不是就太平无事了?大体上轻松很多,但也不是完全没坑。
繁转简之所以相对简单,是因为方向是“多对一”:好几个繁体字(發、髮)合并成同一个简体字(发),机器只要把繁体字映射回那个唯一的简体字就行,不存在“该选哪个”的纠结。所以“頭髮”转“头发”、“出發”转“出发”,都不会出错。这是简化字方案设计上“化繁为简”带来的天然便利。
但繁转简也有它自己的小麻烦。第一是地区词反向的问题:一篇台湾繁体内容里写的是“軟體”“網路”“部落格”,繁转简如果只做字形转换,会得到“软体”“网路”“部落格”——字是简体了,但词还是台湾说法,大陆用户读着别扭。要转成大陆地道的“软件”“网络”“博客”,同样需要地区词库的反向支持,而这个工具的词库主要是为简转繁配的,反向覆盖更弱。
第二是异体字归并:繁体里一些异体字,简体可能归并也可能保留,这个工具的常用字表未必处理得周全。所以繁转简虽然比简转繁省心,拿来做大陆市场的正式内容,仍然建议人工扫一遍用词,别假设“转成简体就万事大吉”。
台港市场和海外华人市场,繁体策略是一回事吗?
做繁体本地化,很多人脑子里只有一个笼统的“繁体市场”,其实它至少分成性格很不一样的几块,策略不能一刀切。
台湾是最大的繁体内容市场,用的是台湾正体,用词自成一套(軟體、網路、計程車),对本地化的地道程度要求高——用词一露大陆味,信任就打折。香港用繁体,但用词和台湾又不一样(軟件、的士、巴士),而且香港的书面语和口语差距大,正式内容用书面繁体、贴近生活的内容可能掺粤语词。这两块,正是工具那两套地区词库想覆盖的,但前面说了词库太小,只能打个底,地道还得靠人。
还有一块常被忽略的,是散布全球的海外华人——北美、东南亚的华人社区。他们里繁简都有读者,且很多人简繁都能读,对用词的地区敏感度反而没台港本地那么苛刻。面向这块市场,繁体内容的“字形正确”比“用词百分百地道”更要紧。把这三块分清楚,你就知道工具的输出该用到什么程度:发台湾、香港正式内容,工具初稿后必须重度人工本地化;发面向泛华人社区的内容,工具初稿加一遍歧义字校对,可能就够用了。市场不同,对工具输出的打磨深度也不同。
转换之外,繁体站还有哪些容易被忽略的本地化细节?
把文字转成繁体,只是繁体站本地化的一部分,还有些藏在文字之外的细节,不处理同样会露怯。
一是数字、日期、货币格式。台湾常用民国纪年和特定的日期写法,货币是新台币(写法和人民币、港币都不同),香港用港币。这些光靠简繁转换器换不了,得在内容层面单独适配。二是标点和排版习惯。繁体内容的标点用法、甚至直排横排的偏好,和简体有细微差异,正式出版物尤其讲究。三是本地化的例子和指代。一篇面向大陆写的内容,里面举的例子、提到的平台、引用的场景,可能在台港根本不适用——把“微信”“支付宝”这种大陆专属的指代直接搬到台湾内容里,就很违和,得换成当地对应的东西。
这些细节,工具一个都管不了——它只动字形和少量地区词。但它们恰恰是“机翻味”和“真本地化”的分水岭。所以正确的认知是:简繁转换器解决的是本地化里“文字系统适配”这一层,它是必要的第一步,但远不是全部。文字转对了,上面这些格式、习惯、指代的本地化跟不上,繁体站照样让本地用户一眼看出“这是大陆做的”。把工具的活和这些工具管不到的活分清楚,你才能对“做一个真正地道的繁体站要花多少功夫”有个不被低估的预期。
一句话判断:你到底该不该用这个工具?
把前面所有的能力和边界收成一个判断框架,帮你快速决定要不要用它、怎么用它。
如果你的需求是“快速出一版繁体初稿、后面有人工校对兜底”——比如做台港市场的内容、需要先有个繁体底子再打磨——那它很适合,是个省力的起点。
如果你的需求是“一键转出能直接上线的、母语级地道的繁体内容”,那它满足不了,你要的是生产级方案加本地化人工,别指望这个轻量工具。如果你要处理的是专业领域(中医、法律、古籍)的精密繁体,它的常用字表和小词库撑不住,必须上专业方案加领域专家。
一句话:把它当“初稿生成器加学习工具”,它好用;当“定稿方案”,它会坑你。需求对上了,它就是趁手的;需求错配了,再好的工具也是错的选择。
关键词的简繁差异,到底怎么落到选词和页面布局上?
前面提了简繁关键词搜索量不同,这里把它落到具体的操作上,因为这才是简繁转换对SEO最实在的影响。
核心认知是:对搜索引擎来说,“软件”“軟體”“軟件”是三个不同的词。一个简体页面把“软件”机械转成繁体的“軟件”,它就只匹配到搜“軟件”的香港用户,搜“軟體”的台湾用户和搜“软件”的大陆用户都对不上。所以做多地区中文SEO,第一步不是急着转换,而是先按地区做关键词调研——搞清楚目标市场的人到底用哪个词搜、搜索量多大,再决定页面主打哪个词。这个工具的地区词库能提示你“台湾叫軟體、香港叫軟件”这个差异的存在,但具体哪个词搜索量大、值得做,得靠关键词工具去查,工具替代不了调研。
调研定了主词,落到页面上还有几个讲究。标题和正文的核心词要统一用目标市场的说法——做台湾站,标题、H1、正文就一致用“軟體”,别简繁词混着来,否则相关性信号就散了。但可以适度兼顾变体:在正文自然的地方带上“軟件”这种其它地区的说法,能多覆盖一点搜索面,前提是别堆砌、别读着别扭。这套“主词统一、变体兼顾”的布局,靠的是对地区用词的清楚认知,而工具帮你把这层差异摆到了台面上。
反过来也提醒一个常见错误:别用一个简单的简繁转换,就以为做完了多地区SEO。把简体站整站转成繁体挂上去,字是繁体了,但如果关键词没按地区重新选、用词没本地化,那它在台港的搜索结果里依然竞争不过本地内容。简繁转换是多地区中文SEO的“字形适配”这一环,必要但不充分;真正决定排名的,是建立在地区关键词调研之上的选词和内容质量。把工具的定位摆正——它解决字形,选词靠调研,地道靠人工——你的多地区中文SEO才不会停在“转了个字形”的表面功夫上。
自动检测方向,它到底靠什么判断、什么时候会判错?
自动检测是个方便功能——你不确定一段文本是简是繁,丢进去让它自己判方向。但用之前得知道它的判断有多“聪明”,免得被它带偏。
它的判断逻辑,说穿了很朴素:扫一遍文本,数出现了多少个“只在简体里有”的字、多少个“只在繁体里有”的字,哪边多就判成哪边,再往相反方向转。比如简体字明显多,它就判这是简体、给你转繁体。这套统计法在“纯简体”或“纯繁体”的长文本上很可靠,几乎不会错。
它会犯迷糊的,是几类边界情况。一是简繁混排的文本:如果一段话里简繁各半(比如复制粘贴拼凑出来的),它的比例统计会摇摆,可能判错方向。二是极短的文本:只有几个字、又恰好都是简繁通用的字(很多常用字简繁同形),它没有足够样本去统计,容易瞎猜。三是本身就有歧义的内容。所以自动检测适合“我手上一大段文本,懒得自己看是简是繁”这种省事场景;但凡涉及正式、重要的转换,建议你自己确认方向、手动选简转繁还是繁转简,别把方向判断这种基础决策完全甩给一个数字数的统计逻辑。
转换前后的差异对比和字符统计,能帮上什么忙?
这个工具除了转换本身,还附带两个辅助功能,用好了能明显提高校对效率。第一个是差异高亮:转换后,它会把发生了改动的字标出来。这个功能在校对歧义字时特别有用——你不用把成百上千字的繁体输出从头看一遍,只需重点盯那些被标出来“改动过”的字,逐个确认繁体选对没有。前面说过含“发、里、干”这类歧义字最容易转错,差异高亮正好帮你快速定位到这些“动过手脚”的地方。
第二个是字符统计:它会数出文本里简体字、繁体字、通用汉字、非汉字各有多少。这个数据的用处,一是帮你判断转换是否彻底(转完繁体后,如果统计里还残留一堆简体字,说明有字没转到,可能是表里没收的字);二是配合自动检测,让你对“这段文本到底简繁比例如何”有个量化的认识。把这两个辅助功能用起来,校对就从“大海捞针逐字看”变成“按图索骥盯改动”,效率差很多。它们不解决转换精度问题,但能让你更快地发现并修正那些精度不够导致的错误。
一个汉方草本护肤出海站,是怎么用它做台湾繁体初稿的?
讲个具体场景,比干说规则更能看清它的用法和边界。我们团队接触过一个做汉方草本护肤(主打植物成分、东方养肤概念)的出海品牌,主站是简体内容,要新开一个面向台湾市场的繁体站。台湾对这类东方养生概念的接受度高,是块好市场,但内容本地化的工作量不小——几十篇产品文案、成分科普、品牌故事,都得从简体转成台湾人读着地道的繁体。
他们的做法,是“工具出初稿、分层人工校”。第一步,把简体原文按“简转繁 + 台湾模式”批量过一遍,几十篇文案几分钟就出了一版繁体初稿,“软件层面”的字形转换和最显眼的地区词替换(虽然护肤内容里科技词不多,但“信息”转“資訊”“文件”转“檔案”这类还是被换掉了)一次到位,省去了从零逐字改的苦工。
第二步是分层校对,这步最见功夫。第一层先借差异高亮,集中核对歧义字——护肤文案里高频出现的“面”(面膜、面部)、“发”(如果涉及护发)、“干”(干燥、干性肌)这些都是一简多繁的重灾区,得逐个确认。果然,初稿里“干燥”“干性”这类被工具按写死映射转成了不对的繁体,得手动改成台湾惯用的写法。第二层是请台湾本地的兼职编辑过一遍用词和语感——成分名、养肤术语、广告话术里有大量工具词库覆盖不到的本地表达,这一层必须靠母语者。
这个案例清楚地说明了工具的卡位:它把最枯燥的字形转换和最基础的地区词替换包了,让本地化不用从一张白纸开始;但歧义字消解和地道语感这两件真正决定繁体内容质量的事,一个靠人工借差异高亮逐字核、一个靠本地母语者把关,工具都替代不了。如果当时图省事,把工具初稿直接上线,那些转错的“干燥”“面部”就成了挂在产品页上的硬伤,反而砸了“东方养肤”想立的专业人设。工具是省力的起点,不是放心的终点。
简繁双版本站,目录和URL结构该怎么搭才不打架?
把内容转好只是一半,简繁双版本要在一个站里和平共处、还能被搜索引擎正确理解,结构上有讲究。这部分超出了工具本身,但和它的输出怎么落地直接相关,值得讲清。
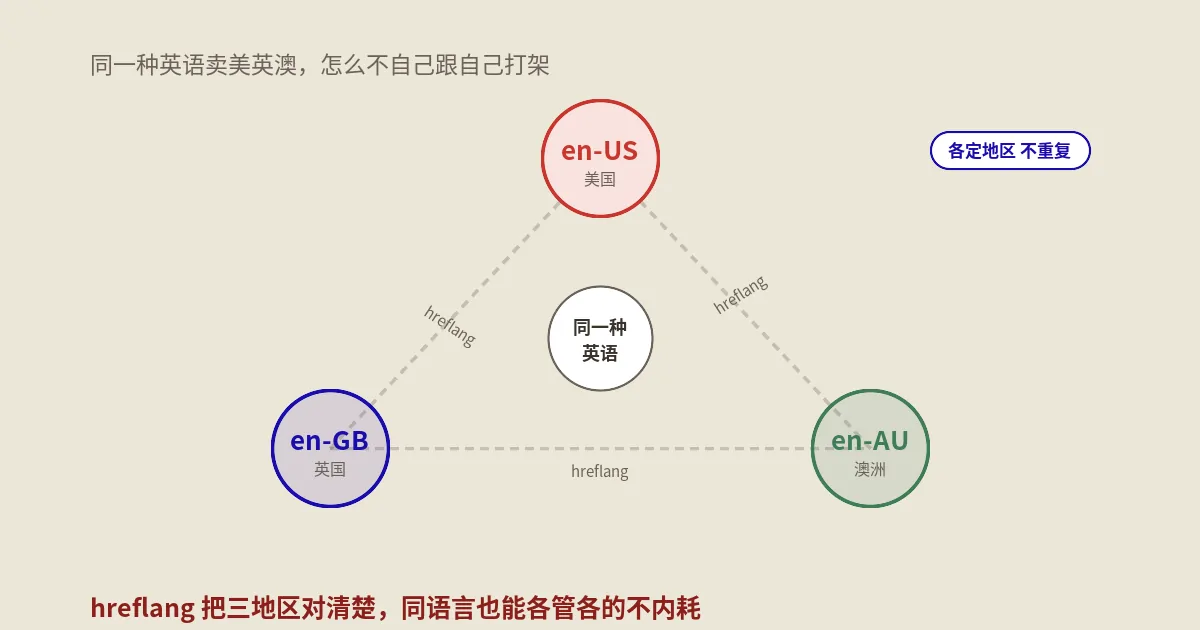
主流的做法是用独立的子目录区分语言版本,比如简体放 /zh-hans/、繁体放 /zh-hant/(要细分台港,可用 /zh-hant-tw/、/zh-hant-hk/)。每个语言版本有自己独立的URL,互不覆盖。这样做的好处是结构清晰、每个版本都能被独立收录,也方便配hreflang。要避免的反例,是“同一个URL靠cookie或IP自动切换简繁”——这种做法搜索引擎的爬虫看不到不同版本,等于白做了本地化。
结构搭好后,每个页面的 <head> 里都要用hreflang把所有语言版本互相声明一遍:简体版要列出自己,也要列出繁体版;繁体版反之。这是hreflang的硬规矩——每个版本都得“自我声明 + 声明所有兄弟版本”,漏了哪个都可能失效。把目录结构和hreflang这两件事配套做好,工具帮你转出来的繁体内容才能真正变成一个被搜索引擎认可、能独立获取流量的版本,而不是一堆躺在某个角落、爬虫都够不着的繁体文字。本地化的价值,最终要靠正确的技术落地来兑现。
它和机器翻译、专业本地化方案,分工到底在哪?
最后把它放进整个本地化工具谱系里,给它一个准确的坐标,你就不会高估也不会低估它。这条谱系上有三类东西。
最轻的一端,是这个简繁转换器这类字形/词库转换工具。它处理的是“同一种语言、不同书写系统”之间的转换——简体中文和繁体中文,本质是同一种语言,所以它不需要“翻译”,只需要换字形、换地区词。它的活儿是机械的、确定性的,快,但精度受限于字表和词库的大小。中间一端,是 OpenCC这类生产级的开源转换方案,做的事和它一样,但词条以万计、地区标准更全、消歧更讲究,是同一类工具里的“重装版”,适合对转换质量要求高、又能接受一定工程投入的场景。
最重的一端,是 机器翻译和专业本地化,它们处理的是“不同语言”之间的转换(中文转英文、日文等),或者“带文化适配的深度本地化”,那是另一个维度的问题,需要真正的语义理解。简繁转换和这些不是替代关系,而是流程上的不同环节——简繁转换解决“中文内部的书写系统适配”,翻译解决“跨语言”。
把这个谱系记清楚,你就知道这个工具该用在哪:它是面向繁体中文市场、做中文内容简繁适配的入门级利器,适合出初稿、做快速适配;要追求生产级精度,往OpenCC走;要跨语言,那是翻译的事,跟它无关。各就各位,它就是个好用的轻量工具。
最容易转错的一简多繁字,给你一份重点核对清单
既然“一简对多繁”是这个工具最大的出错源,那把那些高频踩雷的字集中列出来,你校对时心里就有了重点,不用每个字都疑神疑鬼。下面这些是简体内容里最常见、又最容易被工具转错的字,记住它们,繁体初稿出来后优先盯这几处。
“发”对应“發”(出发、发展、发财)和“髮”(头发、理发、发型),凡是和毛发有关的都该用“髮”,工具常错转成“發”。“里”对应“裡”(里面、这里、心里)和“里”(公里、邻里),表示内部、方位的多用“裡”。“干”最复杂,对应“乾”(干燥、干净、干杯)、“幹”(干活、干部、能干)和“干”(干涉、干扰、若干),三个义项各不相同。“后”对应“後”(后面、以后、前后)和“后”(皇后、太后),表方位时间的用“後”、表君主配偶的用“后”。
再列几个:“面”对应“麵”(面条、面粉、方便面)和“面”(面部、表面、见面),食物相关用“麵”。“松”对应“鬆”(轻松、松开、蓬松)和“松”(松树、松柏)。“表”对应“錶”(手表、钟表)和“表”(表格、外表、表示)。“系”对应“係”(关系、係数)、“繫”(联系、维系)和“系”(系统、中文系)。“台”对应“臺”(舞台、台湾的正式写法)和“台”(台风、一台机器)。“谷”对应“穀”(谷物、五谷)和“谷”(山谷、峡谷)。“范”对应“範”(范围、模范、规范)和“范”(姓氏)。
这份清单不用背,但要建立一个意识:看到繁体初稿里出现这些字,先停一下,确认工具选的繁体字符合上下文。它们占了一简多繁错误的绝大多数。配合前面说的差异高亮功能,你可以快速跳到这些被改动的字上逐个核对,校对效率会高很多。把这几个高频字盯死,繁体内容的质量就稳住了大半。
繁体内容的SEO收录,和简体站有什么不同要注意的?
繁体内容做好了,怎么让它在台港的搜索里被正确收录、获得流量,有几个和简体站不太一样的点要留意。
第一是编码与字符的正确性。繁体页面要确保用UTF-8编码,<html> 的 lang 属性标对(繁体用 zh-Hant 或更细的 zh-Hant-TW),让搜索引擎一眼认出这是繁体内容、推给对的用户。如果编码或语言标记出错,繁体字可能显示成乱码,或被错判成其它语言,收录就受影响。第二是搜索引擎的地区差异。台湾、香港的搜索市场以Google为主,做法和大陆以百度为主的简体SEO有差异——关键词调研要用面向台港的数据,内容偏好、外链生态也不同,不能把简体站那套原封不动搬过去。
第三是避免简繁版本互相打架。一个站如果同时有简体和繁体版本,又没用hreflang正确标注,搜索引擎可能把它们当成重复内容、或者在搜索结果里给用户推错版本(台湾用户搜到了简体版)。前面讲的目录结构加hreflang,正是为了解决这个——让每个版本各自独立收录、各自匹配对的地区用户。把这三点做到位,工具帮你转出、人工帮你打磨的繁体内容,才能真正在台港的搜索结果里站稳,而不是转好了却收录不佳、白费功夫。本地化的最后一公里,是技术收录这一关。
三步用它生成一版繁体市场的内容初稿
把它接进出海内容的本地化流程,操作就三步,适合快速产出台湾或香港版的文案初稿。
- 先定目标市场、选对模式。要发台湾,就选“简转繁 + 台湾模式”;要发香港,选“简转繁 + 香港模式”。这一步定的是“往哪个地区的繁体转”,直接决定它套哪套地区词库——选错了,台湾市场会读到香港词,反之亦然。
- 把简体原文贴进去、生成繁体初稿。它支持较大篇幅(上限约50万字符),可以整篇文案、整个产品描述一次性转。它会先按地区词库换词、再逐字转字形,几秒出一版繁体初稿,还会高亮显示哪些字发生了改动,方便你定位。
- 逐项人工校对歧义字和本地词。这步是本地化的命门,不可省。拿到初稿后,重点盯两类地方:一是含“发、里、干、后”这类一简多繁歧义字的词,逐个核对繁体字选对没有;二是那些词库没覆盖、还带着大陆味的用词,按目标市场的地道说法替换。校完,再交给本地母语者终审最稳。
这套流程的定位,是“用工具出初稿、用人工保地道”。它替你把字形转换和最常见的地区词替换这两件体力活包了,让你不用从零开始一个字一个字改;但繁体本地化里真正考验功力的歧义消解和地道用词,仍然得人来把关。把它卡在“初稿”这一步,它高效;指望它一键出能直接上线的繁体内容,它会让你在某个“頭發”上栽跟头。
简繁转换和国际SEO,到底有什么真实关联?
把它放回SEO的语境,简繁转换不是个孤立的文字游戏,它牵着国际SEO的好几根线。
第一根线是关键词的简繁差异。简体用户搜“软件”,繁体用户搜“軟體”或“軟件”——这是三个不同的搜索词,搜索量、竞争度都不一样。如果你只把简体站的内容做字形转换、不换地区词,台湾用户搜“軟體”时,你那个写着“軟件”的页面就对不上他的搜索词,白白丢掉匹配。所以面向台港市场做关键词,得用对应地区的真实用词,而这正需要地区词库的支持——这个工具能帮你把方向找对,但用词的精准还得人工补。
第二根线是 hreflang的正确标注。一个站同时有简体和繁体版本,得用hreflang告诉Google它们是同一内容的不同语言版本,否则容易被当成重复内容。Google在本地化页面的官方文档里讲清了怎么标注本地化版本。
关键在于,中文的核心区别是“文字系统”而非“国家”,所以业界推荐用基于书写系统的语言标签——zh-Hans(简体)和 zh-Hant(繁体),而不是容易把书写系统和地理位置混为一谈的 zh-CN、zh-TW。W3C关于语言标签的官方说明专门讲了 zh-Hans、zh-Hant 这两个书写系统子标签的由来和用法,是配置hreflang时的权威参考。要做台湾、香港的细分,还能进一步用 zh-Hant-TW、zh-Hant-HK。
第三根线是内容质量与重复。光做字形转换、不做本地化的繁体页面,在母语者眼里是“机翻味”很重的次品,停留、互动都会差,间接拖累SEO表现。这又回到工具的定位上——它给的是初稿,能不能成为一个让繁体用户读着舒服、愿意停留的优质页面,取决于初稿之后的人工打磨。这个工具是国际化的第一块踏板,不是终点。
常见问题解答
用它转出来的繁体内容,能直接发布到台湾或香港站吗?不建议直接发,必须先人工校对。它对“一简对多繁”的字是写死的一对一映射、不看上下文,“头发”会被转成“頭發”这种错(正确是“頭髮”);它的地区词库也只有几十个词,大量本地词没覆盖。正确做法是把它的输出当初稿,重点核对歧义字和地道用词,最好再由本地母语者终审后再发布。
它说的“智能检测”“智能替换”,是真有AI吗?没有。它的“智能检测”就是统计文本里简体字和繁体字各有多少个、比个大小来判断方向;“智能替换”就是拿地区词库做字符串查找替换。整个过程没有任何自然语言理解或AI成分,是查表加统计。这不影响它好用,但你别因为“智能”两个字就高估了它的精度。
转出来的繁体字,台湾人读着会觉得地道吗?比纯字形转换强,但远谈不上完全地道。选台湾模式时,它会把“软件、网络、博客”这些最显眼的大陆词换成“軟體、網路、部落格”,能挡掉一眼露馅的尴尬。但它的台湾词库只有约52个词,大量日常和专业用词没收,读起来仍会有大陆味。要真正地道,得在它的初稿基础上补本地化人工。
“软件”在台湾和香港转出来的结果一样吗?不一样,这正是地区词库的价值。选台湾模式,“软件”转成“軟體”;选香港模式,“软件”转成“軟件”(香港跟着用“件”而非“體”)。如果你选的是不套词库的标准模式,那“软件”只会按字形转成“軟件”,在香港对、在台湾就不地道。所以面向哪个市场,就要选对应的地区模式。
它能处理中医、法律这类专业内容里的繁体吗?不建议依赖它。专业内容里有大量异体字、罕用字和专业术语,而它的约2700字对照表是常用字子集,异体字、罕用字基本不覆盖;专业术语的地区差异它的小词库更是收不全。这类内容用它转,出错率会明显升高,必须有该领域的专业人员逐字校对。它适合的是通用的营销、产品内容,不是专业领域的精密文本。
本文标题:《中文简繁转换器怎么用?台湾香港用语本地化与那个会转错的“头发”》
本文链接:https://zhangwenbao.com/chinese-converter-simplified-traditional-localization-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0